
Статистический анализ случайных ошибок
При проведении серии измерений некоторой
физической величины (например, длины,
с помощью линейки или силы тока с помощью
амперметра) из-за случайных ошибок
отдельные значения x1,x2, и т.
д. неодинаковы.
Абсолютнаяпогрешность определяет
границы интервала, внутри которого с
некоторой вероятностью заключено
«истинное значение» искомой величины,
и она равна взятой по модулю разности
между «истинным значением» измеряемой
величины и его приближенным значениемxi.
![]()
Но так как «истинное значение» измеряемой
величины остается неизвестным, то в
качестве наилучшего значения искомой
величины принимают среднее арифметическое:
![]() (1)
(1)
где xi–i-е измеренное
значение,an— общее число измерений. Символ![]() означает
означает
суммирование отi=1доi=n.Абсолютная погрешность отдельногоi-го
измерения запишется тогда так
![]() или
или![]() .
.
Малый разброс измеренных
значений относительно среднего
значения означает высокую точность.
Относительнойпогрешностьюxназывается отношение абсолютной
погрешности![]() к значениюxист,
к значениюxист,
т.е.
![]() .
.
В отличие от абсолютной погрешности,
которая имеет такую же размерность, как
и сама величина x,
относительная погрешность является
безразмерной величиной (её выражают
или в долях единицы, или в процентах).
Для оценки величины случайной ошибки
(погрешности) измерения обычно используют
величину
![]() —
—
дисперсию измерения (стандартное
отклонение)
![]() , (2)
, (2)
где
n – общее число
измерений.
Если стандартное отклонение мало, то
разброс измеренных значений относительно
среднего значения является малым,
следовательно, точность измерения
высокая. Заметим, что стандартное
отклонение является всегда положительным
и имеет ту же размерность, что и измеренные
значения.
Используя всю совокупность измерений,
мы, естественно, находим искомое значение
измеряемой величины с лучшей точностью,
чем это можно сделать с помощью одного
измерения. Причина улучшения заключается
в том, что положительные и отрицательные
ошибки частично компенсируются при
усреднении результатов нескольких
измерений.
Поэтому в качестве меры погрешности
результатов измеренийвеличиныx(или неопределенности среднего значения
![]() )
)
принимаютстандартное отклонение от
среднегоSn,
которое часто называют средним
квадратичным отклонением илистандартной
погрешностьюи определяют как
![]() .(3)
.(3)
Для более полного обсуждения разброса
или распределения измеренных значений
полезно рассмотреть нормальное или
Гауссово распределение.
Нормальное или Гауссово распределение
На рис. 2ав виде диаграммы показано
распределение результатовnизмерений некоторой физической величиныxотносительно среднего
значения
![]() .
.
Ось абцисс разбита на равные интервалы
ширинойx.
Высота каждого столбика диаграммы
показывает количествоN(x)
близких результатов измерений, попадающих
в интервалxс центром в точкеx.
Пунктирная кривая (которая здесь не
является симметричной) вычерчена, чтобы
показать зависимость числа отсчетовN(x)
отx при относительно
небольшом числе измерений.

Рис.
2.
Если число измерений nстановитсяочень большим, то
результаты измерений стремятся к
симметричному распределению около
среднего значения (рис. 2б). Как
показывается в теории вероятности, в
идеальном случае такая кривая описывается
аналитическим выражением
![]() , (4)
, (4)
где n— очень большое число измерений,
![]() — среднее значение, а- стандартное отклонение, определяемое
— среднее значение, а- стандартное отклонение, определяемое
по формуле (2) при условииn
. Величина2называетсядисперсией. Уравнение
(4) представляет собойраспределение
Гауссаилинормальноераспределение.
Для большого числа измерений nраспределение Гаусса описывает
теоретическое распределение измеренных
значенийxотносительно
среднего значения
![]() .
.
Если измерения выполняются с высокой
точностью, тобудет
малым, и нормальное, или Гауссово,
распределение будет иметь острый пик
приx=
![]() (рис. 3).
(рис. 3).

Рис.
3.
Разделив
обе части уравнения (4) на nи определивN(x)/n
какР(x), имеем:
![]() . (5)
. (5)
Выражение (5) имеет смысл плотности
вероятности того, что в результате
измерения мы получим значение х.
Таким образом, вероятность того, что
измеренное значениеxбудет лежать в некотором интервалеx1<x<x2,
определяется площадью под соответствующим
участком кривой:
 .
.
Заметим, что наиболее вероятным
значением, которое можно ожидать в
результате измерения, являетсясреднее
значение. Следует также отметить, что
полная площадь под кривой, представляющей
функциюP(x),
всегда равна единице:
![]() .
.
Особенностью распределения Гаусса
является то, что 68% всех результатов
измерений попадают в интервал от
![]() до
до![]() ,
,
95% всех результатов измерений попадают
в интервал от![]() до
до![]() ,
,
а 99,7% всех результатов измерений попадают
в интервал от![]() до
до![]() .
.
Другими словами, с вероятностью 0,68
истинное значение величиныxлежит в интервале![]() ,
,
с вероятностью 0,95 – в интервале![]() ,
,
и т.д.
Следует иметь в виду, что распределение
Гаусса не является единственно возможным.
Могут существовать и другие виды
распределений, например, распределение
Пуассона, экспоненциальное распределение,
2-распределение
и т.д. Тем не менее, нормальное распределение
встречается достаточно часто, причём
все остальные распределения в пределе
(приn)
переходят в распределение Гаусса.
На практике, однако, число измерений
обычно сравнительно невелико. В этом
случае для повышения достоверности
результатов измерений следует при
оценке погрешности пользоваться
модифицированными формулами. Так,
абсолютная погрешность xизмеряемой величиныxпри относительно малом (скажем, 10 — 100)
количестве измерений определяется как:
 , (6)
, (6)
где
t,n– коэффициент (коэффициент Стьюдента),
зависящий от числа измеренийnи от величины доверительной вероятности. Значения коэффициентовt,nдля некоторых различных значенийnиприведены в табл.
1.![]() —
—
полная абсолютная погрешность или
доверительный интервал, внутри которого
находится истинное значение величины![]() .
.
В соответствии с действующими
государственными стандартами рекомендуется
при оценке погрешностей пользоваться
доверительной вероятностью = 0,95.
Таблица 1. Коэффициенты Стьюдента
|
|
|
0,90 |
0,95 |
0,98 |
|
2 |
6,31 |
12,71 |
31,82 |
|
|
3 |
2,92 |
4,30 |
6,96 |
|
|
4 |
2,35 |
3,18 |
4,54 |
|
|
5 |
2,13 |
2,78 |
3,75 |
|
|
6 |
2,02 |
2,57 |
3,36 |
|
|
7 |
1,94 |
2,45 |
3,14 |
|
|
8 |
1,90 |
2,36 |
3,00 |
|
|
9 |
1,86 |
2,31 |
2,90 |
|
|
10 |
1,83 |
2,26 |
2,82 |
|
|
12 |
1,78 |
2,18 |
2,68 |
|
|
15 |
1,75 |
2,13 |
2,60 |
|
|
30 |
1,70 |
2,04 |
2,46 |
|
|
50 |
1,68 |
2,01 |
2,40 |
|
|
100 |
1,66 |
1,98 |
2,36 |
 n
n
Таким образом, окончательный результат
измерений запишется в виде:
![]() ед.
ед.
измерений, (), (7)
где xопределяется из выражения (6). Запись
(7) означает, что истинное значение
величиныx с
вероятностьюнаходится в интервале (доверительном
интервале) значений от![]() до
до![]() .
.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Все сводится к использованию возможностей методов статистического анализа, с помощью которых ученые сотрудничают и собирают данные для выявления тенденций и закономерностей.
За последние десять лет повседневный бизнес претерпел значительные изменения. Нередко кажется, что все осталось по-прежнему, будь то технологии, используемые на рабочих местах, или программное обеспечение, применяемое для общения.
Сейчас доступно огромное количество информации, которая раньше была редкостью. Но она может быть подавляющей, если вы не имеете ни малейшего представления о том, как проанализировать данные вашей компании, чтобы найти в них значимый и точный смысл.
В этом блоге будут рассмотрены 5 различных методов статистического анализа, а также подробное обсуждение каждого метода.
Что такое метод статистического анализа?
Практика сбора и анализа данных для выявления закономерностей и тенденций известна как статистический анализ. Это метод устранения предвзятости при оценке данных с помощью численного анализа.
Эти методы статистического анализа полезны для сбора интерпретаций исследований, создания статистических моделей и организации опросов и исследований.
Для анализа данных используются два основных статистических метода:
- описательная статистика, которая использует такие показатели, как среднее и медиана, для обобщения данных,
- инференциальная статистика, экстраполирующая результаты из данных с помощью статистических тестов, таких как t-тест студента.
Следующие три фактора определяют, является ли статистический подход наиболее подходящим:
- Цель и основная задача исследования,
- Вид и дисперсия используемых данных, и
- Тип наблюдений (парные/непарные).
«Параметрический» относится ко всем типам статистических процедур, используемых для сравнения средних. Напротив, «непараметрические» относятся к статистическим методам, которые сравнивают меры, отличные от средних, такие как медианы, средние ранги и пропорции.
Для каждого уникального обстоятельства статистические методы анализа в биостатистике могут быть использованы для анализа и интерпретации данных. Знание допущений и условий применения статистических методов необходимо для выбора наилучшего статистического метода анализа данных.
5 методов статистического анализа для исследований и анализа
Независимо от того, являетесь ли вы специалистом по исследованию данных или нет, нет сомнений в том, что большие данные захватывают мир. В результате вы должны знать, с чего начать. Существует 5 вариантов этого метода статистического анализа:
-
Среднее значение
Большие данные захватывают мир, как бы вы их ни нарезали. Среднее значение, чаще известное как среднее, является исходным методом, используемым для проведения статистического анализа. Чтобы найти среднее значение, нужно сложить список чисел, разделить общую сумму на составляющие списка, а затем добавить еще один список чисел.
Применение этой техники позволяет быстро просмотреть данные и одновременно определить общую тенденцию сбора данных. Простой и быстрый расчет также выгоден пользователям метода.
Центр рассматриваемых данных определяется с помощью среднего статистического значения. Результат известен как среднее значение представленных данных. В реальном мире при взаимодействии в сфере исследований, образования и спорта часто используются уничижительные выражения. Подумайте, как часто в разговоре упоминается средний показатель бейсболиста — его среднее значение, если вы считаете себя специалистом по исследованию данных. В результате вы должны знать, с чего начать.
-
Стандартное отклонение
Статистический метод, называемый стандартным отклонением, измеряет, насколько широко распределены данные от среднего значения.
При работе с данными высокое стандартное отклонение указывает на то, что данные сильно разбросаны от среднего значения. Низкое отклонение указывает на то, что большинство данных соответствует среднему значению и может также называться ожидаемым значением набора.
Стандартное отклонение часто используется при анализе дисперсии точек данных — независимо от того, сгруппированы они или нет.
Представьте, что вы маркетолог, который только что закончил опрос клиентов. Предположим, вы хотите определить, будет ли большая группа клиентов давать такие же ответы. В этом случае после получения результатов опроса вам следует оценить зависимость ответов. Если стандартное отклонение низкое, то можно спрогнозировать ответы большего числа клиентов.
-
Регрессия
Регрессия в статистике изучает связь между независимой переменной и зависимой переменной (информацией, которую вы пытаетесь оценить) (данные, используемые для прогнозирования зависимой переменной).
Это также можно объяснить с точки зрения того, как одна переменная влияет на другую, или как изменения в одной непоследовательной величине приводят к изменениям в другой, или наоборот, простая причина и следствие. Это предполагает, что результат зависит от одного или нескольких факторов.
На графиках и диаграммах регрессионного анализа используются линии, показывающие тенденции за заранее определенный период, а также силу или слабость корреляций между переменными.
-
Проверка гипотез
Два набора случайных переменных в наборе данных должны быть проверены с помощью проверки гипотез, иногда называемой «Т-тестированием» в статистическом анализе.
Этот подход фокусируется на определении того, справедливо ли данное утверждение или заключение для набора данных. Он позволяет сравнить данные с многочисленными предположениями и гипотезами. Он также может помочь в прогнозировании того, как выбор повлияет на компанию.
Проверка гипотезы в статистике определяет количество при определенном предположении. Результат проверки показывает, верно ли предположение или оно нарушено. Нулевая гипотеза, иногда известная как гипотеза 0, является этим предположением. Первая гипотеза, часто известная как гипотеза 1, — это любая другая теория, которая противоречит гипотезе 0.
При проверке гипотез результаты теста считаются статистически значимыми, если они показывают, что событие не могло произойти случайно или случайным образом.
-
Определение размера выборки
При оценке данных для статистического анализа сбор достоверных данных иногда может быть затруднен, поскольку набор данных слишком велик. В таких случаях большинство выбирает метод, известный как определение размера выборки, который предполагает изучение выборки или меньшего объема данных.
Для эффективного выполнения этой задачи необходимо выбрать подходящий размер выборки. Вы не получите достоверных результатов после анализа, если размер выборки будет слишком мал.
Для достижения этого результата вы будете использовать несколько методов выборки данных. Для этого вы можете разослать опрос своим клиентам, а затем использовать метод прямой случайной выборки, чтобы отобрать данные клиентов для выборочного анализа.
И наоборот, чрезмерный размер выборки может привести к потере времени и денег. Чтобы определить размер выборки, можно рассмотреть такие факторы, как стоимость, время или простота сбора данных.
Вы запутались? Не волнуйтесь! Вы можете воспользоваться нашим калькулятором размера выборки.
Вывод
Способность аналитически мыслить жизненно важна для корпоративного успеха. Поскольку данные являются одним из наиболее важных ресурсов, доступных сегодня, их эффективное использование может привести к лучшим результатам и принятию решений.
Независимо от выбранных вами методов статистического анализа, обязательно обратите пристальное внимание на каждый потенциальный недостаток и его конкретную формулу. Ни один метод не является правильным или неправильным, и не существует золотого стандарта. Все будет зависеть от собранной вами информации и выводов, которые вы надеетесь сделать.
Статистическая погрешность — это та неопределенность в оценке истинного значения измеряемой величины, которая возникает из-за того, что несколько повторных измерений тем же самым инструментом дали различающиеся результаты. Возникает она, как правило, из-за того, что результаты измерения в микромире не фиксированы, а вероятностны. Она тесно связана с объемом статистики: обычно чем больше данных, тем меньше статистическая погрешность и тем точнее результат измерения. Среди всех типов погрешностей она, пожалуй, самая безобидная: понятно, как ее считать, и понятно, как с ней бороться.
Статистическая погрешность: чуть подробнее
Предположим, что ваш детектор может очень точно измерить какую-то величину в каждом конкретном столкновении. Это может быть энергия или импульс какой-то родившейся частицы, или дискретная величина (например, сколько мюонов родилось в событии), или вообще элементарный ответ «да» или «нет» на какой-то вопрос (например, родилась ли в этом событии хоть одна частица с импульсом больше 100 ГэВ).
Это конкретное число, полученное в одном столкновении, почти бессмысленно. Скажем, взяли вы одно событие и выяснили, что в нём хиггсовский бозон не родился. Никакой научной пользы от такого единичного факта нет. Законы микромира вероятностны, и если вы организуете абсолютно такое же столкновение протонов, то картина рождения частиц вовсе не обязана повторяться, она может оказаться совсем другой. Если бозон не родился сейчас, не родился в следующем столкновении, то это еще ничего не говорит о том, может ли он родиться вообще и как это соотносится с теоретическими предсказаниями. Для того, чтобы получить какое-то осмысленное число в экспериментах с элементарными частицами, надо повторить эксперимент много раз и набрать статистику одинаковых столкновений. Всё свое рабочее время коллайдеры именно этим и занимаются, они накапливают статистику, которую потом будут обрабатывать экспериментаторы.
В каждом конкретном столкновении результат измерения может быть разный. Наберем статистику столкновений и усредним по ней результат. Этот средний результат, конечно, тоже не фиксирован, он может меняться в зависимости от статистики, но он будет намного стабильнее, он не будет так сильно прыгать от одной статистической выборки к другой. У него тоже есть некая неопределенность (в статистическом анализе она так и называется: «неопределенность среднего»), но она обычно небольшая. Вот эта величина и называется статистической погрешностью измерения.
Итак, когда экспериментаторы предъявляют измерение какой-то величины, то они сообщают результат усреднения этой величины по всей набранной статистике столкновений и сопровождают его статистической погрешностью. Именно такие средние значения имеют физический смысл, только их может предсказывать теория.
Есть, конечно, и иной источник статистической погрешности: недостаточный контроль условий эксперимента при повторном измерении. Если в физике частиц этот источник можно попытаться устранить, по крайней мере, в принципе, то в других разделах естественных наук он выходит на первый план; например, в медицинских исследованиях каждый человек отличается от другого по большому числу параметров.
Как считать статистическую погрешность?
Существует теория расчета статистической погрешности, в которую мы, конечно, вдаваться не будем. Но есть одно очень простое правило, которое легко запомнить и которое срабатывает почти всегда. Пусть у вас есть статистическая выборка из N столкновений и в ней присутствует n событий какого-то определенного типа. Тогда в другой статистической выборке из N событий, набранной в тех же условиях, можно ожидать примерно n ± √n таких событий. Поделив это на N, мы получим среднюю вероятность встретить такое событие и погрешность среднего: n/N ± √n/N. Оценка истинного значения вероятности такого типа события примерно соответствует этому выражению.
Сразу же, впрочем, подчеркнем, что эта простая оценка начинает сильно «врать», когда количество событий очень мало. В науке обсчета маленькой статистики есть много дополнительных тонкостей.
Более серьезное (но умеренно краткое) введение в методы статистической обработки данных в применении к экспериментам на LHC см. в лекциях arXiv.1307.2487.
Именно поэтому эксперименты в физике элементарных частиц стараются оптимизировать не только по энергии, но и по светимости. Ведь чем больше светимость, тем больше столкновений будет произведено — значит, тем больше будет статистическая выборка. И уже это позволит сделать измерения более точными — даже без каких-либо улучшений в эксперименте. Примерная зависимость тут такая: если вы увеличите статистику в k раз, то относительные статистические погрешности уменьшатся примерно в √k раз.
Этот пример — некая симуляция того, как могло бы происходить измерение массы ρ-мезона свыше полувека назад, на заре адронной физики, если бы он был вначале обнаружен в процессе e+e– → π+π–. А теперь перенесемся в наше время.

Сейчас этот процесс изучен вдоль и поперек, статистика набрана огромная (миллионы событий), а значит, и масса ρ-мезона сейчас определена несравнимо точнее. На рис. 3 показано современное состояние дел в этой области масс. Если ранние эксперименты еще имели какие-то существенные погрешности, то сейчас они практически неразличимы глазом. Огромная статистика позволила не только измерить массу (примерно равна 775 МэВ с точностью в десятые доли МэВ), но и заметить очень странную форму этого пика. Такая форма получается потому, что практически в том же месте на шкале масс находится и другой мезон, ω(782), который «вмешивается» в процесс и искажает форму ρ-мезонного пика.
Другой, гораздо более реальный пример влияния статистики на процесс поиска и изучения хиггсовского бозона обсуждался в новости Анимации показывают, как в данных LHC зарождался хиггсовский сигнал.
Статистические ошибки
Использование
методов биометрии позволяет исследователю
на ограниченном по численности материале
делать заключения о проявлении признака,
его изменчивости и других параметрах
в генеральной совокупности. Но так
как выборочная совокупность — часть
генеральной и ее формируют методом
случайного отбора, то в выборку могут
попасть животные с более низкими
продуктивными качествами, или несколько
лучшие особи. В этом случае вычисленные
значения M, б, Cv и
других биометрических величин будут
отличаться от значений этих величин в
генеральной совокупности, то есть
выборка отражает генеральную совокупность
с ошибкой. Эти ошибки, связанные с
методом выборочности, называются
статистическими и устранить их нельзя.
Ошибки не будет лишь в том случае, когда
в обработку включаются все члены
генеральной совокупности. Величины
статистических ошибок зависят от
изменчивости признаков и объема выборки:
чем более изменчив признак, тем больше
ошибка, и чем больше объем выборки, тем
она меньше. Ошибки статистических
величин в биометрии принято обозначать
буквой m.
Ошибки
имеют все статистические величины.
Вычисляют их по формулам:
![]()
Все сводится к использованию возможностей методов статистического анализа, с помощью которых ученые сотрудничают и собирают данные для выявления тенденций и закономерностей.
За последние десять лет повседневный бизнес претерпел значительные изменения. Нередко кажется, что все осталось по-прежнему, будь то технологии, используемые на рабочих местах, или программное обеспечение, применяемое для общения.
Сейчас доступно огромное количество информации, которая раньше была редкостью. Но она может быть подавляющей, если вы не имеете ни малейшего представления о том, как проанализировать данные вашей компании, чтобы найти в них значимый и точный смысл.
В этом блоге будут рассмотрены 5 различных методов статистического анализа, а также подробное обсуждение каждого метода.
Что такое метод статистического анализа?
Практика сбора и анализа данных для выявления закономерностей и тенденций известна как статистический анализ. Это метод устранения предвзятости при оценке данных с помощью численного анализа.
Эти методы статистического анализа полезны для сбора интерпретаций исследований, создания статистических моделей и организации опросов и исследований.
Для анализа данных используются два основных статистических метода:
- описательная статистика, которая использует такие показатели, как среднее и медиана, для обобщения данных,
- инференциальная статистика, экстраполирующая результаты из данных с помощью статистических тестов, таких как t-тест студента.
Следующие три фактора определяют, является ли статистический подход наиболее подходящим:
- Цель и основная задача исследования,
- Вид и дисперсия используемых данных, и
- Тип наблюдений (парные/непарные).
«Параметрический» относится ко всем типам статистических процедур, используемых для сравнения средних. Напротив, «непараметрические» относятся к статистическим методам, которые сравнивают меры, отличные от средних, такие как медианы, средние ранги и пропорции.
Для каждого уникального обстоятельства статистические методы анализа в биостатистике могут быть использованы для анализа и интерпретации данных. Знание допущений и условий применения статистических методов необходимо для выбора наилучшего статистического метода анализа данных.
5 методов статистического анализа для исследований и анализа
Независимо от того, являетесь ли вы специалистом по исследованию данных или нет, нет сомнений в том, что большие данные захватывают мир. В результате вы должны знать, с чего начать. Существует 5 вариантов этого метода статистического анализа:
-
Среднее значение
Большие данные захватывают мир, как бы вы их ни нарезали. Среднее значение, чаще известное как среднее, является исходным методом, используемым для проведения статистического анализа. Чтобы найти среднее значение, нужно сложить список чисел, разделить общую сумму на составляющие списка, а затем добавить еще один список чисел.
Применение этой техники позволяет быстро просмотреть данные и одновременно определить общую тенденцию сбора данных. Простой и быстрый расчет также выгоден пользователям метода.
Центр рассматриваемых данных определяется с помощью среднего статистического значения. Результат известен как среднее значение представленных данных. В реальном мире при взаимодействии в сфере исследований, образования и спорта часто используются уничижительные выражения. Подумайте, как часто в разговоре упоминается средний показатель бейсболиста — его среднее значение, если вы считаете себя специалистом по исследованию данных. В результате вы должны знать, с чего начать.
-
Стандартное отклонение
Статистический метод, называемый стандартным отклонением, измеряет, насколько широко распределены данные от среднего значения.
При работе с данными высокое стандартное отклонение указывает на то, что данные сильно разбросаны от среднего значения. Низкое отклонение указывает на то, что большинство данных соответствует среднему значению и может также называться ожидаемым значением набора.
Стандартное отклонение часто используется при анализе дисперсии точек данных — независимо от того, сгруппированы они или нет.
Представьте, что вы маркетолог, который только что закончил опрос клиентов. Предположим, вы хотите определить, будет ли большая группа клиентов давать такие же ответы. В этом случае после получения результатов опроса вам следует оценить зависимость ответов. Если стандартное отклонение низкое, то можно спрогнозировать ответы большего числа клиентов.
-
Регрессия
Регрессия в статистике изучает связь между независимой переменной и зависимой переменной (информацией, которую вы пытаетесь оценить) (данные, используемые для прогнозирования зависимой переменной).
Это также можно объяснить с точки зрения того, как одна переменная влияет на другую, или как изменения в одной непоследовательной величине приводят к изменениям в другой, или наоборот, простая причина и следствие. Это предполагает, что результат зависит от одного или нескольких факторов.
На графиках и диаграммах регрессионного анализа используются линии, показывающие тенденции за заранее определенный период, а также силу или слабость корреляций между переменными.
-
Проверка гипотез
Два набора случайных переменных в наборе данных должны быть проверены с помощью проверки гипотез, иногда называемой «Т-тестированием» в статистическом анализе.
Этот подход фокусируется на определении того, справедливо ли данное утверждение или заключение для набора данных. Он позволяет сравнить данные с многочисленными предположениями и гипотезами. Он также может помочь в прогнозировании того, как выбор повлияет на компанию.
Проверка гипотезы в статистике определяет количество при определенном предположении. Результат проверки показывает, верно ли предположение или оно нарушено. Нулевая гипотеза, иногда известная как гипотеза 0, является этим предположением. Первая гипотеза, часто известная как гипотеза 1, — это любая другая теория, которая противоречит гипотезе 0.
При проверке гипотез результаты теста считаются статистически значимыми, если они показывают, что событие не могло произойти случайно или случайным образом.
-
Определение размера выборки
При оценке данных для статистического анализа сбор достоверных данных иногда может быть затруднен, поскольку набор данных слишком велик. В таких случаях большинство выбирает метод, известный как определение размера выборки, который предполагает изучение выборки или меньшего объема данных.
Для эффективного выполнения этой задачи необходимо выбрать подходящий размер выборки. Вы не получите достоверных результатов после анализа, если размер выборки будет слишком мал.
Для достижения этого результата вы будете использовать несколько методов выборки данных. Для этого вы можете разослать опрос своим клиентам, а затем использовать метод прямой случайной выборки, чтобы отобрать данные клиентов для выборочного анализа.
И наоборот, чрезмерный размер выборки может привести к потере времени и денег. Чтобы определить размер выборки, можно рассмотреть такие факторы, как стоимость, время или простота сбора данных.
Вы запутались? Не волнуйтесь! Вы можете воспользоваться нашим калькулятором размера выборки.
Вывод
Способность аналитически мыслить жизненно важна для корпоративного успеха. Поскольку данные являются одним из наиболее важных ресурсов, доступных сегодня, их эффективное использование может привести к лучшим результатам и принятию решений.
Независимо от выбранных вами методов статистического анализа, обязательно обратите пристальное внимание на каждый потенциальный недостаток и его конкретную формулу. Ни один метод не является правильным или неправильным, и не существует золотого стандарта. Все будет зависеть от собранной вами информации и выводов, которые вы надеетесь сделать.
Статистическая погрешность — это та неопределенность в оценке истинного значения измеряемой величины, которая возникает из-за того, что несколько повторных измерений тем же самым инструментом дали различающиеся результаты. Возникает она, как правило, из-за того, что результаты измерения в микромире не фиксированы, а вероятностны. Она тесно связана с объемом статистики: обычно чем больше данных, тем меньше статистическая погрешность и тем точнее результат измерения. Среди всех типов погрешностей она, пожалуй, самая безобидная: понятно, как ее считать, и понятно, как с ней бороться.
Статистическая погрешность: чуть подробнее
Предположим, что ваш детектор может очень точно измерить какую-то величину в каждом конкретном столкновении. Это может быть энергия или импульс какой-то родившейся частицы, или дискретная величина (например, сколько мюонов родилось в событии), или вообще элементарный ответ «да» или «нет» на какой-то вопрос (например, родилась ли в этом событии хоть одна частица с импульсом больше 100 ГэВ).
Это конкретное число, полученное в одном столкновении, почти бессмысленно. Скажем, взяли вы одно событие и выяснили, что в нём хиггсовский бозон не родился. Никакой научной пользы от такого единичного факта нет. Законы микромира вероятностны, и если вы организуете абсолютно такое же столкновение протонов, то картина рождения частиц вовсе не обязана повторяться, она может оказаться совсем другой. Если бозон не родился сейчас, не родился в следующем столкновении, то это еще ничего не говорит о том, может ли он родиться вообще и как это соотносится с теоретическими предсказаниями. Для того, чтобы получить какое-то осмысленное число в экспериментах с элементарными частицами, надо повторить эксперимент много раз и набрать статистику одинаковых столкновений. Всё свое рабочее время коллайдеры именно этим и занимаются, они накапливают статистику, которую потом будут обрабатывать экспериментаторы.
В каждом конкретном столкновении результат измерения может быть разный. Наберем статистику столкновений и усредним по ней результат. Этот средний результат, конечно, тоже не фиксирован, он может меняться в зависимости от статистики, но он будет намного стабильнее, он не будет так сильно прыгать от одной статистической выборки к другой. У него тоже есть некая неопределенность (в статистическом анализе она так и называется: «неопределенность среднего»), но она обычно небольшая. Вот эта величина и называется статистической погрешностью измерения.
Итак, когда экспериментаторы предъявляют измерение какой-то величины, то они сообщают результат усреднения этой величины по всей набранной статистике столкновений и сопровождают его статистической погрешностью. Именно такие средние значения имеют физический смысл, только их может предсказывать теория.
Есть, конечно, и иной источник статистической погрешности: недостаточный контроль условий эксперимента при повторном измерении. Если в физике частиц этот источник можно попытаться устранить, по крайней мере, в принципе, то в других разделах естественных наук он выходит на первый план; например, в медицинских исследованиях каждый человек отличается от другого по большому числу параметров.
Как считать статистическую погрешность?
Существует теория расчета статистической погрешности, в которую мы, конечно, вдаваться не будем. Но есть одно очень простое правило, которое легко запомнить и которое срабатывает почти всегда. Пусть у вас есть статистическая выборка из N столкновений и в ней присутствует n событий какого-то определенного типа. Тогда в другой статистической выборке из N событий, набранной в тех же условиях, можно ожидать примерно n ± √n таких событий. Поделив это на N, мы получим среднюю вероятность встретить такое событие и погрешность среднего: n/N ± √n/N. Оценка истинного значения вероятности такого типа события примерно соответствует этому выражению.
Сразу же, впрочем, подчеркнем, что эта простая оценка начинает сильно «врать», когда количество событий очень мало. В науке обсчета маленькой статистики есть много дополнительных тонкостей.
Более серьезное (но умеренно краткое) введение в методы статистической обработки данных в применении к экспериментам на LHC см. в лекциях arXiv.1307.2487.
Именно поэтому эксперименты в физике элементарных частиц стараются оптимизировать не только по энергии, но и по светимости. Ведь чем больше светимость, тем больше столкновений будет произведено — значит, тем больше будет статистическая выборка. И уже это позволит сделать измерения более точными — даже без каких-либо улучшений в эксперименте. Примерная зависимость тут такая: если вы увеличите статистику в k раз, то относительные статистические погрешности уменьшатся примерно в √k раз.
Этот пример — некая симуляция того, как могло бы происходить измерение массы ρ-мезона свыше полувека назад, на заре адронной физики, если бы он был вначале обнаружен в процессе e+e– → π+π–. А теперь перенесемся в наше время.
Сейчас этот процесс изучен вдоль и поперек, статистика набрана огромная (миллионы событий), а значит, и масса ρ-мезона сейчас определена несравнимо точнее. На рис. 3 показано современное состояние дел в этой области масс. Если ранние эксперименты еще имели какие-то существенные погрешности, то сейчас они практически неразличимы глазом. Огромная статистика позволила не только измерить массу (примерно равна 775 МэВ с точностью в десятые доли МэВ), но и заметить очень странную форму этого пика. Такая форма получается потому, что практически в том же месте на шкале масс находится и другой мезон, ω(782), который «вмешивается» в процесс и искажает форму ρ-мезонного пика.
Другой, гораздо более реальный пример влияния статистики на процесс поиска и изучения хиггсовского бозона обсуждался в новости Анимации показывают, как в данных LHC зарождался хиггсовский сигнал.
Статистические ошибки
Использование
методов биометрии позволяет исследователю
на ограниченном по численности материале
делать заключения о проявлении признака,
его изменчивости и других параметрах
в генеральной совокупности. Но так
как выборочная совокупность — часть
генеральной и ее формируют методом
случайного отбора, то в выборку могут
попасть животные с более низкими
продуктивными качествами, или несколько
лучшие особи. В этом случае вычисленные
значения M, б, Cv и
других биометрических величин будут
отличаться от значений этих величин в
генеральной совокупности, то есть
выборка отражает генеральную совокупность
с ошибкой. Эти ошибки, связанные с
методом выборочности, называются
статистическими и устранить их нельзя.
Ошибки не будет лишь в том случае, когда
в обработку включаются все члены
генеральной совокупности. Величины
статистических ошибок зависят от
изменчивости признаков и объема выборки:
чем более изменчив признак, тем больше
ошибка, и чем больше объем выборки, тем
она меньше. Ошибки статистических
величин в биометрии принято обозначать
буквой m.
Ошибки
имеют все статистические величины.
Вычисляют их по формулам:
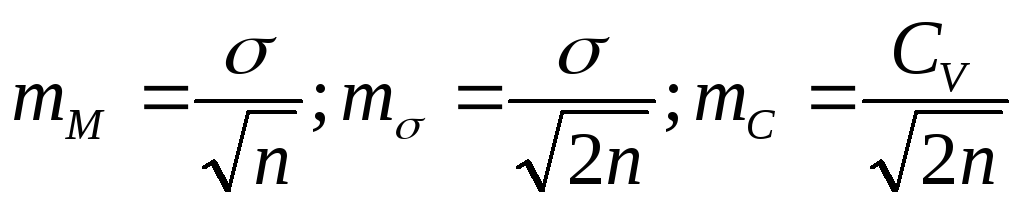
Все
ошибки измеряют в тех же единицах, что
и сами показатели, и записывают обычно
рядом с ними.
Статистические
ошибки указывают интервал, в котором
находится величина того или иного
статистического показателя в генеральной
совокупности. Зная среднее значение
признака (М) и его ошибку (m), можно
установить доверительные границы
средней величины в генеральной
совокупности по формуле: Мген.=Мв.
tm, где t — нормированное отклонение,
которое зависит от уровня вероятности
и объема выборки. Цифровое значение t
для каждого конкретного случая находят
с помощью специальной таблицы. Например,
нас интересует средняя частота пульса
у овец породы прекос. Для изучения этого
показателя была сформирована выборка
в количестве 50 голов и определена у
этих животных средняя частота пульса.
Оказалось, что этот показатель равен
75 ударов в минуту, изменчивость его б =
12 ударов. Ошибка средней арифметической
величины в этом случае составит:
б
12
m
= ──── = ──── = 1,7 (уд./мин).
n
50
Итоговая
запись будет иметь вид: М
m или 75
1,7, то есть частота пульса 75 ударов в
минуту — среднее значение для 50 голов.
Чтобы определить среднюю частоту пульса
в генеральной совокупности животных,
возьмем в качестве доверительной
вероятности P = 0,95. В этом случае, исходя
из таблицы, t = 2,01. Определим доверительные
границы частоты пульса в генеральной
совокупности M
tm.
75,0
+ 2,01 x 1,7 = 75,0 + 3,4 = 78,4 (уд./мин)
75,0
— 2,01 x 1,7 = 75,0 — 3,4 = 71,6 (уд./мин)
Таким
образом, средняя частота пульса для
генеральной совокупности будет в
пределах от 71,6 до 78,4 ударов в минуту.
Зная
величину статистических ошибок,
устанавливают также, правильно ли
выборочная совокупность отражает тот
или иной параметр генеральной, то есть
устанавливают критерий доверительности
выборочных величин.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)
Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.










Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
Ошибки, встроенные в систему: их роль в статистике
Время на прочтение
6 мин
Количество просмотров 13K
В прошлой статье я указал, как распространена проблема неправильного использования t-критерия в научных публикациях (и это возможно сделать только благодаря их открытости, а какой трэш творится при его использовании во всяких курсовых, отчетах, обучающих задачах и т.д. — неизвестно). Чтобы обсудить это, я рассказал об основах дисперсионного анализа и задаваемом самим исследователем уровне значимости α. Но для полного понимания всей картины статистического анализа необходимо подчеркнуть ряд важных вещей. И самая основная из них — понятие ошибки.
Ошибка и некорректное применение: в чем разница?
В любой физической системе содержится какая-либо ошибка, неточность. В самой разнообразной форме: так называемый допуск — отличие в размерах разных однотипных изделий; нелинейная характеристика — когда прибор или метод измеряют что-то по строго известному закону в определенных пределах, а дальше становятся неприменимыми; дискретность — когда мы чисто технически не можем обеспечить плавность выходной характеристики.
И в то же время существует чисто человеческая ошибка — некорректное использование устройств, приборов, математических законов. Между ошибкой, присущей системе, и ошибкой применения этой системы есть принципиальная разница. Важно различать и не путать между собой эти два понятия, называемые одним и тем же словом «ошибка». Я в данной статье предпочитаю использовать слово «ошибка» для обозначения свойства системы, а «некорректное применение» — для ошибочного ее использования.
То есть, ошибка линейки равна допуску оборудования, наносящего штрихи на ее полотно. А ошибкой в смысле некорректного применения было бы использовать ее при измерении деталей наручных часов. Ошибка безмена написана на нем и составляет что-то около 50 граммов, а неправильным использованием безмена было бы взвешивание на нем мешка в 25 кг, который растягивает пружину из области закона Гука в область пластических деформаций. Ошибка атомно-силового микроскопа происходит из его дискретности — нельзя «пощупать» его зондом предметы мельче, чем диаметром в один атом. Но способов неправильно использовать его или неправильно интерпретировать данные существует множество. И так далее.
Так, а что же за ошибка имеет место в статистических методах? А этой ошибкой как раз и является пресловутый уровень значимости α.
Ошибки первого и второго рода
Ошибкой в математическом аппарате статистики является сама ее Байесовская вероятностная сущность. В прошлой статье я уже упоминал, на чем стоят статистические методы: определение уровня значимости α как наибольшей допустимой вероятности неправомерно отвергнуть нулевую гипотезу, и самостоятельное задание исследователем этой величины перед исследователем.
Вы уже видите эту условность? На самом деле, в критериальных методах нету привычной математической строгости. Математика здесь оперирует вероятностными характеристиками.
И тут наступает еще один момент, где возможна неправильная трактовка одного слова в разном контексте. Необходимо различать само понятие вероятности и фактическую реализацию события, выражающуюся в распределении вероятности. Например, перед началом любого нашего эксперимента мы не знаем, какую именно величину мы получим в результате. Есть два возможных исхода: загадав некоторое значение результата, мы либо действительно его получим, либо не получим. Логично, что вероятность и того, и другого события равна 1/2. Но показанная в предыдущей статье Гауссова кривая показывает распределение вероятности того, что мы правильно угадаем совпадение.
Наглядно можно проиллюстрировать это примером. Пусть мы 600 раз бросаем два игральных кубика — обычный и шулерский. Получим следующие результаты:

До эксперимента для обоих кубиков выпадение любой грани будет равновероятно — 1/6. Однако после эксперимента проявляется сущность шулерского кубика, и мы можем сказать, что плотность вероятности выпадения на нем шестерки — 90%.
Другой пример, который знают химики, физики и все, кто интересуется квантовыми эффектами — атомные орбитали. Теоретически электрон может быть «размазан» в пространстве и находиться практически где угодно. Но на практике есть области, где он будет находиться в 90 и более процентах случаев. Эти области пространства, образованные поверхностью с плотностью вероятности нахождения там электрона 90%, и есть классические атомные орбитали, в виде сфер, гантелей и т.д.
Так вот, самостоятельно задавая уровень значимости, мы заведомо соглашаемся на описанную в его названии ошибку. Из-за этого ни один результат нельзя считать «стопроцентно достоверным» — всегда наши статистические выводы будут содержать некоторую вероятность сбоя.
Ошибка, формулируемая определением уровня значимости α, называется ошибкой первого рода. Ее можно определить, как «ложная тревога», или, более корректно, ложноположительный результат. В самом деле, что означают слова «ошибочно отвергнуть нулевую гипотезу»? Это значит, по ошибке принять наблюдаемые данные за значимые различия двух групп. Поставить ложный диагноз о наличии болезни, поспешить явить миру новое открытие, которого на самом деле нет — вот примеры ошибок первого рода.
Но ведь тогда должны быть и ложноотрицательные результаты? Совершенно верно, и они называются ошибками второго рода. Примеры — не поставленный вовремя диагноз или же разочарование в результате исследования, хотя на самом деле в нем есть важные данные. Ошибки второго рода обозначаются буквой, как ни странно, β. Но само это понятие не так важно для статистики, как число 1-β. Число 1-β называется мощностью критерия, и как нетрудно догадаться, оно характеризует способность критерия не упустить значимое событие.
Однако содержание в статистических методах ошибок первого и второго рода не является только лишь их ограничением. Само понятие этих ошибок может использоваться непосредственным образом в статистическом анализе. Как?
ROC-анализ
ROC-анализ (от receiver operating characteristic, рабочая характеристика приёмника) — это метод количественного определения применимости некоторого признака к бинарной классификации объектов. Говоря проще, мы можем придумать некоторый способ, как отличить больных людей от здоровых, кошек от собак, черное от белого, а затем проверить правомерность такого способа. Давайте снова обратимся к примеру.
Пусть вы — подающий надежды криминалист, и разрабатываете новый способ скрытно и однозначно определять, является ли человек преступником. Вы придумали количественный признак: оценивать преступные наклонности людей по частоте прослушивания ими Михаила Круга. Но будет ли давать адекватные результаты ваш признак? Давайте разбираться.
Вам понадобится две группы людей для валидации вашего критерия: обычные граждане и преступники. Положим, действительно, среднегодовое время прослушивания ими Михаила Круга различается (см. рисунок):

Здесь мы видим, что по количественному признаку времени прослушивания наши выборки пересекаются. Кто-то слушает Круга спонтанно по радио, не совершая преступлений, а кто-то нарушает закон, слушая другую музыку или даже будучи глухим. Какие у нас есть граничные условия? ROC-анализ вводит понятия селективности (чувствительности) и специфичности. Чувствительность определяется как способность выявлять все-все интересующие нас точки (в данном примере — преступников), а специфичность — не захватывать ничего ложноположительного (не ставить под подозрение простых обывателей). Мы можем задать некоторую критическую количественную черту, отделяющую одних от других (оранжевая), в пределах от максимальной чувствительности (зеленая) до максимальной специфичности (красная).
Посмотрим на следующую схему:
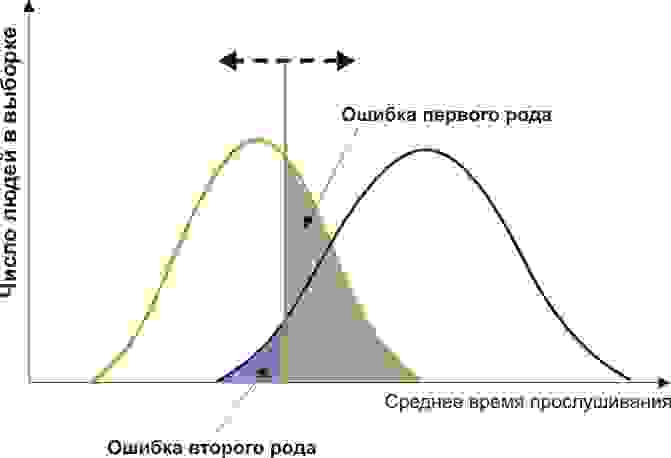
Смещая значение нашего признака, мы меняем соотношения ложноположительного и ложноотрицательного результатов (площади под кривыми). Точно так же мы можем дать определения Чувствительность = Полож. рез-т/(Полож. рез-т + ложноотриц. рез-т) и Специфичность = Отриц. рез-т/(Отриц. рез-т + ложноположит. рез-т).
Но главное, мы можем оценить соотношение положительных результатов к ложноположительным на всем отрезке значений нашего количественного признака, что и есть наша искомая ROC-кривая (см. рисунок):
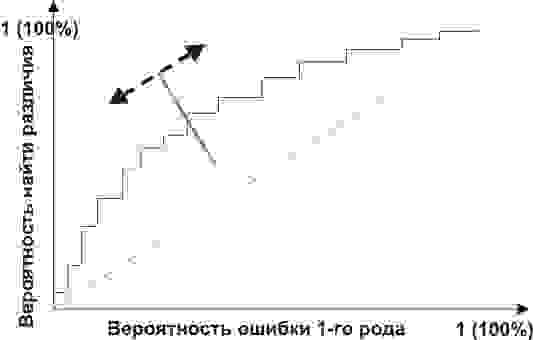
А как нам понять из этого графика, насколько хорош наш признак? Очень просто, посчитать площадь под кривой (AUC, area under curve). Пунктирная линия (0,0; 1,1) означает полное совпадение двух выборок и совершенно бессмысленный критерий (площадь под кривой равна 0,5 от всего квадрата). А вот выпуклость ROC кривой как раз и говорит о совершенстве критерия. Если же нам удастся найти такой критерий, что выборки вообще не будут пересекаться, то площадь под кривой займет весь график. В целом же признак считается хорошим, позволяющим надежно отделить одну выборку от другой, если AUC > 0,75-0,8.
С помощью такого анализа вы можете решать самые разные задачи. Решив, что слишком много домохозяек оказались под подозрением из-за Михаила Круга, а кроме того упущены опасные рецидивисты, слушающие Ноггано, вы можете отвергнуть этот критерий и разработать другой.
Возникнув, как способ обработки радиосигналов и идентификации «свой-чужой» после атаки на Перл-Харбор (отсюда и пошло такое странное название про характеристику приемника), ROC-анализ нашел широкое применение в биомедицинской статистике для анализа, валидации, создания и характеристики панелей биомаркеров и т.д. Он гибок в использовании, если оно основано на грамотной логике. Например, вы можете разработать показания для медицинской диспансеризации пенсионеров-сердечников, применив высокоспецифичный критерий, повысив эффективность выявления болезней сердца и не перегружая врачей лишними пациентами. А во время опасной эпидемии ранее неизвестного вируса вы наоборот, можете придумать высокоселективный критерий, чтобы от вакцинации в прямом смысле не ускользнул ни один чих.
С ошибками обоих родов и их наглядностью в описании валидируемых критериев мы познакомились. Теперь же, двигаясь от этих логических основ, можно разрушить ряд ложных стереотипных описаний результатов. Некоторые неправильные формулировки захватывают наши умы, часто путаясь своими схожими словами и понятиями, а также из-за очень малого внимания, уделяемого неверной интерпретации. Об этом, пожалуй, нужно будет написать отдельно.

Деятельность людей во множестве случаев предполагает работу с данными, а она в свою очередь может подразумевать не только оперирование ими, но и их изучение, обработку и анализ. Например, когда нужно уплотнить информацию, найти какие-то взаимосвязи или определить структуры. И как раз для аналитики в этом случае очень удобно пользоваться не только разными техниками мышления, но и применять статистические методы.
Особенностью методов статистического анализа является их комплексность, обусловленная многообразием форм статистических закономерностей, а также сложностью процесса статистических исследований. Однако мы хотим поговорить именно о таких методах, которые может применять каждый, причем делать это эффективно и с удовольствием.
Статистическое исследование может проводиться посредством следующих методик:
- Статистическое наблюдение;
- Сводка и группировка материалов статистического наблюдения;
- Абсолютные и относительные статистические величины;
- Вариационные ряды;
- Выборка;
- Корреляционный и регрессионный анализ;
- Ряды динамики.
Далее мы рассмотрим каждый из них более подробно. Но отметим, что представим лишь основные характеристики без подробного описания алгоритмов действий. Впрочем, понять их не составит никакого труда.
Статистическое наблюдение
Статистическое наблюдение является планомерным, организованным и в большинстве случаев систематическим сбором информации, направленным, главным образом, на явления социальной жизни. Реализуется данный метод через регистрацию предварительно определенных наиболее ярких признаков, цель которой состоит в последующем получении характеристик изучаемых явлений.
Статистическое наблюдение должно выполняться с учетом некоторых важных требований:
- Оно должно полностью охватывать изучаемые явления;
- Получаемые данные должны быть точными и достоверными;
- Получаемые данные должны быть однообразными и легкосопоставимыми.
Также статистическое наблюдение может иметь две формы:
- Отчетность – это такая форма статистического наблюдения, где информация поступает в конкретные статистические подразделения организаций, учреждений или предприятий. В этом случае данные вносятся в специальные отчеты.
- Специально организованное наблюдение – наблюдение, которое организуется с определенной целью, чтобы получить сведения, которых не имеется в отчетах, или же для уточнения и установления достоверности информации отчетов. К этой форме относятся опросы (например, опросы мнений людей), перепись населения и т.п.
Кроме того, статистическое наблюдение может быть категоризировано на основе двух признаков: либо на основе характера регистрации данных, либо на основе охвата единиц наблюдения. К первой категории относятся опросы, документирование и прямое наблюдение, а ко второй – наблюдение сплошное и несплошное, т.е. выборочное.
Для получения данных при помощи статистического наблюдения можно применять такие способы как анкетирование, корреспондентская деятельность, самоисчисление (когда наблюдаемые, например, сами заполняют соответствующие документы), экспедиции и составление отчетов.
Сводка и группировка материалов статистического наблюдения
Говоря о втором методе, в первую очередь следует сказать о сводке. Сводка представляет собой процесс обработки определенных единичных фактов, которые образуют общую совокупность данных, собранных при наблюдении. Если сводка проводится грамотно, огромное количество единичных данных об отдельных объектах наблюдения может превратиться в целый комплекс статистических таблиц и результатов. Также такое исследование способствует определению общих черт и закономерностей исследуемых явлений.
С учетом показателей точности и глубины изучения можно выделить простую и сложную сводку, но любая из них должна основываться на конкретных этапах:
- Выбирается группировочный признак;
- Определяется порядок формирования групп;
- Разрабатывается система показателей, позволяющих охарактеризовать группу и объект или явление в целом;
- Разрабатываются макеты таблиц, где будут представлены результаты сводки.
Важно заметить, что есть и разные формы сводки:
- Централизованная сводка, требующая передачи полученного первичного материала в вышестоящий центр для последующей обработки;
- Децентрализованная сводка, где изучение данных происходит на нескольких ступенях по восходящей.
Выполняться же сводка может при помощи специализированного оборудования, например, с использованием компьютерного ПО или вручную.
Что же касается группировки, то этот процесс отличается разделением исследуемых данных на группы по признакам. Особенности поставленных статистическим анализом задач влияют на то, какой именно будет группировка: типологической, структурной или аналитической. Именно поэтому для сводки и группировки либо прибегают к услугам узкопрофильных специалистов, либо применяют конкретные техники мышления.
Абсолютные и относительные статистические величины
Абсолютные величина считаются самой первой формой представления статистических данных. С ее помощью удается придать явлениям размерные характеристики, например, по времени, по протяженности, по объему, по площади, по массе и т.д.
Если требуется узнать об индивидуальных абсолютных статистических величинах, можно прибегнуть к замерам, оценке, подсчету или взвешиванию. А если нужно получить итоговые объемные показатели, следует использовать сводку и группировку. Нужно иметь в виду, что абсолютные статистические величины отличаются наличием единиц измерения. К таким единицам относят стоимостные, трудовые и натуральные.
А относительные величины выражают количественные соотношения, касающиеся явлений социальной жизни. Чтобы их получить, одни величины всегда делятся на другие. Показатель, с которым сравнивают (это знаменатель), называют основанием сравнения, а показатель, которой сравнивают (это числитель), называют отчетной величиной.
Относительные величины могут быть разными, что зависит от их содержательной части. Например, существуют величины сравнения, величины уровня развития, величины интенсивности конкретного процесса, величины координации, структуры, динамики и т.д. и т.п.
Чтобы изучить какую-то совокупность по дифференцирующимся признакам, в статистическом анализе применяются средние величины – обобщающие качественные характеристики совокупности однородных явлений по какому-либо дифференцирующемуся признаку.
Крайне важным свойством средних величин является то, что они говорят о значениях конкретных признаков во всем их комплексе единым числом. Невзирая на то, что у отдельных единиц может наблюдаться количественная разница, средние величины выражают общие значения, свойственные всем единицам исследуемого комплекса. Получается, что при помощи характеристики чего-то одного можно получить характеристику целого.
Следует иметь в виду, что одним из самых важных условий применения средних величин, если проводится статистический анализ социальных явлений, считается однородность их комплекса, для которого и нужно узнать среднюю величину. А от такого, как именно будут представлены начальные данные для исчисления средней величины, будет зависеть и формула ее определения.
Вариационные ряды
В некоторых случаях данных о средних показателях тех или иных изучаемых величин может быть недостаточно, чтобы провести обработку, оценку и глубокий анализ какого-то явления или процесса. Тогда во внимание следует брать вариацию или разброс показателей отдельных единиц, который тоже представляет собой важную характеристику исследуемой совокупности.
На индивидуальные значения величин могут воздействовать многие факторы, а сами изучаемые явления или процессы могут быть очень многообразны, т.е. обладать вариацией (это многообразие и есть вариационные ряды), причины которой следует искать в сущности того, что изучается.
Вышеназванные абсолютные величины находятся в непосредственной зависимости от единиц измерения признаков, а значит, делают процесс изучения, оценки и сравнения двух и более вариационных рядов более сложным. А относительные показатели нужно вычислять в качестве соотношения абсолютных и средних показателей.
Выборка
Смысл выборочного метода (или проще – выборки) состоит в том, что по свойствам одной части определяются численные характеристики целого (это называется генеральной совокупностью). Основной выборочного метода является внутренняя связь, объединяющая части и целое, единичное и общее.
Метод выборки отличается рядом существенных преимуществ перед остальными, т.к. благодаря уменьшению количества наблюдений позволяет сократить объемы работы, затрачиваемые средства и усилия, а также успешно получать данные о таких процессах и явлениях, где либо нецелесообразно, либо просто невозможно исследовать их полностью.
Соответствие характеристик выборки характеристикам изучаемого явления или процесса будет зависеть от комплекса условий, и в первую очередь от того, как вообще будет реализовываться выборочный метод на практике. Это может быть как планомерный отбор, идущий по подготовленной схеме, так и непланомерный, когда выборка производится из генеральной совокупности.
Но во всех случаях выборочный метод должен быть типичным и соответствовать критериям объективности. Данные требования нужно выполнять всегда, т.к. именно от них будет зависеть соответствие характеристик метода и характеристик того, что подвергается статистическому анализу.
Таким образом, перед обработкой выборочного материала необходимо провести его тщательную проверку, избавившись тем самым от всего ненужного и второстепенного. Одновременно с этим, составляя выборку, в обязательном порядке нужно обходить стороной любую самодеятельность. Это означает, что ни в коем случае не следует делать выборку только из вариантов, кажущихся типичными, а все другие – отбрасывать.
Эффективная и качественная выборка должна составляться объективно, т.е. производить ее нужно так, чтобы были исключены любые субъективные влияния и предвзятые побуждения. И чтобы это условие было соблюдено должным образом, требуется прибегнуть к принципу рандомизации или, проще говоря, к принципу случайного отбора вариантов из всей их генеральной совокупности.
Представленный принцип служит основой теории выборочного метода, и следовать ему нужно всегда, когда требуется создать эффективную выборочную совокупность, причем случаи планомерного отбора исключением здесь не являются.
Корреляционный и регрессионный анализ
Корреляционный анализ и регрессионный анализ – это два высокоэффективных метода, позволяющие проводить анализ больших объемов данных для изучения возможной взаимосвязи двух или большего количества показателей.
В случае с корреляционным анализом задачами являются:
- Измерить тесноту имеющейся связи дифференцирующихся признаков;
- Определить неизвестные причинные связи;
- Оценить факторы, в наибольшей степени воздействующие на окончательный признак.
А в случае с регрессионным анализом задачи следующие:
- Определить форму связи;
- Установить степень воздействия независимых показателей на зависимый;
- Определить расчетные значения зависимого показателя.
Чтобы решить все вышеназванные задачи, практически всегда нужно применять и корреляционный и регрессионный анализ в комплексе.
Ряды динамики
Посредством этого метода статистического анализа очень удобно определять интенсивность или скорость, с которой развиваются явления, находить тенденцию их развития, выделять колебания, сравнивать динамику развития, находить взаимосвязь развивающихся во времени явлений.
Ряд динамики – это такой ряд, в котором во времени последовательно расположены статистические показатели, изменения которых характеризуют процесс развития исследуемого объекта или явления.
Ряд динамики включает в себя два компонента:
- Период или момент времени, связанный с имеющимися данными;
- Уровень или статистический показатель.
В совокупности эти компоненты представляют собой два члена ряда динамики, где первый член (временной период) обозначается буквой «t», а второй (уровень) – буквой «y».
Исходя из длительности временных промежутков, с которыми взаимосвязаны уровни, ряды динамики могут быть моментными и интервальными. Интервальные ряды позволяют складывать уровни для получения общей величины периодов, следующих один за другим, а в моментных такой возможности нет, но этого там и не требуется.
Ряды динамики также существуют с равными и разными интервалами. Суть же интервалов в моментных и интервальных рядах всегда разная. В первом случае интервалом является временной промежуток между датами, к которым привязаны данные для анализа (удобно использовать такой ряд, например, для определения количества действий за месяц, год и т.д.). А во втором случае – временной промежуток, к которому привязана совокупность обобщенных данных (такой ряд можно использовать для определения качества тех же самых действий за месяц, год и т.п.). Интервалы могут быть равными и разными, независимо от типа ряда.
Естественно, чтобы научиться грамотно применять каждый из методов статистического анализа, недостаточно просто знать о них, ведь, по сути, статистика – это целая наука, требующая еще и определенных навыков и умений. Но чтобы она давалась проще, можно и нужно тренировать свое мышление и улучшать когнитивные способности.
В остальном же исследование, оценка, обработка и анализ информации – очень интересные процессы. И даже в тех случаях, когда это не приводит к какому-то конкретному результату, за время исследования можно узнать множество интересных вещей. Статистический анализ нашел свое применение в огромном количестве сфер деятельности человека, а вы можете использовать его в учебе, работе, бизнесе и других областях, включая развитие детей и самообразование.