
Расчеты по определению средней величины и среднеквадратичного отклонения для сгруппированного вариационного ряда
(I—обычный
способ, II—способ
моментов)
|
Возраст |
Число |
I |
II |
|||||||||||
|
Vp |
D=V-M |
dp |
d2 |
d2р |
d=V-A |
Dp |
d2 |
d2р |
||||||
|
39 |
1 |
39 |
-10,3 |
-10,3 |
|
-72,9 |
105,09 |
103,09 |
-9,0 |
-9,0 |
|
-56,0 |
81,0 |
81,0 |
|
41 |
1 |
41 |
-8,3 |
-8,3 |
68,89 |
68,89 |
-7,0 |
-7,0 |
49,0 |
49,0 |
||||
|
42 |
4 |
168 |
-7,3 |
-29,2 |
53,29 |
213,16 |
-6,0 |
-24,0 |
36,0 |
144,0 |
||||
|
43 |
2 |
86 |
-6,3 |
-12,3 |
39,69 |
79,38 |
-5,0 |
-10,0 |
25,0 |
50,0 |
||||
|
46 |
3 |
138 |
-3,3 |
-9,9 |
10,89 |
32,67 |
-2,0 |
-6,0 |
4,0 |
12,0 |
||||
|
48 |
2 |
96 |
-1,3 |
-2,6 |
1,69 |
3,38 |
0,0 |
0,0 |
0,0 |
0,0 |
||||
|
50 |
4 |
200 |
0,7 |
2,8 |
0,49 |
1,96 |
2,0 |
8,0 |
4,0 |
16,0 |
||||
|
52 |
3 |
156 |
2,7 |
8,1 |
|
+72,9 |
7,29 |
24,81 |
4,0 |
12,0 |
|
+95,0 |
16,0 |
48,0 |
|
54 |
5 |
270 |
4,7 |
23,5 |
22,09 |
110,45 |
6,0 |
30,0 |
36,0 |
180,0 |
||||
|
56 |
4 |
224 |
6,7 |
26,8 |
44,89 |
179,56 |
8,0 |
32,0 |
64,0 |
256,0 |
||||
|
61 |
1 |
61 |
11,7 |
11,7 |
136,89 |
136,89 |
13,0 |
13,0 |
169,0 |
169,0 |
||||
|
n=30 |
Σdp=0 |
Σd2 |
Σdp=39 |
Σd2 |




Средняя
арифметическая имеет следующие свойства:
-
сумма
отклонений от средней равна нулю (см.
табл. 2, гр. 5); -
при
умножении (делении) всех вариант на
один и тот же множитель (делитель)
средняя арифметическая умножается
(делится) на тот же множитель (делитель); -
если
прибавить (вычесть) ко всем вариантам
одно и то же число, средняя арифметическая
увеличивается (уменьшается) на то же
число.
Эти
свойства могут быть использованы для
облегчения и упрощения
расчета средней арифметической.
Первое
свойство, например, служит обоснованием
для расчета средней
арифметической по способу моментов.
Как
видно из табл. 2 (гр. 5), сумма всех отклонений
вариант от средней
равна нулю (отклонение d
— это разность между каждой вариантой
и средней величиной, т. е. d
= V-M).
Поскольку в сгруппированном вариационном
ряду варианты имеют различную частоту,
то
каждая из них в итоге дает отклонения,
зависящие от этой повторяемости.
Следовательно, значение отклонения
варианты необходимо умножить на частоту,
а затем суммировать все эти произведения.
Каждая
варианта отклоняется от средней величины
в большую или меньшую
сторону со знаком «+» или «-». Эти значения
следует учитывать
при проведении вычислений. Сумма
отрицательных отклонений
равна -72,9, сумма положительных отклонений
составляет 72,9,
а итоговая сумма всех отклонений равна
нулю (Σdp
= 0). Это свидетельствует о том, что средняя
величина действительно есть общая
количественная характеристика данного
вариационного ряда, так как она
взаимоисключает, взаимоуничтожает все
отклонения. Это свойство
положено в основу вычисления средней
величины по способу
моментов. Значение средней определяется
по формуле
![]() ,
,
где
А
является
условной средней величиной. Если А
является
истинной средней, т. е. А = М, то сумма ее
отклонений будет равна
нулю, если же она не является истинной
средней, то сумма отклонений
будет иметь значение, отличное от нуля,
и явится основой для
определения поправки. В табл. 2 (II
способ) показаны этапы вычисления
средней величины по способу моментов
(А = 48). Из гр. 9 табл. 2 видно,
что сумма отклонений Σdp
равна 39. С учетом поправки легко определить
действительное значение средней
величины, подставив соответствующие
значения в формулу:
![]()
Таким
образом, полученное значение средней
арифметической
величины по способу моментов идентично
таковому, найденному обычным
способом.
При
выборе условной средней А
следует
ориентироваться на моду
или медиану.
Способ
моментов значительно упрощает расчеты
и делает их более
быстрыми.
Второе
свойство средней арифметической полезно
применять при
анализе вариационного ряда, состоящего
либо из очень больших, либо
из очень малых величин. Имеются, например,
варианты: 0,0001; 0,0002;
0,0003. Используя это свойство, увеличим
их в 10000 раз. Получим
величины 1, 2, 3. Средняя арифметическая
из них равна 2, а
искомая средняя арифметическая в 10000
раз меньше, т. е. 0,0002.
При
обработке вариационного ряда, состоящего
их положительных и отрицательных
значений, иногда бывает полезно прибавить
ко всем вариантам такое число, чтобы
сделать их все положительными.
Из полученного среднего результата эту
величину следует вычесть.
Например, имеются величины: +10, +5, -3, -1,
+6, -1, -2. Определим
среднюю арифметическую:
![]()
Чтобы
избавиться от отрицательных величин,
можно использовать
третье свойство средней арифметической,
т. е. прибавить к каждой варианте
определенное число, например, в нашем
случае 4. Тогда величины
приобретут следующий вид: 14, 9, 1, 3, 10, 3,
2. Их сумма равна
42. При делении на 7 получим 6. При вычитании
4 из 6 получим среднюю
арифметическую величину 2.
МЕТОДЫ
ОЦЕНКИ КОЛЕБЛЕМОСТИ РЯДА
И
ТИПИЧНОСТИ СРЕДНИХ ВЕЛИЧИН
Средние
арифметические величины, взятые сами
по себе без учета колеблемости
рядов, из которых они вычислены, имеют
подчас ограниченное
значение. Средние — это величины, вокруг
которых рассеяны различные варианты,
поэтому понятно, что чем ближе друг к
другу отдельные
варианты по своей количественной
характеристике, тем меньше
рассеяние, колеблемость ряда, тем
типичнее его средняя. Одинаковые по
размеру средние могут быть получены из
рядов с различной
степенью рассеяния.
Приблизительно
о колеблемости можно судить по амплитуде
(размаху)
вариационного ряда — разности максимальной
и минимальной вариант. Символика
обозначения амплитуды: Am
= Vmax-Vmin.
Основной,
общепринятой мерой колеблемости
вариационного ряда
является среднее квадратическое
отклонение, обозначаемое греческой
буквой σ (сигма малая).
Чем
больше среднее квадратическое отклонение,
тем, следовательно,
степень колеблемости данного ряда выше.
Так, при определении средней длительности
послеоперационного лечения аппендицита
в двух больницах были получены следующие
результаты:
-
Больница
1Больница
2М=9
днейМ=9
днейσ
=±2 дняσ
=±4 дня
Средняя
длительность лечения в обеих больницах
одинакова. Однако в первой больнице
сроки послеоперационного лечения у
отдельных
больных были близки к 9 дням. Во второй
больнице колебания были
значительнее, отсюда и среднеквадратическое
отклонение здесь больше,
и следовательно, полученная средняя
величина послеоперационного
периода является менее типичной, чем в
первой больнице.
Среднее
квадратическое отклонение характеризует
среднее отклонение
всех вариант вариационного ряда от
средней арифметической
величины. Поскольку отклонения вариант
от средней, как было
сказано выше, имеют значения с «+» и «-»,
то при суммировании
они взаимоуничтожаются. Чтобы избежать
этого, отклонения возводятся
во вторую степень, а затем, после
определенных вычислений,
производится обратное действие —
извлечение корня квадратного. Поэтому
среднее отклонение именуется
квадратическим.
Среднее
квадратическое отклонение определяют
по формуле:
![]()
Ход
вычислений при определении
среднеквадратического отклонения
следующий:
-
возвести
каждое отклонение d
во
вторую степень; -
умножить
квадрат каждого отклонения d2
на
соответствующую
частоту р; -
суммировать
полученные произведения Σd2p
; -
разделить
данную сумму на количество вариант,
входящих в
вариационный ряд n
(при числе наблюдений менее 30 сумма
делится
на n-1); -
извлечь
квадратный корень из полученного
частного.
![]()
Расчеты
представлены в табл. 2 (I
способ). Подставив полученные значения
в формулу, находим среднеквадратическое
отклонение:
![]()
При
вычислении среднеквадратического
отклонения по способу
моментов используется следующая формула:

В
чем суть этой формулы? Как видно, первая
часть данного подкоренного выражения
![]() полностью
полностью
идентична вышеприведенной
формуле вычисления среднеквадратического
отклонения обычным
способом
![]() .
.
Однако необходимо указать, что отклонения,
находимые для условной средней А,
заведомо
будут ошибочными, т. е. отличными от
отклонений, которые определяются для
фактической средней
М.
Учитывая
это обстоятельство, в формулу вносится
поправка, которая определяется для
условной средней А.
Эта
поправка называется
моментом первой степени
![]() .
.
Для
разбираемого нами случая она
равна + 1,3
(см. с. 11).
Поскольку поправка вносится в подкоренное
выражение,
то она возводится во вторую степень.
Первая
часть формулы
![]() называется моментом второйстепени,
называется моментом второйстепени,
т. к. отклонение d
возведено
во вторую степень.
Таким
образом, формула вычисления
среднеквадратического отклонения
по способу моментов будет читаться как
корень квадратный
из
разности момента второй степени и
квадрата момента первой степени.
Определим
среднеквадратическое отклонение по
способу моментов
для рассматриваемого
нами примера (табл. 2). Подставив значения
в формулу,
находим:

Результаты
вычисления среднеквадратического
отклонения обычным способом и способом
моментов идентичны. Однако, как указывалось
выше, второй способ значительно убыстряет
и упрощает
расчеты.
Итак,
нахождение среднеквадратического
отклонения позволяет
судить о характере однородности
исследуемой группы наблюдений. Если
величина среднеквадратического
отклонения небольшая, то
это свидетельствует о достаточно высокой
однородности изучаемого
явления. Среднюю арифметическую в таком
случае следует признать
вполне характерной для данного
вариационного ряда. Однако
слишком малая величина сигмы заставляет
думать об искусственном
подборе наблюдений. При очень большой
сигме средняя арифметическая в меньшей
степени характеризует вариационный
ряд,
что говорит о значительной вариабельности
изучаемого признака
или явления или о неоднородности
исследуемой группы.
Оценка
степени рассеяния вариант около средней
может быть произведена с помощью
коэффициента вариации, вычисляемого
по формуле:
![]()
Значения
коэффициента вариации С менее 10%
свидетельствует
о малом рассеянии, от 10 до 20% — о среднем,
более 20% — о сильном
рассеянии вариант вокруг средней
арифметической.
Возвращаясь
к нашему примеру (табл. 1 и 2), дадим
характеристику
изучаемому вариационному ряду.
Амплитуда
этого вариационного ряда равна 22 годам
(61-39 = 22),
σ
=±5,64,
![]() .
.
Расчеты
свидетельствуют о среднем рассеянии
вариант, следовательно, средняя
арифметическая величина вполне типична,
а исследуемая
группа наблюдений является достаточно
однородной.
Коэффициент
вариации часто используется при оценке
колеблемости рядов различных признаков,
например, веса и роста. Непосредственное
сравнение сигм в данном случае невозможно,
т. к. среднеквадратическое
отклонение — величина, именованная и
выраженная абсолютным числом. Предположим,
что при изучении физического
развития группы подростков коэффициент
изменчивости для веса составил 9,7%, а
для роста — 4,6%. Эти цифры можно сравнить
и сделать заключение, что в данном
примере рост является более
устойчивым признаком, чем вес.
Определение
среднеквадратического отклонения
представляет
немалую ценность для медицинской науки
и практики. При диагностике
отдельных заболеваний очень важно
оценить на основании конкретных
исследований, какие признаки проявляются
у соответствующей
группы больных относительно одинаково,
с небольшими колебаниями,
а для каких признаков характерны большие
индивидуальные
колебания. Очень широко используется
это свойство при оценке
физического развития отдельных групп
населения, при выработке
стандартов школьной мебели и т. д.
Согласно
теории вероятности в явлениях,
подчиняющихся нормальному
закону распределения, между значениями
средней арифметической, среднеквадратического
отклонения и вариантами существует
строгая зависимость (правило трех сигм).
Например, 68,3% значений
варьирующего признака находятся в
пределах М ± 1σ , 95,5% — в пределах М ± 2σ
и 99,7% — в пределах М ± Зσ .
Данные,
полученные эмпирически, не всегда строго
совпадают с
теоретическими, но они тем ближе к ним,
чем больше число наблюдений
и однороднее их состав.
Более
подробно о применении правила трех сигм
можно познакомиться
в руководствах или пособиях по медицинской
статистике.
ОПРЕДЕЛЕНИЕ
ОШИБКИ РЕПРЕЗЕНТАТИВНОСТИ
Полученная
средняя арифметическая М
при
повторных исследованиях
под влиянием случайных явлений может
колебаться на ту или иную
величину. Это обусловлено тем, что
исследуется, как правило,
только
часть изучаемых явлений, то есть
выборочная совокупность. Сумма же всех
единиц, представляющих изучаемое
явление, называется генеральной
совокупностью. Результаты, полученные
на основе
выборочной совокупности, как правило,
переносятся на генеральную
совокупность. Чтобы определить степень
точности выборочного
наблюдения, необходимо оценить величину
ошибки, которая может
случайно произойти в процессе выборки.
Такие ошибки носят название
случайных ошибок репрезентативности
т
или
средней ошибки
средней арифметической. Они фактически
являются разностью
между средними числами, полученными
при выборочном статистическом
наблюдении, и аналогичными величинами,
которые были бы
получены при сплошном исследовании
того же объекта (т. е. при исследовании
генеральной совокупности).
Ошибки
репрезентативности нельзя смешивать
с ошибками регистрации или ошибками
внимания (описки, просчеты, опечатки и
др.), которые должны быть сведены до
минимума.
Ошибки
репрезентативности вытекают из самой
сущности выборочного
исследования. С помощью ошибок
репрезентативности числовые характеристики
выборочной совокупности распространяются
на всю генеральную совокупность, то
есть она характеризуется с учетом
определенной погрешности.
Величины
ошибок репрезентативности определяются
как объемом
выборки, так и разнообразием признака.
Чем больше число наблюдений,
тем меньше ошибка, чем больше изменчив
признак, тем больше
величина статистической ошибки.
На
практике для определения средней ошибки
выборки в статистических
исследованиях пользуются следующей
формулой:
![]()
где
m
— ошибка репрезентативности
σ
— среднее квадратическое отклонение;
n
— число наблюдений в выборке (при числе
наблюдений менее 30
в подкоренное выражение вносится
значение п-1).
Из
формулы видно, что размер средней ошибки
прямо пропорционален
среднему квадратичному отклонению, т.
е. вариабельности изучаемого
признака, и обратно пропорционален
корню квадратному из
числа наблюдений.
Для
рассматриваемого нами случая ошибка
репрезентативности равна:
![]()
ОПРЕДЕЛЕНИЕ
ДОВЕРИТЕЛЬНЫХ ГРАНИЦ
Определение
величины ошибки репрезентативности
необходимо для нахождения
возможных значений генеральных
параметров. Оценка генеральных параметров
проводится в виде двух значений —
минимального и максимального. Эти
крайние значения возможных отклонении,
в пределах
которых может колебаться искомая средняя
величина генерального
параметра, называются доверительными
границами.
Согласно
теории вероятностей можно предположить
с достоверностью в 99,7%, что эти крайние
значения отклонений будут не больше
величины
утроенной ошибки репрезентативности
(М ± Зm);
в 95,5% — не больше
величины удвоенной средней ошибки
средней величины (М
± 2m);
в 68,3% — не больше величины одной средней
ошибки (М±1m).
ПРИМЕЧАНИЕ.
При малой выборке (менее 30) величину
доверительного
коэффициента необходимо определять
каждый раз в зависимости от числа
наблюдений по таблице Стьюдента.
Предположим,
что с учетом аналогичных условий будут
повторяться
исследования на выявление среднего
возраста больных с инфарктом
миокарда, которое было взято нами в
качестве примера, так
как, естественно, количество больных
инфарктом не замкнется количеством 30
человек. Можно ожидать, что полученные
при этом средние,
хотя бы и близкие по величине, все же
будут отличаться друг от
друга. Используя методику определения
доверительных границ, нетрудно
найти возможные колебания среднего
возраста больных инфарктом
миокарда. В медико-биологических
исследованиях чаще всего
используется 95% вероятность. Таким
образом, с учетом двойной
ошибки репрезентативности, если будут
продолжаться исследования
по определению среднего возраста больных
инфарктом миокарда,
можно определить, что средний возраст
будет находиться в пределах
следующих возрастных периодов: от 47,3
до 51,3 лет.
Таблица
3
Таблица
значений критерия t
(Стьюдента)
|
k |
Уровень |
||
|
95% |
99% |
99,9% |
|
|
1 |
12,7 |
63,6 |
636,6 |
|
2 |
4,3 |
9,9 |
31,6 |
|
3 |
3,1 |
5,8 |
12,9 |
|
4 |
2,7 |
4,6 |
8,6 |
|
5 |
2,5 |
4,0 |
6,8 |
|
6 |
2,4 |
3,7 |
5,9 |
|
7 |
2,3 |
3,5 |
5,4 |
|
8 |
2,3 |
3,3 |
5,1 |
|
9 |
2,2 |
3,2 |
4,7 |
|
10 |
2,2 |
3,1 |
4,6 |
|
11 |
2,2 |
3,1 |
4,4 |
|
12 |
2,2 |
3,0 |
4,3 |
|
13 |
2,1 |
3,0 |
4,2 |
|
14 |
2,1 |
2,9 |
4,1 |
|
15 |
2,1 |
2,9 |
4,0 |
|
16 |
2,1 |
2,9 |
4,0 |
|
17 |
2,1 |
2,8 |
3,9 |
|
18 |
2,1 |
2,8 |
3,9 |
|
19 |
2,0 |
2,8 |
3,8 |
|
20 |
2,0 |
2,8 |
3,8 |
|
21 |
2,0 |
2,8 |
3,8 |
|
22 |
2,0 |
2,8 |
3,7 |
|
23 |
2,0 |
2,8 |
3,7 |
|
24 |
2,0 |
2,7 |
3,7 |
|
25 |
2,0 |
2,7 |
3,7 |
|
26 |
2,0 |
2,7 |
3,7 |
|
27 |
2,0 |
2,7 |
3,6 |
|
28 |
2,0 |
2,7 |
3,6 |
|
29 |
2,0 |
2,7 |
3,6 |
|
30 |
2,0 |
2,7 |
3,6 |
|
∞ |
1.9 |
2.5 |
3.3 |
Расчеты
по определению доверительных границ в
этом случае выглядят следующим образом:
М±2m=49.3±2*1.0=49.3±2.0=47.3-51.3
(лет)
ПРИМЕЧАНИЕ:
В руководствах по санитарной статистике
средняя величина генеральной совокупности
обозначается
![]() ,
,
а выборочной –
![]()
ПОНЯТИЕ
О РАСПРЕДЕЛЕНИИ ПРИЗНАКА
В
СТАТИСТИЧЕСКОЙ СОВОКУПНОСТИ
Элементы,
составляющие статистическую совокупность,
имеют различные
по величине значения изучаемого признака,
и каждое из этих значений
встречается в группе с неодинаковой
частотой. Зависимость
между значением величины признака и
частотой, с которой оно встречается,
называется характером распределения
признака. Его можно
определить только на достаточно большой
совокупности наблюдений.
Изучая характер распределения признака,
получают важную
информацию о закономерностях, присущих
тому или иному явлению,
а также возможность правильно выбрать
статистические критерии
для анализа и обобщения.

Типы
распределения статистической совокупности
В
медицинских исследованиях встречаются
разные по характеру
распределения: альтернативный, нормальный
(симметричный), асимметричный
(правосторонний, левосторонний, двугорбый
— бимодальный) и др. На рисунке показаны
основные типы распределения статистической
совокупности.
Чаще
других типов встречается нормальное
распределение, которое в статистике
называют еще распределением Гаусса.
Оно характеризуется
не только симметричностью, но также
«ниспадающими» концами
кривой распределения. При таком
распределении признака в вариационном
ряду мода, медиана и средняя арифметическая
практически
совпадают по значению. Нормальный
характер распределения обычно
наблюдается в рядах, вариантами которых
являются количественные
признаки: рост, масса тела, уровень
артериального давления, сроки
госпитализации и др. Следует также
отметить, что с помощью критерия
Стьюдента t
можно сравнивать вариационные ряды
именно с нормальным
характером распределения признака.
ОПРЕДЕЛЕНИЕ
ДОСТОВЕРНОСТИ РАЗЛИЧИЙ
СРЕДНИХ
ВЕЛИЧИН
В
научно-исследовательской практике
часто бывает необходимо сравнение
двух средних арифметических величин,
например, при сравнении
результатов в контрольной и экспериментальной
группах, при сравнении
показателей здоровья населения в
различных местностях за различные
годы и т. д.
Применяемый
метод оценки достоверности средних
величин позволяет установить, насколько
выявленные различия существенны,
то есть носят ли они достоверный характер
или являются результатом
действия случайных причин.
В
основе метода лежит определение так
называемого критерия Стьюдента
t
(коэффициента достоверности). Величина
его определяется
отношением разности сравниваемых
средних величин к ошибке
их разности. Ошибка разности равна корню
квадратному из суммы квадратов
средних ошибок сравниваемых величин
![]() .
.
Таким
образом, коэффициент достоверности
определяется по формуле:
![]()
2
где
М1
— средняя величина первого
исследования;
М2
— средняя величина второго исследования;
m1
и m2
— ошибки репрезентативности сравниваемых
средних величин.
Критерий
достоверности t
указывает, во сколько раз разность
сравниваемых
средних превышает их ошибку. При различных
значениях
критерия существует определенная мера
надежности, которая говорит
о существенности, достоверности
выявленных различий между
сравниваемыми средними.
В
медико-биологических исследованиях
достаточно иметь значение
t,
равное или больше 2, тогда выявленные
различия не случайны, достоверны,
статистически подтверждены (с вероятностью
более 95%).
Если значение критерия меньше 2, то
разница не доказана, носит
случайный характер, статистически не
подтверждается (вероятность
менее 95%).
Пример.
У
47
больных
с хронической пневмонией с легочной
недостаточностью
I
степени среднее количество циркулирующей
крови M1
составило 6,64 л (m1
= ±0,17 л). В контрольной группе (56 человек)
эти
показатели составили: М2
= 6,12 л, m2
= ± 0,13 л.
Разность
среднего количества циркулирующей
крови у больных хронической пневмонией
I
стадии и контрольной группы оказалась
вполне убедительной:
![]()
При
числе наблюдений в каждой группе менее
30 коэффициент достоверности необходимо
каждый раз определять по таблице
Стьюдента.
ОЦЕНКА
ДОСТОВЕРНОСТИ РЕЗУЛЬТАТОВ
СТАТИСТИЧЕСКОГО
ИССЛЕДОВАНИЯ
ПРИ
ИСПОЛЬЗОВАНИИ ОТНОСИТЕЛЬНЫХ ПОКАЗАТЕЛЕЙ
Определение
средней ошибки для относительных
показателей производится
по формуле:
![]()
где
Р
— величина относительного
показателя;
q
— величина, обратная Р и выраженная как
(1-Р), (100-Р), (ЮОО-Р)
и т. д., в зависимости от основания, на
которое рассчитан показатель;
n
— число наблюдений в выборочной
совокупности (для числа наблюдений
менее 30 берется n-1).
Зная
средние ошибки относительных показателей,
по аналогии со
средними арифметическими величинами
можно определять доверительные границы
генеральной совокупности и использовать
метод оценки
достоверности разности этих показателей.
При этом используется следующая формула.
Пример.
В
городе А со 135000 населения заболело
гриппом 1600 человек,
в городе Б с 68000 населения заболело 500
человек. Заболеваемость
на 1000 человек в городе А составила 11,85,
в городе Б — 7,35. Требуется
определить, является ли преобладание
заболеваемости гриппом
в городе А случайным или оно определяется
какими-то причинами,
предположим, санитарно-эпидемиологического
характера.
Находим
средние ошибки показателей:
![]()
![]()
Определяем
коэффициент достоверности:
![]()
Показатель
достоверности значительно превышает
значение t
> 2, при
котором разница признается достоверной.
Следовательно, уровни заболеваемости
в городах А и Б носят неслучайный
характер. Необходимо
найти причины, способствующие более
интенсивному распространению гриппа
в городе А.
С![]() ледовательно,
ледовательно,
для определения доверительных границ
значения
средней арифметической генеральной
совокупности
используют формулу: ,
а
для относительных показателей эта
формула
имеет вид:![]() .
.
,
Вопросы
для самопроверки
-
С
какой целью используются в медицинских
исследованиях средние величины
и их параметры? -
Перечислите
основные направления в медицинских и
социально-гигиенических
исследованиях, где широко используются
средние величины. -
Дайте
определение средней величины. -
Какие
требования предъявляются при работе
со средними величинами? -
Дайте
определение вариационного ряда. -
Какие
типы количественных вариаций различают? -
Какие
учетные признаки можно использовать
для построения вариационного
ряда и расчета средней арифметической? -
Назовите
основные элементы вариационного ряда. -
Как
вычисляется средняя арифметическая
простая? -
Как
вычисляется средняя арифметическая
взвешенная? -
Назовите
основные свойства средней арифметической
величины. -
Какие
особенности лежат в основе расчетов
средней арифметической величины по
способу моментов? -
Что
такое среднее квадратическое отклонение
и его значение? -
Укажите
особенности, на которых основано
вычисление среднего квадратического
отклонения по способу моментов. -
Роль
коэффициента вариации и его применение. -
Понятие
о достоверности полученных данных
(ошибка репрезентативности). -
Чем
определяется величина ошибки
репрезентативности? -
Какова
формула ошибки (т) для относительных
показателей? -
Как
определяются доверительные границы
средней в генеральной совокупности
и с какой целью? -
Как
определяется достоверность различий
средних величин, для каких
целей? -
Как
определяется достоверность различий
относительных показателей?
Вариант
1
А.
В районе N,
где расположена тепловая электростанция,
в одной из точек жилого поселка было
взято 125 проб атмосферного воздуха,
в результате чего установлено, что
средняя концентрация пыли
составляла 0,26 мг/м3,
σ1
=
±0,08 мг/м3
, m1
= ±0,007 мг/ м3
После
введения золоуловителя количество пыли
измерялось следующими
цифрами: 0,09 мг/м3
— 2 раза, 0,08 мг/м3
— 2 раза, 0,15
мг/м3
—16 раз, 0,12мг/м3
—14раз, 0,14мг/м3
— 30 раз, 0,16 мг/м3
— 4
раза, 0,13 мг/м3
— 16 раз, 0,11
мг/м3
— 9 раз, 0,10 мг/м3
— 5 раз, 0,17 мг/м3
—2 раза.
Составьте
ранжированный сгруппированный
вариационный ряд.
Определите, достоверно ли уменьшение
среднесуточной концентрации пыли после
введения в действие золоуловителя?
Б.
Сравните характер разнообразия веса у
новорожденных, детей первого года жизни
и семилетних, если известны следующие
параметры:
-
Возраст
Средний
вес (М), кгσ,
кгНоворожденные
3,4
±
0,51
год10,5
±
0,87
лет22,9
±
2,7
В.
Группа больных в количестве 130 человек
применяла при лечении
лекарственный препарат Z
в течение 5 дней. У 106 человек наступило
полное выздоровление. Определите
доверительные границы
с вероятностью безошибочного прогноза
(р = 95%), при которых может
наступать выздоровление больных.
Вариант
2
А.
В N-ской
районной больнице в истекшем календарном
году число дней занятости койки в году
было представлено следующем образом:
4 койки — 285 дней, 4 — 290, 8 — 295, 8 — 300, 16 —
315, 20
— 320, 24 — 325, 40 — 330, 50 — 335, 24 — 340, 20 — 347,
10 — 350,8
— 355,4 — 360.
Составьте
сгруппированный вариационный ряд.
Определите среднегодовую
занятость койки. Определите также,
достоверно ли отличается показатель
среднегодовой занятости койки в больнице
N-ского
района от аналогичного показателя
больницы соседнего района, если известно,
что он составлял 341 день (m
= ± 3,5дня).
Б.
Сравните характер разнообразия
лабораторных анализов с различной
размерностью, которые приведены ниже:
-
Наименование
тестаСредний
показательσ
Общий
белок крови, мг%6,8
±
0,4СОЭ,
мм/ч9
±
2Лейкоциты
8000
±
800
В.
При обследовании 280 учащихся 3-х классов
пяти школ района
К у 64 из них было обнаружено нарушение
осанки. Определите
доверительные границы (р = 95%) частоты
нарушения осанки у школьников
третьих классов остальных школ района
К.
Вариант
3
А.
При обследовании группы школьников 4-х
классов сельского района
А было установлено, что в среднем на
одного человека приходится
2,98 кариозных зуба (m
= ±0,26).
При обследовании аналогичной
группы школьников в районе Б были
получены следующие
результаты: 2 человека имели по 5 кариозных
зубов, 28 — по 1, 8
— по 4,1 — 8, 20 — по 3,16 — по 2 и 6 человек
не имели пораженных кариесом
зубов.
Составьте
ранжированный сгруппированный
вариационный ряд.
Определите интенсивность поражения
кариесом школьников района Б и установите,
достоверно ли она отличается от такого
же показателя
в районе А.
Б.
Сравните характер разнообразия
антропометрических данных
у мальчиков 7-летнего возраста, которые
представлены ниже:
-
Показатель
М
σ
Рост,
см123,4
±
4,9Вес,
кг24,2
±
3,1Окружность
грудной клетки, см60,1
±
2,5
В.
При выборочном обследовании 220 рабочих
одного из промышленных предприятий у
47 из них были выявлены гастроэнтерологические
заболевания. Определите доверительные
границы (р=95%)
возможной частоты гастроэнтерологических
заболеваний среди
всех работающих на предприятии.
Вариант
4
А.
Перед сдачей экзамена по гигиене у
студентов определялась
частота пульса. Были получены следующие
данные: у 2 студентов
— 76 ударов в минуту, у 3 — 80, у 4 — 108, у 2
— 116, у 20 — 88, у
6—98, у 17 —86, у 11 —92.
Составьте
вариационный ряд. Определите среднюю
частоту пульса
у студентов перед экзаменом. Определите
также, достоверно ли отличается показатель
частоты пульса перед экзаменом от
частоты
пульса у этих же студентов после
экзаменов, если известно, что она
составляла 72,4 (m
= ± 3,0).
Б.
Сравните характер разнообразия
антропометрических данных у девушек
17-летнего возраста, которые представлены
ниже:
-
Показатель
М
σ
Рост,
см161,2
±
5,1Вес,
кг55,8
±
7,2Жизненная
емкость легких, см33400
±
250
В.
Было осмотрено 185 учеников 5-х классов.
У 26 из них обнаружена
миопия. Определите доверительные границы
(р = 95%) возможной
частоты близорукости у школьников 5-х
классов в школах данного района.
Вариант
5
А.
Исследовалась длительность лечения
больных пневмонией в стационаре
центральной районной больницы N-ского
района. Были получены
следующие результаты: 25 дней лечилось
2 больных, 26 —1, 11
—1, 12 —1,23 —3, 13 — 1,21
— 3,24 — 1,22 — 3, 14 — 2,20 — 5, 15 — 2, 16 — 3, 17 —
4, 19 — 8, 18 — 7. Составьте ранжированный
сгруппированный
вариационный ряд. Рассчитайте по способу
моментов среднюю
длительность лечения пневмонии.
Определите, достоверно ли
отличается средняя длительность лечения
пневмонии от аналогичного
показателя соседнего района, если
известно, что она составила 23
дня (m
= ± 1,3
дня).
Б.
Сравните характер разнообразия
антропометрических данных у 12-летних
мальчиков:
-
Показатель
М,
смσ,
смРост
142,0
±
8,5Окружность
грудной клетки66,0
±
4,0Окружность
головы50,0
±
2,0
В.
Исследовано 110
больных абсцессом легкого, у 36 из них
обнаружена
дистрофия пародонта. Определите
доверительные границы
(р = 95%) возможной частоты дистрофии
пародонта при абцессе легкого.
Вариант
6
А.
Исследовалась длина тела новорожденных
девочек по данным
родильного дома. Были получены следующие
данные: у 8 девочек рост составил 48
см, у 6 — 51, у 7 — 53, у 1 — 49, у 9 — 52, у 8 —
50,
у 1 — 47, у 2 — 46, у 2 — 54, у 1 — 55, у 1 — 56.
Составьте ранжированный сгруппированный
вариационный ряд, определите среднюю
длину тела новорожденных девочек и
достоверно ли она отличается от длины
тела новорожденных мальчиков, если по
данным
этого же родильного дома мальчики имели
среднюю длину тела 51
см(m=
±2,3 см).
Б.
Сравните характер разнообразия
антропометрических данных
у 12-летних девочек:
-
Показатель
м
σ
Рост,
см140
±
9,5Масса
тела, кг40
±
6Жизненная
емкость легких, см2300
±
460
В.
При выборочном обследовании 150 ткачих
хлопчатобумажного комбината у 32 из них
обнаружена гинекологическая патология.
Определите
доверительные границы (р = 95%) возможной
частоты гинекологической патологии у
всех работниц этого комбината

![]()
Загрузить PDF
![]()
Загрузить PDF
Нужно вычислить средний возраст некоторой группы людей? Это довольно просто. Вычисления представляют собой трехэтапный процесс, который легко понять и запомнить.
-

1
Составьте список всех возрастов. Вычислить среднее значение довольно легко. В вычислениях нужно учесть все числа набора данных. Поэтому запишите все числа (в данном случае возрасты) или внесите их в таблицу.[1]
-
2
Найдите сумму всех записанных возрастов. Для этого сложите все числа. Например, рассмотрим группу из пяти человек следующих возрастов: 31, 30, 26, 21, 10. Сумма этих чисел равна 118.[2]
-
3
Разделите полученную сумму на количество чисел (возрастов). Так вы найдете средний возраст. В нашем примере разделите 118 (сумма всех возрастов) на 5 (количество возрастов в списке). Средний возраст составит 23,6.
- Этот метод применим к набору данных с любым количеством чисел. Например, нужно найти средний возраст членов клуба. Допустим, что в клуб вступили 100 человек. Необходимо выяснить точный возраст каждого члена клуба. Сложите все возрасты, чтобы получить их сумму. Затем эту сумму разделите на 100, чтобы вычислить средний возраст членов клуба.
-
4
Найдите среднее значение других величин. С помощью описанного метода можно найти среднее значение любой величины, а не только средний возраст.
- Например, нужно узнать среднее население 10 крупнейших городов России. Необходимо определить количество жителей в каждом городе. Затем сложите найденные числа, а сумму разделите на 10, чтобы вычислить среднее население.
- Иногда вычисляют средневзвешенное значение. Например, при усреднении оценок учащегося оценки по некоторым предметам считаются важнее других.[3]
Чтобы вычислить средневзвешенное значение, умножьте каждое число на значимость его вклада (вес). Сложите полученные значения, а сумму разделите на общее количество чисел.[4]
Реклама




-
1
Запомните отличие среднего значения от медианы. Некоторые люди не видят разницы между средним значением и медианой набора чисел. На самом деле в некоторых случаях лучше вычислить медиану, а не среднее значение.
- Медиана – это некоторое число набора данных, которое больше одной половины чисел набора данных и меньше другой половины чисел набора данных. То есть это число (в нашем случае возраст), которое делит набор чисел на две равные части.[5]
. - Медиана может быть лучшей оценкой возраста группы, если в группе есть выброс (аномальное число). Допустим, что возраст группы студентов университета лежит в пределах от 18 до 25 лет, а возраст одного студента равен 80 годам. Если вычислить среднее значение, престарелый студент исказит средний возраст группы, то есть группа окажется старше, чем на самом деле. Если же найти число, которое находится посередине группы чисел (возрастов), оно лучше охарактеризует возраст студентов. Поэтому вычисляйте медиану, если в наборе чисел присутствует выброс.
- Медиана – это некоторое число набора данных, которое больше одной половины чисел набора данных и меньше другой половины чисел набора данных. То есть это число (в нашем случае возраст), которое делит набор чисел на две равные части.[5]
-
2
Запомните отличие среднего значения от моды. Мода – это число, которое встречается в группе чисел чаще всего.
- В некоторых случаях целесообразно вычислить среднее значение и моду или среднее значение и медиану.
- Если нужно найти средний возраст, но даны только диапазоны возрастов (например, определенное количество детей в возрасте от 2 до 4 лет и от 4 до 6 лет), вычислите среднее значение для каждого диапазона, сложите полученные числа, а сумму разделите на общее количество детей в каждом возрастном диапазоне.[6]
Реклама


-
1
Воспользуйтесь электронной таблицей Excel. Чтобы вычислить средний возраст большой группы людей, внесите все возрасты в таблицу Excel. В противном случае (если вы пользуетесь только бумагой, ручкой и калькулятором) на такое вычисление уйдет много времени.
- Допустим, необходимо найти средний возраст всех учеников школы или работников крупной компании. В этом случае возрастов будет так много, что лучше воспользоваться программой для работы с электронными таблицами, такой как Excel.
- Сначала введите все возрасты в ячейки электронной таблицы Excel. Excel входит в пакет Microsoft Office. Либо введите возрасты вручную, либо импортируйте в Excel документ со всеми возрастами. Возможно, возрасты уже внесены в таблицу Excel.
- Чтобы импортировать текстовый файл в Excel, нажмите «Получить внешние данные» – «Из текста». Откроется мастер импортирования данных из внешнего документа в электронную таблицу.[7]
-
2
Используйте формулу Excel, чтобы найти среднее значение. Предположим, возраст введен в ячейки столбца A в строках с 1 по 200. (Столбцы объединяют ячейки, которые расположены вертикально, а строки – ячейки, которые расположены горизонтально.) Чтобы вычислить среднее значение, нужно ввести соответствующую формулу Excel. Ее можно ввести в ячейке A201.
- Формула для вычисления среднего значения в Excel: =(СРЗНАЧ)A1:A200.[8]
Здесь вместо A1 нужно подставить адрес ячейки с первым возрастом. В нашем примере первый возраст находится в ячейке A1, потому что введен в первом столбце и первой строке. Вместо A200 нужно подставить адрес ячейки с последним возрастом. - В нашем примере последний возраст находится в ячейке A200, потому что введен в первом столбце и двухсотой строке. Двоеточие между адресами двух ячеек указывает программе, что нужно сложить все числа, находящиеся в ячейках с А1 по А200, а затем найти среднее значение этой суммы. Нажмите Enter, чтобы в ячейке А201 отобразился средний возраст.
- Формула для вычисления среднего значения в Excel: =(СРЗНАЧ)A1:A200.[8]
-
3
Воспользуйтесь онлайн-калькулятором. В интернете есть сервисы, которые упрощают вычисление среднего значения. Такие сервисы снабжены онлайн-калькуляторами, в которые вводится набор чисел.[9]
- Конечно, можно пользоваться карандашом, бумагой и обычным калькулятором. Как только вы поймете, как работает формула для вычисления среднего значения, вы с легкостью определите, чем пользоваться в процессе вычислений.
Реклама



Советы
- Работая в Excel, не трогайте исходную таблицу с данными; сделайте копию и редактируйте ее. Это необходимо на тот случай, если вы запутаетесь или захотите проверить вычисления.
Реклама
Об этой статье
Эту страницу просматривали 78 910 раз.
Была ли эта статья полезной?
Пример выполнения расчетного задания по статистике
Имеются следующие выборочные данные службы занятости о времени поиска работы 30 безработными одного из районов города (выборка 1%-ная, механическая):
|
№ п/п |
Возраст безработного, Лет |
Время поиска работы, Мес. |
№ п/п |
Возраст безработного, Лет |
Время поиска работы, Мес. |
|
1 |
37 |
8,7 |
16 |
60 |
11,3 |
|
2 |
53 |
9,4 |
17 |
21 |
5,6 |
|
3 |
18 |
5,1 |
18 |
33 |
7,5 |
|
4 |
25 |
6,9 |
19 |
29 |
7,2 |
|
5 |
33 |
7,9 |
20 |
42 |
8,3 |
|
6 |
32 |
7,8 |
21 |
17 |
5,3 |
|
7 |
48 |
8,5 |
22 |
44 |
8,4 |
|
8 |
61 |
10,4 |
23 |
41 |
7,9 |
|
9 |
29 |
7,8 |
24 |
26 |
7,4 |
|
10 |
39 |
8,4 |
25 |
30 |
7,9 |
|
11 |
28 |
7,9 |
26 |
41 |
8,1 |
|
12 |
35 |
8,5 |
27 |
47 |
8,7 |
|
13 |
52 |
9,4 |
28 |
27 |
7,5 |
|
14 |
36 |
8,7 |
29 |
23 |
6,7 |
|
15 |
48 |
8,9 |
30 |
57 |
10,0 |
Задание 1
По исходным данным:
1) постройте Статистический ряд распределения по признаку возраст безработного, образовав 4 группы с равными интервалами;
2) графическим методом и путем расчетов определите значения Моды и Медианы полученного ряда распределения;
3) рассчитайте характеристики интервального ряда распределения: Среднюю арифметическую, Среднее квадратическое отклонение, Коэффициент вариации.
Сделайте выводы по результатам выполнения пунктов 1, 2, 3 задания;
4) вычислите Среднюю арифметическую по исходным данным, сравните ее с аналогичным показателем, рассчитанным в п. 3 для интервального ряда распределения. Объясните причину их расхождения.
Задание 2
По результатам выполнения задания 1 с вероятностью 0,683 определите:
1) ошибку выборки среднего возраста безработных в районе и границы, в которых будет находиться средний возраст безработных в целом по району;
2) ошибку выборки доли безработных в районе в возрасте до 50 лет и границы, в которых будет находиться генеральная доля.
Выполнение задания 1
1.1. Построение интервального ряда распределения безработных по возрасту
Для построения интервального вариационного ряда, характеризующего распределение безработных по возрасту, необходимо вычислить Величину и границы интервалов ряда.
При построении ряда с равными интервалами величина интервала H определяется по формуле
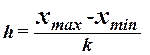 , (1)
, (1)
Где ![]() – наибольшее и наименьшее значения признака в исследуемой совокупности, K – число групп интервального ряда.
– наибольшее и наименьшее значения признака в исследуемой совокупности, K – число групп интервального ряда.
Число групп K задается в условии задания или рассчитывается по формуле Г. Стерджесса
K=1+3,322 Lg N, (2)
Где N – число единиц совокупности. По условиям задания k=4.
Определение величины интервала по формуле (1) при заданных K = 4:
XmaX = 61 год, Xmin = 17 лет
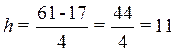 Лет.
Лет.
При H = 11 границы интервалов ряда распределения имеют следующий вид (табл. 2):
Таблица 2
|
Номер группы |
Возраст безработного, лет |
|
1 |
17 – 28 |
|
2 |
28 – 39 |
|
3 |
39 – 50 |
|
4 |
50 – 61 |
Для построения интервального ряда необходимо подсчитать число безработных, входящих в каждую группу (Частоты групп). При этом возникает вопрос, в какую группу включать единицы совокупности, у которых значения признака выступают одновременно и верхней, и нижней границами смежных интервалов. Отнесение таких единиц к одной из двух смежных групп рекомендуется осуществлять По принципу полуоткрытого интервала. Т. к. при этом верхние границы интервалов не принадлежат данным интервалам, то соответствующие им единицы совокупности включаются не в данную группу, а в следующую. В последний интервал включаются и Нижняя, и Верхняя границы.
Процесс группировки единиц совокупности по признаку Возраст безработного представлен во вспомогательной (разработочной) таблице 3 (графа 4 этой таблицы необходима для построения аналитической группировки в Задании 2).
Таблица 3
Разработочная таблица для построения интервального ряда распределения и аналитической группировки
|
Возраст безработного, лет |
Середина интервала |
Частота |
|
17 – 28 |
22,5 |
7 |
|
28 – 39 |
33,5 |
10 |
|
39 – 50 |
44,5 |
8 |
|
50 – 61 |
55,5 |
5 |
|
Всего |
30 |
На основе групповых итоговых строк «Всего» табл. 3 формируется итоговая табл. 4, представляющая Интервальный ряд распределения безработных по возрасту.
Таблица 4
Распределение безработных по возрасту
|
I |
Возраст безработного, лет |
Середины интервалов |
Частота (nI) |
Частость (доля), ni/n |
Накопленная частота (Sj) |
Накопленная частость |
|
1 |
17-28 |
22,5 |
7 |
0,2333 |
7 |
23% |
|
2 |
28-39 |
33,5 |
10 |
0,3333 |
17 |
57% |
|
3 |
39-50 |
44,5 |
8 |
0,2667 |
25 |
83% |
|
4 |
50-61 |
55,5 |
5 |
0,1667 |
30 |
100% |
|
Всего (n) |
30 |
Помимо частот групп в абсолютном выражении в анализе интервальных рядов используются ещё три характеристики ряда, приведенные в графах 4 – 6 табл. 1.4. Это Частоты групп в относительном выражении, Накопленные (кумулятивные) частоты Sj, Получаемые путем последовательного суммирования частот всех предшествующих (j-1) интервалов, и Накопленные частости, рассчитываемые по формуле 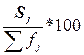 .
.
Вывод. Анализ интервального ряда распределения изучаемой совокупности безработных показывает, что распределение безработных по возрасту не является равномерным: преобладают безработные в возрасте от 28 до 39 лет (это 10 безработных, доля которых составляет 33%), почти в два раза меньше (17%) старшая возрастная группа (от 50 лет до 61 года); группы от 17 до 28 лет и от 39 до 50 лет отличаются не так заметно (23% и 27% соответственно).
1.2. Нахождение моды и медианы полученного интервального ряда распределения графическим методом и путем расчетов
Мода и медиана являются Структурными средними величинами, характеризующими (наряду со средней арифметической) центр распределения единиц совокупности по изучаемому признаку.
Мода Мо для дискретного ряда – это значение признака, наиболее часто встречающееся у единиц исследуемой совокупности[1]. В интервальном вариационном ряду модой приближенно считается Центральное значение модального интервала (имеющего наибольшую частоту). Более точно моду можно определить графическим методом по гистограмме ряда (рис.1).
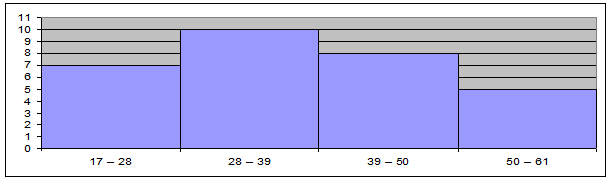
Рис. 1 Определение моды графическим методом
Конкретное значение моды для интервального ряда рассчитывается по формуле:
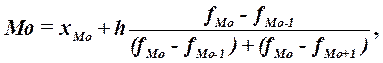 (3)
(3)
Где ХМo – нижняя граница модального интервала,
H –величина модального интервала,
FMo – частота модального интервала,
FMo-1 – частота интервала, предшествующего модальному,
FMo+1 – частота интервала, следующего за модальным.
Согласно табл.1.3 модальным интервалом построенного ряда является интервал 28 – 39 лет, так как его частота максимальна (f2 = 10).
Расчет моды по формуле (3):
![]()
Вывод. Для рассматриваемой совокупности безработных наиболее распространенный возраст характеризуется средней величиной 34,4 года.
Медиана Ме – это значение признака, приходящееся на середину ранжированного ряда. По обе стороны от медианы находится одинаковое количество единиц совокупности.
Медиану можно определить графическим методом по кумулятивной кривой (рис. 2). Кумулята строится по накопленным частотам (табл. 5, графа 5).
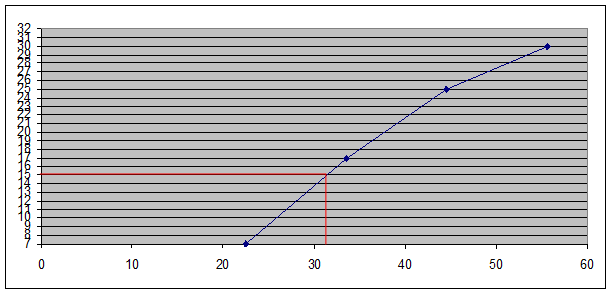
Рис. 2. Определение медианы графическим методом
Конкретное значение медианы для интервального ряда рассчитывается по формуле:
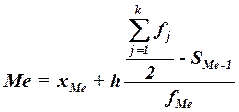 , (4)
, (4)
Где ХМе– нижняя граница медианного интервала,
H – величина медианного интервала,
![]() – сумма всех частот,
– сумма всех частот,
FМе – частота медианного интервала,
SMе-1 – кумулятивная (накопленная) частота интервала, предшествующего медианному.
Для расчета медианы необходимо, прежде всего, определить медианный интервал, для чего используются накопленные частоты (или частости) из табл. 5 (графа 5). Так как медиана делит численность ряда пополам, она будет располагаться в том интервале, где накопленная частота Впервые равна полусумме всех частот ![]() или превышает ее (т. е. все предшествующие накопленные частоты меньше этой величины).
или превышает ее (т. е. все предшествующие накопленные частоты меньше этой величины).
В демонстрационном примере медианным интервалом является интервал 28 – 39 лет, так как именно в этом интервале накопленная частота Sj = 17 впервые превышает величину, равную половине численности единиц совокупности (![]() =
=![]() ).
).
Расчет значения медианы по формуле (4):
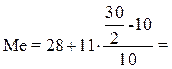 33,5 года
33,5 года
Вывод. В рассматриваемой совокупности, половина безработных имеют возраст в среднем не более 33,5 лет, а другая половина – не менее 33,5 лет.
1.3. Расчет характеристик ряда распределения
Для расчета характеристик ряда распределения ![]() , σ, σ2, Vσ на основе табл. 5 строится вспомогательная табл. 6 (
, σ, σ2, Vσ на основе табл. 5 строится вспомогательная табл. 6 (![]() – середина j-го интервала).
– середина j-го интервала).
Таблица 6
Расчетная таблица для нахождения характеристик ряда распределения
|
Возраст безработного, лет |
Середина интервала,
|
Частота. Fj |
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
17-28 |
22,5 |
7 |
157,5 |
-15,033 |
226,001 |
1582,01 |
|
28-39 |
33,5 |
10 |
335 |
-4,0333 |
16,2678 |
162,678 |
|
39-50 |
44,5 |
8 |
356 |
6,96667 |
48,5344 |
388,276 |
|
50-61 |
55,5 |
5 |
277,5 |
17,9667 |
322,801 |
1614,01 |
|
Итого |
30 |
1126 |
3746,97 |
Расчет средней арифметической взвешенной:
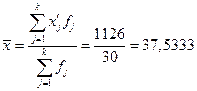 лет (5)
лет (5)
Расчет дисперсии:
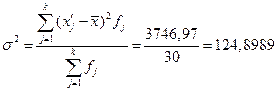 (6)
(6)
Расчет среднего квадратического отклонения:
![]()
Расчет коэффициента вариации:
![]() (7)
(7)
Вывод. Анализ полученных значений показателей ![]() и σ говорит о том, что средний возраст безработных составляет 37,5333 лет, отклонение от среднего возраста в ту или иную сторону составляет в среднем 11,1758 лет (или 29,78%), наиболее характерные значения среднего возраста безработных находятся в пределах от 26,3575 до 48,7092 (диапазон
и σ говорит о том, что средний возраст безработных составляет 37,5333 лет, отклонение от среднего возраста в ту или иную сторону составляет в среднем 11,1758 лет (или 29,78%), наиболее характерные значения среднего возраста безработных находятся в пределах от 26,3575 до 48,7092 (диапазон ![]() ).
).
Значение Vσ = 29,78% не превышает 33%, следовательно, вариация возраста в исследуемой совокупности безработных незначительна и совокупность по данному признаку качественно однородна. Расхождение между значениями ![]() , Мо и Ме незначительно (
, Мо и Ме незначительно (![]() =37,5333 лет, Мо=34,4 года, Ме=33,5 лет), что подтверждает вывод об однородности по возрасту совокупности безработных. Таким образом, найденное среднее значение возраста безработных (37,5333 лет) является типичной, надежной характеристикой исследуемой совокупности безработных.
=37,5333 лет, Мо=34,4 года, Ме=33,5 лет), что подтверждает вывод об однородности по возрасту совокупности безработных. Таким образом, найденное среднее значение возраста безработных (37,5333 лет) является типичной, надежной характеристикой исследуемой совокупности безработных.
1.4. Вычисление средней арифметической по исходным данным
Для расчета применяется формула средней арифметической простой:
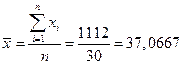 (8)
(8)
Причина расхождения средних величин, рассчитанных по формулам (8) и (5), заключается в том, что по формуле (8) средняя определяется по фактическим значениям исследуемого признака для всех 30-ти безработных, а по формуле (5) средняя вычисляется для интервального ряда, когда в качестве значений признака берутся середины интервалов ![]() и, следовательно, значение средней будет менее точным (за исключением случая равномерного распределения значений признака внутри каждой группы).
и, следовательно, значение средней будет менее точным (за исключением случая равномерного распределения значений признака внутри каждой группы).
Задание 2
По результатам выполнения задания 1 с вероятностью 0,683 определите:
1) ошибку выборки среднего возраста безработных в районе и границы, в которых будет находиться средний возраст безработных в целом по району;
2) ошибку выборки доли безработных в районе в возрасте до 50 лет и границы, в которых будет находиться генеральная доля.
Выполнение Задания 3
1. Определение ошибки выборки для Среднего возраста безработных в районе и границы, в которых будет находиться генеральная средняя
Применение выборочного метода наблюдения всегда связано с Установлением степени достоверности оценок показателей генеральной совокупности, полученных на основе значений показателей выборочной совокупности. Достоверность этих оценок зависит от репрезентативности выборки, т. е. от того, насколько полно и адекватно представлены в выборке статистические свойства генеральной совокупности. Как правило, генеральные и выборочные характеристики не совпадают, а отклоняются на некоторую величину ε, которую называют Ошибкой выборки (ошибкой репрезентативности).
Значения признаков единиц, отобранных из генеральной совокупности в выборочную, всегда случайны, поэтому и статистические характеристики выборки случайны, следовательно, и ошибки выборки также случайны. Ввиду этого принято вычислять два вида ошибок — среднюю ![]() и предельную
и предельную ![]() .
.
Средняя ошибка выборки ![]() – это среднее квадратическое отклонение всех возможных значений выборочной средней от генеральной средней, т. е. от своего математического ожидания M[
– это среднее квадратическое отклонение всех возможных значений выборочной средней от генеральной средней, т. е. от своего математического ожидания M[![]() ].
].
Величина средней ошибки выборки рассчитывается Дифференцированно (по различным формулам) в зависимости от Вида и способа отбора единиц из генеральной совокупности в выборочную.
Для собственно-случайной и механической выборки с бесповторным способом отбора средняя ошибка ![]() выборочной средней
выборочной средней ![]() определяется по формуле
определяется по формуле
![]() , (15)
, (15)
Где ![]() – общая дисперсия выборочных значений признаков,
– общая дисперсия выборочных значений признаков,
N – число единиц в генеральной совокупности,
N – число единиц в выборочной совокупности.
Предельная ошибка выборки ![]() определяет границы, в пределах которых будет находиться генеральная средняя:
определяет границы, в пределах которых будет находиться генеральная средняя:
![]() ,
,
![]() , (16)
, (16)
Где ![]() – выборочная средняя,
– выборочная средняя,
![]() – генеральная средняя.
– генеральная средняя.
Границы ![]() задают Доверительный интервал генеральной средней, т. е. случайную область значений, которая с вероятностью Р гарантированно содержит значение генеральной средней. Эту вероятность Р называют Доверительной вероятностью Или Уровнем надёжности.
задают Доверительный интервал генеральной средней, т. е. случайную область значений, которая с вероятностью Р гарантированно содержит значение генеральной средней. Эту вероятность Р называют Доверительной вероятностью Или Уровнем надёжности.
В экономических исследованиях чаще всего используются доверительные вероятности Р= 0,954, Р= 0,997, Реже Р= 0,683.
В математической статистике доказано, что предельная ошибка выборки![]() кратна средней ошибке µ с Коэффициентом кратности T (Называемым также Коэффициентом доверия), который зависит от значения доверительной вероятности Р. Для предельной ошибки выборочной средней
кратна средней ошибке µ с Коэффициентом кратности T (Называемым также Коэффициентом доверия), который зависит от значения доверительной вероятности Р. Для предельной ошибки выборочной средней ![]() это теоретическое положение выражается формулой
это теоретическое положение выражается формулой
![]() (17)
(17)
Значения T вычислены заранее для различных доверительных вероятностей Р и Протабулированы (таблицы функции Лапласа Ф). Для наиболее часто используемых уровней надежности Р Значения T задаются следующим образом (табл. 15):
Таблица 15
|
Доверительная вероятность P |
0,683 |
0,866 |
0,954 |
0,988 |
0,997 |
0,999 |
|
Значение T |
1,0 |
1,5 |
2,0 |
2,5 |
3,0 |
3,5 |
По условию демонстрационного примера выборочная совокупность насчитывает 30 безработных, выборка 1% механическая, следовательно, Генеральная совокупность включает 3000 безработных. Выборочная средняя ![]() , дисперсия
, дисперсия ![]() определены в Задании 1 (п. 3). Значения параметров, необходимых для решения задачи, представлены в табл. 16:
определены в Задании 1 (п. 3). Значения параметров, необходимых для решения задачи, представлены в табл. 16:
Таблица 16
|
Р |
T |
N |
N |
|
|
|
0,683 |
1 |
30 |
3000 |
36,8 |
130,2767 |
Расчет средней ошибки выборки по формуле (15):
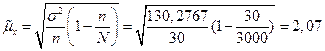
Расчет предельной ошибки выборки по формуле (17):
![]()
Определение по формуле (16) доверительного интервала для генеральной средней:
36,8-2,07![]() 36,8+2,07,
36,8+2,07,
34,73 лет ![]() 38,87 лет.
38,87 лет.
Вывод. На основании проведенного выборочного обследования среднего возраста безработных в районе с вероятностью 0,683 можно утверждать, что для генеральной совокупности безработных средний возраст находится в пределах от 34,73 лет до 38,87 лет.
2. Определение ошибки выборки для Доли безработных в районе в возрасте до 50 лет и границы, в которых будет находиться генеральная доля
Доля единиц выборочной совокупности, обладающих тем или иным заданным свойством, выражается формулой
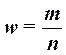 , (18)
, (18)
Где M – число единиц совокупности, обладающих заданным свойством;
N – общее число единиц в совокупности.
Для собственно-случайной и механической выборки с бесповторным способом отбора предельная ошибка выборки ![]() доли единиц, обладающих заданным свойством, рассчитывается по формуле
доли единиц, обладающих заданным свойством, рассчитывается по формуле
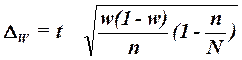 , (19)
, (19)
Где W – доля единиц совокупности, обладающих заданным свойством;
(1-W) – доля единиц совокупности, не обладающих заданным свойством,
N – число единиц в генеральной совокупности,
N– число единиц в выборочной совокупности.
Предельная ошибка выборки ![]() определяет границы, в пределах которых будет находиться генеральная доля Р единиц, обладающих заданным свойством:
определяет границы, в пределах которых будет находиться генеральная доля Р единиц, обладающих заданным свойством:
![]() (20)
(20)
По условию Задания 3 исследуемым свойством является не Превышение среднего возраста безработных 50 лет.
Число безработных с заданным свойством определяется из табл. 3 (графа 3):
M=25
Расчет выборочной доли по формуле (18):
![]()
Расчет по формуле (19) предельной ошибки выборки для доли:
![]()
Определение по формуле (20) доверительного интервала генеральной доли:
0,8333-0,0677<=p<=0,8333+0,0677
Или
76,56% <= p<=90,10%
Вывод. С вероятностью 0,683 можно утверждать, что в генеральной совокупности безработных доля безработных в возрасте до 50 лет будет находиться в пределах от 77% до 90%.
[1] Если в дискретном ряду все варианты встречаются одинаково часто, то в этом случае мода отсутствует. Могут быть распределения, где не один, а два (или более) варианта имеют наибольшие частоты. Тогда ряд имеет две (или более) моды, распределение является бимодальным (или многомодальным), что указывает на качественную неоднородность совокупности по изучаемому признаку.
| < Предыдущая | Следующая > |
|---|
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
![]() Download Article
Download Article
![]() Download Article
Download Article
Do you need to calculate the average age? It’s easy to do. All you need to do is use a simple three-step process, and you should be able to figure it out.
-
1
Organize all of the ages in a list. Figuring out the average of something is simple. It means that you take every single number in the list. Write them down or put them in a spreadsheet.[1]
-
2
Find the sum of all of the ages on the list. That means that you add them all up for a grand total. Let’s say you have 5 ages: 31, 30, 26, 21, 10. The total or sum of those numbers is 118.[2]
Advertisement
-
3
Now, divide the sum you got by the number of ages in the list. That’s the average. Using the above example, you would divide 118 (the sum of all the ages) by 5 (the number of ages in the list). The average age is 23.6.[3]
- This works for much larger number sets too. For example, let’s say you wanted to find the average age of people in a club. Let’s say there were 100 members in the club. You would need the exact ages of each club member. You would add those ages together to get a sum. Then, you would divide that sum by the number 100. That’s the average age of members in the club.
-
4
Find the average of other sets of numbers. It’s no different when calculating average for other types of numbers that aren’t ages. Average works the same way.
- For example, let’s say you want to know the average population of the 10 largest cities in America. You would list the population for each city. Then, you would add all of those numbers up. You would divide the sum by 10, and that’s the average.
- There are times you might want to use a weighted average. For example, when averaging a student’s grades, you might want to weigh some assignments as being worth more than others. To do this, multiply each grade by the weight. Then add those numbers together, and divide by the total number of grades [4]




Advertisement
-
1
Know the difference between average and median. Sometimes people are confused by the difference between the average and the median of a set of numbers. There are times that the median can be a better number to use than the average, actually.[5]
- The median means the midpoint number in the data. It means the number (in this case age) that appears exactly in the middle.[6]
. - Median might be a better assessment of the group’s age if there is an outlier in the group. Let’s say every student in a college class of 20 is between the ages of 18-25, but there is a single older returning student who is 80. If you calculated the average, the much older student would skew the average upward making the class look older than it really is. If you selected the number at the midpoint of all the ages on a list, it would be a closer representation of the class. So, use median if there is an extreme outlier on your list.
- The median means the midpoint number in the data. It means the number (in this case age) that appears exactly in the middle.[6]
-
2
Realize how mode differs from mean or average. Mode is different; that means the number that appears most frequently in the data.[7]
- Mean is the same thing as average. It’s just another word used for it. Sometimes the best way to handle numbers is simply to present more than one number, say both median and average.
- If you’re asked to find the average age but only have age ranges (such as a certain number of people in age range 2-4 and age range 4-6, you would calculate the midpoint number for each range, add those up, and then divide them by the total number in each age range.)


Advertisement
-
1
Try using an Excel spreadsheet. If you need to calculate the average from a lengthy list of ages, try putting them into Excel. Otherwise, if you sit there with a calculator or notepad and paper, it could take you a long time.
- Let’s say for the sake of argument that you needed to calculate the average age of every student in a school or of every person on the payroll of a large company. Those are examples of lists where there would be so many ages that it would be beneficial to use a spreadsheet program like Excel.
- The first thing you need to do is put the ages in an Excel spreadsheet. Excel is widely available through Microsoft Office package. Either you will need to type the ages into Excel or, better yet, you can import another document containing the ages into Excel. Perhaps the ages are already organized in Excel.
- To import a text file into Excel, click on «get external data» and the text. Excel will walk you through a wizard to import that data into a spreadsheet[8]
-
2
Use the Excel formula for average. Let’s say the ages are listed in column A in Excel. Let’s say they start at row 1 and stop at row 200 (columns are vertical in Excel, and rows are horizontal). To get the average, you need to input the Excel formula for average. You can type it at the bottom of column A.
- The formula for average in Excel is =(AVERAGE)A1:A200.[9]
You need to substitute the column and row coordinates that house the first age in the column for A1. In this example, it would literally be A1, if the first age was listed in the first row in column A. You would need to substitute A200 for the column and row coordinates that house the last age in column A in your own data set. - In this example, it was A200 because the last age is housed in column A, row 200. The colon in between tells the computer to add up the age in A1, in A200 and everything in between, and average them. Hit enter, and you should have the average.
- The formula for average in Excel is =(AVERAGE)A1:A200.[9]
-
3
Try using an average calculator. There are websites that will make it easier to calculate average. They provide online calculators in which you put the string of numbers.[10]
- Of course, a pencil and paper or a regular calculator work too. Once you understand how the formula for average works, you can figure out which tool will get you there.



Advertisement
Add New Question
-
Question
The average age of 4 boys is 12 years. If another boy of 14 years joins them, what’s the average age of the whole group?

With four boys averaging 12 years old, the combined ages of the four boys would be 4 x 12 = 48. Add the age of the new boy to that total to get 48 + 14 = 62. Now divide this number by your total number of people (5) to find the average age: 62 / 5 = 12.4.
-
Question
The average age of 30 students of a class is 15 years. Average age remains unaltered even if 3 new students are admitted. The total age of 3 new students is what?
If the new students don’t change the average age of the class, that means their average age is 15, too, which means their total age is 3 x 15 = 45 years.
-
Question
How do I compute the mode of these ages: 25, 26, 28, 30, 54, 54, 52?
Look at the given numbers, and decide which number appears most often in the list. That number is the mode.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
-
When working in Excel, always keep a copy of the original data sheet, and work off a copy, in case you lose or need to check your work.
Advertisement
About This Article
Article SummaryX
If you need to calculate the average age of a sample, write down a list of everyone in the sample and their ages. Add together all of the ages in the list to get the sum, then divide that sum by the number of ages in the list. The result is the average age. To learn when to use averages, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 267,860 times.