
Результаты прогнозирования методом скользящего среднего с минимальными значениями ошибок прогнозирования
|
Код |
Квартал |
Фактическое |
Прогнозируемое |
Отношение |
m |
|
y1 |
1/2005 |
83098 |
237165,6667 |
0,425619863 |
3 |
|
2/2005 |
106481 |
222477,3333 |
|||
|
3/2005 |
238814 |
142797,6667 |
|||
|
y2 |
1/2005 |
63636 |
150601,8889 |
0,582976972 |
9 |
|
2/2005 |
85730 |
154314,6667 |
|||
|
3/2005 |
186906 |
163593,2222 |
|||
|
y3 |
1/2005 |
3958 |
5858 |
0,235388066 |
9 |
|
2/2005 |
6161 |
6353,333333 |
|||
|
3/2005 |
8593 |
6913,777778 |
|||
|
y4 |
1/2005 |
12950 |
24837,4 |
0,496375532 |
5 |
|
2/2005 |
14928 |
26756,4 |
|||
|
3/2005 |
37149 |
29021 |
|||
|
y5 |
1/2005 |
2554 |
2880,666667 |
0,424243204 |
3 |
|
2/2005 |
2216 |
3061,333333 |
|||
|
3/2005 |
6166 |
3645,333333 |
|||
|
y6 |
1/2005 |
1428 |
2431,8 |
0,265790571 |
5 |
|
2/2005 |
2487 |
2886,8 |
|||
|
3/2005 |
3911 |
3386,8 |
|||
|
y7 |
1/2005 |
283 |
887,8888889 |
0,529258772 |
9 |
|
2/2005 |
716 |
930,3333333 |
|||
|
3/2005 |
1118 |
1036,555556 |
|||
|
y8 |
1/2005 |
673 |
468,2857143 |
0,260025866 |
7 |
|
2/2005 |
400 |
521,2857143 |
|||
|
3/2005 |
765 |
625,2857143 |
|||
|
y9 |
1/2005 |
47586 |
30194,4 |
0,472606146 |
5 |
|
2/2005 |
10864 |
31269 |
|||
|
3/2005 |
52109 |
38280,8 |
|||
|
y10 |
1/2005 |
48991 |
30427 |
0,499967477 |
5 |
|
2/2005 |
9633 |
31182,8 |
|||
|
3/2005 |
54554 |
38482,8 |
|||
|
y11 |
1/2005 |
67 |
24527,66667 |
68,36838773 |
3 |
|
2/2005 |
199 |
13876 |
|||
|
3/2005 |
444 |
236,6666667 |
|||
|
y12 |
1/2005 |
465 |
21483,33333 |
20,50273748 |
3 |
|
2/2005 |
459 |
11217,66667 |
|||
|
3/2005 |
1071 |
665 |
|||
|
y13 |
1/2005 |
139,6605042 |
321,453728 |
0,588150888 |
5 |
|
2/2005 |
177,7646077 |
333,7849497 |
|||
|
3/2005 |
396,0431177 |
359,9255947 |
|||
|
y14 |
1/2005 |
4,292436975 |
4,93971937 |
0,424349043 |
3 |
|
2/2005 |
3,699499165 |
5,200760323 |
|||
|
3/2005 |
10,22553897 |
6,072491704 |
Результаты
сглаживания и прогнозирования для
интервала усреднения m
= 3, при котором получены лучшие результаты
для y1
и y2
и для m
= 5, при котором получены лучшие результаты
для y13,
представлены на рис. 5.2.1-5.2.3.

Рис. 5.2.1. Прогнозируемое
значение выручки (нетто) от продажи
товаров, продукции, работ, услуг

Рис. 5.2.2. Прогнозируемое
значение прибыли от продаж

Рис. 5.2.3. Прогнозируемое
значение дохода на одного работника
5.3. Экспоненциальное сглаживание и прогнозирование
В основу
экспоненциального сглаживания и
прогнозирования положен принцип введения
различных удельных весов для усредняемых
значений ВДР, так называемый принцип
«взвешивания». Чем дальше отстоит
элемент ВДР от точки сглаживания или
прогнозирования, тем меньшее влияние
на вычисляемый элемент он должен иметь.
Таким образом, влияние прошлых наблюдений
должно затухать по мере удаления от
момента, для которого определяется
средняя. Поставленная задача может быть
решена с помощью применения специальной
системы весов, а именно информации
приписывается вес, соответствующий
степени ее новизны.
Один из простейших
приемов сглаживания ряда с учетом
«устаревания» данных заключается в
расчете специальных показателей,
получивших название экспоненциальных
средних.
Экспоненциальная
средняя
![]()
![]() , (5.3.1)
, (5.3.1)
где
![]() —
—
экспоненциальная средняя (сглаженное
значение уровня ряда) на моментj;
yj
– фактическое значение на момент времени
j;
![]() — коэффициент
— коэффициент
сглаживания, характеризующий вес
текущего наблюдения при расчете
экспоненциальной средней,
![]() .
.
Средняя формируется
под влиянием всех предыдущих значений,
но вес каждого из них с каждым шагом
уменьшается в (1 —
![]() )
)
раз, т.е. для расчетного значения это![]() ;
;
ближайшая переменная![]() (1
(1
—![]() );
);
затем![]() (1-
(1-![]() )2
)2
и т.д…, для i-го
элемента
![]() (1
(1
—![]() )i…
)i…
![]() ; (5.3.2)
; (5.3.2)
![]() ;
;
![]() ;
;
![]() .
.
Очевидно, результат
сглаживания зависит от коэффициента
сглаживания —
![]() .
.
Если![]() равно1,
равно1,
то предыдущие наблюдения полностью
игнорируются. Если
![]() равно0,
равно0,
то игнорируются текущие наблюдения.
Значения
![]() между0 и
между0 и
1
дают промежуточные результаты.
Соответственно
этому выражению средний уровень ряда
на момент времени j
равен линейной комбинации двух величин:
фактического уровня для этого же момента
и среднего уровня, рассчитанного для
предыдущего периода. Таким образом,
средняя здесь формируется под влиянием
всех предшествующих уровней ряда от
его начала и до момента времени j
включительно.
Следовательно,
средняя для момента времени j
представляет собой линейную комбинацию
значений всех наблюдений от y1
до yj.
При расчете
прогнозируемых значений ВДР методом
экспоненциального сглаживания
используется следующая формула:
![]() (5.3.3)
(5.3.3)
В дополнении к
простому экспоненциальному сглаживанию,
были предложены более сложные модели,
включающие сезонную компоненту и тренд.
Общая идея таких моделей состоит в том,
что прогнозы вычисляются не только по
предыдущим значениям (как в простом
экспоненциальном сглаживании), но и с
некоторыми задержками, что позволяет
независимо оценить тренд и сезонную
составляющую.
Экспоненциальное
сглаживание и прогнозирование проведено
с помощью ППП Statistica6.0
[6].
Сводные результаты
сглаживания и прогнозирования методом
экспоненциального сглаживания при
изменении параметра
![]() приведены в таблице 5.3.1.
приведены в таблице 5.3.1.
Таблица 5.3.1
Сводная таблица
ошибок прогноза при изменении параметра
alpha
(delta=0,100;
lag=4)
|
Код |
Ошибка |
Среднее |
Отношение |
||||||
|
alpha=0,2 |
alpha=0,4 |
alpha=0,6 |
alpha=0,8 |
alpha=0,2 |
alpha=0,4 |
alpha=0,6 |
alpha=0,8 |
||
|
y1 |
38341,0552 |
42085,5413 |
48242,96 |
54720,48 |
142797,6667 |
0,268499171 |
0,294721491 |
0,337841355 |
0,383202922 |
|
y2 |
29079,5659 |
34037,9663 |
41381,09 |
48127,33 |
112090,6667 |
0,259428967 |
0,303664589 |
0,369175164 |
0,429360727 |
|
y3 |
811,639186 |
1388,67414 |
2077,875 |
2631,703 |
6237,33 |
0,130125992 |
0,222639077 |
0,333135182 |
0,421927592 |
|
y4 |
6685,6415 |
7109,65678 |
7469,075 |
7888,403 |
21675,66667 |
0,308439948 |
0,328001758 |
0,344583404 |
0,363928978 |
|
y5 |
2303,93178 |
1663,40198 |
1545,68 |
3237,102 |
3645,33 |
0,632022252 |
0,45630998 |
0,424015193 |
0,888012577 |
|
y6 |
1332,1064 |
1479,26759 |
1458,08 |
1421,655 |
2608,666667 |
0,510646461 |
0,567058879 |
0,558936934 |
0,544973636 |
|
y7 |
227,224502 |
229,372177 |
381,5196 |
551,6347 |
705,6666667 |
0,321999767 |
0,325043236 |
0,540651326 |
0,78172141 |
|
y8 |
156,904051 |
281,977886 |
311,2799 |
271,1022 |
612,6666667 |
0,256100193 |
0,460246822 |
0,508073904 |
0,442495466 |
|
y9 |
420304,804 |
36112,8909 |
44832,28 |
84275,83 |
36853 |
11,40490065 |
0,979917262 |
1,216516356 |
2,286810484 |
|
y10 |
30115,7989 |
31271,5872 |
33697,3 |
36463,81 |
37726 |
0,798277021 |
0,828913407 |
0,893211691 |
0,966543289 |
|
y11 |
19356,6999 |
14607,9703 |
8682,66 |
4619,337 |
236,6666667 |
81,78887273 |
61,72381808 |
36,68729565 |
19,51832489 |
|
y12 |
23410,9955 |
19330,226 |
17347,26 |
19096,68 |
665 |
35,20450448 |
29,06800896 |
26,08609931 |
28,7168064 |
|
y13 |
74,4604795 |
77,5113267 |
85,90946 |
93,10522 |
237,8227432 |
0,313092341 |
0,325920581 |
0,361233168 |
0,391489971 |
|
y14 |
4,46463244 |
2,52296944 |
2,993029 |
2,922797 |
6,072491704 |
0,735222485 |
0,415475156 |
0,492883187 |
0,481317589 |
По результатам
таблицы 5.3.1, были сделаны следующие
выводы:
-
Изменение
коэффициента сглаживания от 0,2 до 0,8 с
шагом 0,2 при прогнозировании методом
экспоненциального сглаживания показало,
что наиболее близкие к фактическим
прогнозируемые значения достигаются
в большинстве случаев при значении
 =0,2.
=0,2. -
Наименьшая ошибка
прогнозирования методом экспоненциального
сглаживания составила 0,130125992, а
наибольшая – 81,78887273. -
Наиболее достоверные
результаты, полученные при прогнозировании
методом экспоненциального сглаживания
по результативным показателям yj, ,
,
представлены в таблице 5.3.2.
Таблица 5.3.2
Введение
В настоящее время известно большое количество различных методов прогнозирования, основывающихся только на анализе прошлых значений временной последовательности, то есть методов, использующих принципы, принятые в техническом анализе. Основным инструментом этих методов является схема экстраполяции, когда свойства последовательности, выявленные на рассматриваемом интервале времени распространяются за его пределы.
При этом предполагается, что свойства последовательности в будущем будут такими же, как в прошлом и настоящем. Реже в процессе прогнозирования используется более сложная схема экстраполяции, предполагающая исследование динамики изменения свойств последовательности и учет этой динамики на интервале прогноза.
Наверное, наиболее известными методами прогнозирования, основанными на экстраполяции, являются методы, использующие модель авторегрессии и скользящего среднего (ARIMA). Своей популярностью эти методы, в первую очередь, обязаны работам Бокса и Дженкинса (Boks Dzh., Dzhenkins G.), предложившим и развившим обобщенную модель ARIMA. Но кроме представленных Боксом и Дженкинсом
моделей, конечно, существуют и другие модели и методы прогнозирования.
В данной статье будут кратко рассмотрены более простые модели – модели экспоненциального сглаживания, которые были предложены Хольтом (Holt C.C) и Брауном (Brown R.G) еще до появления работ Бокса и Дженкинса.
Несмотря на более простой и доступный математический аппарат, прогнозирование при помощи моделей экспоненциального сглаживания часто дает результат, сопоставимый с результатом, полученным при использовании модели ARIMA. Это неудивительно, так как модели экспоненциального сглаживания являются частным случаем моделей ARIMA. Другими словами, каждая рассматриваемая в статье модель экспоненциального сглаживания имеет соответствующую эквивалентную модель ARIMA. Эти эквивалентные модели в статье рассматриваться не будут и приведены лишь для информации.
Известно, что процесс прогнозирования в каждом конкретном случае требует индивидуального подхода и обычно включает в себя целый ряд процедур.
Например:
- Анализ временной последовательности на предмет наличия пропущенных и выпадающих значений. Коррекция этих значений.
- Определение наличия тренда и его типа. Определение наличия периодичности в последовательности.
- Проверка последовательности на стационарность.
- Анализ последовательности на предмет необходимости предварительной обработки (логарифмирование, взятие разностей и так далее).
- Выбор модели.
- Определение параметров модели. Прогноз на основании выбранной модели.
- Оценка точности прогнозирования модели.
- Анализ характера ошибок выбранной модели.
- Определение адекватности выбранной модели и в случае необходимости ее замена и возвращение к предыдущим пунктам.
Здесь приведен далеко не полный список действий, необходимых для получения эффективного прогноза.
Следует подчеркнуть тот факт, что определение параметров модели и непосредственно получение прогноза являются лишь небольшой частью общей процедуры прогнозирования. Но рассмотреть в статье весь круг вопросов, так или иначе связанных с прогнозированием, не представляется возможным.
Поэтому в данной статье ограничимся только рассмотрением непосредственно самих моделей экспоненциального сглаживания, а в качестве тестовых последовательностей будем использовать котировки валют, без какой-либо их предварительной обработки. Конечно, совсем избежать в статье сопутствующих вопросов не удастся, но они будут затронуты лишь в объеме, необходимом для рассмотрения самих моделей.
1. Стационарность
Само понятие экстраполяции предполагает, что рассматриваемый процесс в будущем будет развиваться так же, как в прошлом и настоящем. Другими словами, речь идет о стационарности процесса. Стационарный процесс является наиболее привлекательным с точки зрения построения прогнозов, но, к сожалению, в природе таких процессов не существует, любой реальный процесс по мере своего развития подвержен изменениям.
У реальных процессов с течением времени могут заметно меняться математическое ожидание, дисперсия, закон распределения, но процессы, у которых эти характеристики изменяются очень медленно можно с той или иной вероятностью отнести к стационарным процессам. В данном случае понятие «очень медленно» означает, что изменение характеристик процесса на конечном интервале наблюдения оказывается настолько незначительным, что этими изменениями можно пренебречь.
Понятно, что чем короче доступный интервал наблюдения (короткая выборка), тем выше вероятность принятия ошибочного решения о стационарности процесса в целом. С другой стороны, если нас в большей степени интересует состояние процесса в более поздние моменты времени, и мы собираемся производить прогноз на очень короткий интервал, сокращение размера выборки в некоторых случаях может привести к увеличению точности такого прогноза.
Если процесс подвержен изменениям, то параметры последовательности, определенные на интервале наблюдения, за его пределами будут изменяться. Таким образом, чем длиннее интервал прогноза, тем большее влияние на погрешность прогноза будет оказывать изменчивость характеристик последовательности. Этот факт заставляет ограничиться лишь краткосрочным прогнозом, сильное сокращение интервала прогноза позволяет ожидать, что медленно изменяющиеся характеристики последовательности не внесут в прогноз существенных погрешностей.
Кроме того, изменчивость параметров последовательности приводит к тому, что при оценке по интервалу наблюдения мы получаем некоторое усредненное их значение, так как на этом интервале они не оставались постоянными. Поэтому найденные значения параметров не будут относиться к последнему моменту времени этого интервала, а будут отражать некоторое среднее их значение. Полностью устранить это неприятное явление, к сожалению, не представляется возможным, но его можно ослабить, если по возможности сокращать длительность интервала наблюдения, на котором производится оценка параметров модели (интервал обучения).
Укорачивать до бесконечности этот интервал тоже нельзя, так как при чрезмерном сокращении интервала обучения наверняка будет снижаться точность оценки параметров последовательности. Необходимо искать компромисс между влиянием ошибок, связанных с изменчивостью характеристик последовательности и возрастанием погрешностей, связанных с чрезмерным сокращением интервала обучения.
Все сказанное в полной мере относится к прогнозированию с использованием моделей экспоненциального сглаживания, так как эти модели построены исходя из предположения стационарности процессов, как впрочем, и модели ARIMA. Тем не менее, для упрощения в дальнейшем будем условно предполагать, что у всех рассматриваемых нами последовательностей их параметры на интервале наблюдения изменяются, но происходит это настолько медленно, что этими изменениями можно пренебречь.
Таким образом, в статье будут рассматриваться вопросы, связанные с краткосрочным прогнозированием последовательностей с медленно меняющимися характеристиками на базе моделей экспоненциального сглаживания. В данном случае понятие «краткосрочное прогнозирование» следует понимать как прогнозирование на один, два или несколько интервалов времени вперед, а не в смысле прогнозирования на период менее одного года, как это зачастую принято в экономике.
2. Тестовые последовательности
При написании статьи использовались предварительно сохраненные для периодов M1, M5, M30 и H1 котировки EURRUR, EURUSD, USDJPY и XAUUSD. Каждый из сохраненных файлов содержит по 1100 значений «open». Самое «старое» значение расположено в начале файла, а самое «новое» в конце. Самое последнее значение, записанное в файл, соответствует времени создания файла. Файлы с тестовыми последовательностями были созданы при помощи скрипта HistoryToCSV.mq5. Сами файлы с данными и скрипт, при помощи которого они были созданы, размещены в конце статьи в архиве Files.zip.
Как уже упоминалось, сохраненные котировки в данной статье используются без какой-либо предварительной обработки, несмотря на явные проблемы, на которые все же хочется обратить внимание. Например, котировки EURRUR_H1 в течение суток содержат то 12, то 13 бар, котировки XAUUSD по пятницам содержат на один бар меньше, чем в другие дни. Эти примеры показывают, что котировки представлены с неравномерным шагом дискретизации, и это совершенно неприемлемо для алгоритмов, рассчитанных на работу с корректными временными последовательностями, предполагающими равномерный шаг квантования.
Даже если при помощи интерполяции восстановить недостающие значения котировок, то открытым остается вопрос об отсутствии котировок в выходные дни. Можно предположить, что события, происходящие в мире в выходные дни, влияют на состояние мировой экономики не меньше, чем события, происходящие по будням. Революции, природные явления, громкие скандалы, смена правительства и другие более или менее крупные события подобного рода могут произойти когда угодно. Если такое событие произошло в субботу, то вряд ли оно окажет меньшее влияние на мировые рынки, чем в случае, если бы оно произошло в рабочий день.
Возможно, именно такие события приводят к тому, что мы часто наблюдаем разрывы котировок на границе рабочей недели. Скорее всего, мир продолжает существовать по своим законам даже тогда, когда FOREX не работает. Пока совершенно неясно, нужно ли в котировках, предназначенных для технического анализа восстанавливать значения, соответствующие выходным дням, даст ли это какую-либо выгоду?
Эти вопросы явно выходят за рамки данной статьи, но на первый взгляд, последовательность, не имеющая пропусков, представляется для анализа более привлекательной, хотя бы с точки зрения обнаружения циклических (сезонных) составляющих.
Значение предварительной подготовки данных для последующего анализа трудно переоценить, в данном случае это отдельная большая тема, так как котировки, в том виде, как они представлены в терминале, вообще малопригодны для технического анализа. К уже упомянутым проблемам с пропуском данных можно добавить еще целый ряд.
Например, при формировании котировок фиксированному моменту времени присваиваются значения «open» и «close» ему не принадлежащие, эти значения соответствуют времени формирования тика, а не фиксированному моменту выбранного таймфрейма графика, при этом тики, как известно иногда поступают очень редко.
Другой пример, это полное игнорирование теоремы Котельникова, ведь никто не дает гарантии, что хотя бы на минутном интервале частота дискретизации удовлетворяет упомянутой теореме (не говоря уже о других, более старших интервалах). Кроме всего прочего необходимо помнить и о наличии переменного спреда, который в некоторых случаях может наложиться на значения котировок.
Все же оставим все эти вопросы за рамками данной статьи и вернемся к ее непосредственной теме.
3. Экспоненциальное сглаживание
Для начала рассмотрим самую простую модель
![]() ,
,
где:
- X(t) – исследуемый (моделируемый) процесс,
- L(t) – изменяющийся уровень процесса,
- r(t)– случайная величина с нулевым средним значением.
Как видим, модель включает в себя сумму двух компонент, из которых нас интересует уровень процесса L(t), именно его мы и попытаемся выделить.
Хорошо известно, что при усреднении случайной последовательности можно добиться снижения ее дисперсии, то есть уменьшить размах ее отклонения от среднего значения. Поэтому можно предположить, что если процесс, описываемый нашей простейшей моделью подвергнуть усреднению (сглаживанию), то мы сможем если не совсем избавиться от случайной компоненты r(t), то хотя бы заметно ее ослабить, выделив тем самым интересующий нас уровень L(t).
Для этого обратимся к простому экспоненциальному сглаживанию (Simple Exponential Smoothing, SES).
![]()
В этом хорошо известном выражении степень сглаживания задается коэффициентом альфа, который можно установить в интервале от 0 до 1. При выборе значения альфа, равным нулю, вновь поступающие величины входной последовательности X не смогут оказать никакого влияния на результат сглаживания. Результатом сглаживания для любых моментов времени будет являться постоянная величина.
Таким образом, в этом крайнем случае мы полностью подавим мешающую случайную компоненту, но при этом и интересующий нас уровень процесса будет сглажен до состояния горизонтальной прямой линии. Если значение коэффициента альфа установить равным единице, то на входную последовательность процесс сглаживания вообще не будет оказывать никакого влияния. При этом интересующий нас уровень L(t) не будет искажен, но и случайная компонента подавлена не будет.
Интуитивно понятно, что при выборе величины альфа необходимо одновременно удовлетворять противоречивым требованиям. С одной стороны значение альфа должно быть близко к нулю, чтобы эффективно подавить случайную составляющую r(t). С другой, чтобы не исказить интересующую нас компоненту L(t), желательно выбирать значение альфа, близким к единице. Для нахождения оптимального значения альфа нам необходимо определить критерий, по которому это значение можно будет оптимизировать.
При определении такого критерия вспомним, что в данной статье речь идет о прогнозировании, а не просто о сглаживании последовательности.
В данном случае для простой модели экспоненциального сглаживания прогнозом на любое количество шагов вперед принято считать найденное в данный момент времени значение ![]() .
.
![]()
где ![]() – прогноз в момент времени t на m шагов вперед.
– прогноз в момент времени t на m шагов вперед.
Значит, прогнозом значения последовательности на момент времени t будет являться прогноз, сделанный на предыдущем шаге на один шаг вперед
![]()
В этом случае в качестве критерия для оптимизации значения коэффициента альфа можно использовать ошибку предсказания на один шаг
![]()
Таким образом, если минимизировать сумму квадратов этих ошибок по всей выборке, то можно будет определить оптимальное значение коэффициента альфа для данной последовательности. Естественно, наилучшим значением альфа будет такое, при котором величина суммы квадратов ошибок окажется минимальной.
На рисунке 1 приведен график зависимости суммы квадратов ошибок прогноза на один шаг вперед от величины коэффициента альфа для фрагмента тестовой последовательности USDJPY M1.

Рисунок 1. Простое экспоненциальное сглаживание
На полученном графике слабо различим минимум, примерно в районе значения альфа, равном 0,8. Но такую картину для простого экспоненциального сглаживания можно наблюдать далеко не всегда. При попытке определить оптимальное значение альфа для фрагментов тестовых последовательностей, используемых в статье, мы чаще всего будем получать непрерывно спадающий к единице график.
Столь высокие оптимальные значения коэффициента сглаживания говорят о том, что такая простейшая модель плохо подходит для описания наших тестовых последовательностей (котировок). Или уровень процесса L(t) изменяется слишком быстро, или в процессе присутствует тренд.
Несколько усложним нашу модель, добавив в нее ещё одну компоненту
![]() ,
,
где:
- X(t) — исследуемый (моделируемый) процесс;
- L(t) — изменяющийся уровень процесса;
- T(t) — линейный тренд;
- r(t) — случайная величина с нулевым средним значением.
Известно, что коэффициенты линейной регрессии можно определить, осуществив двойное сглаживание последовательности:
![]()
![]()
![]()
![]()
Для найденных таким образом коэффициентов a1 и a2 прогноз в момент времени t на m шагов вперед будет равен
![]()
Следует обратить внимание на тот факт, что в приведенных выражениях при первом и повторном сглаживании используется одинаковый коэффициент альфа. Такую модель называют аддитивной однопараметрической моделью линейного роста.
Продемонстрируем различие между простой моделью и моделью линейного роста.
Предположим, что на протяжении длительного времени исследуемый процесс представлял собой постоянную составляющую, то есть на графике выглядел как прямая горизонтальная линия и в какой-то момент времени начался линейный тренд. Прогноз такого процесса, сделанный упомянутыми моделями, показан на рисунке 2.

Рисунок 2. Сравнение моделей
Как видим, модель простого экспоненциального сглаживания заметно отстает от линейно изменяющейся входной последовательности, а прогноз, сделанный при помощи этой модели, еще больше от нее удаляется. При использовании модели линейного роста наблюдается иная картина. При возникновении тренда эта модель стремиться, как бы догнать линейно изменяющуюся последовательность, а ее прогноз лучше совпадает с направлением изменения входных значений.
Если бы в приведенном примере был выбран коэффициент сглаживания большей величины, то модель линейного роста за указанный промежуток времени вполне успела бы «догнать» входной сигнал, а ее прогноз практически совпал бы с входной последовательностью.
Несмотря на то, что в установившемся состоянии модель линейного роста при наличии линейного тренда показывает хороший результат, нетрудно заметить, что ей требуется определенное время для того чтобы «догнать» тренд. Поэтому, при частой смене направления тренда между моделью и входной последовательностью все время будет наблюдаться расхождение. Кроме того, если тренд нарастает не линейно, а по квадратичному закону, то модель линейного роста уже будет не в состоянии его «догнать». Но, несмотря на эти недостатки, при линейном тренде модель имеет преимущества перед моделью простого экспоненциального сглаживания.
Как уже упоминалось, мы использовали однопараметрическую модель линейного роста. Для поиска оптимального значения параметра альфа для фрагмента тестовой последовательности USDJPY M1 построим график зависимости суммы квадратов ошибок прогноза на один шаг вперед от величины этого параметра.
График такой зависимости показан на рисунке 3, при построении графика был использован тот же фрагмент последовательности, что и при построении графика, показанного на рисунке 1.

Рисунок 3. Модель линейного роста
По сравнению с результатом, показанным на рисунке 1, в данном случае величина оптимального значения для коэффициента альфа снизилась до значения, примерно равного 0,4. В данной модели для первого и второго сглаживания выбираются одинаковые коэффициенты, хотя теоретически они могут иметь разную величину. Модель линейного роста с двумя различными коэффициентами сглаживания будет представлена далее.
Обе рассмотренные модели экспоненциального сглаживания имеют свои аналоги в виде индикаторов, поставляемых в составе MetaTrader 5. Это хорошо известные EMA и DEMA, но предназначены они не для получения прогноза, а для сглаживания значений последовательности.
Следует учитывать, что при использовании индикатора DEMA на экран выводится значение соответствующее коэффициенту a1, а не значение прогноза на один шаг вперед. Коэффициент a2 (см. приведенные выше выражения для модели линейного роста) при этом не вычисляется и не используется. Кроме того, значение коэффициента сглаживания вычисляется через величину эквивалентного периода n
![]()
Для примера, значению альфа равному 0,8 будет соответствовать величина n примерно равная 2, а при значении альфа равным 0,4 величина n равна 4.
4. Начальные значения
Как уже упоминалось, при применении экспоненциального сглаживания необходимо тем или иным способом выбрать величину коэффициента сглаживания. Но этого оказывается недостаточно. Так как при экспоненциальном сглаживании текущее значение вычисляется на основе предыдущего, то для нулевого момента времени возникает ситуация, когда такое значение еще отсутствует. То есть, для нулевого момента времени, каким-то образом должны быть определенны начальное значение для S или для S1 и S2 в случае модели линейного роста.
Проблема выбора начальных значений не всегда легко разрешима. Если (как в случае использования котировок в MetaTrader 5) нам доступна очень длительная история, то даже при неточном определении начальных значений кривая экспоненциального сглаживания к текущему моменту времени успеет стабилизироваться, скорректировав нашу начальную ошибку. На это может понадобиться примерно от 10 до 200 (а иногда и больше) периодов в зависимости от величины коэффициента сглаживания.
В этой ситуации достаточно грубо оценить исходные значения и начать процесс экспоненциального сглаживания заранее, за 200-300 периодов до интересующего нас участка времени. Сложнее дело обстоит, когда в нашем распоряжении имеется выборка, содержащая, например, всего 100 значений.
В литературе можно встретить разные рекомендации по выбору начальных значений. Например, начальное значение для простого экспоненциального сглаживания может быть приравнено первому элементу последовательности или в надежде на сглаживание случайных выбросов может быть найдено как среднее значение трех-четырех начальных элементов последовательности. Для модели линейного роста начальные значения S1 и S2 могут быть определены исходя из предположения, что начальный уровень прогнозной кривой должен быть равен первому элементу последовательности, а наклон линейного тренда равен нулю.
В различных источниках можно найти еще целый ряд рекомендаций по выбору начальных значений, но все они не могут обеспечить отсутствие весьма чувствительных ошибок на начальных шагах алгоритма сглаживания. Особенно это заметно при использовании коэффициентов сглаживания с низкими значениями, когда для достижения стабильного состояния требуется большое количество периодов.
Поэтому чтобы свести к минимуму влияние проблем, связанных с выбором начальных значений (особенно для коротких последовательностей) иногда используют метод, предполагающий поиск таких значений, при которых ошибка прогноза окажется минимальной. Речь идет о вычислении ошибки прогноза по всей последовательности для изменяющихся с небольшим шагом величин исходных значений.
Наиболее удачный вариант можно выбрать после вычисления величины ошибки по сетке всех возможных комбинаций исходных значений. Но такой способ является очень трудоемким, требует большого количества вычислений и в прямом виде практически не используется.
Описанная задача является задачей оптимизации или поиска минимального значения функции многих переменных. Для решения подобного рода задач разработаны различные алгоритмы, позволяющие существенно сократить требуемые объемы вычислений. К вопросам оптимизации параметров сглаживания и начальных значений при прогнозировании вернемся несколько позже.
5. Оценка точности прогноза
В процессе прогнозирования и выбора начальных значений или параметров модели возникает задача оценки точности прогнозирования. Оценка точности важна и при сравнении между собой различных моделей или при определении состоятельности полученного прогноза. Известно большое количество оценок, определяющих точность прогнозирования, но для вычисления любой из них необходимо знать на каждом шаге ошибку прогнозирования.
Как уже упоминалось, ошибка прогнозирования на один шаг вперед в момент времени t равна
![]()
где:
Наверное, наиболее распространенной оценкой точности прогнозирования является среднее значение квадратов ошибок (Mean Squared Error):
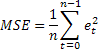
где n – количество элементов последовательности.
Иногда, в качестве недостатка оценки MSE указывают на ее чрезмерную чувствительность к редким одиночным ошибкам большой величины. Это объясняется тем, что значение ошибки при вычислении MSE возводится в квадрат. В этом случае в качестве альтернативы предлагается использовать среднее значение абсолютной ошибки (Mean Absolute Error)
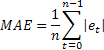
Здесь операция возведения значения ошибки в квадрат заменена на использование абсолютного ее значения. Предполагается, что при использовании MAE можно получить более устойчивые оценки.
Обе эти оценки хорошо подходят, например, для определения точности прогноза одной и той же последовательности при различных параметрах модели или при использовании различных моделей, но они оказываются малопригодными для сравнения между собой результатов прогнозирования, полученных на разных последовательностях.
Кроме того, непосредственно по величине этих оценок нельзя определить, насколько хорош результат прогнозирования. Например, получив значение MAE равное 0,03, или какое либо другое, мы не можем сказать хорошо это или плохо.
Для того чтобы иметь возможность сравнивать между собой точность
прогноза разных последовательностей можно использовать относительные оценки RelMSE и RelMAE:
![]()
При этом найденные оценки точности прогноза делятся на
соответствующие оценки, полученные при использовании тестового метода
прогнозирования. В качестве такого тестового метода удобно использовать так
называемый наивный метод, когда предполагается, что значение процесса в будущем
будет равно его значению в данный момент времени.
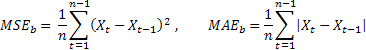
Если средняя величина ошибок прогнозирования равна
величине ошибок полученных при использовании наивного метода, то значение
относительных оценок будет равно единице. Если значение относительных оценок
меньше единицы, то это означает, что в среднем величина ошибок прогноза меньше,
чем при наивном методе. То есть, точность результатов прогноза превосходит
точность наивного метода. И наоборот, если значение относительных оценок больше
единицы, то точность результатов прогноза в среднем хуже, чем при наивном
методе прогнозирования.
Эти оценки так же пригодны для определения точности прогноза на два или более шагов вперед. Для этого нужно лишь вместо ошибки прогноза на один шаг при их расчете использовать значение ошибок прогноза на соответствующее количество шагов вперед.
Для примера в таблице приведены ошибки прогноза на один
шаг вперед RelMAE при использовании однопараметрической модели линейного
роста. Подсчет ошибок производился по 200 последним значениям каждой тестовой последовательности.
|
Таблица 1. Ошибки прогноза RelMAE на один шаг вперед.
Оценка RelMAE позволяет сравнить между собой эффективность
выбранного метода при прогнозировании разных последовательностей. Как видно из
результатов, приведенных в таблице 1, нам ни разу не удалось произвести прогноз
точнее, чем в случае использования наивного метода, все значения RelMAE больше единицы.
6. Аддитивные модели
Ранее в статье уже приводилась модель, которая включала в себя сумму уровня процесса, линейного тренда и случайной величины. В список рассматриваемых в статье моделей добавим еще и модель, которая в дополнение к перечисленным компонентам в виде суммы включает в себя циклическую, сезонную составляющую.
Модели экспоненциального сглаживания, в которых все компоненты входят в виде суммы, называют аддитивными моделями. Кроме таких моделей существуют мультипликативные модели, в которых одна, несколько или все компоненты входят в них в виде произведения. Перейдем к рассмотрению группы аддитивных моделей.
В прошлых разделах уже не раз упоминалось об ошибке прогноза, сделанного на один шаг вперед. Практически в любых приложениях, связанных с прогнозированием, на основе экспоненциального сглаживания приходится вычислять значение этой ошибки. Зная величину ошибки прогнозирования, выражения для представленных ранее моделей экспоненциального сглаживания можно записать в несколько иной форме (форма с коррекцией ошибки).
В данном случае будем использовать форму представления модели, когда в ее выражениях ошибка частично или полностью суммируется с ранее полученными значениями. Такое представление называют моделями с аддитивной ошибкой. Модели экспоненциального сглаживания также могут быть выражены и в форме с мультипликативной ошибкой, но в
данной статье такое представление моделей использовать не будем.
Рассмотрим аддитивные модели экспоненциального
сглаживания.
Простое экспоненциальное сглаживание:
![]()
![]()
Эквивалентная модель – ARIMA(0,1,1): ![]()
Аддитивная модель линейного роста:
![]()
![]()
![]()
В отличие от ранее представленной однопараметрической модели линейного роста, в данном случае используются два различных параметра сглаживания.
Эквивалентная модель – ARIMA(0,2,2): ![]()
Модель линейного роста с демпфированием:
![]()
![]()
![]()
Смысл такого демпфирования заключается в том, что на каждом последующем шаге прогнозирования крутизна тренда будет убывать в зависимости от величины значения коэффициента демпфирования. Этот эффект демонстрируется на рисунке 4.

Рисунок 4. Влияние коэффициента демпфирования
Как следует из приведенного рисунка, при построении прогноза, с уменьшением величины коэффициента демпфирования тренд все быстрее будет терять свою силу, таким образом, линейный рост оказывается все более демпфированным.
Эквивалентная модель — ARIMA(1,1,2): ![]()
К каждой из этих трех моделей можно в виде суммы добавить сезонную составляющую, при этом получим еще три модели.
Простая модель с аддитивной сезонностью:
![]()
![]()
![]()
Модель линейного роста с аддитивной сезонностью:
![]()
![]()
![]()
![]()
Модель линейного роста с демпфированием и аддитивной сезонностью:
![]()
![]()
![]()
![]()
Для моделей с сезонностью также существуют эквивалентные модели ARIMA, но они здесь не приводятся, так как вряд ли будут иметь какое-либо практическое значение.
В приведенных выражениях используются следующие обозначения:
Нетрудно заметить, что выражения для последней из приведенных моделей включают в себя все шесть рассматриваемых вариантов.
Если в
выражениях для модели линейного роста с демпфированием и аддитивной сезонностью
принять
![]() ,
,
то при вычислении прогноза сезонность учитываться не будет. Далее, при ![]() будет получена модель линейного роста, а при
будет получена модель линейного роста, а при ![]() получим модель линейного роста с демпфированием.
получим модель линейного роста с демпфированием.
Значениям ![]() будет соответствовать модель простого экспоненциального сглаживания.
будет соответствовать модель простого экспоненциального сглаживания.
При применении моделей, учитывающих сезонность, вначале необходимо каким-либо доступным методом определить наличие цикличности и период цикла, затем эти данные использовать для инициализации значения сезонных индексов.
В нашем случае, когда прогноз производится на коротких интервалах времени, обнаружить значительную устойчивую цикличность в используемых фрагментах тестовых последовательностей не удалось. Поэтому в статье не будем приводить примеры и подробно рассматривать особенности, связанные с учетом сезонности.
Для определения вероятностных пределов прогноза (prediction intervals) для рассматриваемых моделей воспользуемся аналитическим выводами, представленными в литературе [3]. В качестве оценки дисперсии ошибок прогноза на один шаг вперед будем использовать среднее значение суммы их квадратов, вычисленное по всей выборке размером n.
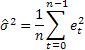
Тогда для определения величины дисперсии при прогнозе на 2 и более шагов вперед для рассматриваемых моделей будет справедливо выражение:
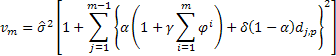
где ![]() равняется единице в случае, если j, взятое по модулю p равно нулю, в противном случае
равняется единице в случае, если j, взятое по модулю p равно нулю, в противном случае ![]() равно нулю.
равно нулю.
Вычислив значение дисперсии прогноза для каждого шага m, можно найти границы прогноза для 95% вероятностного интервала:
![]()
Далее такой вероятностный диапазон условимся называть доверительным интервалом прогноза.
Используя приведенные для моделей экспоненциального сглаживания выражения, реализуем их в виде класса написанного на MQL5.
7. Программная реализация класса AdditiveES
При реализации в виде класса использовались выражения для модели линейного роста с демпфированием и аддитивной сезонностью.
Как упоминалось ранее, остальные модели могут быть получены из нее путем соответствующего выбора параметров.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #include <Object.mqh> class AdditiveES:public CObject { protected: double Alpha; double Gamma; double Phi; double Delta; int nSes; double S; double T; double Ises[]; int p_Ises; double F; public: AdditiveES(); double Init(double s,double t,double alpha=1,double gamma=0, double phi=1,double delta=0,int nses=1); double GetS() { return(S); } double GetT() { return(T); } double GetF() { return(F); } double GetIs(int m); void IniIs(int m,double is); double NewY(double y); double Fcast(int m); double VarCoefficient(int m); }; void AdditiveES::AdditiveES() { Alpha=0.5; Gamma=0; Delta=0; Phi=1; nSes=1; ArrayResize(Ises,nSes); ArrayInitialize(Ises,0); p_Ises=0; S=0; T=0; } double AdditiveES::Init(double s,double t,double alpha=1,double gamma=0, double phi=1,double delta=0,int nses=1) { S=s; T=t; Alpha=alpha; if(Alpha<0)Alpha=0; if(Alpha>1)Alpha=1; Gamma=gamma; if(Gamma<0)Gamma=0; if(Gamma>1)Gamma=1; Phi=phi; if(Phi<0)Phi=0; if(Phi>1)Phi=1; Delta=delta; if(Delta<0)Delta=0; if(Delta>1)Delta=1; nSes=nses; if(nSes<1)nSes=1; ArrayResize(Ises,nSes); ArrayInitialize(Ises,0); p_Ises=0; F=S+Phi*T; return(F); } double AdditiveES::NewY(double y) { double e; e=y-F; S=S+Phi*T+Alpha*e; T=Phi*T+Alpha*Gamma*e; Ises[p_Ises]=Ises[p_Ises]+Delta*(1-Alpha)*e; p_Ises++; if(p_Ises>=nSes)p_Ises=0; F=S+Phi*T+GetIs(0); return(F); } double AdditiveES::GetIs(int m) { if(m<0)m=0; int i=(int)MathMod(m+p_Ises,nSes); return(Ises[i]); } void AdditiveES::IniIs(int m,double is) { if(m<0)m=0; if(m<nSes) { int i=(int)MathMod(m+p_Ises,nSes); Ises[i]=is; } } double AdditiveES::Fcast(int m) { int i,h; double v,v1; if(m<1)h=1; else h=m; v1=1; v=0; for(i=0;i<h;i++){v1=v1*Phi; v+=v1;} return(S+v*T+GetIs(h)); } double AdditiveES::VarCoefficient(int m) { int i,h; double v,v1,a,sum,k; if(m<1)h=1; else h=m; if(h==1)return(1); v=0; v1=1; sum=0; for(i=1;i<h;i++) { v1=v1*Phi; v+=v1; if((int)MathMod(i,nSes)==0)k=1; else k=0; a=Alpha*(1+v*Gamma)+k*Delta*(1-Alpha); sum+=a*a; } return(1+sum); }
Кратко рассмотрим методы класса AdditiveES.
Метод Init
Входные параметры:
- double s — устанавливаемое начальное значение сглаженного уровня;
- double t — устанавливаемое начальное значение сглаженного тренда;
- double alpha=1 — устанавливаемый параметр сглаживания уровня последовательности;
- double gamma=0 — устанавливаемый параметр сглаживания тренда;
- double phi=1 — устанавливаемый параметр демпфирования;
- double delta=0 — устанавливаемый параметр сглаживания сезонных индексов;
- int nses=1 — устанавливаемое количество периодов в сезонном цикле.
Возвращаемое значение:
- Возвращает вычисленный на основании установленных начальных значений прогноз на один шаг вперед.
Обращение к методу Init необходимо производить в самую первую очередь. Это необходимо для установки параметров сглаживания и начальных значений. Следует отметить, что метод Init не предусматривает возможности инициализации сезонных индексов произвольными значениями, сезонные индексы при обращении к нему всегда будут установлены в нуль.
Метод IniIs
Входные параметры:
- Int m — номер сезонного индекса;
- double is — устанавливаемое значение сезонного индекса с номером m.
Возвращаемое значение:
- Нет
Обращение к методу IniIs(…) производится в случае необходимости присвоить сезонным индексам начальные значения отличные от нуля. Производить инициализацию сезонных индексов следует сразу после обращения к методу Init(…).
Метод NewY
Входные параметры:
- double y – новое значение входной последовательности
Возвращаемое значение:
- Возвращает вычисленный на основании нового поступившего значения последовательности прогноз на один шаг вперед
Метод, предназначенный для вычисления прогноза на один шаг вперед при поступлении каждого следующего значения входной последовательности. Обращаться к методу следует только после инициализации класса методами Init и при необходимости IniIs.
Метод Fcast
Входные параметры:
- int m – горизонт прогнозирования 1,2,3,… периода;
Возвращаемое значение:
- Возвращает значение прогноза, сделанного на m-шагов вперед.
Метод только рассчитывает значение прогноза, не влияя на состояние процесса сглаживания. Обычно обращение к нему должно производиться после обращения к методу NewY.
Метод VarCoefficient
Входные параметры:
- int m – горизонт прогнозирования 1,2,3,… периода;
Возвращаемое значение:
- Возвращает значение коэффициента для вычисления дисперсии прогноза.
Вычисляется значение коэффициента показывающего насколько возрастет величина дисперсии для прогноза на m-шагов по сравнению с дисперсией прогноза на один шаг вперед.
Методы GetS, GetT, GetF, GetIs
Методы служат для обеспечения доступа к защищенным переменным класса. GetS, GetT и GetF возвращают значения сглаженного уровня, сглаженного значения тренда и значение прогноза на один шаг соответственно. Метод GetIs обеспечивает доступ к сезонным индексам и требует в качестве входного аргумента указания номера индекса m.
Самой сложной из рассматриваемых нами моделей является модель линейного
роста с демпфированием и аддитивной сезонностью , на основе которой и создан класс AdditiveES. Совершенно резонно возникает вопрос, для чего тогда могут понадобиться остальные более простые модели?
Несмотря на то, что на первый взгляд более сложные модели должны иметь явное преимущество перед более простыми, на самом деле это далеко не всегда так. Более простые модели, имеющие меньшее число параметров в подавляющем большинстве случаев будут обеспечивать меньшую величину дисперсии ошибок прогнозирования, то есть будут работать более устойчиво. Этот факт используют при создании алгоритмов прогнозирования базирующихся на одновременной параллельной работе всех имеющихся в наличии моделей, от самых простых до самых сложных.
После того как последовательность полностью обработана, для прогнозирования выбирается модель, показавшая наименьшее значение ошибки с учетом числа ее параметров (то есть с учетом ее сложности). Для такого выбора разработан ряд критериев, например Akaike’s Information Criterion (AIC). В результате будет выбрана модель, от которой ожидается получение наиболее устойчивого прогноза.
Для демонстрации использования класса AdditiveES был создан несложный индикатор, в котором все параметры сглаживания задаются вручную.
Исходный код индикатора AdditiveES_Test.mq5 приводится ниже.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #property indicator_chart_window #property indicator_buffers 4 #property indicator_plots 4 #property indicator_label1 "History" #property indicator_type1 DRAW_LINE #property indicator_color1 clrDodgerBlue #property indicator_style1 STYLE_SOLID #property indicator_width1 1 #property indicator_label2 "Forecast" #property indicator_type2 DRAW_LINE #property indicator_color2 clrDarkOrange #property indicator_style2 STYLE_SOLID #property indicator_width2 1 #property indicator_label3 "PInterval+" #property indicator_type3 DRAW_LINE #property indicator_color3 clrCadetBlue #property indicator_style3 STYLE_SOLID #property indicator_width3 1 #property indicator_label4 "PInterval-" #property indicator_type4 DRAW_LINE #property indicator_color4 clrCadetBlue #property indicator_style4 STYLE_SOLID #property indicator_width4 1 double HIST[]; double FORE[]; double PINT1[]; double PINT2[]; input double Alpha=0.2; input double Gamma=0.2; input double Phi=0.8; input double Delta=0; input int nSes=1; input int nHist=250; input int nTest=150; input int nFore=12; #include "AdditiveES.mqh" AdditiveES fc; int NHist; int NFore; int NTest; double ALPH; double GAMM; double PHI; double DELT; int nSES; int OnInit() { NHist=nHist; if(NHist<100)NHist=100; NFore=nFore; if(NFore<2)NFore=2; NTest=nTest; if(NTest>NHist)NTest=NHist; if(NTest<50)NTest=50; ALPH=Alpha; if(ALPH<0)ALPH=0; if(ALPH>1)ALPH=1; GAMM=Gamma; if(GAMM<0)GAMM=0; if(GAMM>1)GAMM=1; PHI=Phi; if(PHI<0)PHI=0; if(PHI>1)PHI=1; DELT=Delta; if(DELT<0)DELT=0; if(DELT>1)DELT=1; nSES=nSes; if(nSES<1)nSES=1; MqlRates rates[]; CopyRates(NULL,0,0,NHist,rates); SetIndexBuffer(0,HIST,INDICATOR_DATA); PlotIndexSetString(0,PLOT_LABEL,"History"); SetIndexBuffer(1,FORE,INDICATOR_DATA); PlotIndexSetString(1,PLOT_LABEL,"Forecast"); PlotIndexSetInteger(1,PLOT_SHIFT,NFore); SetIndexBuffer(2,PINT1,INDICATOR_DATA); PlotIndexSetString(2,PLOT_LABEL,"Conf+"); PlotIndexSetInteger(2,PLOT_SHIFT,NFore); SetIndexBuffer(3,PINT2,INDICATOR_DATA); PlotIndexSetString(3,PLOT_LABEL,"Conf-"); PlotIndexSetInteger(3,PLOT_SHIFT,NFore); IndicatorSetInteger(INDICATOR_DIGITS,_Digits); return(0); } int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { int i,j,init,start; double v1,v2; if(rates_total<NHist){Print("Error: Not enough bars for calculation!"); return(0);} if(prev_calculated>rates_total||prev_calculated<=0||(rates_total-prev_calculated)>1) {init=1; start=rates_total-NHist;} else {init=0; start=prev_calculated;} if(start==rates_total)return(rates_total); if(init==1) { i=start; v2=(open[i+2]-open[i])/2; v1=(open[i]+open[i+1]+open[i+2])/3.0-v2; fc.Init(v1,v2,ALPH,GAMM,PHI,DELT,nSES); ArrayInitialize(HIST,EMPTY_VALUE); } PlotIndexSetInteger(1,PLOT_DRAW_BEGIN,rates_total-NFore); PlotIndexSetInteger(2,PLOT_DRAW_BEGIN,rates_total-NFore); PlotIndexSetInteger(3,PLOT_DRAW_BEGIN,rates_total-NFore); for(i=start;i<rates_total;i++) { HIST[i]=fc.NewY(open[i]); } v1=0; for(i=0;i<NTest;i++) { j=rates_total-NTest+i; v2=close[j]-HIST[j-1]; v1+=v2*v2; } v1/=NTest; j=1; for(i=rates_total-NFore;i<rates_total;i++) { v2=1.96*MathSqrt(v1*fc.VarCoefficient(j)); FORE[i]=fc.Fcast(j++); PINT1[i]=FORE[i]+v2; PINT2[i]=FORE[i]-v2; } return(rates_total); }
При запуске или повторной инициализации индикатора происходит установка начальных значений экспоненциального сглаживания
![]()
Для сезонных индексов в данном индикаторе начальных
установок не производится, поэтому их начальные значения всегда оказываются
равны нулю. При такой инициализации влияние сезонности на результат прогноза
при поступлении новых значений будет постепенно возрастать от нуля, до какой-то
установившейся величины.
Количество циклов, необходимых для достижения
установившегося режима, зависит от величины коэффициента сглаживания сезонных
индексов: чем ниже значение коэффициента сглаживания, тем больше времени на это
потребуется.
На рисунке 5 показан результат работы индикатора AdditiveES_Test.mq5 с установками по умолчанию.

Рисунок 5. Индикатор AdditiveES_Test.mq5
Кроме непосредственно прогноза индикатор дополнительно выводит линию, соответствующую прогнозу на один шаг для прошлых значений последовательности и границы 95% доверительного интервала прогноза.
Доверительный интервал строится на основе оценки дисперсии ошибки на один шаг вперед. Для того чтобы снизить влияние неточностей, допущенных при выборе начальных значений, эта оценка производится не по всей длине nHist, а только по последним барам, количество которых указывается во входном параметре nTest.
В конце статьи размещен архив Files.zip, включающий в себя файлы AdditiveES.mqh и AdditiveES_Test.mq5. При компиляции индикатора необходимо, чтобы включаемый файл AdditiveES.mqh был расположен в том же каталоге, что и AdditiveES_Test.mq5.
Если при построении индикатора AdditiveES_Test.mq5 проблема выбора начальных значений хоть как-то была решена, то проблема с выбором оптимальных значений параметров сглаживания так и осталась открытой.
8. Выбор оптимальных значений параметров
Простая модель экспоненциального сглаживания имеет единственный параметр сглаживания и для поиска его оптимального значения можно воспользоваться методом простого перебора. Произведя по всей последовательности расчет величины ошибок прогнозирования, изменим на небольшой шаг значение параметра и вновь произведем полный расчет. Будем повторять эту процедуру до тех пор, пока не переберем все возможные значения параметра. Далее
нам останется только выбрать значение параметра, при котором была получена
наименьшая величина ошибок.
Для того чтобы искать оптимальное значение коэффициента сглаживания в диапазоне от 0.1 до 0.9 с шагом 0.05, нам понадобиться семнадцать раз произвести полный расчет величины ошибок прогнозирования. Как видим, требуется не так уж много вычислений. Но для модели линейного роста с демпфированием оптимизировать необходимо уже три параметра сглаживания, и для того чтобы перебрать все их комбинации по сетке с тем же шагом 0.05, потребуется уже 4913 проходов.
Количество полных проходов, которое требуется для перебора всех возможных значений параметров, очень быстро возрастает с увеличением количества параметров, уменьшением шага их изменения и увеличением диапазона поиска. Если в дальнейшем возникнет необходимость кроме параметров сглаживания оптимизировать и начальные значения моделей, то методом простого перебора это сделать уже будет достаточно сложно.
Проблемы, связанные с поиском минимума функций многих переменных хорошо изучены и существует достаточно много различных алгоритмов такого рода. Описание и сравнение разных методов поиска минимума функции можно найти в литературе [7]. Все эти методы в первую очередь направлены на уменьшение количества обращений к целевой функции, то есть на снижение вычислительных затрат в процессе поиска минимума.
Часто в различной литературе можно встретить упоминание о так называемых квазиньютоновских методах оптимизации. Скорее всего, это связано с высокой их эффективностью, но для демонстрации подхода к оптимизации процесса прогнозирования достаточно будет реализовать какой-нибудь более простой метод. Остановим свой выбор на методе Пауэлла. Метод Пауэлла не требует вычисления производных целевой функции и относится к методам поиска.
Программно данный метод, впрочем, как и любой другой, может быть реализован по-разному. Окончание поиска может осуществляться при достижении определенной точности по значению целевой функции или по значению аргумента. Кроме того, конкретная реализация может включать в себя возможность использования ограничений на допустимый диапазон изменения параметров функции.
В нашем случае алгоритм безусловного поиска минимума методом Пауэлла реализован в виде класса PowellsMethod. Алгоритм прекращает поиск при достижении заданной точности по значению целевой функции. В качестве прототипа при реализации данного метода был использован алгоритм, приведенный в литературе [8].
Ниже приведен исходный код класса PowellsMethod.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #include <Object.mqh> #define GOLD 1.618034 #define CGOLD 0.3819660 #define GLIMIT 100.0 #define SHFT(a,b,c,d) (a)=(b);(b)=(c);(c)=(d); #define SIGN(a,b) ((b) >= 0.0 ? fabs(a) : -fabs(a)) #define FMAX(a,b) (a>b?a:b) class PowellsMethod:public CObject { protected: double P[],Xi[]; double Pcom[],Xicom[],Xt[]; double Pt[],Ptt[],Xit[]; int N; double Fret; int Iter; int ItMaxPowell; double FtolPowell; int ItMaxBrent; double FtolBrent; int MaxIterFlag; public: void PowellsMethod(void); void SetItMaxPowell(int n) { ItMaxPowell=n; } void SetFtolPowell(double er) { FtolPowell=er; } void SetItMaxBrent(int n) { ItMaxBrent=n; } void SetFtolBrent(double er) { FtolBrent=er; } int Optimize(double &p[],int n=0); double GetFret(void) { return(Fret); } int GetIter(void) { return(Iter); } private: void powell(void); void linmin(void); void mnbrak(double &ax,double &bx,double &cx,double &fa,double &fb,double &fc); double brent(double ax,double bx,double cx,double &xmin); double f1dim(double x); virtual double func(const double &p[]) { return(0); } }; void PowellsMethod::PowellsMethod(void) { ItMaxPowell= 200; FtolPowell = 1e-6; ItMaxBrent = 200; FtolBrent = 1e-4; } void PowellsMethod::powell(void) { int i,j,m,n,ibig; double del,fp,fptt,t; n=N; Fret=func(P); for(j=0;j<n;j++)Pt[j]=P[j]; for(Iter=1;;Iter++) { fp=Fret; ibig=0; del=0.0; for(i=0;i<n;i++) { for(j=0;j<n;j++)Xit[j]=Xi[j+n*i]; fptt=Fret; linmin(); if(fabs(fptt-Fret)>del){del=fabs(fptt-Fret); ibig=i;} } if(2.0*fabs(fp-Fret)<=FtolPowell*(fabs(fp)+fabs(Fret)+1e-25))return; if(Iter>=ItMaxPowell) { Print("powell exceeding maximum iterations!"); MaxIterFlag=1; return; } for(j=0;j<n;j++){Ptt[j]=2.0*P[j]-Pt[j]; Xit[j]=P[j]-Pt[j]; Pt[j]=P[j];} fptt=func(Ptt); if(fptt<fp) { t=2.0*(fp-2.0*(Fret)+fptt)*(fp-Fret-del)*(fp-Fret-del)-del*(fp-fptt)*(fp-fptt); if(t<0.0) { linmin(); for(j=0;j<n;j++){m=j+n*(n-1); Xi[j+n*ibig]=Xi[m]; Xi[m]=Xit[j];} } } } } void PowellsMethod::linmin(void) { int j,n; double xx,xmin,fx,fb,fa,bx,ax; n=N; for(j=0;j<n;j++){Pcom[j]=P[j]; Xicom[j]=Xit[j];} ax=0.0; xx=1.0; mnbrak(ax,xx,bx,fa,fx,fb); Fret=brent(ax,xx,bx,xmin); for(j=0;j<n;j++){Xit[j]*=xmin; P[j]+=Xit[j];} } void PowellsMethod::mnbrak(double &ax,double &bx,double &cx, double &fa,double &fb,double &fc) { double ulim,u,r,q,fu,dum; fa=f1dim(ax); fb=f1dim(bx); if(fb>fa) { SHFT(dum,ax,bx,dum) SHFT(dum,fb,fa,dum) } cx=bx+GOLD*(bx-ax); fc=f1dim(cx); while(fb>fc) { r=(bx-ax)*(fb-fc); q=(bx-cx)*(fb-fa); u=bx-((bx-cx)*q-(bx-ax)*r)/(2.0*SIGN(FMAX(fabs(q-r),1e-20),q-r)); ulim=bx+GLIMIT*(cx-bx); if((bx-u)*(u-cx)>0.0) { fu=f1dim(u); if(fu<fc){ax=bx; bx=u; fa=fb; fb=fu; return;} else if(fu>fb){cx=u; fc=fu; return;} u=cx+GOLD*(cx-bx); fu=f1dim(u); } else if((cx-u)*(u-ulim)>0.0) { fu=f1dim(u); if(fu<fc) { SHFT(bx,cx,u,cx+GOLD*(cx-bx)) SHFT(fb,fc,fu,f1dim(u)) } } else if((u-ulim)*(ulim-cx)>=0.0){u=ulim; fu=f1dim(u);} else {u=cx+GOLD*(cx-bx); fu=f1dim(u);} SHFT(ax,bx,cx,u) SHFT(fa,fb,fc,fu) } } double PowellsMethod::brent(double ax,double bx,double cx,double &xmin) { int iter; double a,b,d,e,etemp,fu,fv,fw,fx,p,q,r,tol1,tol2,u,v,w,x,xm; a=(ax<cx?ax:cx); b=(ax>cx?ax:cx); d=0.0; e=0.0; x=w=v=bx; fw=fv=fx=f1dim(x); for(iter=1;iter<=ItMaxBrent;iter++) { xm=0.5*(a+b); tol2=2.0*(tol1=FtolBrent*fabs(x)+2e-19); if(fabs(x-xm)<=(tol2-0.5*(b-a))){xmin=x; return(fx);} if(fabs(e)>tol1) { r=(x-w)*(fx-fv); q=(x-v)*(fx-fw); p=(x-v)*q-(x-w)*r; q=2.0*(q-r); if(q>0.0)p=-p; q=fabs(q); etemp=e; e=d; if(fabs(p)>=fabs(0.5*q*etemp)||p<=q*(a-x)||p>=q*(b-x)) d=CGOLD*(e=(x>=xm?a-x:b-x)); else {d=p/q; u=x+d; if(u-a<tol2||b-u<tol2)d=SIGN(tol1,xm-x);} } else d=CGOLD*(e=(x>=xm?a-x:b-x)); u=(fabs(d)>=tol1?x+d:x+SIGN(tol1,d)); fu=f1dim(u); if(fu<=fx) { if(u>=x)a=x; else b=x; SHFT(v,w,x,u) SHFT(fv,fw,fx,fu) } else { if(u<x)a=u; else b=u; if(fu<=fw||w==x){v=w; w=u; fv=fw; fw=fu;} else if(fu<=fv||v==x||v==w){v=u; fv=fu;} } } Print("Too many iterations in brent"); MaxIterFlag=1; xmin=x; return(fx); } double PowellsMethod::f1dim(double x) { int j; double f; for(j=0;j<N;j++) Xt[j]=Pcom[j]+x*Xicom[j]; f=func(Xt); return(f); } int PowellsMethod::Optimize(double &p[],int n=0) { int i,j,k,ret; k=ArraySize(p); if(n==0)N=k; else N=n; if(N<1||N>k)return(0); ArrayResize(P,N); ArrayResize(Xi,N*N); ArrayResize(Pcom,N); ArrayResize(Xicom,N); ArrayResize(Xt,N); ArrayResize(Pt,N); ArrayResize(Ptt,N); ArrayResize(Xit,N); for(i=0;i<N;i++)for(j=0;j<N;j++)Xi[i+N*j]=(i==j?1.0:0.0); for(i=0;i<N;i++)P[i]=p[i]; MaxIterFlag=0; powell(); for(i=0;i<N;i++)p[i]=P[i]; if(MaxIterFlag==1)ret=-1; else ret=Iter; return(ret); }
Основным методом класса является метод Optimize.
Метод Optimize
Входные параметры :
- double &p[] — массив, содержащий на входе начальные величины параметров, оптимальное значение которых должно быть найдено, на выходе массив содержит найденные оптимальные значения этих параметров.
- int n=0 — количество аргументов в массиве p[]. При n=0 количество параметров считается равным размеру массива p[].
Возвращаемое значение:
- Возвращает количество итераций, которое потребовалось для работы алгоритма, или -1 если было достигнуто максимально
допустимое их количество.
В процессе поиска оптимальных значений параметров происходит итеративное приближение к точке минимума целевой функции. Метод Optimize возвращает количество итераций, понадобившихся для достижения минимума функции с заданной точностью. На каждой итерации происходит несколько обращений к целевой функции, то есть количество вызовов целевой функции может значительно (в десятки, а то и в сотни раз) превышать количество итераций, возвращаемое методом Optimize.
Другие методы класса.
Метод SetItMaxPowell
Входные параметры:
- Int n — максимально допустимое для метода Пауэлла количество итераций. Значение по умолчанию 200.
Возвращаемое значение:
- Нет.
Задается максимально допустимое количество итераций, при достижении которого поиск будет прекращен независимо от того, удалось или нет обнаружить с заданной точностью минимум целевой функции. При этом в журнал будет выведено соответствующее сообщение.
Метод SetFtolPowell
Входные параметры:
- double er — точность. Величина отклонения от значения минимума целевой функции, при достижении которой метод Пауэлла прекращает поиск. Значение по умолчанию 1e-6.
Возвращаемое значение:
- Нет.
Метод SetItMaxBrent
Входные параметры:
- Int n — максимально допустимое количество итераций для вспомогательного метода Брента. Значение по умолчанию 200.
Возвращаемое значение:
- Нет.
Задается максимально допустимое количество итераций. При его достижении вспомогательный метод Брента прекратит поиск и в журнал будет выведено соответствующее сообщение.
Метод SetFtolBrent
Входные параметры:
- double er – точность. Величина, определяющая точность при поиске минимума для вспомогательного метода Брента. Значение по умолчанию 1e-4.
Возвращаемое значение:
- Нет.
Метод GetFret
Входные параметры:
- Нет.
Возвращаемое значение:
- Возвращает найденное минимальное значение целевой функции.
Метод GetIter
Входные параметры:
- Нет.
Возвращаемое значение:
- Возвращает количество итераций, которое потребовалось для работы алгоритма.
Виртуальная функция func(const double &p[])
Входные параметры:
- const double &p[] – адрес массива содержащего
оптимизируемые параметры. Размер массива соответствует количеству параметров функции.
Возвращаемое значение:
- Возвращает значение функции
соответствующее переданным ей параметрам.
Виртуальначя
функция func() в каждом конкретном случае должна быть переопределена в
производном от PowellsMethod классе. Функция func()
является целевой функцией, для которой при обращении к алгоритму поиска будут
найдены ее аргументы, соответствующие минимальному возвращаемому функцией
значению.
В данной реализации метода Пауэлла для определения направления поиска по каждому из параметров используется одномерный метод параболической интерполяции Брента. Точность и максимально допустимое количество итераций для этих методов можно задавать раздельно при помощи обращения к SetItMaxPowell, SetFtolPowell, SetItMaxBrent и SetFtolBrent.
Таким образом можно изменить принятые по умолчанию характеристики алгоритма. Это может понадобиться в случае, если, например, для конкретной целевой функции, установленная по умолчанию точность оказалась завышенной и в процессе поиска алгоритму требуется слишком большое количество итераций. Изменением значения требуемой точности можно оптимизировать процедуру поиска для различных категорий целевых функций.
Несмотря на кажущуюся сложность алгоритма, реализующего метод Пауэлла, использовать его достаточно просто.
Приведем пример. Пусть у нас имеется функция
![]()
и нам необходимо найти величины параметров ![]() и
и ![]() , при которых функция будет иметь наименьшее значение.
, при которых функция будет иметь наименьшее значение.
Создадим скрипт, демонстрирующий способ решения этой задачи.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #include "PowellsMethod.mqh" class PM_Test:public PowellsMethod { public: void PM_Test(void) {} private: virtual double func(const double &p[]); }; double PM_Test::func(const double &p[]) { double f,r1,r2; r1=p[0]-0.5; r2=p[1]-6.0; f=r1*r1*4.0+r2*r2; return(f); } void OnStart() { int it; double p[2]; p[0]=8; p[1]=9; PM_Test *pm = new PM_Test; it=pm.Optimize(p); Print("Iter= ",it," Fret= ",pm.GetFret()); Print("p[0]= ",p[0]," p[1]= ",p[1]); delete pm; }
При написании скрипта в первую очередь была создана
как член класса PM_Test
функция func(), которая по переданным ей величинам параметров p[0] и p[1] вычисляет значение заданной тестовой функции. Далее в теле функции OnStart() искомым параметрам присваиваются начальные значения. С этих значений будет начат поиск.
Далее
создается экземпляр класса PM_Test и обращением к методу Optimize производится
запуск процесса поиска искомых величин p[0] и p[1], при этом методы родительского
класса PowellsMethod будут обращаться к переопределенной нами функции func(). По завершении поиска в журнал будет выведено количество произведенных итераций, значение функции в точке найденного минимума и найденные значения параметров p[0]=0.5 и p[1]=6.
Файл PowellsMethod.mqh и тестовый пример PM_Test.mq5 размещены в конце статьи в архиве Files.zip. Для того чтобы откомпилировать PM_Test.mq5, необходимо, чтобы он был расположен в том же каталоге, что и файл PowellsMethod.mqh.
9. Оптимизация значений параметров модели
В предыдущем разделе была представлена реализация метода поиска минимума функции и приведен простой пример ее использования. Теперь перейдем к рассмотрению вопросов, связанных с оптимизацией параметров непосредственно самой модели экспоненциального сглаживания.
Для начала максимально упростим представленный ранее класс AdditiveES, исключив из него все элементы, связанные с учетом сезонной компоненты, так как далее в статье все равно не предполагается рассматривать модели, учитывающие сезонность. Это позволит исходный код класса сделать более легким для восприятия и сократить количество вычислений. Кроме того, так же исключим все вычисления связанные с прогнозированием и расчетом доверительных интервалов прогноза, так легче продемонстрировать подход к оптимизации параметров используемой модели линейного роста с демпфированием.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #include "PowellsMethod.mqh" class OptimizeES:public PowellsMethod { protected: double Dat[]; int Dlen; double Par[5]; int NCalc; public: void OptimizeES(void) {} int Calc(string fname); private: int readCSV(string fnam,double &dat[]); virtual double func(const double &p[]); }; int OptimizeES::Calc(string fname) { int i,it; double relmae,naiv,s,t,alp,gam,phi,e,ae,pt; if(readCSV(fname,Dat)<0){Print("Error."); return(-1);} Dlen=ArraySize(Dat); NCalc=200; if(NCalc<0||NCalc>Dlen-1){Print("Error."); return(-1);} Par[0]=Dat[Dlen-NCalc]; Par[1]=0; Par[2]=0.5; Par[3]=0.5; Par[4]=0.5; it=Optimize(Par); s=Par[0]; t=Par[1]; alp=Par[2]; gam=Par[3]; phi=Par[4]; relmae=0; naiv=0; for(i=Dlen-NCalc;i<Dlen;i++) { e=Dat[i]-(s+phi*t); relmae+=MathAbs(e); naiv+=MathAbs(Dat[i]-Dat[i-1]); ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } relmae/=naiv; PrintFormat("%s: N=%i, RelMAE=%.3f",fname,NCalc,relmae); PrintFormat("Iter= %i, Fmin= %e",it,GetFret()); PrintFormat("p[0]= %.5f, p[1]= %.5f, p[2]= %.2f, p[3]= %.2f, p[4]= %.2f", Par[0],Par[1],Par[2],Par[3],Par[4]); return(0); } int OptimizeES::readCSV(string fnam,double &dat[]) { int n,asize,fhand; fhand=FileOpen(fnam,FILE_READ|FILE_CSV|FILE_ANSI); if(fhand==INVALID_HANDLE) { Print("FileOpen Error!"); return(-1); } asize=512; ArrayResize(dat,asize); n=0; while(FileIsEnding(fhand)!=true) { dat[n++]=FileReadNumber(fhand); if(n+128>asize) { asize+=128; ArrayResize(dat,asize); } } FileClose(fhand); ArrayResize(dat,n-1); return(0); } double OptimizeES::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,sse,ae,pt; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95;} else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} sse=0; for(i=Dlen-NCalc;i<Dlen;i++) { e=Dat[i]-(s+phi*t); sse+=e*e; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } return(NCalc*MathLog(k1*k2*k3*sse)); }
Класс OptimizeES создан как производный от класса PowellsMethod и в него включено переопределение виртуальной функция func(). Как уже ранее упоминалось, на вход этой функции должны передаваться параметры, для которых вычисляется значение, величина которого будет минимизироваться в процессе оптимизации.
В соответствии с методом максимального правдоподобия в функции func() вычисляется логарифм суммы квадрата ошибок предсказания на один шаг вперед. Вычисление ошибок производится в цикле для NCalc последних значений последовательности.
Для сохранения устойчивости модели нам необходимо ввести ограничения на диапазон изменения ее параметров. Определим этот диапазон для параметров Alpha и Gamma от значения 0.05 до 0.95, а для параметра Phi от 0.05 до 1.0. Но в нашем случае для оптимизации используется метод безусловного поиска минимума, не предусматривающий использования ограничений на значения аргументов целевой функции.
Для того чтобы учесть налагаемые на параметры ограничения и при этом не изменять алгоритм поиска, попытаемся свести задачу поиска минимума функции многих переменных с ограничениями к задаче безусловного поиска минимума. Для этого воспользуемся так называемым методом штрафных функций. Этот метод легко продемонстрировать для одномерного случая.
Предположим, что у нас имеется функция одного аргумента (область определения которой лежит в диапазоне от 2.0 до 3.0) и алгоритм, который в процессе поиска может задавать любые значения параметру этой функции. В этом случае можно поступить следующим образом: если алгоритм поиска передал аргумент, превосходящий максимально допустимое значение, например 3.5, то можно вычислить функцию для аргумента равного 3.0, а затем полученный результат умножить на коэффициент, пропорциональный величине превышения максимального значения, например, k=1+(3.5-3)*200.
Если таким же образом поступить и со значениями аргумента, которые оказались ниже минимально возможного, то нам гарантировано возрастание результирующей целевой функции за пределами допустимого диапазона изменений ее аргумента. Такое искусственное увеличение возвращаемого значения целевой функции позволяет скрыть от алгоритма, осуществляющего поиск, тот факт, что передаваемый функции аргумент был каким-то образом ограничен, и гарантировать то, что минимум результирующей функции будет располагаться в заданных пределах аргумента. Такой подход легко переносится и на случай функции нескольких переменных.
Осовноым методом класса OptimizeES является метод Calc. При обращении к этому методу производится чтение данных из файла, поиск оптимальных величин параметров модели и для найденных значений параметров вычисляется оценка точности предсказания RelMAE. При этом количество обрабатываемых значений считанной из файла последовательности, задается в переменной NCalc.
Ниже приведен пример скрипта Optimization_Test.mq5, использующего класс OptimizeES.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #include "OptimizeES.mqh" OptimizeES es; void OnStart() { es.Calc("Dataset\USDJPY_M1_1100.TXT"); }
В результате исполнения этого скрипта мы должны получить следующий результат.

Рисунок 6. Результат исполнения скрипта Optimization_Test.mq5
Несмотря на то, что мы получили возможность находить оптимальные значения параметров и начальных значений модели, все же остается один параметр, оптимизировать который простыми средствами не удастся — это количество значений последовательности, по которым производится оптимизация. Производя оптимизацию по последовательности большой длинны, мы будем получать оптимальные значения параметров, в среднем обеспечивающих минимальную ошибку на всей ее длине.
Но если характер последовательности на протяжении этого интервала изменялся, то для отдельных ее фрагментов найденные значения уже не будут являться оптимальными. С другой стороны, если резко сократить длину последовательности, то мы получим оптимальные параметры для этого короткого отрезка, но в этом случае нет никакой гарантии, что эти значения будут оптимальными и на более продолжительном интервале времени.
Файлы OptimizeES.mqh и Optimization_Test.mq5 размещены в конце статьи в архиве Files.zip. При компиляции необходимо, чтобы файлы OptimizeES.mqh и PowellsMethod.mqh были размещены в том же каталоге, что и компилируемый файл Optimization_Test.mq5. В приведенном примере используется содержащий тестовую последовательность файл USDJPY_M1_1100.TXT, который должен находиться в каталоге MQL5FilesDataset.
В таблице 2 приведены значения оценки точности прогнозирования RelMAE, полученные при помощи этого скрипта. Прогнозирование производилось для восьми тестовых последовательностей, о которых говорилось в начале статьи. При построении прогноза использовались 100, 200 и 400 последних значений каждой из этих последовательностей.
| N=100 | N=200 | N=400 | |
|---|---|---|---|
| EURRUR M1 |
0.980 | 1.000 | 0.968 |
| EURRUR M30 |
0.959 | 0.992 | 0.981 |
| EURUSD M1 |
0.995 | 0.981 | 0.981 |
| EURUSD M30 |
1.023 | 0.985 | 0.999 |
| USDJPY M1 |
1.004 | 0.976 | 0.989 |
| USDJPY M30 |
0.993 | 0.987 | 0.988 |
| XAUUSD M1 |
0.976 | 0.993 | 0.970 |
| XAUUSD M30 |
0.973 | 0.985 | 0.999 |
Таблица 2. Ошибки прогнозирования RelMAE.
Как видим, оценки величины ошибок прогноза оказались близкими к единице, но в большинстве случаев точность прогноза используемой модели для заданных последовательностей превышает точность наивного метода.
10. Индикатор IndicatorES.mq5
Ранее при рассмотрении класса AdditiveES.mqh был приведен индикатор AdditiveES_Test.mq5, построенный на базе этого класса. В этом индикаторе все параметры сглаживания задавались вручную.
Теперь после рассмотрения метода, позволяющего производить оптимизацию параметров модели, можно создать такой же индикатор, оптимальные значения параметров и начальных значений которого будут определяться автоматически, задавать вручную нужно будет только длину обрабатываемой выборки. При этом исключим вычисления связанные с учетом сезонности.
Ниже приведен исходный код класса CIndiсatorES который используется при написании индикатора.
#property copyright "2011, victorg" #property link "https://www.mql5.com" #include "PowellsMethod.mqh" class CIndicatorES:public PowellsMethod { protected: double Dat[]; int Dlen; double Par[5]; public: void CIndicatorES(void) { } void CalcPar(double &dat[]); double GetPar(int n) { if(n>=0||n<5)return(Par[n]); else return(0); } private: virtual double func(const double &p[]); }; void CIndicatorES::CalcPar(double &dat[]) { Dlen=ArraySize(dat); ArrayResize(Dat,Dlen); ArrayCopy(Dat,dat); Par[0]=Dat[0]; Par[1]=0; Par[2]=0.5; Par[3]=0.5; Par[4]=0.5; Optimize(Par); } double CIndicatorES::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,sse,ae,pt; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95;} else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} sse=0; for(i=0;i<Dlen;i++) { e=Dat[i]-(s+phi*t); sse+=e*e; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } return(Dlen*MathLog(k1*k2*k3*sse)); }
Данный класс содержит методы CalcPar и GetPar, первый из которых предназначен для вычисления оптимального значения параметров модели, а второй для доступа к этим значениям. Кроме того, класс CIndicatorES включает в себя переопределение виртуальной функции func().
Исходный код индикатора IndicatorES.mq5:
#property copyright "2011, victorg" #property link "https://www.mql5.com" #property indicator_chart_window #property indicator_buffers 4 #property indicator_plots 4 #property indicator_label1 "History" #property indicator_type1 DRAW_LINE #property indicator_color1 clrDodgerBlue #property indicator_style1 STYLE_SOLID #property indicator_width1 1 #property indicator_label2 "Forecast" #property indicator_type2 DRAW_LINE #property indicator_color2 clrDarkOrange #property indicator_style2 STYLE_SOLID #property indicator_width2 1 #property indicator_label3 "ConfUp" #property indicator_type3 DRAW_LINE #property indicator_color3 clrCrimson #property indicator_style3 STYLE_DOT #property indicator_width3 1 #property indicator_label4 "ConfDn" #property indicator_type4 DRAW_LINE #property indicator_color4 clrCrimson #property indicator_style4 STYLE_DOT #property indicator_width4 1 input int nHist=80; #include "CIndicatorES.mqh" #define NFORE 12 double Hist[],Fore[],Conf1[],Conf2[]; double Data[]; int NDat; CIndicatorES Es; int OnInit() { NDat=nHist; if(NDat<24)NDat=24; MqlRates rates[]; CopyRates(NULL,0,0,NDat,rates); ArrayResize(Data,NDat); SetIndexBuffer(0,Hist,INDICATOR_DATA); PlotIndexSetString(0,PLOT_LABEL,"History"); SetIndexBuffer(1,Fore,INDICATOR_DATA); PlotIndexSetString(1,PLOT_LABEL,"Forecast"); PlotIndexSetInteger(1,PLOT_SHIFT,NFORE); SetIndexBuffer(2,Conf1,INDICATOR_DATA); PlotIndexSetString(2,PLOT_LABEL,"ConfUp"); PlotIndexSetInteger(2,PLOT_SHIFT,NFORE); SetIndexBuffer(3,Conf2,INDICATOR_DATA); PlotIndexSetString(3,PLOT_LABEL,"ConfDN"); PlotIndexSetInteger(3,PLOT_SHIFT,NFORE); IndicatorSetInteger(INDICATOR_DIGITS,_Digits); return(0); } int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { int i,start; double s,t,alp,gam,phi,e,f,a,a1,a2,a3,var,ci; if(rates_total<NDat){Print("Error: Not enough bars for calculation!"); return(0);} if(prev_calculated==rates_total)return(rates_total); start=rates_total-NDat; PlotIndexSetInteger(0,PLOT_DRAW_BEGIN,rates_total-NDat); PlotIndexSetInteger(1,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(2,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(3,PLOT_DRAW_BEGIN,rates_total-NFORE); for(i=0;i<NDat;i++)Data[i]=open[rates_total-NDat+i]; Es.CalcPar(Data); s=Es.GetPar(0); t=Es.GetPar(1); alp=Es.GetPar(2); gam=Es.GetPar(3); phi=Es.GetPar(4); f=(s+phi*t); var=0; for(i=0;i<NDat;i++) { e=Data[i]-f; var+=e*e; a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); Hist[start+i]=f; } var/=(NDat-1); a1=1; a2=0; a3=1; for(i=rates_total-NFORE;i<rates_total;i++) { a1=a1*phi; a2+=a1; Fore[i]=s+a2*t; ci=1.96*MathSqrt(var*a3); a=alp*(1+a2*gam); a3+=a*a; Conf1[i]=Fore[i]+ci; Conf2[i]=Fore[i]-ci; } return(rates_total); }
В индикаторе при поступлении каждого нового бара происходит поиск оптимальных значений параметров модели, модель просчитывается для заданного числа NHist баров и строится прогноз и доверительные границы прогноза.
Единственным параметром индикатора является длина обрабатываемой последовательности, минимальное значение которой ограничивается на уровне 24 баров. Все расчеты в индикаторе производятся на основании значений open[]. Горизонт прогнозирования составляет 12 баров. Код индикатора IndicatorES.mq5 и файл CIndicatorES.mqh размещены в конце статьи в архиве Files.zip.

Рисунок 7. Результат работы индикатора IndicatorES.mq5
На рисунке 7 приведен пример работы индикатора IndicatorES.mq5. При работе индикатора, 95% доверительный интервал прогноза будет принимать значения, соответствующие найденным оптимальным величинам параметров модели. Чем больше значения параметров сглаживания, тем быстрее при увеличении горизонта прогноза увеличивается доверительный интервал.
При несложной доработке индикатор IndicatorES.mq5 может быть использован не только для прогнозирования непосредственно котировок валют, но и для построения прогноза значений различного рода индикаторов или предварительно подготовленных данных.
Заключение
Основной целью статьи было знакомство читателя с используемыми для прогнозирования аддитивными моделями экспоненциального сглаживания. В процессе демонстрации их практического применения были затронуты и некоторые сопутствующие вопросы. Однако представленные в статье материалы можно рассматривать лишь как первое прикосновение к огромному пласту связанных с прогнозированием проблем и решений.
Хочется обратить внимание на то, что приведенные в статье классы, функции, скрипты и индикаторы были созданы в процессе написания статьи и предназначены в первую очередь для использования в качестве иллюстрации к материалам статьи. Поэтому серьезного тестирования на устойчивость и отсутствие ошибок не производилось. Кроме того, приведенные в статье индикаторы следует рассматривать только как демонстрацию программной реализации рассматриваемых в статье методов.
Скорее всего, точность прогнозирования приведенного в статье индикатора IndicatorES.mq5 можно несколько увеличить, если использовать модификации применяемой модели, которые будут лучше учитывать особенности рассматриваемых котировок. Так же можно дополнить индикатор другими моделями. Но эти вопросы уже выходят за рамки данной статьи.
В завершении следует отметить, что модели экспоненциального сглаживания в определенных случаях в состоянии давать прогнозы, не уступающие по точности прогнозам, полученным при использовании более сложных моделей, при этом лишний раз подтверждая тот факт, что самая сложная модель далеко не всегда является самой лучшей.
Ссылки
- Everette S. Gardner Jr. Exponential smoothing: The state of the art – Part II. June 3, 2005.
- Rob J Hyndman. Forecasting based on state space models for exponential smoothing. 29 August 2002.
- Rob J Hyndman et al. Prediction intervals for exponential smoothing using two new classes of state space models. 30 January 2003.
- Rob J Hyndman and Muhammad Akram. Some nonlinear exponential smoothing models are unstable. 17 January 2006.
- Rob J Hyndman and Anne B Koehler. Another look at measures of forecast accuracy. 2 November 2005.
- Лукашин Ю.П., Адаптивные методы краткосрочного прогнозирования временных рядов: Учебное пособие. — М.: Финансы и статистика, 2003.-416 с.
- Химмельблау Д., Прикладное нелинейное программирование. М.: Мир, 1975.
- Numerical Recipes in C. The Art of Scientific Computing. SecondEdition. Cambridge University Press.
Обновление статьи от 04.07.2019г.
В статье приводится сравнение алгоритмов прогнозирования для решения задачи управления товарными запасами с использованием ошибки прогнозирования RMSE. На текущий момент мы не рекомендуем пользоваться этим методом. О причинах отказа от сравнения с использованием ошибок прогнозирования, читайте в статье Почему мы не считаем MAPE, RMSE и другие математические ошибки при прогнозировании спроса Рекомендуемый способ сравнения – имитационное моделирование.
Метод Экспоненциального сглаживания относится к алгоритмам прогнозирования 1 поколения (либо 2-го поколения при наличии страхового запаса по модельному распределению спроса). Он подходит только для прогнозирования товаров с гладким регулярным спросом, который характерен приблизительно 6% ассортимента типового продуктового супермаркета и не характерен практически ни для каких товаров других отраслей. Поэтому мы рекомендуем прогнозировать товарные запасы, а не спрос.
Подробнее о поколениях алгоритмов прогнозирования в видео «Эволюция алгоритмов прогнозирования спроса»
Также рекомендуем прочитать статью «Почему нужно прогнозировать товарные запасы, а не спрос?»
Насколько Forecast NOW! лучше модели Экспоненциального сглаживания (ES) вы можете увидеть на графике ниже. По оси X — номер товара, по оси Y — процентное улучшение качества прогноза. Описание модели, детальное исследование, результаты экспериментов читайте ниже.

Описание модели
Прогнозирование методом экспоненциального сглаживания является одним из самых простых способов прогнозирования. Прогноз может быть получен только на один период вперед. Если прогнозирование ведется в разрезе дней, то только на один день вперед, если недель, то на одну неделю.
Для сравнения прогнозирование проводилось на неделю вперед в течение 8 недель.
Что такое экспоненциально сглаживание?
Пусть ряд С представляет исходный ряд продаж для прогнозирования
С(1)– продажи в первую неделю, С(2) во второй и так далее.

Рисунок 1. Продажи по неделям, ряд С
Аналогично, ряд S представляет собой экспоненциально сглаженный ряд продаж. Коэффициент α находится от нуля до единицы. Получается он следующим образом, здесь t – момент времени (день, неделя)
S (t+1) = S(t) + α *(С(t) – S(t))
Большие значения константы сглаживания α ускоряют отклик прогноза на скачок наблюдаемого процесса, но могут привести к непредсказуемым выбросам, потому что сглаживание будет почти отсутствовать.
Первый раз после начала наблюдений, располагая лишь одним результатом наблюдений С (1), когда прогноза S(1) нет и формулой (1) воспользоваться еще невозможно, в качестве прогноза S(2) следует взять С (1).
Формула легко может быть переписана в ином виде:
S(t+1) = (1 – α)* S(t) + α * С(t).
Таким образом, с увеличением константы сглаживания доля последних продаж увеличивается, а доля сглаженных предыдущих уменьшается.
Константа α выбирается опытным путем. Обычно строится несколько прогнозов для разных констант и выбирается наиболее оптимальная константа с точки зрения выбранного критерия.
Критерием может выступать точность прогнозирования на предыдущие периоды.
В своем исследовании мы рассмотрели модели экспоненциального сглаживания, в которых α принимает значения {0.2, 0.4, 0.6, 0.8}. Для сравнения с алгоритмом прогнозирования Forecast NOW! для каждого товара строились прогнозы при каждом α, выбирался наиболее точный прогноз. В действительности же, ситуация обстояла бы гораздо более сложная, пользователю не зная наперед точности прогноза нужно определиться с коэффициентом α, от которого очень сильно зависит качество прогноза. Вот такой замкнутый круг.
Наглядно

Рисунок 2. α =0.2 , степень экспоненциального сглаживания высокая, реальные продажи учитываются слабо

Рисунок 3. α =0.4 , степень экспоненциального сглаживания средняя, реальные продажи учитываются в средней степени
Можно видеть как с увеличением константы α сглаженный ряд все сильнее соответствует реальным продажам, и если там присутствуют выбросы или аномалии, мы получим крайне неточный прогноз.

Рисунок 4. α =0.6 , степень экспоненциального сглаживания низкая, реальные продажи учитываются значительно
Можем видеть, что при α=0.8 ряд почти в точности повторяет исходный, а значит прогноз стремится к правилу «будет продано столько же, сколько и вчера»
Стоит отметить, что здесь совершенно нельзя ориентироваться на ошибку приближения к исходным данным. Можно добиться идеального соответствия, но получить неприемлемый прогноз.

Рисунок 5. α =0.8 , степень экспоненциального сглаживания крайне низкая, реальные продажи учитываются сильно
Примеры прогнозов
Теперь давайте посмотрим на прогнозы, которые получаются с использованием различных значений α. Как можно видеть из рисунка 6 и 7, чем больше коэффициент сглаживания, тем точнее повторяет реальные продажи с опозданием на один шаг, прогноз. Такое опоздание на деле может оказаться критичным, поэтому нельзя просто выбирать максимальное значение α. Иначе получится ситуация, когда мы говорим, что будет продано ровно столько, сколько было продано в прошлый период.

Рисунок 6. Прогноз метода экспоненциального сглаживания при α=0.2

Рисунок 7. Прогноз метода экспоненциального сглаживания при α=0.6
Давайте посмотрим, что получается при α = 1.0. Напомним, S – прогнозируемые (сглаженные) продажи, C – реальные продажи.
S(t+1) = (1 – α)* S(t) + α * С(t).
S(t+1) = С(t).
Продажи в t+1 день согласно прогнозу равны продажам в предыдущий день. Поэтому к выбору константы надо подходить с умом.
Сравнение с Forecast NOW!
Теперь рассмотрим данный метод прогнозирования в сравнении с Forecast NOW!. Сравнение велось на 256 товарах, которые имеют различные продажи, с сезонностью краткосрочной и долгосрочной, с «плохими» продажами и дефицитом, акциями и прочими выбросами. Для каждого товара был построен прогноз по модели экспоненциального сглаживания, для различных α, выбирался лучший и сравнивался с прогнозом по модели Forecast NOW!
В таблице ниже вы видите значение ошибки прогноза для каждого товара. Ошибка здесь считалась как RMSE. Это корень из среднеквадратичного отклонения прогноза от реальности. Грубо говоря, показывает, на сколько единиц товара мы отклонились в прогнозе. Улучшение показывает, на сколько процентов прогноз Forecast NOW! лучше, если цифра положительная, и хуже, если отрицательная. На рисунке 8 по оси X отложены товары, по оси Y указано насколько прогноз Forecast NOW! лучше, чем прогнозирование методом экспоненциального сглаживания. Как можно видеть из этого графика, точность прогнозирования Forecast NOW! почти всегда в два раза выше и почти никогда не хуже. На деле это означает, что использование Forecast NOW! позволит в два раза сократить запасы или снизить дефицит.
Рисунок 8. Сравнение точности прогнозирования Forecast NOW! и метода экспоненциального сглаживания
Таким образом, можно сделать вывод, что прогнозирование с использованием простой модели экспоненциального сглаживания дает результаты гораздо хуже, нежели Forecast NOW!
Вы можете ознакомиться с результатами прогнозирования по каждому товару. Таблицы приведены в сокращенном варианте, для ознакомления с полным вариантом, напишите нам info@forecastnow.ru, мы вам вышлем подробные результаты.

Таблица 1. Сравнение ошибок прогнозирования Forecast NOW! и экспоненциального сглаживания (в сокращении)

Таблица 2. Ошибки прогнозирования эксп. сглаживания с различными значениями коэффициента α (в сокращении)
Обзор других методов:
- Метод Хольта-Винтерса (1-2 поколение);
- Простая Скользящая средняя (SMA, Simple Moving Average) (1-2 поколение);
- Авторегрессия (1-2 поколение);
- Вероятностное прогнозирование (4 поколение)
Метод экспоненциального сглаживания
Предмет
Товароведение
Разместил
🤓 arsenij.gusev.98
👍 Проверено Автор24
метод прогнозирования потребности в запасе, в котором каждый новый прогноз основан на учете значения предыдущего прогноза и его отклонения от фактического значения.
Научные статьи на тему «Метод экспоненциального сглаживания»
Временные ряды в эконометрических исследованиях
Для прогнозирования применяются модели экспоненциального сглаживания, модели скользящего среднего, трендовые…
Анализ временных рядов осуществляется совокупностью математических и статистических методов….
Они показывают особенности тренда – постоянный, затухающий, экспоненциальный или падение….
В некоторых случаях применяется экспоненциальное сглаживание, либо сглаживание с трендом или сезонностью…
Трендовые модели опираются на линейные, логарифмические, экспоненциальные расчеты.

Статья от экспертов
Учет ошибки в методе экспоненциального сглаживания
Установлено, что учет ошибки прогноза в методе экспоненциального сглаживания приводит к уменьшению минимума среднего значения квадрата ошибки прогноза.
Аппроксимация табличных функций в Excel
Понятие аппроксимации
Среди разных методик прогнозирования следует отдельно выделить метод аппроксимации…
Название этого метода произошло от латинского слова “proxima”, то есть, «ближайшая»….
Далее рассмотрим экспоненциальный тип аппроксимации в Excel….
В блоке выбора типа аппроксимации необходимо установить переключатель в положение «Экспоненциальная»….
Экспоненциальный тип аппроксимации.
Статья от экспертов
Применение метода экспоненциального сглаживания к задаче обнаружения маневра корабля
В статье предлагается решение задачи обнаружения маневра корабля при помощи метода экспоненциального сглаживания. Приводится пример решения задачи обнаружения маневра и результаты численного эксперимента. Результаты могут применяться при проектировании систем обеспечения безопасности плавания.
Еще термины по предмету «Товароведение»
Анализ Мак Кинси «7S» (McKinsey analysis)
оценка внутренней среды компании, работающей на рынке: 1.стратегии компании, 2. конкурентные преимущества, 3. цели и ценностные установки, 4. кадровый состав, 5. стиль деятельности фирмы, 6. организационная и функциональная структура, 7. различные процессы, протекающие в ней (управление, производство, сбыт, движение информационных потоков).
Бренд, расширение
использование имени бренда для нового товара, выходящего на смежный целевой сегмент.
Спрос зависимый
спрос, который имеет место при наличии обусловленности закупок, производственного процесса или процесса потребления технологического или иного характера.
-
Экспоненциальное сглаживание
-
Метод сглаживания
-
Сглаживание
-
Экспоненциальная функция
-
Экспоненциальное распределение
-
Экспоненциальный ряд
-
Механическое сглаживание
-
Система сглаживания волн давления
-
Коэффициент сглаживания пульсаций интегральной микросхемы
-
Метод А-В-С
-
Методы
-
Метод
-
Психофизические методы (сенсометрические методы)
-
Гаусса метод (исключения метод)
-
Ньютона метод (касательных метод)
-
Агротехнические метод
-
Биологический метод
-
Метод нормирования
-
Расчетный метод
-
Аналитические методы
Смотреть больше терминов
Повышай знания с онлайн-тренажером от Автор24!
- Напиши термин
- Выбери определение из предложенных или загрузи свое
-
Тренажер от Автор24 поможет тебе выучить термины с помощью удобных и приятных
карточек
Задачи прогнозирования построены на изменении неких данных во времени (продаж, спроса, поставок, ВВП, выбросов углерода, численности населения…) и проецировании этих изменений на будущее. К сожалению, выявленные на исторических данных, тренды могут нарушаться множеством непредвиденных обстоятельств. Так что данные в будущем могут существенно отличаться от произошедшего в прошлом. [1] В этом и состоит проблема прогнозирования.
Однако, существуют методики (под названием экспоненциальное сглаживание), позволяющие не только попытаться предсказать будущее, но и выразить численно неопределенность всего, что связано с прогнозом. Численное выражение неопределенности с помощью создания интервалов прогнозирования поистине неоценимо, но часто игнорируется в прогностическом мире.

Рис. 1. Временной ряд данных
Скачать заметку в формате Word или pdf, примеры в формате Excel
Исходные данные
Допустим, вы фанат «Властелина Колец», и вот уже три года изготавливаете и торгуете мечами (рис. 1). Отобразим продажи графически (рис. 2). За три года спрос удвоился — может быть, это тренд? Мы вернемся к этой мысли чуть позже. На графике есть несколько пиков и спадов, что может быть признаком сезонности. В частности, пики приходятся на месяцы с номерами 12, 24 и 36, которые оказываются декабрями. Но может быть это лишь случайность? Давайте выясним.

Рис. 2. Диаграмма временного ряда данных
Простое экспоненциальное сглаживание
Методы экспоненциального сглаживания основываются на прогнозировании будущего по данным из прошлого, где более новые наблюдения весят больше, чем старые. Такое взвешивание возможно благодаря константам сглаживания. Первый метод экспоненциального сглаживания, который мы опробуем, называется простым экспоненциальным сглаживанием (ПЭС, simple exponential smoothing, SES). Он использует лишь одну константу сглаживания.
При простом экспоненциальном сглаживании предполагается, что ваш временной ряд данных состоит из двух компонентов: уровня (или среднего) и некоей погрешности вокруг этого значения. Нет никакого тренда или сезонных колебаний — есть просто уровень, вокруг которого колеблется спрос, тут и там окруженный небольшими погрешностями. Отдавая предпочтение более новым наблюдениям, ПЭС может явиться причиной сдвигов этого уровня. Говоря языком формул,
Спрос в момент времени t = уровень + случайная погрешность около уровня в момент времени t
Так как же найти приблизительное значение уровня? Если принять все временные значения как имеющие одинаковую ценность, то следует просто вычислить их среднее значение. Однако, это плохая идея. Следует дать больший вес недавним наблюдениям.
Создадим несколько уровней. Рассчитаем исходный уровень в первый год:
уровень0 = среднее значение спроса за первый год (месяцы 1-12)
Для спроса на мечи он равен 163. Мы используем уровень0 (163) как прогноз спроса на месяц 1. Спрос в месяц1 равен 165, то есть он на 2 меча выше уровня0. Стоит обновить приближение исходного уровня. Уравнение простого экспоненциального сглаживания:
уровень1 = уровень0 + несколько процентов × (спрос1 – уровень0)
уровень2 = уровень1 + несколько процентов × (спрос2 – уровень1)
И т.д. «Несколько процентов» — называется константой сглаживания, и обозначается альфой. Это может быть любое число от 0 до 100% (от 0 до 1). Выбирать значение альфы вы научитесь позже. В общем случае значение для разных моментов времени:
Уровеньтекущий период = уровеньпредыдущий период +
альфа × (спрос текущий период – уровень предыдущий период)
Будущий спрос равен последнему вычисленному уровню (рис. 3). Поскольку вы не знаете, чему равна альфа, установите для начала в ячейке С2 значение 0,5. После того, как модель будет построена, найдите такую альфа, чтобы сумма квадратов ошибки – Е2 (или стандартное отклонение – F2) были минимальны. Для этого запустите опцию Поиск решения. Для этого пройдите по меню ДАННЫЕ –> Поиск решения, и установите в окне Параметры поиска решения требуемые значения (рис. 4). Чтобы отразить результаты прогноза на диаграмме, для начала выберите диапазон А6:В41, и постройте простую линейную диаграмму. Далее кликните на диаграмме правой кнопкой мыши, выберите опцию Выбрать данные. В открывшемся окне создайте второй ряд и вставьте в него предсказания из диапазона А42:В53 (рис. 5).

Рис. 3. Простое экспоненциальное сглаживание

Рис. 4. Параметры поиска решения

Рис. 5. Диаграмма прогноза простого экспоненциального сглаживания
Возможно, у вас есть тренд
Чтобы проверить это предположение достаточно подогнать линейную регрессию под данные спроса и выполнить тест на соответствие критерию Стьюдента на подъеме этой линии тренда (как в главе 6). Если уклон линии ненулевой и статистически значимый (в проверке по критерию Стьюдента величина р менее 0,05), у данных есть тренд (рис. 6).

Рис. 6. Тест Стьюдента показывает наличие тренда
Мы воспользовались функцией ЛИНЕЙН, которая возвращает 10 описательных статистик (если вы ранее не пользовались этой функцией, рекомендую Функция массива ЛИНЕЙН) и функцией ИНДЕКС, которая позволяет «вытащить» только три требуемые статистики, а не весь набор. Получилось, что наклон равен 2,54, и он значим, так как тест Стьюдента показал, 0,000000012 существенно меньше 0,05. Итак, тренд есть, и осталось включить его в прогноз.
Экспоненциальное сглаживание Холта с корректировкой тренда
Часто оно называется двойным экспоненциальным сглаживанием, потому что имеет не один параметр сглаживания — альфа, а два. Если у временной последовательности линейный тренд, то:
спрос за время t = уровень + t × тренд + случайное отклонение уровня в момент времени t
Экспоненциальное сглаживание Холта с корректировкой тренда имеет два новых уравнения, одно — для уровня по мере его продвижения во времени, а другое — тренд. Уравнение уровня содержит сглаживающий параметр альфа, а уравнение тренда – гамма. Вот как выглядит новое уравнение уровня:
уровень1 = уровень0 + тренд0 + альфа × (спрос1 – (уровень0 + тренд0))
Обратите внимание, что уровень0 + тренд0 — это просто одношаговый прогноз от исходных значений к месяцу 1, поэтому спрос1 – (уровень0 + тренд0) — это одношаговое отклонение. Таким образом, основное уравнение приближения уровня будет следующим:
уровеньтекущий период = уровеньпредыдущий период + трендпредыдущий период + альфа × (спростекущий период – (уровень предыдущий период) + трендпредыдущий период))
Уравнение обновления тренда:
трендтекущий период = трендпредыдущий период + гамма × альфа × (спростекущий период – (уровень предыдущий период) + трендпредыдущий период))
Холтовское сглаживание в Excel аналогично простому сглаживанию (рис. 7), и, как и выше, цель – найти два коэффициента, минимизируя сумму квадратов ошибок (рис. 8). Чтобы получить исходные значения уровня и тренда (в ячейках С5 и D5 на рис. 7), постройте график за первые 18 месяцев продаж и добавьте к нему линию тренда с уравнением. Исходное значение тренда 0,8369 и исходный уровень 155,88 занесите в ячейки С5 и D5. Прогнозные данные можно представить графически (рис. 9).

Рис. 7. Экспоненциальное сглаживание Холта с корректировкой тренда; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке

Рис. 8. Параметры поиска решения для экспоненциального сглаживания Холта

Рис. 9. Диаграмма прогноза холтовского экспоненциального сглаживания
Выявление закономерностей в данных
Есть способ испытать прогностическую модель на прочность — сравнить погрешности сами с собой, сдвинутыми на шаг (или несколько шагов). Если отклонения случайны, то улучшить модель нельзя. Однако, возможно, в данных о спросе есть сезонный фактор. Концепция погрешности, коррелирующей с собственной версией за другой период, называется автокорреляцией (подробнее об автокорреляции см. Простая линейная регрессия). Чтобы рассчитать автокорреляцию, начните с данных об ошибке прогноза за каждый период (столбец F на рис. 7 переносим в столбец В на рис. 10). Далее определите среднюю ошибку прогноза (рис. 10, ячейка В39; формула в ячейке: =СРЗНАЧ(B3:B38)). В столбце С рассчитайте отклонение ошибки прогноза от среднего; формула в ячейке С3: =B3-B$39. Далее последовательно сдвигайте столбец С на столбец вправо и строку вниз. Формулы в ячейках D39: =СУММПРОИЗВ($C3:$C38;D3:D38), D41: =D39/$C39, D42: =2/КОРЕНЬ(36), D43: =-2/КОРЕНЬ(36).

Рис. 10. Расчет автокорреляции
Что может значить для одного из столбцов D:O «синхронное движение» со столбцом С. Например, если столбцы С и D синхронны, то число, отрицательное в одном из них, должно быть отрицательным и в другом, положительное в одном, положительное – в другом. Это означает, что сумма произведений двух столбцов будет значительной (отличия накапливаются). Или, что тоже самое, чем ближе значение в диапазоне D41:О41 к нулю, тем ниже корреляция столбца (соответственно от D до О) со столбцом С (рис. 11).

Рис. 11. Диаграмма автокорреляции
Одна автокорреляция выше критического значения. Погрешность, сдвинутая на год, коррелирует сама с собой. Это означает 12-месячный сезонный цикл. И это неудивительно. Если вы посмотрите на график спроса (рис. 2), то окажется, что есть пики спроса на каждое Рождество и провалы в апреле-мае. Рассмотрим технику прогнозирования, учитывающую сезонность.
Мультипликативное экспоненциальное сглаживание Холта-Винтерса
Метод называется мультипликативным (от multiplicate — умножать), поскольку использует умножение для учета сезонности:
Спрос в момент t = (уровень + t × тренд) × сезонная поправка для момента t × все оставшиеся нерегулярные поправки, которые мы не можем учесть
Сглаживание Холта-Винтерса также называют тройным экспоненциальным сглаживанием, потому что у него три сглаживающих параметра (альфа, гамма и сезонный фактор – дельта). Например, если имеется 12-месячный сезонный цикл:
Прогноз на месяц 39 = (уровень36 + 3 × тренд36) х сезонность27
Анализируя данные, необходимо выяснить, что в серии данных является трендом, а что — сезонностью. Чтобы выполнить вычисления по методу Холта-Винтерса, необходимо:
- Сгладить исторические данные методом скользящего среднего.
- Сравнить сглаженную версию временного ряда данных с оригиналом, чтобы получить приблизительную оценку сезонности.
- Получить новые данные без сезонного компонента.
- Найти приближения уровня и тренда на основе этих новых данных.
Начните с исходных данных (столбцы А и В на рис. 12) и добавьте столбец С со сглаженными значениями на основе скользящего среднего. Так как сезонность имеет 12-месячные циклы, имеет смысл использовать среднее за 12 месяцев. С этим средним есть небольшая проблема. 12 – четное число. Если вы сглаживаете спрос за месяц 7, стоит ли считать его средним спросом с 1-го по 12-й месяц или со 2-го по 13-й? Чтобы справиться с этим затруднением, нужно сгладить спрос с помощью «скользящего среднего 2×12». Т.е., взять половину от двух средних с 1 по 12-й месяц и со 2 по 13. Формула в ячейке С8: =(СРЗНАЧ(B3:B14)+СРЗНАЧ(B2:B13))/2.

Рис. 12. Данные, очищенные от сезонного фактора
Сглаженные данных для месяцев 1–6 и 31–36 получить нельзя, так как не хватает предыдущих и последующих периодов. Для наглядности исходные и сглаженные данные можно отразить на диаграмме (рис. 13).

Рис. 13. Сглаженные данные спроса
Теперь в столбце D разделите оригинальную величину на сглаженную и получите приблизительное значение сезонной поправки (столбец D на рис. 12). Формула в ячейке D8: =B8/C8. Обратите внимание на всплески в 20% выше нормального спроса в месяцах 12 и 24 (декабрь), в то время как весной наблюдаются провалы. Эта техника сглаживания дала вам две точечные оценки для каждого месяца (всего 24 месяца). В столбце Е найдено среднее значение этих двух факторов. Формула в ячейке Е1: =СРЗНАЧ(D14;D26). Для наглядности уровень сезонных колебаний можно представить графически (рис. 14).

Рис. 14. Сезонные колебания
Теперь можно получить данные, скорректированные на сезонные колебания. Формула в ячейке G1: =B2/E2. Постройте график на основе данных столбца G, дополните его линией тренда, выведите уравнение тренда на диаграмму (рис. 15), и используйте коэффициенты в последующих расчетах.

Рис. 15. Данные, скорректированные на сезонные колебания
Сформируйте новый лист, как показано на рис. 16. Значения в диапазон Е5:Е16 подставьте с рис. 12 области Е2:Е13. Значения С16 и D16 возьмите из уравнения линии тренда на рис. 15. Значения констант сглаживания установите для начала на отметке 0,5. Растяните значения в строке 17 на диапазон месяцев с 1 по 36. Запустите Поиск решения для оптимизации коэффициентов сглаживания (рис. 18). Формула в ячейке В53: =(C$52+(A53-A$52)*D$52)*E41.

Рис. 16. Данные для прогноза Холта-Винтера

Рис. 17. График прогноза Холта-Винтерса
Теперь в сделанном прогнозе нужно проверить автокорреляции (рис. 18). Так как все значения расположились между верхней и нижней границами, вы понимаете, что модель неплохо поработала над пониманием структуры значений спроса.

Рис. 18. Коррелограмма модели Холта-Винтерса
Построение доверительного интервала прогноза
Итак, у нас есть вполне рабочий прогноз. Как установить верхние и нижние границы, которые можно использовать для построения реалистичных предположений? В этом вам поможет симуляция Монте-Карло, с которой вы уже встречались в главе 4 (см. также Использование метода Монте-Карло для расчета риска). Смысл заключается в том, чтобы сгенерировать будущие сценарии поведения спроса и определить группу, в которую попадают 95% из них.
Удалите с листа Excel прогноз из ячеек В53:В64 (см. рис. 17). Вы запишете туда спрос на основе симуляции. Последнюю можно сгенерировать с помощью функции НОРМОБР. Для будущих месяцев вам достаточно снабдить ее средним (0), стандартным распределением (10,37 из ячейки $Н$2) и случайным числом от 0 до 1. Функция вернет отклонение с вероятностью, соответствующей колоколообразной кривой. Поместите симуляцию одношаговой погрешности в ячейку G53: =НОРМОБР(СЛЧИС();0;H$2). Растянув эту формулу вниз до G64, и вы получите симуляции ошибки прогноза для 12 месяцев одношагового прогноза (рис. 19). Ваши значения симуляций будут отличаться от приведенных на рисунке (на то она и симуляция!).

Рис. 19. Симулированные ошибки прогноза
С погрешностью прогноза у вас есть все, что нужно для обновления уровня, тренда и сезонного коэффициента. Так что выделите ячейки C52:F52 и растяните их до строки 64. В результате у вас имеются симулированная ошибка прогноза и сам прогноз. Идя от обратного, можно спрогнозировать значения спроса. Вставьте в ячейку В53 формулу: =F53+G53 и растяните ее до В64 (рис. 20, диапазон В53:F64). Теперь вы можете нажимать на кнопку F9, каждый раз обновляя прогноз. Разместите результаты 1000 симуляций в ячейках А71:L1070, каждый раз транспонируя значения из диапазона В53:В64 в диапазон А71:L71, A72:L72, … A1070:L1070. Если вас это напрягает напишите код VBA.

Рис. 20. Тысяча сценариев дают хорошую оценку 95%-ного доверительного интервала
Теперь у вас есть по 1000 сценариев на каждый месяц, и вы можете использовать функцию ПЕРСЕНТИЛЬ, чтобы получить верхние и нижние границы в середине 95%-ного доверительно интервала. В ячейке А66 формула: =ПЕРСЕНТИЛЬ(A71:A1070;0,975), а в ячейке А67: =ПЕРСЕНТИЛЬ(A71:A1070;0,025).
Как обычно, для наглядности данные можно представить в графическом виде (рис. 21).

Рис. 21. Прогностический интервал по Холту-Винтерсу
На графике есть два интересных момента:
- Погрешность со временем становится шире. В этом есть смысл. Неуверенность накапливается с каждым месяцем.
- Точно так же погрешность растет и в частях, приходящихся на периоды сезонного повышения спроса. С последующим его падением погрешность сжимается.
[1] Написано по материалам книги Джона Формана Много цифр: Анализ больших данных при помощи Excel. – М.: Альпина Паблишер, 2016. – С. 329–381