
Обзор открытых решений для исправления опечаток
Время на прочтение
11 мин
Количество просмотров 14K
У каждого пользователя когда-либо были опечатки при написании поисковых запросов. Отсутствие механизмов, которые исправляют опечатки, приводит к выдаче нерелевантных результатов, а то и вовсе к их отсутствию. Поэтому, чтобы поисковая система была более ориентированной на пользователей, в неё встраивают механизмы исправления ошибок.

Задача исправления опечаток, на первый взгляд, кажется довольно несложной. Но если отталкиваться от разнообразия ошибок, реализация решения может оказаться трудной. В целом, исправление опечаток разделяется на контекстно-независимое и контекстно-зависимое (где учитывается словарное окружение). В первом случае ошибки исправляются для каждого слова в отдельности, во втором – с учетом контекста (например, для фразы «она пошле домой» в контекстно-независимом случае исправление происходит для каждого слова в отдельности, где мы можем получить «она пошел домой», а во втором случае правильное исправление выдаст «она пошла домой»).
В поисковых запросах русскоязычного пользователя можно выделить четыре основные группы ошибок только для контекстно-независимого исправления [1]:
1) ошибки в самих словах (пмрвет → привет), к этой категории относятся всевозможные пропуски, вставки и перестановки букв – 63,7%,
2) слитно-раздельное написание слов – 16,9%,
3) искаженная раскладка (ghbdtn → привет) – 9,7 %,
4) транслитерация (privet → привет) – 1,3%,
5) смешанные ошибки – 8,3%.
Пользователи совершают опечатки приблизительно в 10-15% случаях. При этом 83,6% запросов имеют одну ошибку, 11,7% –две, 4,8% – более трёх. Контекст важен в 26% случаев.
Эта статистика была составлена на основе случайной выборки из дневного лога Яндекса в далеком 2013 году на основе 10000 запросов. В открытом доступе есть гораздо более ранняя презентация от Яндекса за 2008 год, где показано похожее распределение статистики [2]. Отсюда можно сделать вывод, что распределение разновидностей ошибок для поисковых запросов, в среднем, с течением времени не изменяется.
В общем виде механизм исправления опечаток основывается на двух моделях: модель ошибок и языковая модель. Причем для контекстно-независимого исправления используется только модель ошибок, а в контекстно-зависимом – сразу две. В качестве модели ошибок обычно выступает либо редакционное расстояние (расстояние Левенштейна, Дамерау-Левенштейна, также сюда могут добавляться различные весовые коэффициенты, методы на подобие Soundex и т. д. – в таком случае расстояние называется взвешенным), либо модель Бриля-Мура, которая работает на вероятностях переходов одной строки в другую. Бриль и Мур позиционируют свою модель как более совершенную, однако на одном из последних соревнований SpellRuEval подход Дамерау-Левенштейна показал результат лучше [3], несмотря на тот факт, что расстояние Дамерау-Левенштейна (уточнение – невзвешенное) не использует априори информацию об опечаточной статистике. Это наблюдение особо показательно в том случае, если для разных реализаций автокорректоров в библиотеке DeepPavlov использовались одинаковые обучающие тексты.
Очевидно, что возможность контекстно-зависимого исправления усложняет построение автокорректора, т. к. дополнительно к модели ошибок добавляется необходимость в языковой модели. Но если обратить внимание на статистику опечаток, то ¾ всех неверно написанных поисковых запросов можно исправлять без контекста. Это говорит о том, что польза как минимум от контекстно-независимого автокорректора может быть весьма существенной.
Также контекстно-зависимое исправление для корректировки опечаток в запросах очень требовательно по ресурсам. Например, в одном из выступлений Яндекса список пар для исправления опечаток (биграмм) слов отличался в 10 раз по сравнению с количеством слов (униграмм), что тогда говорить про триграммы? Очевидно, что это существенно зависит от вариативности запросов. Немного странно выглядит, когда автокорректор занимает половину памяти от предлагаемого продукта компании, целевое назначение которого не ориентировано на решение проблемы правописания. Так что вопрос внедрения контекстно-зависимого исправления в поисковых системах программных продуктов может быть весьма спорным.
На первый взгляд, складывается впечатление, что существует много готовых решений под любой язык программирования, которые можно использовать без особого погружения в подробности работы алгоритмов, в том числе – в коммерческих системах. Но на практике продолжается разработка своих решений. Например, сравнительно недавно в Joom было сделано собственное решение по исправлению опечаток с использованием языковых моделей для поисковых запросов [4]. Действительно ли ситуация непроста с доступностью готовых решений? С этой целью был сделан, по возможности, широкий обзор существующих решений. Перед тем как приступить к обзору, определимся с тем, как проверяется качество работы автокорректора.
Проверка качества работы
Вопрос проверки качества работы автокорректора весьма неоднозначен. Один из простых подходов проверки — через точность (Precision) и полноту (Recall). В соответствии со стандартом ISO, точность и полнота дополняются правильностью (на англ. «corectness»).

Полнота (Recall) рассчитывается следующим образом: список из правильных слов подается автокорректору (Total_list_true), и, количество слов, которое автокорректор считает правильными (Spellchecker_true), разделенное на общее количество правильных слов (Total_list_true), будет считаться полнотой.

Для определения точности (Precision) на вход автокорректора подается список из неправильных слов (Total_list_false), и, количество слов, которое автокорректор считает неправильным (Spell_checker_false), разделенное на общее количество неправильных слов (Total_list_false), определяют как точность.

Насколько вообще эти метрики информативны и как могут быть полезны, каждый определяет самостоятельно. Ведь, фактически, суть данной проверки сводится к тому, что проверяется вхождение слова в обучающий словарь. Более наглядной метрикой можно считать correctness, согласно которой автокорректор для каждого слова из тестового множества неправильных слов формирует список кандидатов-замен, на которые можно исправить это неправильное слово (следует иметь в виду, что здесь могут оказаться слова, которые не содержатся в обучающем словаре). Допустим, размер такого списка кандидатов-замен равен 5. Исходя из того, что размер списка равен 5, будет сформировано 6 групп, в одну из которых мы будем помещать наше каждое исходное неправильное слово по следующему принципу: в 1-ую группу — если в списке кандидатов-замен предполагаемое нами правильное слово стоит 1-ым, во 2-ую если стоит 2-ым и т. д., а в последнюю группу — если предполагаемого правильного слова в списке кандидатов-замен не оказалось. Разумеется, чем больше слов попало в 1-ую группу и чем меньше в 6-ую, тем лучше работает автокорректор.
Рассмотренного выше подхода придерживались авторы в статье [5], в которой сравнивались контекстно-независимые автокорректоры с уклоном на стандарт ISO. Там же приведены ссылки на другие способы оценки качества.
С одной стороны, такой подход не базируется на опечаточной статистике, в основу которого может быть положена модель ошибок Бриля-Мура [6], либо модель ошибок взвешенного расстояния Дамерау-Левенштейна.
Для проверки качества работы контекстно-независимого автокорректора был создан собственный генератор опечаток, который генерировал опечатки неверной раскладки и орфографические опечатки исходя из статистики по опечаткам, представленной Яндексом. Для орфографических опечаток генерировались произвольные вставки, замены, удаления, перестановки, а количество ошибок так же варьировалось в соответствии с этой статистикой. Для ошибок искаженной раскладки, правильное слово посимвольно изменялось целиком в соответствии с таблицей перевода символов.
Далее была проведена серия экспериментов для всего списка слов обучающего словаря (слова обучающего словаря исправлялись на неправильные в соответствии с вероятностью возникновения той или иной опечатки). В среднем, автокорректор исправляет слова верно в 75% случаев. Вне всякого сомнения, это количество будет сокращаться при пополнении обучающего словаря близкими по редакционному расстоянию словами, большом многообразии словоформ. Эта проблема может решаться за счет дополнения языковыми моделями, но здесь следует учитывать, что количество требуемых ресурсов ощутимо возрастет.
Готовые решения

Рассмотрение готовых решений проводилось с уклоном на собственное использование, и приоритет отдавался автокорректорам, которые удовлетворяют трем критериям:
1) язык реализации,
2) тип лицензии,
3) обновляемость.
В продуктовой разработке язык Java считается одним из самых популярных, поэтому приоритет при поиске библиотек отдавался ему. Из лицензий актуальны: MIT, Public, Apache, BSD. Обновляемость — не более 2-х лет с последнего обновления. В ходе поиска фиксировалась дополнительная информация, например, о поддерживаемой платформе, требуемые дополнительные программы, особенности применения, возможные затруднения при первом использовании и т. д. Ссылки с основными и полезными ресурсами на источники приведены в конце статьи. В целом, если не ограничиваться вышеупомянутыми критериями, количество существующих решений велико. Давайте кратко рассмотрим основные, а более подробно уделим внимание лишь некоторым.
Исторически одним из самых старых автокорректоров является Ispell (International Spell), написан в 1971 на ассемблере, позднее перенесен на C и в качестве модели ошибок использует редакционное расстояние Дамерау-Левенштейна. Для него даже есть словарь на русском языке. В последующем ему на замену пришли два автокорректора HunSpell (ранее MySpell) и Aspell. Оба реализованы на на C++ и распространяются под GPL лицензиями. На HunSpell также распространяется GPL/MPL и его используют для исправления опечаток в OpenOffice, LibreOffice, Google Chrome и других инструментах.
Для Интернета и браузеров есть целое множество решений на JS (сюда можно отнести: nodehun-sentences, nspell, node-markdown-spellcheck, Proofreader, Spellcheck-API — группа решений, базирующаяся на автокорректоре Hunspell; grunt-spell — под NodeJS; yaspeller-ci — обертка для автокорректора Яндекс.Спеллер, распространяется под MIT; rousseau — Lightweight proofreader in JS — используется для проверки правописания).
В категорию платных решений входят: Spellex; Source Code Spell Checker — как десктопное приложение; для JS: nanospell; для Java: Keyoti RapidSpell Spellchecker, JSpell SDK, WinterTree (у WinterTree можно даже купить исходный код за $5000).
Широкой популярностью пользуется автокорректор Питера Норвига, программный код на Python которого находится в публичном доступе в статье «How to Write a Spelling Corrector» [7]. На основе этого простого решения были построены автокорректоры на других языках, например: Norvig-spell-check, scala-norvig-spell-check (на Scala), toy-spelling-corrector — Golang Spellcheck (на GO), pyspellchecker (на Python). Разумеется, здесь никакой речи не идет о языковых моделях и контекстно-зависимом исправлении.
Для текстовых редакторов, в частности для VIM сделаны vim-dialect, vim-ditto — распространяются под публичной лицензией; для Notepad++ разработан DspellCheck на C++, лицензия GPL; для Emacs сделан инструмент автоматического определения языка при печати, называется guess-language, распространяется под публичной лицензией.
Есть отдельные сервисы от поисковых гигантов: Яндекс.Спеллер — от Яндекса, про обертку к нему было сказано выше, google-api-spelling-java (соответственно, от Google).
Бесплатные библиотеки для Java: languagetool (лицензируется под LGPL), интегрируется с библиотекой текстового поиска Lucene и допускает использование языковых моделей, для работы необходима 8 версия Java; Jazzy (аналог Aspell) распространяется под лицензией LGPLv2 и не обновлялась с 2005 года, а в 2013 была перенесена на GitHub. По подобию этого автокорректора сделано отдельное решение [8]; Jortho (Java Orthography) распространяется под GPL и разрешает бесплатное использование исключительно в некоммерческих целях, в коммерческих — за дополнительную плату; Jaspell (лицензируется под BSD и не обновлялся с 2005 года); Open Source Java Suggester — не обновлялся с 2013 года, распространяется SoftCorporation LLC и разрешает коммерческое применение; LuceneSpellChecker — автокорректор библиотеки Lucene, написана на Java и распространяется под лицензией Apache.
На протяжении длительного времени вопросом исправления опечаток занимался Wolf Garbe, им были предложены алгоритмы SymSpell (под MIT лицензией) и LinSpell (под LGPL) с реализациями на C# [9], которые используют расстояние Дамерау-Левенштейна для модели ошибок. Особенность их реализации в том, что на этапе формирования возможных ошибок для входного слова, используются только удаления, вместо всевозможных удалений, вставок, замен и перестановок. По сравнению с реализацией автокорректора Питера Норвига оба алгоритма за счет этого работают быстрее, при этом прирост в скорости существенно увеличивается, если расстояние по Дамерау-Левенштейну становится больше двух. Также за счет того, что используются только удаления, сокращается время формирования словаря. Отличие между двумя алгоритмами в том, что LinSpell более экономичен по памяти и медленнее по скорости поиска, SymSpell — наоборот. В более поздней версии SymSpell исправляет ошибки слитно-раздельного написания. Языковые модели не используются.
К числу наиболее свежих и перспективных для пользования автокорректоров, работающих с языковыми моделями и исправляющих контекстно-зависимые опечатки относятся Яндекс.Спеллер, JamSpell [10], DeepPavlov [11]. Последние 2 распространяются свободно: JamSpell (MIT), DeepPavlov (под Apache).
Яндекс.Спеллер использует алгоритм CatBoost, работает с несколькими языками и исправляет всевозможные разновидности ошибок даже с учетом контекста. Единственное из найденных решение, которое исправляет ошибки неверной раскладки и транслитерацию. Решение обладает универсальностью, что делает его популярным. Его недостатком является то, что это удаленный сервис, а про ограничения и условия пользования можно прочитать здесь [12]. Сервис работает с ограниченным количеством языков, нельзя самостоятельно добавлять слова и управлять процессом исправления. В соответствии с ресурсом [3] по результатам соревнований RuSpellEval этот автокорректор показал самое высокое качество исправлений. JamSpell — самый быстрый из известных автокорректор (C++ реализация), здесь есть готовые биндинги под другие языки. Исправляет ошибки только в самих словах и работает с конкретным языком. Использовать решение на уровне униграмм и биграмм нельзя. Для получения приемлемого качества требуется большой обучающий текст.
Есть неплохие наработки у DeepPavlov, однако интеграция этих решений и последующая поддержка в собственном продукте может вызвать затруднения, т. к. при работе с ними требуется подключение виртуального окружения и использование более ранней версии Python 3.6. DeepPavlov предоставляет на выбор три готовых реализации автокорректоров, в двух из которых применены модели ошибок Бриля-Мура и в двух языковые модели. Исправляет только ошибки орфографии, а вариант с моделью ошибок на основе расстояния Дамерау-Левенштейна может исправлять ошибки слитного написания.
Упомяну ещё про один из современных подходов к исправлению опечаток, который основан на применении векторных представлений слов (Word Embeddings). Достоинством его является то, что на нем можно построить автокорректор для исправления слов с учетом контекста. Более подробно про этот подход можно прочитать здесь [13]. Но чтобы его использовать для исправления опечаток поисковых запросов вам потребуется накопить большой лог запросов. Кроме того, сама модель может оказаться довольно емкой по потребляемой памяти, что отразится на сложности интеграцию в продукт.
Выбор Naumen

Из готовых решений для Java был выбран автокорректор от Lucene (распространяется под лицензией от Apache). Позволяет исправлять опечатки в словах. Процесс обучения быстрый: например, формирование специальной структуры данных словаря – индекса для 3 млн. строк составило 30 секунд на процессоре Intel Core i5-8500 3.00GHz, 32 Gb RAM, Lucene 8.0.0. В более ранних версиях время может быть больше в 2 раза. Размер обучающего словаря – 3 млн. строк (~73 Mb txt-файл), структура индекса ~235 Mb. Для модели ошибок можно выбирать расстояние Джаро-Винклера, Левенштейна, Дамерау-Левенштейна, N-Gram, если нужно, то можно добавить свое. При необходимости есть возможность подключения языковой модели [14]. Модели известны с 2001 года, но их сравнение с известными современными решениями в открытом доступе не было обнаружено. Следующим этапом будет проверка их работы.
Полученное решение на основе Lucene исправляет только ошибки в самих словах. К любому подобному решению несложно добавить исправление искаженной раскладки клавиатуры путем соответствующей таблицы перевода, тем самым сократить возможность нерелевантной выдачи до 10% (в соответствии с опечаточной статистикой). Кроме того, несложно добавить раздельное написание слитых 2-х слов и транслитерацию.
В качестве основных недостатков решения можно выделить необходимость знания Java, отсутствие подробных кейсов использования и подробной документации, что отражается на снижении скорости разработки решения для Data-Science специалистов. Кроме того, не исправляются опечатки с расстоянием по Дамерау-Левенштейну более 2-х. Опять же, если отталкиваться от опечаточной статистики, более 2-х ошибок в слове возникает реже, чем в 5% случаев. Обоснована ли необходимость усложнения алгоритма, в частности, увеличение потребляемой памяти? Тут уже зависит от кейса заказчика. Если есть дополнительные ресурсы, то почему бы их не использовать?
Основные ресурсы по доступным автокорректорам:
- 30 best open source spellcheck project
- Evaluation of legal words in three Java open source spell checkers: Hunspell, Basic Suggester, and Jazzy
- spell checker: Java Glossary
- nlp — Looking for Java spell checker library
- Open source spell checking library for Java
Ссылки
- Панина М. Ф. Автоматическое исправление
опечаток в поисковых запросах
без учета контекста - Байтин А. Исправление поисковых запросов в Яндексе
- DeepPavlov. Таблица сравнения автокорректоров
- Joom. Исправляем опечатки в поисковых запросах
- Dall’Oglio P. Evaluation of legal words in three Java open source spell checkers: Hunspell, Basic Suggester, and Jazzy
- Eric B. and Robert M. An Improved Error Model for Noisy Channel Spelling Correction
- Norvig P. How to Write a Spelling Corrector
- Автокорректор на основе Jazzy
- Garbe W. SymSpell vs. BK-tree: 100x faster fuzzy string search & spell checking
- Jamspell. Исправляем опечатки с учётом контекста
- DeepPavlov. Automatic spelling correction pipelines
- Условия использования сервиса «API Яндекс.Спеллер»
- Singularis. Исправление опечаток, взгляд сбоку
- Apache Lucene. Языковые модели
Программы для исправления ошибок бывают необходимы во многих случаях: когда нужно проверить документ большого объема или быстро устранить опечатки в тексте. Часто пользователи жалуются на то, что вычитывают текст по нескольку раз, но все равно пропускают ряд ошибок, списывая это на собственную невнимательность. В чем бы ни заключалась проблема, без программ для исправления ошибок работать действительно сложно — даже тем, у кого с внимательностью нет никаких проблем. В этой статье мы расскажем, какими программами для исправления ошибок пользуются юзеры сети и почему.

Навигация по статье
- ТОП-10 программ по исправлению ошибок в тексте
- Сравнение возможностей сервисов

ТОП-10 программ по исправлению ошибок в тексте
Мы сделали для вас подборку из десяти самых популярных программ и сервисов, которые проверяют текст на наличие ошибок и подсвечивают их, чтобы пользователь мог легко их обнаружить и устранить.

Orfogrammka.ru
Это платная платформа, которая дает возможность проверить до 1 млн символов текста в течение одного месяца. Данный сервис, помимо синтаксических и орфографических ошибок, дает возможность проверить:
- наличие тавтологии;
- водность текста;
- иностранные слова;
- замену символов.
Сервис работает по подписке, которая предоставляет доступ к полноценной работе на один месяц. Стоимость ее обойдется пользователю в 300 рублей. Здесь также есть возможность проверить 6 тысяч символов текста с пробелами в тестовом режиме. Это же касается и исправления ошибок.
Яндекс.Спеллер
Сервис от известной группы разработчиков Яндекс — “Спеллер”, был создан для тех, кто хочет быстро осуществить проверку текста и исправить ошибки в режиме онлайн. Как и в большинстве других программ и сервисов подобного типа, здесь в окно проверки текста помещается сам текст, после чего сервис осуществляет проверку последнего в порядке очередности на сервере. В нижнем окне представлены варианты исправления.

Text.ru
Эта программа проверки орфографии на наличие ошибок в русском языке пользуется большой популярностью. Сервис в своем роде уникален, т.к. выполняет одновременно проверку уникальности, ошибок и SEO-данных текста.
Advego
Адвего — пожалуй, самая распространенная программа проверки текста. Это высококачественный и удобный сервис, который удерживает высокие позиции уже довольно долгое время. Он получил широкую известность как у разработчиков и SEO-специалистов, так и у копирайтеров с редакторами. Помимо функции проверки текста на наличие ошибок, здесь представлена масса других полезных возможностей:
- расчет количества символов;
- выявление орфографических ошибок;
- количество вхождений слов;
- водность текста;
- тошнота текста (академ. и классическая);
- уникальность текста.

Орфограф
Студия Артемия Лебедева представила еще один свой сервис, на этот раз, касающийся проверки текста. Как и все остальные проекты этой группы, Орфограф имеет минимальный набор функций — а именно, проверяет текст на наличие ошибок. В сервисе представлен собственный уникальный словарь, и если какая-то часть текста не имеет совпадений с базой данных Орфографа, то неизвестные слова выделяются дополнительным цветом.

Onlinecorrector
У этой программы проверки текстов есть одна специфическая функция — она способна проверять Google-документы. Это расширение требует установки в браузере, после чего с сервисом можно работать в режиме онлайн.

Орфо
Для осуществления проверок программой на ошибки в текстах многие пользователи сети предпочитают Орфо. Программу можно скачать на сайте, а также воспользоваться сервисом в режиме онлайн. Помарки в тексте подсвечиваются зеленым и красным цветом, в зависимости от того, какой тип ошибки будет обнаружен. Офлайн-версия предлагает пользователям расширенный функционал — здесь можно создавать переносы или автоматически корректировать буквы.

LanguageTool
Сервис был разработан и создан с целью предоставить функцию автоматического исправления орфографии на русском языке. Разработчики побеспокоились о том, чтобы создать две версии — онлайн и стационарную, для работы с расширением в браузере. При анализе текста, все слова с ошибками подсвечиваются другим цветом. Данная функция работает по аналогии с другими сервисами, которые предоставляют те же функции. Однако, здесь присутствует одно ключевое отличие — при нажатии на подсвеченное слово с ошибкой выпадает дополнительное меню, в котором можно выбрать один из вариантов исправления. Премиум версия программы (платная) предоставляет расширенный функционал, который может оказаться полезным для профессиональных корректоров, а также частных редакций.

Мета.ua
Этот сервис подойдет пользователям, которые ищут бесплатный инструмент, способный не только подсветить слова с ошибками, но и предоставить варианты для замены. Помимо всего прочего, данный сервис представляет еще и функции автоматического перевода. Ошибки в словах выделяются пунктирной линией. При нажатии на подсвеченное слово, пользователь может увидеть список слов для замены и выбрать из них подходящее.
Главред
Сайт Главред предлагает интересную функцию — проверку не только орфографического, но и смыслового качества текста. Это позволяет оценить текст сразу по нескольким критериям. Все предлагаемые исправления в тексте подчеркиваются пунктиром.
Присоединяйтесь к
Rush-Analytics уже сегодня
7-ми дневный бесплатный доступ к полному функционалу. Без привязки карты.
Попробовать бесплатно

Сравнение возможностей сервисов
| Название сервиса / программы | Проприетарность | Версия | Автокоррекция |
| Orfogrammka.ru | Платная | Онлайн | Нет |
| Яндекс.Спеллер | Бесплатная | Онлайн | Нет |
| Text.ru | Платная и бесплатная | Онлайн | Нет |
| Advego | Платная и бесплатная | Онлайн и офлайн | Нет |
| Орфограф | Платная | Онлайн | Нет |
| Onlinecorrector | Платная и бесплатная | Онлайн и офлайн | Нет |
| Орфо | Платная и бесплатная | Онлайн и офлайн | Да |
| LanguageTool | Платная и бесплатная | Онлайн и офлайн | Да |
| Мета.ua | Бесплатная | Онлайн | Да |
| Главред | Бесплатная | Онлайн | Нет |
Рекомендуем протестировать каждый из этих инструментов, чтобы выбрать наиболее удобный и эффективный для ваших целей.

Грамотность в нашем менталитете — базовая прошивка, поэтому так бросаются в глаза чужие ошибки. И соответственно, доверие к неграмотным продавцам пропадает где-то на подсознательном уровне. Это как тест на уважение к читателю. Мы собрали 12 сервисов для проверки текста на ошибки и 6 лайфхаков, которые помогут вам всегда оставаться на высоте.
Содержание
- Проверка текста на ошибки: пошаговый алгоритм действий
- Сервисы для проверки текста на ошибки
- Как улучшить навык грамотного письма во взрослом возрасте
- Что делать, если ошибка все-таки попала на сайт и на нее указал читатель?
Влияют ли ошибки в текстах на уровень доверия потенциальных клиентов и читателей к вашей компании? Или современное интернет-пространство достаточно лояльно и прощает неграмотность? Как считаете?
Недавно я участвовала в обсуждении на Facebook, темой которого был вопрос: обращаете ли вы внимание на ошибки в текстах интернет-магазинов и влияют ли они на дальнейшее решение о покупке.
Большинство комментаторов писали о том, что замечают ошибки, даже специально не вычитывая текст. Ошибки подрывают доверие, а для первого знакомства с сайтом и решения заказать — это критично.
Особенность ошибок в текстах в том, что они сами бросаются в глаза. И если единичные опечатки или небольшие неточности в знаках препинания бренду еще могут простить, то более грубые ошибки сигнализируют: что-то с этим сайтом не так, даже ошибки не вычитали, может, и с услугами/курсами/экспертностью у них тоже проблемы?
Как влияют ошибки в текстах на восприятие бренда:
- раздражают — «ох, даже ошибки не могли вычитать»;
- портят репутацию компании — «если вы пишете с ошибками, какие же вы профи»;
- усложняют чтение — особенно стилистические и логические ошибки;
- показывают неуважение к читателю.
Проверка текста на ошибки: пошаговый алгоритм действий
Идеальная картина мира — ваш текст вычитывает профессиональный редактор или корректор. И дело тут не только в профессионализме. Ошибки в тексте, над которым вы корпели несколько часов или дней, сложно увидеть, так как глаз замылился. А вот в чужих текстах они виднее.
Совет: не думайте об ошибках, стилистике и редактировании сразу в момент написания текста — это может парализовать вас и убить творческий настрой. Сначала думайте о смыслах, пишите и только потом, после того как текст немного «отлежится», начинайте редактирование и исправление ошибок.
Но если проверить ошибки все-таки нужно самостоятельно, действуйте следующим образом:
- Напишите текст, думая о смыслах, и дайте ему «отдохнуть» хотя бы 1–2 часа.
- Перечитайте текст — грубые ошибки и опечатки вы увидите уже на этом этапе.
- Проверьте текст, используя специальные программы и сервисы. Они не помогут избавиться от всех ошибок, поскольку не всесильны, но большую часть заметят. О сервисах и программах проверки текстов ниже расскажу подробнее.
- Перечитайте текст еще раз — вслух, используя один из методов: «орфографическое чтение» или чтение задом наперед. В первом случае вы читаете слова так, как они пишутся, побуквенно или по слогам, четко произнося каждую букву без фонетических изменений, которые мы обычно делаем в речи, формируя в памяти привычку писать правильно. Например, читаем [ко-то-рый], а не [ка-то-рый]. Во втором — читаете текст слово за словом, но с конца, не проглатывая куски предложений, как мы это делаем, когда читаем знакомый текст.
- Засомневались в слове, знаке препинания, слитном или раздельном написании? Проверяйте! Гуглите свой вопрос и ищите достоверные источники. Например, в случаях написания частицы «не» слитно или раздельно, -н- или -нн- сервисы часто допускают ошибки, так как не чувствуют оттенков смыслов.

Сервисы для проверки текста на ошибки
Редакторы Word или Google Doc
Начните проверку ошибок со встроенных возможностей того редактора, где вы набираете текст. Они постоянно совершенствуются, поэтому их способность находить грамматические ошибки и предлагать правильный вариант написания растет. При хорошем уровне внимательности и базовых знаниях языка этого может быть достаточно.

Онлайн-сервис проверки «Орфограммка»
«Орфограммка» копируете текст в форму проверки и смотрите рекомендации. Сервис платный: вы получаете 6000 знаков для знакомства, а потом выбираете тариф коммерческой лицензии по количеству знаков или на определенный срок действия.
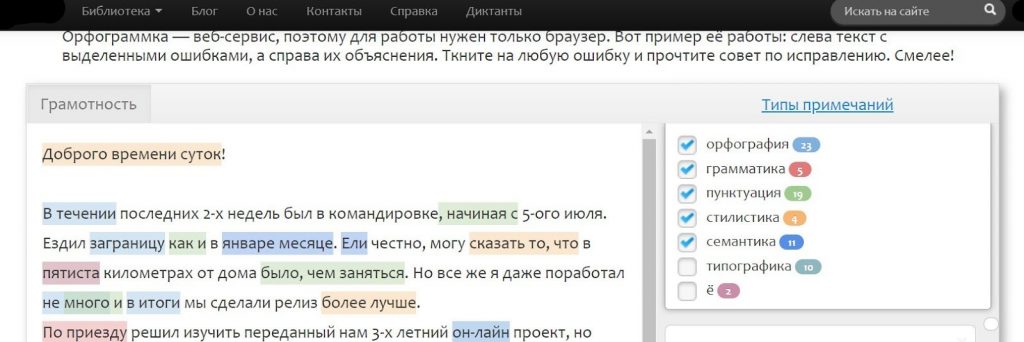
Сервис «Орфограф» от студии Лебедева
Сервис «Орфограф» визуально похож на обычный редактор: подчеркивает красным ошибки и при выделении слова предлагает варианты правильного написания.
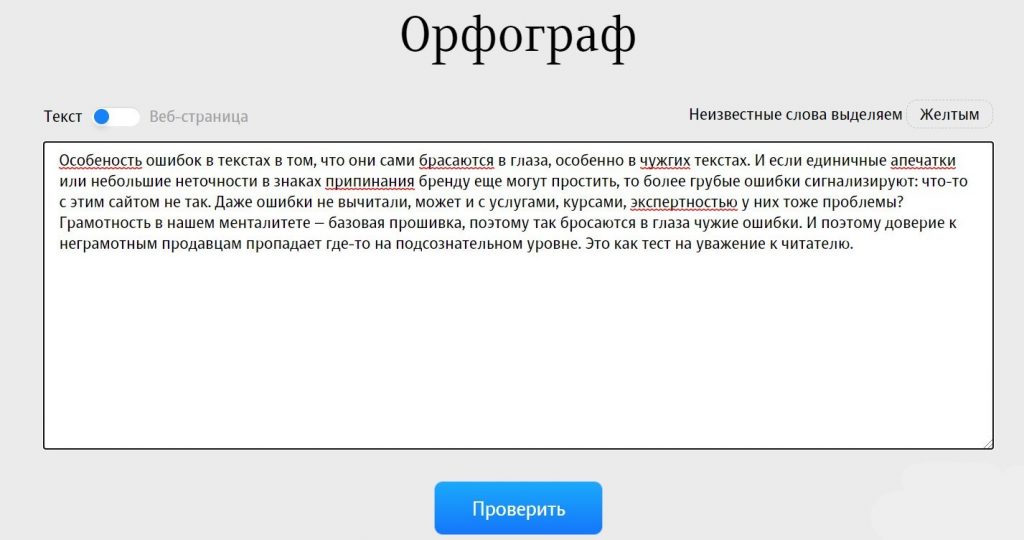
Расширение для браузера Languagetool (languagetool.org)
Сервис Languagetool можно добавить в браузер Google Chrome или Firefox, а также использовать в отдельной вкладке, как и предыдущие сервисы. Он подходит для проверки орфографии и грамматики, работает онлайн, с MS Word, LibreOffice, Google Docs, более чем на 10 языках.
Или так:

Практически аналогично работают такие сервисы и программы проверки ошибок: «Яндекс.Спеллер», «Орфо», Spell-Checker, PerevodSpell. Поэтому попробуйте разные варианты и выберите тот, с которым вам будет наиболее комфортно.
Сервис проверки отдельных слов «Грамота.ру»
Этот сервис мне нравится тем, что здесь можно не просто посмотреть, как пишется то или иное слово, но и вспомнить правила. Используйте его, когда вам нужно уточнить написание одного слова или сложного случая.
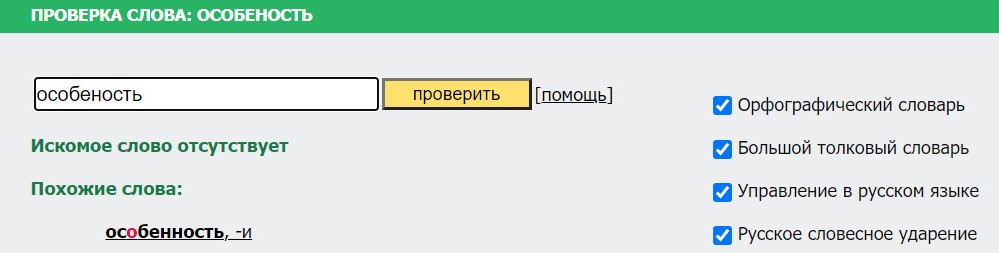
Сервисы проверки уникальности текста
Сервисы проверки уникальности текста и SEO-анализа, которые созданы для проверки текста на плагиат, показывают допущенные орфографические ошибки. Некоторые из них выделяют все неправильно написанные слова отдельной строкой. Эти сервисы удобны в том случае, если вы хотите выполнить проверку и на уникальность, и на ошибки одновременно. Самые популярные программы проверки: text.ru, content-watch и advego.
Вот так выглядит проверка на Аdvego:

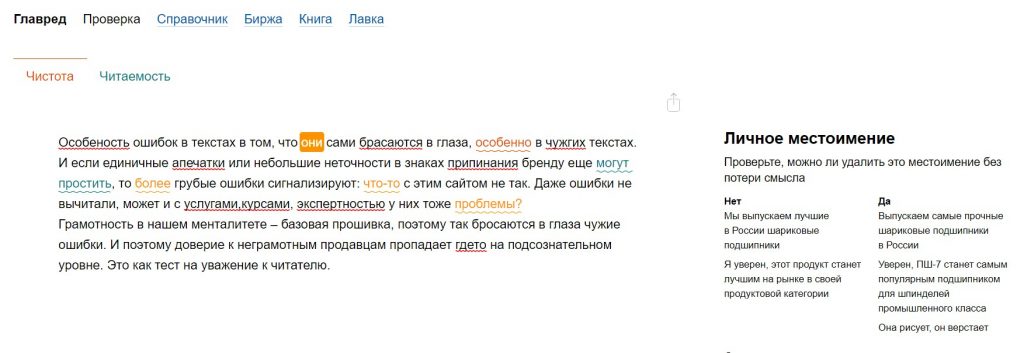
Сервис для проверки стилистики текста «Главред»
Если вы хотите проверить текст не только на грамматические ошибки, но и поработать со стилистикой и редактурой, обратите внимание на сервис «Главред», разработанный Максимом Ильяховым. Сервис сразу проверит ошибки и предложит рекомендации по доработке стилистики. Возможно, не ко всем рекомендациям вы прислушаетесь, но от каких-то лишних слов точно сможете избавиться без потери смысла.
Сервисы оформления текста для размещения на сайте
Перед публикацией на сайте будет нелишним прогнать текст через «Типограф», чтобы проставить неразрывные пробелы, исправить кавычки и тире, спецсимволы. Сейчас это выглядит как абракадабра, но при добавлении на сайт в виде готового HTML-кода, который можно выделить с помощью кнопки «Выделить все» и скопировать, вы получите правильно отформатированный текст.

Как улучшить навык грамотного письма во взрослом возрасте
Никогда не верьте сервисам на 100%, прокачивайте собственную грамотность.
Для этого:
- Регулярно читайте книги — подойдет художественная литература и бизнес-книги.
- Интересуйтесь сложными случаями орфографии и пунктуации.
- Регулярно, но понемногу (много вы просто не запомните) читайте о сложных случаях. Почитать можно такие ресурсы: mel.fm, gramota.ru. Вот, например, несколько хороших подборок: одна и вторая.
- Пишите тексты и онлайн-диктанты. Например, на сайте gramota.ru есть интерактивные диктанты в этом разделе.
- Работайте с редактором и корректором, которые не просто исправят ошибки, но и расскажут, почему так правильно.
- Смотрите, что особо выделяют в редполитиках крупных интернет-СМИ. Часто это не орфограммы, а рекомендации по написанию отдельных слов. При том, что правильное написание может быть двойным, вы будете знать, какие варианты предпочитают издательства. Например, как это описано здесь:
- Если ошибок регулярно много и вы не чувствуете язык, с этим тоже можно бороться, например, используя методики повышения грамотности для взрослых людей. Посмотрите интересные методики на этом ресурсе.
Что делать, если ошибка все-таки попала на сайт и на нее указал читатель?
Поблагодарить за внимательность и исправить. Это сложно, особенно с первыми текстами, но не стоит делать из этого трагедию, лучше сделать выводы.
Воспользуйтесь этой подборкой и составьте свой пошаговый план действий, который поможет победить врага, способного испортить сетевую репутацию.
Грамматические и орфографические ошибки в тексте больше не будут мешать вашему успеху
Нейросеть проверит текст на ошибки и автоматически исправит его, так как это бы сделал преподаватель русского языка

Нейросеть исправит все ошибки
Грамматика, орфография, пунктуация и другие ошибки больше вам не страшны
Все мы делаем ошибки, особенно когда пишем на русском языке. Но что, если я скажу вам, что теперь вы можете забыть о грамматических и орфографических ошибках в своих текстах? Наша нейросеть проверит ваш текст и автоматически исправит его, так как это бы сделал преподаватель русского языка. Давайте разберемся, как это работает и как это поможет вам достичь успеха в своих проектах.
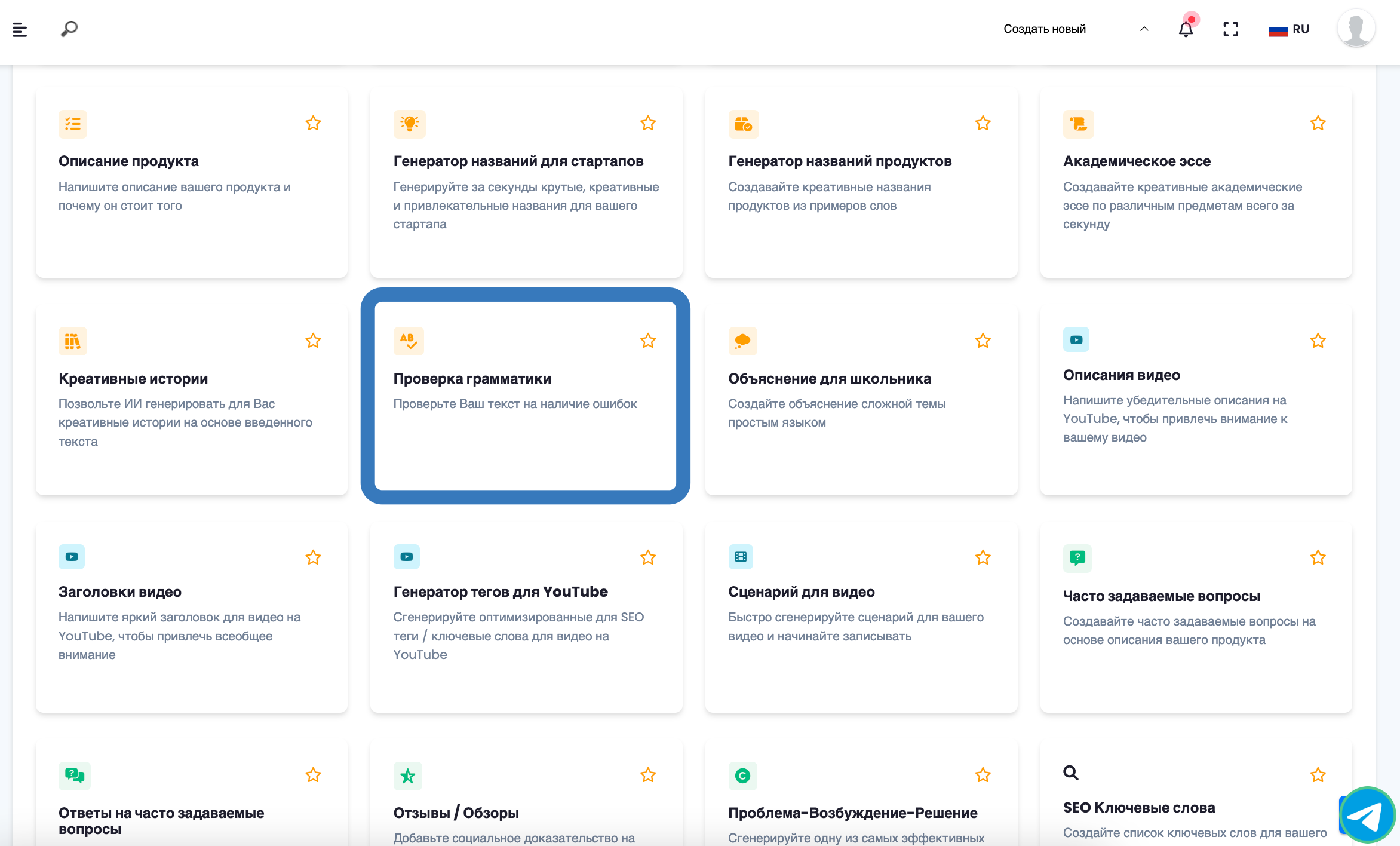
1 ШАГ
Выберите шаблон
После успешной регистрации на AIRUCO, перейдите в раздел «Шаблоны» и выберите инструмент «Проверка грамматики»
Выберите шаблон под ваши задачи
Список шаблонов постоянно пополняется
2 ШАГ
Вставьте текст
Вставьте ваш текст который хотите проверить на ошибки
Настройте стиль
Вы можете задать стиль написания, выбрать количество результатов и установить количество символов в ответе

3 ШАГ
Доработайте текст в редакторе
Получите результат, генерируйте, пока не получите идеальный текст приветственного письма. Готовый вариант доработайте во встроенном редакторе.
Отредактированные документы можно сохранять внутри личного кабинета распределяя контент по папкам

Воспользуйтесь бесплатно всеми функциями нейросете
Все функции без ограничений станут доступны после регистрации
Более 30 шаблонов
Готовые шаблоны от рерайта текста до создания идей для блогов, создание отзывов и ключевых слов для сайта
Встроенный чат бот
Общайтесь с чат ботом в формате диалога и выстраивайте длинные диалоги для достижения сложных задач


Как нейросеть проверит ваш текст на ошибки и исправит его
Орфографические и грамматические ошибки в тексте – это одна из самых распространенных проблем, с которыми сталкиваются авторы текстов. Ведь даже самый опытный писатель может допустить ошибку в написании слова или нарушить правила грамматики и пунктуации. Но теперь есть решение этой проблемы – нейросеть, которая проверит ваш текст на ошибки и исправит их.
Нейросеть – это компьютерная программа, которая способна обучаться и принимать решения на основе большого количества данных. В случае с проверкой текста на ошибки, нейросеть использует свои знания о правильном написании слов, грамматике и пунктуации, чтобы выявить ошибки в тексте.
Как работает нейросеть для проверки текста на ошибки? Сначала программа анализирует текст на наличие ошибок, используя свои знания о правильном написании слов и правилах грамматики и пунктуации. Затем нейросеть заменит ошибки на правильные слова или исправит грамматические и пунктуационные ошибки.
Нейросеть для проверки текста на ошибки – это удобный и быстрый способ исправления текста. Ведь теперь вам не нужно тратить много времени на проверку своего текста на ошибки – нейросеть сделает это за вас. Кроме того, нейросеть для проверки текста на ошибки может использоваться в различных областях, где важно правильно написать текст – например, в журналистике, рекламе, маркетинге и т.д.
Однако, стоит помнить, что нейросеть для проверки текста на ошибки не является 100% надежным инструментом. Иногда программа может допустить ошибку или не учесть некоторые особенности языка. Поэтому, перед отправкой текста, всегда следует его проверить на наличие ошибок еще раз.
В итоге, нейросеть для проверки текста на ошибки – это удобный и быстрый инструмент, который поможет вам исправить ошибки в тексте. Он использует свои знания о правильном написании слов, грамматике и пунктуации, чтобы выявить ошибки в тексте и заменить их на правильные слова или исправить грамматические и пунктуационные ошибки. Но не стоит полагаться только на нейросеть – перед отправкой текста всегда следует его проверить на наличие ошибок еще раз.
Приятные цены
Тарифные планы
Вы можете использовать свой лимит на генерацию контента бессрочно. Тогда, когда захотите
Весь функционал включен в каждый тариф
Чем больше символов тем ниже цена
Бесплатно
₽0 / Бессрочно
Для ознакомления со всеми возможностями
10000 символов
5 изображений
Стартовый
₽190 / Бессрочно
3.8 руб. за 1000 символов
50000 символов
25 изображений
Стандарт
₽290 / Бессрочно
2.9 руб. за 1000 символов
100 000 символов
50 изображений
Мегавыгода
₽990 / Бессрочно
0.99 руб. за 1000 символов
1 000 000 символов
100 изображений
Читайте другие статьи про искусственный интеллект
Подпишитесь на рассылку от нашего бота, узнавайте о новых трендах искусственного интеллекта

Для работы проектов iXBT.com нужны файлы cookie и сервисы аналитики.
Продолжая посещать сайты проектов вы соглашаетесь с нашей
Политикой в отношении файлов cookie
В русском языке сложная пунктуация. Есть случаи, когда запятую можно поставить, а можно не ставить. Или, например, сразу нужны и запятая, и тире. Даже если интуитивно знать эти правила, глаз всё равно может замылиться. Здесь на помощь приходят корректоры — очень внимательные специалисты, которые вычитывают текст вплоть до каждой буковки и исправляют ошибки.
Мне стало интересно, сможет ли ChatGPT хотя бы частично заменить работу корректоров. Сейчас покажу на примерах, что получилось.

Содержание
- Исправляем только пунктуацию
- Исправляем пунктуацию и типографику
- Исправляем сложную пунктуацию и грамматику
- Исправляем абсурд
- Исправляем полный абсурд. Или не исправляем
- Что в итоге делать корректорам
- Ссылки, которые помогут больше узнать о ChatGPT
ChatGPT — самая буквальная нейросеть. Чем точнее написать ей запрос, тем точнее будет ответ. Посмотрите, как от одной маленькой формулировки меняется результат.
Сленг нейросеть тоже не понимает. Она не смогла разобрать, что делать со словом «мультяшки».
Пусть тире на скриншотах сверху вас не смущают: ChatGPT их поставила, потому что уже видела этот фрагмент текста с правильными чёрточками.
Добровольно нейросеть ставит только дефис. К ещё трём чертам, которые есть в русском языке, её нужно принуждать. Как и ставить кавычки-ёлочки вместо эмбрионов: «» вместо «».
Я отправил ChatGPT довольно сложный фрагмент: с двоеточием, скобочками и ошибками в словах. Ответ без ошибок она так и не выдала, хотя я формулировал запросы по-разному.
Ошибки были в синтаксисе, логике, пунктуации и даже в словах. «Иллюстрацию» с одной «л» нейросеть так и не заметила. А «художники стоят разными ценами» — вообще шедевр.
Даже если собрать в кучу лучшее из каждого ответа, результат всё равно будет не очень. Придётся править.
Дисклеймер: в тексте, который я написал для ChatGPT, слишком много ошибок. Берегите глаза и читайте на свой страх и риск. Исправлял в два этапа: сначала грамматику с пунктуацией, потом типографику с мелкими деталями.
Мошенник почему-то превратился в машиниста и покинул героев истории, а не кинул. Но если бы покинул, никто бы не расстроился.
У ChatGPT тоже есть пределы понимания. Сегодня нейросеть не всё может исправить. Вернее, исправить может не только лишь всё… Смейтесь, короче.

Продолжать работать, исправлять тонны ошибок и причёсывать текст так, чтобы полиция грамматических нравов могла спать спокойно. Никакого толкового корректора ChatGPT пока не заменит. А вот помочь может сильно.
В общем, не соревнуйтесь с ChatGPT. Она наш друг, а не враг. Помощник, а не конкурент.
Общий обзор: что нейросеть может, чего не может и каких специалистов заменит
Гайд: как пользоваться ChatGPT в России
Пример: как ChatGPT помогла другу написать отклик на вакансию
Обзор: как лучше писать ChatGPT. На русском или через переводчик
Сейчас на главной
Новости
Публикации

«Как хорошо, что старая сломалась!» — сказала в конце этой истории мама, и это было очень нехарактерно для бережливой хозяйки. Но, обо всем по порядку. Мамина зажигалка для газовой…

Давненько у меня лежала катушка филамента EcoPETG от
SYNTECHLAB, и вот дошли руки до тестов. Итоги теста: дешевый и качественный
филамент, который мне очень понравился. По свойствам это обычный…

Ugreen уже давно специализируется не только на производстве качественных зарядных устройств и различных дополнительных аксессуаров для носимой техники, но и на достаточно неплохих наушников….

Планшет может
быть не только прикроватным девайсом,
но и рабочим помощником в условиях,
далеких от комнатных. Для бесперебойной
работы на природе, в любое время года и
при любой погоде нужно…

Рыбалка считается самый популярным видом отдыха для мужчин, но и девушки часто проявляют интерес к этому виду отдыха. В обзоре рассмотрим эхолот фирмы Lucky и выясним, можно ли считать данное…

В этом обзоре я расскажу про недорогие, полноразмерные, компьютерные наушники от компании GMNG. Современный дизайн, мягкое оголовье и это все подчеркивает стильная, отключаемая RGB подсветка….