
Современные жесткие диски обладают технологией S.M.A.R.T. C момента начала работы диск анализирует свои параметры и записывает их результат в служебную зону накопителя. Проанализировав эти данные можно узнать текущее состояние диска, критические ошибки. На этой информации можно спрогнозировать целесообразность дальнейшей эксплуатации. В Linux системах есть две утилиты способные прочитать данные состояния диска. Первая утилита smartctl. Вторая […]

Современные
жесткие диски обладают технологией S.M.A.R.T.
C момента начала работы диск анализирует свои параметры и записывает их
результат в служебную зону накопителя. Проанализировав эти данные можно узнать
текущее состояние диска, критические ошибки. На этой информации можно
спрогнозировать целесообразность дальнейшей эксплуатации.
По статистике спрогнозировать 100% отказ работоспособности HDD на основе полученной информации не получится. Это обусловлено множеством факторов. Вероятность выхода из строя в ближайшее время равна чуть более 50%.
В Linux системах есть две утилиты способные
прочитать данные состояния диска.
Первая
утилита smartctl. Вторая smartd
С помощью
утилиты Smartctl можно посмотреть состояние диска на данный момент времени.
Утилита Smartd – это демон, опрашивающий состояние
диска каждые 30 минут. Собранные данные пишутся в лог файл.
Частота опроса жесткого диска настраивается в конфигурационном файле. Файл лога по умолчанию «/var/log/messages»
Описанные
две утилиты находятся в одном пакете «Smartmontools».
По умолчанию
в операционную систему Centos этот пакет не установлен. Произведем его установку
командой:
# yum install –y smartmontoolsПосле
установки утилит можно посмотреть полную информацию о жестком диске командой:
# smartctl –all /dev/sdaВ самом Тут следует В следующем Информация о состоянии жесткого диска находится в Ниже рассмотрим название и параметры атрибутов. Если значение VALUE стало меньше THRESH в случае типа Pre-fail атрибута — существует, большая вероятность, что диск выйдет из строя в ближайшие 24 часа. Если значение VALUE стало меньше THRESH в случае Old_age атрибута — существует большая вероятность, что диск выйдет из строя т.к. выработан ресурс. Вот только когда — науке это неизвестно. Практически все значения атрибутов измеряются в условных единицах (исключение могут составлять такие параметры как температура и.т.д) Далее разберем что одначают, те или иные атрибуты из нашего Далее Утилита Smartctl очень полезна для диагностики В зависимости от типа жесткого диска в статистике могут отображаться различные атрибуты. Всю информацию по ним можно найти в Вики. Посмотреть Узнать всю Тут следует Команда 
начале полученной информации выводится описание жесткого диска.
остановиться на таких пунктах как:
твердотельное устройство)
данных)
разделе идет предварительная Smart информация устройства
test result: PASSED — Результат теста самооценки SMART общего состояния
здоровья: ПРОЙДЕН.
SMART Values – общие данные SMART. Тут описываются общие настройки и
рекомендуемые параметры настройки.
следующем разделе:
номер.
Name – Имя атрибута
флаг, назначенный производителем.
диска на основе Raw_value. Измеряется в условных единицах). Низкое значение
говорит о быстрой деградации диска или о возможном скором сбое. т.е. чем выше
значение Value атрибута, тем лучше. Это значение атрибута нужно сравнивать с
пороговым (threshold) значением. Если это критический атрибут и значение ниже
порогового — нужно проводить замену диска.
может изменяться на протяжении жизни диска, и не должно быть ниже или равным
пороговому значению (threshold). По нему нельзя однозначно судить о
здоровье диска, его необходимо сравнивать со значением Thresh.
параметр Value для того, чтобы состояние атрибута
было признано критическим.
атрибута. Критические (Pre-fail) и не критические (Old_age)
– когда происходит
обновление информации
Worst значениями).
примера.
операций переназначения секторов. При обнаружении повреждённого сектора на
винчестере, информация из него помечается и переносится в специально отведённую
зону, происходит утилизация bad блоков, с последующим консервированием этих
мест на диске. Этот процесс называют remapping. Чем больше значение Reallocated
Sectors Count, тем хуже состояние поверхности дисков — физический износ
поверхности. Поле raw value содержит общее количество переназначенных секторов.
устройством, во включенном состоянии. В качестве порогового значения для него
выбирается паспортное время наработки на отказ.
–выключения.
текущий уровень жизни SSD в процентах.
переназначенных секторов.
ошибок.
из строя этот счётчик увеличивается. Большое число таких ячеек указывает на
высокую вероятность того, что диск выйдет из строя преждевременно – задолго до
достижения заложенного производителем числа циклов перезаписи.
блоков во время выполнения.
Необработанное значение Raw Value: количество ошибок, которые не
удалось исправить с помощью внутренних подпрограмм накопителя.
жесткого диска.
ошибок считывания, исправленных оборудованием накопителя с применением кода
коррекции ошибок. Подобные ошибки не требуют повторного считывания сектора, и
не приводят к потере скорости обмена данными, но большое их количество говорит
об ухудшении параметров тракта считывания.
Количество ошибок при передаче данных в режиме прямого доступа к памяти,
обнаруженных средствами циклического избыточного кода. Аппаратные средства
контроля передачи данных из накопителя в оперативную память обнаружили ошибку
контрольной суммы и исправили ее, если ошибка исправимая. В данном случае
алгоритм обычной работы диска не изменяется. В случае же неисправимой ошибки,
процедура ее обработки выполняется системой.
записанных секторов LBA. Значение Raw Value : совокупное количество секторов, записанных
системой. Значение увеличивается на 1 на каждые 65 536 секторов (32 МБ),
записываемых системой.
сообщение «No Errors Logged» говорит о том, что ошибки не зарегистрированы.
состояния жестких дисков.
описание жесткого диска можно командой:# smartctl – i /dev/sda
информацию об устройстве можно командой:# smartctl –x /dev/sda
обратить внимание на информацию о температуре жесткого диска. В заголовке
указывается как часто происходит замер температуры и как часто эта информация
логируется. # smartctl –scan выводит список подключенных
устройств.
Одно из самых важных устройств компьютера — это жесткий диск, именно на нём хранится операционная система и вся ваша информация. Единица хранения информации на жестком диске — сектор или блок. Это одна ячейка в которую записывается определённое количество информации, обычно это 512 или 1024 байт.
Битые сектора, это повреждённые ячейки, которые больше не работают по каким либо причинам. Но файловая система всё ещё может пытаться записать в них данные. Прочитать данные из таких секторов очень сложно, поэтому вы можете их потерять. Новые диски SSD уже не подвержены этой проблеме, потому что там существует специальный контроллер, следящий за работоспособностью ячеек и перемещающий данные из нерабочих в рабочие. Однако традиционные жесткие диски используются всё ещё очень часто. В этой статье мы рассмотрим как проверить диск на битые секторы Linux.
Для поиска битых секторов можно использовать утилиту badblocks. Если вам надо проверить корневой или домашний раздел диска, то лучше загрузится в LiveCD, чтобы файловая система не была смонтирована. Все остальные разделы можно сканировать в вашей установленной системе. Вам может понадобиться посмотреть какие разделы есть на диске. Для этого можно воспользоваться командой fdisk:
sudo fdisk -l /dev/sda1
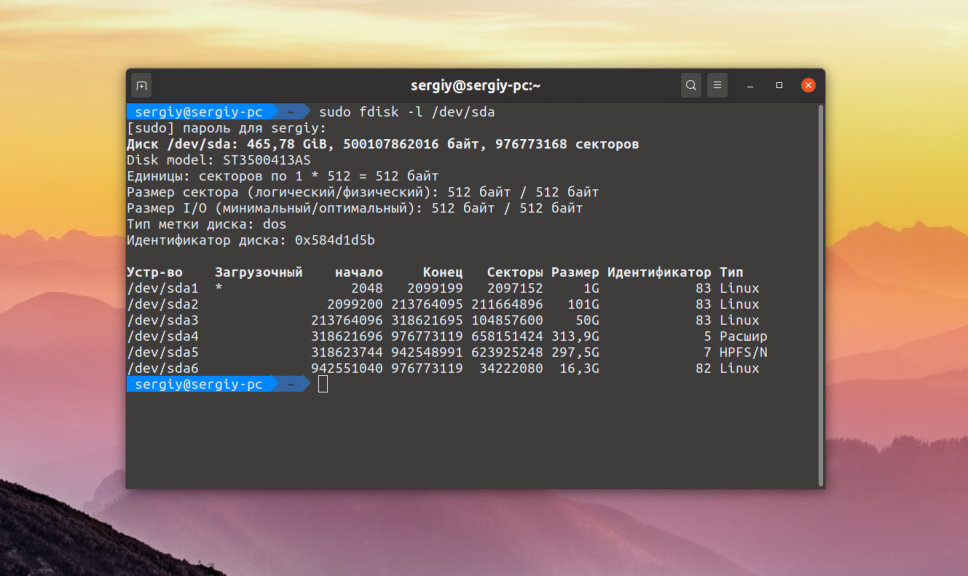
Или если вы предпочитаете использовать графический интерфейс, это можно сделать с помощью утилиты Gparted. Просто выберите нужный диск в выпадающем списке:
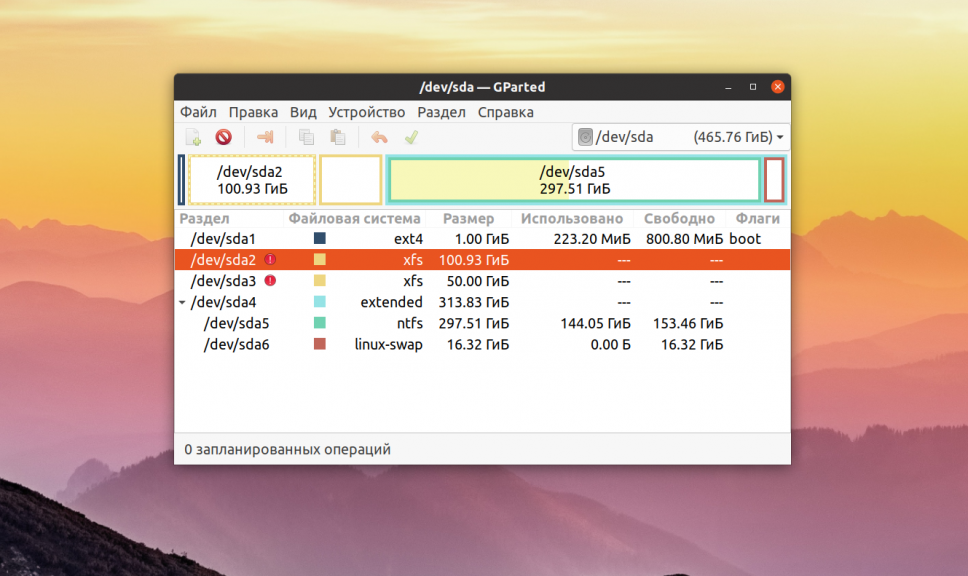
В этом примере я хочу проверить раздел /dev/sda2 с файловой системой XFS. Как я уже говорил, для этого используется команда badblocks. Синтаксис у неё довольно простой:
$ sudo badblocks опции /dev/имя_раздела_диска
Давайте рассмотрим опции программы, которые вам могут понадобится:
- -e — позволяет указать количество битых блоков, после достижения которого дальше продолжать тест не надо;
- -f — по умолчанию утилита пропускает тест с помощью чтения/записи если файловая система смонтирована чтобы её не повредить, эта опция позволяет всё таки выполнять эти тесты даже для смонтированных систем;
- -i — позволяет передать список ранее найденных битых секторов, чтобы не проверять их снова;
- -n — использовать безопасный тест чтения и записи, во время этого теста данные не стираются;
- -o — записать обнаруженные битые блоки в указанный файл;
- -p — количество проверок, по умолчанию только одна;
- -s — показывать прогресс сканирования раздела;
- -v — максимально подробный режим;
- -w — позволяет выполнить тест с помощью записи, на каждый блок записывается определённая последовательность байт, что стирает данные, которые хранились там раньше.
Таким образом, для обычной проверки используйте такую команду:
sudo badblocks -v /dev/sda2 -o ~/bad_sectors.txt
Это безопасно и её можно выполнять на файловой системе с данными, она ничего не повредит. В принципе, её даже можно выполнять на смонтированной файловой системе, хотя этого делать не рекомендуется. Если файловая система размонтирована, можно выполнить тест с записью с помощью опции -n:
sudo badblocks -vn /dev/sda2 -o ~/bad_sectors.txt
После завершения проверки, если были обнаружены битые блоки, надо сообщить о них файловой системе, чтобы она не пыталась писать туда данные. Для этого используйте утилиту fsck и опцию -l:
fsck -l ~/bad_sectors.txt /dev/sda1
Если на разделе используется файловая система семейства Ext, например Ext4, то для поиска битых блоков и автоматической регистрации их в файловой системе можно использовать команду e2fsck. Например:
sudo e2fsck -cfpv /dev/sda1
Параметр -с позволяет искать битые блоки и добавлять их в список, -f — проверяет файловую систему, -p — восстанавливает повреждённые данные, а -v выводит всё максимально подробно.
Выводы
В этой статье мы рассмотрели как выполняется проверка диска на битые секторы Linux, чтобы вовремя предусмотреть возможные сбои и не потерять данные. Но на битых секторах проблемы с диском не заканчиваются. Там есть множество параметров стабильности работы, которые можно отслеживать с помощью таблицы SMART. Читайте об этом в статье Проверка диска в Linux.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Об авторе
![]()
Основатель и администратор сайта losst.ru, увлекаюсь открытым программным обеспечением и операционной системой Linux. В качестве основной ОС сейчас использую Ubuntu. Кроме Linux, интересуюсь всем, что связано с информационными технологиями и современной наукой.
Throughout this answer I’ll assume, that a storage drive appears as a block device at the path /dev/sdc. To find the path of a storage drive in our current setup, use:
- Gnome Disks
 (formerly Gnome Disk Utility, a. k. a.
(formerly Gnome Disk Utility, a. k. a. palimpsest), if a GUI is available, or - on the terminal look at the output of
lsblkandls -l /dev/disk/by-idand try to find the right device by size, partitioning, manufacturer and model name.
Basic check
- only detects entirely unresponsive media
- almost instantaneous (unless medium is spun down or broken)
- safe
- works on read-only media (e. g. CD, DVD, BluRay)
Sometimes a storage medium simply refuses to work at all. It still appears as a block device to the kernel and in the disk manager, but its first sector holding the partition table is not readable. This can be verified easily with:
sudo dd if=/dev/sdc of=/dev/null count=1
If this command results in a message about an “Input/output error”, our drive is broken or otherwise fails to interact with the Linux kernel as expected. In the a former case, with a bit of luck, a data recovery specialist with an appropriately equipped lab can salvage its content. In the latter case, a different operating system is worth a try. (I’ve come across USB drives that work on Windows without special drivers, but not on Linux or OS X.)
S.M.A.R.T. self-test
- adjustable thoroughness
- instantaneous to slow or slower (depends on thoroughness of the test)
- safe
- warns about likely failure in the near future
Devices that support it, can be queried about their health through S.M.A.R.T. or instructed to perform integrity self-tests of different thoroughness. This is generally the best option, but usually only available on (non-ancient) hard disk and solid state drives. Most removable flash media don’t support it.
Further resources and instructions:
- Answer about S.M.A.R.T. on this question
- How can I check the SMART status of a drive on Ubuntu 14.04 through 16.10?
Read-only check
- only detects some flash media errors
- quite reliable for hard disks
- slow
- safe
- works on read-only media (e. g. CD, DVD, BluRay)
To test the read integrity of the whole device without writing to it, we can use badblocks(8) like this:
sudo badblocks -b 4096 -c 4096 -s /dev/sdc
This operation can take a lot of time, especially if the storage drive actually is damaged. If the error count rises above zero, we’ll know that there’s a bad block. We can safely abort the operation at any moment (even forcefully like during a power failure), if we’re not interested in the exact amount (and maybe location) of bad blocks. It’s possible to abort automatically on error with the option -e 1.
Note for advanced usage: if we want to reuse the output for e2fsck, we need to set the block size (-b) to that of the contained file system. We can also tweak the amount of data (-c, in blocks) tested at once to improve throughput; 16 MiB should be alright for most devices.
Non-destructive read-write check
- very thorough
- slowest
- quite safe (barring a power failure or intermittent kernel panic)
Sometimes – especially with flash media – an error only occurs when trying to write. (This will not reliably discover (flash) media, that advertise a larger size, than they actually have; use Fight Flash Fraud instead.)
-
NEVER use this on a drive with mounted file systems!
badblocksrefuses to operate on those anyway, unless you force it. -
Don’t interrupt this operation forcefully! Ctrl+C (SIGINT/SIGTERM) and waiting for graceful premature termination is ok, but
killall -9 badblocks(SIGKILL) isn’t. Upon forceful terminationbadblockscannot restore the original content of the currently tested block range and will leave it overwritten with junk data and possibly corrupt the file system.
To use non-destructive read-write checks, add the -n option to the above badblocks command.
Destructive read-write check
- very thorough
- slower
- ERASES ALL DATA ON THE DRIVE
As above, but without restoring the previous drive content after performing the write test, therefore it’s a little faster. Since data is erased anyway, forceful termination remains without (additional) negative consequence.
To use destructive read-write checks, add the -w option to the above badblocks command.
Неисправный жёсткий диск — одно из самых неприятных явлений в работе компьютера. Мало того что мы легко можем потерять очень много важной информации и файлов, так и замена HDD неслабо бьёт по бюджету. Прибавим к этому потраченное время и нервы, которые, как известно, не восстанавливаются. Чтобы не дать проблеме застать нас врасплох и заранее диагностировать её, стоит знать, как проверить жёсткий диск на ошибки в ОС Ubuntu. Программных средств, предоставляющих такие услуги, предостаточно.

Основатель и администратор сайта losst.ru, увлекаюсь открытым программным обеспечением и операционной системой Linux. В качестве основной ОС сейчас использую Ubuntu. Кроме Linux, интересуюсь всем, что связано с информационными технологиями и современной наукой.












