
…
Прикладная наука о методах и способах преобразования информации с целью ее защиты от незаконных пользователей — это
криптография
криптология
…
Тайнопись — это
тайные знаки
способ, позволяющий передавать секретные сообщения от одного человека к другому
написание тайных знаков в тетради
…
Кто открыл методы кодирования с коррекцией ошибок?
Колд Шеннон
Франсуа Виет
Юлий Цезарь
Полибий
…
В честь греческого писателя и историка названа
доска
карта
планета
страна
…
Кому принадлежит фраза «Чтобы узнать мысли человека, ему влезают в сердце,а в письма тем более». Подсказка: ЩЁЛТРЙС
Вильям Шекспир
Клод Шеннон
Норберт Винер
Юлий Цезарь
…
Кому принадлежит фраза «Любой шифр может быть вскрыт, если только в этом есть настоятельная необходимость и информация, которую стоит получить, стоит затраченных средств, усилий и времени»? Подсказка: ДКПЖТ
Норберт Гинер
Норебрт Винес
Норберт Винер
Норберт Венер
…
Шифр Цезаря — это
симметричный шифр
шифрование биграммами
шифр замены со сдвигом
шифр ОТР
«Информация есть форма жизни», — писал американский поэт и эссеист Джон Перри Барлоу. Действительно, мы постоянно сталкиваемся со словом «информация» — ее получают, передают и сохраняют. Узнать прогноз погоды или результат футбольного матча, содержание фильма или книги, поговорить по телефону — всегда ясно, с каким видом информации мы имеем дело. Но что такое сама информация, а главное — как ее можно измерить, никто обычно не задумывается. А между тем, информация и способы ее передачи — важная вещь, которая во многом определяет нашу жизнь, неотъемлемой частью которой стали информационные технологии. Научный редактор издания «Лаба.Медиа» Владимир Губайловский объясняет, что такое информация, как ее измерять, и почему самое сложное — это передача информации без искажений.
Читайте «Хайтек» в
Пространство случайных событий
В 1946 году американский ученый-статистик Джон Тьюки предложил название БИТ (BIT, BInary digiT — «двоичное число» — «Хайтек») — одно из главных понятий XX века. Тьюки избрал бит для обозначения одного двоичного разряда, способного принимать значение 0 или 1. Клод Шеннон в своей программной статье «Математическая теория связи» предложил измерять в битах количество информации. Но это не единственное понятие, введенное и исследованное Шенноном в его статье.
Представим себе пространство случайных событий, которое состоит из бросания одной фальшивой монеты, на обеих сторонах которой орел. Когда выпадает орел? Ясно, что всегда. Это мы знаем заранее, поскольку так устроено наше пространство. Выпадение орла — достоверное событие, то есть его вероятность равна 1. Много ли информации мы сообщим, если скажем о выпавшем орле? Нет. Количество информации в таком сообщении мы будем считать равным 0.
Теперь давайте бросать правильную монету: с одной стороны у нее орел, а с другой решка, как и положено. Выпадение орла или решки будут двумя разными событиями, из которых состоит наше пространство случайных событий. Если мы сообщим об исходе одного бросания, то это действительно будет новая информация. При выпадении орла мы сообщим 0, а при решке 1. Для того, чтобы сообщить эту информацию, нам достаточно 1 бита.
Что изменилось? В нашем пространстве событий появилась неопределенность. Нам есть, что о нем рассказать тому, кто сам монету не бросает и исхода бросания не видит. Но чтобы правильно понять наше сообщение, он должен точно знать, чем мы занимаемся, что означают 0 и 1. Наши пространства событий должны совпадать, и процесс декодирования — однозначно восстанавливать результат бросания. Если пространство событий у передающего и принимающего не совпадает или нет возможности однозначного декодирования сообщения, информация останется только шумом в канале связи.
Если независимо и одновременно бросать две монеты, то разных равновероятных результатов будет уже четыре: орел-орел, орел-решка, решка-орел и решка-решка. Чтобы передать информацию, нам понадобится уже 2 бита, и наши сообщения будут такими: 00, 01, 10 и 11. Информации стало в два раза больше. Это произошло, потому что выросла неопределенность. Если мы попытаемся угадать исход такого парного бросания, то имеем в два раза больше шансов ошибиться.
Чем больше неопределенность пространства событий, тем больше информации содержит сообщение о его состоянии.
Немного усложним наше пространство событий. Пока все события, которые случались, были равновероятными. Но в реальных пространствах далеко не все события имеют равную вероятность. Скажем, вероятность того, что увиденная нами ворона будет черной, близка к 1. Вероятность того, что первый встреченный на улице прохожий окажется мужчиной, — примерно 0,5. Но встретить на улице Москвы крокодила почти невероятно. Интуитивно мы понимаем, что сообщение о встрече с крокодилом имеет гораздо большую информационную ценность, чем о черной вороне. Чем ниже вероятность события, тем больше информации в сообщении о таком событии.
Пусть пространство событий не такое экзотическое. Мы просто стоим у окна и смотрим на проезжающие машины. Мимо проезжают автомобили четырех цветов, о которых нам необходимо сообщить. Для этого мы закодируем цвета: черный — 00, белый — 01, красный — 10, синий — 11. Чтобы сообщить о том, какой именно автомобиль проехал, нам достаточно передать 2 бита информации.
Но довольно долго наблюдая за автомобилями, замечаем, что цвет автомобилей распределен неравномерно: черных — 50% (каждый второй), белых — 25% (каждый четвертый), красных и синих — по 12,5% (каждый восьмой). Тогда можно оптимизировать передаваемую информацию.
Больше всего черных автомобилей, поэтому обозначим черный — 0 — самый короткий код, а код всех остальных пусть начинается на 1. Из оставшихся половина белые — 10, а оставшиеся цвета начинаются на 11. В заключение обозначим красный — 110, а синий — 111.
Теперь, передавая информацию о цвете автомобилей, мы можем закодировать ее плотнее.

Энтропия по Шеннону
Пусть наше пространство событий состоит из n разных событий. При бросании монеты с двумя орлами такое событие ровно одно, при бросании одной правильной монеты — 2, при бросании двух монет или наблюдении за автомобилями — 4. Каждому событию соответствует вероятность его наступления. При бросании монеты с двумя орлами событие (выпадение орла) одно и его вероятность p1 = 1. При бросании правильной монеты событий два, они равновероятны и вероятность каждого — 0,5: p1 = 0,5, p2 = 0,5. При бросании двух правильных монет событий четыре, все они равновероятны и вероятность каждого — 0,25: p1 = 0,25, p2 = 0,25, p3 = 0,25, p4 = 0,25. При наблюдении за автомобилями событий четыре, и они имеют разные вероятности: черный — 0,5, белый — 0,25, красный — 0,125, синий — 0,125: p1 = 0,5, p2 = 0,25, p3 = 0,125, p4 = 0,125.

Это не случайное совпадение. Шеннон так подобрал энтропию (меру неопределенности в пространстве событий), чтобы выполнялись три условия:
- 1Энтропия достоверного события, вероятность которого 1, равна 0.
- Энтропия двух независимых событий равна сумме энтропий этих событий.
- Энтропия максимальна, если все события равновероятны.
Все эти требования вполне соответствуют нашим представлениям о неопределенности пространства событий. Если событие одно (первый пример) — никакой неопределенности нет. Если события независимы — неопределенность суммы равна сумме неопределенностей — они просто складываются (пример с бросанием двух монет). И, наконец, если все события равновероятны, то степень неопределенности системы максимальна. Как в случае с бросанием двух монет, все четыре события равновероятны и энтропия равна 2, она больше, чем в случае с автомобилями, когда событий тоже четыре, но они имеют разную вероятность — в этом случае энтропия 1,75.
Клод Элвуд Шеннон — американский инженер, криптоаналитик и математик. Считается «отцом информационного века». Основатель теории информации, нашедшей применение в современных высокотехнологических системах связи. Предоставил фундаментальные понятия, идеи и их математические формулировки, которые в настоящее время формируют основу для современных коммуникационных технологий.
В 1948 году предложил использовать слово «бит» для обозначения наименьшей единицы информации. Он также продемонстрировал, что введенная им энтропия эквивалентна мере неопределенности информации в передаваемом сообщении. Статьи Шеннона «Математическая теория связи» и «Теория связи в секретных системах» считаются основополагающими для теории информации и криптографии.
Во время Второй мировой войны Шеннон в Bell Laboratories занимался разработкой криптографических систем, позже это помогло ему открыть методы кодирования с коррекцией ошибок.
Шеннон внес ключевой вклад в теорию вероятностных схем, теорию игр, теорию автоматов и теорию систем управления — области наук, входящие в понятие «кибернетика».
Кодирование
И бросаемые монеты, и проезжающие автомобили не похожи на цифры 0 и 1. Чтобы сообщить о событиях, происходящих в пространствах, нужно придумать способ описать эти события. Это описание называется кодированием.
Кодировать сообщения можно бесконечным числом разных способов. Но Шеннон показал, что самый короткий код не может быть меньше в битах, чем энтропия.
Именно поэтому энтропия сообщения и есть мера информации в сообщении. Поскольку во всех рассмотренных случаях количество бит при кодировании равно энтропии, — значит кодирование прошло оптимально. Короче закодировать сообщения о событиях в наших пространствах уже нельзя.
При оптимальном кодировании нельзя потерять или исказить в сообщении ни одного передаваемого бита. Если хоть один бит потеряется, то исказится информация. А ведь все реальные каналы связи не дают 100-процентной уверенности, что все биты сообщения дойдут до получателя неискаженными.
Для устранения этой проблемы необходимо сделать код не оптимальным, а избыточным. Например, передавать вместе с сообщением его контрольную сумму — специальным образом вычисленное значение, получаемое при преобразовании кода сообщения, и которое можно проверить, пересчитав при получении сообщения. Если переданная контрольная сумма совпадет с вычисленной, вероятность того, что передача прошла без ошибок, будет довольно высока. А если контрольная сумма не совпадет, то необходимо запросить повторную передачу. Примерно так работает сегодня большинство каналов связи, например, при передаче пакетов информации по интернету.
Сообщения на естественном языке
Рассмотрим пространство событий, которое состоит из сообщений на естественном языке. Это частный случай, но один из самых важных. Событиями здесь будут передаваемые символы (буквы фиксированного алфавита). Эти символы встречаются в языке с разной вероятностью.
Самым частотным символом (то есть таким, который чаще всего встречается во всех текстах, написанных на русском языке) является пробел: из тысячи символов в среднем пробел встречается 175 раз. Вторым по частоте является символ «о» — 90, далее следуют другие гласные: «е» (или «ё» — мы их различать не будем) — 72, «а» — 62, «и» — 62, и только дальше встречается первый согласный «т» — 53. А самый редкий «ф» — этот символ встречается всего два раза на тысячу знаков.
Будем использовать 31-буквенный алфавит русского языка (в нем не отличаются «е» и «ё», а также «ъ» и «ь»). Если бы все буквы встречались в языке с одинаковой вероятностью, то энтропия на символ была бы Н = 5 бит, но если мы учтем реальные частоты символов, то энтропия окажется меньше: Н = 4,35 бит. (Это почти в два раза меньше, чем при традиционном кодировании, когда символ передается как байт — 8 бит).
Но энтропия символа в языке еще ниже. Вероятность появления следующего символа не полностью предопределена средней частотой символа во всех текстах. То, какой символ последует, зависит от символов уже переданных. Например, в современном русском языке после символа «ъ» не может следовать символ согласного звука. После двух подряд гласных «е» третий гласный «е» следует крайне редко, разве только в слове «длинношеее». То есть следующий символ в некоторой степени предопределен. Если мы учтем такую предопределенность следующего символа, неопределенность (то есть информация) следующего символа будет еще меньше, чем 4,35. По некоторым оценкам, следующий символ в русском языке предопределен структурой языка более чем на 50%, то есть при оптимальном кодировании всю информацию можно передать, вычеркнув половину букв из сообщения.
Другое дело, что не всякую букву можно безболезненно вычеркнуть. Высокочастотную «о» (и вообще гласные), например, вычеркнуть легко, а вот редкие «ф» или «э» — довольно проблематично.
Естественный язык, на котором мы общаемся друг с другом, высоко избыточен, а потому надежен, если мы что-то недослышали — нестрашно, информация все равно будет передана.
Но пока Шеннон не ввел меру информации, мы не могли понять и того, что язык избыточен, и до какой степени мы может сжимать сообщения (и почему текстовые файлы так хорошо сжимаются архиватором).
Избыточность естественного языка
В статье «О том, как мы ворпсиманием теcкт» (название звучит именно так!) был взят фрагмент романа Ивана Тургенева «Дворянское гнездо» и подвергнут некоторому преобразованию: из фрагмента было вычеркнуто 34% букв, но не случайных. Были оставлены первые и последние буквы в словах, вычеркивались только гласные, причем не все. Целью было не просто получить возможность восстановить всю информацию по преобразованному тексту, но и добиться того, чтобы человек, читающий этот текст, не испытывал особых трудностей из-за пропусков букв.

Почему сравнительно легко читать этот испорченный текст? В нем действительно содержится необходимая информация для восстановления целых слов. Носитель русского языка располагает определенным набором событий (слов и целых предложений), которые он использует при распознавании. Кроме того, в распоряжении носителя еще и стандартные языковые конструкции, которые помогают ему восстанавливать информацию. Например, «Она бла блее чвствтльна» — с высокой вероятностью можно прочесть как «Она была более чувствительна». Но взятая отдельно фраза «Она бла блее», скорее, будет восстановлена как «Она была белее». Поскольку мы в повседневном общении имеем дело с каналами, в которых есть шум и помехи, то довольно хорошо умеем восстанавливать информацию, но только ту, которую мы уже знаем заранее. Например, фраза «Чрты ее не бли лшны приятнсти, хтя нмнго рспхли и спллсь» хорошо читается за исключением последнего слова «спллсь» — «сплылись». Этого слова нет в современном лексиконе. При быстром чтении слово «спллсь» читается скорее как «слиплись», при медленном — просто ставит в тупик.
Оцифровка сигнала
Звук, или акустические колебания — это синусоида. Это видно, например, на экране звукового редактора. Чтобы точно передать звук, понадобится бесконечное количество значений — вся синусоида. Это возможно при аналоговом соединении. Он поет — вы слушаете, контакт не прерывается, пока длится песня.
При цифровой связи по каналу мы можем передать только конечное количество значений. Значит ли это, что звук нельзя передать точно? Оказывается, нет.
Разные звуки — это по-разному модулированная синусоида. Мы передаем только дискретные значения (частоты и амплитуды), а саму синусоиду передавать не надо — ее может породить принимающий прибор. Он порождает синусоиду, и на нее накладывается модуляция, созданная по значениям, переданным по каналу связи. Существуют точные принципы, какие именно дискретные значения надо передавать, чтобы звук на входе в канал связи совпадал со звуком на выходе, где эти значения накладываются на некоторую стандартную синусоиду (об этом как раз теорема Котельникова).
Теорема Котельникова (в англоязычной литературе — теорема Найквиста — Шеннона, теорема отсчетов) — фундаментальное утверждение в области цифровой обработки сигналов, связывающее непрерывные и дискретные сигналы и гласящее, что «любую функцию F(t), состоящую из частот от 0 до f1, можно непрерывно передавать с любой точностью при помощи чисел, следующих друг за другом через 1/(2*f1) секунд.
Помехоустойчивое кодирование. Коды Хэмминга
Если по ненадежному каналу передать закодированный текст Ивана Тургенева, пусть и с некоторым количеством ошибок, то получится вполне осмысленный текст. Но вот если нам нужно передать все с точностью до бита, задача окажется нерешенной: мы не знаем, какие биты ошибочны, потому что ошибка случайна. Даже контрольная сумма не всегда спасает.
Именно поэтому сегодня при передаче данных по сетям стремятся не столько к оптимальному кодированию, при котором в канал можно затолкать максимальное количество информации, сколько к такому кодированию (заведомо избыточному) при котором можно восстановить ошибки — так, примерно, как мы при чтении восстанавливали слова во фрагменте Ивана Тургенева.
Существуют специальные помехоустойчивые коды, которые позволяют восстанавливать информацию после сбоя. Один из них — код Хэмминга. Допустим, весь наш язык состоит из трех слов: 111000, 001110, 100011. Эти слова знают и источник сообщения, и приемник. И мы знаем, что в канале связи случаются ошибки, но при передаче одного слова искажается не более одного бита информации.
Предположим, мы сначала передаем слово 111000. В результате не более чем одной ошибки (ошибки мы выделили) оно может превратиться в одно из слов:
1) 111000, 011000, 101000, 110000, 111100, 111010, 111001.
При передаче слова 001110 может получиться любое из слов:
2) 001110, 101110, 011110, 000110, 001010, 001100, 001111.
Наконец, для 100011 у нас может получиться на приеме:
3) 100011, 000011, 110011, 101011, 100111, 100001, 100010.
Заметим, что все три списка попарно не пересекаются. Иными словами, если на другом конце канала связи появляется любое слово из списка 1, получатель точно знает, что ему передавали именно слово 111000, а если появляется любое слово из списка 2 — слово 001110, а из списка 3 — слово 100011. В этом случае говорят, что наш код исправил одну ошибку.
Исправление произошло за счет двух факторов. Во-первых, получатель знает весь «словарь», то есть пространство событий получателя сообщения совпадает с пространством того, кто сообщение передал. Когда код передавался всего с одной ошибкой, выходило слово, которого в словаре не было.
Во-вторых, слова в словаре были подобраны особенным образом. Даже при возникновении ошибки получатель не мог перепутать одно слово с другим. Например, если словарь состоит из слов «дочка», «точка», «кочка», и при передаче получалось «вочка», то получатель, зная, что такого слова не бывает, исправить ошибку не смог бы — любое из трех слов может оказаться правильным. Если же в словарь входят «точка», «галка», «ветка» и нам известно, что допускается не больше одной ошибки, то «вочка» это заведомо «точка», а не «галка». В кодах, исправляющих ошибки, слова выбираются именно так, чтобы они были «узнаваемы» даже после ошибки. Разница лишь в том, что в кодовом «алфавите» всего две буквы — ноль и единица.
Избыточность такого кодирования очень велика, а количество слов, которые мы можем таким образом передать, сравнительно невелико. Нам ведь надо исключать из словаря любое слово, которое может при ошибке совпасть с целым списком, соответствующим передаваемым словам (например, в словаре не может быть слов «дочка» и «точка»). Но точная передача сообщения настолько важна, что на исследование помехоустойчивых кодов тратятся большие силы.
Сенсация
Понятия энтропии (или неопределенности и непредсказуемости) сообщения и избыточности (или предопределенности и предсказуемости) очень естественно соответствуют нашим интуитивным представлениям о мере информации. Чем более непредсказуемо сообщение (тем больше его энтропия, потому что меньше вероятность), — тем больше информации оно несет. Сенсация (например, встреча с крокодилом на Тверской) — редкое событие, его предсказуемость очень мала, и потому велика информационная стоимость. Часто информацией называют новости — сообщения о только что произошедших событиях, о которых мы еще ничего не знаем. Но если о случившемся нам расскажут второй и третий раз примерно теми же словами, избыточность сообщения будет велика, его непредсказуемость упадет до нуля, и мы просто не станем слушать, отмахиваясь от говорящего со словами «Знаю, знаю». Поэтому СМИ так стараются быть первыми. Вот это соответствие интуитивному чувству новизны, которое рождает действительно неожиданное известие, и сыграло главную роль в том, что статья Шеннона, совершенно не рассчитанная на массового читателя, стала сенсацией, которую подхватила пресса, которую приняли как универсальный ключ к познанию природы ученые самых разных специальностей — от лингвистов и литературоведов до биологов.
Но понятие информации по Шеннону — строгая математическая теория, и ее применение за пределами теории связи очень ненадежно. Зато в самой теории связи она играет центральную роль.
Семантическая информация
Шеннон, введя понятие энтропии как меры информации, получил возможность работать с информацией — в первую очередь, ее измерять и оценивать такие характеристики, как пропускная способность каналов или оптимальность кодирования. Но главным допущением, которое позволило Шеннону успешно оперировать с информацией, было предположение, что порождение информации — это случайный процесс, который можно успешно описать в терминах теории вероятности. Если процесс неслучайный, то есть он подчиняется закономерностям (к тому же не всегда ясным, как это происходит в естественном языке), то к нему рассуждения Шеннона неприменимы. Все, что говорит Шеннон, никак не связано с осмысленностью информации.
Пока мы говорим о символах (или буквах алфавита), мы вполне можем рассуждать в терминах случайных событий, но как только мы перейдем к словам языка, ситуация резко изменится. Речь — это процесс, особым образом организованный, и здесь структура сообщения не менее важна, чем символы, которыми она передается.
Еще недавно казалось, что мы ничего не можем сделать, чтобы хоть как-то приблизиться к измерению осмысленности текста, но в последние годы ситуация начала меняться. И связано это прежде всего с применением искусственных нейронных сетей к задачам машинного перевода, автоматического реферирования текстов, извлечению информации из текстов, генерированию отчетов на естественном языке. Во всех этих задачах происходит преобразование, кодирование и декодирование осмысленной информации, заключенной в естественном языке. И постепенно складывается представление об информационных потерях при таких преобразованиях, а значит — о мере осмысленной информации. Но на сегодняшний день той четкости и точности, которую имеет шенноновская теория информации, в этих трудных задачах еще нет.
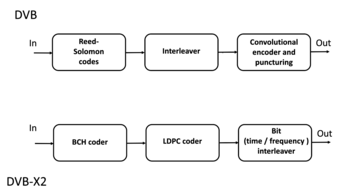
| Коды Рида – Соломона | |
|---|---|
| Названный в честь | Ирвинг С. Рид и Гюстав Соломон |
| Классификация | |
| Иерархия |
Линейный блочный код Полиномиальный код Код Рида – Соломона |
| Длина блока | п |
| Длина сообщения | k |
| Расстояние | п — к + 1 |
| Размер алфавита |
q = p m ≥ n ( p простое) Часто n = q — 1. |
| Обозначение | [ n , k , n — k + 1] q- код |
| Алгоритмы | |
|
Берлекамп – Мэсси Евклидов и др. |
|
| Характеристики | |
| Разделимый код максимального расстояния | |
|
Коды Рида-Соломона представляют собой группу кодов , исправляющих ошибки , которые были введены Ирвингу С. Рид и Густава Соломона в 1960 г. Они имеют множество применений, наиболее известными из которых включают в себя потребительские технологии , такие как минидисков , компакт — диски , DVD — диски , Blu-Ray диски, QR-коды , технологии передачи данных, такие как DSL и WiMAX , системы вещания , такие как спутниковая связь, DVB и ATSC , а также системы хранения, такие как RAID 6 .
Коды Рида – Соломона работают с блоком данных, рассматриваемым как набор элементов с конечным полем, называемых символами. Коды Рида – Соломона способны обнаруживать и исправлять множественные символьные ошибки. Добавляя t = n — k проверочных символов к данным, код Рида – Соломона может обнаруживать (но не исправлять) любую комбинацию до t ошибочных символов или находить и исправлять до ⌊ t / 2⌋ ошибочных символов в неизвестных местах. . В качестве кода стирания он может исправлять до t стираний в местах, которые известны и предоставлены алгоритму, или он может обнаруживать и исправлять комбинации ошибок и стираний. Коды Рида – Соломона также подходят в качестве кодов с множественными пакетами исправления битовых ошибок, поскольку последовательность из b + 1 последовательных битовых ошибок может повлиять не более чем на два символа размера b . Выбор t остается на усмотрение разработчика кода и может выбираться в широких пределах.
Существует два основных типа кодов Рида-Соломона — исходное представление и представление BCH — причем представление BCH является наиболее распространенным, поскольку декодеры представления BCH быстрее и требуют меньше памяти, чем декодеры исходного представления.
История
Коды Рида – Соломона были разработаны в 1960 году Ирвингом С. Ридом и Густавом Соломоном , которые в то время были сотрудниками лаборатории Линкольна Массачусетского технологического института . Их основополагающая статья называлась «Полиномиальные коды над некоторыми конечными полями». ( Рид и Соломон, 1960 ). Исходная схема кодирования, описанная в статье Рида и Соломона, использовала переменный многочлен, основанный на сообщении, которое должно быть закодировано, где кодировщику и декодеру известен только фиксированный набор значений (точек оценки), которые должны быть закодированы. Первоначальный теоретический декодер генерировал потенциальные многочлены на основе подмножеств k (длина незашифрованного сообщения) из n (длина закодированного сообщения) значений полученного сообщения, выбирая наиболее популярный многочлен в качестве правильного, что было непрактично для всех, кроме простейшего из случаи. Первоначально это было решено путем изменения исходной схемы на схему, подобную коду BCH , основанную на фиксированном полиноме, известном как кодеру, так и декодеру, но позже были разработаны практические декодеры на основе исходной схемы, хотя и более медленные, чем схемы BCH. Результатом этого является то, что существует два основных типа кодов Рида-Соломона: те, которые используют исходную схему кодирования, и те, которые используют схему кодирования BCH.
Также в 1960 году практический фиксированный полиномиальный декодер для кодов BCH, разработанный Дэниелом Горенштейном и Нилом Цирлером, был описан в отчете лаборатории Линкольна Массачусетского технологического института, опубликованном Цирлером в январе 1960 года, а затем в статье в июне 1961 года. Декодер Горенштейна – Цирлера и связанная с ним работа коды BCH описаны в книге Уэсли Петерсона (1961) « Коды с исправлением ошибок» . К 1963 году (или, возможно, раньше) Дж. Дж. Стоун (и другие) осознали, что коды Рида-Соломона могут использовать схему BCH с использованием фиксированного полинома генератора, что делает такие коды специальным классом кодов BCH, но коды Рида-Соломона, основанные на исходной кодировке схемы, не являются классом кодов BCH, и в зависимости от набора точек оценки они даже не являются циклическими кодами .
В 1969 году Элвин Берлекамп и Джеймс Мэсси разработали усовершенствованный декодер схемы BCH , который с тех пор известен как алгоритм декодирования Берлекампа-Месси .
В 1975 году Ясуо Сугияма разработал еще один улучшенный декодер схемы BCH, основанный на расширенном алгоритме Евклида .
В 1977 году коды Рида – Соломона были реализованы в программе « Вояджер» в виде составных кодов исправления ошибок . Первое коммерческое применение в массовых потребительских товарах появилось в 1982 году с компакт-диском , где используются два чередующихся кода Рида – Соломона. Сегодня коды Рида-Соломона широко применяются в цифровых устройствах хранения и стандартах цифровой связи , хотя они постепенно заменяются более современными кодами контроля четности с низкой плотностью (LDPC) или турбокодами . Например, коды Рида – Соломона используются в стандарте цифрового видеовещания (DVB) DVB-S , но коды LDPC используются в его преемнике, DVB-S2 .
В 1986 году был разработан оригинальный схемный декодер, известный как алгоритм Берлекампа – Велча .
В 1996 году Мадху Судан и другие разработали варианты декодеров исходной схемы, называемые декодерами списков или программными декодерами, и работа над этими типами декодеров продолжается — см. Алгоритм декодирования списка Гурусвами-Судан .
В 2002 году Шухонг Гао разработал еще одну оригинальную схему декодирования, основанную на расширенном алгоритме Евклида Gao_RS.pdf .
Приложения
Хранилище данных
Кодирование Рида – Соломона очень широко используется в системах хранения данных для исправления пакетных ошибок, связанных с дефектами носителя.
Кодирование Рида – Соломона — ключевой компонент компакт-диска . Это было первое использование кодирования с сильной коррекцией ошибок в массовом потребительском продукте, и DAT и DVD используют аналогичные схемы. В компакт-диске два уровня кодирования Рида – Соломона, разделенные 28-канальным сверточным перемежителем, дают схему, называемую перекрестным чередованием кодирования Рида – Соломона ( CIRC ). Первым элементом декодера CIRC является относительно слабый внутренний (32,28) код Рида – Соломона, сокращенный от кода (255,251) с 8-битовыми символами. Этот код может исправить до 2-х байтовых ошибок на 32-байтовый блок. Что еще более важно, он помечает как стирающие любые неисправимые блоки, т. Е. Блоки с более чем 2-байтовыми ошибками. Декодированные 28-байтовые блоки с индикацией стирания затем распространяются обращенным перемежителем на разные блоки внешнего кода (28,24). Благодаря обращенному чередованию стертый 28-байтовый блок внутреннего кода становится одним стертым байтом в каждом из 28 внешних кодовых блоков. Внешний код легко исправляет это, поскольку он может обрабатывать до 4 таких стираний на блок.
Результатом является CIRC, который может полностью исправить пакеты ошибок размером до 4000 бит или около 2,5 мм на поверхности диска. Этот код настолько силен, что большинство ошибок при воспроизведении компакт-дисков почти наверняка вызваны ошибками отслеживания, которые приводят к смещению трека лазера, а не пакетами неисправимых ошибок.
DVD используют аналогичную схему, но с гораздо большими блоками, внутренним кодом (208,192) и внешним кодом (182,172).
Исправление ошибок Рида – Соломона также используется в файлах архива, которые обычно публикуются вместе с мультимедийными файлами на USENET . Служба распределенного онлайн-хранилища Wuala (прекращенная в 2015 г.) также использовала Рида – Соломона при разделении файлов.
Штрих-код
Почти все двумерные штрих-коды, такие как PDF-417 , MaxiCode , Datamatrix , QR Code и Aztec Code, используют коррекцию ошибок Рида – Соломона, чтобы обеспечить правильное считывание, даже если часть штрих-кода повреждена. Когда сканер штрих-кода не может распознать символ штрих-кода, он будет рассматривать его как стирание.
Кодирование Рида – Соломона менее распространено в одномерных штрих-кодах, но используется в символике PostBar .
Передача информации
Специализированные формы кодов Рида-Соломон, в частности Коши -rs и Вандермонд -rs, может быть использованы для преодоления ненадежного характера передачи данных по стиранию каналов . Процесс кодирования предполагает код RS ( N , K ), который приводит к N кодовым словам длиной N символов, каждое из которых хранит K символов данных, которые генерируются, которые затем отправляются по каналу стирания.
Любой комбинации K кодовых слов, полученных на другом конце, достаточно для восстановления всех N кодовых слов. Кодовая скорость обычно устанавливается равной 1/2, если вероятность стирания канала не может быть адекватно смоделирована и не считается меньшей. В заключение, N обычно составляет 2 К , что означает, что по крайней мере половина всех отправленных кодовых слов должна быть принята, чтобы восстановить все отправленные кодовые слова.
Коды Рида-Соломона также используются в XDSL системах и CCSDS «s спецификации протокола космической связи в форме упреждающей коррекции ошибок .
Космическая передача
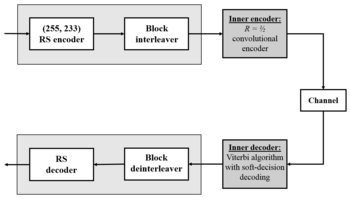
Система конкатенированного кодирования в глубоком космосе. Обозначение: RS (255, 223) + CC («длина ограничения» = 7, кодовая скорость = 1/2).
Одним из важных применений кодирования Рида-Соломона было кодирование цифровых изображений, отправленных обратно программой « Вояджер» .
Вояджер представил кодирование Рида-Соломона, объединенное со сверточными кодами , практика, которая с тех пор стала очень широко распространенной в дальнем космосе и спутниковой связи (например, прямое цифровое вещание).
Декодеры Витерби обычно генерируют ошибки короткими пакетами. Исправление этих пакетных ошибок лучше всего выполнять с помощью коротких или упрощенных кодов Рида – Соломона.
Современные версии конкатенированного сверточного кодирования с декодированием Рида – Соломона / Витерби использовались и используются в миссиях Mars Pathfinder , Galileo , Mars Exploration Rover и Cassini , где они работают в пределах примерно 1–1,5 дБ от конечного предела, пропускной способности Шеннона .
Эти сцепленные коды теперь заменяются более мощными турбокодами :
| Годы | Код | Миссия (и) |
|---|---|---|
| 1958 – настоящее время | Некодированный | Explorer, Mariner, многие другие |
| 1968–1978 | сверточные коды (СС) (25, 1/2) | Пионер, Венера |
| 1969–1975 | Код Рида-Мюллера (32, 6) | Моряк, Викинг |
| 1977 – настоящее время | Двоичный код Голея | Путешественник |
| 1977 – настоящее время | RS (255, 223) + CC (7, 1/2) | Вояджер, Галилей и многие другие |
| 1989–2003 | RS (255, 223) + CC (7, 1/3) | Путешественник |
| 1958 – настоящее время | RS (255, 223) + CC (14, 1/4) | Галилео |
| 1996 – настоящее время | RS + CC (15, 1/6) | Кассини, Mars Pathfinder, другие |
| 2004 – настоящее время | Турбо коды | Посланник, стерео, ТОиР, другие |
| оценка 2009 г. | Коды LDPC | Созвездие, MSL |
Конструкции (кодировка)
Код Рида – Соломона на самом деле представляет собой семейство кодов, где каждый код характеризуется тремя параметрами: размером алфавита q , длиной блока n и длиной сообщения k, где k <n ≤ q. Набор символов алфавита интерпретируется как конечное поле порядка q , поэтому q должно быть степенью простого числа . В наиболее полезных параметризациях кода Рида – Соломона длина блока обычно является некоторым постоянным кратным длине сообщения, то есть скорость R = k / n является некоторой константой, и, кроме того, длина блока равна или единице меньше размера алфавита, то есть n = q или n = q — 1 .
Исходный взгляд Рида и Соломона: кодовое слово как последовательность значений
Существуют разные процедуры кодирования для кода Рида – Соломона, и, следовательно, существуют разные способы описания набора всех кодовых слов. В исходной точке зрения Рида и Соломона (1960) каждое кодовое слово кода Рида – Соломона представляет собой последовательность значений функций полинома степени меньше k . Чтобы получить кодовое слово кода Рида – Соломона, символы сообщения (каждый в алфавите размера q) обрабатываются как коэффициенты многочлена p степени меньше k над конечным полем F с q элементами. В свою очередь, многочлен p оценивается в n ≤ q различных точках поля F , и последовательность значений представляет собой соответствующее кодовое слово. Обычный выбор для набора точек оценки включает {0, 1, 2, …, n — 1}, {0, 1, α , α 2 , …, α n −2 } или для n < q , {1, α , & alpha ; 2 , …, α п -1 }, …, где α представляет собой примитивный элемент из F .

Формально набор кодовых слов кода Рида – Соломона определяется следующим образом:


Поскольку любые два различных полинома степени меньше, чем совпадают в большинстве точек, это означает, что любые два кодовых слова кода Рида – Соломона не согласуются по крайней мере в позициях. Кроме того, есть два многочлена, которые совпадают в точках, но не равны, и, таким образом, расстояние кода Рида – Соломона точно . Тогда относительное расстояние , где — скорость. Этот компромисс между относительным расстоянием и скоростью является асимптотически оптимальным, поскольку, согласно границе Синглтона , удовлетворяет каждый код . Код Рида – Соломона, являющийся кодом, позволяющим достичь этого оптимального компромисса, принадлежит к классу кодов с разделением на максимальное расстояние .







Хотя количество различных многочленов степени меньше k и количество разных сообщений равны , и, таким образом, каждое сообщение может быть однозначно отображено на такой многочлен, существуют разные способы выполнения этого кодирования. Первоначальная конструкция Рида и Соломона (1960) интерпретирует сообщение x как коэффициенты многочлена p , тогда как последующие конструкции интерпретируют сообщение как значения многочлена в первых k точках и получают многочлен p путем интерполяции этих значений с помощью многочлен степени меньше k . Последняя процедура кодирования, хотя и немного менее эффективна, имеет то преимущество, что она дает систематический код , то есть исходное сообщение всегда содержится как подпоследовательность кодового слова.


Простая процедура кодирования: сообщение как последовательность коэффициентов.
В исходной конструкции Рида и Соломона (1960) сообщение отображается в многочлен с



Кодовое слово получается путем оценки в разных точках поля . Таким образом, классическая функция кодирования для кода Рида – Соломона определяется следующим образом:





Эта функция является линейным отображением , то есть удовлетворяет следующей -матрице с элементами из :





Эта матрица является транспонирование матрицы Вандермонда над . Другими словами, код Рида – Соломона является линейным кодом , а в классической процедуре кодирования его порождающая матрица имеет вид .
Систематическая процедура кодирования: сообщение как начальная последовательность значений.
Существует альтернативная процедура кодирования, которая также производит код Рида – Соломона, но делает это систематическим образом. Здесь отображение сообщения в полином работает по-другому: полином теперь определяется как уникальный полином меньшей степени, чем такой, что
-
 справедливо для всех .
справедливо для всех .


Чтобы вычислить этот многочлен от , можно использовать Лагранжа интерполяции . Как только он был найден, он оценивается в других точках поля. Альтернативная функция кодирования для кода Рида – Соломона снова представляет собой просто последовательность значений:

Поскольку первые записи каждого кодового слова совпадают с , эта процедура кодирования действительно является систематической . Поскольку интерполяция Лагранжа является линейным преобразованием, является линейным отображением. Фактически, мы имеем , где



Дискретное преобразование Фурье и его обратное
Дискретное преобразование Фурье , по существу , такой же , как процедура кодирования; он использует полином генератора p (x) для отображения набора точек оценки в значения сообщения, как показано выше:
Обратное преобразование Фурье может использоваться для преобразования безошибочного набора из n < q значений сообщения обратно в кодирующий полином из k коэффициентов с ограничением, что для того, чтобы это работало, набор точек оценки, используемых для кодирования сообщения, должен — набор возрастающих степеней α :


Однако интерполяция Лагранжа выполняет то же преобразование без ограничения на набор точек оценки или требования безошибочного набора значений сообщения и используется для систематического кодирования и на одном из этапов декодера Gao .
Представление BCH: кодовое слово как последовательность коэффициентов
В этом представлении сообщение интерпретируется как коэффициенты многочлена . Отправитель вычисляет связанный многочлен степени где и отправляет многочлен . Полином создается путем умножения полинома сообщения , имеющего степень , на порождающий полином степени, который известен как отправителю, так и получателю. Генераторный полином определяется как полином, корни которого являются последовательными степенями примитива поля Галуа







Для «узкого смысла кода» .


Систематическая процедура кодирования
Процедура кодирования для представления кодов Рида – Соломона BCH может быть изменена для получения систематической процедуры кодирования , в которой каждое кодовое слово содержит сообщение в качестве префикса и просто добавляет символы с исправлением ошибок в качестве суффикса. Здесь, вместо отправки , кодер строит переданный многочлен так , что коэффициенты наибольших одночленов равны соответствующим коэффициентам , а младшие коэффициенты выбираются точно таким образом, чтобы делиться на . Тогда коэффициенты при являются подпоследовательностью коэффициентов при . Чтобы получить в целом систематический код, мы строим полином сообщения , интерпретируя сообщение как последовательность его коэффициентов.

Формально построение выполняется путем умножения на, чтобы освободить место для символов проверки, деления этого произведения на, чтобы найти остаток, а затем компенсации этого остатка путем его вычитания. Контрольные символы создаются путем вычисления остатка :





Остаток имеет степень не выше , а коэффициенты многочлена равны нулю. Следовательно, следующее определение кодового слова обладает тем свойством, что первые коэффициенты идентичны коэффициентам :




В результате кодовые слова действительно являются элементами , то есть делятся на порождающий полином :

Характеристики
Код Рида – Соломона представляет собой код [ n , k , n — k + 1]; другими словами, это линейный блочный код длины n (над F ) с размерностью k и минимальным расстоянием Хэмминга. Код Рида-Соломона оптимален в том смысле, что минимальное расстояние имеет максимальное значение, возможное для линейного кода размера ( п , л ); это известно как граница Синглтона . Такой код также называется кодом с разделением на максимальное расстояние (MDS) .

Способность кода Рида-Соломона исправлять ошибки определяется его минимальным расстоянием или, что эквивалентно , мерой избыточности в блоке. Если расположение ошибочных символов заранее не известно, то код Рида – Соломона может исправить до ошибочных символов, т. Е. Он может исправить вдвое меньше ошибок, чем есть избыточные символы, добавленные в блок. Иногда местоположения ошибок известны заранее (например, «дополнительная информация» в отношениях сигнал / шум демодулятора ) — это называется стиранием . Рида-Соломона (как и любой код MDS ) способен корректировать в два раза больше стираний как ошибки, и любой комбинации ошибок и стираний могут быть исправлены до тех пор , как отношение 2 Е + S ≤ п — к удовлетворяется, где находится количество ошибок и — количество стираний в блоке.




Теоретическая производительность BER кода Рида-Соломона (N = 255, K = 233, QPSK, AWGN). Ступенчатая характеристика.
Теоретическая граница ошибки может быть описана следующей формулой для канала AWGN для FSK :

и для других схем модуляции:

где , , , является частотой ошибок символов в незакодированном АБГШЕ случае и является порядком модуляции.





Для практического использования кодов Рида – Соломона обычно используется конечное поле с элементами. В этом случае каждый символ может быть представлен как битовое значение. Отправитель отправляет точки данных как закодированные блоки, а количество символов в закодированном блоке равно . Таким образом, код Рида-Соломона, работающий с 8-битовыми символами, имеет символы на блок. (Это очень популярным значение из — за распространенности байт-ориентированных компьютерных систем.) Число , с , из данных символов в блок является параметром конструкции. Обычно используемый код кодирует восьмибитовые символы данных плюс 32 восьмибитовых символа четности в блоке -символа; он обозначается как код и может исправлять до 16 символьных ошибок на блок.








Обсуждаемые выше свойства кода Рида – Соломона делают его особенно подходящим для приложений, в которых ошибки возникают в пакетном режиме . Это связано с тем, что для кода не имеет значения, сколько битов в символе ошибочно — если несколько битов в символе повреждены, это считается только одной ошибкой. И наоборот, если поток данных характеризуется не всплесками или пропаданием ошибок, а случайными одиночными битовыми ошибками, код Рида – Соломона обычно является плохим выбором по сравнению с двоичным кодом.
Код Рида – Соломона, как и сверточный код , является прозрачным кодом. Это означает, что если символы канала были инвертированы где-то вдоль линии, декодеры все равно будут работать. Результатом будет инверсия исходных данных. Однако код Рида – Соломона теряет прозрачность при сокращении кода. «Недостающие» биты в сокращенном коде необходимо заполнить нулями или единицами, в зависимости от того, дополняются ли данные или нет. (Другими словами, если символы инвертированы, то заполнение нулями должно быть инвертировано в заполнение одним.) По этой причине обязательно, чтобы смысл данных (т.е. истинный или дополняемый) был разрешен до декодирования Рида – Соломона.
Будет ли код Рида-Соломона является циклическим или нет , зависит от тонких деталей конструкции. В исходной точке зрения Рида и Соломона, где кодовые слова являются значениями полинома, можно выбрать последовательность точек оценки таким образом, чтобы сделать код циклическим. В частности, если является примитивным корнем поля , то по определению все ненулевые элементы принимают вид для , где . Каждый полином по дает кодовое слово . Поскольку функция также является многочленом той же степени, эта функция дает кодовое слово ; поскольку выполняется, это кодовое слово является циклическим сдвигом влево исходного кодового слова, полученного из . Таким образом, выбор последовательности примитивных корневых степеней в качестве точек оценки делает исходное представление кода Рида – Соломона циклическим . Коды Рида – Соломона в представлении BCH всегда циклические, потому что коды BCH цикличны .








От разработчиков не требуется использовать «естественные» размеры блоков кода Рида – Соломона. Метод, известный как «сокращение», может производить меньший код любого желаемого размера из большего кода. Например, широко используемый код (255,223) можно преобразовать в код (160,128), добавив в неиспользуемую часть исходного блока 95 двоичных нулей и не передав их. В декодере та же часть блока загружается локально двоичными нулями. Теорема Дельсарта – Гетальса – Зейделя иллюстрирует пример применения сокращенных кодов Рида – Соломона. Параллельно с сокращением метод, известный как выкалывание, позволяет опускать некоторые закодированные символы четности.
Декодеры просмотра BCH
Декодеры, описанные в этом разделе, используют представление BCH кодового слова как последовательности коэффициентов. Они используют фиксированный полином генератора, известный как кодировщику, так и декодеру.
Декодер Петерсона – Горенштейна – Цирлера
Даниэль Горенштейн и Нил Цирлер разработали декодер, который был описан Цирлером в отчете лаборатории Линкольна Массачусетского технологического института в январе 1960 года, а затем в статье в июне 1961 года. Декодер Горенштейна – Цирлера и связанная с ним работа над кодами BCH описаны в книге « Исправление ошибок». коды по В. Уэсли Петерсон (1961).
Формулировка
Переданное сообщение рассматривается как коэффициенты многочлена s ( x ):


В результате процедуры кодирования Рида-Соломона s ( x ) делится на порождающий полином g ( x ):

где α — первообразный корень.
Поскольку s ( x ) кратно генератору g ( x ), отсюда следует, что он «наследует» все свои корни:

Переданный полином искажается при передаче полиномом ошибок e ( x ), чтобы получить полученный полином r ( x ).


Коэффициент e i будет равен нулю, если нет ошибки при этой степени x, и ненулевым, если есть ошибка. Если имеется ν ошибок при различных степенях i k функции x , то

Цель декодера — найти количество ошибок ( ν ), позиции ошибок ( i k ) и значения ошибок в этих позициях ( e i k ). Из них можно вычислить e ( x ) и вычесть из r ( x ), чтобы получить первоначально отправленное сообщение s ( x ).
Расшифровка синдрома
Декодер начинает с оценки полинома, полученного в точках . Мы называем результаты этой оценки «синдромами», S j . Они определяются как:


Преимущество рассмотрения синдромов в том, что полином сообщения выпадает. Другими словами, синдромы относятся только к ошибке и не зависят от фактического содержимого передаваемого сообщения. Если все синдромы равны нулю, алгоритм останавливается на этом и сообщает, что сообщение не было повреждено при передаче.
Локаторы ошибок и значения ошибок
Для удобства определите локаторы ошибок X k и значения ошибок Y k как:

Тогда синдромы могут быть записаны в терминах этих локаторов ошибок и значений ошибок как

Это определение значений синдрома эквивалентно предыдущему, поскольку .

Синдромы дают систему n — k ≥ 2 ν уравнений с 2 ν неизвестными, но эта система уравнений нелинейна по X k и не имеет очевидного решения. Однако, если X k были известны (см. Ниже), то синдромные уравнения представляют собой линейную систему уравнений, которую можно легко решить для значений ошибки Y k .

Следовательно, проблема заключается в нахождении X k , потому что тогда была бы известна крайняя левая матрица, и обе части уравнения можно было бы умножить на обратное, что даст Y k
В варианте этого алгоритма, где местоположения ошибок уже известны (когда он используется в качестве кода стирания ), это конец. Места возникновения ошибок ( X k ) уже известны некоторым другим методом (например, в FM-передаче участки, где поток битов был нечетким или преодолен с помехами, можно определить с помощью частотного анализа с вероятностью). В этом сценарии можно исправить до ошибок.
Остальная часть алгоритма служит для поиска ошибок и потребует значений синдрома вплоть до , а не только используемых до сих пор. Вот почему необходимо добавить в 2 раза больше символов исправления ошибок, чем можно исправить, не зная их местоположения.


Многочлен локатора ошибок
Существует линейное рекуррентное соотношение, порождающее систему линейных уравнений. Решение этих уравнений идентифицирует эти места ошибки X k .
Определим полином локатора ошибок Λ ( x ) как

Нули Λ ( x ) являются обратными . Это следует из приведенной выше конструкции обозначения произведения, поскольку, если тогда один из умноженных членов будет равен нулю , в результате чего весь полином будет равен нулю.




Позвольте быть любое целое число такое, что . Умножьте обе стороны на, и получится ноль.




Суммируйте от k = 1 до ν, и оно все равно будет равно нулю.

Соберите каждый член в отдельную сумму.

Извлеките постоянные значения, на которые суммирование не влияет.


Эти суммы теперь эквивалентны значениям синдромов, которые мы знаем и можем подставить! Следовательно, это сводится к

Вычитание с обеих сторон дает


Напомним, что j было выбрано как любое целое число от 1 до v включительно, и эта эквивалентность верна для любого и всех таких значений. Следовательно, у нас есть v линейных уравнений, а не одно. Таким образом, эта система линейных уравнений может быть решена относительно коэффициентов Λ i полинома определения ошибки:

Вышесказанное предполагает, что декодеру известно количество ошибок ν , но это количество еще не определено. Декодер PGZ не определяет ν напрямую, а скорее ищет его, пробуя последовательные значения. Декодер сначала принимает наибольшее значение для пробного ν и устанавливает линейную систему для этого значения. Если уравнения могут быть решены (т. Е. Определитель матрицы отличен от нуля), то пробным значением является количество ошибок. Если линейная система не может быть решена, тогда испытание ν сокращается на единицу, и исследуется следующая меньшая система. ( Гилл , стр. 35)
Найдите корни полинома локатора ошибок
Используйте коэффициенты Λ i, найденные на последнем шаге, для построения полинома местоположения ошибки. Корни полинома определения местоположения ошибки могут быть найдены путем исчерпывающего поиска. Локаторы ошибок X k являются обратными этим корням. Порядок коэффициентов полинома определения местоположения ошибки может быть изменен на обратный, и в этом случае корни этого обратного полинома являются локаторами ошибок (а не их обратными величинами ). Поиск Chien — эффективное выполнение этого шага.

Рассчитайте значения ошибок
Как только локаторы ошибок X k известны, можно определить значения ошибок. Это можно сделать прямым решением для Y k в матрице уравнений ошибок, приведенной выше, или с помощью алгоритма Форни .
Рассчитайте места ошибок
Вычислить я K , взяв логарифм с основанием из X к . Обычно это делается с помощью предварительно вычисленной справочной таблицы.
Исправьте ошибки
Наконец, e (x) генерируется из i k и e i k, а затем вычитается из r (x), чтобы получить первоначально отправленное сообщение s (x) с исправленными ошибками.
Пример
Рассмотрим код Рида – Соломона, определенный в GF (929) с α = 3 и t = 4 (это используется в штрих- кодах PDF417 ) для кода RS (7,3). Генераторный полином равен

Если полином сообщения равен p ( x ) = 3 x 2 + 2 x + 1 , то систематическое кодовое слово кодируется следующим образом.


Ошибки при передаче могут привести к получению этого сообщения.

Синдромы рассчитываются путем оценки r при степенях α .



Использование исключения Гаусса :

- Λ (x) = 329 x 2 + 821 x + 001, с корнями x 1 = 757 = 3 −3 и x 2 = 562 = 3 −4
Коэффициенты можно поменять местами, чтобы получить корни с положительными показателями, но обычно это не используется:
- R (x) = 001 x 2 + 821 x + 329, с корнями 27 = 3 3 и 81 = 3 4
с журналом корней, соответствующим местоположениям ошибок (справа налево, ячейка 0 — последний член в кодовом слове).
Чтобы вычислить значения ошибок, примените алгоритм Форни .
- Ω (x) = S (x) Λ (x) mod x 4 = 546 x + 732
- Λ ‘(х) = 658 х + 821
- е 1 = −Ω (x 1 ) / Λ ‘(x 1 ) = 074
- е 2 = −Ω (x 2 ) / Λ ‘(x 2 ) = 122
Вычитание из полученного полинома r (x) воспроизводит исходное кодовое слово s .

Декодер Берлекампа – Месси
Алгоритм Берлекемп-Massey альтернативная итерационная процедура для нахождения локатора ошибки полинома. Во время каждой итерации он вычисляет расхождение на основе текущего экземпляра Λ (x) с предполагаемым количеством ошибок e :

а затем регулирует Λ ( x ) и e так, чтобы пересчитанное Δ было равно нулю. В статье « Алгоритм Берлекампа – Месси » подробно описана процедура. В следующем примере C ( x ) используется для представления Λ ( x ).
Пример
Используя те же данные, что и в приведенном выше примере Peterson Gorenstein Zierler:
| п | S n +1 | d | C | B | б | м |
|---|---|---|---|---|---|---|
| 0 | 732 | 732 | 197 х + 1 | 1 | 732 | 1 |
| 1 | 637 | 846 | 173 х + 1 | 1 | 732 | 2 |
| 2 | 762 | 412 | 634 х 2 + 173 х + 1 | 173 х + 1 | 412 | 1 |
| 3 | 925 | 576 | 329 х 2 + 821 х + 1 | 173 х + 1 | 412 | 2 |
Конечным значением C является многочлен локатора ошибок Λ ( x ).
Евклидов декодер
Другой итерационный метод вычисления как полинома локатора ошибок, так и полинома значения ошибки основан на адаптации Сугиямы расширенного алгоритма Евклида .
Определите S (x), Λ (x) и Ω (x) для t синдромов и e ошибок:



Ключевое уравнение:

Для t = 6 и e = 3:

Средние члены равны нулю из-за связи между Λ и синдромами.
Расширенный алгоритм Евклида может найти серию многочленов вида
- А я ( х ) S ( х ) + В я ( х ) х t = R я ( х )
где степень R уменьшается с увеличением i . Если степень R i ( x ) < t / 2, то
А я (х) = Λ (х)
В я (х) = -Q (х)
R i (x) = Ω (x).
B (x) и Q (x) сохранять не нужно, поэтому алгоритм становится:
- R −1 = x t
- R 0 = S (х)
- А −1 = 0
- А 0 = 1
- я = 0
- а степень R i ≥ t / 2
- я = я + 1
- Q = R i-2 / R i-1
- R i = R i-2 — QR i-1
- A i = A i-2 — QA i-1
чтобы установить младший член Λ (x) равным 1, разделите Λ (x) и Ω (x) на A i (0):
- Λ (х) = A i / A i (0)
- Ω (х) = R i / A i (0)
A i (0) — постоянный член (младшего разряда) A i .
Пример
Используя те же данные, что и в приведенном выше примере Петерсона – Горенштейна – Цирлера:
| я | R i | А я |
|---|---|---|
| −1 | 001 х 4 + 000 х 3 + 000 х 2 + 000 х + 000 | 000 |
| 0 | 925 х 3 + 762 х 2 + 637 х + 732 | 001 |
| 1 | 683 х 2 + 676 х + 024 | 697 х + 396 |
| 2 | 673 х + 596 | 608 х 2 + 704 х + 544 |
- Λ (х) = A 2 /544 = 329 х 2 + 821 + 001 х
- Ω (х) = Р 2 / = 546 544 По й + 732
Декодер с использованием дискретного преобразования Фурье
Для декодирования можно использовать дискретное преобразование Фурье. Чтобы избежать конфликта с названиями синдромов, пусть c ( x ) = s ( x ) закодированное кодовое слово. r ( x ) и e ( x ) такие же, как указано выше. Определите C ( x ), E ( x ) и R ( x ) как дискретные преобразования Фурье для c ( x ), e ( x ) и r ( x ). Поскольку r ( x ) = c ( x ) + e ( x ) и поскольку дискретное преобразование Фурье является линейным оператором, R ( x ) = C ( x ) + E ( x ).
Преобразуйте r ( x ) в R ( x ), используя дискретное преобразование Фурье. Поскольку вычисление для дискретного преобразования Фурье такое же, как вычисление для синдромов, коэффициенты t для R ( x ) и E ( x ) такие же, как для синдромов:


Используйте сквозные как синдромы (они одинаковые) и сгенерируйте полином локатора ошибок, используя методы любого из вышеперечисленных декодеров.


Пусть v = количество ошибок. Генерация Е (х) с использованием известных коэффициентов к , локатор ошибки полинома, и эти формулы





Затем вычислите C ( x ) = R ( x ) — E ( x ) и выполните обратное преобразование (полиномиальную интерполяцию) C ( x ), чтобы получить c ( x ).
Декодирование за пределами исправления ошибок
Граница синглтона состояния , что минимальное расстояние d линейного блочного кода размера ( п , K ) ограничена сверху на п — к + 1 расстояние d обычно понимается , чтобы ограничить возможность коррекции ошибок к ⌊ (d- 1) / 2⌋. Код Рида – Соломона достигает этой границы с равенством и, таким образом, может исправлять до (nk) / 2⌋ ошибок. Однако эта граница исправления ошибок не точна.
В 1999 году Мадху Судан и Венкатесан Гурусвами из Массачусетского технологического института опубликовали «Улучшенное декодирование кодов Рида – Соломона и алгебраической геометрии», в котором представлен алгоритм, позволяющий исправлять ошибки, превышающие половину минимального расстояния кода. Это применимо к кодам Рида – Соломона и в более общем плане к алгебро-геометрическим кодам . Этот алгоритм создает список кодовых слов (это алгоритм декодирования списка ) и основан на интерполяции и факторизации многочленов и их расширений.

Мягкое декодирование
Алгебраические методы декодирования, описанные выше, являются методами жесткого решения, что означает, что для каждого символа принимается жесткое решение о его значении. Например, декодер может связать с каждым символом дополнительное значение, соответствующее уверенности демодулятора канала в правильности символа. Появление LDPC и турбокодов , в которых используются итерационные методы декодирования распространения уверенности с мягким решением для достижения эффективности исправления ошибок, близкой к теоретическому пределу , подстегнуло интерес к применению декодирования с мягким решением к традиционным алгебраическим кодам. В 2003 году Ральф Кёттер и Александр Варди представили алгоритм полиномиального алгебраического декодирования списков с мягким решением для кодов Рида – Соломона, который был основан на работе Судана и Гурусвами. В 2016 году Стивен Дж. Франке и Джозеф Х. Тейлор опубликовали новый декодер мягкого решения.
Пример Matlab
Кодировщик
Здесь мы представляем простую реализацию Matlab для кодировщика.
function [encoded] = rsEncoder(msg, m, prim_poly, n, k) % RSENCODER Encode message with the Reed-Solomon algorithm % m is the number of bits per symbol % prim_poly: Primitive polynomial p(x). Ie for DM is 301 % k is the size of the message % n is the total size (k+redundant) % Example: msg = uint8('Test') % enc_msg = rsEncoder(msg, 8, 301, 12, numel(msg)); % Get the alpha alpha = gf(2, m, prim_poly); % Get the Reed-Solomon generating polynomial g(x) g_x = genpoly(k, n, alpha); % Multiply the information by X^(n-k), or just pad with zeros at the end to % get space to add the redundant information msg_padded = gf([msg zeros(1, n - k)], m, prim_poly); % Get the remainder of the division of the extended message by the % Reed-Solomon generating polynomial g(x) [~, remainder] = deconv(msg_padded, g_x); % Now return the message with the redundant information encoded = msg_padded - remainder; end % Find the Reed-Solomon generating polynomial g(x), by the way this is the % same as the rsgenpoly function on matlab function g = genpoly(k, n, alpha) g = 1; % A multiplication on the galois field is just a convolution for k = mod(1 : n - k, n) g = conv(g, [1 alpha .^ (k)]); end end
Декодер
Теперь расшифровка:
function [decoded, error_pos, error_mag, g, S] = rsDecoder(encoded, m, prim_poly, n, k) % RSDECODER Decode a Reed-Solomon encoded message % Example: % [dec, ~, ~, ~, ~] = rsDecoder(enc_msg, 8, 301, 12, numel(msg)) max_errors = floor((n - k) / 2); orig_vals = encoded.x; % Initialize the error vector errors = zeros(1, n); g = []; S = []; % Get the alpha alpha = gf(2, m, prim_poly); % Find the syndromes (Check if dividing the message by the generator % polynomial the result is zero) Synd = polyval(encoded, alpha .^ (1:n - k)); Syndromes = trim(Synd); % If all syndromes are zeros (perfectly divisible) there are no errors if isempty(Syndromes.x) decoded = orig_vals(1:k); error_pos = []; error_mag = []; g = []; S = Synd; return; end % Prepare for the euclidean algorithm (Used to find the error locating % polynomials) r0 = [1, zeros(1, 2 * max_errors)]; r0 = gf(r0, m, prim_poly); r0 = trim(r0); size_r0 = length(r0); r1 = Syndromes; f0 = gf([zeros(1, size_r0 - 1) 1], m, prim_poly); f1 = gf(zeros(1, size_r0), m, prim_poly); g0 = f1; g1 = f0; % Do the euclidean algorithm on the polynomials r0(x) and Syndromes(x) in % order to find the error locating polynomial while true % Do a long division [quotient, remainder] = deconv(r0, r1); % Add some zeros quotient = pad(quotient, length(g1)); % Find quotient*g1 and pad c = conv(quotient, g1); c = trim(c); c = pad(c, length(g0)); % Update g as g0-quotient*g1 g = g0 - c; % Check if the degree of remainder(x) is less than max_errors if all(remainder(1:end - max_errors) == 0) break; end % Update r0, r1, g0, g1 and remove leading zeros r0 = trim(r1); r1 = trim(remainder); g0 = g1; g1 = g; end % Remove leading zeros g = trim(g); % Find the zeros of the error polynomial on this galois field evalPoly = polyval(g, alpha .^ (n - 1 : - 1 : 0)); error_pos = gf(find(evalPoly == 0), m); % If no error position is found we return the received work, because % basically is nothing that we could do and we return the received message if isempty(error_pos) decoded = orig_vals(1:k); error_mag = []; return; end % Prepare a linear system to solve the error polynomial and find the error % magnitudes size_error = length(error_pos); Syndrome_Vals = Syndromes.x; b(:, 1) = Syndrome_Vals(1:size_error); for idx = 1 : size_error e = alpha .^ (idx * (n - error_pos.x)); err = e.x; er(idx, :) = err; end % Solve the linear system error_mag = (gf(er, m, prim_poly) gf(b, m, prim_poly))'; % Put the error magnitude on the error vector errors(error_pos.x) = error_mag.x; % Bring this vector to the galois field errors_gf = gf(errors, m, prim_poly); % Now to fix the errors just add with the encoded code decoded_gf = encoded(1:k) + errors_gf(1:k); decoded = decoded_gf.x; end % Remove leading zeros from Galois array function gt = trim(g) gx = g.x; gt = gf(gx(find(gx, 1) : end), g.m, g.prim_poly); end % Add leading zeros function xpad = pad(x, k) len = length(x); if (len < k) xpad = [zeros(1, k - len) x]; end end
Оригинальные декодеры вида Рида Соломона
Декодеры, описанные в этом разделе, используют исходное представление кодового слова Рида-Соломона как последовательность полиномиальных значений, где полином основан на кодируемом сообщении. Один и тот же набор фиксированных значений используется кодером и декодером, и декодер восстанавливает полином кодирования (и, возможно, полином обнаружения ошибки) из полученного сообщения.
Теоретический декодер
Рид и Соломон (1960) описали теоретический декодер, который исправляет ошибки, находя самый популярный полином сообщений. Декодер знает только набор значений , чтобы и какой метод кодирования был использован для генерации последовательности кодового слова в значений. Исходное сообщение, многочлен и любые ошибки неизвестны. Процедура декодирования может использовать такой метод, как интерполяция Лагранжа на различных подмножествах из n значений кодового слова, взятых k за раз, для многократного создания потенциальных многочленов, пока не будет создано достаточное количество совпадающих многочленов, чтобы разумно устранить любые ошибки в полученном кодовом слове. После определения полинома любые ошибки в кодовом слове могут быть исправлены путем пересчета соответствующих значений кодового слова. К сожалению, во всех случаях, кроме самых простых, существует слишком много подмножеств, поэтому алгоритм непрактичен. Количество подмножеств — это биномиальный коэффициент , а количество подмножеств невозможно даже для скромных кодов. Для кода, который может исправить 3 ошибки, простой теоретический декодер исследовал бы 359 миллиардов подмножеств.




Декодер Berlekamp Welch
В 1986 году был разработан декодер, известный как алгоритм Берлекампа – Велча, как декодер, способный восстанавливать исходный полином сообщения, а также полином «локатора» ошибок, который выдает нули для входных значений, соответствующих ошибкам, с временной сложностью. O (n ^ 3), где n — количество значений в сообщении. Восстановленный полином затем используется для восстановления (при необходимости пересчета) исходного сообщения.
Пример
Используя RS (7,3), GF (929) и набор точек оценки a i = i — 1
- а = {0, 1, 2, 3, 4, 5, 6}
Если полином сообщения
- р ( х ) = 003 х 2 + 002 х + 001
Кодовое слово
- c = {001, 006, 017, 034, 057, 086, 121}
Ошибки при передаче могут привести к получению этого сообщения.
- b = c + e = {001, 006, 123, 456, 057, 086, 121}
Ключевые уравнения:

Предположим максимальное количество ошибок: e = 2. Ключевые уравнения принимают следующий вид:


Использование исключения Гаусса :

- Q ( x ) = 003 x 4 + 916 x 3 + 009 x 2 + 007 x + 006
- Е ( х ) = 001 х 2 + 924 х + 006
- Q ( x ) / E ( x ) = P ( x ) = 003 x 2 + 002 x + 001
Пересчитайте P (x), где E (x) = 0: {2, 3}, чтобы исправить b, что приведет к исправлению кодового слова:
- c = {001, 006, 017, 034, 057, 086, 121}
Декодер гао
В 2002 году Шухонг Гао разработал улучшенный декодер на основе расширенного алгоритма Евклида Gao_RS.pdf .
Пример
Используя те же данные, что и в приведенном выше примере Berlekamp Welch:
-
Интерполяция Лагранжа для i = от 1 до n





| я | R i | А я |
|---|---|---|
| −1 | 001 х 7 + 908 х 6 + 175 х 5 + 194 х 4 + 695 х 3 + 094 х 2 + 720 х + 000 | 000 |
| 0 | 055 х 6 + 440 х 5 + 497 х 4 + 904 х 3 + 424 х 2 + 472 х + 001 | 001 |
| 1 | 702 х 5 + 845 х 4 + 691 х 3 + 461 х 2 + 327 х + 237 | 152 х + 237 |
| 2 | 266 х 4 + 086 х 3 + 798 х 2 + 311 х + 532 | 708 х 2 + 176 х + 532 |
- Q ( х ) = R 2 = 266 х 4 + 086 х 3 + 798 х 2 + 311 х + 532
- Е ( х ) = А 2 = 708 х 2 + 176 х + 532
разделите Q (x) и E (x) на наиболее значимый коэффициент при E (x) = 708. (Необязательно)
- Q ( x ) = 003 x 4 + 916 x 3 + 009 x 2 + 007 x + 006
- Е ( х ) = 001 х 2 + 924 х + 006
- Q ( x ) / E ( x ) = P ( x ) = 003 x 2 + 002 x + 001
Пересчитайте P ( x ), где E ( x ) = 0: {2, 3}, чтобы исправить b, что приведет к исправлению кодового слова:
- c = {001, 006, 017, 034, 057, 086, 121}
Смотрите также
- Код BCH
- Циклический код
- Чиен поиск
- Алгоритм Берлекампа – Месси
- Прямое исправление ошибок
- Алгоритм Берлекампа – Велча
- Сложенный код Рида – Соломона
Примечания
использованная литература
дальнейшее чтение
- Гилл, Джон (nd), EE387 Notes # 7, раздаточный материал # 28 (PDF) , Стэнфордский университет, заархивировано из оригинала (PDF) 30 июня 2014 г. , получено 21 апреля 2010 г.
- Хонг, Джонатан; Веттерли, Martin (август 1995), «Простые алгоритмы МПБ декодировании» (PDF) , IEEE Transactions по сообщениям , 43 (8): 2324-2333, DOI : 10,1109 / 26.403765
- Линь, Шу; Костелло младший, Дэниел Дж. (1983), Кодирование с контролем ошибок: основы и приложения , Нью-Джерси, Нью-Джерси: Прентис-Холл, ISBN 978-0-13-283796-5
- Масси, JL (1969), «Синтез регистра сдвига и ВСН декодирования» (PDF) , IEEE Transactions по теории информации , ИТ-15 (1): 122-127, DOI : 10,1109 / tit.1969.1054260
- Петерсон, Уэсли В. (1960), «Процедуры кодирования и исправления ошибок для кодов Бозе-Чоудхури», IRE Сделки по теории информации , IT-6 (4): 459-470, DOI : 10,1109 / TIT.1960.1057586
- Рид, Ирвинг С .; Соломон, Гюстав (1960), « О полиномиальных кодов над некоторыми конечными полями», журнал Общества промышленной и прикладной математики , 8 (2): 300-304, DOI : 10,1137 / 0108018
- Уэлч, Л. Р. (1997), Исходный взгляд на коды Рида – Соломона (PDF) , Примечания к лекциям
- Берлекамп, Элвин Р. (1967), Недвоичное декодирование BCH , Международный симпозиум по теории информации, Сан-Ремо, Италия
- Берлекамп, Элвин Р. (1984) [1968], Алгебраическая теория кодирования (пересмотренная редакция), Лагуна-Хиллз, Калифорния: Aegean Park Press, ISBN 978-0-89412-063-3
- Ципра, Барри Артур (1993), «Вездесущие коды Рида – Соломона» , SIAM News , 26 (1)
- Форни-младший, Г. (октябрь 1965), «О декодировании кодов БЧХ», IEEE Transactions по теории информации , 11 (4): 549-557, да : 10,1109 / TIT.1965.1053825
- Koetter, Ralf (2005), коды Рида – Соломона , MIT Lecture Notes 6.451 (видео), заархивировано из оригинала 13 марта 2013 г.
- MacWilliams, FJ; Слоан, штат Нью-Джерси (1977), Теория кодов с исправлением ошибок , Нью-Йорк, Нью-Йорк: издательство North-Holland Publishing Company
- Рид, Ирвинг С .; Чен, Сюэминь (1999), Кодирование с контролем ошибок для сетей передачи данных , Бостон, Массачусетс: Kluwer Academic Publishers
внешние ссылки
Информация и учебные пособия
- Введение в коды Рида – Соломона: принципы, архитектура и реализация (CMU)
- Учебное пособие по кодированию Рида – Соломона для обеспечения отказоустойчивости в RAID-подобных системах
- Алгебраическое мягкое декодирование кодов Рида – Соломона.
- Викиверситет: коды Рида – Соломона для программистов
- Белая книга BBC R&D WHP031
- Гейзель, Уильям А. (август 1990 г.), Учебное пособие по кодированию с исправлением ошибок Рида – Соломона , Технический меморандум, НАСА , TM-102162
- Гао, Шухонг (январь 2002 г.), Новый алгоритм декодирования кодов Рида-Соломона (PDF) , Клемсон
- Составные коды доктора Дэйва Форни (scholarpedia.org).
- Рид, Джефф А. (апрель 1995 г.), CRC и Рид Соломон ECC (PDF)
Реализации
- Кодек Рида – Соломона с открытым исходным кодом Schifra C ++
- Библиотека RSCode Генри Мински, кодировщик / декодер Рида – Соломона
- Библиотека программного декодирования Рида – Соломона с открытым исходным кодом C ++
- Реализация в Matlab ошибок и стираний декодирования Рида – Соломона
- Реализация Octave в коммуникационном пакете
- Реализация кодека Рида – Соломона на чистом Python

Приложение 2. Модифицированная альтернативная кодировка.

Приложение 3: клод элвуд шеннон.
Клод
Элвуд Шеннон (Shannon
(1916 — 2001))
—
выдающийся американский инженер и
математик,
основоположник современных теорий
информации и связи.
Осенним
днем 1989 года корреспондент журнала
“ScientificAmerican”
вошел в старинный
дом с видом на озеро к северу от Бостона.
Но встретивший его хозяин, 73-летний
стройный старик с пышной седой гривой
и озорной улыбкой, совсем не желал
вспоминать
«дела давно минувших дней» и
обсуждать свои научные открытия
30-50-летней давности. Быть может, гость
лучше посмотрит его игрушки? Хозяин
увлек изумленного журналиста
в соседнюю комнату, где с гордостью
десятилетнего мальчишки продемонстрировал
свои сокровища: семь шахматных машин,
цирковой шест с пружиной и бензиновым
двигателем, складной нож с сотней лезвий,
двухместный одноколесный велосипед,
жонглирующий манекен, а также компьютер,
вычисляющий в римской системе счисления.
И не беда, что многие из этих творений
хозяина давно сломаны и порядком
запылены,
— он счастлив.
Кто
этот старик? Неужели это он, будучи еще
молодым инженером фирмы “Bell
Laboratories”
написал в 1948 году Великую хартию
информационной эры — «Математическую
теорию связи»? Его ли труд назвали
«величайшей работой технической
мысли»? Его ли интуицию
первооткрывателя сравнивали с гением
Эйнштейна? Да, это все о нем. И он же в
тех же 40-х годах конструировал летающий
диск на ракетном двигателе и катался,
одновременно
жонглируя, на одноколесном велосипеде
по коридорам “Bell
Laboratories”.
Это Клод Элвуд
Шеннон, отец кибернетики и теории
информации, гордо заявивший: «Я всегда
следовал
своим интересам, не думая ни о том, во
что они мне обойдутся, ни об их ценности
для мира. Я потратил уйму времени на
совершенно бесполезные вещи».
Клод
Шеннон родился в 1916 году и вырос в городе
Гэйлорде штата Мичиган. Еще в детские
годы Клод познакомился, как с детальностью
технических конструкций, так и с общностью
математических принципов. Он постоянно
возился с детекторными приемниками
и радиоконструкторами, которые приносил
ему отец, помощник судьи, и решал
математические задачки и головоломки,
которыми снабжала его старшая сестра
Кэтрин,
ставшая впоследствии профессором
математики. Клод полюбил эти два мира,
столь
несхожие между собой, — технику и
математику.
Будучи
студентом Мичиганского университета,
который он окончил в 1936 году, Клод
специализировался
одновременно и в математике, и в
электротехнике. Эта двусторонность
интересов
и образования определила первый крупный
успех, которого Клод Шеннон достиг
в свои аспирантские годы в Массачусетском
технологическом институте. В своей
диссертации,
защищенной в 1940 году, он доказал, что
работу переключателей и реле в
электрических
схемах можно представить посредством
алгебры, изобретенной в середине XIX
века английским математиком Джорджем
Булем. «Просто случилось так, что
никто другой
не был знаком с этими обеими областями
одновременно!» — так скромно Шеннон
объяснил
причину своего открытия. С тех пор булева
алгебра
является основой схемотехники.
В
1941 году 25-летний Клод Шеннон
поступил на работу в фирму “Bell
Laboratories”.
В годы войны он занимался разработкой
криптографических
систем, и позже это помогло ему открыть
методы
кодирования с коррекцией
ошибок.
В это же время он начал разрабатывать
основы теории
информации.
Цель Шеннона заключалась в улучшении
передачи
информации по телеграфному и телефонному
каналу, находящемуся под воздействием
электрических шумов. Он пришел к выводу,
что решение проблемы
заключается в более эффективной упаковке
информации.
Но
что же такое информация? Чем измерять
ее количество? Шеннону пришлось ответить
на эти вопросы еще до того, как он
приступил к исследованиям пропускной
способности каналов связи. В своих
работах 1948-49 годов он определил количество
информации
через энтропию
— величину, известную в термодинамике
и статистической физике
как мера неупорядоченности системы, а
за единицу информации принял то, что
впоследствии
окрестили битом.
Позже
Шеннон любил рассказывать, что использовать
энтропию ему посоветовал знаменитый
математик Джон фон Нейман, который
мотивировал свой совет тем, что мало
кто
из математиков и инженеров знает об
энтропии, и это обеспечит Шеннону большое
преимущество
в неизбежных спорах.
На
прочном фундаменте своего определения
количества информации Клод Шеннон
доказал
теорему о пропускной способности
зашумленных каналов связи. Во всей
полноте эта теорема была опубликована
в его работах в период 1957-1961 г.г. и теперь
носит его
имя. В чем суть теоремы Шеннона? Всякий
зашумленный канал связи характеризуется
своей предельной скоростью передачи
информации, называемой пределом
Шеннона.
При скоростях
передачи выше этого предела неизбежны
ошибки в передаваемой информации. Зато
снизу к этому пределу можно подойти
сколь угодно близко, обеспечивая
соответствующим
кодированием информации сколь угодно
малую вероятность ошибки при любой
зашумленности канала.
Эти
идеи Шеннона оказались слишком
революционными и не смогли найти себе
применения
в полной мере в годы медленной ламповой
электроники. Но в наше время высокоскоростных
микросхем они работают повсюду, где
хранится, обрабатывается и передается
информация: в
компьютерах, лазерных дисках, линиях
связи.
Кроме
теории информации, Шеннон успешно
работал во многих других областях. Одним
из первых он высказал мысль о том, что
машины могут играть в игры и самообучаться.
В 1950 году он сделал механическую мышку
Тесей, дистанционно управляемую сложной
электронной схемой. Эта мышка училась
находить выход из лабиринта.
В честь его изобретения был учрежден
международный конкурс «Микромышь»,
в котором
до сих пор принимают участие тысячи
студентов технических вузов. В те же
50-е годы
Шеннон создал машину, которая «читала
мысли» при игре в «монетку»:
человек
загадывал «орел» или «решку”, а
машина отгадывала с вероятностью выше
50%, потому что человек никак не может
избежать каких-либо закономерностей,
которые машина может использовать.
В
1956 году Шеннон покинул фирму “Bell
Laboratories”
и со следующего года стал профессором
Массачусетского
технологического института, откуда
ушел на пенсию в 1978 году. В числе его
студентов были многие известные ученые,
работавшие в области искусственного
интеллекта.
Труды
Шеннона, к которым с благоговением
относятся теоретики, столь же интересны
и для специалистов, решающих сугубо
прикладные задачи. Шеннон заложил основы
современного кодирования
с коррекцией ошибок,
без которого не обходится
сейчас ни один дисковод для жестких
дисков и другие электронные устройства,
предназначенные для хранения, передачи
и обработки информации.
В
Массачусетском
технологическом институте
и на пенсии им завладело его давнее
увлечение жонглированием. Шеннон
построил несколько жонглирующих машин
и даже создал общую
теорию жонглирования,
которая, впрочем, не помогла ему побить
личный рекорд — жонглирование
четырьмя мячиками. Еще он испытал свои
силы в поэзии, а также разработал
разнообразные модели игры на бирже
акций и опробовал их (по его словам
успешно). Но
с начала 60-х годов Шеннон не сделал в
теории информации практически больше
ничего.
В
1985 году Клод Шеннон и его жена Бетти
неожиданно посетили Международный
симпозиум по теории информации в
английском городе Брайтоне. Почти целое
поколение Шеннон не появлялся на
конференциях, и поначалу его никто не
узнал. Затем участники симпозиума
начали перешептываться: вон тот скромный
седой джентльмен — это Клод Элвуд
Шеннон, тот самый! На банкете Шеннон
сказал несколько слов, немного жонглировал
тремя (увы, только тремя) мячиками, а
затем подписал сотни автографов
ошеломленным инженерам и ученым,
выстроившимся в длиннейшую очередь.
Стоящие в очереди говорили, что испытывают
такие же чувства, какие испытали бы
физики, явись на их
конференцию сам сэр Исаак Ньютон.
Клод
Шеннон скончался в 2001 году в массачусетском
доме для престарелых от болезни
Альцгеймера на 84 году жизни.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Quantum error correction (QEC) is used in quantum computing to protect quantum information from errors due to decoherence and other quantum noise. Quantum error correction is theorised as essential to achieve fault tolerant quantum computing that can reduce the effects of noise on stored quantum information, faulty quantum gates, faulty quantum preparation, and faulty measurements. This would allow algorithms of greater circuit depth.[1]
Classical error correction employs redundancy. The simplest albeit inefficient approach is the repetition code. The idea is to store the information multiple times, and—if these copies are later found to disagree—take a majority vote; e.g. suppose we copy a bit in the one state three times. Suppose further that a noisy error corrupts the three-bit state so that one of the copied bits is equal to zero but the other two are equal to one. Assuming that noisy errors are independent and occur with some sufficiently low probability p, it is most likely that the error is a single-bit error and the transmitted message is three ones. It is possible that a double-bit error occurs and the transmitted message is equal to three zeros, but this outcome is less likely than the above outcome. In this example, the logical information was a single bit in the one state, the physical information are the three copied bits, and determining what logical state is encoded in the physical state is called decoding. Similar to classical error correction, QEC codes do not always correctly decode logical qubits, but their use reduces the effect of noise.
Copying quantum information is not possible due to the no-cloning theorem. This theorem seems to present an obstacle to formulating a theory of quantum error correction. But it is possible to spread the (logical) information of one qubit onto a highly entangled state of several (physical) qubits. Peter Shor first discovered this method of formulating a quantum error correcting code by storing the information of one qubit onto a highly entangled state of nine qubits.
Classical error correcting codes use a syndrome measurement to diagnose which error corrupts an encoded state. An error can then be reversed by applying a corrective operation based on the syndrome. Quantum error correction also employs syndrome measurements. It performs a multi-qubit measurement that does not disturb the quantum information in the encoded state but retrieves information about the error. Depending on the QEC code used, syndrome measurement can determine the occurrence, location and type of errors. In most QEC codes, the type of error is either a bit flip, or a sign (of the phase) flip, or both (corresponding to the Pauli matrices X, Z, and Y). The measurement of the syndrome has the projective effect of a quantum measurement, so even if the error due to the noise was arbitrary, it can be expressed as a combination of basis operations called the error basis (which is given by the Pauli matrices and the identity). To correct the error, the Pauli operator corresponding to the type of error is used on the corrupted qubit to revert the effect of the error.
The syndrome measurement provides information about the error that has happened, but not about the information that is stored in the logical qubit—as otherwise the measurement would destroy any quantum superposition of this logical qubit with other qubits in the quantum computer, which would prevent it from being used to convey quantum information.
Bit flip code[edit]
The repetition code works in a classical channel, because classical bits are easy to measure and to repeat. This approach does not work for a quantum channel in which, due to the no-cloning theorem, it is not possible to repeat a single qubit three times. To overcome this, a different method has to be used, such as the three-qubit bit flip code first proposed by Asher Peres in 1985.[2] This technique uses entanglement and syndrome measurements and is comparable in performance with the repetition code.

Consider the situation in which we want to transmit the state of a single qubit  through a noisy channel
through a noisy channel  . Let us moreover assume that this channel either flips the state of the qubit, with probability , or leaves it unchanged. The action of on a general input
. Let us moreover assume that this channel either flips the state of the qubit, with probability , or leaves it unchanged. The action of on a general input  can therefore be written as
can therefore be written as  .
.
Let  be the quantum state to be transmitted. With no error correcting protocol in place, the transmitted state will be correctly transmitted with probability
be the quantum state to be transmitted. With no error correcting protocol in place, the transmitted state will be correctly transmitted with probability  . We can however improve on this number by encoding the state into a greater number of qubits, in such a way that errors in the corresponding logical qubits can be detected and corrected. In the case of the simple three-qubit repetition code, the encoding consists in the mappings
. We can however improve on this number by encoding the state into a greater number of qubits, in such a way that errors in the corresponding logical qubits can be detected and corrected. In the case of the simple three-qubit repetition code, the encoding consists in the mappings  and
and  . The input state is encoded into the state
. The input state is encoded into the state  . This mapping can be realized for example using two CNOT gates, entangling the system with two ancillary qubits initialized in the state
. This mapping can be realized for example using two CNOT gates, entangling the system with two ancillary qubits initialized in the state  .[3] The encoded state
.[3] The encoded state  is what is now passed through the noisy channel.
is what is now passed through the noisy channel.
The channel acts on by flipping some subset (possibly empty) of its qubits. No qubit is flipped with probability  , a single qubit is flipped with probability
, a single qubit is flipped with probability  , two qubits are flipped with probability
, two qubits are flipped with probability  , and all three qubits are flipped with probability
, and all three qubits are flipped with probability  . Note that a further assumption about the channel is made here: we assume that acts equally and independently on each of the three qubits in which the state is now encoded. The problem is now how to detect and correct such errors, while not corrupting the transmitted state.
. Note that a further assumption about the channel is made here: we assume that acts equally and independently on each of the three qubits in which the state is now encoded. The problem is now how to detect and correct such errors, while not corrupting the transmitted state.

Comparison of output minimum fidelities, with (red) and without (blue) error correcting via the three qubit bit flip code. Notice how, for  , the error correction scheme improves the fidelity.
, the error correction scheme improves the fidelity.
Let us assume for simplicity that is small enough that the probability of more than a single qubit being flipped is negligible. One can then detect whether a qubit was flipped, without also querying for the values being transmitted, by asking whether one of the qubits differs from the others. This amounts to performing a measurement with four different outcomes, corresponding to the following four projective measurements:

This reveals which qubits are different from the others, without at the same time giving information about the state of the qubits themselves. If the outcome corresponding to  is obtained, no correction is applied, while if the outcome corresponding to
is obtained, no correction is applied, while if the outcome corresponding to  is observed, then the Pauli X gate is applied to the
is observed, then the Pauli X gate is applied to the  -th qubit. Formally, this correcting procedure corresponds to the application of the following map to the output of the channel:
-th qubit. Formally, this correcting procedure corresponds to the application of the following map to the output of the channel:

Note that, while this procedure perfectly corrects the output when zero or one flips are introduced by the channel, if more than one qubit is flipped then the output is not properly corrected. For example, if the first and second qubits are flipped, then the syndrome measurement gives the outcome  , and the third qubit is flipped, instead of the first two. To assess the performance of this error-correcting scheme for a general input we can study the fidelity
, and the third qubit is flipped, instead of the first two. To assess the performance of this error-correcting scheme for a general input we can study the fidelity  between the input and the output
between the input and the output  . Being the output state
. Being the output state  correct when no more than one qubit is flipped, which happens with probability
correct when no more than one qubit is flipped, which happens with probability  , we can write it as
, we can write it as ![{displaystyle [(1-p)^{3}+3p(1-p)^{2}],vert psi 'rangle langle psi 'vert +(...)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/339e43e84be56445c2eb3f56a60d1b32febe38bd) , where the dots denote components of resulting from errors not properly corrected by the protocol. It follows that
, where the dots denote components of resulting from errors not properly corrected by the protocol. It follows that

This fidelity is to be compared with the corresponding fidelity obtained when no error-correcting protocol is used, which was shown before to equal  . A little algebra then shows that the fidelity after error correction is greater than the one without for
. A little algebra then shows that the fidelity after error correction is greater than the one without for  . Note that this is consistent with the working assumption that was made while deriving the protocol (of being small enough).
. Note that this is consistent with the working assumption that was made while deriving the protocol (of being small enough).
Sign flip code[edit]

Flipped bits are the only kind of error in classical computer, but there is another possibility of an error with quantum computers, the sign flip. Through the transmission in a channel the relative sign between  and
and  can become inverted. For instance, a qubit in the state
can become inverted. For instance, a qubit in the state  may have its sign flip to
may have its sign flip to 
The original state of the qubit
will be changed into the state

In the Hadamard basis, bit flips become sign flips and sign flips become bit flips. Let  be a quantum channel that can cause at most one phase flip. Then the bit flip code from above can recover
be a quantum channel that can cause at most one phase flip. Then the bit flip code from above can recover  by transforming into the Hadamard basis before and after transmission through .
by transforming into the Hadamard basis before and after transmission through .
Shor code[edit]
The error channel may induce either a bit flip, a sign flip (i.e., a phase flip), or both. It is possible to correct for both types of errors on any one qubit using a QEC code, which can be done using the Shor code published in 1995.[4][5]: 10 This is equivalent to saying the Shor code corrects arbitrary single-qubit errors.

Quantum circuit to encode a single logical qubit with the Shor code and then perform bit flip error correction on each of the three blocks.
Let be a quantum channel that can arbitrarily corrupt a single qubit. The 1st, 4th and 7th qubits are for the sign flip code, while the three groups of qubits (1,2,3), (4,5,6), and (7,8,9) are designed for the bit flip code. With the Shor code, a qubit state will be transformed into the product of 9 qubits  , where
, where


If a bit flip error happens to a qubit, the syndrome analysis will be performed on each block of qubits (1,2,3), (4,5,6), and (7,8,9) to detect and correct at most one bit flip error in each block.
If the three bit flip group (1,2,3), (4,5,6), and (7,8,9) are considered as three inputs, then the Shor code circuit can be reduced as a sign flip code. This means that the Shor code can also repair a sign flip error for a single qubit.
The Shor code also can correct for any arbitrary errors (both bit flip and sign flip) to a single qubit. If an error is modeled by a unitary transform U, which will act on a qubit , then  can be described in the form
can be described in the form

where  ,
, ,
, , and
, and  are complex constants, I is the identity, and the Pauli matrices are given by
are complex constants, I is the identity, and the Pauli matrices are given by

If U is equal to I, then no error occurs. If  , a bit flip error occurs. If
, a bit flip error occurs. If  , a sign flip error occurs. If
, a sign flip error occurs. If  then both a bit flip error and a sign flip error occur. In other words, the Shor code can correct any combination of bit or phase errors on a single qubit.
then both a bit flip error and a sign flip error occur. In other words, the Shor code can correct any combination of bit or phase errors on a single qubit.
Bosonic codes[edit]
Several proposals have been made for storing error-correctable quantum information in bosonic modes.[clarification needed] Unlike a two-level system, a quantum harmonic oscillator has infinitely many energy levels in a single physical system. Codes for these systems include cat,[6][7][8] Gottesman-Kitaev-Preskill (GKP),[9] and binomial codes.[10][11] One insight offered by these codes is to take advantage of the redundancy within a single system, rather than to duplicate many two-level qubits.
Binomial code[10][edit]
Written in the Fock basis, the simplest binomial encoding is

where the subscript L indicates a «logically encoded» state. Then if the dominant error mechanism of the system is the stochastic application of the bosonic lowering operator  the corresponding error states are
the corresponding error states are  and
and  respectively. Since the codewords involve only even photon number, and the error states involve only odd photon number, errors can be detected by measuring the photon number parity of the system.[10][12] Measuring the odd parity will allow correction by application of an appropriate unitary operation without knowledge of the specific logical state of the qubit. However, the particular binomial code above is not robust to two-photon loss.
respectively. Since the codewords involve only even photon number, and the error states involve only odd photon number, errors can be detected by measuring the photon number parity of the system.[10][12] Measuring the odd parity will allow correction by application of an appropriate unitary operation without knowledge of the specific logical state of the qubit. However, the particular binomial code above is not robust to two-photon loss.
Cat code[6][7][8][edit]
Schrödinger cat states, superpositions of coherent states, can also be used as logical states for error correction codes. Cat code, realized by Ofek et al.[13] in 2016, defined two sets of logical states:  and
and  , where each of the states is a superposition of coherent state as follows
, where each of the states is a superposition of coherent state as follows

Those two sets of states differ from the photon number parity, as states denoted with  only occupy even photon number states and states with
only occupy even photon number states and states with  indicate they have odd parity. Similar to the binomial code, if the dominant error mechanism of the system is the stochastic application of the bosonic lowering operator
indicate they have odd parity. Similar to the binomial code, if the dominant error mechanism of the system is the stochastic application of the bosonic lowering operator  , the error takes the logical states from the even parity subspace to the odd one, and vice versa. Single-photon-loss errors can therefore be detected by measuring the photon number parity operator
, the error takes the logical states from the even parity subspace to the odd one, and vice versa. Single-photon-loss errors can therefore be detected by measuring the photon number parity operator  using a dispersively coupled ancillary qubit.[12]
using a dispersively coupled ancillary qubit.[12]
Still, cat qubits are not protected against two-photon loss  , dephasing noise
, dephasing noise  , photon-gain error
, photon-gain error  , etc.
, etc.
General codes[edit]
In general, a quantum code for a quantum channel is a subspace  , where
, where  is the state Hilbert space, such that there exists another quantum channel
is the state Hilbert space, such that there exists another quantum channel  with
with

where  is the orthogonal projection onto
is the orthogonal projection onto  . Here is known as the correction operation.
. Here is known as the correction operation.
A non-degenerate code is one for which different elements of the set of correctable errors produce linearly independent results when applied to elements of the code. If distinct of the set of correctable errors produce orthogonal results, the code is considered pure.[14]
Models[edit]
Over time, researchers have come up with several codes:
- Peter Shor’s 9-qubit-code, a.k.a. the Shor code, encodes 1 logical qubit in 9 physical qubits and can correct for arbitrary errors in a single qubit.
- Andrew Steane found a code that does the same with 7 instead of 9 qubits, see Steane code.
- Raymond Laflamme and collaborators found a class of 5-qubit codes that do the same, which also have the property of being fault-tolerant. A 5-qubit code is the smallest possible code that protects a single logical qubit against single-qubit errors.
- A generalisation of the technique used by Steane, to develop the 7-qubit code from the classical [7, 4] Hamming code, led to the construction of an important class of codes called the CSS codes, named for their inventors: Robert Calderbank, Peter Shor and Andrew Steane. According to the quantum Hamming bound, encoding a single logical qubit and providing for arbitrary error correction in a single qubit requires a minimum of 5 physical qubits.
- A more general class of codes (encompassing the former) are the stabilizer codes discovered by Daniel Gottesman, and by Robert Calderbank, Eric Rains, Peter Shor, and N. J. A. Sloane; these are also called additive codes.
- Two dimensional Bacon–Shor codes are a family of codes parameterized by integers m and n. There are nm qubits arranged in a square lattice.[15]
- A newer idea is Alexei Kitaev’s topological quantum codes and the more general idea of a topological quantum computer.
- Todd Brun, Igor Devetak, and Min-Hsiu Hsieh also constructed the entanglement-assisted stabilizer formalism as an extension of the standard stabilizer formalism that incorporates quantum entanglement shared between a sender and a receiver.
That these codes allow indeed for quantum computations of arbitrary length is the content of the quantum threshold theorem, found by Michael Ben-Or and Dorit Aharonov, which asserts that you can correct for all errors if you concatenate quantum codes such as the CSS codes—i.e. re-encode each logical qubit by the same code again, and so on, on logarithmically many levels—provided that the error rate of individual quantum gates is below a certain threshold; as otherwise, the attempts to measure the syndrome and correct the errors would introduce more new errors than they correct for.
As of late 2004, estimates for this threshold indicate that it could be as high as 1–3%,[16] provided that there are sufficiently many qubits available.
Experimental realization[edit]
There have been several experimental realizations of CSS-based codes. The first demonstration was with nuclear magnetic resonance qubits.[17] Subsequently, demonstrations have been made with linear optics,[18] trapped ions,[19][20] and superconducting (transmon) qubits.[21]
In 2016 for the first time the lifetime of a quantum bit was prolonged by employing a QEC code.[13] The error-correction demonstration was performed on Schrodinger-cat states encoded in a superconducting resonator, and employed a quantum controller capable of performing real-time feedback operations including read-out of the quantum information, its analysis, and the correction of its detected errors. The work demonstrated how the quantum-error-corrected system reaches the break-even point at which the lifetime of a logical qubit exceeds the lifetime of the underlying constituents of the system (the physical qubits).
Other error correcting codes have also been implemented, such as one aimed at correcting for photon loss, the dominant error source in photonic qubit schemes.[22][23]
In 2021, an entangling gate between two logical qubits encoded in topological quantum error-correction codes has first been realized using 10 ions in a trapped-ion quantum computer.[24][25] 2021 also saw the first experimental demonstration of fault-tolerant Bacon-Shor code in a single logical qubit of a trapped-ion system, i.e. a demonstration for which the addition of error correction is able to suppress more errors than is introduced by the overhead required to implement the error correction as well as fault tolerant Steane code.[26][27][28]
In 2022, researchers at the University of Innsbruck have demonstrated a fault-tolerant universal set of gates on two logical qubits in a trapped-ion quantum computer. They have performed a logical two-qubit controlled-NOT gate between two instances of the seven-qubit colour code, and fault-tolerantly prepared a logical magic state.[29]
In February 2023 researchers at Google claimed to have decreased quantum errors by increasing the qubit number in experiments, they used a fault tolerant surface code measuring an error rate of 3.028% and 2.914% for a distance-3 qubit array and a distance-5 qubit array respectively.[30][31][32]
Quantum error-correction without encoding and parity-checks[edit]
Also in 2022, research at University of Engineering and Technology Lahore demonstrated error-cancellation by inserting single-qubit Z-axis rotation gates into strategically chosen locations of the superconductor quantum circuits.[33] The scheme has been shown to effectively correct errors that would otherwise rapidly add up under constructive interference of coherent noise. This is a circuit-level calibration scheme that traces deviations (e.g. sharp dips or notches) in the decoherence curve to detect and localize the coherent error, but does not require encoding or parity measurements.[34] However, further investigation is needed to establish the effectiveness of this method for the incoherent noise.[33]
See also[edit]
- Error detection and correction
- Soft error
References[edit]
- ^ Cai, Weizhou; Ma, Yuwei (2021). «Bosonic quantum error correction codes in superconducting quantum circuits». Fundamental Research. 1 (1): 50–67. doi:10.1016/j.fmre.2020.12.006.
A practical quantum computer that is capable of large circuit depth, therefore, ultimately calls for operations on logical qubits protected by quantum error correction
- ^ Peres, Asher (1985). «Reversible Logic and Quantum Computers». Physical Review A. 32 (6): 3266–3276. Bibcode:1985PhRvA..32.3266P. doi:10.1103/PhysRevA.32.3266. PMID 9896493.
- ^ Nielsen, Michael A.; Chuang, Isaac L. (2000). Quantum Computation and Quantum Information. Cambridge University Press.
- ^ Shor, Peter W. (1995). «Scheme for reducing decoherence in quantum computer memory». Physical Review A. 52 (4): R2493–R2496. Bibcode:1995PhRvA..52.2493S. doi:10.1103/PhysRevA.52.R2493. PMID 9912632.
- ^ Devitt, Simon J; Munro, William J; Nemoto, Kae (2013-06-20). «Quantum error correction for beginners». Reports on Progress in Physics. 76 (7): 076001. arXiv:0905.2794. Bibcode:2013RPPh…76g6001D. doi:10.1088/0034-4885/76/7/076001. ISSN 0034-4885. PMID 23787909. S2CID 206021660.
- ^ a b Cochrane, P. T.; Milburn, G. J.; Munro, W. J. (1999-04-01). «Macroscopically distinct quantum-superposition states as a bosonic code for amplitude damping». Physical Review A. 59 (4): 2631–2634. arXiv:quant-ph/9809037. Bibcode:1999PhRvA..59.2631C. doi:10.1103/PhysRevA.59.2631. S2CID 119532538.
- ^ a b Leghtas, Zaki; Kirchmair, Gerhard; Vlastakis, Brian; Schoelkopf, Robert J.; Devoret, Michel H.; Mirrahimi, Mazyar (2013-09-20). «Hardware-Efficient Autonomous Quantum Memory Protection». Physical Review Letters. 111 (12): 120501. arXiv:1207.0679. Bibcode:2013PhRvL.111l0501L. doi:10.1103/physrevlett.111.120501. ISSN 0031-9007. PMID 24093235. S2CID 19929020.
- ^ a b Mirrahimi, Mazyar; Leghtas, Zaki; Albert, Victor V; Touzard, Steven; Schoelkopf, Robert J; Jiang, Liang; Devoret, Michel H (2014-04-22). «Dynamically protected cat-qubits: a new paradigm for universal quantum computation». New Journal of Physics. 16 (4): 045014. arXiv:1312.2017. Bibcode:2014NJPh…16d5014M. doi:10.1088/1367-2630/16/4/045014. ISSN 1367-2630. S2CID 7179816.
- ^ Daniel Gottesman; Alexei Kitaev; John Preskill (2001). «Encoding a qubit in an oscillator». Physical Review A. 64 (1): 012310. arXiv:quant-ph/0008040. Bibcode:2001PhRvA..64a2310G. doi:10.1103/PhysRevA.64.012310. S2CID 18995200.
- ^ a b c Michael, Marios H.; Silveri, Matti; Brierley, R. T.; Albert, Victor V.; Salmilehto, Juha; Jiang, Liang; Girvin, S. M. (2016-07-14). «New Class of Quantum Error-Correcting Codes for a Bosonic Mode». Physical Review X. 6 (3): 031006. arXiv:1602.00008. Bibcode:2016PhRvX…6c1006M. doi:10.1103/PhysRevX.6.031006. S2CID 29518512.
- ^ Albert, Victor V.; Noh, Kyungjoo; Duivenvoorden, Kasper; Young, Dylan J.; Brierley, R. T.; Reinhold, Philip; Vuillot, Christophe; Li, Linshu; Shen, Chao; Girvin, S. M.; Terhal, Barbara M.; Jiang, Liang (2018). «Performance and structure of single-mode bosonic codes». Physical Review A. 97 (3): 032346. arXiv:1708.05010. Bibcode:2018PhRvA..97c2346A. doi:10.1103/PhysRevA.97.032346. S2CID 51691343.
- ^ a b Sun, L.; Petrenko, A.; Leghtas, Z.; Vlastakis, B.; Kirchmair, G.; Sliwa, K. M.; Narla, A.; Hatridge, M.; Shankar, S.; Blumoff, J.; Frunzio, L.; Mirrahimi, M.; Devoret, M. H.; Schoelkopf, R. J. (July 2014). «Tracking photon jumps with repeated quantum non-demolition parity measurements». Nature. 511 (7510): 444–448. arXiv:1311.2534. Bibcode:2014Natur.511..444S. doi:10.1038/nature13436. ISSN 1476-4687. PMID 25043007. S2CID 987945.
- ^ a b Ofek, Nissim; Petrenko, Andrei; Heeres, Reinier; Reinhold, Philip; Leghtas, Zaki; Vlastakis, Brian; Liu, Yehan; Frunzio, Luigi; Girvin, S. M.; Jiang, L.; Mirrahimi, Mazyar (August 2016). «Extending the lifetime of a quantum bit with error correction in superconducting circuits». Nature. 536 (7617): 441–445. Bibcode:2016Natur.536..441O. doi:10.1038/nature18949. ISSN 0028-0836. PMID 27437573. S2CID 594116.
- ^ Calderbank, A. R.; Rains, E. M.; Shor, P. W.; Sloane, N. J. A. (1998). «Quantum Error Correction via Codes over GF(4)». IEEE Transactions on Information Theory. 44 (4): 1369–1387. arXiv:quant-ph/9608006. doi:10.1109/18.681315. S2CID 1215697.
- ^ Bacon, Dave (2006-01-30). «Operator quantum error-correcting subsystems for self-correcting quantum memories». Physical Review A. 73 (1): 012340. arXiv:quant-ph/0506023. Bibcode:2006PhRvA..73a2340B. doi:10.1103/PhysRevA.73.012340. S2CID 118968017.
- ^ Knill, Emanuel (2004-11-02). «Quantum Computing with Very Noisy Devices». Nature. 434 (7029): 39–44. arXiv:quant-ph/0410199. Bibcode:2005Natur.434…39K. doi:10.1038/nature03350. PMID 15744292. S2CID 4420858.
- ^ Cory, D. G.; Price, M. D.; Maas, W.; Knill, E.; Laflamme, R.; Zurek, W. H.; Havel, T. F.; Somaroo, S. S. (1998). «Experimental Quantum Error Correction». Phys. Rev. Lett. 81 (10): 2152–2155. arXiv:quant-ph/9802018. Bibcode:1998PhRvL..81.2152C. doi:10.1103/PhysRevLett.81.2152. S2CID 11662810.
- ^ Pittman, T. B.; Jacobs, B. C.; Franson, J. D. (2005). «Demonstration of quantum error correction using linear optics». Phys. Rev. A. 71 (5): 052332. arXiv:quant-ph/0502042. Bibcode:2005PhRvA..71e2332P. doi:10.1103/PhysRevA.71.052332. S2CID 11679660.
- ^ Chiaverini, J.; Leibfried, D.; Schaetz, T.; Barrett, M. D.; Blakestad, R. B.; Britton, J.; Itano, W. M.; Jost, J. D.; Knill, E.; Langer, C.; Ozeri, R.; Wineland, D. J. (2004). «Realization of quantum error correction». Nature. 432 (7017): 602–605. Bibcode:2004Natur.432..602C. doi:10.1038/nature03074. PMID 15577904. S2CID 167898.
- ^ Schindler, P.; Barreiro, J. T.; Monz, T.; Nebendahl, V.; Nigg, D.; Chwalla, M.; Hennrich, M.; Blatt, R. (2011). «Experimental Repetitive Quantum Error Correction». Science. 332 (6033): 1059–1061. Bibcode:2011Sci…332.1059S. doi:10.1126/science.1203329. PMID 21617070. S2CID 32268350.
- ^ Reed, M. D.; DiCarlo, L.; Nigg, S. E.; Sun, L.; Frunzio, L.; Girvin, S. M.; Schoelkopf, R. J. (2012). «Realization of Three-Qubit Quantum Error Correction with Superconducting Circuits». Nature. 482 (7385): 382–385. arXiv:1109.4948. Bibcode:2012Natur.482..382R. doi:10.1038/nature10786. PMID 22297844. S2CID 2610639.
- ^ Lassen, M.; Sabuncu, M.; Huck, A.; Niset, J.; Leuchs, G.; Cerf, N. J.; Andersen, U. L. (2010). «Quantum optical coherence can survive photon losses using a continuous-variable quantum erasure-correcting code». Nature Photonics. 4 (10): 700. arXiv:1006.3941. Bibcode:2010NaPho…4..700L. doi:10.1038/nphoton.2010.168. S2CID 55090423.
- ^ Guo, Qihao; Zhao, Yuan-Yuan; Grassl, Markus; Nie, Xinfang; Xiang, Guo-Yong; Xin, Tao; Yin, Zhang-Qi; Zeng, Bei (2021). «Testing a quantum error-correcting code on various platforms». Science Bulletin. 66 (1): 29–35. arXiv:2001.07998. Bibcode:2021SciBu..66…29G. doi:10.1016/j.scib.2020.07.033. PMID 36654309. S2CID 210861230.
- ^ «Error-protected quantum bits entangled for the first time». phys.org. 2021-01-13. Retrieved 2021-08-30.
- ^ Erhard, Alexander; Poulsen Nautrup, Hendrik; Meth, Michael; Postler, Lukas; Stricker, Roman; Stadler, Martin; Negnevitsky, Vlad; Ringbauer, Martin; Schindler, Philipp; Briegel, Hans J.; Blatt, Rainer; Friis, Nicolai; Monz, Thomas (2021-01-13). «Entangling logical qubits with lattice surgery». Nature. 589 (7841): 220–224. arXiv:2006.03071. Bibcode:2021Natur.589..220E. doi:10.1038/s41586-020-03079-6. ISSN 1476-4687. PMID 33442044. S2CID 219401398.
- ^ Bedford, Bailey (2021-10-04). «Foundational step shows quantum computers can be better than the sum of their parts». phys.org. Retrieved 2021-10-05.
- ^ Egan, Laird; Debroy, Dripto M.; Noel, Crystal; Risinger, Andrew; Zhu, Daiwei; Biswas, Debopriyo; Newman, Michael; Li, Muyuan; Brown, Kenneth R.; Cetina, Marko; Monroe, Christopher (2021-10-04). «Fault-tolerant control of an error-corrected qubit». Nature. 598 (7880): 281–286. Bibcode:2021Natur.598..281E. doi:10.1038/s41586-021-03928-y. ISSN 0028-0836. PMID 34608286. S2CID 238357892.
- ^ Ball, Philip (2021-12-23). «Real-Time Error Correction for Quantum Computing». Physics. 14. 184. Bibcode:2021PhyOJ..14..184B. doi:10.1103/Physics.14.184. S2CID 245442996.
- ^ Postler, Lukas; Heuβen, Sascha; Pogorelov, Ivan; Rispler, Manuel; Feldker, Thomas; Meth, Michael; Marciniak, Christian D.; Stricker, Roman; Ringbauer, Martin; Blatt, Rainer; Schindler, Philipp; Müller, Markus; Monz, Thomas (2022-05-25). «Demonstration of fault-tolerant universal quantum gate operations». Nature. 605 (7911): 675–680. arXiv:2111.12654. Bibcode:2022Natur.605..675P. doi:10.1038/s41586-022-04721-1. PMID 35614250. S2CID 244527180.
- ^ Google Quantum AI (2023-02-22). «Suppressing quantum errors by scaling a surface code logical qubit». Nature. 614 (7949): 676–681. doi:10.1038/s41586-022-05434-1. ISSN 1476-4687. PMC 9946823. PMID 36813892.
- ^ Boerkamp, Martijn (2023-03-20). «Breakthrough in quantum error correction could lead to large-scale quantum computers». Physics World. Retrieved 2023-04-01.
- ^ Conover, Emily (2023-02-22). «Google’s quantum computer reached an error-correcting milestone». ScienceNews. Retrieved 2023-04-01.
- ^ a b Ahsan, Muhammad; Naqvi, Syed Abbas Zilqurnain; Anwer, Haider (2022-02-18). «Quantum circuit engineering for correcting coherent noise». Physical Review A. 105 (2). arXiv:2109.03533. doi:10.1103/physreva.105.022428. ISSN 2469-9926. S2CID 237442177.
- ^ Steffen, Matthias (2022-10-20). «What’s the difference between error suppression, error mitigation, and error correction?». IBM Research Blog. Retrieved 2022-11-26.
Further reading[edit]
- Daniel Lidar and Todd Brun, ed. (2013). Quantum Error Correction. Cambridge University Press.
- La Guardia, Giuliano Gadioli, ed. (2020). Quantum Error Correction: Symmetric, Asymmetric, Synchronizable, and Convolutional Codes. Springer Nature.
- Frank Gaitan (2008). Quantum Error Correction and Fault Tolerant Quantum Computing. Taylor & Francis.
- Freedman, Michael H.; Meyer, David A.; Luo, Feng (2002). «Z2-Systolic freedom and quantum codes». Mathematics of quantum computation. Comput. Math. Ser. Boca Raton, FL: Chapman & Hall/CRC. pp. 287–320.
- Freedman, Michael H.; Meyer, David A. (1998). «Projective plane and planar quantum codes». Found. Comput. Math. 2001 (3): 325–332. arXiv:quant-ph/9810055. Bibcode:1998quant.ph.10055F.
External links[edit]
- Error-check breakthrough in quantum computing[permanent dead link]
- «Topological Quantum Error Correction». Quantum Light. University of Sheffield. 2018-09-28. Archived from the original on 2021-12-22 – via YouTube.