
Расчеты
и проверка достоверности полученных
оценок коэффициентов регрессии не
являются самоцелью, это лишь необходимый
промежуточный этап. Основное – это
использование модели для анализа и
прогноза поведения изучаемого
экономического явления. Прогноз
осуществляется подстановкой значения
фактора х
в полученную формулу регрессии.
Используем
полученное в примере 2.1 уравнение
регрессии для прогноза объема
товарооборота. Пусть намечается открытие
магазина с численностью работников
х=140
чел., тогда достаточно обоснованный
объем товарооборота следует установить
по уравнению ŷ(х)=
–0,974 + 0,01924140=1,72
млрд. руб.
Доверительный
интервал для прогностического значения
у(х)=
0+1хопределяется
по формуле
 ,
,
(5.2)
где
tp
– критическая граница распределения
Стьюдента с n
– 2 степенями свободы, соответствующая
уровню значимости р.
Для получения доверительного интервала
воспользуемся выражением (5.2).
Выберем
уровень значимости 5%. Число степеней
свободы у нас 8 – 2 = 6, тогда по таблице
распределения Стьюдента (приложение
1) находим

t0.05(6)=2,447.=
0,008=0,089,
![]()
следовательно, с
вероятностью 95% истинные значения
объемов товарооборота будут лежать в
пределах
1,72
– 2,4470,048<y(x)<1,72+2,4470,048,
или 1,60<y(x)<1,84.
-
Практический
блок
Пример.
Построить
модель связи между указанными факторами,
проверить её адекватность, осуществить
точечный и интервальный прогноз методом
экстраполяции.
1.
Построить
диаграмму рассеяния в EXCELи
сделать предварительное заключение о
наличии связи.
Таблица
5.6Диаграмма 5.1
|
x |
Y |
|
2,1 |
29,5 |
|
2,9 |
34,2 |
|
3,3 |
30,6 |
|
3,8 |
35,2 |
|
4,2 |
40,7 |
|
3,9 |
44,5 |
|
5,0 |
47,2 |
|
4,9 |
55,2 |
|
6,3 |
51,8 |
|
5,8 |
56,7 |

Вывод:
Из диаграммы 5.1 видно, что связь между
факторами x
и y
прямая
сильная линейная связь.
2.
Рассчитайте
линейный коэффициент корреляции.
Используя t-критерий
Стьюдента, проверьте значимость
коэффициента корреляции. Сделайте вывод
о тесноте связи между факторами х
и у.
Таблица
5.7
|
№ |
|
|
|
|
xy |
|
|
|
|
1 |
2,1 |
29,5 |
4,41 |
870,25 |
61,95 |
27,91 |
1,59 |
0,054 |
|
2 |
2,9 |
34,2 |
8,41 |
1169,64 |
99,18 |
33,46 |
0,74 |
0,022 |
|
3 |
3,3 |
30,6 |
10,89 |
936,36 |
100,98 |
36,23 |
-5,63 |
0,184 |
|
4 |
3,8 |
35,2 |
14,44 |
1239,04 |
133,76 |
39,69 |
-4,49 |
0,128 |
|
5 |
4,2 |
40,7 |
17,64 |
1656,49 |
170,94 |
42,47 |
-1,77 |
0,043 |
|
6 |
3,9 |
44,5 |
15,21 |
1980,25 |
173,55 |
40,39 |
4,11 |
0,092 |
|
7 |
5,0 |
47,2 |
25 |
2227,84 |
236 |
48,01 |
-0,81 |
0,017 |
|
8 |
4,9 |
55,2 |
24,01 |
3047,04 |
270,48 |
47,32 |
7,88 |
0,143 |
|
9 |
6,3 |
51,8 |
39,69 |
2683,24 |
326,34 |
57,02 |
-5,22 |
0,101 |
|
10 |
5,8 |
56,7 |
33,64 |
3214,89 |
328,86 |
53,55 |
3,15 |
0,056 |
|
ИТОГО: |
42,2 |
426 |
193,34 |
19025,04 |
1902,04 |
426 |
0,840 |
|
|
Среднее |
4,22 |
42,56 |
19,334 |
1902,504 |
190,204 |
2.1.Проверим
тесноту связи между факторами:
![]() ;
;![]()
Вывод:
связь сильная.
2.2.Проверим
статистическую значимость по критерию
Стьюдента:
1)Критерий
Стьюдента: tвыб<=tкр
2)Но:
r=0
tкр=2,31
tвыб=rвыб*![]()
Вывод:
таким образом поскольку tвыб=5,84<tкр=2,31,
то с доверительной вероятностью
90%
нулевая гипотеза отвергается, это
указывает на наличие сильной
линейной связи.
3.
Полагая,
что связь между факторами х
и у
может быть описана линейной функцией,
используя процедуру метода наименьших
квадратов, запишите систему нормальных
уравнений относительно коэффициентов
линейного уравнения регрессии. Любым
способом рассчитайте эти коэффициенты.

Последовательно
подставляя в уравнение регрессии
![]() из графы (2) табл.5.7, рассчитаем значения
из графы (2) табл.5.7, рассчитаем значения
и заполним графу (7) табл.5.7.
4.
Для
полученной модели связи между факторами
Х и У рассчитайте среднюю ошибку
аппроксимации. Сделайте предварительное
заключение приемлемости полученной
модели.
![]()
Для
расчета заполним 8-ую и 9-ую графу табл.5.7.
![]() <Екр=12%
<Екр=12%
Вывод:
модель следует признать удовлетворительной.
5.
Проверьте значимость коэффициента
уравнения регрессии a1
на основе t-критерия
Стьюдента.
Решение:
Таблица 5.8
|
№ |
|
|
|
|
|
|
|
1 |
2,1 |
29,5 |
27,91 |
2,5281 |
214,623 |
170,5636 |
|
2 |
2,9 |
34,2 |
33,46 |
0,5476 |
82,81 |
69,8896 |
|
3 |
3,3 |
30,6 |
36,23 |
31,6969 |
40,069 |
143,0416 |
|
4 |
3,8 |
35,2 |
39,69 |
20,1601 |
8,237 |
54,1696 |
|
5 |
4,2 |
40,7 |
42,47 |
3,1329 |
0,008 |
3,4596 |
|
6 |
3,9 |
44,5 |
40,39 |
16,8921 |
4,709 |
3,7636 |
|
7 |
5 |
47,2 |
48,01 |
0,6561 |
29,703 |
21,5296 |
|
8 |
4,9 |
55,2 |
47,32 |
62,0944 |
22,658 |
159,7696 |
|
9 |
6,3 |
51,8 |
57,02 |
27,2484 |
209,092 |
85,3776 |
|
10 |
5,8 |
56,7 |
53,55 |
9,9225 |
120,78 |
199,9396 |
|
ИТОГО: |
42,2 |
425,6 |
426,1 |
174,8791 |
732,687 |
911,504 |
|
Среднее |
4,22 |
42,56 |
Статистическая
проверка:

![]() Вывод:
Вывод:
С доверительной вероятностью 90%
коэффициент a1—
статистически значим, т.е. нулевая
гипотеза отвергается.
6.
Проверьте адекватность модели (уравнения
регрессии) в целом на основе F-критерия
Фишера-Снедекора.
Решение:
Процедура
статистической проверки:
![]() :модель
:модель
не адекватна

Вывод:
т.к. Fвыб.>Fкр.,
то с доверительной вероятностью 95%
нулевая гипотеза отвергается (т.е.
принимается альтернативная). Изучаемая
модель адекватна и может быть использована
для прогнозирования и принятия
управленческих решений.
7.
Рассчитайте эмпирический коэффициент
детерминации.
Решение:
 (таб.
(таб.
3)
![]() -показывает
-показывает
долю вариации.
Вывод:
т.е. 80% вариации объясняется фактором,
включенным в модель, а 20% не включенными
в модель факторами.
8.
Рассчитайте корреляционное отношение.
Сравните полученное значение с величиной
линейного коэффициента корреляции.
Решение:

![]()
Эмпирическое
корреляционное отношение указывает на
тесноту связи между двумя факторами
для любой связи, если связь линейная,
то
![]() ,
,
т.е. коэффициент корреляции совпадает
с коэффициентом детерминации.
9.
Выполните точечный прогноз для
![]()
.
Решение:

10-12.
Рассчитайте доверительные интервалы
для уравнения регрессии и для
результирующего признака
![]()
при доверительной вероятности
![]() =90%.
=90%.
Изобразите в одной системе координат:
а) исходные данные,
б) линию регрессии,
в) точечный прогноз,
г) 90% доверительные
интервалы.
Сформулируйте
общий вывод относительно полученной
модели.
Решение:
![]() -математическое
-математическое
ожидание среднего.
Для выполнения
интервального прогноза рассматриваем
две области.
-
для
y
из области изменения фактора x
доверительные границы для линейного
уравнения регрессии рассчитывается
по формуле:

-
для
прогнозного значения
 доверительный
доверительный
интервал для
 рассчитывается
рассчитывается
по формуле:

Исходные
данные:
-
n=10
-
t=2,31(таб.)
-

4)![]()
5)![]() :
:
27,91 42,56 57,02 66,72
6)![]() 19,334-4,222)=1,53.
19,334-4,222)=1,53.
Таблица
5.9
|
№ |
|
|
|
|
|
|
|
|
|
|
|
|
1 |
2,1 |
-2,12 |
4,49 |
3,03 |
1,74 |
2,31 |
4,68 |
18,81 |
27,91 |
9,10 |
46,72 |
|
2 |
4,22 |
0,00 |
0,00 |
0,1 |
0,32 |
2,31 |
4,68 |
3,46 |
42,56 |
39,10 |
46,02 |
|
3 |
6,3 |
2,08 |
4,33 |
2,93 |
1,71 |
2,31 |
4,68 |
18,49 |
57,02 |
38,53 |
75,51 |
|
4 |
7,7 |
3,48 |
12,11 |
9,02 |
3 |
2,31 |
4,68 |
32,43 |
66,72 |
34,29 |
99,15 |

Вывод: поскольку
90% точек наблюдения попало в 90%
доверительный интервал, данная модель
и ее доверительные границы могут
использоваться для прогнозирования с
90% доверительной вероятностью.
Соседние файлы в папке эконометрика-раздача
- #
09.05.201520.48 Кб17Книга1.xls
- #
- #
- #
- #
- #
- #
- #
- #
- #
Расчет доверительных интервалов и прогнозов для линейного уравнения регрессии
Как правило, в линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров.Показатели корреляционной связи, вычисленные по ограниченной совокупности (по выборке), являются лишь оценками той или иной статистической закономерности, поскольку в любом параметре сохраняется элемент не полностью погасившейся случайности, присущей индивидуальным значениям признаков. Поэтому необходима статистическая оценка степени точности и надежности параметров корреляции. Под надежностью здесь понимается вероятность того, что значение проверяемого параметра не равно нулю, не включает в себя величины противоположных знаков.
Вероятностная оценка параметров корреляции производится по общим правилам проверки статистических гипотез, разработанным математической статистикой, в частности путем сравнения оцениваемой величины со средней случайной ошибкой оценки. Для коэффициента парной регрессии b средняя ошибка оценки вычисляется как:
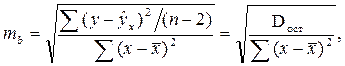
где Dост – остаточная дисперсия на одну степень свободы.
Для нашего примера величина стандартной ошибки коэффициента регрессии составила:
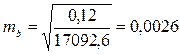 .
.
Для оценки того, насколько точные значения показателей могут отличаться от рассчитанных, осуществляется построение доверительных интервалов. Они определяют пределы, в которых лежат точные значения определяемых показателей с заданной степенью точности, соответствующей заданному уровню значимости α (α – вероятность отвергнуть правильную гипотезу при условии, что она верна, обычно принимается равной 0,05 или 0,01).
Для оценки статистической значимости коэффициента линейной регрессии и линейного коэффициента парной корреляции, а также для расчета доверительных интервалов b, применяется t – критерий Стьюдента.
Для оценки существенности коэффициента регрессии его величина сравнивается с его стандартной ошибкой, т.е. определяется фактическое значение t-критерия Стьюдента: 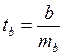 , которое затем сравнивается с табличным значением при определенном уровне значимости а и числе степеней свободы (n — 2).
, которое затем сравнивается с табличным значением при определенном уровне значимости а и числе степеней свободы (n — 2).
В рассматриваемом примере фактическое значение t-критерия для коэффициента регрессии составило:
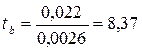 .
.
Этот же результат получим, извлекая квадратный корень из найденного F-критерия, т.е.
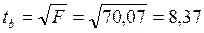 .
.
Действительно, справедливо равенство 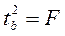 .
.
При 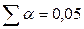 (для двустороннего критерия) и числе степеней свободы 13 табличное значение tb=2,16. Так как фактическое значение t‑критерия превышает табличное, то, следовательно, гипотезу о несущественности коэффициента регрессии можно отклонить.
(для двустороннего критерия) и числе степеней свободы 13 табличное значение tb=2,16. Так как фактическое значение t‑критерия превышает табличное, то, следовательно, гипотезу о несущественности коэффициента регрессии можно отклонить.
Для расчета доверительных интервалов для параметров a и b уравнения линейной регрессии определяем предельную ошибку ∆ для каждого показателя:
Формулы для расчета доверительных интервалов имеют вид:
Если границы интервала имеют разные знаки, т.е. в эти границы попадает ноль, то оцениваемый параметр принимается нулевым.
Доверительный интервал для коэффициента регрессии определяется как 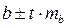 . Для коэффициента регрессии b в примере 95%-ные границы составят:
. Для коэффициента регрессии b в примере 95%-ные границы составят:
0,022 ± 2,16·0,0026 = 0,022 ± 0,0057, т.е.
Поскольку коэффициент регрессии в эконометрических исследованиях имеет четкую экономическую интерпретацию, то доверительные границы интервала для коэффициента регрессии не должны содержать противоречивых результатов, например, -10 ≤ b ≤ 40. Такого рода запись указывает, что истинное значение коэффициента регрессии одновременно содержит положительные и отрицательные величины и даже ноль, чего не может быть.
Стандартная ошибка параметра а определяется по формуле:
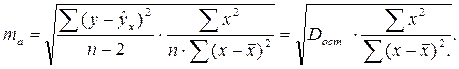
Процедура оценивания существенности данного параметра не отличается от рассмотренной выше для коэффициента регрессии; вычисляется t-критерий: 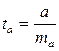 , его величина сравнивается с табличным значением при df = n — 2 степенях свободы. В нашем примере ma составила 0,032.
, его величина сравнивается с табличным значением при df = n — 2 степенях свободы. В нашем примере ma составила 0,032.
Значимость линейного коэффициента корреляции проверяется на основе величины ошибки коэффициента корреляции mr:
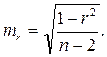
Фактическое значение t-критерия Стьюдента определяется как
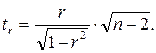
Данная формула свидетельствует, что в парной линейной регрессии 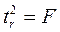 , ибо, как уже указывалось,
, ибо, как уже указывалось, 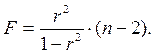 Кроме того,
Кроме того, 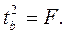 Следовательно,
Следовательно, 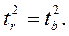
Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
В рассматриваемом примере tr совпало с tb. Величина tr =8,37 значительно превышает табличное значение 2,16 при а=0,05. Следовательно, коэффициент корреляции существенно отличен от нуля и зависимость является достоверной.
Прогноз, полученный подстановкой в уравнение регрессии ожидаемого значения фактора, называют точечным прогнозом. Вероятность точной реализации такого прогноза крайне мала. Необходимо сопроводить его значением средней ошибки прогноза или доверительным интервалом прогноза с достаточно большой вероятностью.
Точечный прогноз заключается в получении прогнозного значения yp, которое определяется путем подстановки в уравнение регрессии
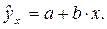 соответствующего прогнозного значения xp:
соответствующего прогнозного значения xp:
Интервальный прогноз заключается в построении доверительного интервала прогноза, т.е. верхней и нижней границы ypmin, ypmax интервала, содержащего точную величину для прогнозного значения
(ypmin 2 – индекс детерминации;
n – число наблюдений;
m – число параметров при переменных х.
Величина m характеризует число степеней свободы для факторной суммы квадратов, а (n – m — 1) – число степеней свободы для остаточной суммы квадратов.
Для степенной функции 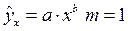 и формула F – критерия примет тот же вид, что и при линейной зависимости:
и формула F – критерия примет тот же вид, что и при линейной зависимости:
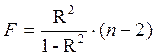
Для параболы второй степени y=a + b·x + c·x 2 + ε m=2 и 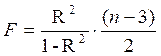 .
.
Для оценки качества построенной модели используется также средняя ошибка аппроксимации. Фактические значения результативного признака отличаются от теоретических, рассчитанных по уравнению регрессии, т.е. у и . Чем меньше это отличие, тем ближе теоретические значения подходят к эмпирическим данным, лучше качество модели. Величина отклонений фактических и расчетных значений результативного признака (у— ) по каждому наблюдению представляет собой ошибку аппроксимации. Их число соответствует объему совокупности. В отдельных случаях ошибка аппроксимации может оказаться равной нулю. Для сравнения берутся величины отклонений, выраженные в процентах к фактическим значениям. Так, если для первого наблюдения у=20, а для второго у=50, ошибка аппроксимации составит 25% для первого наблюдения и 20% — для второго.
Поскольку (у— ) может быть как величиной положительной, так и отрицательной, то ошибки аппроксимации для каждого наблюдения принято определять в процентах по модулю.
Чтобы иметь общее суждение о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации как среднюю арифметическую простую:
.
Для нашего примера представим расчет средней ошибки аппроксимации в таблице 4.
Пример нахождения доверительных интервалов коэффициентов регрессии
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Постройте уравнение зависимости экспорта нефти от цены на нефть.
3. Рассчитайте среднюю ошибку аппроксимации и коэффициент детерминации. Оценить статистическую значимость параметров регрессии и уравнения в целом.
4. Оцените полученные результаты, выводы оформите в аналитической записке.
Таблица 5
Цена нефти марки Urals (Россия), долл/барр.
Экспорт нефти и нефтепродуктов, млн.т.
Решение:
Уравнение имеет вид y = ax + b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y- y ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 119 | 298.12 | 14161 | 88875.53 | 35476.28 | 219.63 | 232120.8 | 6160.56 | 24362.01 |
| 203 | 481.03 | 41209 | 231389.86 | 97649.09 | 521.16 | 89328.76 | 1610.26 | 5196.01 |
| 281 | 539.12 | 78961 | 290650.37 | 151492.72 | 801.15 | 57979.42 | 68658.51 | 35.01 |
| 305 | 653.57 | 93025 | 427153.74 | 199338.85 | 887.3 | 15961.59 | 54628.94 | 895.01 |
| 381 | 987.66 | 145161 | 975472.28 | 376298.46 | 1160.11 | 43160.41 | 29738.57 | 11218.34 |
| 363 | 1252.85 | 131769 | 1569633.12 | 454784.55 | 1095.5 | 223673.03 | 24760.35 | 7729.34 |
| 389 | 1276.88 | 151321 | 1630422.53 | 496706.32 | 1188.83 | 246980.01 | 7753.57 | 12977.01 |
| 387 | 1396.70 | 149769 | 1950770.89 | 540522.9 | 1181.65 | 380430.93 | 46248.04 | 12525.34 |
| 315 | 952.03 | 99225 | 906361.12 | 299889.45 | 923.19 | 29625.58 | 831.49 | 1593.34 |
| 217 | 619.96 | 47089 | 384350.4 | 134531.32 | 571.41 | 25583.74 | 2356.85 | 3373.67 |
| 149 | 384.40 | 22201 | 147763.36 | 57275.6 | 327.32 | 156427.5 | 3258.23 | 15897.01 |
| 192 | 516.59 | 36864 | 266865.23 | 99185.28 | 481.67 | 69336.98 | 1219.24 | 6902.84 |
| 3301 | 9358.91 | 1010755 | 8869708.45 | 2943150.82 | 9358.91 | 1570608.75 | 247224.62 | 102704.92 |
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.4906
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 1
(-587.75;179.86)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (7.32>1.812)
Статистическая значимость коэффициента регрессии b не подтверждается (1.46 Fkp, то коэффициент детерминации статистически значим.
Доверительные интервалы для зависимой переменной
Уравнение тренда имеет вид y = at 2 + bt + c
1. Находим параметры уравнения методом наименьших квадратов.
Система уравнений
Для наших данных система уравнений имеет вид (см. таблицу).
Получаем a0 = -11.37, a1 = 88.47, a2 = 2151.09
Уравнение тренда: y = -11.37t 2 +88.47t+2151.09
Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве тренда
Средние значения
т.е. в 87.35 % случаев влияет на изменение данных. Другими словами — точность подбора уравнения тренда — высокая
| t | y | t 2 | y 2 | x ∙ y | y(t) | (y-y cp ) 2 | (y-y(t)) 2 | (t-t p ) 2 | (y-y(t)) : y | t 3 | t 4 | t 2 y |
| 1 | 2225.3 | 1 | 4951960.09 | 2225.3 | 2228.19 | 65.6099 | 8.352 | 16 | 6431.117 | 1 | 1 | 2225.3 |
| 2 | 2254.9 | 4 | 5084574.01 | 4509.8 | 2282.55 | 462.25 | 764.5225 | 9 | 62347.985 | 8 | 16 | 9019.6 |
| 3 | 2332.3 | 9 | 5439623.29 | 6996.9 | 2314.17 | 9781.21 | 328.6969 | 4 | 42284.599 | 27 | 81 | 20990.7 |
| 4 | 2365.8 | 16 | 5597009.64 | 9463.2 | 2323.05 | 17529.76 | 1827.5625 | 1 | 101137.95 | 64 | 256 | 37852.8 |
| 5 | 2295.4 | 25 | 5268861.16 | 11477 | 2309.19 | 3844 | 190.1641 | 0 | 31653.566 | 125 | 625 | 57385 |
| 6 | 2303.9 | 36 | 5307955.21 | 13823.4 | 2272.59 | 4970.25 | 980.3161 | 1 | 72135.109 | 216 | 1296 | 82940.4 |
| 7 | 2166.7 | 49 | 4694588.89 | 15166.9 | 2213.25 | 4448.89 | 2166.9025 | 4 | 100859.885 | 343 | 2401 | 106168.3 |
| 8 | 2080.4 | 64 | 4328064.16 | 16643.2 | 2131.17 | 23409 | 2577.5929 | 9 | 105621.908 | 512 | 4096 | 133145.6 |
| 9 | 2075.9 | 81 | 4309360.81 | 18683.1 | 2026.35 | 24806.25 | 2455.2025 | 16 | 102860.845 | 729 | 6561 | 168147.9 |
| 45 | 20100.6 | 285 | 44981997.26 | 98988.8 | 20100.51 | 89317.2199 | 11299.312 | 60 | 625332.964 | 4050 | 30666 | 1235751.2 |
2. Анализ точности определения оценок параметров уравнения тренда.
Анализ точности определения оценок параметров уравнения тренда
S a = 4.8518
Доверительные интервалы для зависимой переменной
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (7;0.05) = 1.895
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и t = 6
2151.09 + 88.47*6 + -11.37*62 — 1.895*39.911 ; 2151.09 + 88.47*6 + -11.37*62 — 1.895*39.911
(-55.3814;95.8814)
Интервальный прогноз.
Определим среднеквадратическую ошибку прогнозируемого показателя.
где L — период упреждения; уn+L — точечный прогноз по модели на (n + L)-й момент времени; n — количество наблюдений во временном ряду; Sy — стандартная ошибка прогнозируемого показателя; Tтабл — табличное значение критерия Стьюдента для уровня значимости а и для числа степеней свободы, равного n — 2.
Точечный прогноз, t = 10: y(10) = -11.37*10 2 + 88.47* + 2151.09 = 1898.79
K1 = 247.4924
1898.79 — 247.4924 = 1651.2976 ; 1898.79 + 247.4924 = 2146.2824
t = 10: (1651.2976;2146.2824)
Точечный прогноз, t = 11: y(11) = -11.37*11 2 + 88.47* + 2151.09 = 1748.49
K2 = 261.9213
1748.49 — 261.9213 = 1486.5687 ; 1748.49 + 261.9213 = 2010.4113
t = 11: (1486.5687;2010.4113)
Точечный прогноз, t = 12: y(12) = -11.37*12 2 + 88.47* + 2151.09 = 1575.45
K3 = 278.0099
1575.45 — 278.0099 = 1297.4401 ; 1575.45 + 278.0099 = 1853.4599
t = 12: (1297.4401;1853.4599)
Точечный прогноз, t = 13: y(13) = -11.37*13 2 + 88.47* + 2151.09 = 1379.67
K4 = 295.4871
1379.67 — 295.4871 = 1084.1829 ; 1379.67 + 295.4871 = 1675.1571
t = 13: (1084.1829;1675.1571)
Точечный прогноз, t = 14: y(14) = -11.37*14 2 + 88.47* + 2151.09 = 1161.15
K5 = 314.1213
1161.15 — 314.1213 = 847.0287 ; 1161.15 + 314.1213 = 1475.2713
t = 14: (847.0287;1475.2713)
3. Проверка гипотез относительно коэффициентов линейного уравнения тренда.
1) t-статистика. Критерий Стьюдента.
Статистическая значимость коэффициента уравнения подтверждается
Статистическая значимость коэффициента тренда подтверждается
Доверительный интервал для коэффициентов уравнения тренда
Определим доверительные интервалы коэффициентов тренда, которые с надежность 95% будут следующими (tтабл=1.895):
(a — tтабл·Sa; a + tтабл·Sa)
(-20.5642;-2.1758)
(b — t табл·Sb; b + tтаблS·b)
(36.7313;140.2087)
2) F-статистика. Критерий Фишера.
Fkp = 5.32
Поскольку F > Fkp, то коэффициент детерминации статистически значим
4. Тест Дарбина-Уотсона на наличие автокорреляции остатков для временного ряда.
| y | y(x) | e i = y-y(x) | e 2 | (e i — e i-1 ) 2 |
| 2225.3 | 2228.19 | -2.89 | 8.3521 | 0 |
| 2254.9 | 2282.55 | -27.65 | 764.5225 | 613.0576 |
| 2332.3 | 2314.17 | 18.13 | 328.6969 | 2095.8084 |
| 2365.8 | 2323.05 | 42.75 | 1827.5625 | 606.1444 |
| 2295.4 | 2309.19 | -13.79 | 190.1641 | 3196.7716 |
| 2303.9 | 2272.59 | 31.31 | 980.3161 | 2034.01 |
| 2166.7 | 2213.25 | -46.55 | 2166.9025 | 6062.1796 |
| 2080.4 | 2131.17 | -50.77 | 2577.5929 | 17.8084 |
| 2075.9 | 2026.35 | 49.55 | 2455.2025 | 10064.1024 |
| 11299.3121 | 24689.8824 |
Критические значения d1 и d2 определяются на основе специальных таблиц для требуемого уровня значимости a, числа наблюдений n и количества объясняющих переменных m.
Не обращаясь к таблицам, можно пользоваться приблизительным правилом и считать, что автокорреляция остатков отсутствует, если 1.5
Задача №3. Расчёт параметров регрессии и корреляции с помощью Excel
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости .
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.
Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;
Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;
Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу , а затем на комбинацию клавиш + + .
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R 2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов |
Остаточная сумма квадратов
Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:
Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
3. Коэффициент детерминации означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции: .
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:
Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.
Рисунок 5 Расчёт средних значений функции и аргумент
Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
• Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.
Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.
Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.
Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:
Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:
Качество построенной модели оценивается как хорошее, так как не превышает 8 – 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера:
Поскольку при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:
.
для числа степеней свободы
На рисунке 7 имеются фактические значения t-статистики:
t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ:
где – случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.
II способ:
Фактические значения t-статистики превосходят табличные значения:
Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как
Для параметра a 95%-ные границы как показано на рисунке 7 составили:
Доверительный интервал для коэффициента регрессии определяется как
Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:
Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:
Тогда прогнозное значение прожиточного минимума составит:
Ошибку прогноза рассчитаем по формуле:
где
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.
Рисунок 10 Расчёт дисперсии
Получили значение дисперсии
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.
Доверительные интервалы прогноза индивидуальных значений у при с вероятностью 0,95 определяются выражением:
Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.
http://math.semestr.ru/corel/prim1.php
http://ecson.ru/economics/econometrics/zadacha-3.raschyot-parametrov-regressii-i-korrelyatsii-s-pomoschju-excel.html
Эконометрика
Вариант 1
Задание 1. Модель парной линейной регрессии.
Имеются данные о размере среднемесячных доходов в разных группах семей
|
Номер группы |
Среднедушевой денежный доход в месяц, руб., X |
Доля оплаты труда в структуре доходов семьи, %, Y |
|
1 |
79,8 |
64,2 |
|
2 |
152,1 |
66,1 |
|
3 |
199,3 |
69,0 |
|
4 |
240,8 |
70,6 |
|
5 |
282,4 |
72,4 |
|
6 |
301,8 |
74,3 |
|
7 |
385,3 |
76,0 |
|
8 |
457,8 |
77,1 |
|
9 |
577,4 |
78,4 |
Задания:
1. Рассчитать линейный коэффициент парной корреляции, оценить его статистическую значимость и построить для него доверительный интервал с уровнем значимости a =0,05. Сделать выводы
2. Построить линейное уравнение парной регрессии Y на X и оценить статистическую значимость параметров регрессии. Сделать рисунок.
3. Оценить качество уравнения регрессии при помощи коэффициента детерминации. Сделать выводы. Проверить качество уравнения регрессии при помощи F-критерия Фишера.
4. Выполнить прогноз доли оплаты труда структуре доходов семьи Y при прогнозном значении среднедушевого денежного дохода X, составляющем 111% от среднего уровня. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал для уровня значимости a =0,05. Сделать выводы.
Решение: Построим поле корреляции зависимости доли оплаты труда в структуре доходов семьи от среднедушевого денежного дохода в месяц.
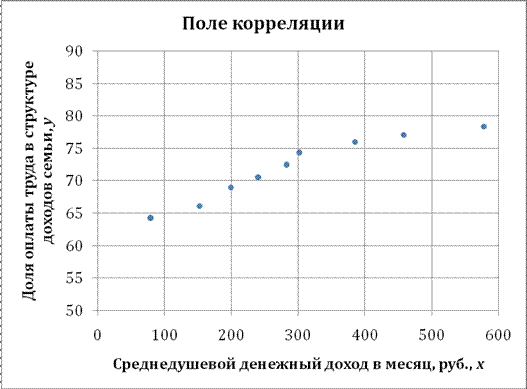
Точки на построенном графике размещаются вблизи кривой, напоминающей по форме Прямую, поэтому можно предположить, что между указанными величинами существует Линейная зависимость вида ![]() .
.
Для расчета линейного коэффициента парной корреляции и параметров линейной регрессии составим вспомогательную таблицу.
|
№ п/п |
X |
Y |
X×Y |
X2 |
Y2 |
|
1 |
79,8 |
64,2 |
5123,16 |
6368,04 |
4121,64 |
|
2 |
152,1 |
66,1 |
10053,81 |
23134,41 |
4369,21 |
|
3 |
199,3 |
69,0 |
13751,70 |
39720,49 |
4761,00 |
|
4 |
240,8 |
70,6 |
17000,48 |
57984,64 |
4984,36 |
|
5 |
282,4 |
72,4 |
20445,76 |
79749,76 |
5241,76 |
|
6 |
301,8 |
74,3 |
22423,74 |
91083,24 |
5520,49 |
|
7 |
385,3 |
76,0 |
29282,80 |
148456,09 |
5776,00 |
|
8 |
457,8 |
77,1 |
35296,38 |
209580,84 |
5944,41 |
|
9 |
577,4 |
78,4 |
45268,16 |
333390,76 |
6146,56 |
|
S |
2676,7 |
648,1 |
198645,99 |
989468,27 |
46865,43 |
|
Среднее |
297,41 |
72,01 |
22071,78 |
109940,92 |
5207,27 |
Вычислим коэффициент корреляции. Используем следующую формулу:

![]() = 0,9568.
= 0,9568.
Можно сказать, что между рассматриваемыми признаками существует Прямая тесная Корреляционная связь.
Среднюю ошибку коэффициента корреляции определим по формуле:
![]() = 0,032.
= 0,032.
Найдем табличное значение TТабл по таблице распределения Стьюдента для
a = 0,05 и числе степеней свободы K = N – M – 1 = 9 – 1 – 1 = 7.
TТабл(0,05; 7) = 2,36.
Запишем доверительный интервал для коэффициента корреляции.
![]()
![]()
Доверительный интервал не включает число 0, поэтому при заданном уровне значимости коэффициент корреляции является статистически значимым.
Вычислим параметры уравнения регрессии.
![]() = 0,03.
= 0,03.
![]() = 72,01 – 0,03×297,41 = 63,09.
= 72,01 – 0,03×297,41 = 63,09.
Получим следующее уравнение: ![]() .
.
Для проверки статистической значимости (существенности) линейного коэффициента парной корреляции рассчитаем T-критерий Стьюдента по формуле:
 = 23,04.
= 23,04.
Фактическое значение по абсолютной величине больше табличного, что свидетельствует о значимости линейного коэффициента корреляции и существенности связи между рассматриваемыми признаками.
Проверим значимость оценок теоретических коэффициентов регрессии с помощью t-статистики Стьюдента и сделаем соответствующие выводы о значимости этих оценок.
Для определения статистической значимости коэффициентов A и B найдем T-статистики Стьюдента:
Рассчитаем по полученному уравнению теоретические значения![]() . Составим вспомогательную таблицу.
. Составим вспомогательную таблицу.
|
№ п/п |
X |
Y |
|
|
|
|
1 |
79,8 |
64,2 |
65,48 |
1,6384 |
47354,1 |
|
2 |
152,1 |
66,1 |
67,65 |
2,4025 |
21115,0 |
|
3 |
199,3 |
69,0 |
69,07 |
0,0049 |
9625,6 |
|
4 |
240,8 |
70,6 |
70,31 |
0,0841 |
3204,7 |
|
5 |
282,4 |
72,4 |
71,56 |
0,7056 |
225,3 |
|
6 |
301,8 |
74,3 |
72,14 |
4,6656 |
19,3 |
|
7 |
385,3 |
76,0 |
74,65 |
1,8225 |
7724,7 |
|
8 |
457,8 |
77,1 |
76,82 |
0,0784 |
25725,0 |
|
9 |
577,4 |
78,4 |
80,41 |
4,0401 |
78394,4 |
|
S |
2676,7 |
648,1 |
648,09 |
15,4421 |
193388,1 |
Вычислим стандартные ошибки коэффициентов уравнения.
 = 1,2.
= 1,2.
 = 0,003.
= 0,003.
Вычислим T-статистики.
![]()
![]()
Сравнение расчетных и табличных величин критерия Стьюдента показывает, что ![]() и
и ![]() , т. е. оценки A и B теоретических коэффициентов регрессии статистически значимы.
, т. е. оценки A и B теоретических коэффициентов регрессии статистически значимы.
Сделаем рисунок.

Рассчитаем коэффициент детерминации: ![]() = 0,95682= 0,915 = 91,5%.
= 0,95682= 0,915 = 91,5%.
Таким образом, вариация результата Y на 91,5% объясняется вариацией фактора X.
Оценку значимости уравнения регрессии проведем с помощью F-критерия Фишера:
 = 75,81.
= 75,81.
Найдем табличное значение Fтабл по таблице критических точек Фишера для
a = 0,05; K1 = M = 1 (число факторов), K2 = N – M – 1 = 9 – 1 – 1 = 7.
Fтабл(0,05; 1; 7) = 5,59.
Поскольку F > FТабл, уравнение регрессии с вероятностью 0,95 в целом Является статистически значимым.
Выполним прогноз доли оплаты труда структуре доходов семьи y при прогнозном значении среднедушевого денежного дохода x, составляющем 111% от среднего уровня.
XP = 297,41 × 1,11 = 330,1.
Вычислим прогнозное значение Yp с помощью уравнения регрессии.
![]() » 73%.
» 73%.
Доверительный интервал прогноза имеет вид
(УP – Tкр×My, УP + Tкр×My),
Где  , M = 2 – число параметров уравнения.
, M = 2 – число параметров уравнения.
 = 1,695 » 1,7.
= 1,695 » 1,7.
Запишем доверительный интервал прогноза:
![]() Þ
Þ ![]()
Данный прогноз является надежным, поскольку доверительный интервал не включает число 0, точность прогноза составляет 4.
Задание 2. Модель парной нелинейной регрессии.
По территориям Центрального района известны данные за 1995 г.
|
Район |
Прожиточный минимум в среднем на одного пенсионера в месяц, тыс. руб., X |
Средний размер назначенных ежемесячных пенсий, тыс. руб., Y |
|
Брянская обл. |
178 |
240 |
|
Владимирская обл. |
202 |
226 |
|
Ивановская обл. |
197 |
221 |
|
Калужская обл. |
201 |
226 |
|
Костромская обл. |
189 |
220 |
|
Орловская обл. |
166 |
232 |
|
Рязанская обл. |
199 |
215 |
|
Смоленская обл. |
180 |
220 |
|
Тверская обл. |
181 |
222 |
|
Тульская обл. |
186 |
231 |
|
Ярославская обл. |
250 |
229 |
Задания:
1. Построить поле корреляции и сформулируйте гипотезу о форме связи. Рассчитать параметры уравнений полулогарифмической (![]() ) и степенной (
) и степенной (![]() ) парной регрессии. Сделать рисунки.
) парной регрессии. Сделать рисунки.
2. Дать с помощью среднего коэффициента эластичности сравнительную оценку силы связи фактора с результатом для каждой модели. Сделать выводы. Оценить качество уравнений регрессии с помощью средней ошибки аппроксимации и коэффициента детерминации. Сделать выводы.
3. По значениям рассчитанных характеристик выбрать лучшее уравнение регрессии. Дать экономический смысл коэффициентов выбранного уравнения регрессии
4. Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости a =0,05. Сделать выводы.
Решение: Решение: Для предварительного определения вида связи между указанными признаками построим поле корреляции. Для этого построим в системе координат точки, у которых первая координата X, а вторая – Y.
Получим следующий рисунок.

По внешнему виду диаграммы рассеяния трудно предположить, какая зависимость существует между указанными показателями.
Построение полулогарифмической модели регрессии.
Уравнение логарифмической кривой: ![]() .
.
Обозначим: ![]()
Получим линейное уравнение регрессии:
Y = A + B×X.
Произведем линеаризацию модели путем замены ![]() . В результате получим линейное уравнение
. В результате получим линейное уравнение ![]() .
.
Рассчитаем его параметры, используя данные таблицы.
|
№ п/п |
X |
Y |
X = ln(X) |
Xy |
X2 |
Y2 |
|
|
|
Ai |
|
1 |
178 |
240 |
5,1818 |
1243,63 |
26,85 |
57600 |
226,40 |
206,314 |
184,904 |
6,006 |
|
2 |
202 |
226 |
5,3083 |
1199,67 |
28,18 |
51076 |
225,17 |
0,132 |
0,694 |
0,370 |
|
3 |
197 |
221 |
5,2832 |
1167,59 |
27,91 |
48841 |
225,41 |
21,496 |
19,464 |
1,957 |
|
4 |
201 |
226 |
5,3033 |
1198,55 |
28,13 |
51076 |
225,22 |
0,132 |
0,615 |
0,348 |
|
5 |
189 |
220 |
5,2417 |
1153,18 |
27,48 |
48400 |
225,82 |
31,769 |
33,833 |
2,576 |
|
6 |
166 |
232 |
5,1120 |
1185,98 |
26,13 |
53824 |
227,08 |
40,496 |
24,172 |
2,165 |
|
7 |
199 |
215 |
5,2933 |
1138,06 |
28,02 |
46225 |
225,31 |
113,132 |
106,362 |
4,577 |
|
8 |
180 |
220 |
5,1930 |
1142,45 |
26,97 |
48400 |
226,29 |
31,769 |
39,601 |
2,781 |
|
9 |
181 |
222 |
5,1985 |
1154,07 |
27,02 |
49284 |
226,24 |
13,223 |
17,968 |
1,874 |
|
10 |
186 |
231 |
5,2257 |
1207,15 |
27,31 |
53361 |
225,97 |
28,769 |
25,273 |
2,225 |
|
11 |
250 |
229 |
5,5215 |
1264,41 |
30,49 |
52441 |
223,09 |
11,314 |
34,980 |
2,651 |
|
Итого |
2129 |
2482 |
57,862 |
13054,74 |
304,48 |
560528 |
2482,00 |
498,545 |
487,867 |
27,530 |
|
Среднее |
193,5 |
225,6 |
5,260 |
1186,79 |
27,68 |
50957,091 |
225,636 |
45,322 |
44,352 |
2,503 |
![]() = -9,76.
= -9,76.
![]() = 225,6 – (-9,76)×5,26 = 276,99.
= 225,6 – (-9,76)×5,26 = 276,99.
Уравнение модели имеет вид: ![]()
Определим индекс корреляции 
Используя данные таблицы, получим:
 .
.
Рассчитаем коэффициент детерминации: ![]() = 0,14642= 0,021 = 2,1%.
= 0,14642= 0,021 = 2,1%.
Вариация результата Y всего на 2,1% объясняется вариацией фактора X.
Сделаем рисунок.

Рассчитаем средний коэффициент эластичности по формуле:
![]() = -0,04%.
= -0,04%.
Коэффициент эластичности ![]() показывает, что при среднем росте признака X на 1% признак Y снижается на 0,04%.
показывает, что при среднем росте признака X на 1% признак Y снижается на 0,04%.
Вычислим среднюю ошибку аппроксимации. Используя данные расчетной таблицы, получаем:
![]() = 2,5%.
= 2,5%.
Построение степенной модели парной регрессии.
Уравнение степенной модели имеет вид: ![]() .
.
Для построения этой модели необходимо произвести линеаризацию переменных. Для этого произведем логарифмирование обеих частей уравнения:
![]() .
.
Произведем линеаризацию модели путем замены ![]() и
и ![]() . В результате получим линейное уравнение
. В результате получим линейное уравнение ![]() .
.
Рассчитаем его параметры, используя данные таблицы.
|
№ п/п |
X |
Y |
X = ln(X) |
Y = ln(Y) |
XY |
X2 |
Y2 |
|
|
|
|
Ai |
|
1 |
178 |
240 |
5,1818 |
5,4806 |
28,3995 |
26,851 |
30,037 |
226,3 |
206,3 |
188,391 |
241,661 |
6,07 |
|
2 |
202 |
226 |
5,3083 |
5,4205 |
28,7737 |
28,178 |
29,382 |
225,1 |
0,132 |
0,835 |
71,479 |
0,406 |
|
3 |
197 |
221 |
5,2832 |
5,3982 |
28,5196 |
27,912 |
29,140 |
225,3 |
21,496 |
18,671 |
11,934 |
1,918 |
|
4 |
201 |
226 |
5,3033 |
5,4205 |
28,7467 |
28,125 |
29,382 |
225,1 |
0,132 |
0,753 |
55,570 |
0,385 |
|
5 |
189 |
220 |
5,2417 |
5,3936 |
28,2720 |
27,476 |
29,091 |
225,7 |
31,769 |
32,607 |
20,661 |
2,530 |
|
6 |
166 |
232 |
5,1120 |
5,4467 |
27,8437 |
26,132 |
29,667 |
226,9 |
40,496 |
25,675 |
758,752 |
2,233 |
|
7 |
199 |
215 |
5,2933 |
5,3706 |
28,4284 |
28,019 |
28,844 |
225,2 |
113,132 |
104,576 |
29,752 |
4,540 |
|
8 |
180 |
220 |
5,1930 |
5,3936 |
28,0089 |
26,967 |
29,091 |
226,2 |
31,769 |
38,059 |
183,479 |
2,728 |
|
9 |
181 |
222 |
5,1985 |
5,4027 |
28,0858 |
27,024 |
29,189 |
226,1 |
13,223 |
16,950 |
157,388 |
1,821 |
|
10 |
186 |
231 |
5,2257 |
5,4424 |
28,4407 |
27,308 |
29,620 |
225,9 |
28,769 |
26,413 |
56,934 |
2,275 |
|
11 |
250 |
229 |
5,5215 |
5,4337 |
30,0021 |
30,487 |
29,525 |
223,1 |
11,314 |
34,846 |
3187,116 |
2,646 |
|
Итого |
2129 |
2482 |
57,862 |
59,603 |
313,521 |
304,479 |
322,969 |
2480,927 |
498,545 |
487,777 |
4774,727 |
27,548 |
|
Среднее |
193,5 |
225,6 |
5,260 |
5,418 |
28,502 |
27,680 |
29,361 |
225,539 |
45,322 |
44,343 |
434,066 |
2,504 |
С учетом введенных обозначений уравнение примет вид: Y = A + BX – линейное уравнение регрессии. Рассчитаем его параметры, используя данные таблицы.
![]() = -0,042.
= -0,042.
![]() = 5,418 – 0,959×5,26 = 5,637.
= 5,418 – 0,959×5,26 = 5,637.
Перейдем к исходным переменным X и Y, выполнив потенцирование данного уравнения.
A = eA = e5,637 = 280,76
Получим уравнение степенной модели регрессии: ![]() .
.
Определим индекс корреляции
Используя данные таблицы, получим:
 .
.
Рассчитаем коэффициент детерминации: ![]() = 0,1472= 0,021 = 2,1%.
= 0,1472= 0,021 = 2,1%.
Вариация результата Y всего на 2,1% объясняется вариацией фактора X.
Сделаем рисунок.

Для степенной модели средний коэффициент эластичности равен коэффициенту B.
![]() = -0,042%.
= -0,042%.
Коэффициент эластичности ![]() показывает, что при среднем росте признака X на 1% признак Y снижается на 0,042%.
показывает, что при среднем росте признака X на 1% признак Y снижается на 0,042%.
Вычислим среднюю ошибку аппроксимации. Используя данные расчетной таблицы, получаем:
![]() = 2,5%.
= 2,5%.
Сводная таблица вычислений
|
Параметры |
Модель |
|
|
Полулогарифмическая |
Степенная |
|
|
Уравнение связи |
|
|
|
Индекс корреляции |
0,1464 |
0,147 |
|
Коэффициент детерминации |
0,021 |
0,021 |
|
Средняя ошибка аппроксимации, % |
2,5 |
2,5 |
Для выявления формы связи между указанными признаками были построены полулогарифмическая и степенная модели регрессии. Анализ показателей корреляции, а также оценка качества моделей с использованием средней ошибки аппроксимации позволил предположить, что из перечисленных моделей более адекватной является степенная модель, поскольку для нее индекс корреляции принимает наибольшее значение R = 0,147, свидетельствующий о том, что между рассматриваемыми признаками наблюдается Слабая корреляционная связь.
Рассчитаем прогнозное значение результата по степенной модели регрессии, если прогнозируется увеличение значения фактора на 10% от среднего уровня.
Прогнозное значение составит:
![]() = 193,5 × 1,1 = 212,9 тыс. р., тогда прогнозное значение Y составит:
= 193,5 × 1,1 = 212,9 тыс. р., тогда прогнозное значение Y составит:
![]() = 224,6 тыс. р.
= 224,6 тыс. р.
Определим доверительный интервал прогноза для уровня значимости a = 0,05.
Вычислим Среднюю стандартную ошибку прогноза ![]() По следующей формуле:
По следующей формуле:
 , где
, где ![]()
Получаем:  = 7,55.
= 7,55.
Найдем предельную ошибку прогноза ![]() , где для доверительной вероятности 0,95 значение T составляет 1,96.
, где для доверительной вероятности 0,95 значение T составляет 1,96.
![]() = 14,8.
= 14,8.
Запишем доверительный интервал прогноза.
![]() = 224,6 – 14,8 = 209,8 тыс. р.
= 224,6 – 14,8 = 209,8 тыс. р.
![]() = 224,6 + 14,8 = 239,4 тыс. р.
= 224,6 + 14,8 = 239,4 тыс. р.
Таким образом, с вероятностью 0,95 можно утверждать, что прогнозное значение среднего размера назначенных ежемесячных пенсий будет находиться в пределах от 209,8 тыс. р. до 239,4 тыс. р.
Задание 3. Моделирование временных рядов
Имеются поквартальные данные по розничному товарообороту России в 1995-1999 гг.
|
Номер квартала |
Товарооборот % к предыдущему периоду |
Номер квартала |
Товарооборот % к предыдущему периоду |
|
1 |
100 |
11 |
98,8 |
|
2 |
93,9 |
12 |
101,9 |
|
3 |
96,5 |
13 |
113,1 |
|
4 |
101,8 |
14 |
98,4 |
|
5 |
107,8 |
15 |
97,3 |
|
6 |
96,3 |
16 |
112,1 |
|
7 |
95,7 |
17 |
97,6 |
|
8 |
98,2 |
18 |
93,7 |
|
9 |
104 |
19 |
114,3 |
|
10 |
99 |
20 |
108,4 |
Задания:
1. Построить график данного временного ряда. Охарактеризовать структуру этого ряда.
2. Рассчитать сезонную компоненты временного ряда и построить его Мультипликативную Модель.
3. Рассчитать трендовую компоненту временного ряда и построить его график
4. Оценить качество модели через показатели средней абсолютной ошибки и среднего относительного отклонения.
Решение: Пронумеруем указанные месяцы от 1 до 24 и построим график временного ряда.

Полученный график показывает, что а данном временном ряду присутствуют сезонные колебания.
Построим мультипликативную модель временного ряда.
Эта модель предполагает, что каждый уровень временного ряда может быть представлен как произведение трендовой (T), сезонной (S) и случайной (E) компонент.
Построение мультипликативной моделей сведем к расчету значений T, S и E для каждого уровня ряда.
Процесс построения модели включает в себя следующие шаги.
1) Выравнивание исходного ряда методом скользящей средней.
2) Расчет значений сезонной компоненты S.
3) Устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных T×E.
4) Аналитическое выравнивание уровней T×E и расчет значений T с использованием полученного уравнения тренда.
5) Расчет полученных по модели значений T×E.
6) Расчет абсолютных и/или относительных ошибок.
Шаг 1. Проведем выравнивание исходных уровней ряда методом скользящей средней. Для этого:
1.1. Просуммируем уровни ряда последовательно за каждые четыре месяца со сдвигом на один момент времени и определим условные годовые уровни объема продаж (гр. 3 табл. 2.1).
1.2. Разделив полученные суммы на 4, найдем скользящие средние (гр. 4 табл. 2.1). Полученные таким образом выровненные значения уже не содержат сезонной компоненты.
1.3. Приведем эти значения в соответствие с фактическими моментами времени, для чего найдем средние значения из двух последовательных скользящих средних – центрированные скользящие средние (гр. 5 табл. 2.1).
Таблица 2.1
|
№ месяца, T |
Товарооборот, Yi |
Итого за четыре месяца |
Скользящая средняя за четыре месяца |
Центрированная скользящая средняя |
Оценка сезонной компоненты |
|
1 |
2 |
3 |
4 |
5 |
6 |
|
1 |
100,0 |
– |
– |
– |
– |
|
2 |
93,9 |
392 |
98 |
– |
– |
|
3 |
96,5 |
400 |
100 |
99 |
0,975 |
|
4 |
101,8 |
402 |
100,5 |
100,25 |
1,015 |
|
5 |
107,8 |
402 |
100,5 |
100,5 |
1,073 |
|
6 |
96,3 |
398 |
99,5 |
100 |
0,963 |
|
7 |
95,7 |
394 |
98,5 |
99 |
0,967 |
|
8 |
98,2 |
397 |
99,25 |
98,875 |
0,993 |
|
9 |
104,0 |
400 |
100 |
99,625 |
1,044 |
|
10 |
99,0 |
404 |
101 |
100,5 |
0,985 |
|
11 |
98,8 |
413 |
103,25 |
102,125 |
0,967 |
|
12 |
101,9 |
412 |
103 |
103,125 |
0,988 |
|
13 |
113,1 |
411 |
102,75 |
102,875 |
1,099 |
|
14 |
98,4 |
309 |
77,25 |
90 |
1,093 |
|
15 |
97,3 |
196 |
49 |
63,125 |
1,541 |
|
16 |
112,1 |
303 |
75,75 |
62,375 |
1,797 |
|
17 |
97,6 |
418 |
104,5 |
90,125 |
1,083 |
|
18 |
93,7 |
414 |
103,5 |
104 |
0,901 |
|
19 |
114,3 |
– |
– |
– |
– |
|
20 |
108,4 |
– |
– |
– |
– |
Шаг 2. Найдем оценки сезонной компоненты как частное от деления фактических уровней ряда на центрированные скользящие средние (гр. 6 табл. 2.1). Эти оценки используются для расчета сезонной компоненты S (табл. 2.2). Для этого найдем средние за каждый месяц оценки сезонной компоненты Si. Так же как и в аддитивной модели считается, что сезонные воздействия за период взаимопогашаются. В мультипликативной модели это выражается в том, что сумма значений сезонной компоненты по всем месяцам должна быть равна числу периодов в цикле. В нашем случае число периодов одного цикла равно 4.
Таблица 2.2
|
Показатели |
Год |
№ квартала, I |
|||
|
I |
II |
III |
IV |
||
|
1 |
– |
– |
0,975 |
1,015 |
|
|
2 |
1,073 |
0,963 |
0,967 |
0,993 |
|
|
3 |
1,044 |
0,985 |
0,967 |
0,988 |
|
|
4 |
1,099 |
1,093 |
1,541 |
1,797 |
|
|
5 |
1,083 |
0,901 |
– |
– |
|
|
Всего за I-й квартал |
4,299 |
3,942 |
4,45 |
4,793 |
|
|
Средняя оценка сезонной компоненты для I-го квартала, |
0,860 |
0,788 |
0,890 |
0,959 |
|
|
Скорректированная сезонная компонента, |
0,984 |
0,901 |
1,018 |
1,097 |
Имеем: 0,860 + 0,788 + 0,890 + 0,959 = 3,497.
Определяем корректирующий коэффициент: K = 4 : 3,497 = 1,144.
Скорректированные значения сезонной компоненты ![]() получаются при умножении ее средней оценки
получаются при умножении ее средней оценки ![]() на корректирующий коэффициент K.
на корректирующий коэффициент K.
Проверяем условие: равенство 4 суммы значений сезонной компоненты:
0,984 + 0,901 + 1,018 + 1,097 = 4.
Шаг 3. Разделим каждый уровень исходного ряда на соответствующие значения сезонной компоненты. В результате получим величины ![]() (гр. 4 табл. 2.3), которые содержат только тенденцию и случайную компоненту.
(гр. 4 табл. 2.3), которые содержат только тенденцию и случайную компоненту.
Таблица 2.3
|
T |
Yt |
St |
|
T |
T×S |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
1 |
100,0 |
0,984 |
101,6 |
100,02 |
98,42 |
1,016 |
|
2 |
93,9 |
0,901 |
104,2 |
100,19 |
90,27 |
1,040 |
|
3 |
96,5 |
1,018 |
94,8 |
100,36 |
102,17 |
0,945 |
|
4 |
101,8 |
1,097 |
92,8 |
100,53 |
110,28 |
0,923 |
|
5 |
107,8 |
0,984 |
109,6 |
100,7 |
99,09 |
1,088 |
|
6 |
96,3 |
0,901 |
106,9 |
100,87 |
90,88 |
1,060 |
|
7 |
95,7 |
1,018 |
94,0 |
101,04 |
102,86 |
0,930 |
|
8 |
98,2 |
1,097 |
89,5 |
101,21 |
111,03 |
0,884 |
|
9 |
104,0 |
0,984 |
105,7 |
101,38 |
99,76 |
1,043 |
|
10 |
99,0 |
0,901 |
109,9 |
101,55 |
91,50 |
1,082 |
|
11 |
98,8 |
1,018 |
97,1 |
101,72 |
103,55 |
0,954 |
|
12 |
101,9 |
1,097 |
92,9 |
101,89 |
111,77 |
0,912 |
|
13 |
113,1 |
0,984 |
114,9 |
102,06 |
100,43 |
1,126 |
|
14 |
98,4 |
0,901 |
109,2 |
102,23 |
92,11 |
1,068 |
|
15 |
97,3 |
1,018 |
95,6 |
102,4 |
104,24 |
0,933 |
|
16 |
112,1 |
1,097 |
102,2 |
102,57 |
112,52 |
0,996 |
|
17 |
97,6 |
0,984 |
99,2 |
102,74 |
101,10 |
0,965 |
|
18 |
93,7 |
0,901 |
104,0 |
102,91 |
92,72 |
1,011 |
|
19 |
114,3 |
1,018 |
112,3 |
103,08 |
104,94 |
1,089 |
|
20 |
108,4 |
1,097 |
98,8 |
103,25 |
113,27 |
0,957 |
|
Среднее |
101,4 |
1,0011 |
Шаг 4. Определим компоненту T в мультипликативной модели. Для этого рассчитаем параметры линейного тренда, используя уровни T×E. Составим вспомогательную таблицу.
Таблица 2.4
|
T |
|
T2 |
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
1 |
101,6 |
1 |
101,6 |
2,5 |
1,58 |
2,0 |
|
|
2 |
104,2 |
4 |
208,4 |
13,2 |
3,87 |
56,3 |
|
|
3 |
94,8 |
9 |
284,4 |
32,1 |
5,88 |
24,0 |
|
|
4 |
92,8 |
16 |
371,2 |
71,9 |
8,33 |
0,2 |
|
|
5 |
109,6 |
25 |
548 |
75,9 |
8,08 |
41,0 |
|
|
6 |
106,9 |
36 |
641,4 |
29,4 |
5,63 |
26,0 |
|
|
7 |
94,0 |
49 |
658 |
51,3 |
7,48 |
32,5 |
|
|
8 |
89,5 |
64 |
716 |
164,6 |
13,07 |
10,2 |
|
|
9 |
105,7 |
81 |
951,3 |
18,0 |
4,08 |
6,8 |
|
|
10 |
109,9 |
100 |
1099 |
56,3 |
7,58 |
5,8 |
|
|
11 |
97,1 |
121 |
1068,1 |
22,6 |
4,81 |
6,8 |
|
|
12 |
92,9 |
144 |
1114,8 |
97,4 |
9,69 |
0,3 |
|
|
13 |
114,9 |
169 |
1493,7 |
160,5 |
11,20 |
136,9 |
|
|
14 |
109,2 |
196 |
1528,8 |
39,6 |
6,39 |
9,0 |
|
|
15 |
95,6 |
225 |
1434 |
48,2 |
7,13 |
16,8 |
|
|
20 |
102,2 |
400 |
2044 |
0,2 |
0,37 |
114,5 |
|
|
21 |
99,2 |
441 |
2083,2 |
12,3 |
3,59 |
14,4 |
|
|
22 |
104,0 |
484 |
2288 |
1,0 |
1,05 |
59,3 |
|
|
23 |
112,3 |
529 |
2582,9 |
87,6 |
8,19 |
166,4 |
|
|
24 |
98,8 |
576 |
2371,2 |
23,7 |
4,49 |
49,0 |
|
|
Сумма |
230 |
2035,2 |
3670 |
23588 |
1008,3 |
122,49 |
778,2 |
|
Среднее |
11,5 |
101,8 |
183,5 |
1179,4 |
50,4 |
6,12 |
38,91 |
Вычислим параметры уравнения тренда.
 = 0,17.
= 0,17.
![]() = 99,85.
= 99,85.
В результате получим уравнение тренда:
T = 99,85 + 0,17×T.
Подставляя в это уравнение значения T = 1,2,…,16, найдем уровни T для каждого момента времени (гр. 5 табл. 2.3).
Шаг 5. Найдем уровни ряда, умножив значения T на соответствующие значения сезонной компоненты (гр. 6 табл. 2.3). На одном графике откладываем фактические значения уровней временного ряда и теоретические, полученные по мультипликативной модели.

Расчет ошибки в мультипликативной модели произведем по формуле:
![]()
Средняя абсолютная ошибка составила 1,0011 (см. гр. 7 табл. 2.3).
Рассчитаем сумму квадратов абсолютных ошибок ![]() .
.
Используя 5-й столбец таблицы 2.4, получим:
 = 7,099.
= 7,099.
Рассчитаем среднюю относительную ошибку: ![]() .
.
Используя 6-й столбец таблицы 2.4, получим, что средняя относительная ошибка составила 6,12%, т. е. построенная модель достаточно точно описывает динамику данного явления.
| < Предыдущая | Следующая > |
|---|
Вариант 1
Задание 1. Модель парной линейной регрессии.
Имеются данные о размере среднемесячных доходов в разных группах семей
|
Номер группы |
Среднедушевой денежный доход в месяц, руб., X |
Доля оплаты труда в структуре доходов семьи, %, Y |
|
1 |
79,8 |
64,2 |
|
2 |
152,1 |
66,1 |
|
3 |
199,3 |
69,0 |
|
4 |
240,8 |
70,6 |
|
5 |
282,4 |
72,4 |
|
6 |
301,8 |
74,3 |
|
7 |
385,3 |
76,0 |
|
8 |
457,8 |
77,1 |
|
9 |
577,4 |
78,4 |
Задания:
1. Рассчитать линейный коэффициент парной корреляции, оценить его статистическую значимость и построить для него доверительный интервал с уровнем значимости a =0,05. Сделать выводы
2. Построить линейное уравнение парной регрессии Y на X и оценить статистическую значимость параметров регрессии. Сделать рисунок.
3. Оценить качество уравнения регрессии при помощи коэффициента детерминации. Сделать выводы. Проверить качество уравнения регрессии при помощи F-критерия Фишера.
4. Выполнить прогноз доли оплаты труда структуре доходов семьи Y при прогнозном значении среднедушевого денежного дохода X, составляющем 111% от среднего уровня. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал для уровня значимости a =0,05. Сделать выводы.
Решение: Построим поле корреляции зависимости доли оплаты труда в структуре доходов семьи от среднедушевого денежного дохода в месяц.
Точки на построенном графике размещаются вблизи кривой, напоминающей по форме Прямую, поэтому можно предположить, что между указанными величинами существует Линейная зависимость вида ![]() .
.
Для расчета линейного коэффициента парной корреляции и параметров линейной регрессии составим вспомогательную таблицу.
|
№ п/п |
X |
Y |
X×Y |
X2 |
Y2 |
|
1 |
79,8 |
64,2 |
5123,16 |
6368,04 |
4121,64 |
|
2 |
152,1 |
66,1 |
10053,81 |
23134,41 |
4369,21 |
|
3 |
199,3 |
69,0 |
13751,70 |
39720,49 |
4761,00 |
|
4 |
240,8 |
70,6 |
17000,48 |
57984,64 |
4984,36 |
|
5 |
282,4 |
72,4 |
20445,76 |
79749,76 |
5241,76 |
|
6 |
301,8 |
74,3 |
22423,74 |
91083,24 |
5520,49 |
|
7 |
385,3 |
76,0 |
29282,80 |
148456,09 |
5776,00 |
|
8 |
457,8 |
77,1 |
35296,38 |
209580,84 |
5944,41 |
|
9 |
577,4 |
78,4 |
45268,16 |
333390,76 |
6146,56 |
|
S |
2676,7 |
648,1 |
198645,99 |
989468,27 |
46865,43 |
|
Среднее |
297,41 |
72,01 |
22071,78 |
109940,92 |
5207,27 |
Вычислим коэффициент корреляции. Используем следующую формулу:
![]() = 0,9568.
= 0,9568.
Можно сказать, что между рассматриваемыми признаками существует Прямая тесная Корреляционная связь.
Среднюю ошибку коэффициента корреляции определим по формуле:
![]() = 0,032.
= 0,032.
Найдем табличное значение TТабл по таблице распределения Стьюдента для
a = 0,05 и числе степеней свободы K = N – M – 1 = 9 – 1 – 1 = 7.
TТабл(0,05; 7) = 2,36.
Запишем доверительный интервал для коэффициента корреляции.
![]()
![]()
Доверительный интервал не включает число 0, поэтому при заданном уровне значимости коэффициент корреляции является статистически значимым.
Вычислим параметры уравнения регрессии.
![]() = 0,03.
= 0,03.
![]() = 72,01 – 0,03×297,41 = 63,09.
= 72,01 – 0,03×297,41 = 63,09.
Получим следующее уравнение: ![]() .
.
Для проверки статистической значимости (существенности) линейного коэффициента парной корреляции рассчитаем T-критерий Стьюдента по формуле:
= 23,04.
Фактическое значение по абсолютной величине больше табличного, что свидетельствует о значимости линейного коэффициента корреляции и существенности связи между рассматриваемыми признаками.
Проверим значимость оценок теоретических коэффициентов регрессии с помощью t-статистики Стьюдента и сделаем соответствующие выводы о значимости этих оценок.
Для определения статистической значимости коэффициентов A и B найдем T-статистики Стьюдента:
Рассчитаем по полученному уравнению теоретические значения![]() . Составим вспомогательную таблицу.
. Составим вспомогательную таблицу.
|
№ п/п |
X |
Y |
|
|
|
|
1 |
79,8 |
64,2 |
65,48 |
1,6384 |
47354,1 |
|
2 |
152,1 |
66,1 |
67,65 |
2,4025 |
21115,0 |
|
3 |
199,3 |
69,0 |
69,07 |
0,0049 |
9625,6 |
|
4 |
240,8 |
70,6 |
70,31 |
0,0841 |
3204,7 |
|
5 |
282,4 |
72,4 |
71,56 |
0,7056 |
225,3 |
|
6 |
301,8 |
74,3 |
72,14 |
4,6656 |
19,3 |
|
7 |
385,3 |
76,0 |
74,65 |
1,8225 |
7724,7 |
|
8 |
457,8 |
77,1 |
76,82 |
0,0784 |
25725,0 |
|
9 |
577,4 |
78,4 |
80,41 |
4,0401 |
78394,4 |
|
S |
2676,7 |
648,1 |
648,09 |
15,4421 |
193388,1 |
Вычислим стандартные ошибки коэффициентов уравнения.
= 1,2.
= 0,003.
Вычислим T-статистики.
![]()
![]()
Сравнение расчетных и табличных величин критерия Стьюдента показывает, что ![]() и
и ![]() , т. е. оценки A и B теоретических коэффициентов регрессии статистически значимы.
, т. е. оценки A и B теоретических коэффициентов регрессии статистически значимы.
Сделаем рисунок.
Рассчитаем коэффициент детерминации: ![]() = 0,95682= 0,915 = 91,5%.
= 0,95682= 0,915 = 91,5%.
Таким образом, вариация результата Y на 91,5% объясняется вариацией фактора X.
Оценку значимости уравнения регрессии проведем с помощью F-критерия Фишера:
= 75,81.
Найдем табличное значение Fтабл по таблице критических точек Фишера для
a = 0,05; K1 = M = 1 (число факторов), K2 = N – M – 1 = 9 – 1 – 1 = 7.
Fтабл(0,05; 1; 7) = 5,59.
Поскольку F > FТабл, уравнение регрессии с вероятностью 0,95 в целом Является статистически значимым.
Выполним прогноз доли оплаты труда структуре доходов семьи y при прогнозном значении среднедушевого денежного дохода x, составляющем 111% от среднего уровня.
XP = 297,41 × 1,11 = 330,1.
Вычислим прогнозное значение Yp с помощью уравнения регрессии.
![]() » 73%.
» 73%.
Доверительный интервал прогноза имеет вид
(УP – Tкр×My, УP + Tкр×My),
Где , M = 2 – число параметров уравнения.
= 1,695 » 1,7.
Запишем доверительный интервал прогноза:
![]() Þ
Þ ![]()
Данный прогноз является надежным, поскольку доверительный интервал не включает число 0, точность прогноза составляет 4.
Задание 2. Модель парной нелинейной регрессии.
По территориям Центрального района известны данные за 1995 г.
|
Район |
Прожиточный минимум в среднем на одного пенсионера в месяц, тыс. руб., X |
Средний размер назначенных ежемесячных пенсий, тыс. руб., Y |
|
Брянская обл. |
178 |
240 |
|
Владимирская обл. |
202 |
226 |
|
Ивановская обл. |
197 |
221 |
|
Калужская обл. |
201 |
226 |
|
Костромская обл. |
189 |
220 |
|
Орловская обл. |
166 |
232 |
|
Рязанская обл. |
199 |
215 |
|
Смоленская обл. |
180 |
220 |
|
Тверская обл. |
181 |
222 |
|
Тульская обл. |
186 |
231 |
|
Ярославская обл. |
250 |
229 |
Задания:
1. Построить поле корреляции и сформулируйте гипотезу о форме связи. Рассчитать параметры уравнений полулогарифмической (![]() ) и степенной (
) и степенной (![]() ) парной регрессии. Сделать рисунки.
) парной регрессии. Сделать рисунки.
2. Дать с помощью среднего коэффициента эластичности сравнительную оценку силы связи фактора с результатом для каждой модели. Сделать выводы. Оценить качество уравнений регрессии с помощью средней ошибки аппроксимации и коэффициента детерминации. Сделать выводы.
3. По значениям рассчитанных характеристик выбрать лучшее уравнение регрессии. Дать экономический смысл коэффициентов выбранного уравнения регрессии
4. Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости a =0,05. Сделать выводы.
Решение: Решение: Для предварительного определения вида связи между указанными признаками построим поле корреляции. Для этого построим в системе координат точки, у которых первая координата X, а вторая – Y.
Получим следующий рисунок.
По внешнему виду диаграммы рассеяния трудно предположить, какая зависимость существует между указанными показателями.
Построение полулогарифмической модели регрессии.
Уравнение логарифмической кривой: ![]() .
.
Обозначим: ![]()
Получим линейное уравнение регрессии:
Y = A + B×X.
Произведем линеаризацию модели путем замены ![]() . В результате получим линейное уравнение
. В результате получим линейное уравнение ![]() .
.
Рассчитаем его параметры, используя данные таблицы.
|
№ п/п |
X |
Y |
X = ln(X) |
Xy |
X2 |
Y2 |
|
|
|
Ai |
|
1 |
178 |
240 |
5,1818 |
1243,63 |
26,85 |
57600 |
226,40 |
206,314 |
184,904 |
6,006 |
|
2 |
202 |
226 |
5,3083 |
1199,67 |
28,18 |
51076 |
225,17 |
0,132 |
0,694 |
0,370 |
|
3 |
197 |
221 |
5,2832 |
1167,59 |
27,91 |
48841 |
225,41 |
21,496 |
19,464 |
1,957 |
|
4 |
201 |
226 |
5,3033 |
1198,55 |
28,13 |
51076 |
225,22 |
0,132 |
0,615 |
0,348 |
|
5 |
189 |
220 |
5,2417 |
1153,18 |
27,48 |
48400 |
225,82 |
31,769 |
33,833 |
2,576 |
|
6 |
166 |
232 |
5,1120 |
1185,98 |
26,13 |
53824 |
227,08 |
40,496 |
24,172 |
2,165 |
|
7 |
199 |
215 |
5,2933 |
1138,06 |
28,02 |
46225 |
225,31 |
113,132 |
106,362 |
4,577 |
|
8 |
180 |
220 |
5,1930 |
1142,45 |
26,97 |
48400 |
226,29 |
31,769 |
39,601 |
2,781 |
|
9 |
181 |
222 |
5,1985 |
1154,07 |
27,02 |
49284 |
226,24 |
13,223 |
17,968 |
1,874 |
|
10 |
186 |
231 |
5,2257 |
1207,15 |
27,31 |
53361 |
225,97 |
28,769 |
25,273 |
2,225 |
|
11 |
250 |
229 |
5,5215 |
1264,41 |
30,49 |
52441 |
223,09 |
11,314 |
34,980 |
2,651 |
|
Итого |
2129 |
2482 |
57,862 |
13054,74 |
304,48 |
560528 |
2482,00 |
498,545 |
487,867 |
27,530 |
|
Среднее |
193,5 |
225,6 |
5,260 |
1186,79 |
27,68 |
50957,091 |
225,636 |
45,322 |
44,352 |
2,503 |
![]() = -9,76.
= -9,76.
![]() = 225,6 – (-9,76)×5,26 = 276,99.
= 225,6 – (-9,76)×5,26 = 276,99.
Уравнение модели имеет вид: ![]()
Определим индекс корреляции
Используя данные таблицы, получим:
.
Рассчитаем коэффициент детерминации: ![]() = 0,14642= 0,021 = 2,1%.
= 0,14642= 0,021 = 2,1%.
Вариация результата Y всего на 2,1% объясняется вариацией фактора X.
Сделаем рисунок.
Рассчитаем средний коэффициент эластичности по формуле:
![]() = -0,04%.
= -0,04%.
Коэффициент эластичности ![]() показывает, что при среднем росте признака X на 1% признак Y снижается на 0,04%.
показывает, что при среднем росте признака X на 1% признак Y снижается на 0,04%.
Вычислим среднюю ошибку аппроксимации. Используя данные расчетной таблицы, получаем:
![]() = 2,5%.
= 2,5%.
Построение степенной модели парной регрессии.
Уравнение степенной модели имеет вид: ![]() .
.
Для построения этой модели необходимо произвести линеаризацию переменных. Для этого произведем логарифмирование обеих частей уравнения:
![]() .
.
Произведем линеаризацию модели путем замены ![]() и
и ![]() . В результате получим линейное уравнение
. В результате получим линейное уравнение ![]() .
.
Рассчитаем его параметры, используя данные таблицы.
|
№ п/п |
X |
Y |
X = ln(X) |
Y = ln(Y) |
XY |
X2 |
Y2 |
|
|
|
|
Ai |
|
1 |
178 |
240 |
5,1818 |
5,4806 |
28,3995 |
26,851 |
30,037 |
226,3 |
206,3 |
188,391 |
241,661 |
6,07 |
|
2 |
202 |
226 |
5,3083 |
5,4205 |
28,7737 |
28,178 |
29,382 |
225,1 |
0,132 |
0,835 |
71,479 |
0,406 |
|
3 |
197 |
221 |
5,2832 |
5,3982 |
28,5196 |
27,912 |
29,140 |
225,3 |
21,496 |
18,671 |
11,934 |
1,918 |
|
4 |
201 |
226 |
5,3033 |
5,4205 |
28,7467 |
28,125 |
29,382 |
225,1 |
0,132 |
0,753 |
55,570 |
0,385 |
|
5 |
189 |
220 |
5,2417 |
5,3936 |
28,2720 |
27,476 |
29,091 |
225,7 |
31,769 |
32,607 |
20,661 |
2,530 |
|
6 |
166 |
232 |
5,1120 |
5,4467 |
27,8437 |
26,132 |
29,667 |
226,9 |
40,496 |
25,675 |
758,752 |
2,233 |
|
7 |
199 |
215 |
5,2933 |
5,3706 |
28,4284 |
28,019 |
28,844 |
225,2 |
113,132 |
104,576 |
29,752 |
4,540 |
|
8 |
180 |
220 |
5,1930 |
5,3936 |
28,0089 |
26,967 |
29,091 |
226,2 |
31,769 |
38,059 |
183,479 |
2,728 |
|
9 |
181 |
222 |
5,1985 |
5,4027 |
28,0858 |
27,024 |
29,189 |
226,1 |
13,223 |
16,950 |
157,388 |
1,821 |
|
10 |
186 |
231 |
5,2257 |
5,4424 |
28,4407 |
27,308 |
29,620 |
225,9 |
28,769 |
26,413 |
56,934 |
2,275 |
|
11 |
250 |
229 |
5,5215 |
5,4337 |
30,0021 |
30,487 |
29,525 |
223,1 |
11,314 |
34,846 |
3187,116 |
2,646 |
|
Итого |
2129 |
2482 |
57,862 |
59,603 |
313,521 |
304,479 |
322,969 |
2480,927 |
498,545 |
487,777 |
4774,727 |
27,548 |
|
Среднее |
193,5 |
225,6 |
5,260 |
5,418 |
28,502 |
27,680 |
29,361 |
225,539 |
45,322 |
44,343 |
434,066 |
2,504 |
С учетом введенных обозначений уравнение примет вид: Y = A + BX – линейное уравнение регрессии. Рассчитаем его параметры, используя данные таблицы.
![]() = -0,042.
= -0,042.
![]() = 5,418 – 0,959×5,26 = 5,637.
= 5,418 – 0,959×5,26 = 5,637.
Перейдем к исходным переменным X и Y, выполнив потенцирование данного уравнения.
A = eA = e5,637 = 280,76
Получим уравнение степенной модели регрессии: ![]() .
.
Определим индекс корреляции
Используя данные таблицы, получим:
.
Рассчитаем коэффициент детерминации: ![]() = 0,1472= 0,021 = 2,1%.
= 0,1472= 0,021 = 2,1%.
Вариация результата Y всего на 2,1% объясняется вариацией фактора X.
Сделаем рисунок.
Для степенной модели средний коэффициент эластичности равен коэффициенту B.
![]() = -0,042%.
= -0,042%.
Коэффициент эластичности ![]() показывает, что при среднем росте признака X на 1% признак Y снижается на 0,042%.
показывает, что при среднем росте признака X на 1% признак Y снижается на 0,042%.
Вычислим среднюю ошибку аппроксимации. Используя данные расчетной таблицы, получаем:
![]() = 2,5%.
= 2,5%.
Сводная таблица вычислений
|
Параметры |
Модель |
|
|
Полулогарифмическая |
Степенная |
|
|
Уравнение связи |
|
|
|
Индекс корреляции |
0,1464 |
0,147 |
|
Коэффициент детерминации |
0,021 |
0,021 |
|
Средняя ошибка аппроксимации, % |
2,5 |
2,5 |
Для выявления формы связи между указанными признаками были построены полулогарифмическая и степенная модели регрессии. Анализ показателей корреляции, а также оценка качества моделей с использованием средней ошибки аппроксимации позволил предположить, что из перечисленных моделей более адекватной является степенная модель, поскольку для нее индекс корреляции принимает наибольшее значение R = 0,147, свидетельствующий о том, что между рассматриваемыми признаками наблюдается Слабая корреляционная связь.
Рассчитаем прогнозное значение результата по степенной модели регрессии, если прогнозируется увеличение значения фактора на 10% от среднего уровня.
Прогнозное значение составит:
![]() = 193,5 × 1,1 = 212,9 тыс. р., тогда прогнозное значение Y составит:
= 193,5 × 1,1 = 212,9 тыс. р., тогда прогнозное значение Y составит:
![]() = 224,6 тыс. р.
= 224,6 тыс. р.
Определим доверительный интервал прогноза для уровня значимости a = 0,05.
Вычислим Среднюю стандартную ошибку прогноза ![]() По следующей формуле:
По следующей формуле:
, где ![]()
Получаем: = 7,55.
Найдем предельную ошибку прогноза ![]() , где для доверительной вероятности 0,95 значение T составляет 1,96.
, где для доверительной вероятности 0,95 значение T составляет 1,96.
![]() = 14,8.
= 14,8.
Запишем доверительный интервал прогноза.
![]() = 224,6 – 14,8 = 209,8 тыс. р.
= 224,6 – 14,8 = 209,8 тыс. р.
![]() = 224,6 + 14,8 = 239,4 тыс. р.
= 224,6 + 14,8 = 239,4 тыс. р.
Таким образом, с вероятностью 0,95 можно утверждать, что прогнозное значение среднего размера назначенных ежемесячных пенсий будет находиться в пределах от 209,8 тыс. р. до 239,4 тыс. р.
Задание 3. Моделирование временных рядов
Имеются поквартальные данные по розничному товарообороту России в 1995-1999 гг.
|
Номер квартала |
Товарооборот % к предыдущему периоду |
Номер квартала |
Товарооборот % к предыдущему периоду |
|
1 |
100 |
11 |
98,8 |
|
2 |
93,9 |
12 |
101,9 |
|
3 |
96,5 |
13 |
113,1 |
|
4 |
101,8 |
14 |
98,4 |
|
5 |
107,8 |
15 |
97,3 |
|
6 |
96,3 |
16 |
112,1 |
|
7 |
95,7 |
17 |
97,6 |
|
8 |
98,2 |
18 |
93,7 |
|
9 |
104 |
19 |
114,3 |
|
10 |
99 |
20 |
108,4 |
Задания:
1. Построить график данного временного ряда. Охарактеризовать структуру этого ряда.
2. Рассчитать сезонную компоненты временного ряда и построить его Мультипликативную Модель.
3. Рассчитать трендовую компоненту временного ряда и построить его график
4. Оценить качество модели через показатели средней абсолютной ошибки и среднего относительного отклонения.
Решение: Пронумеруем указанные месяцы от 1 до 24 и построим график временного ряда.
Полученный график показывает, что а данном временном ряду присутствуют сезонные колебания.
Построим мультипликативную модель временного ряда.
Эта модель предполагает, что каждый уровень временного ряда может быть представлен как произведение трендовой (T), сезонной (S) и случайной (E) компонент.
Построение мультипликативной моделей сведем к расчету значений T, S и E для каждого уровня ряда.
Процесс построения модели включает в себя следующие шаги.
1) Выравнивание исходного ряда методом скользящей средней.
2) Расчет значений сезонной компоненты S.
3) Устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных T×E.
4) Аналитическое выравнивание уровней T×E и расчет значений T с использованием полученного уравнения тренда.
5) Расчет полученных по модели значений T×E.
6) Расчет абсолютных и/или относительных ошибок.
Шаг 1. Проведем выравнивание исходных уровней ряда методом скользящей средней. Для этого:
1.1. Просуммируем уровни ряда последовательно за каждые четыре месяца со сдвигом на один момент времени и определим условные годовые уровни объема продаж (гр. 3 табл. 2.1).
1.2. Разделив полученные суммы на 4, найдем скользящие средние (гр. 4 табл. 2.1). Полученные таким образом выровненные значения уже не содержат сезонной компоненты.
1.3. Приведем эти значения в соответствие с фактическими моментами времени, для чего найдем средние значения из двух последовательных скользящих средних – центрированные скользящие средние (гр. 5 табл. 2.1).
Таблица 2.1
|
№ месяца, T |
Товарооборот, Yi |
Итого за четыре месяца |
Скользящая средняя за четыре месяца |
Центрированная скользящая средняя |
Оценка сезонной компоненты |
|
1 |
2 |
3 |
4 |
5 |
6 |
|
1 |
100,0 |
– |
– |
– |
– |
|
2 |
93,9 |
392 |
98 |
– |
– |
|
3 |
96,5 |
400 |
100 |
99 |
0,975 |
|
4 |
101,8 |
402 |
100,5 |
100,25 |
1,015 |
|
5 |
107,8 |
402 |
100,5 |
100,5 |
1,073 |
|
6 |
96,3 |
398 |
99,5 |
100 |
0,963 |
|
7 |
95,7 |
394 |
98,5 |
99 |
0,967 |
|
8 |
98,2 |
397 |
99,25 |
98,875 |
0,993 |
|
9 |
104,0 |
400 |
100 |
99,625 |
1,044 |
|
10 |
99,0 |
404 |
101 |
100,5 |
0,985 |
|
11 |
98,8 |
413 |
103,25 |
102,125 |
0,967 |
|
12 |
101,9 |
412 |
103 |
103,125 |
0,988 |
|
13 |
113,1 |
411 |
102,75 |
102,875 |
1,099 |
|
14 |
98,4 |
309 |
77,25 |
90 |
1,093 |
|
15 |
97,3 |
196 |
49 |
63,125 |
1,541 |
|
16 |
112,1 |
303 |
75,75 |
62,375 |
1,797 |
|
17 |
97,6 |
418 |
104,5 |
90,125 |
1,083 |
|
18 |
93,7 |
414 |
103,5 |
104 |
0,901 |
|
19 |
114,3 |
– |
– |
– |
– |
|
20 |
108,4 |
– |
– |
– |
– |
Шаг 2. Найдем оценки сезонной компоненты как частное от деления фактических уровней ряда на центрированные скользящие средние (гр. 6 табл. 2.1). Эти оценки используются для расчета сезонной компоненты S (табл. 2.2). Для этого найдем средние за каждый месяц оценки сезонной компоненты Si. Так же как и в аддитивной модели считается, что сезонные воздействия за период взаимопогашаются. В мультипликативной модели это выражается в том, что сумма значений сезонной компоненты по всем месяцам должна быть равна числу периодов в цикле. В нашем случае число периодов одного цикла равно 4.
Таблица 2.2
|
Показатели |
Год |
№ квартала, I |
|||
|
I |
II |
III |
IV |
||
|
1 |
– |
– |
0,975 |
1,015 |
|
|
2 |
1,073 |
0,963 |
0,967 |
0,993 |
|
|
3 |
1,044 |
0,985 |
0,967 |
0,988 |
|
|
4 |
1,099 |
1,093 |
1,541 |
1,797 |
|
|
5 |
1,083 |
0,901 |
– |
– |
|
|
Всего за I-й квартал |
4,299 |
3,942 |
4,45 |
4,793 |
|
|
Средняя оценка сезонной компоненты для I-го квартала, |
0,860 |
0,788 |
0,890 |
0,959 |
|
|
Скорректированная сезонная компонента, |
0,984 |
0,901 |
1,018 |
1,097 |
Имеем: 0,860 + 0,788 + 0,890 + 0,959 = 3,497.
Определяем корректирующий коэффициент: K = 4 : 3,497 = 1,144.
Скорректированные значения сезонной компоненты ![]() получаются при умножении ее средней оценки
получаются при умножении ее средней оценки ![]() на корректирующий коэффициент K.
на корректирующий коэффициент K.
Проверяем условие: равенство 4 суммы значений сезонной компоненты:
0,984 + 0,901 + 1,018 + 1,097 = 4.
Шаг 3. Разделим каждый уровень исходного ряда на соответствующие значения сезонной компоненты. В результате получим величины ![]() (гр. 4 табл. 2.3), которые содержат только тенденцию и случайную компоненту.
(гр. 4 табл. 2.3), которые содержат только тенденцию и случайную компоненту.
Таблица 2.3
|
T |
Yt |
St |
|
T |
T×S |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
1 |
100,0 |
0,984 |
101,6 |
100,02 |
98,42 |
1,016 |
|
2 |
93,9 |
0,901 |
104,2 |
100,19 |
90,27 |
1,040 |
|
3 |
96,5 |
1,018 |
94,8 |
100,36 |
102,17 |
0,945 |
|
4 |
101,8 |
1,097 |
92,8 |
100,53 |
110,28 |
0,923 |
|
5 |
107,8 |
0,984 |
109,6 |
100,7 |
99,09 |
1,088 |
|
6 |
96,3 |
0,901 |
106,9 |
100,87 |
90,88 |
1,060 |
|
7 |
95,7 |
1,018 |
94,0 |
101,04 |
102,86 |
0,930 |
|
8 |
98,2 |
1,097 |
89,5 |
101,21 |
111,03 |
0,884 |
|
9 |
104,0 |
0,984 |
105,7 |
101,38 |
99,76 |
1,043 |
|
10 |
99,0 |
0,901 |
109,9 |
101,55 |
91,50 |
1,082 |
|
11 |
98,8 |
1,018 |
97,1 |
101,72 |
103,55 |
0,954 |
|
12 |
101,9 |
1,097 |
92,9 |
101,89 |
111,77 |
0,912 |
|
13 |
113,1 |
0,984 |
114,9 |
102,06 |
100,43 |
1,126 |
|
14 |
98,4 |
0,901 |
109,2 |
102,23 |
92,11 |
1,068 |
|
15 |
97,3 |
1,018 |
95,6 |
102,4 |
104,24 |
0,933 |
|
16 |
112,1 |
1,097 |
102,2 |
102,57 |
112,52 |
0,996 |
|
17 |
97,6 |
0,984 |
99,2 |
102,74 |
101,10 |
0,965 |
|
18 |
93,7 |
0,901 |
104,0 |
102,91 |
92,72 |
1,011 |
|
19 |
114,3 |
1,018 |
112,3 |
103,08 |
104,94 |
1,089 |
|
20 |
108,4 |
1,097 |
98,8 |
103,25 |
113,27 |
0,957 |
|
Среднее |
101,4 |
1,0011 |
Шаг 4. Определим компоненту T в мультипликативной модели. Для этого рассчитаем параметры линейного тренда, используя уровни T×E. Составим вспомогательную таблицу.
Таблица 2.4
|
T |
|
T2 |
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
1 |
101,6 |
1 |
101,6 |
2,5 |
1,58 |
2,0 |
|
|
2 |
104,2 |
4 |
208,4 |
13,2 |
3,87 |
56,3 |
|
|
3 |
94,8 |
9 |
284,4 |
32,1 |
5,88 |
24,0 |
|
|
4 |
92,8 |
16 |
371,2 |
71,9 |
8,33 |
0,2 |
|
|
5 |
109,6 |
25 |
548 |
75,9 |
8,08 |
41,0 |
|
|
6 |
106,9 |
36 |
641,4 |
29,4 |
5,63 |
26,0 |
|
|
7 |
94,0 |
49 |
658 |
51,3 |
7,48 |
32,5 |
|
|
8 |
89,5 |
64 |
716 |
164,6 |
13,07 |
10,2 |
|
|
9 |
105,7 |
81 |
951,3 |
18,0 |
4,08 |
6,8 |
|
|
10 |
109,9 |
100 |
1099 |
56,3 |
7,58 |
5,8 |
|
|
11 |
97,1 |
121 |
1068,1 |
22,6 |
4,81 |
6,8 |
|
|
12 |
92,9 |
144 |
1114,8 |
97,4 |
9,69 |
0,3 |
|
|
13 |
114,9 |
169 |
1493,7 |
160,5 |
11,20 |
136,9 |
|
|
14 |
109,2 |
196 |
1528,8 |
39,6 |
6,39 |
9,0 |
|
|
15 |
95,6 |
225 |
1434 |
48,2 |
7,13 |
16,8 |
|
|
20 |
102,2 |
400 |
2044 |
0,2 |
0,37 |
114,5 |
|
|
21 |
99,2 |
441 |
2083,2 |
12,3 |
3,59 |
14,4 |
|
|
22 |
104,0 |
484 |
2288 |
1,0 |
1,05 |
59,3 |
|
|
23 |
112,3 |
529 |
2582,9 |
87,6 |
8,19 |
166,4 |
|
|
24 |
98,8 |
576 |
2371,2 |
23,7 |
4,49 |
49,0 |
|
|
Сумма |
230 |
2035,2 |
3670 |
23588 |
1008,3 |
122,49 |
778,2 |
|
Среднее |
11,5 |
101,8 |
183,5 |
1179,4 |
50,4 |
6,12 |
38,91 |
Вычислим параметры уравнения тренда.
= 0,17.
![]() = 99,85.
= 99,85.
В результате получим уравнение тренда:
T = 99,85 + 0,17×T.
Подставляя в это уравнение значения T = 1,2,…,16, найдем уровни T для каждого момента времени (гр. 5 табл. 2.3).
Шаг 5. Найдем уровни ряда, умножив значения T на соответствующие значения сезонной компоненты (гр. 6 табл. 2.3). На одном графике откладываем фактические значения уровней временного ряда и теоретические, полученные по мультипликативной модели.
Расчет ошибки в мультипликативной модели произведем по формуле:
![]()
Средняя абсолютная ошибка составила 1,0011 (см. гр. 7 табл. 2.3).
Рассчитаем сумму квадратов абсолютных ошибок ![]() .
.
Используя 5-й столбец таблицы 2.4, получим:
= 7,099.
Рассчитаем среднюю относительную ошибку: ![]() .
.
Используя 6-й столбец таблицы 2.4, получим, что средняя относительная ошибка составила 6,12%, т. е. построенная модель достаточно точно описывает динамику данного явления.
| < Предыдущая | Следующая > |
|---|
Тема 8. Доверительные интервалы прогноза. Оценка адекватности и точности моделей
Доверительные интервалы прогноза
Прогнозные значения исследуемого показателя вычисляют путем подстановки в уравнение кривой значений времени t, соответствующих периоду упреждения. Полученный таким образом прогноз называется точечным прогнозом. На практике в дополнение к точечному определяют границы возможного значения прогнозированного показателя, то есть вычисляют интервальный прогноз.
Несовпадение фактических данных с точечным прогнозом может быть вызвано:
1) субъективной ошибочностью выбора вида кривой;
2) погрешностью оценивания параметров кривых;
3) погрешностью, связанной с отклонением отдельных наблюдений от тренда.
Погрешность, связанная со вторым и третьим источником, может быть отражена в виде доверительного интервала прогноза. Доверительный интервал прогноза определяется в следующем виде:

Рекомендуемые материалы

Ширина доверительного интервала зависит от уровня значимости, периода упреждения, среднего квадратического отклонения от тренда и степени полинома. Чем выше степень полинома, тем шире доверительный интервал при одном и том же значении Sр, так как дисперсия уравнения тренда вычисляется как взвешенная сумма дисперсий соответствующих параметров уравнения
Доверительные интервалы прогнозов, полученных с использованием уравнения экспоненты, определяют аналогичным образом. Отличие состоит в том, что как при вычислении параметров кривой, так и при вычислении средней квадратической ошибки используют не сами значения уровней временного ряда, а их логарифмы.
По такой же схеме могут быть определены доверительные интервалы для ряда кривых, имеющих асимптоты, в случае, если значение асимптоты известно (например, для модифицированной экспоненты).
В таблице приведены значения K* в зависимости от длины временного ряда n и периода упреждения L для прямой и параболы. Очевидно, что при увеличении длины рядов (n) значения K* уменьшаются, с ростом периода упреждения L значения K* увеличиваются. При этом влияние периода упреждения неодинаково для различных значений n : чем больше длина ряда, тем меньшее влияние оказывает период упреждения L.

Например, для временного ряда розничного товарооборота региона, длиной 20, оценены параметры модели yt=10,2+1,2t, и дисперсия отклонений фактических значений от теоретических S2y=0.25. Используя эту модель рассчитать точечный и интервальный прогнозы в точке n=21.
Упрогн=10,2+1,2*21=35,4
Sy= =
=  =0.5
=0.5
K*=1.9117
Упрогн=35,4±0,5*1,9117=35,4±0,96=
Проверка адекватности выбранных моделей
Проверка адекватности выбранных моделей реальному процессу строится на анализе случайной компоненты. Случайная (остаточная) компонента получается после выделения из исследуемого ряда тренда и периодической составляющей. Предположим, что исходный временной ряд описывает процесс, не подверженный периодическими колебаниями, то есть примем гипотезу об аддитивной модели временного ряда:
Уt=ut+et
Тогда ряд случайной компоненты будет получен как отклонение фактических уровней временного ряда (yt) от выровненных, расчетных 


Принято считать, что модель адекватна описываемому процессу, если значения остаточной компоненты удовлетворяют свойствам независимости и подчиняются закону нормального распределения.
При правильном выборе вида тренда отклонения от него будут носить случайный характер. Это означает, что изменение остаточной случайной величины не связано с изменением времени. Таким образом, по выборке, полученной для всех моментов времени на изучаемом интервале, проверяется гипотеза о зависимости последовательности значений et от времени, или, что то же самое, о наличии тенденции в ее изменении. Поэтому для проверки данного свойства может быть использован один из критериев, например, критерий серий.
Если вид функции, описывающей тренд, выбран неудачно, то последовательные значения ряда остатков могут не обладать свойствами независимости, так как они могут коррелировать между собой. В этом случае имеет место явление автокорреляции.
В условиях автокорреляции оценки параметров модели будут обладать свойствами несмещенности и состоятельности.
Существует несколько приемов обнаружения автокорреляции. Наиболее распространенным является метод, предложенный Дарбиным и Уотсоном.
Критерий Дарбина-Уотсона связан с гипотезой о существовании автокорреляции первого порядка (то есть между соседними остаточными уровнями ряда). Значение этого критерия определяется по формуле:
d=
Можно показать, что величина d приближенно равна:

где r1- коэффициент автокорреляции первого порядка (т.е. парный коэффициент корреляции между двумя рядами e1, e2, … ,en-1 и e2, e3, …, en).
Из последней формулы видно, что если в значениях et имеется сильная положительная автокорреляция  ,то величина d=0 , в случае сильной отрицательной автокорреляции
,то величина d=0 , в случае сильной отрицательной автокорреляции  d=4. При отсутствии автокорреляции
d=4. При отсутствии автокорреляции  .
.
Для этого критерия найдены критические границы, позволяющие принять или отвергнуть гипотезу об отсутствии автокорреляции. Авторами критерия границы определены для 1, 2,5 и 5% уровней значимости.
Рассчитанные значения d сравнивают с табличными значениями. Здесь ( в таблице): d1 и d2 — соответственно нижняя и верхняя доверительная граница критерия d;
К – число переменных в модели
n – длина ряда.
При сравнении величины d с d1 и d2 возможны следующие ситуации:
1) d< d2, то гипотеза об отсутствии автокорреляции отвергается;
2) d> d2, то гипотеза об отсутствии автокорреляции не отвергается;
3) d1≤ d≤ d2, то нет достаточных основании для принятия решений, величина попадает в область неопределенности.
Рассмотренные варианты относятся к случаю, когда в остатках имеется положительная автокорреляция. Когда же расчетное значение d превышает 2, то можно говорить о том, что в et существует отрицательная автокорреляция. Для проверки отрицательной автокорреляции с критическими значениями d1 и d2 сравнивается не сам коэффициент d, а 4-d.
Поскольку временные ряды экономических показателей, как правило, небольшие, то проверка распределения на нормальность может быть произведена лишь приближенно на основе исследования показателей ассиметрии и эксцесса.
При нормальном распределении показатели ассиметрии и эксцесса равны нулю.
Можно рассчитать показатель ассиметрии и эксцесса, их средние квадратические ошибки:
А=

Э=

Если одновременно выполняются следующие неравенства:
 ,
,
то гипотеза о нормальном характере распределения случайной компоненты не отвергается.
Если выполняется хотя бы одно из следующих неравенств:
 ,
,
то гипотеза о нормальном характере распределения отвергается.
|
t |
Yt |
|
1 |
47 |
|
2 |
51 |
|
3 |
55 |
|
4 |
59 |
|
5 |
62 |
|
6 |
66 |
|
7 |
70 |
|
8 |
75 |
|
9 |
79 |
|
10 |
82 |
|
11 |
86 |
|
12 |
89 |
|
13 |
92 |
|
14 |
96 |
|
15 |
100 |
|
16 |
103 |
d=
Еt= уt-утеор
Yтеор=a0+a1t
а0= а1=
а1=
n=16
К´=1
d1=1.1
d2=1.37
d=1.4E-17
Гипотеза об отсутствии автокорреляции отвергается.
Характеристики точности моделей
Чтобы судить о качестве выбранной модели необходимо проанализировать систему показателей, характеризующих как адекватность модели, так и ее точность. О точности прогноза судят по величине ошибки прогноза.
Ошибка прогноза – это величина, характеризующая расхождения между прогнозным значением показателя и фактическим значением.
Абсолютная ошибка прогноза определяется по формуле:
 у прогн. – yt
у прогн. – yt
Относительная ошибка прогноза:
δt=
Используются также средние ошибки по модулю.
Абсолютная ошибка по модулю:

Относительная средняя ошибка по модулю:
S=
Если абсолютная и относительная ошибка >0, то это свидетельствует о завышенной прогнозной оценке, а если <0, то прогноз был занижен. Эти характеристики могут быть вычислены после того, как период упреждения уже закончился и имеются фактические данные о прогнозируемом показателе.
При проведении сравнительной оценки моделей прогнозирования применяются также дисперсия и среднее квадратическое отклонение:
S2=
S=
Чем меньше значение дисперсии и среднее квадратическое отклонение, тем выше точность модели.
О точности модели нельзя судить по одному значению ошибки прогноза, поскольку единичный хороший прогноз может быть получен и по плохой модели, поэтому о качестве применяемых моделей можно судить лишь по совокупности сопоставлений прогнозных значений с фактическими.
Простой мерой качества прогнозов может служить характеристика  . Это относительное число случаев, когда фактическое значение охватывалось интервальным прогнозом:
. Это относительное число случаев, когда фактическое значение охватывалось интервальным прогнозом:
 ,
,
где Р – число прогнозов, подтвержденных фактическими данными;
q – число прогнозов, не подтвержденных фактическими данными.
Сопоставление характеристик для разных моделей может иметь смысл при условии, что доверительные вероятности приняты одинаковыми.
|
t |
yt |
|
|
Условное время |
Утеор |
|
1 |
91,6 |
— |
— |
-5 |
91,64 |
|
2 |
91,5 |
-0,1 |
— |
-4 |
91,47 |
|
3 |
91,3 |
-0,2 |
-0,1 |
-3 |
92,3 |
|
4 |
91,1 |
-0,2 |
0 |
-2 |
91,13 |
|
5 |
91,0 |
-0,1 |
0,1 |
-1 |
90,96 |
|
6 |
90,8 |
-0,2 |
-0,1 |
0 |
90,79 |
|
7 |
90,6 |
-0,2 |
0 |
1 |
90,62 |
|
8 |
90,4 |
-0,2 |
0 |
2 |
90,45 |
|
9 |
90,2 |
-0,2 |
0 |
3 |
90,28 |
|
10 |
90,0 |
-0,2 |
0 |
4 |
90,11 |
|
11 |
89,9 |
-0,1 |
0,1 |
5 |
89,94 |
|
Итого |
-17 |
0 |


-0,1-(-0,2)=0,1

Утеор = 90,79-0,17t
|
Месяц |
Прогнозное значение |
Фактическое значение |
|
|
1 модель |
2 модель |
||
|
Апрель |
35400 |
36300 |
36505 |
|
Май |
41600 |
Ещё посмотрите лекцию «34 Девиация» по этой теме. 99200 |
40524 |
|
Июнь |
45600 |
43100 |
45416 |