
Ошибки — это хорошо. Автор материала, перевод которого мы сегодня публикуем, говорит, что уверен в том, что эта идея известна всем. На первый взгляд ошибки кажутся чем-то страшным. Им могут сопутствовать какие-то потери. Ошибка, сделанная на публике, вредит авторитету того, кто её совершил. Но, совершая ошибки, мы на них учимся, а значит, попадая в следующий раз в ситуацию, в которой раньше вели себя неправильно, делаем всё как нужно.

Выше мы говорили об ошибках, которые люди совершают в обычной жизни. Ошибки в программировании — это нечто иное. Сообщения об ошибках помогают нам улучшать код, они позволяют сообщать пользователям наших проектов о том, что что-то пошло не так, и, возможно, рассказывают пользователям о том, как нужно вести себя для того, чтобы ошибок больше не возникало.
Этот материал, посвящённый обработке ошибок в JavaScript, разбит на три части. Сначала мы сделаем общий обзор системы обработки ошибок в JavaScript и поговорим об объектах ошибок. После этого мы поищем ответ на вопрос о том, что делать с ошибками, возникающими в серверном коде (в частности, при использовании связки Node.js + Express.js). Далее — обсудим обработку ошибок в React.js. Фреймворки, которые будут здесь рассматриваться, выбраны по причине их огромной популярности. Однако рассматриваемые здесь принципы работы с ошибками универсальны, поэтому вы, даже если не пользуетесь Express и React, без труда сможете применить то, что узнали, к тем инструментам, с которыми работаете.
Код демонстрационного проекта, используемого в данном материале, можно найти в этом репозитории.
1. Ошибки в JavaScript и универсальные способы работы с ними
Если в вашем коде что-то пошло не так, вы можете воспользоваться следующей конструкцией.
throw new Error('something went wrong')В ходе выполнения этой команды будет создан экземпляр объекта Error и будет сгенерировано (или, как говорят, «выброшено») исключение с этим объектом. Инструкция throw может генерировать исключения, содержащие произвольные выражения. При этом выполнение скрипта остановится в том случае, если не были предприняты меры по обработке ошибки.
Начинающие JS-программисты обычно не используют инструкцию throw. Они, как правило, сталкиваются с исключениями, выдаваемыми либо средой выполнения языка, либо сторонними библиотеками. Когда это происходит — в консоль попадает нечто вроде ReferenceError: fs is not defined и выполнение программы останавливается.
▍Объект Error
У экземпляров объекта Error есть несколько свойств, которыми мы можем пользоваться. Первое интересующее нас свойство — message. Именно сюда попадает та строка, которую можно передать конструктору ошибки в качестве аргумента. Например, ниже показано создание экземпляра объекта Error и вывод в консоль переданной конструктором строки через обращение к его свойству message.
const myError = new Error('please improve your code')
console.log(myError.message) // please improve your code
Второе свойство объекта, очень важное, представляет собой трассировку стека ошибки. Это — свойство stack. Обратившись к нему можно просмотреть стек вызовов (историю ошибки), который показывает последовательность операций, приведшую к неправильной работе программы. В частности, это позволяет понять — в каком именно файле содержится сбойный код, и увидеть, какая последовательность вызовов функций привела к ошибке. Вот пример того, что можно увидеть, обратившись к свойству stack.
Error: please improve your code
at Object.<anonymous> (/Users/gisderdube/Documents/_projects/hacking.nosync/error-handling/src/general.js:1:79)
at Module._compile (internal/modules/cjs/loader.js:689:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:700:10)
at Module.load (internal/modules/cjs/loader.js:599:32)
at tryModuleLoad (internal/modules/cjs/loader.js:538:12)
at Function.Module._load (internal/modules/cjs/loader.js:530:3)
at Function.Module.runMain (internal/modules/cjs/loader.js:742:12)
at startup (internal/bootstrap/node.js:266:19)
at bootstrapNodeJSCore (internal/bootstrap/node.js:596:3)Здесь, в верхней части, находится сообщение об ошибке, затем следует указание на тот участок кода, выполнение которого вызвало ошибку, потом описывается то место, откуда был вызван этот сбойный участок. Это продолжается до самого «дальнего» по отношению к ошибке фрагмента кода.
▍Генерирование и обработка ошибок
Создание экземпляра объекта Error, то есть, выполнение команды вида new Error(), ни к каким особым последствиям не приводит. Интересные вещи начинают происходить после применения оператора throw, который генерирует ошибку. Как уже было сказано, если такую ошибку не обработать, выполнение скрипта остановится. При этом нет никакой разницы — был ли оператор throw использован самим программистом, произошла ли ошибка в некоей библиотеке или в среде выполнения языка (в браузере или в Node.js). Поговорим о различных сценариях обработки ошибок.
▍Конструкция try…catch
Блок try...catch представляет собой самый простой способ обработки ошибок, о котором часто забывают. В наши дни, правда, он используется гораздо интенсивнее чем раньше, благодаря тому, что его можно применять для обработки ошибок в конструкциях async/await.
Этот блок можно использовать для обработки любых ошибок, происходящих в синхронном коде. Рассмотрим пример.
const a = 5
try {
console.log(b) // переменная b не объявлена - возникает ошибка
} catch (err) {
console.error(err) // в консоль попадает сообщение об ошибке и стек ошибки
}
console.log(a) // выполнение скрипта не останавливается, данная команда выполняется
Если бы в этом примере мы не заключили бы сбойную команду console.log(b) в блок try...catch, то выполнение скрипта было бы остановлено.
▍Блок finally
Иногда случается так, что некий код нужно выполнить независимо от того, произошла ошибка или нет. Для этого можно, в конструкции try...catch, использовать третий, необязательный, блок — finally. Часто его использование эквивалентно некоему коду, который идёт сразу после try...catch, но в некоторых ситуациях он может пригодиться. Вот пример его использования.
const a = 5
try {
console.log(b) // переменная b не объявлена - возникает ошибка
} catch (err) {
console.error(err) // в консоль попадает сообщение об ошибке и стек ошибки
} finally {
console.log(a) // этот код будет выполнен в любом случае
}▍Асинхронные механизмы — коллбэки
Программируя на JavaScript всегда стоит обращать внимание на участки кода, выполняющиеся асинхронно. Если у вас имеется асинхронная функция и в ней возникает ошибка, скрипт продолжит выполняться. Когда асинхронные механизмы в JS реализуются с использованием коллбэков (кстати, делать так не рекомендуется), соответствующий коллбэк (функция обратного вызова) обычно получает два параметра. Это нечто вроде параметра err, который может содержать ошибку, и result — с результатами выполнения асинхронной операции. Выглядит это примерно так:
myAsyncFunc(someInput, (err, result) => {
if(err) return console.error(err) // порядок работы с объектом ошибки мы рассмотрим позже
console.log(result)
})
Если в коллбэк попадает ошибка, она видна там в виде параметра err. В противном случае в этот параметр попадёт значение undefined или null. Если оказалось, что в err что-то есть, важно отреагировать на это, либо так как в нашем примере, воспользовавшись командой return, либо воспользовавшись конструкцией if...else и поместив в блок else команды для работы с результатом выполнения асинхронной операции. Речь идёт о том, чтобы, в том случае, если произошла ошибка, исключить возможность работы с результатом, параметром result, который в таком случае может иметь значение undefined. Работа с таким значением, если предполагается, например, что оно содержит объект, сама может вызвать ошибку. Скажем, это произойдёт при попытке использовать конструкцию result.data или подобную ей.
▍Асинхронные механизмы — промисы
Для выполнения асинхронных операций в JavaScript лучше использовать не коллбэки а промисы. Тут, в дополнение к улучшенной читабельности кода, имеются и более совершенные механизмы обработки ошибок. А именно, возиться с объектом ошибки, который может попасть в функцию обратного вызова, при использовании промисов не нужно. Здесь для этой цели предусмотрен специальный блок catch. Он перехватывает все ошибки, произошедшие в промисах, которые находятся до него, или все ошибки, которые произошли в коде после предыдущего блока catch. Обратите внимание на то, что если в промисе произошла ошибка, для обработки которой нет блока catch, это не остановит выполнение скрипта, но сообщение об ошибке будет не особенно удобочитаемым.
(node:7741) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1): Error: something went wrong
(node:7741) DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code. */
В результате можно порекомендовать всегда, при работе с промисами, использовать блок catch. Взглянем на пример.
Promise.resolve(1)
.then(res => {
console.log(res) // 1
throw new Error('something went wrong')
return Promise.resolve(2)
})
.then(res => {
console.log(res) // этот блок выполнен не будет
})
.catch(err => {
console.error(err) // о том, что делать с этой ошибкой, поговорим позже
return Promise.resolve(3)
})
.then(res => {
console.log(res) // 3
})
.catch(err => {
// этот блок тут на тот случай, если в предыдущем блоке возникнет какая-нибудь ошибка
console.error(err)
})▍Асинхронные механизмы и try…catch
После того, как в JavaScript появилась конструкция async/await, мы вернулись к классическому способу обработки ошибок — к try...catch...finally. Обрабатывать ошибки при таком подходе оказывается очень легко и удобно. Рассмотрим пример.
;(async function() {
try {
await someFuncThatThrowsAnError()
} catch (err) {
console.error(err) // об этом поговорим позже
}
console.log('Easy!') // будет выполнено
})()
При таком подходе ошибки в асинхронном коде обрабатываются так же, как в синхронном. В результате теперь, при необходимости, в одном блоке catch можно обрабатывать более широкий диапазон ошибок.
2. Генерирование и обработка ошибок в серверном коде
Теперь, когда у нас есть инструменты для работы с ошибками, посмотрим на то, что мы можем с ними делать в реальных ситуациях. Генерирование и правильная обработка ошибок — это важнейший аспект серверного программирования. Существуют разные подходы к работе с ошибками. Здесь будет продемонстрирован подход с использованием собственного конструктора для экземпляров объекта Error и кодов ошибок, которые удобно передавать во фронтенд или любым механизмам, использующим серверные API. Как структурирован бэкенд конкретного проекта — особого значения не имеет, так как при любом подходе можно использовать одни и те же идеи, касающиеся работы с ошибками.
В качестве серверного фреймворка, отвечающего за маршрутизацию, мы будем использовать Express.js. Подумаем о том, какая структура нам нужна для организации эффективной системы обработки ошибок. Итак, вот что нам нужно:
- Универсальная обработка ошибок — некий базовый механизм, подходящий для обработки любых ошибок, в ходе работы которого просто выдаётся сообщение наподобие
Something went wrong, please try again or contact us, предлагающее пользователю попробовать выполнить операцию, давшую сбой, ещё раз или связаться с владельцем сервера. Эта система не отличается особой интеллектуальностью, но она, по крайней мере, способна сообщить пользователю о том, что что-то пошло не так. Подобное сообщение гораздо лучше, чем «бесконечная загрузка» или нечто подобное. - Обработка конкретных ошибок — механизм, позволяющий сообщить пользователю подробные сведения о причинах неправильного поведения системы и дать ему конкретные советы по борьбе с неполадкой. Например, это может касаться отсутствия неких важных данных в запросе, который пользователь отправляет на сервер, или в том, что в базе данных уже существует некая запись, которую он пытается добавить ещё раз, и так далее.
▍Разработка собственного конструктора объектов ошибок
Здесь мы воспользуемся стандартным классом Error и расширим его. Пользоваться механизмами наследования в JavaScript — дело рискованное, но в данном случае эти механизмы оказываются весьма полезными. Зачем нам наследование? Дело в том, что нам, для того, чтобы код удобно было бы отлаживать, нужны сведения о трассировке стека ошибки. Расширяя стандартный класс Error, мы, без дополнительных усилий, получаем возможности по трассировке стека. Мы добавляем в наш собственный объект ошибки два свойства. Первое — это свойство code, доступ к которому можно будет получить с помощью конструкции вида err.code. Второе — свойство status. В него будет записываться код состояния HTTP, который планируется передавать клиентской части приложения.
Вот как выглядит класс CustomError, код которого оформлен в виде модуля.
class CustomError extends Error {
constructor(code = 'GENERIC', status = 500, ...params) {
super(...params)
if (Error.captureStackTrace) {
Error.captureStackTrace(this, CustomError)
}
this.code = code
this.status = status
}
}
module.exports = CustomError▍Маршрутизация
Теперь, когда наш объект ошибки готов к использованию, нужно настроить структуру маршрутов. Как было сказано выше, нам требуется реализовать унифицированный подход к обработке ошибок, позволяющий одинаково обрабатывать ошибки для всех маршрутов. По умолчанию фреймворк Express.js не вполне поддерживает такую схему работы. Дело в том, что все его маршруты инкапсулированы.
Для того чтобы справиться с этой проблемой, мы можем реализовать собственный обработчик маршрутов и определять логику маршрутов в виде обычных функций. Благодаря такому подходу, если функция маршрута (или любая другая функция) выбрасывает ошибку, она попадёт в обработчик маршрутов, который затем может передать её клиентской части приложения. При возникновении ошибки на сервере мы планируем передавать её во фронтенд в следующем формате, полагая, что для этого будет применяться JSON-API:
{
error: 'SOME_ERROR_CODE',
description: 'Something bad happened. Please try again or contact support.'
}Если на данном этапе происходящие кажется вам непонятным — не беспокойтесь — просто продолжайте читать, пробуйте работать с тем, о чём идёт речь, и постепенно вы во всём разберётесь. На самом деле, если говорить о компьютерном обучении, здесь применяется подход «сверху-вниз», когда сначала обсуждаются общие идеи, а потом осуществляется переход к частностям.
Вот как выглядит код обработчика маршрутов.
const express = require('express')
const router = express.Router()
const CustomError = require('../CustomError')
router.use(async (req, res) => {
try {
const route = require(`.${req.path}`)[req.method]
try {
const result = route(req) // Передаём запрос функции route
res.send(result) // Передаём клиенту то, что получено от функции route
} catch (err) {
/*
Сюда мы попадаем в том случае, если в функции route произойдёт ошибка
*/
if (err instanceof CustomError) {
/*
Если ошибка уже обработана - трансформируем её в
возвращаемый объект
*/
return res.status(err.status).send({
error: err.code,
description: err.message,
})
} else {
console.error(err) // Для отладочных целей
// Общая ошибка - вернём универсальный объект ошибки
return res.status(500).send({
error: 'GENERIC',
description: 'Something went wrong. Please try again or contact support.',
})
}
}
} catch (err) {
/*
Сюда мы попадём, если запрос окажется неудачным, то есть,
либо не будет найдено файла, соответствующего пути, переданному
в запросе, либо не будет экспортированной функции с заданным
методом запроса
*/
res.status(404).send({
error: 'NOT_FOUND',
description: 'The resource you tried to access does not exist.',
})
}
})
module.exports = routerПолагаем, комментарии в коде достаточно хорошо его поясняют. Надеемся, читать их удобнее, чем объяснения подобного кода, данные после него.
Теперь взглянем на файл маршрутов.
const CustomError = require('../CustomError')
const GET = req => {
// пример успешного выполнения запроса
return { name: 'Rio de Janeiro' }
}
const POST = req => {
// пример ошибки общего характера
throw new Error('Some unexpected error, may also be thrown by a library or the runtime.')
}
const DELETE = req => {
// пример ошибки, обрабатываемой особым образом
throw new CustomError('CITY_NOT_FOUND', 404, 'The city you are trying to delete could not be found.')
}
const PATCH = req => {
// пример перехвата ошибок и использования CustomError
try {
// тут случилось что-то нехорошее
throw new Error('Some internal error')
} catch (err) {
console.error(err) // принимаем решение о том, что нам тут делать
throw new CustomError(
'CITY_NOT_EDITABLE',
400,
'The city you are trying to edit is not editable.'
)
}
}
module.exports = {
GET,
POST,
DELETE,
PATCH,
}
В этих примерах с самими запросами ничего не делается. Тут просто рассматриваются разные сценарии возникновения ошибок. Итак, например, запрос GET /city попадёт в функцию const GET = req =>..., запрос POST /city попадёт в функцию const POST = req =>... и так далее. Эта схема работает и при использовании параметров запросов. Например — для запроса вида GET /city?startsWith=R. В целом, здесь продемонстрировано, что при обработке ошибок, во фронтенд может попасть либо общая ошибка, содержащая лишь предложение попробовать снова или связаться с владельцем сервера, либо ошибка, сформированная с использованием конструктора CustomError, которая содержит подробные сведения о проблеме.
Данные общей ошибки придут в клиентскую часть приложения в таком виде:
{
error: 'GENERIC',
description: 'Something went wrong. Please try again or contact support.'
}
Конструктор CustomError используется так:
throw new CustomError('MY_CODE', 400, 'Error description')Это даёт следующий JSON-код, передаваемый во фронтенд:
{
error: 'MY_CODE',
description: 'Error description'
}Теперь, когда мы основательно потрудились над серверной частью приложения, в клиентскую часть больше не попадают бесполезные логи ошибок. Вместо этого клиент получает полезные сведения о том, что пошло не так.
Не забудьте о том, что здесь лежит репозиторий с рассматриваемым здесь кодом. Можете его загрузить, поэкспериментировать с ним, и, если надо, адаптировать под нужды вашего проекта.
3. Работа с ошибками на клиенте
Теперь пришла пора описать третью часть нашей системы обработки ошибок, касающуюся фронтенда. Тут нужно будет, во-первых, обрабатывать ошибки, возникающие в клиентской части приложения, а во-вторых, понадобится оповещать пользователя об ошибках, возникающих на сервере. Разберёмся сначала с показом сведений о серверных ошибках. Как уже было сказано, в этом примере будет использована библиотека React.
▍Сохранение сведений об ошибках в состоянии приложения
Как и любые другие данные, ошибки и сообщения об ошибках могут меняться, поэтому их имеет смысл помещать в состояние компонентов. При монтировании компонента данные об ошибке сбрасываются, поэтому, когда пользователь впервые видит страницу, там сообщений об ошибках не будет.
Следующее, с чем надо разобраться, заключается в том, что ошибки одного типа нужно показывать в одном стиле. По аналогии с сервером, здесь можно выделить 3 типа ошибок.
- Глобальные ошибки — в эту категорию попадают сообщения об ошибках общего характера, приходящие с сервера, или ошибки, которые, например, возникают в том случае, если пользователь не вошёл в систему и в других подобных ситуациях.
- Специфические ошибки, выдаваемые серверной частью приложения — сюда относятся ошибки, сведения о которых приходят с сервера. Например, подобная ошибка возникает, если пользователь попытался войти в систему и отправил на сервер имя и пароль, а сервер сообщил ему о том, что пароль неправильный. Подобные вещи в клиентской части приложения не проверяются, поэтому сообщения о таких ошибках должны приходить с сервера.
- Специфические ошибки, выдаваемые клиентской частью приложения. Пример такой ошибки — сообщение о некорректном адресе электронной почты, введённом в соответствующее поле.
Ошибки второго и третьего типов очень похожи, работать с ними можно, используя хранилище состояния компонентов одного уровня. Их главное различие заключается в том, что они исходят из разных источников. Ниже, анализируя код, мы посмотрим на работу с ними.
Здесь будет использоваться встроенная в React система управления состоянием приложения, но, при необходимости, вы можете воспользоваться и специализированными решениями для управления состоянием — такими, как MobX или Redux.
▍Глобальные ошибки
Обычно сообщения о таких ошибках сохраняются в компоненте наиболее высокого уровня, имеющем состояние. Они выводятся в статическом элементе пользовательского интерфейса. Это может быть красное поле в верхней части экрана, модальное окно или что угодно другое. Реализация зависит от конкретного проекта. Вот как выглядит сообщение о такой ошибке.
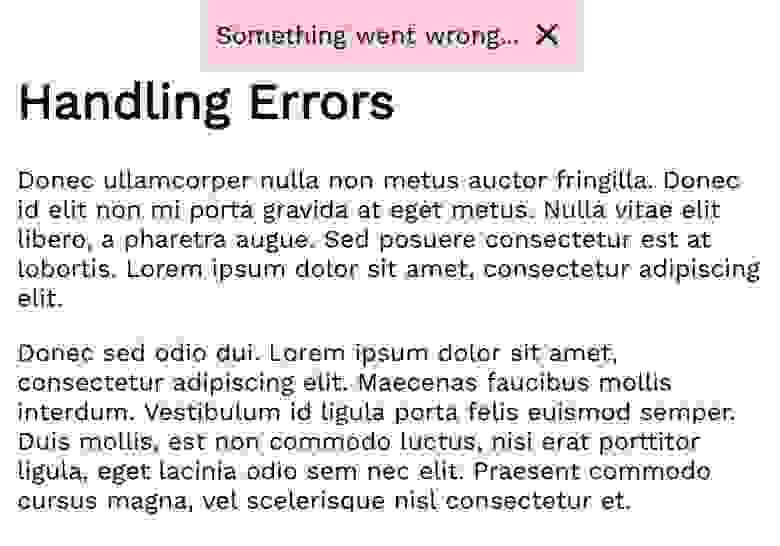
Сообщение о глобальной ошибке
Теперь взглянем на код, который хранится в файле Application.js.
import React, { Component } from 'react'
import GlobalError from './GlobalError'
class Application extends Component {
constructor(props) {
super(props)
this.state = {
error: '',
}
this._resetError = this._resetError.bind(this)
this._setError = this._setError.bind(this)
}
render() {
return (
<div className="container">
<GlobalError error={this.state.error} resetError={this._resetError} />
<h1>Handling Errors</h1>
</div>
)
}
_resetError() {
this.setState({ error: '' })
}
_setError(newError) {
this.setState({ error: newError })
}
}
export default Application
Как видно, в состоянии, в Application.js, имеется место для хранения данных ошибки. Кроме того, тут предусмотрены методы для сброса этих данных и для их изменения.
Ошибка и метод для сброса ошибки передаётся компоненту GlobalError, который отвечает за вывод сообщения об ошибке на экран и за сброс ошибки после нажатия на значок x в поле, где выводится сообщение. Вот код компонента GlobalError (файл GlobalError.js).
import React, { Component } from 'react'
class GlobalError extends Component {
render() {
if (!this.props.error) return null
return (
<div
style={{
position: 'fixed',
top: 0,
left: '50%',
transform: 'translateX(-50%)',
padding: 10,
backgroundColor: '#ffcccc',
boxShadow: '0 3px 25px -10px rgba(0,0,0,0.5)',
display: 'flex',
alignItems: 'center',
}}
>
{this.props.error}
<i
className="material-icons"
style={{ cursor: 'pointer' }}
onClick={this.props.resetError}
>
close
</font></i>
</div>
)
}
}
export default GlobalError
Обратите внимание на строку if (!this.props.error) return null. Она указывает на то, что при отсутствии ошибки компонент ничего не выводит. Это предотвращает постоянный показ красного прямоугольника на странице. Конечно, вы, при желании, можете поменять внешний вид и поведение этого компонента. Например, вместо того, чтобы сбрасывать ошибку по нажатию на x, можно задать тайм-аут в пару секунд, по истечении которого состояние ошибки сбрасывается автоматически.
Теперь, когда всё готово для работы с глобальными ошибками, для задания глобальной ошибки достаточно воспользоваться _setError из Application.js. Например, это можно сделать в том случае, если сервер, после обращения к нему, вернул сообщение об общей ошибке (error: 'GENERIC'). Рассмотрим пример (файл GenericErrorReq.js).
import React, { Component } from 'react'
import axios from 'axios'
class GenericErrorReq extends Component {
constructor(props) {
super(props)
this._callBackend = this._callBackend.bind(this)
}
render() {
return (
<div>
<button onClick={this._callBackend}>Click me to call the backend</button>
</div>
)
}
_callBackend() {
axios
.post('/api/city')
.then(result => {
// сделать что-нибудь с результатом в том случае, если запрос оказался успешным
})
.catch(err => {
if (err.response.data.error === 'GENERIC') {
this.props.setError(err.response.data.description)
}
})
}
}
export default GenericErrorReqНа самом деле, на этом наш разговор об обработке ошибок можно было бы и закончить. Даже если в проекте нужно оповещать пользователя о специфических ошибках, никто не мешает просто поменять глобальное состояние, хранящее ошибку и вывести соответствующее сообщение поверх страницы. Однако тут мы не остановимся и поговорим о специфических ошибках. Во-первых, это руководство по обработке ошибок иначе было бы неполным, а во-вторых, с точки зрения UX-специалистов, неправильно будет показывать сообщения обо всех ошибках так, будто все они — глобальные.
▍Обработка специфических ошибок, возникающих при выполнении запросов
Вот пример специфического сообщения об ошибке, выводимого в том случае, если пользователь пытается удалить из базы данных город, которого там нет.

Сообщение о специфической ошибке
Тут используется тот же принцип, который мы применяли при работе с глобальными ошибками. Только сведения о таких ошибках хранятся в локальном состоянии соответствующих компонентов. Работа с ними очень похожа на работу с глобальными ошибками. Вот код файла SpecificErrorReq.js.
import React, { Component } from 'react'
import axios from 'axios'
import InlineError from './InlineError'
class SpecificErrorRequest extends Component {
constructor(props) {
super(props)
this.state = {
error: '',
}
this._callBackend = this._callBackend.bind(this)
}
render() {
return (
<div>
<button onClick={this._callBackend}>Delete your city</button>
<InlineError error={this.state.error} />
</div>
)
}
_callBackend() {
this.setState({
error: '',
})
axios
.delete('/api/city')
.then(result => {
// сделать что-нибудь с результатом в том случае, если запрос оказался успешным
})
.catch(err => {
if (err.response.data.error === 'GENERIC') {
this.props.setError(err.response.data.description)
} else {
this.setState({
error: err.response.data.description,
})
}
})
}
}
export default SpecificErrorRequest
Тут стоит отметить, что для сброса специфических ошибок недостаточно, например, просто нажать на некую кнопку x. То, что пользователь прочёл сообщение об ошибке и закрыл его, не помогает такую ошибку исправить. Исправить её можно, правильно сформировав запрос к серверу, например — введя в ситуации, показанной на предыдущем рисунке, имя города, который есть в базе. В результате очищать сообщение об ошибке имеет смысл, например, после выполнения нового запроса. Сбросить ошибку можно и в том случае, если пользователь внёс изменения в то, что будет использоваться при формировании нового запроса, то есть — при изменении содержимого поля ввода.
▍Ошибки, возникающие в клиентской части приложения
Как уже было сказано, для хранения данных о таких ошибках можно использовать состояние тех же компонентов, которое используется для хранения данных по специфическим ошибкам, поступающим с сервера. Предположим, мы позволяем пользователю отправить на сервер запрос на удаление города из базы только в том случае, если в соответствующем поле ввода есть какой-то текст. Отсутствие или наличие текста в поле можно проверить средствами клиентской части приложения.

В поле ничего нет, мы сообщаем об этом пользователю
Вот код файла SpecificErrorFrontend.js, реализующий вышеописанный функционал.
import React, { Component } from 'react'
import axios from 'axios'
import InlineError from './InlineError'
class SpecificErrorRequest extends Component {
constructor(props) {
super(props)
this.state = {
error: '',
city: '',
}
this._callBackend = this._callBackend.bind(this)
this._changeCity = this._changeCity.bind(this)
}
render() {
return (
<div>
<input
type="text"
value={this.state.city}
style={{ marginRight: 15 }}
onChange={this._changeCity}
/>
<button onClick={this._callBackend}>Delete your city</button>
<InlineError error={this.state.error} />
</div>
)
}
_changeCity(e) {
this.setState({
error: '',
city: e.target.value,
})
}
_validate() {
if (!this.state.city.length) throw new Error('Please provide a city name.')
}
_callBackend() {
this.setState({
error: '',
})
try {
this._validate()
} catch (err) {
return this.setState({ error: err.message })
}
axios
.delete('/api/city')
.then(result => {
// сделать что-нибудь с результатом в том случае, если запрос оказался успешным
})
.catch(err => {
if (err.response.data.error === 'GENERIC') {
this.props.setError(err.response.data.description)
} else {
this.setState({
error: err.response.data.description,
})
}
})
}
}
export default SpecificErrorRequest▍Интернационализация сообщений об ошибках с использованием кодов ошибок
Возможно, сейчас вы задаётесь вопросом о том, зачем нам нужны коды ошибок (наподобие GENERIC), если мы показываем пользователю только сообщения об ошибках, полученных с сервера. Дело в том, что, по мере роста и развития приложения, оно, вполне возможно, выйдет на мировой рынок, а это означает, что настанет время, когда создателям приложения нужно будет задуматься о поддержке им нескольких языков. Коды ошибок позволяют отличать их друг от друга и выводить сообщения о них на языке пользователя сайта.
Итоги
Надеемся, теперь у вас сформировалось понимание того, как можно работать с ошибками в веб-приложениях. Нечто вроде console.error(err) следует использовать только в отладочных целях, в продакшн подобные вещи, забытые программистом, проникать не должны. Упрощает решение задачи логирования использование какой-нибудь подходящей библиотеки наподобие loglevel.
Уважаемые читатели! Как вы обрабатываете ошибки в своих проектах?

При работе над веб-приложениями программисту легко попасть в ловушку: разрабатывать и тестировать только понятные сценарии, в которых всё происходит правильно. К сожалению, в реальности встречаются ситуации, в которых всё идёт не так, как планировалось. Обработка ошибок — важная часть пользовательского опыта любого приложения. Если приложение реагирует на ошибки правильно, ваши пользователи будут знать, что делать дальше, даже если что-то идёт не так.
- Обработка ошибок в бэкенд- и фронтенд-приложениях: в чём разница
- Как правильно обрабатывать ошибки
- Как работать с ошибками в AJAX-запросах и что нужно знать о кодах ответа HTTP
- Как перехватывать ошибки во фронтенд-приложениях
- Главное об обработке ошибок во фронтенд-приложениях
Большинство ошибок, с которыми сталкиваются пользователи веб-приложений, можно отнести к одной из перечисленных ниже категорий.
Ошибки ввода
Они возникают, когда приложение по каким-либо причинам не может принять введённую пользователем информацию. Например, такое происходит, если пользовательские данные не проходят валидацию, человек повторно отправляет форму, вводит неуникальный юзернейм, приложение не может найти запрошенные ресурсы и так далее.
Ошибки авторизации
Такое происходит, когда пользователь пытается совершить действие, которое ему не разрешено. Например, если рядовой пользователь форума пытается удалить чужое сообщение или незарегистрированный человек хочет опубликовать пост в блоге.
Ошибки доступности
Эти ошибки возникают, когда ресурс, нужный для завершения действия пользователя, по каким-то причинам недоступен. Такие ошибки бывают запланированными (плановое обновление сайта) и незапланированными (выход из строя сервера).
Неожиданные ошибки
Это ошибки, которые обычно говорят о багах в приложении, например, о необработанных исключениях.
Практически во всех приложениях случаются ошибки из перечисленных выше категорий. Правильная обработка ошибок — ключ к тому, чтобы пользователи оставались довольными, когда во время работы с приложением случается ошибка.
Примечание — тема обработки ошибок во фронтенд-приложениях подробно рассматривается в рамках профессии «Фронтенд-программист». Базовые курсы в этой профессии, включая «Введение в программирование», «Основы командной строки», «Настройка окружения», «Системы контроля версий», доступны бесплатно после регистрации.
Обработка ошибок в бэкенд- и фронтенд-приложениях: в чём разница
Обработка ожидаемых ошибок в бэкенде веб-приложений обычно происходит так: приложение отвечает сообщением об ошибке или отображает это сообщение пользователю. Неожиданные ошибки ломают нормальный процесс ответа и приводят к отображению общей страницы ошибки.
Плохо настроенные приложения могут даже показывать конечному пользователю информацию о внутренних ошибках. В большинстве случаев бэкенд-приложения не очень хорошо помогают человеку справиться с ошибкой и вернуться к нормальному использованию приложения. Но они хорошо справляются с задачей информирования пользователя об ошибках.
У фронтенд-приложений нет встроенного механизма, позволяющего остановить работу и показать сообщение об ошибке. После возникновения ошибки в JavaScript обычно происходит одно из описанных ниже событий:
- Приложение работает, но не выполняет действий, которые ожидает пользователь. Самая распространённая реакция пользователей в такой ситуации — попробовать ещё раз в надежде, что в этот раз приложение поведёт себя ожидаемо.
- Приложение останавливается, но не сообщает об остановке пользователю. Здесь пользователь повторит действие или попробует выполнить новое действие, но у него ничего не получится.
- Если ошибка происходит достаточно рано, пользователь может увидеть белый экран из-за неудачной попытки приложения отобразить страницу.
Все эти сценарии ужасные с точки зрения пользовательского опыта. Они могут разочаровать пользователя, заставить его чувствовать беспомощность и даже злость. Фронтенд-приложения во многом более гибкие в плане обработки ошибок по сравнению с бэкенд-приложениями. Но позаботиться об обработке ошибок должны разработчики, так как встроенные в браузеры инструменты практически бесполезны для конечных пользователей.
Читайте полезную статью
Что такое магические числа в программировании и как снять это заклятие.
Как правильно обрабатывать ошибки
Есть много способов обработки ошибок в JavaScript-приложениях. Вы можете определить глобальный обработчик ошибок, который будет отображать переданные в него сообщения. Также вы можете построить приложение так, чтобы каждый его компонент самостоятельно обрабатывал ошибки, которые в нём возникают.
Один из простых способов обработки ошибок заключается в том, чтобы создать общую схему для реакции на все ошибки и использовать систему событий браузеров, чтобы перехватывать всплывающие ошибки и обрабатывать их. Например, ошибку валидации формы можно перехватить на элементе form или соответствующем инпуте и показать пользователю сообщение об этой ошибке. А нераспознанная системная ошибка может всплыть на уровень document. В этом случае пользователь увидит обобщённое сообщение об ошибке.
Взаимодействие с пользователем при возникновении ошибки играет очень важную роль. Вы должны сообщить человеку, что пошло не так, а также объяснить, что делать дальше. В целом, сообщения могут иметь такой смысл:
- Измените что-то и повторите действие. Если пользователь ввёл невалидные данные и не смог отправить форму, благодаря сообщению об ошибке он сможет исправить данные и отправить форму.
- Попробуйте позже. Пользователь не смог отправить форму из-за ошибки сети. Благодаря сообщению он вернётся через 10 минут и успешно отправит форму.
- Свяжитесь с нами. Пользователь не смог отправить форму из-за неожиданной ошибки. Благодаря сообщению об ошибке он свяжется со службой поддержки и решит свои задачи.
При обработке ошибок на стороне клиента часто возникает необходимость выбрать между остановкой и продолжением работы приложения. Если ошибка влияет только на часть системы, можно разрешить человеку пользоваться приложением дальше. Если ошибка критическая или она влияет на разные части приложения, можно показать сообщение в модальном окне, которое невозможно закрыть. Также можно заменить контент страницы сообщением об ошибке. Это защитит пользователя от бесполезных попыток выполнить желаемое действие.
Как работать с ошибками в AJAX-запросах и что нужно знать о кодах ответа HTTP
Самый простой и очень эффективный способ сообщить пользователю об ошибке — правильно использовать коды ответов HTTP. Коды статуса HTTP могут самостоятельно дать пользователю достаточно информации о том, почему возникла ошибка запроса, а также подсказать, что делать дальше.
«Ошибочные» коды ответов HTTP объединяются в две группы: ответы 4XX и ответы 5XX. Первые говорят о проблеме с запросом (клиентские ошибки), а вторые — о проблеме с сервером (серверные ошибки). Ниже перечислены самые распространённые «ошибочные» коды статусов HTTP, которые можно получить при работе с веб-приложением:
- 400 — Bad Request. Обычно этот статус связан с ошибкой ввода, например, если пользователь вводит некорректный адрес электронной почты.
- 401 — Unauthorized. Этот статус связан с ситуацией, когда пользователь пытается получить доступ к чему-либо без авторизации там, где авторизация требуется. Также этот код ошибки подходит в ситуации, когда пользователь пытается выполнить действие, на которое у него нет прав.
- 403 — Forbidden. Разница между этим статусом и статусом 400 незначительная. Обычно код 403 говорит о том, что сервер понял запрос, но не может его выполнить. Например, такой статус можно возвращать, если пользователь ввёл номер акционного купона с истекшим сроком действия.
- 404 — Not Found. Это самый известный из «ошибочных» кодов ответа. Он сообщает, что запрошенный ресурс не найден. Это может произойти из-за некорректного URL, удалённой или перемещённой страницы.
- 409 — Conflict. В большинстве случаев этот статус говорит о конфликте управления версиями. Например, такое происходит, если пользователь пробует загрузить версию файла, которая старше загруженной ранее версии этого файла. Также этот код может говорить об ограничениях уникальности, например, если пользователь пытается повторно отправить электронное письмо (второй раз нажимает кнопку «Отправить», не дождавшись завершения действия).
- 500 — Internal Server Error. Этот статус говорит об ошибке, которую можно описать так: «Что-то пошло не так, но мы не знаем, что именно».
- 503 — Unavailable. Сервер вышел из строя, ошибка может быть запланированной или незапланированной.
Если вы хорошо знаете эти коды, вам будет проще обрабатывать ошибки, которые возникают при работе с AJAX-запросами.
Примечание — Обратите внимание на сервис httpstat.us, он пригодится вам для тестирования реакций на ошибки при разработке фронтенд-приложений.
Как перехватывать ошибки во фронтенд-приложениях
Вы можете определить обработчик глобально с помощью функции window.onerror. В этом случае обработчик переопределит дефолтное поведение браузеров, благодаря чему ваше приложение будет показывать пользователям полезную информацию при возникновении ошибок.
window.onerror = (message, url, lineNumber) => {
// определяем, знаем ли мы, как обрабатывать ошибку
if (errorCanBeHandled) {
// показываем сообщение об ошибке пользователю
displayErrorMessage(message);
// возвращаем true и запускаем дефолтную
// реакцию приложения на фатальные ошибки
return true;
} else {
// запускаем дефолтную обработку ошибок браузером
return false;
}
}
Этот подход работает. Но иногда бывает сложно понять точную причину проблемы с помощью выброшенного исключения. При обработке ошибок в AJAX-запросах лучше использовать функцию обработки ошибок библиотеки, которой вы пользуетесь для выполнения запросов. Она позволит определить код ответа и корректно на него среагировать.
Изучайте фронтенд-разработку на Хекслете! Первые курсы в профессии «Фронтенд-программист» доступны бесплатно. Регистрируйтесь и стартуйте в удобное время.
Главное об обработке ошибок во фронтенд-приложениях
Главный факт об обработке ошибок заключается в том, что вы должны их обрабатывать. Любая попытка сообщить пользователю что-то полезное, когда возникает ошибка — отличный ход. Даже информирование с помощью alert() лучше, чем отсутствие информации. Помните, что при проектировании UI вашего приложения нужно учитывать все возможные ситуации, включая различные ошибки.
Адаптированный перевод статьи Front-End Error Handling by Static Apps. Мнение администрации Хекслета может не совпадать с мнением автора оригинальной публикации.
ЧТОБЫ ОБЛЕГЧИТЬ ДЕТЯМ САМОСТОЯТЕЛЬНУЮ
РАБОТУ НАД ОШИБКАМИ,
целесообразно познакомить их с «Памяткой самостоятельной работы
над ошибками». В этой «Памятке» даются указания о том, какие операции и в какой
последовательности необходимо произвести, чтобы объяснить данную орфограмму.
Например, работая над ошибками на безударные гласные в корне слова, учащиеся руководствуются
такими указаниями: 1) разбери слово по составу, определи корень; 2)
поставь ударение, подчеркни безударные гласные в корне; 3) подбери родственные
(однокоренные) слова с ударением на проверяемом гласном; 4) составь с обоими
словами по одному предложению. Особенно важно придерживаться указанной
последовательности работы над ошибками на первых порах: она побуждает детей
выполнять работу не наугад, а вдумчиво, на основе анализа материала и
применения правил.
Анализируя ошибки на безударные гласные в корне слова, учитель
может предложить детям самостоятельно выписать из текста письменной работы
слова с безударными гласными, поставить в них знак ударения и подобрать
однокоренные и проверочные слова. Можно также предложить работу такого
характера: учитель читает текст, дети выписывают из него слова и объясняют
написание их.
Полезной формой работы над ошибками является ведение детьми индивидуальных
словариков с разделом «Мои ошибки» или «конвертов» со словами, где ими были допущены
ошибки. Такие слова учитель должен включать в тренировочные упражнения, творческие
и контрольные работы.
Самостоятельная работа учащихся над ошибками должна проводиться
только после соответствующей подготовки школьников к ее выполнению. Поэтому,
прежде чем проводить урок работы над ошибками, нужно проверить письменную
работу, выявить типичные ошибки и уже на основании этого предложить детям
предварительное задание: повторить правила, которые нарушены большинством
учащихся. Такое задание выполняется до урока работы над ошибками. В этом
случае дети придут на урок подготовленными, следовательно, учитель сможет,
опираясь на воспроизведенные знания по теоретическому материалу, организовать
работу над ошибками в плане закрепления нарушенных правил. Так урок работы над
ошибками превращается в урок закрепления, т. е. в работу по формированию у
учащихся навыков грамотного письма. Фронтальная работа над ошибками, типичными
для всего класса, необходима для усвоения правил и их закрепления. Но для
выработки прочных навыков грамотного письма большое значение имеют самостоятельные
упражнения, когда каждый ученик получает возможность работать над своими
ошибками. Возникают трудности из-за разнородности ошибок и различного темпа
работы учащихся.
Разнородность ошибок требует и разнообразных способов их
исправления и предупреждения. Если для правописания слов с непроизносимыми
согласными достаток» подобрать как можно больше подобных слое написать, запомнить их
правописание, под черкнув непроизносимые согласные, и найти к ним проверочные
слова, то для правильного написания гласных в корне необходимо
подобрать родственные слова, выделить в них корень, написать, поставить
ударения в родственных словах и подчеркнуть проверочные слова. Для правописания
слов с глухими и звонкими согласными необходимо найти в учебнике и повторить
соответствующее правило и выполнить упражнение, подтверждающее это правило.
Не все ученики могут самостоятельно найти правильный путь работы
над ошибками. Ведь разнородность ошибок говорит о разном уровне общего
развития, способностей и знаний. Часть учащихся, владеющая быстрым темпом,
выполняет задания быстрее. Для них необходимо подготовить дополнительный
материал (в виде заданий на листочках). Чтобы произвести классификацию ошибок,
можно изготовить настенную таблицу «Учет грамотности учащихся». Таблица
представляет собой лист плотной бумаги с перечнем фамилий учащихся и пронумерованными
графами, имеющими заголовки повторяемого и вновь изучаемого материала.
Например, в таблице для II класса графа I названа «Точка в конце предложения», графа 2 — «Большая
буква в именах», графа 3 — «Гласные после шипящих». Последняя графа — «Какую
работу надо выполнить». Ошибки каждого ученика отмечаются в соответствующей
графе независимо от количества ошибок.
Ученики смотрят на последнюю графу и по номеру упражнений
определяют свое задание. Таблица вывешивается на следующий день после
проведения контрольной работы. Дети горячо обсуждают итоги, помещенные в
таблице, не только до уроков, но и после, на другой и на третий день.
Систематический учет грамотности детей полезен и учителю, так как
он дает наглядное представление о состоянии грамотности учеников, о различных
категориях ошибок, общих для всего класса. По мере овладения умением
самостоятельно выполнять задания организуется индивидуальная самостоятельная
работа над ошибками по карточке. Каждому ученику рекомендуется
повторить соответствующее грамматическое правило. Это правило ученик
отвечает учителю либо перед тем, как приступить к выполнению самостоятельной
работы. Самостоятельная работа учащихся над ошибками имеет большое значение.
При такой организации работы ученик действительно приучается работать
самостоятельно. Имея в руках задание, которое он должен выполнить сам, не
заглядывая в тетрадь соседа и не списывая механически с доски готовое решение,
ученик начинает по-настоящему учиться, задумываться над написанием слов. При
организаций самостоятельной работы время каждого ученика используется
целесообразно.
Учитель, пользуясь тем, что все дети заняты работой,
может уделить внимание слабоуспевающим, дать им дополнительные разъяснения. Для
тех, кто в последней контрольной работе не допустил ошибок, дается
дидактический материал, стимулирующий творческую деятельность: составление
рассказов по данным словам, по плану (с включением опорных слов и оборотов), по
картине.
Как показывает опыт, при систематической организации
самостоятельной работы над ошибками растет возможность уменьшить объем домашних
заданий, так как значительная часть материала усваивается во время
самостоятельных занятий под непосредственным руководством учителя.
Для организации самостоятельной работы, домашней работы над
ошибками необходимо использовать памятку, которая подсказывает, на какое
правило допущена ошибка, и в которой дан образец, как правильно исправить эту
ошибку.
Каждое правило имеет свой порядковый номер, но это не значит, что
ученик должен его запомнить и соотнести с орфограммой. Порядковый номер
предлагается для того, чтобы ученик мог быстро и легко найти в памятке нужную
ему орфограмму. Памятка заполняется по мере изучения правила.
КАК НАДО РАБОТАТЬ НАД ОШИБКАМИ
(памятка для ученика)
1. Если ты пропустил, переставил или не дописал букву в слове,
напиши слово правильно и подели его на слоги. Подчеркни букву, которую
пропустил, обозначь ударение.
2. Если допустил ошибку на правило, то сначала определи, в какой
части слова находится твоя ошибка. Для этого разбери слово по составу.
3. Если ошибка в приставке, узнай у учителя или в учебнике, как
пишется приставка, и напиши слово правильно. Подбери и напиши три слова с той
же приставкой. Подчеркни приставку и обозначь ударение.
4. Если ошибка в корне, узнай, на какое правило. Напиши
проверочное слово, обозначь ударение, выдели корень. Напиши еще несколько
однокоренных слов. Во всех словах выдели корень.
5. Если ошибка в суффиксе, узнай, как он пишется, и напиши еще два
слова с тем же суффиксом. Выдели суффикс.
6. Если ошибка в окончании существительного, то выпиши это слово
вместе с тем словом, к которому оно относится. Укажи вопрос, падеж, склонение,
окончание. Составь предложение с существительным в этом же падеже.
7. Если ошибка в окончании прилагательного, то выпиши
прилагательное вместе с существительным, к которому оно относится. По роду и
падежу узнай род и падеж прилагательного, вспомни окончание. Составь предложение
с прилагательным в том же падеже.
8. Если ошибка в окончании глагола, напиши неопределенную форму
глагола, узнай спряжение, определи время, лицо, число глагола. Составь
предложение с этим глаголом.
ПАМЯТКА
1. Перенос слов.
Ма-ленький,
малень-кий.
Ап-пликация,
аппли-кация, апплика-ция.
2. Жи, ши, чу,
щу, ча, ща, чк, чн.
(Напиши слово
правильно, подбери еще три слова на это правило.)
Машина, шил,
шина, шило; чулки, чудо, кричу, чугун.
3. Большая буква
в именах собственных. Ленинград — название города.
Иванов Сергей Петрович
— фамилия, имя,
отчество.
С Жучкой — кличка животного.
4. Безударные
гласные в корне, проверяемые ударением.
Грозы — гроза,
снег — снега.
5. Парные звонкие и глухие
согласные в корне слова.
Грибы — гриб,
шуба — шубка.
6. Непроизносимые согласные в корне
слова.
Солнышко — солнце;
но: опасен —
опасный.
7. Правописание
приставки.
Из садика; но: переход.
8. Разделительные ъ
и ь.
Подъезд, въюга.
9. Раздельное
написание предлога со словом. В лес, в густой лес.
10. Мягкий знак
(ь) в конце существительных после шипящих.
Ночь — ж. р.; мяч — м. р.
11. Безударные
гласные в окончаниях прилагательных.
Озером
(каким?) глубоким;
к лесу (какому?)
сосновому.
12. Безударные
падежные окончания существительных.
Шел (по
чему?) по площади — 3-е скл., д. п. (по степи).
Читали (о чем?)
об улице — 1-е
скл., п. п., (о земле).
Мечтали (о чем?) о
космосе — 2-е
скл., п. п. (о коне).
13. Безударные
личные окончания глаголов. Писать (не на ить, не искл, 1-е спр.) — пишет.
Строить (на ить, 2-е спр.) — строят.
Смотреть (искл., 2-е спр.) — смотришь,
14. Глаголы 2-го
лица единственного числа. Играешь — 2-е л., ед. ч.
Работа над ошибками по памятке происходит следующим образом. К
традиционной палочке на полях, обозначающей орфографическую ошибку, учитель
приписывает маленькую цифру — номер орфограммы, помещенной в памятке. После
проверенной работы пропускаются две строчки и на последующих строчках (слева)
ставится столько «галочек», сколько допущено орфографических ошибок. Ученик,
получив тетрадь, первую строчку пропускает, а на второй строчке пишет слова:
«Работа над ошибками». Далее на всех строчках, где имелись «галочки», выполняет
работу над ошибками строго по памятке. Каждую работу над ошибками учитель
проверяет и оценивает, при этом учитывает правильность и точность исправления.
Таким образом, основными видами самостоятельной работы учащихся
над ошибками являются: 1) самостоятельное отыскивание и исправление ошибок; 2)
самостоятельное исправление ошибок, только подчеркнутых учителем или отмеченных
на полях тетради при помощи условных знаков; 3) самостоятельное выписывание
слов, в которых допущены ошибки; 4) составление предложений со словами, в
которых были допущены ошибки; 5) работа с орфографическим словарем; 6)
выполнение дополнительных тренировочных упражнений на те правила, на которые
допущены ошибки.
Мы рассмотрим, как выполнять проверку данных в Excel: создавать правила проверки для чисел, дат или текстовых значений, создавать списки проверки данных, копировать проверку данных в другие ячейки, находить недопустимые записи, исправлять и удалять проверку данных.
При настройке рабочей книги для пользователей часто может потребоваться контролировать ввод информации в определенные ячейки, чтобы убедиться, что все введенные данные точны и непротиворечивы. Кроме того, вы можете захотеть разрешить в ячейке только определенный тип данных, например числа или даты, или ограничить числа определенным диапазоном, а текст — заданной длиной. Возможно, вы даже захотите предоставить заранее определенный список допустимых значений, чтобы исключить возможные ошибки. Проверка данных Excel позволяет выполнять все эти действия во всех версиях Microsoft Excel 365, 2019, 2016, 20013, 2010 и более ранних версиях.
Что такое проверка данных в Excel?
Проверка данных Excel — это функция, которая ограничивает (проверяет) пользовательский ввод на рабочем листе. Технически вы создаете правило проверки, которое контролирует, какие данные можно вводить в определенную ячейку.
Вот лишь несколько примеров того, что может сделать проверка данных в Excel:
- Разрешить только числовые или текстовые значения в ячейке.
- Разрешить только числа в указанном диапазоне.
- Разрешить ввод данных определенной длины.
- Ограничить даты и время вне заданного диапазона.
- Ограничить записи выбором из раскрывающегося списка.
- Проверка вводимого на основе другой ячейки.
- Показать входное сообщение, когда пользователь выбирает ячейку.
- Показывать предупреждающее сообщение при вводе неверных данных.
- Найти неправильные записи в проверенных ячейках.
Например, вы можете настроить правило, которое ограничивает ввод данных 3-значными числами от 100 до 999. Если пользователь вводит что-то другое, Excel покажет предупреждение об ошибке, объясняющее, что было сделано неправильно:

Как сделать проверку данных в Excel
Чтобы добавить проверку данных в Excel, выполните следующие действия.
1. Откройте диалоговое окно «Проверка данных».
Напомним, где находится кнопка проверки данных в Excel. Выбрав одну или несколько ячеек для проверки, перейдите на вкладку «Данные» > группа «Работа с данными» и нажмите кнопку «Проверка данных».

2. Создайте правило проверки Excel.
На вкладке «Параметры» определите критерии проверки в соответствии с вашими потребностями. В критериях вы можете указать любое из следующего:
- Значения — введите числа в поля критериев, как показано на снимке экрана ниже.
- Ссылки на ячейки — создание правила на основе значения или формулы в другой ячейке.
- Формулы — позволяют выразить более сложные условия.
В качестве примера создадим правило, разрешающее пользователям вводить только целое число от 100 до 999:

Настроив правило проверки, нажмите кнопку «ОК», чтобы закрыть окно «Проверка вводимых значений», или переключитесь на другую вкладку, чтобы добавить подсказку по вводу и/или сообщение об ошибке.
3. Подсказка по вводу (необязательно).
Если вы хотите отобразить сообщение, объясняющее пользователю, какие данные разрешены в данной ячейке, откройте соответствующую вкладку и выполните следующие действия:
- Убедитесь, что установлен флажок Отображать подсказку при выборе ячейки.
- Введите заголовок и текст сообщения в соответствующие поля.
- Нажмите OK, чтобы закрыть диалоговое окно.

Как только пользователь выберет проверяемую ячейку, появится следующее сообщение, как на скриншоте ниже:

4. Отображение предупреждения об ошибке (необязательно)
В дополнение к входному сообщению вы можете отобразить одно из следующих предупреждений, когда в ячейку введены недопустимые данные.
| Тип оповещения | Описание |
|---|---|
| Стоп (по умолчанию) |  Самый строгий тип предупреждений, запрещающий пользователям вводить неверные данные. Вы нажимаете «Повторить», чтобы ввести другое значение, или «Отмена», чтобы удалить запись. |
| Предупреждение |  Предупреждает пользователей о том, что данные недействительны, но не препятствует их вводу. Вы нажимаете «Да», чтобы ввести недопустимое значение, «Нет», чтобы изменить его, или «Отмена», чтобы удалить запись. |
| Информация |  Наименее строгий тип оповещения, который информирует пользователей только о неверном вводе данных. Нажмите «ОК», чтобы ввести недопустимое значение, или «Отмена», чтобы удалить его из ячейки. |
Чтобы настроить пользовательское сообщение об ошибке, перейдите на вкладку «Сообщение об ошибке» и задайте следующие параметры:
- Установите флажок Выводить сообщение об ошибке (обычно установлен по умолчанию).
- В поле Вид выберите нужный тип оповещения.
- Введите заголовок и текст сообщения об ошибке в соответствующие поля.
- Нажмите ОК.

И теперь, если пользователь введет недопустимые значения, Excel отобразит специальное предупреждение с объяснением ошибки (как показано в начале этого руководства).
Примечание. Если вы не введете собственное сообщение, появится стандартное предупреждение Stop со следующим текстом: Это значение не соответствует ограничениям проверки данных, установленным для этой ячейки.
Как настроить ограничения проверки данных Excel
При добавлении правила проверки данных в Excel вы можете выбрать один из предопределенных параметров или указать новые критерии на основе собственной формулы. Ниже мы обсудим каждую из встроенных опций.
Как вы уже знаете, критерии проверки определяются на вкладке «Параметры» диалогового окна «Проверка данных» (вкладка «Данные» > «Проверка данных»).
В первую очередь нужно настроить проверку типа записываемых данных.
К примеру, чтобы ограничить ввод данных целым или десятичным числом, выберите соответствующий элемент в поле Тип данных. Затем выберите один из следующих критериев в поле Данные:
- Равно или не равно указанному числу
- Больше или меньше указанного числа
- Между двумя числами или вне, чтобы исключить этот диапазон чисел
Например, вот как выглядят ограничения по проверке данных Excel, которые допускают любое целое число больше 100:

Проверка даты и времени в Excel
Чтобы проверить даты, выберите «Дата» в поле «Тип данных», а затем выберите соответствующий критерий в поле «Значение». Существует довольно много предопределенных параметров на выбор: разрешить только даты между двумя датами, равные, большие или меньшие определенной даты и т. д.
Точно так же, чтобы проверить время, выберите Время в поле Значение, а затем определите необходимые критерии.
Например, чтобы разрешить только даты между датой начала в B1 и датой окончания в B2, примените это правило проверки даты Excel:

Разрешить только будни или выходные
Чтобы разрешить пользователю вводить даты только будних или выходных дней, настройте пользовательское правило проверки на основе функции ДЕНЬНЕД (WEEKDAY).
Если для второго аргумента установлено значение 2, функция возвращает целое число в диапазоне от 1 (понедельник) до 7 (воскресенье). Так, для будних дней (пн-пт) результат формулы должен быть меньше 6, а для выходных (сб и вс) — больше 5.
Таким образом, разрешить только рабочие дни:
=ДЕНЬНЕД( ячейка ; 2)<6
Разрешить только выходные :
=ДЕНЬНЕД( ячейка ; 2)>5
Например, чтобы разрешить ввод только рабочих дней в ячейки C2:C8, используйте следующую формулу:
=ДЕНЬНЕД(A2;2)<6

Проверить даты на основе сегодняшней даты
Во многих случаях может потребоваться использовать сегодняшнюю дату в качестве начальной даты допустимого диапазона дат. Чтобы получить текущую дату, используйте функцию СЕГОДНЯ , а затем добавьте к ней нужное количество дней, чтобы вычислить дату окончания временного периода.
Например, чтобы ограничить ввод данных через 6 дней (7 дней, включая сегодняшний день), мы можем использовать встроенное правило даты с критериями в виде формул:
- Выберите Дата в поле Тип данных
- Выберите в поле Значение – между
- В поле Начальная дата введите выражение =СЕГОДНЯ()
- В поле Конечная дата введите =СЕГОДНЯ() + 6

Аналогичным образом вы можете ограничить пользователей вводом дат до или после сегодняшней даты. Для этого выберите меньше или больше, чем в поле Значение, а затем введите =СЕГОДНЯ() в поле Начальная дата или Конечная дата соответственно.
Проверка времени на основе текущего времени
Чтобы проверить вводимые данные на основе текущего времени, используйте предопределенное правило времени с собственной формулой проверки данных. Для этого сделайте следующее:
В поле Тип данных выберите Время .
В поле Значение выберите «меньше», чтобы разрешить только время до текущего времени, или «больше», чтобы разрешить время после текущего времени.
В поле Время окончания или Время начала (в зависимости от того, какие критерии вы выбрали на предыдущем шаге) введите одну из следующих формул:
Чтобы проверить дату и время на основе текущей даты и времени:
=ТДАТА()
Чтобы проверить время на основе текущего времени, используйте выражение:
=ВРЕМЯ(ЧАС(ТДАТА());МИНУТЫ(ТДАТА());СЕКУНДЫ(ТДАТА()))
Проверка длины текста
Чтобы разрешить ввод данных определенной длины, выберите Длина текста в поле Тип данных и укажите критерии проверки в соответствии с вашей бизнес-логикой.
Например, чтобы ограничить ввод до 15 символов, создайте такое правило:

Примечание. Параметр «Длина текста» ограничивает количество символов, но не тип данных. Это означает, что приведенное выше правило разрешает как текст, так и числа до 15 символов или 15 цифр соответственно.
Список проверки данных Excel (раскрывающийся список)
Чтобы добавить для проверки вводимых данных раскрывающийся список элементов в ячейку или группу ячеек, выберите целевые ячейки и выполните следующие действия:
- Откройте диалоговое окно «Проверка данных» (вкладка «Данные» > «Проверка данных»).
- На вкладке «Настройки» выберите «Список» в поле «Тип данных».
- В поле Источник введите элементы списка проверки Excel, разделенные точкой с запятой. Например, чтобы ограничить пользовательский ввод тремя вариантами, введите Да; Нет; Н/Д.
- Убедитесь, что выбрана опция Список допустимых значений, чтобы стрелка раскрывающегося списка отображалась рядом с ячейкой.
- Нажмите ОК.

Выпадающий список проверки данных Excel будет выглядеть примерно так:

Примечание. Будьте осторожны с опцией «Игнорировать пустые ячейки», которая активна по умолчанию. Если вы создаете раскрывающийся список на основе именованного диапазона, в котором есть хотя бы одна пустая ячейка, установка этого флажка позволит ввести любое значение в проверенную ячейку. Во многих случаях это справедливо и для формул проверки данных: если ячейка, указанная в формуле, пуста, любое значение будет разрешено в проверяемой ячейке.
Другие способы создания списка проверки данных в Excel
Предоставление списков, разделенных точкой с запятой, непосредственно в поле «Источник» — это самый быстрый способ, который хорошо работает для небольших раскрывающихся списков, которые вряд ли когда-либо изменятся. В других сценариях можно действовать одним из следующих способов:
- Создать список проверки данных из диапазона ячеек.
- Создать динамический список проверки данных на основе именованного диапазона.
- Получить список проверки данных Excel из умной таблицы. Лучше всего то, что раскрывающийся список на основе таблицы является динамическим по своей природе и автоматически обновляется при добавлении или удалении элементов из этой таблицы.
Во всех этих случаях вы просто записываете соответствующую ссылку на диапазон либо элемент таблицы в поле Источник.
Разрешить только числа
В дополнение к встроенным правилам проверки данных Excel, обсуждаемым в этом руководстве, вы можете создавать собственные правила с собственными формулами проверки данных.
Удивительно, но ни одно из встроенных правил проверки данных Excel не подходит для очень типичной ситуации, когда вам нужно ограничить пользователей вводом только чисел в определенные ячейки. Но это можно легко сделать с помощью пользовательской формулы проверки данных, основанной на функции ЕЧИСЛО(), например:
=ЕЧИСЛО(C2)
Где C2 — самая верхняя ячейка диапазона, который вы хотите проверить.

Примечание. Функция ЕЧИСЛО допускает любые числовые значения в проверенных ячейках, включая целые числа, десятичные дроби, дроби, а также даты и время, которые также являются числами в Excel.
Разрешить только текст
Если вы ищете обратное — разрешить только текстовые записи в заданном диапазоне ячеек, то создайте собственное правило с функцией ЕТЕКСТ (ISTEXT), например:
=ЕТЕКСТ(B2)
Где B2 — самая верхняя ячейка выбранного диапазона.

Разрешить текст, начинающийся с определенных символов
Если все значения в определенном диапазоне должны начинаться с определенного символа или подстроки, выполните проверку данных Excel на основе функции СЧЁТЕСЛИ с подстановочным знаком:
=СЧЁТЕСЛИ(A2; » текст *»)
Например, чтобы убедиться, что все идентификаторы заказов в столбце A начинаются с префикса «AРТ-», «арт-», «Aрт-» или «aРт-» (без учета регистра), определите пользовательское правило с этой проверкой данных.
=СЧЁТЕСЛИ(A2;»АРТ-*»)

Формула проверки с логикой ИЛИ (несколько критериев)
В случае, если есть 2 или более допустимых префикса, добавьте несколько функций СЧЁТЕСЛИ, чтобы ваше правило проверки данных Excel работало с логикой ИЛИ:
=СЧЁТЕСЛИ(A2;»АРТ-*»)+СЧЁТЕСЛИ(A2;»АБВ-*»)

Проверка ввода с учетом регистра
Если регистр символов имеет значение, используйте СОВПАД (EXACT) в сочетании с функцией ЛЕВСИМВ, чтобы создать формулу проверки с учетом регистра для записей, начинающихся с определенного текста:
=СОВПАД(ЛЕВСИМВ(ячейка; число_символов); текст)
Например, чтобы разрешить только те коды заказов, которые начинаются с «AРТ-» (ни «арт-», ни «Арт-» не допускаются), используйте эту формулу:
=СОВПАД(ЛЕВСИМВ(A2;4);»АРТ-«)

В приведенной выше формуле функция ЛЕВСИМВ извлекает первые 4 символа из ячейки A2, а СОВПАД выполняет сравнение с учетом регистра с жестко заданной подстрокой (в данном примере «AРТ-«). Если две подстроки точно совпадают, формула возвращает ИСТИНА и проверка проходит успешно; в противном случае возвращается ЛОЖЬ и проверка завершается неудачно.
Разрешить только значения, содержащие определенный текст
Чтобы разрешить ввод значений, которые содержат определенный текст в любом месте ячейки (в начале, середине или конце), используйте функцию ЕЧИСЛО (ISNUMBER) в сочетании с НАЙТИ (FIND) или ПОИСК (SEARCH) в зависимости от того, хотите ли вы совпадение с учетом регистра или без учета регистра:
Проверка без учета регистра:
ЕЧИСЛО(ПОИСК( текст ; ячейка ))
Проверка с учетом регистра:
ЕЧИСЛО(НАЙТИ( текст ; ячейка ))
В нашем примере, чтобы разрешить только записи, содержащие текст «AР» в ячейках A2: A8, используйте одну из следующих формул, создав правило проверки в ячейке A2:
Без учета регистра:
=ЕЧИСЛО(ПОИСК(«ар»;A2))
С учетом регистра:
=ЕЧИСЛО(НАЙТИ(«АР»;A2))
Формулы работают по следующей логике:
Вы ищете подстроку «AР» в ячейке A2, используя НАЙТИ или ПОИСК, и оба возвращают позицию первого символа в подстроке. Если текст не найден, возвращается ошибка. Если поиск успешен и «АР» найден в ячейке, мы получаем номер позиции в тексте, где эта подстрока была найдена. Далее функция ЕЧИСЛО возвращает ИСТИНА, и проверка данных проходит успешно. В случае, если подстроку не удалось найти, результатом будет ошибка и ЕЧИСЛО возвращает ЛОЖЬ. Запись не будет разрешена в ячейке.
Разрешить только уникальные записи и запретить дубликаты
В ситуациях, когда определенный столбец или диапазон ячеек не должны содержать дубликатов, настройте пользовательское правило проверки данных, разрешающее только уникальные записи. Для этого мы можем использовать классическую формулу СЧЁТЕСЛИ для выявления дубликатов :
=СЧЁТЕСЛИ( диапазон ; самая верхняя_ячейка )<=1
Например, чтобы убедиться, что в ячейки с A2 по A8 вводятся только уникальные идентификаторы заказов, создайте настраиваемое правило со следующей формулой проверки данных:
=СЧЁТЕСЛИ($A$2:$A$8; A2)<=1

При вводе уникального значения формула возвращает ИСТИНА, и проверка проходит успешно. Если такое же значение уже существует в указанном диапазоне (счетчик больше 1), функция СЧЁТЕСЛИ возвращает ЛОЖЬ, и вводимые данные не проходят проверку.
Обратите внимание, что мы фиксируем диапазон абсолютными ссылками на ячейки (A$2:$A$8) и используем относительную ссылку для верхней ячейки (A2), чтобы формула корректно изменялась для каждой ячейки в проверяемом диапазоне.
Как отредактировать проверку данных в Excel
Чтобы изменить правило проверки Excel, выполните следующие действия:
- Выберите любую из проверенных ячеек.
- Откройте диалоговое окно «Проверка данных» (вкладка «Данные» > «Проверка данных»).
- Внесите необходимые изменения.
- Установите флажок Применить эти изменения ко всем другим ячейкам с теми же параметрами, чтобы скопировать внесенные вами изменения во все остальные ячейки с исходными критериями проверки.
- Нажмите OK, чтобы сохранить изменения.
Например, вы можете отредактировать список проверки данных Excel, добавив или удалив элементы из поля «Источник», и применить эти изменения ко всем другим ячейкам, содержащим тот же раскрывающийся список.
Как скопировать правило проверки данных Excel в другие ячейки
Если вы настроили проверку данных для одной ячейки и хотите проверить другие ячейки с теми же критериями, вам не нужно заново создавать правило с нуля.
Чтобы скопировать правило проверки в Excel, выполните следующие 4 быстрых шага:
- Выберите ячейку, к которой применяется правило проверки, и нажмите Ctrl + С , чтобы скопировать его.
- Выберите другие ячейки, которые вы хотите проверить. Чтобы выделить несмежные ячейки, нажмите и удерживайте клавишу Ctrl при выборе ячеек.
- Щелкните выделенный фрагмент правой кнопкой мыши, выберите «Специальная вставка» и выберите параметр «Условия на значения».
Либо используйте комбинацию клавиш Ctrl + Alt + V, и затем — Н.
- Нажмите ОК.

Подсказка. Вместо того, чтобы копировать проверку данных в другие ячейки, вы можете преобразовать свой набор данных в таблицу Excel. По мере добавления строк в таблицу Excel будет автоматически применять правило проверки к новым строкам.
Как найти ячейки с проверкой данных в Excel
Чтобы быстро найти все проверенные ячейки на текущем листе, перейдите на вкладку «Главная» > группа «Редактирование» и нажмите «Найти и выделить» > «Проверка данных» :

Это выберет все ячейки, к которым применены какие-либо правила проверки данных. Если необходимо, из этих выбранных ячеек вы можете удалить проверку.
Как убрать проверку данных в Excel
В целом, есть два способа удалить проверку в Excel: стандартный подход, разработанный Microsoft, и метод без мыши, разработанный фанатами Excel, которые никогда не отрывают руки от клавиатуры без крайней необходимости (например, чтобы выпить чашку кофе:)
Способ 1: Обычный способ отключить проверку данных
Обычно, чтобы удалить проверку данных на листах Excel, выполните следующие действия:
- Выберите ячейку (ячейки) с проверкой данных.
- На вкладке «Данные» нажмите кнопку «Проверка данных».
- На вкладке «Настройки» нажмите кнопку «Очистить все», а затем нажмите «ОК».

Советы:
- Чтобы удалить проверку данных из всех ячеек на текущем листе, используйте инструмент «Найти и выделить», чтобы выбрать все ячейки с проверкой.
- Чтобы удалить определенное правило проверки данных, выберите любую ячейку с этим правилом, откройте диалоговое окно «Проверка данных», установите флажок «Применить эти изменения ко всем другим ячейкам с такими же настройками» и нажмите кнопку «Очистить все».
Как видите, стандартный метод работает довольно быстро, но требует нескольких щелчков мышью, что, на мой взгляд, не имеет большого значения. Но если вы предпочитаете работать с клавиатурой, а не с мышью, вам может понравиться следующий подход.
Способ 2: Удалить правила проверки данных при помощи Специальной вставки
Изначально специальная вставка Excel предназначена для вставки определенных элементов скопированных ячеек. На самом деле она может делать гораздо больше полезных вещей. Среди прочего, он может быстро удалить правила проверки данных на листе. Вот как:
- Выберите пустую ячейку без проверки данных и нажмите
Ctrl + С, чтобы скопировать ее в буфер обмена. - Выберите ячейки, в которых вы хотите отключить проверку данных.
- Нажмите
Ctrl + Alt + V, и затемН. Эта комбинация клавиш вызовет «Специальная вставка» > «Проверка данных». - Нажимаем ОК.
Советы по проверке данных в Excel
Теперь, когда вы знакомы с основами проверки данных в Excel, позвольте мне поделиться несколькими советами, которые могут сделать ваши правила намного более эффективными.
Проверка данных на основе другой ячейки
Вместо того, чтобы вводить значения непосредственно в поля критериев, вы можете ввести их в некоторые ячейки, а затем ссылаться на эти ячейки. Если вы решите позже изменить условия проверки, вы просто запишете новые значения на рабочем листе, не редактируя правило. Это сэкономит много времени.
Чтобы ввести ссылку на ячейку, либо введите ее в поле, перед которым стоит знак равенства, либо щелкните стрелку рядом с полем, а затем выберите ячейку с помощью мыши. Вы также можете щелкнуть в любом месте поля, а затем выбрать ячейку на листе.
Например, чтобы разрешить любое целое число, находящееся между 100 и 999, выберите критерии «минимум» и «максимум» в вкладке «Параметры» и введите в них адреса ячеек с этими числами:

Рис18
Вы также можете ввести формулу в ячейку, на которую указывает ссылка, и Excel проверит ввод на основе этой формулы.
Например, чтобы запретить пользователям вводить даты после сегодняшней даты, введите формулу =СЕГОДНЯ() в какую-нибудь ячейку, скажем, B1, а затем настройте правило проверки даты на основе этой ячейки:

Или вы можете ввести формулу =СЕГОДНЯ() непосредственно в поле Конечная дата, что будет иметь тот же эффект.
Правила проверки на основе формул
В ситуациях, когда невозможно определить желаемые критерии проверки на основе значения или ссылки на ячейку, вы можете выразить это с помощью формулы.
Например, чтобы ограничить ввод минимальным и максимальным значениями в существующем списке чисел, скажем, A1:A10, используйте следующие формулы:
=МИН($С$2:$С$10)
=МАКС($С$2:$С$10)

Обратите внимание, что мы фиксируем диапазон с помощью знака $ (абсолютная ссылка на ячейки), чтобы наше правило проверки Excel работало правильно для всех выбранных ячеек.
Как найти неверные данные на листе
Хотя Microsoft Excel позволяет применять проверку данных к ячейкам, в которых уже есть данные, он не уведомит вас, если некоторые из уже существующих значений не соответствуют критериям проверки.
Чтобы найти недействительные данные, которые попали в ваши рабочие листы до того, как вы добавили проверку данных, перейдите на вкладку «Данные» и нажмите «Проверка данных» > «Обвести неверные данные».

Это выделит все ячейки, которые не соответствуют критериям проверки.
Как только вы исправите неверную запись, отметка автоматически исчезнет. Чтобы удалить все отметки, перейдите на вкладку «Данные» и нажмите «Проверка данных» > «Удалить обводку неверных данных».
Как поделиться книгой с проверкой данных
Чтобы разрешить нескольким пользователям совместную работу над книгой, обязательно предоставьте к ней общий доступ после проверки данных.
После совместного использования книги ваши правила проверки данных продолжат работать, но вы не сможете ни изменить их, ни добавить новые правила.
Почему проверка данных Excel не работает?
Если проверка данных не работает должным образом на ваших листах, это, скорее всего, происходит по одной из следующих причин.
Проверка данных не работает для скопированных данных
Проверка данных в Excel предназначена для запрета ввода недопустимых данных непосредственно в ячейку, но не может помешать пользователям копировать недопустимые данные.
Хотя нет способа отключить клавиши копирования/вставки (кроме использования VBA), вы можете, по крайней мере, предотвратить копирование данных путем перетаскивания ячеек. Для этого выберите «Файл» > «Параметры» > «Дополнительно» > «Параметры редактирования» и снимите флажок «Включить маркер заполнения и перетаскивания ячеек».
Проверка данных Excel не активна
Кнопка «Проверка данных» не активна (выделена серым цветом), если вы вводите или изменяете данные в ячейке. Закончив редактирование ячейки, нажмите Enter или Esc, чтобы выйти из режима редактирования, а затем выполните проверку данных.
Проверка данных не может быть применена к защищенной или общей книге
Хотя существующие правила проверки продолжают работать в защищенных и общих книгах, невозможно изменить параметры проверки данных или настроить новые правила. Для этого сначала отмените общий доступ и/или снимите защиту с книги.
Неправильные формулы проверки данных
При проверке данных на основе формул в Excel необходимо проверить три важные вещи:
- Формула проверки не возвращает ошибок.
- Формула не ссылается на пустые ячейки.
- Используются правильные ссылки на ячейки.
Ручной пересчет формул включен
Если в Excel включен режим ручного расчета, невычисленные формулы могут помешать правильной проверке данных. Чтобы снова изменить параметр расчета Excel на автоматический, перейдите на вкладку «Формулы» > группу «Расчет», нажмите кнопку «Параметры расчета» и выберите «Автоматически».
Проверьте правильность формулы проверки данных
Для начала скопируйте формулу проверки в какую-нибудь ячейку, чтобы убедиться, что она не возвращает ошибку, такую как #Н/Д, #ЗНАЧ или #ДЕЛ/0!.
Если вы создаете пользовательское правило , формула должна возвращать логические значения ИСТИНА и ЛОЖЬ или приравненные к ним значения 1 и 0 соответственно.
Если вы используете критерий на основе формулы во встроенном правиле (как мы делали для проверки времени на основе текущего времени), он также может возвращать неправильное числовое значение.
Формула проверки данных не должна ссылаться на пустую ячейку
Если вы активируете опцию «Игнорировать пустые ячейки» при определении правила (обычно выбрано по умолчанию), то следите, чтобы ваши формулы или условия не ссылались на пустую ячейку.
В случае, когда одна или несколько ячеек, на которые есть ссылки в вашей формуле, пусты, то в проверяемой ячейке будет разрешено любое значение.
Абсолютные и относительные ссылки на ячейки в формулах проверки
При настройке правила проверки Excel на основе формулы помните, что все ссылки на ячейки в вашей формуле относятся к верхней левой ячейке в выбранном диапазоне.
Если вы создаете правило для нескольких ячеек и ваши критерии проверки содержат адреса конкретных ячеек , обязательно зафиксируйте ячейку в формуле при помощи абсолютной ссылки (со знаком $, например, $A$1), иначе ваше правило будет правильно работать только для первой ячейки.
Чтобы лучше проиллюстрировать это, рассмотрим следующий пример.
Предположим, вы хотите ограничить ввод данных в ячейках с A2 по A8 целыми числами от 100 (минимальное значение) до 999. Чтобы проще было при необходимости изменить критерии проверки, используем ссылки на ячейки с этими значениями, как показано на скриншоте ниже:

Это правило будет корректно выполняться только для первой ячейки диапазона – A2. Для ячейки A3 критерии максимума и минимума изменятся на E3 и F3. Поскольку эти ячейки пусты, то условие ввода теперь – любое число больше либо меньше нуля. Правда, символьные значения и дробные числа вы вводить не сможете, так как продолжает действовать ограничение на тип данных – целые числа.
Чтобы исправить формулу, просто введите «$» перед ссылками на столбцы и строки, чтобы зафиксировать их: =$E$2 и $F$2. Или используйте клавишу F4 для переключения между различными типами ссылок.
Вот как вы можете добавить и использовать проверку данных в Excel. Я благодарю вас за чтение и надеюсь ещё увидеть вас в нашем блоге!
Почти все разработчики так или иначе постоянно работают с api по
http, клиентские разработчики работают с api backend своего сайта
или приложения, а бэкендеры «дергают» бэкенды других сервисов, как
внутренних, так и внешних. И мне кажется, одна из самых главных
вещей в хорошем API это формат передачи ошибок. Ведь если это
сделано плохо/неудобно, то разработчик, использующий это API,
скорее всего не обработает ошибки, а клиенты будут пользоваться
молчаливо ломающимся продуктом.
За 7 лет я как поддерживал множество legacy API, так и
разрабатывал c нуля. И я поработал, наверное, с большинством
стратегий по возвращению ошибок, но каждая из них создавала
дискомфорт в той или иной мере. В последнее время я нащупал
оптимальный вариант, о котором и хочу рассказать, но с начала
расскажу о двух наиболее популярных вариантах.
1: HTTP статусы
Если почитать апологетов REST, то для кодов ошибок надо
использовать HTTP статусы, а текст ошибки отдавать в теле или в
специальном заголовке. Например:
Success:
HTTP 200 GET /v1/user/1Body: { name: 'Вася' }
Error:
HTTP 404 GET /v1/user/1Body: 'Не найден пользователь'
Если у вас примитивная бизнес-логика или API из 5 url, то в
принципе это нормальный подход. Однако как-только бизнес-логика
станет сложнее, то начнется ряд проблем.
Http статусы предназначались для описания ошибок при
передаче данных, а про логику вашего приложения никто не
думал. Статусов явно не хватает для описания всего
разнообразия ошибок в вашем проекте, да они и не были для этого
предназначены. И тут начинается натягивание «совы на глобус»: все
начинают спорить, какой статус ошибки дать в том или ином случае.
Пример: Есть API для task manager. Какой статус надо вернуть в
случае, если пользователь хочет взять задачу, а ее уже взял в
работу другой пользователь? Ссылка на http
статусы. И таких проблемных примеров можно придумать
много.
REST скорее концепция, чем формат общения из чего
следует неоднозначность использования статусов.
Разработчики используют статусы как им заблагорассудится. Например,
некоторые API при отсутствии сущности возвращают 404 и текст
ошибки, а некоторые 200 и пустое тело.
Бэкенд разработчику в проекте непросто выбрать статус
для ошибки, а клиентскому разработчику неочевидно какой статус
предназначен для того или иного типа ошибок бизнес-логики.
По-хорошему в проекте придется держать enum для того, чтобы описать
какие ошибки относятся к тому или иному статусу.
Когда бизнес-логика приложения усложняется, начинают делать
как-то так:
HTTP 400 PUT /v1/task/1 { status: 'doing' }Body: { error_code: '12', error_message: 'Задача уже взята другим исполнителем' }
Из-за ограниченности http статусов разработчики начинают
вводить свои коды ошибок для каждого статуса и передавать их в теле
ответа. Другими словами, пользователю API приходиться
писать нечто подобное:
if (status === 200) { // Success} else if (status === 500) { // some code} else if (status === 400) { if (body.error_code === 1) { // some code } else if (body.error_code === 2) { // some code } else { // some code }} else if (status === 404) { // some code} else { // some code}
Из-за этого ветвление клиентского кода начинает стремительно
расти: множество http статусов и множество кодов в самом сообщении.
Для каждого ошибочного http статуса необходимо проверить наличие
кодов ошибок в теле сообщения. От комбинаторного взрыва начинает
конкретно пухнуть башка! А значит обработку ошибок скорее всего
сведут к сообщению типа Произошла ошибка или к молчаливому
некорректному поведению.
Многие системы мониторинга сервисов привязываются к http
статусам, но это не помогает в мониторинге, если статусы
используются для описания ошибок бизнес логики.
Например, у нас резкий всплеск ошибок 429 на графике. Это
началась DDOS атака, или кто-то из разработчиков выбрал неудачный
статус?
Итог: Начать с таким подходом легко и просто и для
простого API это вполне подойдет. Но если логика стала сложнее, то
использование статусов для описания того, что не укладывается в
заданные рамки протокола http приводит к неоднозначности
использования и последующим костылям для работы с ошибками. Или что
еще хуже к формализму, что ведет к неприятному пользовательскому
опыту.
2: На все 200
Есть другой подход, даже более старый, чем REST, а именно: на
все ошибки связанные с бизнес-логикой возвращать 200, а уже в теле
ответа есть информация об ошибке. Например:
Вариант 1:
Success:HTTP 200 GET /v1/user/1Body: { ok: true, data: { name: 'Вася' } }Error:HTTP 200 GET /v1/user/1Body: { ok: false, error: { code: 1, msg: 'Не найден пользователь' } }
Вариант 2:
Success:HTTP 200 GET /v1/user/1Body: { data: { name: 'Вася' }, error: null }Error:HTTP 200 GET /v1/user/1Body: { data: null, error: { code: 1, msg: 'Не найден пользователь' } }
На самом деле формат зависит от вас или от выбранной библиотеки
для реализации коммуникации, например JSON-API.
Звучит здорово, мы теперь отвязались от http статусов и можем
спокойно ввести свои коды ошибок. У нас больше нет проблемы
впихнуть невпихуемое. Выбор нового типа ошибки не вызывает споров,
а сводится просто к введению нового числового номера (например,
последовательно) или строковой константы. Например:
module.exports = { NOT_FOUND: 1, VALIDATION: 2, // .}module.exports = { NOT_FOUND: NOT_AUTHORIZED, VALIDATION: VALIDATION, // .}
Клиентские разработчики просто основываясь на кодах ошибок могут
создать классы/типы ошибок и притом не бояться, что сервер вернет
один и тот же код для разных типов ошибок (из-за бедности http
статусов).
Обработка ошибок становится менее ветвящейся, множество http
статусов превратились в два: 200 и все остальные (ошибки
транспорта).
if (status === 200) { if (body.error) { var error = body.error; if (error.code === 1) { // some code } else if (error.code === 2) { // some code } else { // some code } } else { // Success }} else { // transport erros}
В некоторых случаях, если есть библиотека десериализации данных,
она может взять часть работы на себя. Писать SDK вокруг такого
подхода проще нежели вокруг той или иной имплементации REST, ведь
реализация зависит от того, как это видел автор. Кроме того, теперь
никто не вызовет случайное срабатывание alert в мониторинге из-за
того, что выбрал неудачный код ошибки.
Но неудобства тоже есть:
-
Избыточность полей при передаче данных, т.е. нужно всегда
передавать 2 поля: для данных и для ошибки. Это усложняет чтение
логов и написание документации. -
При использовании средств отладки (Chrome DevTools) или других
подобных инструментов вы не сможете быстро найти ошибочные запросы
бизнес логики, придется обязательно заглянуть в тело ответа (ведь
всегда 200) -
Мониторинг теперь точно будет срабатывать только на ошибки
транспорта, а не бизнес-логики, но для мониторинга логики надо
будет дописывать парсинг тела сообщения.
В некоторых случаях данный подход вырождается в RPC, то есть по
сути вообще отказываются от использования url и шлют все на один
url методом POST, а в теле сообщения передают все параметры. Мне
кажется это не правильным, ведь url это прекрасный именованный
namespace, зачем от этого отказываться, не понятно?! Кроме того,
RPC создает проблемы:
-
нельзя кэшировать по http GET запросы, так как замешали чтение и
запись в один метод POST -
нельзя делать повторы для неудавшихся GET запросов (на backend)
на реверс-прокси (например, nginx) по указанной выше причине -
имеются проблемы с документированием swagger и ApiDoc не
подходят, а удобных аналогов я не нашел
Итог: Для сложной бизнес-логики с большим количеством
типов ошибок такой подход лучше, чем расплывчатый REST, не зря в
проектах c разухабистой бизнес-логикой часто именно такой подход и
используют.
3: Смешанный
Возьмем лучшее от двух миров. Мы выберем один http статус,
например, 400 или 422 для всех ошибок бизнес-логики, а в теле
ответа будем указывать код ошибки или строковую константу.
Например:
Success:
HTTP 200 /v1/user/1Body: { name: 'Вася' }
Error:
HTTP 400 /v1/user/1Body: { error: { code: 1, msg: 'Не найден пользователь' } }
Коды:
-
200 успех
-
400 ошибка бизнес логики
-
остальное ошибки в транспорте
Тело ответа для удачного запроса у нас имеет произвольную
структуру, а вот для ошибки есть четкая схема. Мы избавляемся от
избыточности данных (поле ошибки/данных) благодаря использованию
http статуса в сравнении со вторым вариантом. Клиентский код
упрощается в плане обработки ошибки (в сравнении с первым
вариантом). Также мы снижаем его вложенность за счет использования
отдельного http статуса для ошибок бизнес логики (в сравнении со
вторым вариантом).
if (status === 200) { // Success} else if (status === 400) { if (body.error.code === 1) { // some code } else if (body.error.code === 2) { // some code } else { // some code }} else { // transport erros}
Мы можем расширять объект ошибки для детализации проблемы, если
хотим. С мониторингом все как во втором варианте, дописывать
парсинг придется, но и риска стрельбы некорректными alert нету. Для
документирования можем спокойно использовать Swagger и ApiDoc. При
этом сохраняется удобство использования инструментов разработчика,
таких как Chrome DevTools, Postman, Talend API.
Итог: Использую данный подход уже в нескольких проектах,
где множество типов ошибок и все крайне довольны, как клиентские
разработчики, так и бэкендеры. Внедрение новой ошибки не вызывает
споров, проблем и противоречий. Данный подход объединяет
преимущества первого и второго варианта, при этом код более
читабельный и структурированный.
Самое главное какой бы формат ошибок вы бы не выбрали лучше
обговорить его заранее и следовать ему. Если эту вещь пустить на
самотек, то очень скоро обработка ошибок в проекте станет
невыносимо сложной для всех.
P.S. Иногда ошибки любят передавать
массивом
{ error: [{ code: 1, msg: 'Не найден пользователь' }] }
Но это актуально в основном в двух случаях:
-
Когда наш API выступает в роли сервиса без фронтенда (нет
сайта/приложения). Например, сервис платежей. -
Когда в API есть url для загрузки какого-нибудь длинного отчета
в котором может быть ошибка в каждой строке/колонке. И тогда для
пользователя удобнее, чтобы ошибки в приложении сразу показывались
все, а не по одной.
В противном случае нет особого смысла закладываться сразу на
массив ошибок, потому что базовая валидация данных должна
происходить на клиенте, зато код упрощается как на сервере, так и
на клиенте. А user-experience хакеров, лезущих напрямую в наше API,
не должен нас волновать?HTTP