
Обнаружение и коррекция ошибок
Канальный
уровень должен обнаруживать ошибки
передачи данных, связанные с искажением
бит в принятом кадре данных или с потерей
кадра, и по возможности их корректировать.
Большая
часть протоколов канального уровня
выполняет только первую задачу —
обнаружение ошибок, считая, что
корректировать ошибки, то есть повторно
передавать данные, содержавшие искаженную
информацию, должны протоколы верхних
уровней. Так работают такие популярные
протоколы локальных сетей, как Ethernet,
Token Ring, FDDI и другие. Однако существуют
протоколы канального уровня, например
LLC2 или LAP-B, которые самостоятельно решают
задачу восстановления искаженных или
потерянных кадров.
Очевидно,
что протоколы должны работать наиболее
эффективно в типичных условиях работы
сети. Поэтому для сетей, в которых
искажения и потери кадров являются
очень редкими событиями, разрабатываются
протоколы типа Ethernet, в которых не
предусматриваются процедуры устранения
ошибок. Действительно, наличие процедур
восстановления данных потребовало бы
от конечных узлов дополнительных
вычислительных затрат, которые в условиях
надежной работы сети являлись бы
избыточными.
Напротив,
если в сети искажения и потери случаются
часто, то желательно уже на канальном
уровне использовать протокол с коррекцией
ошибок, а не оставлять эту работу
протоколам верхних уровней. Протоколы
верхних уровней, например транспортного
или прикладного, работая с большими
тайм-аутами, восстановят потерянные
данные с большой задержкой. В глобальных
сетях первых поколений, например сетях
Х.25, которые работали через ненадежные
каналы связи, протоколы канального
уровня всегда выполняли процедуры
восстановления потерянных и искаженных
кадров.
Поэтому
нельзя считать, что один протокол лучше
другого потому, что он восстанавливает
ошибочные кадры, а другой протокол —
нет. Каждый протокол должен работать в
тех условиях, для которых он разработан.
Методы обнаружения ошибок
Все
методы обнаружения ошибок основаны на
передаче в составе кадра данных служебной
избыточной информации, по которой можно
судить с некоторой степенью вероятности
о достоверности принятых данных. Эту
служебную информацию принято называть
контрольной
суммой
(или последовательностью
контроля кадра — Frame Check Sequence, FCS).
Контрольная сумма вычисляется как
функция от основной информации, причем
необязательно только путем суммирования.
Принимающая сторона повторно вычисляет
контрольную сумму кадра по известному
алгоритму и в случае ее совпадения с
контрольной суммой, вычисленной
передающей стороной, делает вывод о
том, что данные были переданы через сеть
корректно. Существует несколько
распространенных алгоритмов вычисления
контрольной суммы, отличающихся
вычислительной сложностью и способностью
обнаруживать ошибки в данных.
Контроль
по паритету
представляет собой наиболее простой
метод контроля данных. В то же время это
наименее мощный алгоритм контроля, так
как с его помощью можно обнаружить
только одиночные ошибки в проверяемых
данных. Метод заключается в суммировании
по модулю 2 всех бит контролируемой
информации. Например, для данных 100101011
результатом контрольного суммирования
будет значение 1. Результат суммирования
также представляет собой один бит
данных, который пересылается вместе с
контролируемой информацией. При искажении
при пересылке любого одного бита исходных
данных (или контрольного разряда)
результат суммирования будет отличаться
от принятого контрольного разряда, что
говорит об ошибке. Однако двойная ошибка,
например 110101010, будет неверно принята
за корректные данные. Поэтому контроль
по паритету применяется к небольшим
порциям данных, как правило, к каждому
байту, что дает коэффициент избыточности
для этого метода 1/8. Метод редко применяется
в вычислительных сетях из-за его большой
избыточности и невысоких диагностических
способностей.
Вертикальный
и горизонтальный контроль по паритету
представляет собой модификацию описанного
выше метода. Его отличие состоит в том,
что исходные данные рассматриваются в
виде матрицы, строки которой составляют
байты данных. Контрольный разряд
подсчитывается отдельно для каждой
строки и для каждого столбца матрицы.
Этот метод обнаруживает большую часть
двойных ошибок, однако обладает еще
большей избыточностью. На практике
сейчас также почти не применяется.
Циклический
избыточный контроль (Cyclic Redundancy Check, CRC)
является в настоящее время наиболее
популярным методом контроля в
вычислительных сетях (и не только в
сетях, например, этот метод широко
применяется при записи данных на диски
и дискеты). Метод основан на рассмотрении
исходных данных в виде одного
многоразрядного двоичного числа.
Например, кадр стандарта Ethernet, состоящий
из 1024 байт, будет рассматриваться как
одно число, состоящее из 8192 бит. В качестве
контрольной информации рассматривается
остаток от деления этого числа на
известный делитель R. Обычно в качестве
делителя выбирается семнадцати- или
тридцати трехразрядное число, чтобы
остаток от деления имел длину 16 разрядов
(2 байт) или 32 разряда (4 байт). При получении
кадра данных снова вычисляется остаток
от деления на тот же делитель R, но при
этом к данным кадра добавляется и
содержащаяся в нем контрольная сумма.
Если остаток от деления на R равен нулю,
то делается вывод об отсутствии ошибок
в полученном кадре, в противном случае
кадр считается искаженным.
Этот
метод обладает более высокой вычислительной
сложностью, но его диагностические
возможности гораздо выше, чем у методов
контроля по паритету. Метод CRC обнаруживает
все одиночные ошибки, двойные ошибки и
ошибки в нечетном числе бит. Метод
обладает также невысокой степенью
избыточности. Например, для кадра
Ethernet размером в 1024 байт контрольная
информация длиной в 4 байт составляет
только 0,4 %.
(Существует
несколько модифицированная процедура
вычисления остатка, приводящая к
получению в случае отсутствия ошибок
известного ненулевого остатка, что
является более надежным показателем
корректности.)
Соседние файлы в папке РИС гр.446зс 2015
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Data-link layer uses error control techniques to ensure that frames, i.e. bit streams of data, are transmitted from the source to the destination with a certain extent of accuracy.
Errors
When bits are transmitted over the computer network, they are subject to get corrupted due to interference and network problems. The corrupted bits leads to spurious data being received by the destination and are called errors.
Types of Errors
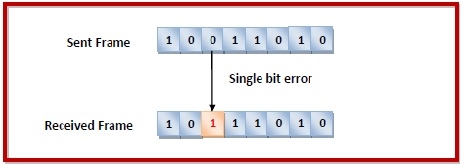
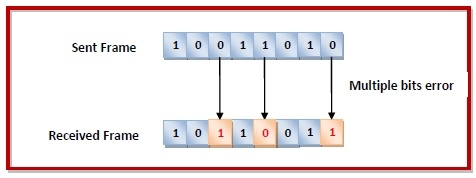
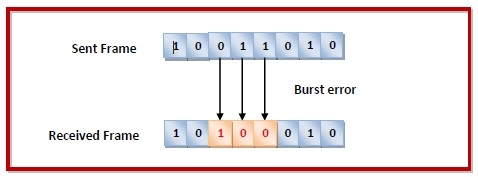
Errors can be of three types, namely single bit errors, multiple bit errors, and burst errors.
-
Single bit error − In the received frame, only one bit has been corrupted, i.e. either changed from 0 to 1 or from 1 to 0.

-
Multiple bits error − In the received frame, more than one bits are corrupted.

-
Burst error − In the received frame, more than one consecutive bits are corrupted.

Error Control
Error control can be done in two ways
-
Error detection − Error detection involves checking whether any error has occurred or not. The number of error bits and the type of error does not matter.
-
Error correction − Error correction involves ascertaining the exact number of bits that has been corrupted and the location of the corrupted bits.
For both error detection and error correction, the sender needs to send some additional bits along with the data bits. The receiver performs necessary checks based upon the additional redundant bits. If it finds that the data is free from errors, it removes the redundant bits before passing the message to the upper layers.
Error Detection Techniques
There are three main techniques for detecting errors in frames: Parity Check, Checksum and Cyclic Redundancy Check (CRC).
Parity Check
The parity check is done by adding an extra bit, called parity bit to the data to make a number of 1s either even in case of even parity or odd in case of odd parity.
While creating a frame, the sender counts the number of 1s in it and adds the parity bit in the following way
-
In case of even parity: If a number of 1s is even then parity bit value is 0. If the number of 1s is odd then parity bit value is 1.
-
In case of odd parity: If a number of 1s is odd then parity bit value is 0. If a number of 1s is even then parity bit value is 1.
On receiving a frame, the receiver counts the number of 1s in it. In case of even parity check, if the count of 1s is even, the frame is accepted, otherwise, it is rejected. A similar rule is adopted for odd parity check.
The parity check is suitable for single bit error detection only.
Checksum
In this error detection scheme, the following procedure is applied
-
Data is divided into fixed sized frames or segments.
-
The sender adds the segments using 1’s complement arithmetic to get the sum. It then complements the sum to get the checksum and sends it along with the data frames.
-
The receiver adds the incoming segments along with the checksum using 1’s complement arithmetic to get the sum and then complements it.
-
If the result is zero, the received frames are accepted; otherwise, they are discarded.
Cyclic Redundancy Check (CRC)
Cyclic Redundancy Check (CRC) involves binary division of the data bits being sent by a predetermined divisor agreed upon by the communicating system. The divisor is generated using polynomials.
-
Here, the sender performs binary division of the data segment by the divisor. It then appends the remainder called CRC bits to the end of the data segment. This makes the resulting data unit exactly divisible by the divisor.
-
The receiver divides the incoming data unit by the divisor. If there is no remainder, the data unit is assumed to be correct and is accepted. Otherwise, it is understood that the data is corrupted and is therefore rejected.
Error Correction Techniques
Error correction techniques find out the exact number of bits that have been corrupted and as well as their locations. There are two principle ways
-
Backward Error Correction (Retransmission) − If the receiver detects an error in the incoming frame, it requests the sender to retransmit the frame. It is a relatively simple technique. But it can be efficiently used only where retransmitting is not expensive as in fiber optics and the time for retransmission is low relative to the requirements of the application.
-
Forward Error Correction − If the receiver detects some error in the incoming frame, it executes error-correcting code that generates the actual frame. This saves bandwidth required for retransmission. It is inevitable in real-time systems. However, if there are too many errors, the frames need to be retransmitted.
The four main error correction codes are
- Hamming Codes
- Binary Convolution Code
- Reed – Solomon Code
- Low-Density Parity-Check Code
Основная задача канального уровня — передача кадров (frame) по каналам связи. На этом уровне и определяется, где в потоке бит начало сообщения, где конец.

На канальном уровне проводится нахождение и корректировка ошибок для некоторых каналов с множественным доступом, где одну и ту же среду передачи данных используют несколько устройств.
Дополнительные задачи канального уровня:
- Адресация — если в канале связи (КС) есть несколько устройств, необходимо определить, к какому именно устройству адресовано передаваемое сообщение;
- Согласованный доступ к каналу. Если все гаджеты одновременно начнут передавать информацию, то данные в КС искажаются и не смогут быть приняты.
Работа с кадрами
Физический уровень предназначен для передачи потока бит по КС. А на канальном уровне необходимо передавать не отдельные биты, а целые сообщения. Задача №1 для канального уровня, выделить сообщения из потока бит, которые приходят по среде передачи данных.

Формирование кадра
Например, есть два ноутбука Хост 1 и Хост 2. И на картинке ниже есть три уровня, сетевой, канальный и физический.

Канальный уровень получает информацию от сетевого и добавляет к нему заголовок и концевик. И именно это сообщение, выделенное красным, заголовок канального уровня, пакет с сетевого уровня и концевик канального уровня и является фреймом. Такое сообщение отправляется через физический уровень по среде передачи данных и поступает на канальный уровень принимающего уровня.
Принимающее устройство читает заголовок и концевик, извлекает пакет сетевого уровня и передает вышестоящему сетевому уровню для последующей обработки.
Методы выделения кадров
Чтобы определить, где в потоке бит начинаются и заканчиваются отдельные frame, были придуманы следующие методы:
- Указание количества байт;
- Вставка байтов (byte stuffing) и битов (bit stuffing);
- Средства физического уровня.
Указатель количества байт
Наипростейший способ определить, где начинается и заканчивается кадр — добавлять длину этого кадра в начало кадра. Например, на картинке ниже показано 3 кадра выделенных разным цветом. В начале каждого кадра указано количество байт. Синим цветом — 6, желтым — 8, зеленым — 4.

Этот метод прост в реализации, но есть недостаток, искажение данных при передаче по сети. Например, при передаче первого кадра появилось искажение и вместо длины кадра шесть байт, получатель получил семь байт.

Получатель посчитает, что семь это длина кадра. Далее идет длина следующего кадра. Здесь она два байта, затем длина следующего кадра семь. Если у нас произошла хоть одна ошибка, то будет нарушена последовательность чтений. Следовательно такой метод на практике не годится к применению.
Вставка byte и bit
Чтобы определить начало и конец кадра, в начале и конце каждого кадра используют специальные последовательности байт или бит. Вставка байтов применялась в протоколах BSC компании IBM, в котором отправлялись обычные текстовые символы.
Перед передачей каждого фрейма добавлялись байты DLE STX (start of text), а после окончания передачи фрейма DLE ETX (end of text). Проблема может возникнуть в том, что в данных тоже может встретиться точно такая же последовательность.
Чтобы отличать последовательность, которая встречается в данных от управляющих символов используются Escape последовательности. В протоколе BSC это тоже последовательность символов DLE (data link escape). Если какая-то последовательность управляющих символов встречается в данных перед ними добавляются escape последовательности DLE, чтобы протокол понимал, что в реальности это данные, а не управляющие символы.
Вставка битов применяется в более современных протоколах, таких как HDLC и PPP. Здесь перед началом и концом каждого кадра добавляется последовательность бит состоящая из 01111110. Может возникнуть проблема, если в данных встречаются подряд идущие 6 или более единиц. Чтобы решить эту задачу в данные, после каждых пяти последовательно идущих 1 добавляется 0. Затем, как получатель прочитал 5 последовательно идущих 1 и встретил 0, то он, этот 0 игнорирует.
Средства физического уровня
Другой вид определения начала и конца кадра, это использование средств физического уровня и он применяется в технологии Ethernet. В первом варианте технологии ethernet использовалась преамбула — это последовательность данных, которая передается перед началом каждого кадра. Она состоит из 8 байт. Первые семь байт состоят из чередующихся 0 и 1: 10101010. Последний байт содержит чередующиеся 0 и 1, кроме двух последних бит в котором две единицы. И именно такая последовательность говорит, что начинается новый кадр.
В более старых версиях используется избыточное кодирование, позволяющее определить ошибки, но при этом не все символы являются значащими. В технологии Fast Ethernet применили эту особенность кода и используют символы, которые не применяются для представления данных в качестве сигналов о начале и конце кадра.
Перед отправкой каждого кадра передаются символы J (11000) и K (10001), а после окончания отправки кадра передается символ T (01101).
Обнаружение и исправление ошибок
Самый простой способ это обнаружить ошибку. Например, с помощью контрольной суммы или какого-либо другого алгоритма. Если у нас технология канального уровня использует обнаружение технических ошибок, то кадр в котором произошла ошибка, просто отбрасывается. Попыток восстановить данные не производится.
Более сложный механизм — это исправление ошибок. Чтобы иметь возможность исправить ошибку, нужно добавить к данным дополнительную информацию, с помощью которой мы сможем обнаружить ошибки и восстановить правильные данные. Для этого используются специальные коды исправляющие ошибки.
Другой вариант исправление ошибок при передаче данных — это повторная отправка тех кадров в которых произошла ошибка. Он используется совместно с обнаружением ошибок, когда отправитель передает данные получателю, получатель обнаруживает ошибку в данных, но вместо того чтобы исправить ошибку в передаваемых данных, отправитель передает эти данные еще раз.
Давайте рассмотрим, как реализуется повторная отправка сообщений. Предположим, что у нас есть отправитель и получатель и отправитель передал получателю некоторое сообщение. Получатель получил это сообщение проверил его на корректность убедился, что данные переданы правильно и после этого передает отправителю подтверждение о получении. Отправитель передает следующее сообщение предположим, что здесь произошла ошибка, получатель эту ошибку обнаружил или сообщение вообще не дошло до получателя, поэтому получатель не может передать подтверждение о получении этого сообщения.

Отправитель, после того как, отправил сообщение запустил таймер ожидания подтверждения. По истечению времени ожидания подтверждение не пришло, отправитель понял, что при передаче сообщения произошла проблема и нужно повторно передать то же самое сообщение.

В этот раз сообщение успешно дошло до получателя и он снова передает подтверждение. После этого отправитель может передавать следующий кадр.

Есть два варианта метода повторной отправки сообщения. Схему которую мы рассмотрели называется с остановкой и ожиданием. Отправитель передает фрейм и останавливается ожидая подтверждение. Следующий кадр передается только после того, как пришло подтверждение о получении предыдущего сообщения. Такой метод используются в технологии канального уровня Wi-Fi.
Другой вариант метода повторной отправки это скользящее окно. В этом случае отправитель передает ни одно сообщение, а сразу несколько сообщений и количество сообщений, которые можно передать не дожидаясь подтверждения называется размером окна. Здесь получатель передает подтверждение не для каждого отдельного сообщения, а для последнего полученного сообщения. Такой метод лучше работает на высокоскоростных каналах связи. Сейчас нет технологии канального уровня, которая использует этот метод, но он используется на транспортном уровне в протоколе TCP.
У нас есть несколько вариантов, что можно делать с ошибками. Можно их обнаруживать, исправлять с помощью кодов исправления ошибок, либо с помощью повторной доставки сообщений. Также мы можем исправлять и обнаруживать ошибки на канальном уровне, либо на вышестоящих уровнях.
Множественный доступ к каналам
Как это лучше делать? Практика показала, что на каналах где ошибки возникают редко, например, если данные передаются по проводам, то на канальном уровне лучше использовать простое обнаружение ошибок. А если ошибки в среде передачи данных происходят часто, например как это происходит в wifi? где используются электромагнитное излучение и много помех, то ошибки эффективнее обнаруживать и исправлять прямо на канальном уровне. Модель взаимодействия открытых систем разрабатывалась, когда на практике использовались только каналы связи “точка-точка” — это были последовательные линии связи, которые объединяли большие компьютеры.
Затем появились другие технологии канального уровня, на основе разделяемых каналов связи, когда к одной и той же среде передачи данных подключено несколько устройств. В таких каналах появились новые задачи, которые не были учтены в модели взаимодействия открытых систем, поэтому пришлось поменять эту модель и разделить канальный уровень на два подуровня.

Подуровни канального уровня
Подуровень №1 — управление логическим каналом (logical link control) LLC, а подуровень №2 — управление доступом к среде (media access control) MAC.
Подуровень LLC отвечает за передачу данных, формирование кадров, обработку ошибок и тому подобное. LLC общий уровень для различных технологий канального уровня.
Подуровень MAC используется, если технология канального уровня с разделяемым доступом. Если технология канального уровня используют соединение “точка-точка”, то подуровень MAC не нужен.
Во-первых если у нас есть несколько устройств, которые подключены к одному и тому же каналу связи, то при передаче данных мы должны явно указать, к какому устройству эти данные предназначены. Для этого используются адресация канального уровня, также необходимо обеспечить корректное, совместное использование разделяемой среды передачи данных.
Подуровень MAC особенный для разных технологий канального уровня, он зависит от того, какая среда передачи данных используется.
Услуги подуровня LLC
Мультиплексирование — передача данных через одну технологию канального уровня, нескольких типов протоколов вышестоящего уровня. Управление потоком, если в сети устройства, которые работают с разной скоростью, то более мощное устройство, может начать передавать данные очень быстро, так что более слабые устройства не успевают их принимать. В компьютерных сетях это называется “затопление” и некоторые технологии канального уровня обеспечивают защиту от затопления медленного получателя быстрым отправителем.
Множественный доступ к каналу связи
Предположим, есть какая-то общая среда передачи данных, к которой подключены несколько компьютеров и они начали передавать данные одновременно. Но так как среда передачи данных одна, то данные искажаются и не могут быть прочитаны из среды. Это называется коллизия. Подуровень MAC обеспечивает управление доступом, к разделяемой среде. В один и тот же момент времени, канал связи для передачи данных должен использовать только один отправитель. В противном случае произойдет коллизия и данные искажаются.
Методы управления доступом:
- Рандомизированный метод. Предположим, к среде подключено N устройств в этом случае для передачи данных случайным образом выбирается одно из этих устройств с вероятностью 1/N. Такой подход применяется в технологиях канального уровня изернет и вай-фай.
- Определение правил использования среды, например, в технологии Token Ring, данные может передавать только одно устройство, у которого сейчас находится токен. После того как это устройство передало данные, оно передает токен следующему устройству и следующее устройство может передавать данные. Хотя такой подход обеспечивает более эффективное использование полосы пропускания канала связи, но он требует более дорогого оборудования. Поэтому на практике получил распространение рандомизированный подход.
Раньше было очень много технологий канального уровня, каждая из которых обладала теми или иными преимуществами и недостатками. Однако сейчас в процессе развития остались только две популярные технологии это ethernet и вай-фай.
Мы рассмотрели канальный уровень, его основные задачи. Выяснили, что канальный уровень может обнаруживать и исправлять ошибки. Спасибо за прочтение статьи, надеемся она была для Вас полезной.
Обнаружение ошибок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды).
Способы борьбы с ошибками[]
В процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях модели OSI).
В системах связи возможны несколько стратегий борьбы с ошибками:
- обнаружение ошибок в блоках данных и автоматический запрос повторной передачи повреждённых блоков — этот подход применяется в основном на канальном и транспортном уровнях;
- обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков — такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
- исправление ошибок (forward error correction) применяется на физическом уровне.
Коды обнаружения и исправления ошибок[]
Корректирующие коды — коды, служащие для обнаружения или исправления ошибок, возникающих при передаче информации под влиянием помех, а также при её хранении.
Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении (приёме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода.
С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её.
В действительности, используемые коды обнаружения ошибок принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически, любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить).
По способу работы с данными коды, исправляющие ошибки делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные, работающие с данными как с непрерывным потоком.
Блоковые коды[]
Пусть кодируемая информация делится на фрагменты длиной  бит, которые преобразуются в кодовые слова длиной
бит, которые преобразуются в кодовые слова длиной  бит. Тогда соответствующий блоковый код обычно обозначают
бит. Тогда соответствующий блоковый код обычно обозначают  . При этом число
. При этом число  называется скоростью кода.
называется скоростью кода.
Если исходные бит код оставляет неизменными, и добавляет  проверочных, такой код называется систематическим, иначе несистематическим.
проверочных, такой код называется систематическим, иначе несистематическим.
Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из информационных бит сопоставляется бит кодового слова. Однако, хороший код должен удовлетворять, как минимум, следующим критериям:
- способность исправлять как можно большее число ошибок,
- как можно меньшая избыточность,
- простота кодирования и декодирования.
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач.
Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования.
Линейные коды общего вида[]
Линейный блоковый код — такой код, что множество его кодовых слов образует -мерное линейное подпространство (назовём его  ) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
Это значит, что операция кодирования соответствует умножению исходного -битного вектора на невырожденную матрицу  , называемую порождающей матрицей.
, называемую порождающей матрицей.
Пусть  — ортогональное подпространство по отношению к , а
— ортогональное подпространство по отношению к , а  — матрица, задающая базис этого подпространства. Тогда для любого вектора
— матрица, задающая базис этого подпространства. Тогда для любого вектора  справедливо:
справедливо:

Минимальное расстояние и корректирующая способность[]
-
Основная статья: Расстояние Хемминга
Расстоянием Хемминга (метрикой Хемминга) между двумя кодовыми словами  и
и  называется количество отличных бит на соответствующих позициях,
называется количество отличных бит на соответствующих позициях,  , что равно числу «единиц» в векторе
, что равно числу «единиц» в векторе  .
.
Минимальное расстояние Хемминга  является важной характеристикой линейного блокового кода. Она показывает насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
является важной характеристикой линейного блокового кода. Она показывает насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
 , округляем «вниз», так чтобы .
, округляем «вниз», так чтобы .


Корректирующая способность определяет, сколько ошибок передачи кода (типа  ) можно гарантированно исправить. То есть вокруг каждого кода
) можно гарантированно исправить. То есть вокруг каждого кода  имеем
имеем  -окрестность
-окрестность  , которая состоит из всех возможных вариантов передачи кода с числом ошибок () не более . Никакие две окрестности двух любых кодов не пересекаются друг с другом, так как расстояние между кодами (то есть центрами этих окрестностей) всегда больше двух их радиусов
, которая состоит из всех возможных вариантов передачи кода с числом ошибок () не более . Никакие две окрестности двух любых кодов не пересекаются друг с другом, так как расстояние между кодами (то есть центрами этих окрестностей) всегда больше двух их радиусов  .
.
Таким образом получив искажённый код из декодер принимает решение, что был исходный код , исправляя тем самым не более ошибок.
Поясним на примере. Предположим, что есть два кодовых слова и  , расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и в частности к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ) то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение что передавалось слово .
, расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и в частности к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ) то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение что передавалось слово .
Коды Хемминга[]
Коды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хемминга может быть представлен в таком виде, что синдром
- , где — принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.


Общий метод декодирования линейных кодов[]
Любой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где каждому значению принятого слова  соответствует наиболее вероятное переданное слово
соответствует наиболее вероятное переданное слово  . Однако, данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
. Однако, данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого вектора вычисляется синдром  . Поскольку
. Поскольку  , где
, где  — кодовое слово, а
— кодовое слово, а  — вектор ошибки, то
— вектор ошибки, то  . Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
. Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
Линейные циклические коды[]
Несмотря на то, что декодирование линейных кодов уже значительно проще декодирования большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно сложен. Циклические коды, кроме более простого декодирования, обладают и другими важными свойствами.
Циклическим кодом является линейный код, обладающий следующим свойством: если является кодовым словом, то его циклическая перестановка также является кодовым словом.
Слова циклического кода удобно представлять в виде многочленов. Например, кодовое слово  представляется в виде полинома
представляется в виде полинома  . При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на
. При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на  по модулю
по модулю  .
.
В дальнейшем, если не указано иное, мы будем считать, что циклический код является двоичным, то есть  могут принимать значения 0 или 1.
могут принимать значения 0 или 1.
Порождающий (генераторный) полином[]
Можно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему полиному  . Порождающий полином является делителем .
. Порождающий полином является делителем .
С помощью порождающего полинома осуществляется кодирование циклическим кодом. В частности:
Коды CRC[]
Коды CRC (cyclic redundancy check — циклическая избыточная проверка) являются систематическими кодами, предназначенными не для исправления ошибок, а для их обнаружения. Они используют способ систематического кодирования, изложенный выше: «контрольная сумма» вычисляется путем деления  на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
Таким образом, вид полинома задаёт конкретный код CRC. Примеры наиболее популярных полиномов:
| название кода | степень | полином |
|---|---|---|
| CRC-12 | 12 | 
|
| CRC-16 | 16 | 
|
| CRC-CCITT | 16 | 
|
| CRC-32 | 32 | 
|
Коды БЧХ[]
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния кода есть очень сложная задача.
Математически полинома на множители в поле Галуа.
Коды коррекции ошибок Рида — Соломона[]
Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида-Соломона, работающие с байтами (октетами).
Математически коды Рида — Соломона являются кодами БЧХ.
Преимущества и недостатки блоковых кодов[]
Хотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок, их эффективность при частых, но небольших ошибках (например, в канале с АБГШ), менее высока.
Свёрточные коды[]
Файл:ECC NASA standard coder.png Свёрточный кодер ( )
)
Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных.
Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании.
Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше.
Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия.
Преимущества и недостатки свёрточных кодов[]
Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок.
Каскадное кодирование. Итеративное декодирование[]
Преимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение.
Например, популярной является следующая конструкция: данные кодируются кодом Рида-Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона.
Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако, декодирование требует больших ресурсов. К таким кодам относят турбо-коды и LDPC-коды (коды Галлагера).
Оценка эффективности кодов[]
Эффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ).
Граница Хемминга и совершенные коды[]
-
Основная статья: Граница Хэмминга
Пусть имеется двоичный блоковый  код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):
код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):

Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с большой корректирующей способностью (такие, как коды Рида — Соломона) не являются совершенными.
Энергетический выигрыш[]
При передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, таким образом при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи (например, телефонной) неограниченно повышать мощность сигнала не дают технические ограничения.
Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении мощность передатчика можно снизить, оставляя скорость передачи информации неизменной. Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии кодирования.
Применение кодов, исправляющих ошибки[]
Коды, исправляющие ошибки, применяются:
- в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам.
- в системах хранения информации, в том числе магнитных и оптических.
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней.
Автоматический запрос повторной передачи[]
Системы с автоматическим запросом повторной передачи (ARQ — Automatic Repeat reQuest) основаны на технологии обнаружения ошибок. Распространены следующие методы автоматического запроса:
Запрос ARQ с остановками (stop-and-wait ARQ)[]
Идея этого метода заключается в том, что передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание.
Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)[]
Для этого метода необходим полнодуплексный канал. Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть, передается ошибочный блок и все последующие).
Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)[]
При этом подходе осуществляется передача только ошибочно принятых блоков данных.
См. также[]
- Цифровая связь
- Линейный код
- Циклический код
- Код Боуза — Чоудхури — Хоквингема
- Код Рида — Соломона
- LDPC
- Свёрточный код
- Турбо-код
Литература[]
- Мак-Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих ошибки. М.: Радио и связь, 1979.
- Блейхут Р. Теория и практика кодов, контролирующих ошибки. М.: Мир, 1986.
- Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение. М.: Техносфера, 2005. — ISBN 5-94836-035-0
Ссылки[]
Имеется викиучебник по теме:
Обнаружение и исправление ошибок
- Помехоустойчивое кодирование (11 ноября 2001). — реферат по проблеме кодирования сообщений с исправлением ошибок. Проверено 25 декабря 2006.
Эта страница использует содержимое раздела Википедии на русском языке. Оригинальная статья находится по адресу: Обнаружение и исправление ошибок. Список первоначальных авторов статьи можно посмотреть в истории правок. Эта статья так же, как и статья, размещённая в Википедии, доступна на условиях CC-BY-SA .
6.5.1. Весовой коэффициент двоичных векторов и расстояние между ними
6.5.2. Минимальное расстояние для линейного кода
6.5.3. Обнаружение и исправление ошибок
6.5.3.1. Распределение весовых коэффициентов кодовых слов
6.5.3.2.Одновременное обнаружение и исправление ошибок
6.5.4. Визуализация пространства 6-кортежей
6.5.5. Коррекция со стиранием ошибок
6.5.1. Весовой коэффициент двоичных векторов и расстояние между ними
Конечно же, понятно, что правильно декодировать можно не все ошибочные комбинации. Возможности кода для исправления ошибок в первую очередь определяются его структурой. Весовой коэффициент Хэмминга (Hamming weight) w(U) кодового слова U определяется как число ненулевых элементов в U. Для двоичного вектора это эквивалентно числу единиц в векторе. Например, если U=100101101, то w(U) = 5. Расстояние Хэмминга (Hamming distance) между двумя кодовыми словами U и V, обозначаемое как d(U, V), определяется как количество элементов, которыми они отличаются.
U=100101101
V=011110100
d(U,V)=6
Согласно свойствам сложения по модулю 2, можно отметить, что сумма двух двоичных векторов является другим двоичным вектором, двоичные единицы которого расположены на тех позициях, которыми эти векторы отличаются.
U + V=111011001
Таким образом, можно видеть, что расстояние Хэмминга между двумя векторами равно весовому коэффициенту Хэмминга их суммы, т.е. d(U, V) = w(U + V). Также видно, что весовой коэффициент Хэмминга кодового слова равен его расстоянию Хэмминга до нулевого вектора.
6.5.2. Минимальное расстояние для линейного кода
Рассмотрим множество расстояний между всеми парами кодовых слой в пространстве Vn. Наименьший элемент этого множества называется минимальным расстоянием кода и обозначается dmin. Как вы думаете, почему нас интересует именно минимальное расстояние, а не максимальное? Минимальное расстояние подобно наиболее слабому звену в цепи, оно дает нам меру минимальных возможностей кода и, следовательно, характеризует его мощность.
Как обсуждалось ранее, сумма двух произвольных кодовых слов дает другой элемент пространства кодовых слов. Это свойство линейных кодов формулируется просто: если U и V — кодовые слова, то и W = U + V тоже должно быть кодовым словом. Следовательно, расстояние между двумя кодовыми словами равно весовому коэффициенту третьего кодового слова, т.е. d(U, V) = w(U + V) = w(W). Таким образом, минимальное расстояние линейного кода можно определить, не прибегая к изучению расстояний между всеми комбинациями пар кодовых слов. Нам нужно лишь определить вес каждого кодового слова (за исключением нулевого вектора) в подпространстве; минимальный вес соответствует минимальному расстоянию dmin. Иными словами, dmin соответствует наименьшему из множества расстояний между нулевым кодовым словом и всеми остальными кодовыми словами.
6.5.3. Обнаружение и исправление ошибок
Задача декодера после приема вектора r заключается в оценке переданного кодового слова Ui. Оптимальная стратегия декодирования может быть выражена в терминах алгоритма максимального правдоподобия (см. приложение Б); считается, что передано было слово Ui, если
![]() (6.41)
(6.41)
Поскольку для двоичного симметричного канала (binary symmetric channel — BSC) правдоподобие Ui относительно r обратно пропорционально расстоянию между r и U, можно сказать, что передано было слово Ui, если
![]() (6.42)
(6.42)
Другими словами, декодер определяет расстояние между r и всеми возможными переданными кодовыми словами Uj, после чего выбирает наиболее правдоподобное Uj, для которого
![]() (6.43)
(6.43)
где М = 2k — это размер множества кодовых слов. Если минимум не один, выбор между минимальными расстояниями является произвольным. Наше обсуждение метрики расстояний будет продолжено в главе 7.
На рис. 6.13 расстояние между двумя кодовыми словами U и V показано как расстояние Хэмминга. Каждая черная точка обозначает искаженное кодовое слово. На рис. 6.13, а проиллюстрирован прием вектора r1 находящегося на расстоянии 1 от кодового слова U и на расстоянии 4 от кодового слова V. Декодер с коррекцией ошибок, следуя стратегии максимального правдоподобия, выберет при принятом векторе r1 кодовое слово U. Если r1 получился в результате появления одного ошибочного бита в переданном векторе кода U, декодер успешно исправит ошибку. Но если же это произошло в результате 4-битовой ошибки в векторе кода V, декодирование будет ошибочным. Точно так же, как показано на рис. 6.13, б, двойная ошибка при передаче U может привести к тому, что в качестве переданного вектора будет ошибочно определен вектор r2, находящийся на расстоянии 2 от вектора U и на расстоянии 3 от вектора кода V. На рис. 6.13 показана ситуация, когда в качестве переданного вектора ошибочно определен вектор r3, который находится на расстоянии 3 от вектора кода U и на расстоянии 2 от вектора V. Из рис. 6.13 видно, что если задача состоит только в обнаружении ошибок, а не в их исправлении, то можно определить искаженный вектор — изображенный черной точкой и представляющий одно-, двух-, трех- и четырехбитовую ошибку. В то же время пять ошибок при передаче могут привести к приему кодового слова V, когда в действительности было передано кодовое слово U; такую ошибку невозможно будет обнаружить.
Из рис. 6.13 можно видеть, что способность кода к обнаружению и исправлению ошибок связана с минимальным расстоянием между кодовыми словами. Линия решения на рисунке служит той же цели, что и в процессе демодуляции, — для разграничения областей решения.
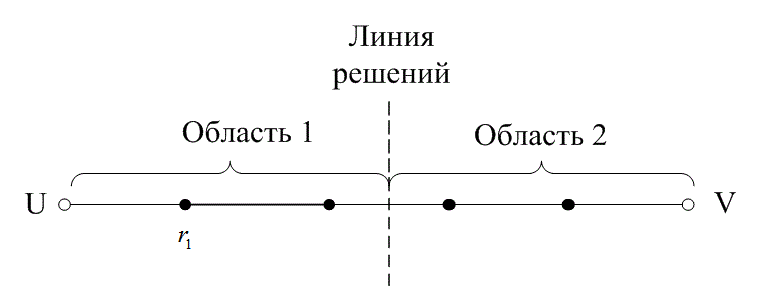
а)
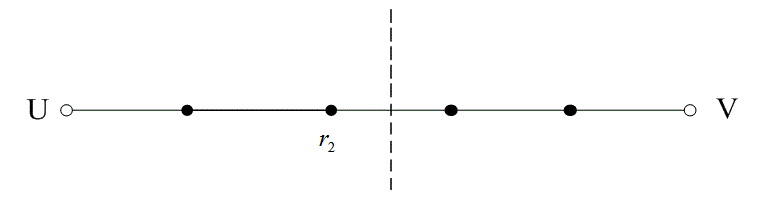
б)
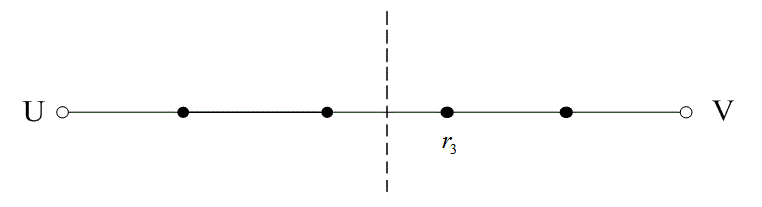
в)
Рис. 6.13. Возможности определения и исправления ошибок: а) принятый вектор r1; б) принятый вектор r2; в) принятый вектор r3
В примере, приведенном на рис. 6.13, критерий принятия решения может быть следующим: выбрать U, если r попадает в область 1, и выбрать V, если r попадает в область 2. Выше показывалось, что такой код (при dmin = 5) может исправить две ошибки. Вообще, способность кода к исправлению ошибок t определяется, как максимальное число гарантированно исправимых ошибок на кодовое слово, и записывается следующим образом [4].
![]() (6.44)
(6.44)
Здесь ![]() означает наибольшее целое, не превышающее х. Часто код, который исправляет все искаженные символы, содержащие ошибку в t или меньшем числе бит, также может исправлять символы, содержащие t +1 ошибочных бит. Это можно увидеть на рис. 6.11. В этом случае dmin = 3, поэтому из уравнения (6.44) можно видеть, что исправимы все ошибочные комбинации из t = 1 бит. Также исправима одна ошибочная комбинация, содержащая / +1 (т.е. 2) ошибочных бит. Вообще, линейный код (n, k), способный исправлять все символы, содержащие t ошибочных бит, может исправить всего 2n—k ошибочных комбинаций. Если блочный код с возможностью исправления символов, имеющих ошибки в t бит, применяется для исправления ошибок в двоичном симметричном канале с вероятностью перехода р, то вероятность ошибки сообщения Рм(вероятность того, что декодер совершит неправильное декодирование и п-битовый блок содержит ошибку) можно оценить сверху, используя уравнение (6.18).
означает наибольшее целое, не превышающее х. Часто код, который исправляет все искаженные символы, содержащие ошибку в t или меньшем числе бит, также может исправлять символы, содержащие t +1 ошибочных бит. Это можно увидеть на рис. 6.11. В этом случае dmin = 3, поэтому из уравнения (6.44) можно видеть, что исправимы все ошибочные комбинации из t = 1 бит. Также исправима одна ошибочная комбинация, содержащая / +1 (т.е. 2) ошибочных бит. Вообще, линейный код (n, k), способный исправлять все символы, содержащие t ошибочных бит, может исправить всего 2n—k ошибочных комбинаций. Если блочный код с возможностью исправления символов, имеющих ошибки в t бит, применяется для исправления ошибок в двоичном симметричном канале с вероятностью перехода р, то вероятность ошибки сообщения Рм(вероятность того, что декодер совершит неправильное декодирование и п-битовый блок содержит ошибку) можно оценить сверху, используя уравнение (6.18).
![]() (6.45)
(6.45)
Оценка переходит в равенство, если декодер исправляет все ошибочные комбинации, содержащие до t ошибочных бит включительно, но не комбинации с числом ошибочных бит, большим t. Такие декодеры называются декодерами с ограниченным расстоянием. Вероятность ошибки в декодированном бите РB зависит от конкретного кода и декодера. Приближенно ее можно выразить следующим образом [5].
![]() (6.46)
(6.46)
В блочном коде, прежде чем исправлять ошибки, необходимо их обнаружить. (Или же код может использоваться только для определения наличия ошибок.) Из рис. 6.13 видно, что любой полученный вектор, который изображается черной точкой (искаженное кодовое слово), можно определить как ошибку. Следовательно, возможность определения наличия ошибки дается следующим выражением.
![]() (6.47)
(6.47)
Блочный код с минимальным расстоянием dmin гарантирует обнаружение всех ошибочных комбинаций, содержащих dmin — 1 или меньшее число ошибочных бит. Такой код также способен обнаружить и большую ошибочную комбинацию, содержащую dmin или более ошибок. Фактически код (n, k) может обнаружить 2n – 2k ошибочных комбинаций длины п. Объясняется это следующим образом. Всего в пространстве 2n n-кортежей существует 2n -1 возможных ненулевых ошибочных комбинаций. Даже правильное кодовое слово — это потенциальная ошибочная комбинация. Поэтому всего существует 2k -1 ошибочных комбинаций, которые идентичны 2k -1 ненулевым кодовым словам. При появлении любая из этих 2k — 1 ошибочных комбинаций изменяет передаваемое кодовое слово Uj на другое кодовое слово Uj. Таким образом, принимается кодовое слово Uj и его синдром равен нулю. Декодер принимает Uj за переданное кодовое слово, и поэтому декодирование дает неверный результат. Следовательно, существует 2k -1 необнаружимых ошибочных комбинаций. Если ошибочная комбинация не совпадает с одним из 2k кодовых слов, проверка вектора r с помощью синдромов дает ненулевой синдром и ошибка успешно обнаруживается. Отсюда следует, что существует ровно 2n-2k выявляемых ошибочных комбинаций. При больших n, когда 2k<<2n, необнаружимой будет только незначительная часть ошибочных комбинаций.
6.5.3.1. Распределение весовых коэффициентов кодовых слов
Пусть Aj — количество кодовых слов с весовым коэффициентом j в линейном коде (п, k). Числа A0,A1,…,An называются распределением весовых коэффициентов этого кода. Если код применяется только для обнаружения ошибок в двоичном симметричном канале, то вероятность того, что декодер не сможет определить ошибку, можно рассчитать, исходя из распределения весовых коэффициентов кода [5].
![]() (6.48)
(6.48)
где р — вероятность перехода в двоичном симметричном канале. Если минимальное расстояние кода равно dmin значения от А1 до ![]() , равны нулю.
, равны нулю.
Пример 6.5. Вероятность необнаруженной ошибки в коде
Пусть код (6,3), введенный в разделе 6.4.3, используется только для обнаружения наличия ошибок. Рассчитайте вероятность необнаруженной ошибки, если применяется двоичный симметричный канал, а вероятность перехода равна 10-2.
Решение
Распределение весовых коэффициентов этого кода выглядит следующим образом: A0=1, А1= А2 = 0, A3 = 4, A5 = 0, A6 = 0. Следовательно, используя уравнение (6.48), можно записать следующее.
![]()
Для р = 10-2 вероятность необнаруженной ошибки будет равна 3,9 х 10-6.
6.5.3.2. Одновременное обнаружение и исправление ошибок
Возможностями исправления ошибок с максимальным гарантированным (t), где t определяется уравнением (6.44), можно пожертвовать в пользу определения класса ошибок. Код можно использовать для одновременного исправления α и обнаружения β ошибок, причем ![]() , а минимальное расстояние кода дается следующим выражением [4].
, а минимальное расстояние кода дается следующим выражением [4].
![]() (6.49)
(6.49)
При появлении t или меньшего числа ошибок код способен обнаруживать и исправлять их. Если ошибок больше t, но меньше е+1, где е определяется уравнением (6.47), код может определять наличие ошибок, но исправить может только некоторые из них. Например, используя код с dmin = 7. можно выполнить обнаружение и исправление со следующими значениями α и β.
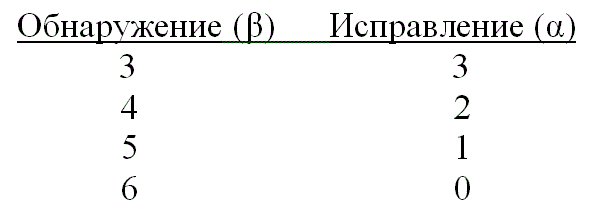
Заметим, что исправление ошибки подразумевает ее предварительное обнаружение. В приведенном выше примере (с тремя ошибками) все ошибки можно обнаружить и исправить. Если имеется пять ошибок, их можно обнаружить, но исправить можно только одну из них.
6.5.4. Визуализация пространства 6-кортежей
На рис. 6.14 визуально представлено восемь кодовых слов, фигурирующих в примере из раздела 6.4.3. Кодовые слова образованы посредством линейных комбинаций из трех независимых 6-кортежей, приведенных в уравнении (6.26); сами кодовые слова образуют трехмерное подпространство. На рисунке показано, что такое подпространство полностью занято восемью кодовыми словами (большие черные круги); координаты подпространства умышленно выбраны неортогональными. На рис. 6.14 предпринята попытка изобразить все пространство, содержащее шестьдесят четыре 6-кортежей, хотя точно нарисовать или составить такую модель невозможно. Каждое кодовое слово окружают сферические слои или оболочки. Радиус внутренних непересекающихся слоев — это расстояние Хэмминга, равное 1; радиус внешнего слоя — это расстояние Хэмминга, равное 2. Большие расстояния в этом примере не рассматриваются. Для каждого кодового слова два показанных слоя заняты искаженными кодовыми словами. На каждой внутренней сфере существует шесть таких точек (всего 48 точек), представляющих шесть возможных однобитовых ошибок в векторах, соответствующих каждому кодовому слову. Эти кодовые слова с однобитовыми возмущениями могут быть соотнесены только с одним кодовым словом; следовательно, такие ошибки могут быть исправлены. Как видно из нормальной матрицы, приведенной на рис. 6.11, существует также одна двухбитовая ошибочная комбинация, которая также поддается исправлению. Всего существует ![]()
Заметим, что исправление ошибки подразумевает ее предварительное обнаружение. В приведенном выше примере (с тремя ошибками) все ошибки можно обнаружить и исправить. Если имеется пять ошибок, их можно обнаружить, но исправить можно только одну из них.
6.5.4. Визуализация пространства 6-кортежей
На рис. 6.14 визуально представлено восемь кодовых слов, фигурирующих в примере из раздела 6.4.3. Кодовые слова образованы посредством линейных комбинаций из трех независимых 6-кортежей, приведенных в уравнении (6.26); сами кодовые слова образуют трехмерное подпространство. На рисунке показано, что такое подпространство полностью занято восемью кодовыми словами (большие черные круги); координаты подпространства умышленно выбраны неортогональными. На рис. 6.14 предпринята попытка изобразить все пространство, содержащее шестьдесят четыре 6-кортежей, хотя точно нарисовать или составить такую модель невозможно. Каждое кодовое слово окружают сферические слои или оболочки. Радиус внутренних непересекающихся слоев — это расстояние Хэмминга, равное 1; радиус внешнего слоя — это расстояние Хэмминга, равное 2. Большие расстояния в этом примере не рассматриваются. Для каждого кодового слова два показанных слоя заняты искаженными кодовыми словами. На каждой внутренней сфере существует шесть таких точек (всего 48 точек), представляющих шесть возможных однобитовых ошибок в векторах, соответствующих каждому кодовому слову. Эти кодовые слова с однобитовыми возмущениями могут быть соотнесены только с одним кодовым словом; следовательно, такие ошибки могут быть исправлены. Как видно из нормальной матрицы, приведенной на рис. 6.11, существует также одна двухбитовая ошибочная комбинация, которая также поддается исправлению. Всего существует 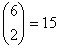 разных двухбитовых ошибочных комбинаций, которыми может быть искажено любое кодовое слово, но исправить можно только одну из них (в нашем примере это ошибочная комбинация 010001). Остальные четырнадцать двухбитовых ошибочных комбинаций описываются векторами, которые нельзя однозначно сопоставить с каким-либо одним кодовым словом; эти не поддающиеся исправлению ошибочные комбинации дают векторы, которые эквивалентны искаженным векторам двух или большего числа кодовых слов. На рисунке все (56) исправимые кодовые слова с одно- и двухбитовыми искажениями показаны маленькими черными кругами. Искаженные кодовые слова, не поддающиеся исправлению, представлены маленькими прозрачными кругами.
разных двухбитовых ошибочных комбинаций, которыми может быть искажено любое кодовое слово, но исправить можно только одну из них (в нашем примере это ошибочная комбинация 010001). Остальные четырнадцать двухбитовых ошибочных комбинаций описываются векторами, которые нельзя однозначно сопоставить с каким-либо одним кодовым словом; эти не поддающиеся исправлению ошибочные комбинации дают векторы, которые эквивалентны искаженным векторам двух или большего числа кодовых слов. На рисунке все (56) исправимые кодовые слова с одно- и двухбитовыми искажениями показаны маленькими черными кругами. Искаженные кодовые слова, не поддающиеся исправлению, представлены маленькими прозрачными кругами.
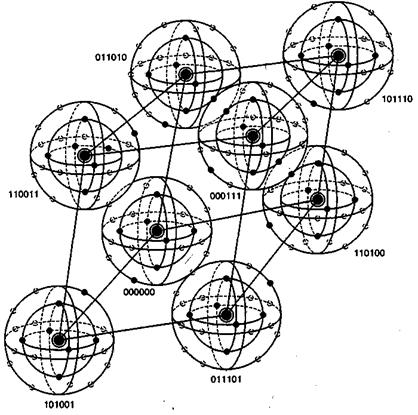
Рис, 6.14. Пример восьми кодовых слов в пространстве 6-кортежей
При представлении свойств класса кодов, известных как совершенные коды (perfect code), рис. 6.14 весьма полезен. Код, исправляющий ошибки в t битах, называется совершенным, если нормальная матрица содержит все ошибочные комбинации из t или меньшего числа ошибок и не содержит иных образующих элементов классов смежности (отсутствует возможность исправления остаточных ошибок). В контексте рис. 6.14 совершенный код с коррекцией ошибок в t битах — это такой код, который (при использовании обнаружения по принципу максимального правдоподобия) может исправить все искаженные кодовые слова, находящиеся на расстоянии Хэмминга t (или ближе) от исходного кодового слова, и не способен исправить ни одну из ошибок, находящихся на расстоянии, превышающем t.
Кроме того, рис. 6.14 способствует пониманию основной цели поиска хороших кодов. Предпочтительным является пространство, максимально заполненное кодовыми словами (эффективное использование введенной избыточности), а также желательно, чтобы кодовые слова были по возможности максимально удалены друг от друга. Очевидно, что эти цели противоречивы.
6.5.5. Коррекция со стиранием ошибок
Приемник можно сконструировать так, чтобы он объявлял символ стертым, если последний принят неоднозначно либо обнаружено наличие помех или кратковременных сбоев. Размер входного алфавита такого канала равен Q, а выходного —Q + 1; лишний выходной символ называется меткой стирания (erasure flag), или просто стиранием (erasure). Если демодулятор допускает символьную ошибку, то для ее исправления необходимы два параметра, определяющие ее расположение и правильное значение символа. В случае двоичных символов эти требования упрощаются — нам необходимо только расположение ошибки. В то же время, если демодулятор объявляет символ стертым (при этом правильное значение символа неизвестно), расположение этого символа известно, поэтому декодирование стертого кодового слова может оказаться проще исправления ошибки. Код защиты от ошибок можно использовать для исправления стертых символов или одновременного исправления ошибок и стертых символов. Если минимальное расстояние кода равно dmin, любая комбинация из ρ или меньшего числа стертых символов может быть исправлена при следующем условии [6].
![]() (6.50)
(6.50)
Предположим, что ошибки появляются вне позиций стирания. Преимущество исправления посредством стираний качественно можно выразить так: если минимальное расстояние кода равно dmin, согласно уравнению (6.50), можно восстановить dmin-1 стирание. Поскольку число ошибок, которые можно исправить без стирания информации, не превышает (dmin-1)/2, то преимущество исправления ошибок посредством стираний очевидно. Далее, любую комбинацию из α ошибок и γ стираний можно исправить одновременно, если, как показано в работе [6],
![]() (6.51)
(6.51)
Одновременное исправление ошибок и стираний можно осуществить следующим образом. Сначала позиции из у стираний замещаются нулями, и получаемое кодовое слово декодируется обычным образом. Затем позиции из у стираний замещаются единицами, и декодирование повторяется для этого варианта кодового слова. После обработки обоих кодовых слов (одно с подставленными нулями, другое — с подставленными единицами) выбирается то из них, которое соответствует наименьшему числу ошибок, исправленных вне позиций стирания. Если удовлетворяется неравенство (6.51), то описанный метод всегда дает верное декодирование.
Пример 6.6. Коррекция со стиранием ошибок
Рассмотрим набор кодовых слов, представленный в разделе 6.4.3.
000000 110100 011010 101110 101001 011101 110011 000111
Пусть передано кодовое слово 110011, в котором два крайних слева разряда приемник объявил стертыми. Проверьте, что поврежденную последовательность хx0011 можно исправить.
Решение
Поскольку ![]() , код может исправить
, код может исправить ![]() = 2 стирания. В этом легко убедиться из рис. 6.11 или приведенного выше перечня кодовых слов, сравнивая 4 крайних правых разряда xx00l1 с каждым из допустимых кодовых слов. Действительно переданное кодовое слово — это ближайшее (с точки зрения расстояния Хэмминга) к искаженной последовательности.
= 2 стирания. В этом легко убедиться из рис. 6.11 или приведенного выше перечня кодовых слов, сравнивая 4 крайних правых разряда xx00l1 с каждым из допустимых кодовых слов. Действительно переданное кодовое слово — это ближайшее (с точки зрения расстояния Хэмминга) к искаженной последовательности.