
Математическая статистика
Определение. Математической статистикой называется наука, занимающаяся разработкой методов
получения, описания и обработки опытных данных с целью изучения закономерностей случайных
массовых явлений.
Одна из основных прикладных задач мат. статистики – определение методов обработки опытных
данных.
Типичные задачи математической статистики:
1. Оценка на основании результатов измерений неизвестной функции распределения.
Постановка задачи: в результате независимых испытаний над случайной величиной Х получены
следующие ее значения х1, х2,…, хn. Требуется приближенно оценить неизвестную функцию
распределения F(x).
2. Оценка неизвестных параметров распределения.
Постановка задачи: пусть случайная величина Х имеет функцию распределения F(x) определенного
вида, зависящую от k неизвестных параметров. Требуется на основании опытных данных оценить
значения этих параметров.
3. Статистическая проверка гипотез.
Постановка задачи: пусть на основании некоторых соображений можно считать, что функция
распределения Х есть F(x). Ставятся вопросы: совместимы ли наблюдаемые значения с гипотезой, что Х
действительно имеет распределение F(x), не опровергают ли опытные данные гипотезу, что параметры
F(x) имеют предположенные значения.
§ 1. Этапы обработки выборки
П. 1. Генеральная совокупность и выборка
Пусть требуется исследовать какой-нибудь признак, свойственный большой группе (N штук)
однотипных элементов, например, вес N изделий, размеры N деталей и т.п.
Определение 1. Совокупность значений признака всех N элементов данного типа, где N велико, т.е.
N , называется генеральной совокупностью.
Если совокупность содержит очень большое число элементов, то провести сплошное ее
обследование физически невозможно, а иногда и практически не имеет смысла (обследование связано с
уничтожением предметов, например, проверка электроники на длительность работы). В таких случаях
случайно отбирают из всей совокупности ограниченное число элементов и подвергают их изучению.
Определение 2. Выборочной совокупностью или просто выборкой называют совокупность
случайно отобранных элементов из генеральной совокупности.
Объемом выборки называется количество элементов выборки – n .
Выборочный метод заключается в том, что из генеральной совокупности берется выборка объема n
( n N ), и определяются характеристики выборки, которые принимаются в качестве приближенных
значений соответствующих характеристик всей генеральной совокупности. То есть на основании
изучения характеристик выборки делают вывод о всей генеральной совокупности. Естественно, что при
этом результаты обследований, составляющие выбору, должны быть независимыми.
Выборка называется репрезентативной, если она правильно отражает пропорции генеральной
совокупности
При n N выборочное распределение приближается к генеральному.
Этапы обработки выборки: 1. составление вариационного ряда. 2. составление эмпирического закона
распределения. 3. поиск параметров, от которых зависит закон распределения.
1
П. 2. Вариационный и статистический ряды. Группированный статистический
ряд
Пусть изучается случайная величина Х, закон распределения которой неизвестен. Сделана выборка
x1 , x2 ,…, xn , над которой производится ряд опытов, результаты которых могут быть записаны в виде
рядов – вариационного и статистического.
Определение 3. Вариационным рядом выборки х1, х2,…, хn называется упорядоченная
последовательность различных значений из выборки, расположенных в порядке возрастания:
x(1) , x( 2) ,…, x( n) , где x(1) x( 2) … x( n) .
(i ) , где i 1,2,…, n – порядок элемента по возрастанию.
Определение 4. Разность между максимальным и минимальным элементами выборки x( n) x(1)
называется размахом выборки.
Пример 1. Записать в виде вариационного ряда выборку 4, 2, 6, 9, 4, 4, 1, 9, 6, 1, 6, 6, 3, 1, 3 и
определить ее объем и размах.
Решение.
Объем выборки n 15 (количество элементов).
Упорядочим элементы по величине, т.е. составим вариационный ряд:
1, 1, 1, 2, 3, 3, 4, 4, 4, 6, 6, 6, 6, 9, 9.
Размах выборки: 9 1 8 .
Пусть выборка x1 , x2 ,…, xn содержит k различных чисел z1 , z2 ,…, zn , причем zi встречается ni раз,
i 1,2,…, k .
Определение 5. Число ni называется частотой элемента выборки zi .
k
Сумма всех частот равна объему выборки: ni n .
i 1
Определение 6. Статистическим рядом выборки х1, х2,…, хn называется последовательность пар
( zi , ni ) , которая записывается в виде таблицы, первая строка которой содержит элементы zi , а вторая их
частоты ni :
zi
z1
z2
…
zk
ni
n1
n2
…
nk
В некоторых учебниках вместо z пишут х.
Замечание. В некоторых старых изданиях статистическим рядом называется таблица, в которой
содержатся номера и результаты измерений:
i
xi
1
x1
2
x2
…
…
n
xn
Сейчас ее называют таблицей значений выборки.
Пример 2. Записать в виде статистического ряда выборку 4, 2, 6, 9, 4, 4, 1, 9, 6, 1, 6, 6, 3, 1, 3.
2
Решение.
zi
1
2
3
4
6
9
ni
3
1
2
3
4
2
Контроль:
k
n
i 1
i
15 .
Пример 3. Из генеральной совокупности извлечена выборка объема 20 и записана в виде
статистического ряда:
1
2
3
4
zi
Найти n4 .
5
6
2
n4
ni
Решение.
k
Сумма всех частот равна объему выборки: ni 5 6 2 n4 20 , отсюда n4 7 .
i 1
Замечание. Если хотят при подсчете результатов наблюдений указать еще и относительные частоты
ni
, то статистический ряд представляют в виде таблицы частот.
n
Накопленная
Частота
частота
Относительная частота
i
zi
ni
nj
ni
n
j 1
…
…
…
Накопленная
относительная
i
n
j 1
частота
…
j
n
…
Пример 4. Записать в виде таблицы частот статистический ряд из примера 3.
Решение.
i
zi
1
2
3
4
ni
5
6
2
7
n
j 1
5
11
13
20
j
ni
n
0,25
0,3
0,1
0,35
i
n
j 1
j
n
0,25
0,55
0,65
1
При большом числе наблюдений, т.е. при большом объеме выборки, представление результатов в
виде статистического, а тем более вариационного рядов, бывает затруднительным или
нецелесообразным. В таких случаях производят подсчет результатов наблюдений, попадающих в
определенные группы, и составляют таблицу, в которой указываются группы и частота получения
результатов наблюдений в каждой группе.
Определение 7. Совокупность групп – интервалов, на которые разбиваются результаты наблюдений,
и частот получения результатов наблюдений в каждой группе, называют статистической
совокупностью.
3
Статистическая совокупность образуется из статистического ряда путем деления его на группы –
интервалы по некоторым признакам и подсчета чисел и частот измерений в каждой группе. Интервал,
содержащий все элементы выборки, разбивают на k непересекающихся интервалов обычно одинаковой
b
длины b:
.
k
После этого определяют частоты ni – количество элементов выборки, попавших в i – ый интервал.
ni
.
n
элемент, совпадающий с верхней границей интервала, относится к
Иногда определяют еще и относительную частоту:
Справедливо ПРАВИЛО:
последующему интервалу.
Пример 5. Дана таблица значений выборки – таблица ошибок 20 измерений дальности до цели с
помощью дальнометра:
i
хi
1
5
2 3
-8 10
4
15
5
3
6
-6
7
-15
8
20
9
12
10
15
11
-4
12
-2
13
20
14
14
15
-8
16
-12
17
16
18
10
19
-5
20
18
Построить статистическую совокупность.
Решение.
Объем выборки n = 20.
Размах выборки ω =20 – (–15) = 35.
Рассмотрим k = 7 интервалов длины b = 35:7 = 5. Разобьем интервал (15,20) , содержащий все
элементы выборки на 7 интервалов длины 5.
№группы
Границы группы Число ошибок в группе –
i
частота ni
1
(–15 ) – (–10)
2
2
(–10) – (–5)
3
3
4
5
6
7
(–5) – 0
0–5
5 – 10
10 – 15
15 – 20
3
1
1
4
6
Относительная частота
ni
n
2
0,1
20
3
0,15
20
0,15
0,05
0,05
0,2
0,3
Контроль:
7
ni
n
1
i 1
Замечание 1. При большом объеме выборки ее элементы объединяют в группы, представляя
результаты опытов в виде группированного статистического ряда
(расширенное понятие
статистической совокупности, иногда совокупность так и называют).
Границы
интервалов
ni
х1- х2
n1
х2- х3
n2
…
хk-1- хk
…
nk
4
Для этого, как и ранее, интервал, содержащий все элементы выборки, разбивают на k
непересекающихся интервалов обычно одинаковой длины b и определяют частоты ni , при этом
правило, сформулированное выше, справедливо.
При этом, чтобы получить статистический ряд, находят середины интервалов. Получающийся
статистический ряд в верхней строке содержит середины zi интервалов группировки, а в нижней –
частоты ni , i 1,2,…, k.
zi z1 z2 … z k
ni n1 n2 … nk
Замечание. В некоторых учебниках вместо z пишут х.
Если подсчитываются также накопленные частоты
i
n
j 1
j
, относительные частоты
i
относительные частоты
nj
j 1
n
ni
и накопленные
n
i
, i 1,2,…, k , при чем,
i
nj n ,
j 1
n
j 1
j
n
1 (если рассматривается сумма
всех частот), то полученные результаты сводятся в таблицу, называемую таблицей частот
группированной выборки.
№
интервала
Границы
интервалов
Середина
интервала
Частота
Накопленная
частота
i
i
zi
(–a) – (–b)
1
nj
ni
j 1
(b) (a)
2
…
Относительная
частота
ni
n
…
…
Накопленная
относительная
i
n
частота
j 1
j
n
…
Замечание 2. Группировка выборки вносит погрешность в дальнейшие вычисления, которая растет с
уменьшением числа интервалов.
Замечание 3. Если в задаче важны только частоты, то иногда записывают выборку с помощью
накопленных частот, т.е. в виде:
n1 , x a1
n n , a x a
i
2
n j = n( x ) 1 2 1
а1, а2,…, аn – точки разбиения интервала.
j 1
…
n, x an
Пример 6. Представить выборку из примера № 5 в виде таблицы частот группированной выборки.
Решение.
Сначала запишем выборку в виде статистического ряда для удобства:
zi
ni
-15
1
-12 -8
1 2
-6 -5
1 1
-4
1
-2
1
3
1
5
1
10
2
12
1
14
1
15
2
16
1
18
1
20
2
Объем выборки n = 20, размах ω = 35. Рассмотрим k = 7 интервалов длины b = 5.
5
Таблица частот группированной выборки имеет вид:
i
Границы
интервалов
i
zi
i
nj
ni
n
ni
n
j 1
1
(–15 ) – (–10)
–12,5
2
2
2
(–10) – (–5)
–7,5
3
5
3
4
5
6
7
(–5) – 0
0 –5
5 – 10
10 – 15
15 – 20
–2,5
2,5
7,5
12,5
17,5
3
1
1
4
6
8
9
10
14
20
2
0,1
20
3
0,15
20
0,15
0,05
0,05
0,2
0,3
j 1
j
n
0,1
5
0,25
20
0,4
0,45
0,5
0,7
1
i
Контроль:
i
n
j 1
j
n 20 ,
n
j 1
n
j
1.
П. 3. Эмпирическая функция распределения
Пусть х1, х2,…, хn – выборка из генеральной совокупности с функцией распределения FX (x) .
Статистический ряд – первичная форма записи статистического материала. Он может быть обработан
различными способами, например, с помощью статистической или эмпирической ( т.е. выборочной)
функции распределения Fn* ( x) . Вероятность Р стремится к частоте.
Определение 8. Распределением выборки называется распределение дискретной случайной
1
величины, принимающей значения х1, х2,…, хn с вероятностями
, а соответствующая функция
n
распределения называется эмпирической функцией распределения.
Определение 9. Эмпирической (или статистической) функцией распределения случайной величины
Х называется закон изменения частоты события X x в данном статистическом материале:
Fn* ( x) P* ( X x) .
Fn* ( x) определяется по значениям накопленных относительных частот соотношением
Fn* ( x)
1
ni ,
n zi x
(т.е. суммируются частоты тех элементов, для которых выполняется неравенство zi x ).
Свойства Fn* ( x) .
1. Fn* ( x) 0 при x x(1) , где x (1) – первый элемент вариационного ряда.
2. Fn* ( x) 1 при x x(n ) , где x (n ) – последний элемент вариационного ряда.
3. Fn* ( x) – неубывающая кусочная постоянная функция на промежутке ( x(1) , x( n ) ]
Аналогично определяется эмпирическая функция распределения для группированной выборки.
ВЫВОД. Если результаты выборки представлены в виде таблицы частот или группированной
таблицы частот, то значения Fn* ( x) берут по данным последнего столбца (отсутствует первое нулевое
значение).
6
Теорема Гливенко. Пусть Fn* ( x) – эмпирическая функция распределения, построенная по выборке
объема n из генеральной совокупности с функцией распределения FX (x) . Тогда для любого x (,)
и любого положительного 0 следует, что lim P Fn* ( x) FX ( x) 1 .
n
Т.е. Fn* ( x) и FX (x) сходятся по вероятности, следовательно, при большом n, Fn* ( x) может служить
приближенным значением (оценкой) функции распределения генеральной
точке х.
совокупности в каждой
Эмпирическая функция распределения дает представление о функции распределения и
используется в основном в статистической проверке гипотез. Кроме того, эмпирическая функция
распределения используется для определения эмпирических (выборочных) квантилей.
Определение 10. Квантилем порядка p (0 < p < 1) называется величина xp, определяемая из
соотношения P{X < xp} = F(xp) = p.
Выборочный квантиль xp определяется из соотношения Fn* ( x p ) p .
Задавая p, можно по графику эмпирической функции распределения оценить, например, значение
xp, которое исследуемая величина не превзойдет с вероятностью p, либо, задавая xp, по тому же графику
оценить соответствующую вероятность p .
Пример 7. Построить график эмпирической функции распределения выборки из примеров № 4, № 5
и группированной выборки из примера № 6. Оценить вероятность того, что ошибка будет меньше 7.
Решение.
1)
Рассмотрим таблицу частот примера № 4. Данные последнего столбца (накопленные
относительные частоты) – есть значения функции распределения без первой (нулевой) строки.
0, z 1
0,25, 1 z 2
Fn ( x) 0,55, 2 z 3
0,65, 3 z 4
1, z 4
2). Рассмотрим статистический ряд примера 5:
zi
ni
-15 -12 -8
1
1 2
1
Fn* ( x) ni .
n zi x
x ≤ –15
–15 < x ≤ –12
–12 < x ≤ –8
–8 < x ≤ –6
–5 < x ≤ –4
-6 -5
1 1
-4
1
-2
1
3
1
5
1
10
2
12
1
14
1
15
2
16
1
18
1
20
2
Fn ( x) 0
1
1
(– 15 наблюдается 1 раз, n = 20 и его частота равна
)
20
20
1
1
1
1
Fn ( x)
(– 15 наблюдается 1 раз, – 12 также 1 раз, их частоты
)
20
20 20 10
1
1
2 1
1
1
2
1 1
Fn ( x)
Fn ( x)
–6 < x ≤ –5
20 20 20 5
20 20 20 20 4
3
7
Fn ( x)
Fn ( x)
–4 < x ≤ –2
10
20
Fn ( x)
7
8
3
20
Fn ( x)
20
Замечание. Можно было составить таблицу частот. Данные
относительные частоты) – есть значения функции распределения.
–2 < x ≤ 3
Fn ( x)
9
20
3
Fn ( x)
5
14
Fn ( x)
20
17
Fn ( x)
20
Fn ( x)
Fn ( x) 1
последнего столбца (накопленные
3) Рассмотрим таблицу частот группированной выборки примера 6.
Середина первого интервала z1 = –12,5, следовательно, Fn* ( x) строят по данным 3 – го и последнего
столбцов.
x ≤ –12,5
Fn ( x) 0
–12,5 < x ≤ –7,5
Fn ( x) 0,1
–7,5 < x ≤ –2,5
Fn ( x) 0,25
–2,5 < x ≤ 2,5
Fn ( x) 0,4
2,5 < x ≤ 7,5
Fn ( x) 0,45
Fn ( x) 0,5
12,5 < x ≤ 17,5
7,5 < x ≤ 12,5
x > 17,5
Fn ( x) 0,7
Fn ( x) 1
Замечание. Можно было не считать, получили данные последнего столбца таблицы группированной
выборки.
0, x 12.5
0.1, 12.5 x 7.5
F*(x)
1
0.25, 7.5 x 2.5
0.4, 2.5 x 2.5
Fn ( x)
0,75
0.45, 2.5 x 7.5
0.5, 7.5 x 12.5
0,5
0.7, 12.5 x 17.5
1, x 17.5
0,25
х
-15
-10 -5
О 5
10 15 20
Оценим вероятность того, что ошибка будет меньше 7: P(X < 7) = F*n(7) ≈ 0,45.
Пример 8. Имеется выборка: –3; 2; –1; –3; 5; –3; 2. Построить график эмпирической функции
распределения.
Решение.
Здесь n = 7, х1 = х4 = х6; х2 = х7.
Выборка небольшая. Запишем ее в виде вариационного ряда: –3; –3; –3; –1; 2; 2; 5. Разобьем на
интервалы точками –3; –1; 2; 5. Построим статистическую совокупность (с помощью накопленных
частот), предварительно записав частоты:
8
0, x 3
3, 3 x 1
частоты ni 1, 1 x 2 , накопленные частоты:
2, 2 x 5
1, x 5
F*(x)
0, x 3
3, 3 x 1
i
n
(
x
)
=
n
4, 1 x 2
j
j 1
6, 2 x 5
7, x 5
значит,
0, x 3
3 / 7, 3 x 1
F * ( x) 4 / 7, 1 x 2
6 / 7, 2 x 5
1, x 5
1
6/7
4/7
3/7
х
-3
-1
2
О
5
Пример 9. По выборке объема 9 найдена эмпирическая функция распределения ДСВ.
0, x 5
1
,5 x 8
3
*
Fn ( x)
2 ,8 x 11
3
1, x 11
Сколько раз в этой выборке наблюдалось возможное значение 8?
Решение.
Объем выборки – n = 9.
относительными частотами.
i
xi
1
5
2
8
3
11
ni
n
1
3
1
3
1
3
Fn* ( x)
1
ni . Составим таблицу частот, добавив столбец с
n zi x
ni
3
3
3
9
n
n
2 1 1
n2 1
9
n
n
2 1
n1 n1 1
n2 3 3) 3 3 1
n1 3 2) 2 2
3
n
9 3 3 3
9 3
3
n
9
3 3
n 9 3
9
n3 3 .
Ответ. Возможное значение 8 наблюдалось 3 раза.
3
1)
П. 4. Гистограмма и полигон частот
Кроме графика эмпирической функции распределения для наглядного представления выборки
бывает полезно построить гистограмму и полигон частот.
9
Графическим изображением статистического ряда и статистической совокупности (группированного
статистического ряда) является гистограмма (ввел Карл Пирсон).
Определение 11. Гистограммой относительных частот статистической совокупности называется
кусочно-постоянная функция, постоянная на интервалах совокупности и принимающая на них все
n
значения i , где ni частота, n объем выборки, b длина интервала, i =1, 2, …, k, k – количество
bn
интервалов.
n
На каждом интервале, как на основании, строится прямоугольник с высотой h i , площадь
bn
n
которого равна относительной частоте данной группы Si i . Полная площадь ступенчатой фигуры
n
k
под графиком гистограммы равна 1: S Si 1 .
i 1
Замечание. При увеличении объема выборки и уменьшении интервала группировки гистограмма
относительных частот является статистическим аналогом плотности распределения fX(x) генеральной
совокупности.
Определение 12. Гистограммой частот группированной выборки называется кусочно-постоянная
n
функция, постоянная на интервалах группировки и принимающая на них все значения i , где
b
ni частота, b длина интервала, i =1, 2, …, k, k – количество интервалов.
ni
, площадь
b
которого равна частоте данной группы Si ni . Полная площадь ступенчатой фигуры под графиком
На каждом интервале, как на основании, строится прямоугольник с высотой h
гистограммы равна объему выборки, т.е. S n .
Пример 10. Построить гистограмму относительных частот выборки из примера 5.
Решение.
Ко 2-му и 4-му столбцам полученной в примере 5 таблицы для удобства добавим столбец со
n
значениями h i , столбцы 1 и 2 удалим. Количество интервалов k = 7. Длина интервала b 5 .
bn
Объем выборки n = 20. В итоге получим:
Границы группы
(–15 ) – (–10)
(–10) – (–5)
(–5) – 0
0–5
5 – 10
10 – 15
15 – 20
ni
n
0,1
0,15
0,15
0,05
0,05
0,2
0,3
Относительная частота
h
ni
bn
0,02
0,03
0,03
0,01
0,01
0,04
0,06
10
ni
bn
0,06
7
i 1
0,02
-15
-10 -5
7
ni
1
i 1 n
S Si
0,04
х
О 5
10
15
20
Пример 11. Построить гистограмму частот группированной выборки из примера 6.
Решение.
В полученной в примере таблице частот группированной выборки оставим лишь 2-ой и 4-ой
n
столбец. Добавим еще один столбец со значениями h i . Длина интервала b 5 . Количество
b
интервалов k = 7. Объем выборки n = 20. В итоге получим:
Границы
интервалов
(–15 ) – (–10)
(–10) – (–5)
(–5) – 0
0 –5
5 – 10
10 – 15
15 – 20
Частота
ni
2
3
3
1
1
4
6
ni
b
h
ni
b
0,4
0,6
0,6
0,2
0,2
0,8
1,2
7
7
i 1
i 1
S Si ni n 20
1,2
0,8
0,4
-15
-10 -5
О 5
х
10
15
20
Аналогом плотности вероятностей (кроме гистограммы) является и полигон частот.
Определение 13. Полигоном частот выборки х1, х2,…, хn называется ломаная с вершинами в
точках ( xi , ni ) , где ni частота.
Вместо чисел ni часто используют относительную частоту
ni
. В результате получим полигон
n
относительных частот выборки.
Определение 14.1. Полигоном относительных частот статистической совокупности называется
n
ломаная с вершинами в точках ( zi , i ) , где ni частота, n объем выборки, zi середины интервалов,
bn
i =1, 2, …, k, k – количество интервалов, b – длина интервала.
11
Определение 14.2. Полигоном частот группированной выборки называется ломаная с вершинами
n
в точках ( zi , i ) , где ni частота, zi середины интервалов, i =1, 2, …, k, k – количество интервалов,
b
b – длина интервала.
Замечания.
1. Полигон относительных частот получается из полигона частот сжатием по оси (оу) в n раз.
2. По гистограмме и полигону частот судят о виде плотности распределения исследуемой
непрерывной случайной величины или о распределении вероятностей дискретной случайной величины.
Если плотность вероятности распределения генеральной совокупности является достаточно гладкой
функцией, то полигон частот является более хорошим приближением плотности, чем гистограмма.
3. Чтобы построить полигон, если задана гистограмма, то достаточно только соединить отрезками
ломаной середины верхних оснований прямоугольников, из которых состоит гистограмма.
Пример 12. Построить полигон частот выборки из примера 7: –3; 2; –1; –3; 5; –3; 2.
Решение.
Для решения построим статистический ряд. Следовательно, полигон – ломаная будет проходить
через точки
(–3;3), (–1;1), (2;2), (5;1).
zi
–3
–1
2
5
ni
3
1
2
1
ni
3
2
zi
1
–3
–1
2
5
Пример 13. Построить полигон частот группированной выборки из примеров 6,10.
Решение.
1,2
ni
В примере 10 построили гистограмму частот
b
группированной выборки. С ее помощью и
0,8
построим полигон, проведя ломаную через середины
верхних оснований прямоугольников.
0,4
х
-15
О 5
-10 -5
15
20
Пример 14. Дана выборка объема 5. Для ее наглядного представления
построена гистограмма частот. Найти значение а.
Решение.
ni
b
а
0,7
0,6
0,4
xi
O
10
2
4 6
8
Это гистограмма частот группированной выборки. В этом случае
полная площадь ступенчатой фигуры под графиком гистограммы равна
объему выборки, т.е. S n 5 , следовательно, для вычисления а надо
найти площадь ступенчатой фигуры:
S 2 0,4 2 0,7 2 0,6 2 a n 5 , отсюда a 0,8 .
12
П. 5. Числовые характеристики выборочного распределения
Пусть х1, х2,…, хn – выборка объема n из генеральной совокупности с функцией распределения Fn* ( x)
или FX* ( x) .
Определение 15. Выборочное распределение – распределение дискретной случайной величины Х,
1
принимающей значения х1, х2,…, хn с вероятностями, равными .
n
Определение 16. Выборочными (эмпирическими) числовыми характеристиками называются
числовые характеристики выборочного распределения.
Они являются характеристиками данной выборки, но не являются характеристиками распределения
генеральной совокупности.
Определение 17. Основные числовые характеристики – выборочное среднее m*X
(традиционное
обозначение x В ), выборочная дисперсия – DX* ( D * , DB ), которые могут быть найдены по формулам:
xB m*X
1 n
xi ,
n i 1
(1)
1 n
1 n 2
1 n 2
2
2
D DB ( xi x ) xi n x xi x 2 .
n i 1
n i 1
n i 1
*
X
(2)
Определение 18. Выборочной модой M * d X* унимодального распределения называется элемент
выборки, встречающийся с наибольшей частотой.
Определение 19. Выборочной медианой Me* hX* распределения называется число, которое делит
вариационный ряд на две части, содержащие равное число элементов.
Замечание. Если объем выборки n – нечетное число:
n = 2l + 1, то hX* x (l 1) ,
т.е. является элементом вариационного ряда со средним номером.
1
Если объем выборки n –четное число: n = 2l, то hX* [ x (l ) x (l 1) ] .
2
(3)
(4)
Пример 15. Определить среднее, дисперсию, моду и медиану для выборки: 5, 6, 8, 2, 3, 1, 1, 4.
Решение.
Представим данные в виде вариационного ряда: 1, 1, 2, 3, 4, 5, 6, 8.
n = 8.
n
1
1
Выборочное среднее: x m*X xi [1 1 2 3 4 5 6 8] 3,75 .
8 i 1
8
1
1 n
Выборочная дисперсия: DX* xi2 n x 2 ([12 12 22 32 42 52 62 82 ] 8 3,752 ) 5,6875
n i 1
8
Все элементы входят в выборку по одному разу, кроме 1, следовательно, d X* 1 .
1
Так как объем выборки n = 8 –четное число hX* [3 4] 3,5 .
2
Пример 16. Определить моду и медиану для выборки: 2, 8, 3, 5, 1, 5, 7, 5, 2.
Решение.
Представим данные в виде вариационного ряда: 1, 2, 2, 3, 5, 5, 5, 7, 8.
13
Чаще всех в выборке встречается элемент 5, следовательно, d X* 5.
Объем выборки n = 9 – нечетное число, следовательно, медиана – элемент вариационного ряда со
средним пятым номером, т.е hX* 5 .
Замечание 1. Если выборка представлена в виде статистического ряда
(в некоторых учебниках в статистическом ряду вместо z пишут х)
то выборочное среднее находится по формуле
выборочная дисперсия:
xB m*X
1 n
( zi ni ) ,
n i 1
zi z1
z2 … zk
ni n1
n2 … nk
(5)
2
2
1 n
1 n
DX* zi2 ni n m*X zi2 ni m*X ,
n i 1
n i 1
(6)
выборочная мода M * d X* – элемент выборки zi, встречающийся с наибольшей частотой ni,
выборочная медиана
Me* hX* – элемент со
Замечание 2.
Если дана группированная
(k интервалов длины b)
Границы интервалов (a1, a2]
(a2, a3]
частота
n1
n2
средним
номером.
выборка в виде статистической совокупности
…
…
(ak, ak+1]
nk
где zi – середины интервалов, то формулы для вычисления выборочных значений аналогичны формулам
замечания 1.
Определение 20. Выборочным начальным моментом порядка s
называется выборочное
1 n
математическое ожидание s – ой степени случайной величины Х: *[ X ] M *[ X S ] xiS .
n i1
Определение 21. Выборочным центральным моментом порядка s называется:
1 n
*[ X ] M *[( X m*X ) S ] ( xi m*X ) S .
n i 1
Замечание. При увеличении числа наблюдений, т.е. при n , все статистические характеристики
будут сходиться по вероятности к соответствующим числовым характеристикам случайной величины и
при достаточном n могут быть приняты приближенно равными им.
§ 2. Статистическое оценивание характеристик распределения генеральной
совокупности по выборке
П. 1. Точечные оценки и их свойства
Пусть закон распределения случайной величины Х содержит неизвестный параметр а. Требуется на
основании опытных данных найти подходящую оценку этого параметра, т.е. найти его приближенное
значение.
Пусть х1, х2,…, хn – наблюдаемые значения Х в результате n независимых опытов. Тогда, если a~
оценка параметра а, то она является функцией величин х1, х2,…, хn: a~ a~( x1, x2 ,…, xn ) .
Определение 22. Точечной оценкой a~ неизвестного параметра генеральной совокупности а
называют приближенное значение этого параметра, полученное при выборке. Оценки называются
14
точечными, так как они указывают точку на числовой оси, в которой должно находиться значение
неизвестного параметра.
Определение 23. Любую функцию элементов выборки называют статистикой.
Для того, чтобы a~ имела практическую ценность, она должна обладать определенными свойствами.
Чтобы выяснить, какие свойства должна иметь статистика a~( x1 , x2 ,…, xn ) для того, чтобы ее значения
могли бы считаться хорошей в некотором смысле оценкой параметра а, ее рассматривают как функцию
случайного вектора (Х1, Х2,…, Хn), одной из реализаций которого является данная выборка х1, х2,…, хn.
Распределение статистики a~ также зависит от параметра а. a~ случайная величина, закон
распределения которой зависит от закона распределения Х и от числа опытов n. Итак, статистика
должна обладать следующими свойствами:
Свойства статистики.
1. Несмещенность оценки.
Определение 24. Смещенными называются оценки, математическое ожидание которых не равно
M [a~( X1 , X 2 ,…, X n )] a . Несмещенными называются оценки, для
оцениваемому параметру, т.е.
которых справедливо: M [a~( X , X ,…, X )] a .
1
2
n
В качестве приближенного неизвестного параметра лучше брать несмещенную оценку для того,
чтобы не делать систематической ошибки в сторону завышения или занижения.
2. Состоятельность оценки.
Определение 25. Оценка a~ для параметра а называется состоятельной, если она сходится по
вероятности к оцениваемому параметру при неограниченном возрастании числа опытов:
lim[ a~ a ] 1 для любого положительного .
n
Т.е. состоятельность означает, что при n отклонение оценки от истинного значения параметра а
меньше заданного малого положительного числа .
Для выполнения равенства достаточно, чтобы D[a~] 0 , где a~ – несмещенная оценка.
n
3. Эффективность оценки.
Определение 26. Оценка
~
D[a ( X1, X 2 ,…, X n )] Dmin .
называется
эффективной,
если
она
обладает
свойством:
Чем меньше дисперсия оценки, тем меньше вероятность грубой ошибки при определении
приближенного значения параметра.
Определить приближенное значение измеряемой величины Х – значит произвести оценку
математического ожидания Х. При этом, если СВ Х – постоянная, то оценка для математического
ожидания – приближенное значение истинного значения измеряемой величины; а если измеряемая
величина Х – случайная, то оценка для математического ожидания – приближенное значение
математического ожидания измеряемой случайной величины.
Необходимость получения по опытным данным приближенного значения дисперсии возникает в
связи с определением характеристики точности прибора или характеристики рассеивания измеряемой
случайной величины.
Измерения бывают равноточные, т.е. проводятся в одинаковых условиях, например, одним и тем же
прибором, и неравноточные, т.е каждое измерение характеризуется своей величиной рассеивания.
15
Если в результате проведенных n независимых равноточных измерений случайной величины Х
с неизвестными математическим ожиданием mX и дисперсией DX получены ее приближенные
значения х1, х2,…, хn , то для определения приближенных значений математического ожидания и
дисперсии пользуются следующими оценками:
1) Оценки для оценки математического ожидания.
n
~
m
x
i 1
i
– состоятельная несмещенная оценка,
n
~ m* x .
она совпала с выборочным средним, т.е. m
B
(7)
n
~
Замечание. Если задан статистический ряд, то m
z n
i i
i 1
n
.
(8)
n
~
Если в статистическом ряду стоят xi, то m
xn
i i
i 1
n
.
2) Оценки для дисперсии.
Смещенной
оценкой
генеральной
дисперсии
служит
выборочная
дисперсия
n
1 n
~ ) 2 1 x 2 m
~ 2.
DX* ( xi m
(9)
i
n i 1
n i 1
Так как оценка смещенная, то вводят поправочный коэффициент и находят исправленную
~
выборочную дисперсию D .
Состоятельной
и
несмещенной
оценкой
служит
исправленная
дисперсия:
n 2
xi
n
1
n i 1
n
~
2
2
*
~
~
m .
D
D
( xi m)
n 1 i 1
n 1
n 1 n
~
D ~ 2 S 2 , где S – выборочное средне квадратическое отклонение
(10)
(11)
(ввел и исследовал К.Пирсон)
Замечание. Если задан статистический ряд, то смещенной оценкой генеральной дисперсии служит
выборочная дисперсия DX*
n
2
1 n
~ ) 2 , 1
zi2 ni m*X ,
ni ( zi m
n i 1
n i 1
n
~
D*
несмещенной состоятельной оценкой– исправленная дисперсия: D
n 1
n
ni zi2
n i 1
~
2
~
m .
или D
n 1 n
В некоторых учебниках вместо z пишут х.
(12)
(13)
(13/)
Замечание. Во избежание громоздких вычислений по формулам (1) – (7) на практике иногда
целесообразнее вместо них использовать формулы:
16
n
( xi a) 2
n i 1
~
2
~
~
i 1
,
D
(
m
a
)
.
m
a
n 1
n
n
Число а находим подбором, исходя из условий задачи.
n
( x a)
i
Асимметрия Sk находится по формуле
Sk
3
, где
X3
(14)
3 [ X ]
1 n
( xi mX )3 (ввел Пирсон).
n i1
4
1 n
3
,
где
[
X
]
( xi mX ) 4
4
4
n i 1
X
~
Эксцесс находится по формуле Ex
V
~
(15)
~ , x 0.
x m
С помощью числовых характеристик можно определить является ли выборочное распределение
близким к нормальному. Если выборочное распределение близко к нормальному (или является
таковым), то:
1) в интервалы xB ~ , xB 2~ , xB 3~ должны попадать соответственно приблизительно 68%,
Коэффициентвариации
95% и 100% выборочных значений;
2) в не слишком маленькой выборке величина коэффициента вариации должна быть не более 33% ,
то есть V < 0,33.
3) выборочное среднее приближенно равно медиане xB hX* ;
4) oценка эксцесса и коэффициента асимметрии должны быть близки к нулю.
Пример 17. Проведено 5 измерений (без систематических ошибок) некоторой случайной величины
в мм: 4, 5, 8, 9, 11. Найти несмещенную оценку математического ожидания.
Решение.
n
~ m*
n = 5. Данная оценка находится по формуле (1): m
x
i 1
i
n
4 5 8 9 11 37
7,4 .
5
5
Пример 18. В результате измерения некоторой случайной величины (без систематических ошибок)
получены следующие результаты в мм: 11, 13, 15. Найти несмещенную оценку дисперсии.
Решение.
n = 3. Данная оценка находится по формуле (4). Чтобы ею воспользоваться, необходимо сначала
n
~
найти оценку математического ожидания по формуле (1): m
x
i 1
n
i
11 13 15
13.
3
n 2
xi
n i 1
3 112 132 152
~
2
~
m
132 3,99 4 .
Тогда D
2
n 1 n
3
Пример 19. Через каждый час измерялось напряжение тока в электросети. Результаты измерений
представлены в виде таблицы значений:
i
1
2
3
4
5
6
7
xi, в
222
219
224
220
218
217
221
Найти оценки для математического ожидания (среднего) и дисперсии результатов измерений.
17
Решение.
n
~
1) n = 7. Оценка среднего находится по формуле (1): m
x
i 1
n
i
1541
220,14285 , т.е. в среднем в
7
сети было напряжение 220,14 вольт.
2) Эту же оценку найдем по первой из формул (14), положив а = 220.
n
~
m
( xi a)
i 1
n
3)
7
a
( x 220)
i 1
i
7
Оценка
220 220,14285 .
дисперсии
находится
по
формуле
(10):
2
2
xi
xi
n i 1
7 i 1
~
2
2
~
D
m
220,14285 5,8135 .
6 7
n 1 n
Пример 20. В результате измерения температуры раздела фракции бензин-авиакеросин на
установке первичной переработки нефти были получены значения температур, приведенные в таблице
(в градусах Цельсия).
N
Знач N
Значен N
Значе N
Значен
ение
ие
ние
ие
1
133,5 14
141,5
27
144,0
40
137,5
2
142,0 15
139,0
28
142,5
41
141,5
3
145,5 16
140,5
29
139,0
42
141,0
4
144,5 17
139,0
30
137,0
43
142,5
5
134,5 18
143,5
31
136,0
44
143,5
6
138,5 19
139,5
32
137,0
45
141,0
7
144,0 20
140,5
33
138,5
46
147,0
8
141,0 21
140,0
34
139,0
47
139,5
9
141,5 22
138,5
35
139,5
48
136,5
10
139,5 23
135,0
36
140,5
49
142,0
11
140,0 24
139,5
37
139,5
50
140,0
12
145,0 25
139,0
38
140,0
13
141,5 26
138,0
39
140,5
Провести предварительную проверку на нормальность.
Решение.
n
7
n 2
xi
7010
n i 1
~
2
~
~
i 1
mx
140,2 , D
m 7,755,
тогда ~ 2,78 . Коэффициент
n 1 n
n
50
~
2,78
V
0,02 . Медина hX* =140,0 (для ее нахождения требовалось записать
вариации
x 140,2
вариационный или статистический ряд).
n
xi
Эксцесс Ex
4
3 = 0,19, асимметрия Sk 33 = 0,0083.
4
X
X
Проверим на нормальность.
1) в интервалы xB ~ = 140,2 ± 2,78, xB 2~ = 140,2 ± 5,56, xB 3~ = 140,2 ± 8,34 попали
соответственно приблизительно 70%, 94% и 100% выборочных значений;
2) V = 0,02 < 0,33;
18
~ x 140,2 h* 140,0 .
3) m
B
X
4) oценка эксцесса и коэффициента асимметрии близки к нулю.
Ответ: Предварительный анализ показывает, что распределение температуры раздела фракции
бензин-авиакеросин не противоречит предположению о нормальности.
Если в результате проведенных n независимых неравноточных измерений случайной величины
Х получены ее приближенные значения х1, х2,…, хn , дисперсии которых соответственно равны
Dx1 x21 , Dx2 x22 ,…, Dxn x2n , то для определения приближенного значения математического
ожидания следует пользоваться оценкой, которая является несмещенной, состоятельной и эффективной,
а именно:
n
~
m
n
[ x g ]
i 1
i 1
n
i
g
i 1
i
,
gi
где
1
x2
вес i – го измерения.
(16)
i
i
Пример 21. Проводились измерения специальной меры длины. Результаты измерений приведены в
таблице. Известно, что дисперсии погрешностей измерений по приборам имели следующие значения:
D1 12 0,32; D2 22 0,25; D3 32 0,5; D4 42 0,16 . Оценить отклонение действительного размера
меры от номинального ее размера.
№ измерения
1
2
3
Сумма
Отклонение от номинального размера, мк.
Прибор № 1
Прибор № 2
Прибор № 3
10,3
10,8
9,9
10,5
11,2
10,6
–
10,7
–
20,8
32,7
20,5
Прибор № 4
11,3
11,1
10,4
32,8
Решение.
Всего 10 результатов измерений, т .е. n = 10. Найдем вес каждого измерения.
1
1
1
1
1
1
№1: g1 g 2 2
, № 2: g3 g 4 g5 2
, № 3: g6 g 7 2
,
1 0,32
2 0,25
3 0,5
№ 4: g8 g9
1
42
1
.
0,16
Тогда
10
g
i 1
i
41 .
Найдем оценку математического ожидания по формуле (10):
n
1
1
1
1
[
xi gi ] 20,8
32,7
20,5
32,8
0,32
0,25
0,5
0,16
~ i 1 i 1
m
10,67 .
n
41
gi
n
i 1
П. 2. Методы статистического оценивания: метод подстановки, метод
максимального (наибольшего правдоподобия, метод моментов)
1 метод для нахождения оценок параметров по данным опыта – метод подстановки или аналогии
– простейший метод статистического оценивания. Он состоит в том, что в качестве оценки той или иной
числовой характеристики (среднего, дисперсии и др.) генеральной совокупности берут
19
соответствующую характеристику распределения выборки, т.е. выборочную характеристику.
выше).
(См.
Пример 22. Пусть х1, х2,…, хn – выборка из генеральной совокупности с конечным математическим
ожиданием m и дисперсией D. Используя метод подстановки, найти оценку m. Проверить
несмещенность и состоятельность полученной оценки.
Решение.
~
В качестве оценки m математического ожидания m надо взять математическое ожидание
n
~x
распределения выборки, т.е. выборочное среднее x : m
B
x
i 1
i
.
n
Проверим несмещенность и состоятельность полученной оценки. Для этого рассмотрим эту
~m
~ ( X , X ,…, X ) . По определению (23) проверим
статистику как функцию выборочного вектора: m
1
2
n
несмещенность оценки:
n
n
~ ( X , X ,…, X )] M [ 1 X ] 1 M [ X ] 1 n m m . Действительно,
M [m
1
2
n
i
i
n i 1
n i 1
n
оценка математического ожидания m генеральной совокупности..
По определению (24) проверим состоятельность оценки:
~
m
–несмещенная
n
n
1
2
2
~ ( X , X ,…, X )] D[ 1 X ] 1
,
D[m
D
[
X
]
n
1
2
n
i
i
n i 1
n 2 i 1
n2
n
~ ] 0 , следовательно,
D[m
n n
генеральной совокупности.
2
~–
m
состоятельная
оценка
математического
ожидания
m
2 метод для нахождения оценок параметров по данным опыта – метод наибольшего (или
максимального) правдоподобия. Данный метод является одним из наиболее распространенных
методов нахождения оценок неизвестных параметров распределения генеральной совокупности.
1) Пусть Х – непрерывная случайная величина с плотностью распределения f X ( x, a) , зависящей от
неизвестного параметра а, значение которого требуется оценить по выборке объема n. Плотность
распределения выборочного вектора ( X1, X 2 ,…, X n ) можно записать в виде
n
f X 1 , X 2 ,…,X n ( x1 , x2 ,…, xn , a) f X i ( xi , a) .
i 1
Пусть х1, х2,…, хn – выборка наблюдений случайной величины Х, по которой находится оценка
неизвестного параметра.
Определение 27. Функцией правдоподобия L(a) выборки объема n называется плотность
выборочного вектора, рассматриваемая при фиксированных значениях переменных х1, х2,…, хn:
n
L(a) f X i ( xi , a) .
i 1
Функция L(a) – функция только одного неизвестного параметра а.
2) Пусть Х – дискретная случайная величина, для которой вероятность P[ X x] p( x, a) – функция
неизвестного параметра а.
Пусть для оценки неизвестного параметра а получена конкретная
выборка наблюдений случайной величины Х объема n: х1, х2,…, хn.
20
Определение 28. Функцией правдоподобия L(a) выборки объема n называется вероятность того,
что компоненты дискретного выборочного вектора ( X1, X 2 ,…, X n ) , примут фиксированные значения
n
n
i 1
i 1
переменных х1, х2,…, хn: L(a) P[ X i xi ] p( xi , a) .
Сущность метода наибольшего правдоподобия заключается в том, что в качестве оценки
неизвестного параметра а принимается значение аргумента a~ , которое обращает функцию L(a) в
максимум. Такую оценку называют МП – оценкой или оценкой наибольшего правдоподобия.
(Для дискретного распределения Х МП-оценка неизвестного параметра а такое значение a~ , при
котором вероятность появления данной конкретной выборки максимальна; для непрерывного
распределения – плотность максимальна).
Согласно известным правилам дифференциального исчисления, для нахождения максимума
функции или, что то же самое, для нахождения оценки наибольшего правдоподобия необходимо решить
L
уравнение:
0
a
и отобрать то значение а, которое обращает функцию L в максимум.
Для упрощения вычислений в некоторых случаях функцию правдоподобия заменяют ее
логарифмом, т.е. используют логарифмическую функцию правдоподобия, и решают вместо уравнения
L
ln L 1 L
0 уравнение
0.
a
a
L a
В случае двух параметров а1 и а2 оценки их определяются из двух совместно решаемых уравнений
L
L
0,
0.
a1
a2
При выполнении некоторых условий МП-оценки асимптотически эффективны и асимптотически
нормально распределены. Метод всегда приводит к состоятельным оценкам (хотя иногда и
смещенным), имеющим наименьшую возможную дисперсию по сравнению с другими и наилучшим
образом (в некотором смысле) использующим всю информацию о неизвестном параметре,
содержащуюся в выборке.
На практике метод часто приводит к необходимости решать сложные системы уравнений.
Пример 23. Оценить качество продукции некоторого производства.
Решение.
Искомой величиной является вероятность р того, что наугад выбранное изделие окажется
бракованным. Вероятность р считается постоянной величиной, не зависящей от результатов проверки
других изделий. Для отыскания величины р из готовой продукции случайным образом отбирается n
изделий и проверяется их качество. Вероятность р можно рассматривать как параметр а, входящий в
распределение дискретной двузначной величины Х, принимающей только два значения х1 = 1, х2 = 0 в
зависимости от того, каким окажется наугад выбранное изделие: бракованным или хорошего качества.
Пусть среди наугад выбранных изделий оказалось m бракованных, тогда согласно определению (27)
имеем, что
n
L(a) P[ X i xi ] p m (1 p) n m , тогда уравнение (10) запишется в виде:
i 1
ln L ln[ p m (1 p)n m ] mpm 1 (1 p)n m p m (n m)(1 p)n m 1 (1) m n m
0.
a
p
p m (1 p)n m
p 1 p
21
m n m m mp np mp m np
0
p 1 p
p(1 p)
p(1 p)
m np 0 p
m
,
n
Следовательно, оценка вероятности р по методу наибольшего правдоподобия совпадает с частотой
m
события появления бракованных изделий.
n
3 метод – метод моментов, также используется для получения оценок неизвестных параметров а1,
а2,…, аs распределения генеральной совокупности. Пирсон предложил «метод моментов», как
позволяющий найти теоретический закон, наилучшим образом соответствующий эмпирической
выборке, для распределений, не соответствующих нормальному закону.
Пусть f X ( x, a1 ,…, as ) — плотность распределения случайной величины Х. Определим с помощью этой
плотности s каких-либо моментов случайной величины Х, например, первые s начальных моментов по
известным формулам:
m (a1 ,…, as ) M [ X m ]
x
m
f X ( x, a1 ,…, as )dx , где m = 1,…, s.
По выборке наблюдений случайной величины найдем значения соответствующих выборочных
1 n
моментов: m* xim .
n i 1
Попарно приравнивая теоретические моменты m случайной величины Х их выборочным значениям
m* , получаем систему s уравнений с неизвестными параметрами а1,…, аs:
m (a1 ,…, as ) m* , где m = 1,…, s.
Решая полученную систему
~
a1 ,…, a~s неизвестных параметров.
относительно
неизвестных
а1,…,
аs,
находим
оценки
Аналогично находятся оценки неизвестных параметров по выборке наблюдений дискретной
случайной величины.
П. 3. Распределения Хи-квадрат ( 2 ), Стьюдента (t-распределение)
и Фишера (F-распределение).
Распределения основных статистик, вычисляемых по выборке из нормально распределенной
генеральной совокупности, связаны с распределениями Хи-квадрат, Стьюдента и Фишера
(распределения случайных величин, являющихся функцией случайных величин). Квантили этих
распределений приведены в специальных таблицах.
(Квантилем порядка p (0 < p < 1) называется величина xp, определяемая из соотношения P{X < xp} =
F(xp) = p.)
1. Распределение Хи-квадрат ( 2 ).
Пусть Хi – независимые случайные величины, распределенные по нормальному закону, причем
М[Xi] =0, X i 1 (i = 0,…, n), что означает, что СВ Хi имеют нормированное нормальное
распределение.
Определение 29. Число степеней свободы — число данных из выборки, значения которых могут
быть случайными, могут варьироваться.
22
Определение 30. Распределением 2 с k степенями свободы называется распределение случайной
величины 2 (k ) , равной сумме квадратов независимых нормально распределенных по закону N(0, 1)
случайных величин Хi, i = 1, 2,…, k , то есть распределение случайной величины
k
2 X i2 = Х 12 Х 22 … Х k2 .
i 1
Дифференциальная
функция
(плотность)
этого
распределения
имеет
вид:
1
x
e , x0
k
2 k
, где Г(х) – известная гамма-функция Г ( x) u x1e u du, Г(n+1)=n!.
f ( x) 2 Г
2
0,
x0
С увеличением числа степеней свободы 2 — распределение стремится к нормальному.
k 2
x
1
2
2
Среднее и дисперсия распределения 2 равны соответственно M [ 2 ] k , D[ 2 ] 2k .
Распределение 2 часто используется в статистических вычислениях, в частности, в связи со
следующей теоремой.
Теорема. Пусть x1 ,…, xn — выборка из нормально распределенной генеральной совокупности
N (m, ) ,
m* x
1 n
xi ,
n i 1
D* s 2
1 n
( xi x ) 2 — соответственно выборочное среднее и
n 1 i 1
выборочная дисперсия. Тогда статистики X и S 2 — независимые случайные величины, причем
(n 1) 2
статистика
S имеет распределение 2 (n 1) .
2
Замечание. Если 2 (k1 ) и 2 (k 2 ) — независимые случайные величины, имеющие распределение
2 с k1 и k 2 степенями свободы соответственно, то сумма этих случайных величин имеет
распределение 2 с ( k1 + k 2 ) степенями свободы: 2 (k1 ) + 2 (k 2 ) = 2 ( k1 + k 2 ).
Распределение 2 при больших значениях k (k > 30) с достаточной для практических расчетов
точностью аппроксимируются нормальным распределением. Это свойство используется для
приближенного выражения квантилей p2 (k ) распределения 2 через квантили нормального
распределения. (Существуют специальные формулы)
2. Распределение Стьюдента (t –распределение).
Определение 31. Пусть случайная величина Х имеет нормированное нормальное распределение, то
есть М[X] =0, X i 1 . У – независимая от Х случайная величина распределена по закону 2 с k
X
имеет распределение Стьюдента, или t–
Y
k
распределение. С увеличением k t–распределение также стремится к нормальному закону.
k
, k 2.
Распределение Стьюдента с с k степенями свободы имеет среднее M [T ] 0, D[T ]
k 2
k 1
k 1
2 2
x
2
1 , x , где Г(х) – известная гамма-функция
плотность f T ( x)
k
k
k
2
степенями свободы, то есть Y 2 (k ) , тогда величина T
Г ( x) u x 1e u du . Г(n+1) = n!
23
Плотность распределения симметрична относительно оси ординат, следовательно для квантилей
имеет место соотношение: t p (k ) t1 p (k ) . При больших значениях k (k > 30) с достаточной для
практических расчетов точностью аппроксимируются нормальным распределением.
Доказано, что при нормальном распределении величины Х с математическим ожиданием, равным
n
нулю,
и
дисперсией,
равной
единице,
случайная
величина
~m
m
T n ~ ,
где
~
m
x
i
i 1
n
,
n
~
D
( x m~ )
i 1
2
i
n 1
, подчиняется закону распределения Стьюдента с n–1 степенью свободы; а плотность
этого закона имеет вид f n1 (t )
n
n
Г
2
2
t
2
1
.
n 1 n 1
(n 1) Г
2
3. Распределение Фишера (F- распределение).
Пусть Х и У — независимые случайные величины, распределенные по закону
2 с k1 и с k2
X
k
степенями свободы соответственно, тогда величина F 1 имеет распределение Фишера, или FY
k2
распределение со степенями свободы k1 и k2. С увеличением k1 и k2 распределение Фишера стремится к
нормальному закону.
§ 3. Интервальные оценки.
Доверительный интервал и доверительная вероятность
Изучаемая генеральная совокупность может быть очень большой, поэтому с целью экономии
времени и материальных ресурсов случайным образом производят выборку из генеральной
совокупности. Для нее вычисляют выборочную среднюю, выборочную дисперсию и интересующие
параметры. Как оценить параметры генеральной совокупности, зная эти параметры для выборки?
В ряде задач требуется не только найти для параметра а генеральной совокупности подходящее
числовое значение, но и оценить его точность и надежность. (Особенно при малом числе наблюдений).
Точечная оценка в значительной мере является случайной, и приближенная замена а на a~ aB может
привести к серьезным ошибкам.
Для определения точности оценки a~ пользуются доверительными интервалами, а для
определения надежности – доверительными вероятностями.
Определение 32. Доверительный интервал – это интервал значений, в пределах которого, как можем
надеяться, находится параметр генеральной совокупности.
Определение 33. Доверительная вероятность – вероятность, с которой доверительный интервал
захватит истинное значение параметра генеральной совокупности.
Пусть для параметра а получена из опыта несмещенная оценка a~ . Требуется оценить возможную
при этом ошибку. Зададим некоторую вероятность β и найдем значение 0 , для которого справедливо
равенство:
24
P( a~ a )
P( a a~ )
или
(*)
т.е. P(a~ a a~ ) , следовательно, неизвестное значение параметра а с вероятностью β
попадет в интервал
(17)
l (a~ ; a~ ) ,
точнее, что случайный интервал l накроет точку a~ .
l
a~
a~ а
a~
Определение 34. Интервал l называется доверительным интервалом. Вероятность β называется
доверительной вероятностью или надежностью или коэффициентом доверия (выбирается
исследователем).
Величина задает границы доверительного интервала, то есть определяет точность интервальной
оценки.
Коэффициент доверия имеет следующий смысл: если мы будем повторять выборку и для каждой из
них находить доверительный интервал, то в среднем на 100 выборок доля тех интервалов, которые
накроют оцениваемый параметр, составит β∙100%. Чем выше доверительная вероятность, тем шире
доверительный интервал.
Задача. Построить доверительный интервал l , соответствующий доверительной вероятности β,
для математического ожидания m величины Х. (То есть параметр а — математическое ожидание m
генеральной совокупности).
Решение.
Воспользуемся тем, что величина m представляет собой сумму n независимых одинаково
распределенных случайных величин Xi , и, согласно центральной предельной теореме, при достаточно
большом n ее закон распределения близок к нормальному. То есть будем исходить из того, что величина
~ (математическое ожидание выборки, состоятельная несмещенная оценка) распределена по
m
нормальному закону. Характеристики этого закона – математическое ожидание и дисперсия, равные
D
соответственно
m
и
.
Найдем величину , для которой справедливо равенство
n
(*) P( a a~ ) , то есть построим доверительный интервал для математического ожидания:
~ ) 2Ф 1 2Ф 1
P( m m
~
~
m
m
(рассматривается функция Лапласа вида
1
2
x
e
1
1
Ф
, отсюда m~ Ф-1
.
2
2
m~
u2
2
du ).
Дисперсия D, через которую выражена величина m~ , в точности не известна. В качестве ее
~
ориентировочного значения можно воспользоваться несмещенной оценкой D .
Вывод: доверительный интервал для математического ожидания при известной дисперсии
приближенно равен:
~ ;m
~ ),
l ( m
(18)
-1 1
где m~ Ф
2
, m~
~
D
.
n
(19)
25
1
2
для функции Лапласа вида
x
e
u2
2
du .
Замечание 1. На практике полезно свойство: если Ф-1(β) = х, то Ф(х)=β.
x
Замечание 2. а) Для функции Лапласа вида
б) Для функции Лапласа вида
u2
1
e 2 du значение m~ Ф-1 .
2 0
2
2
x
e
u 2
du значение m~ 2 Ф-1 .
Замечание 3. Можно сделать следующие выводы: а) при увеличении объема выборки n точность
интервальной оценки увеличивается, так как величина уменьшается. При больших n хорошей
~ x , т.е. точечная оценка; б) в силу того, что функция Ф(х) является
оценкой для m становится m
B
неубывающей, при увеличении надежности β растет величина , т.е. уменьшается точность (интервал
становится шире); в) для фиксированных значений надежности β и точности из формулы (13) можно
определить необходимый объем выборки, обеспечивающий заданное значение β
и . Следует
запомнить, что при неизменном объеме выборки одновременно увеличивать точность и надежность
оценки нельзя.
~
Замечание 4. Доверительный интервал для данных значений D и n можно представить с помощью
~
доверительной полосы графически. Границы полосы задаются уравнениями: m m
и
~ (m
~ x ). При росте n границы доверительной полосы будут стремиться к линии m x .
mm
B
B
Рассмотренный доверительный интервал симметричен относительно m xB , кроме того вероятность
превзойти левую либо правую границу интервала одинакова и равна
1
.
2
Замечание 5. Если удастся получить ориентировочное значение D~ , равное D~
0,8n 1,2 ~
D , то,
n(n 1)
аналогично тому, как был построен доверительный интервал для математического ожидания, можно
построить доверительный интервал для дисперсии:
~
~
l ( D ; D ) ,
(20)
-1 1
где D~ Ф
(рассматривается функция Лапласа вида
2
1
2
x
e
u2
2
du ).
Пример 24. В условиях примера 19 построить доверительные интервалы для математического
ожидания и дисперсии, соответствующие доверительной вероятности β = 0,86.
Решение.
В примере 19 нашли, что несмещенные оценки для математического ожидания (среднего) и
~
~ 220,14 ; D
несмещенной дисперсии результатов измерений равны m
5,81 , следовательно,
~
D
5,81
1
-1
m~
0,91 , тогда m~ Ф-1
0,91 Ф (0,93) = 1,3468.
n
7
2
~
Доверительные границы m m 220,14 1,35 218,79 ,
1
~ 220,14 1,35 221,49 .
m2 m
~ ;m
~ ) (218,79; 221,49).
Доверительный интервал для математического ожидания: l (m
26
~
Доверительный интервал для данных значений D и n можно представить с помощью
~ 1,3468 и
доверительной полосы графически. Границы полосы задаются уравнениями: m m
~ 1,3468 .
mm
D~
0,8 7 1.2
0,8n 1,2 ~
5,81 2,33779242 2,34 ,
D=
76
n(n 1)
1
тогда D~ Ф-1
≈ 2,34 ∙1,48 =3,4632 ≈ 3,46 .
2
~
~
Доверительный интервал для дисперсии: l ( D ; D ) =(2,35; 9,27).
Пример 25. Глубина моря измеряется прибором, случайные ошибки измерения распределены по
нормальному закону с 15 м. Сколько надо сделать измерений, чтобы определить глубину с
ошибкой не более 5 м при доверительной вероятности 0,9?
Решение.
~
D -1 1
15
1 0,9
Точность
Ф
Ф-1
, подставим данные задачи: 5
, отсюда
n
n
2
2
n = 3Ф-1 0,95 = 3·1,65. Тогда n = 24,5, то есть n = 25.
Точные методы построения доверительных интервалов для параметров случайной величины,
распределенной по нормальному закону
В данном пункте были рассмотрены грубо приближенные методы построения доверительных
интервалов для математического ожидания и дисперсии. Для точного нахождения интервалов
совершенно необходимо знать заранее вид закона распределения величины Х, тогда как для применения
приближенных методов это не обязательно. Идея точных методов построения доверительных
интервалов сводится к следующему.
Любой доверительный интервал находится из условия,
выражающего вероятность выполнения некоторых неравенств, в которые входит оценка a~ . Закон
распределения оценки a~ в общем случае зависит от самих неизвестных параметров величины Х. Однако
иногда удается перейти в неравенствах от случайной величины a~ к какой-либо другой функции
наблюдаемых значений Х1, Х2,…, Хn, закон распределения которой не зависит от неизвестных
параметров, а зависит только от числа опытов n и от вида закона распределения величины Х. Наиболее
подробно такие случайные величины изучены для случая нормального распределения величины Х.
Построение доверительного интервала для математического ожидания и дисперсии с
помощью критериев Пирсана («хи-квадрат» 2 ) и Стьюдента (t-распределение).
~
(n 1) D
1. Доказано, что случайная величина Х
имеет распределение «хи-квадрат» 2
D
(Пирсона) с n–1 степенью свободы.
~
D
через величину Х, имеющей распределение 2 , тогда
~
~
D
(n 1) D(n 1)
доверительный интервал для дисперсии выражается формулой l
, где
;
12 и
2
2
2
1
22 соответственно левый и правый концы интервала l , в который величина V попадает с заданной
Выразим случайную величину
вероятностью .
27
2. Доказано, что при нормальном распределении величины Х случайная величина T n
~m
m
,
~
подчиняется закону распределения Стьюдента с n–1 степенью свободы.
Для построения доверительного интервала для математического ожидания при неизвестной
~ необходимо перейти к
дисперсии в равенстве (*) P( a~ a ) от случайной величины a~ m
~m
m
случайной величине T n ~ , распределенной по закону Стьюдента с (n-1) степенями свободы. В
~ , будем еще использовать
этом случае, помимо точечной оценки для математического ожидания m
1 n
~
~ ) 2 .
точечную оценку для дисперсии: D
( xi m
n 1 i1
~
~
D ~
D
~
; m t ,n1
Доверительный интервал выражается формулой l m t ,n1
; величина t ,n1
n
n
t
находится из условия ( P( T t ,n1 ) 2 S n1 (t )dt . Существуют таблицы значений t ,n1 в зависимости
от доверительной вероятности и числа степеней свободы n–1 или от уровня значимости α = 1 — и
числа степеней свободы.
Замечание. В учебнике Ефимова – Демидовича доверительный интервал находится по формуле:
~
~
D ~
D
~ t
l m
;
m
t
.
1 , n 1
1 , n 1
n
n
2
2
Замечание. Распределение Стьюдента при n 50
близко к стандартному нормальному
распределению, поэтому для определения можно пользоваться не значением t ,n1 , а
1
соответствующим значением величины Ф-1
, как было показано выше.
2
Пример 26. При замере освещенности в одной из лабораторий были получены следующие значения
в лк. 356,4; 353,3; 354,3; 350,5; 357,2. Найти доверительные границы для математического ожидания
уровня освещенности при коэффициенте доверия 0,95 (n 5).
Решение.
~
mm
354,9 m
Перейдем к величине Т: T n ~ 5
6,86
n
~x
m
B
X
i 1
n
i
354,9 , n 5; 0,95; тогда уровень значимости 0,05.
1 n
~
~ ) 2 6,86 .
Число степеней свободы n – 1 = 5 – 1 = 4. Дисперсия D
( xi m
n 1 i1
Для 0,95 и четырех степеней свободы по таблицам распределения Стьюдента находим, что
t,n1 2,776 . Следовательно, доверительный интервал, определяемый по формуле, запишется в виде:
~
~
D ~
D
~ t
l m
;
m
t
= (352,5; 357,3).
,n 1
,n 1
n
n
Замечание. Согласно учебнику Ефимова-Демидовича t = 2,776.
1 , n 1
2
28
§ 4. Основы корреляционного и регрессионного анализа
Корреляция, линии регрессии
Особую роль при исследовании взаимосвязи двух случайных величин (компонент случайного
вектора) играет второй смешанный центральный момент.
Определение 35. Второй смешанный центральный момент μ11 называется корреляционным или
моментом связи или ковариацией:
k XY cov XY 11 M [( X mX )(Y mY )] M [ XY ] M [ X ]M [Y ] 11 mX mY .
k XY xi y j pij mX mY для СВДТ .
i
j
k XY
xyf ( x, y)dxdy m
X
mY
для СВНТ.
Свойства корреляционного момента
1. От прибавления к случайным величинам постоянных величин корреляционный момент не
меняется.
2. Для любых случайных величин Х и У абсолютная величина корреляционного момента не
превосходит среднего геометрического дисперсий случайных величин: k XY DX DY X Y .
Ковариация k XY , помимо рассеивания, характеризует взаимное влияние случайных величин X и
Y, входящих в систему.
Для оценки степени влияния используется не сам момент, а безразмерное соотношение, которое
называется нормированной ковариацией или коэффициентом корреляции:
k
cov XY
Число rXY XY
– коэффициент корреляции двух случайных величин X и Y.
(21)
XY
DX DY
(Иногда его обозначают как XY ).
Определение 36. Корреляция – согласованность в изменчивости различных признаков.
Теория корреляции решает две задачи: 1) установление формы связи между случайными
величинами, 2) определение тесноты и силы этой связи.
Теория корреляции применяется для установления связи между двумя случайными величинами Х и
У и для установления тесноты этой связи. Х и У могут быть связаны либо функциональной
зависимостью, либо зависимостью другого рода, называемой статистической, либо быть независимыми.
Определение 37. Статистической называют зависимость, при которой изменение одной из величин
влечет за собой изменение закона распределения другой.
Определение 38. Статистическая зависимость называется корреляционной, если при изменении
одной из величин изменяется среднее значение другой.
Термин «корреляция» был введен в науку выдающимся английским естествоиспытателем
Френсисом Гальтоном в 1886 г. Однако теорию корреляции и точную формулу для подсчета
коэффициента корреляции разработал его ученик Карл Пирсон. Именно он первым ввѐл в науку
понятие корреляции как вероятностный аналог причинно-следственной связи, но он же первым
предупредил, что корреляционная связь шире, чем причинно-следственная, и, вообще говоря,
доказанная корреляция двух факторов не означает, что один из факторов является причиной другого
(например, они оба могут быть следствием третьего фактора).
Коэффициент корреляции — это инструмент, с помощью которого можно проверить гипотезу о
зависимости и измерить силу зависимости двух переменных.
29
Коэффициент корреляции вычисляют двумя способами: 1) параметрический метод (коэффициент
Пирсона), 2) непараметрические методы (коэффициенты Спирмена, Кендалла, гамма и другие.)
Самые важные меры связи — Пирсона, Спирмена и Кендалла. Их общей особенностью является то,
что они отражают взаимосвязь двух признаков, измеренных в количественной шкале — ранговой или
метрической.
Критерий корреляции Пирсона является параметрическим, в связи с чем условием его применения
служит нормальное распределение сопоставляемых переменных (или распределение несущественно
отличается от нормального).
Для порядковых (ранговых) переменных или переменных, чье распределение существенно
отличается от нормального, используется коэффициент корреляции Спирмана или Кендалла.
П 1. Коэффициент корреляции Пирсона – линейный коэффициент
корреляции. Линии регрессии
Посредством критерия корреляции Пирсона можно определить наличие и силу линейной
взаимосвязи между двумя переменными, между двумя признаками, обозначаемыми, как правило,
символами X и Y, причем 1) Х и У распределены нормально; 2) эти сопоставляемые показатели Х и У
должны быть измерены в количественной шкале (например, частота сердечных сокращений,
температура тела, содержание лейкоцитов в 1 мл крови, систолическое артериальное давление).
Иначе, величина коэффициента корреляции Пирсона r * характеризует, насколько близка связь
между Х и У к линейной зависимости y ax b .
Замечание 1. Если количество сопоставляемых величин больше двух, то в случае анализа их
взаимосвязи следует воспользоваться методом факторного анализа.
Прочие характеристики связи, в том числе направление (прямая или обратная), характер изменений
(прямолинейный или криволинейный), а также наличие зависимости одной переменной от другой определяются при помощи регрессионного анализа.
Замечание 2. При помощи дополнительных расчетов можно также определить, насколько
статистически значима выявленная связь. Например, при помощи критерия корреляции Пирсона
можно ответить на вопрос о наличии связи между температурой тела и содержанием лейкоцитов в
крови при острых респираторных инфекциях, между ростом и весом пациента, между содержанием в
питьевой воде фтора и заболеваемостью населения кариесом.
Свойства коэффициента корреляции Пирсона:
1.
Если X и Y – независимые СВ, то k XY = r * 0 . (X и Y некоррелированные случайные
величины). Обратное утверждение неверно, так как X и Y могут быть зависимыми, но при этом r * 0 .
2.
r* 1.
3.
В случае r * 0 говорят о положительной корреляции Х и Y , что означает: при
возрастании одной из них другая тоже имеет тенденцию в среднем возрастать. Такая зависимость носит
название прямо пропорциональной зависимости. Например, вес и рост человека.
4.
В случае r * 0 говорят об отрицательной корреляции Х и Y , что означает: при
возрастании одной из них другая имеет тенденцию в среднем убывать. Такая зависимость носит
название обратно пропорциональной зависимости. Например, время, потраченное на подготовку
прибора к работе и количество неисправностей, обнаруженных при его работе.
5.
От прибавления к случайным величинам постоянных величин коэффициент корреляции
не меняется.
30
Если располагаем n точками (х1, у1), (х2, у2),…, (хn, уn), полученными в результате n независимых
опытов над системой (х, у), то в качестве приближенного значения неизвестного коэффициента
корреляции rХУ берется выборочный коэффициент корреляции r * r , и в общем виде формула для
подсчета коэффициента корреляции такова:
n
( x x )( y
r r ( x, y ) rXY
i
i 1
*
i
n
y)
(22)
n
(x x) ( y
2
i
i 1
i
i 1
y)2
где хi — значения, принимаемые в выборке X, yi — значения, принимаемые в выборке Y; x — средняя
n
по X: x M X
n
xi
i 1
n
;
y — средняя по Y: y = M Y
y
i
i 1
.
n
r* 1
(23)
Замечание 1. Формула (22) предполагает, что при расчете коэффициентов корреляции число
значений переменной Х равно числу значений переменной Y.
Замечание 2. Число степеней свободы k = n – 2.
Замечание 3. Если величину числителя из формулы разделить на n (число значений переменной X
или Y), то получим ковариацию.
Замечание 4. При изучении совокупностей малого объема (n < 30) пользуются следующей
M M X MY
r ( x, y ) XY
формулой:
,
(24)
XY
n
где M X
xi
i 1
n
n
— выборочное мат. ожидание случайной величины Х,
MY
y
i
i 1
n
— выборочное мат.
n
ожидание случайной величины У, M XY
x y
i
i 1
i
n
выборочное мат. ожидание случайного вектора, среднее
квадратическое отклонение Х: *X X DX , где DX M ( x 2 ) M 2 ( x) — выборочная дисперсия
n
случайной величины Х, M ( x 2 )
x
i 1
n
2
i
; среднее квадратическое отклонение У: Y* Y DY , где
n
DY M ( y 2 ) M 2 ( y) — выборочная дисперсия случайной величины У, M ( у 2 )
у
i 1
2
i
.
n
Замечание 5. Если сделать замену: d X xi x , dY yi y , то расчет коэффициента корреляции
n
Пирсона будет производиться по формуле: rXY
(d
i 1
X
n
dY )
d d
i 1
(25)
n
2
X
i 1
2
Y
Для оценки тесноты, или силы, корреляционной связи между Х и У , для оценки близости этой
связи к линейной зависимости y ax b обычно используют общепринятые критерии, согласно
которым 1) абсолютные значения rxy < 0,3 свидетельствуют о слабой связи, чем ближе r * к 0, тем связь
слабее; 2) абсолютные значения rxy от 0,3 до 0,7 – о связи средней тесноты, 3) абсолютные значения
31
rxy > 0,7 – о сильной связи; чем ближе r * к 1, тем связь сильнее; если r * 1 , то случайные величины X
и Y связаны между собой линейной функциональной зависимостью
Более точную оценку силы корреляционной связи можно получить, если воспользоваться таблицей
Чеддока:
Абсолютное значение r*
менее 0,3
от 0,3 до 0,5
от 0,5 до 0,7
от 0,7 до 0,9
более 0,9
Теснота (сила) корреляционной связи
слабая
умеренная
заметная
высокая
весьма высокая
Определение 39. X и Y называются некоррелированными случайными величинами, если их
коэффициент корреляции r * 0 , и коррелированными, если отличен от нуля.
Проверка на значимость коэффициента корреляции r * r
Для статистического вывода о наличии или отсутствии корреляционной связи между исследуемыми
переменными Х и У необходимо произвести проверку значимости выборочного коэффициента
корреляции r * .
При практических исследованиях генеральной совокупности, как правило, основываются на
выборочных наблюдениях. Как всякая статистическая характеристика, выборочный коэффициент
корреляции r * является случайной величиной. То есть его значения случайно рассеиваются вокруг
истинного коэффициента корреляции генеральной совокупности – .
При существенной связи между переменными коэффициент корреляции r * должен значимо
отличаться от нуля. Если корреляционная связь между исследуемыми переменными отсутствует, то
коэффициент корреляции равен нулю.
Из-за случайного характера рассеивания может оказаться, что и в случае отсутствия корреляционной
связи, некоторые коэффициенты корреляции r * , вычисленные по выборкам данной генеральной
совокупности, будут отличны от нуля. К тому же, надежность статистических характеристик, в том
числе и коэффициента корреляции, зависит от объема выборки, в связи с чем может сложиться такая
ситуация, когда величина коэффициента корреляции будет целиком обусловлена случайными
колебаниями в выборке, на основании которой он вычислен.
Могут ли обнаруженные различия быть приписаны случайным колебаниям в выборке или они
отражают существенное изменение условий формирования отношений между переменными? Если
значения выборочного коэффициента корреляции r * попадают в зону рассеивания, обусловленную
случайным характером самого показателя, то это не является доказательством отсутствия связи, и
можно утверждать, что данные наблюдений не отрицают отсутствия связи между переменными. Если
значения выборочного коэффициента корреляции попадают вне этой зоны рассеивания, то можно
сделать вывод, что он значимо отличается от нуля, и можно утверждать, что между переменными Х и У
существует значимая статистическая связь.
Проверка на значимость вычисленных выборочных коэффициентов корреляции представляет собой
проверку следующей гипотезы: существенно ли (значимо ли) отличается от нуля рассчитанный по ряду
измерений объема эмпирический коэффициент корреляции (Смотри §6)?
Используемый для решения этой задачи критерий, называется критерием значимости.
Оценка статистической значимости коэффициента корреляции r* (при малых объемах выборки)
осуществляется при помощи t-критерия (Стьюдента), рассчитываемого по следующей формуле:
32
tr
r* n 2
1 r*
2
,
(26)
t r tнабл. – наблюдаемое значение.
Предварительно исследователем задается значение доверительной вероятности: β или уровень
значимости α = 1 – β .
Вычисленное по результатам выборки значение t r tнабл. сравнивается с критическим значением
tкрит = tα,n-2, определяемым по таблицам распределения Стьюдента при заданном уровне значимости и с
(n – 2) степенях свободы.
Если tr tкрит, то происходит маловероятное событие, и полученное значение коэффициента
признается значимым, то есть выявленная корреляционная связь статистически значима.
Если tr tкрит, то значение коэффициента считается незначимым.
Замечание 1. Следует четко различать понятия зависимости и корреляции. Зависимость
величин обуславливает наличие корреляционной связи между ними, но не наоборот. Для исследователя
очень важно различать фундаментальные в статистике понятия связи и зависимости показателей для
построения верных выводов.
Например, рост ребенка зависит от его возраста, то есть чем старше ребенок, тем он выше. Если мы
возьмем двух детей разного возраста, то с высокой долей вероятности рост старшего ребенка будет
больше, чем у младшего. Данное явление и называется зависимостью, подразумевающей причинноследственную связь между показателями. Разумеется, между ними имеется и корреляционная связь,
означающая, что изменения одного показателя сопровождаются изменениями другого показателя. В
другой ситуации рассмотрим связь роста ребенка и частоты сердечных сокращений (ЧСС). Как известно,
обе эти величины напрямую зависят от возраста, поэтому в большинстве случаев дети большего роста (а
значит и более старшего возраста) будут иметь меньшие значения ЧСС. То есть, корреляционная связь
будет наблюдаться и может иметь достаточно высокую тесноту. Однако, если мы возьмем детей одного
возраста, но разного роста, то, скорее всего, ЧСС у них будет различаться несущественно, в связи с чем
можно сделать вывод о независимости ЧСС от роста.
Линии регрессии
Взаимная связь двух случайных величин, помимо коэффициента корреляции, может быть описана с
помощью линий регрессии.
Определение 40. Регрессия – зависимость изменения одной величины от значений другого.
Действительно, хотя при каждом значении Х = x величина Y остается случайной величиной,
допускающей рассеивание своих значений, однако зависимость Y от Х сказывается часто в изменении
средних размеров Y при переходе от одного значения х к другому. С изменением х будет изменяться и
условное математическое ожидание M (Y X x) (математическое ожидание лучайной величины У пр
условии, что случайная величина Х примет значение х).
Определение 41. Условным средним y X называется среднее арифметическое наблюдавшихся
значений случайной величины У, соответствующих Х = х.
Условное среднее y X , которое находится по выборке, принимают в качестве оценки условного
математического ожидания mY (x) .
Выше сказанное означает, что можно рассматривать функцию y X = mY (x) , областью определения
которой является множество возможных значений случайной величины Х. Эта функция носит название
регрессии Y по х. (в некоторых источниках, Y на х)
Определение 42. Уравнение у = y X f (x) называется выборочным уравнением регрессии У по х.
33
Аналогично, зависимость X от Y описывает функция – условное математическое ожидание
mX ( y) = M ( X Y y) . Находящееся по выборке среднее арифметическое наблюдавшихся значений
случайной величины Х, соответствующих У = у, или условное среднее xУ , принимают в качестве
оценки условного математического ожидания mХ ( у) .
Определение 43. Уравнение xY ( y) называется выборочным уравнением регрессии Х по у.
Если обе линии регрессии – прямые, то корреляционную зависимость называют линейной.
Для нормально распределенного вектора (Х, У) теоретические уравнения регрессии – линейные:
yX y r*
*
Y*
*X
,
(
x
x
)
x
x
r
( y y) ,
y
*X
Y*
(27)
где y и x – выборочные средние случайных величин У и Х, *X X и Y* Y – выборочные средние
квадратические отклонения, r * r выборочный коэффициент корреляции.
Связь коэффициента корреляции и линий регрессии
1) Если
2) Если
3) Если
4) Если
r * 0 , то линии регрессии (27) наклонены вправо.
r * 0 , то линии регрессии наклонены влево.
r * 0 , то линии регрессии проходят параллельно осям координат.
r * 1, то есть переменные пропорциональны друг другу, то линии регрессии сливаются в
одну линию, следовательно, случайные величины X и Y связаны между собой линейной
функциональной зависимостью Y aX b , a, b R .
Графически связь между ними можно представить в виде прямой линии y ax b с
положительным (прямая пропорция) или отрицательным (обратная пропорция) наклоном, то есть знак
коэффициента корреляции (+ r* ) или (– r*) берется в зависимости от знака (+ или –) коэффициента а,
который называется коэффициентом регрессии.
Определение 44. Уравнение y ax b (или x ay b ) называется выборочным уравнением парной
регрессии.
Замечание. На практике связь между двумя переменными, если она есть, является вероятностной и
графически выглядит как облако рассеивания эллипсоидной формы. Этот эллипсоид, однако, можно
представить (аппроксимировать) в виде прямой линии, или линии регрессии. Это прямая, построенная
методом наименьших квадратов: сумма квадратов расстояний (вычисленных по оси Y) от каждой точки
графика рассеивания до прямой является минимальной.
Y*
Рассмотрим уравнение регрессии y X y r * ( x x ) и найдем связь между коэффициентами
X
*
уравнения и выборочными средними квадратическими отклонениями и выборочным коэффициентом
корреляции. Для этого преобразуем уравнение:
yX r*
*
Y*
* Y
x
r
xy
*X
*X
и сравним с уравнением парной регрессии y ax b , отсюда
Y*
ar * ,
X
*
Y*
b r * x y ,
X
*
(28)
следовательно, выборочный коэффициент корреляции равен
r* a
*X
или r a X
*
Y
Y
(29)
34
Замечание 1. Аналогично рассматривается выборочное уравнение парной регрессии x ay b , где
a r*
*
*Х
* Х
и
b
r
у х . Тогда выборочный коэффициент корреляции равен
У*
У*
Y*
r a * или r a Y
X
X
*
(30)
Замечание 2. Формулы (28), (29) будут выведены в следующем параграфе 5.
Пример 27. Имеются две случайные величины Х и У, связанные соотношением У = 4 – Х. Найти
корреляционный момент, если MX = 3, DX = 2.
Решение.
k XY 11 M [ XY ] M [ X ]M [Y ] 11 mX mY M [ X (4 X )] M [ X ]M [4 X ]
4M [ X ] M [ X 2 ] 4M [ X ] M 2[ X ] M [ X 2 ] M 2[ X ] D[ X ] 2 .
Ответ: –2.
Пример 28. Дано уравнение парной регрессии y 2 x 3 . Выберите правильный коэффициент
корреляции: 1) r * = 0,6, 2) r * = – 0,6, 3) r * =1,2.
Решение.
*
Из рассмотрения исключаем r = 1,2, так как по 2 свойству r * 1 . Коэффициент регрессии а = 2,
т.е. со знаком «+», следовательно, r * = 0,6.
Замечание. Можно было знак r * определить с помощью следующего рассуждения: возьмем два
возрастающие значения х: х1 = 1 и х2 = 4, тогда y1 = –1, y2 = 5, т.е. с возрастанием х возрастает y, отсюда,
r * 0 , следовательно, r * = 0,6.
Ответ: 0,6.
Пример 29. Дано выборочное уравнение парной регрессии y 3,2 2,4 x и выборочные средние
квадратические отклонения *X 0,8 и Y* 2,4 . Найти выборочный коэффициент корреляции.
Решение.
*X
0,8
r a * 2,4
0,8 .
Y
2,4
Выборочный коэффициент корреляции найдем по формуле 29:
*
Ответ: 0,8.
Пример 30. Определить тесноту и статистическую значимость корреляционной связи между
уровнем механизации работ и производительностью труда при уровне значимости α = 0,05.
Предприятие i
1
2
3
4
5
6
7
8
9
10 11 12 13 14
i
Производительность 20
Труда yi
Коэффициент
32
Механизации % xj
24
28
30
31
33
34
37
38
40
41
43
45
48
492
30
36
40
41
47
56
54
60
55
61
67
69
76
724
Решение.
Вычислим выборочный коэффициент корреляции по формуле (24): r * r ( x, y)
n
Найдем выборочное мат. ожидание случайной величины Х: M X
n
XY
.
14
x
x
i 1
M XY M X M Y
i
=
i 1
14
i
724
51,71 .
14
35
n
yi
Найдем выборочное мат. ожидание случайной величины У: M Y
i 1
n
Найдем выборочное мат. ожидание случайного вектора M XY
n
i
i 1
14
x y
x y
i
y
492
35,14 .
14
26907
1921,93
14
14
n
i 1
14
i
=
i 1
i
14
i
n
x
2
i
40134
2866,71 , тогда выборочная дисперсия случайной величины Х
n
14
среднее квадратическое отклонение
DX M ( x 2 ) M 2 ( x) = 2866,71 – 2673,92 = 192,79 и
Найдем M ( x 2 )
i 1
*X X DX = 13.88.
n
у
2
i
18138
1295,57 , тогда выборочная дисперсия случайной величины У
n
14
DУ M ( у 2 ) M 2 ( у) = 1295,57 – 1234,82 = 60,75 и тогда среднее квадратическое отклонение равно
Найдем M ( у 2 )
i 1
У* У DУ = 7,79.
Выборочный коэффициент корреляции равен r *
M XY M X M Y
XY
1921,93 51,71 35,14
0,97.
13,88 7,79
Согласно таблице Чеддока: корреляционная связь весьма высокая.
Оценим статистическую значимость коэффициента корреляции r* при помощи t-критерия по
формуле:
t
r* n 2
*2
= 13,52 = tнабл.
1 r
Число степеней свободы n – 2 = 14 – 2 = 12.
Найдем критическое значение по таблице распределения Стьюдента при заданном уровне
значимости α = 0,05 и с 12 степенях свободы: tα,n-2 = t0,05, 12 = 2,79 = tкрит..
Сравним tнабл и tкрит:
13,52 > 2,79, следовательно, полученное значение коэффициента значимое,
то есть выявленная корреляционная связь статистически значима.
Ответ: Значение коэффициента корреляции Пирсона составило 0.97, что соответствует весьма
высокой тесноте связи между производительностью труда и уровнем механизации работ. Данная
корреляционная связь является статистически значимой.
П 2. Коэффициенты корреляции Спирмена или Кендалла (ранговые
корреляции)
Основной коэффициент корреляции r Пирсона является мерой прямолинейной связи между
переменными. В реальной жизни отношения между переменными часто оказываются не только
вероятностными, но и непрямолинейными; монотонными или немонотонными.
а) – отсутствие связи между X и Y б) – обратная (отрицательная) умеренная связь в) – наличие
нелинейной связи между переменными.
36
Если обе переменные X и Y, между которыми изучается связь, представлены в порядковой шкале,
или одна из них — в порядковой, а другая — в метрической; причем связь между X и Y нелинейная, но
монотонная, то применяются ранговые коэффициенты корреляции: Спирмена или τ-Кенделла. И тот, и
другой коэффициент требует для своего применения предварительного ранжирования обеих
переменных.
Пп 1. Коэффициент корреляции Спирмена
Данный критерий был разработан и предложен для проведения корреляционного анализа в 1904
году Чарльзом Эдвардом Спирменом, английским психологом, профессором Лондонского и
Честерфилдского университетов.
Коэффициент ранговой корреляции Спирмена (обозначение rs или ρ) – это непараметрический
метод, который используется для выявления и оценки тесноты связи между двумя рядами
сопоставляемых количественных показателей. Переменные X и Y предварительно ранжируют.
Замечание. Если члены группы численностью были ранжированы сначала по переменной x, затем –
по переменной y, то корреляцию между переменными x и y можно получить, просто вычислив
коэффициент Пирсона для двух рядов рангов. В этом случае, если ранги показателей, упорядоченных
по степени возрастания или убывания, в большинстве случаев совпадают (большему значению одного
показателя соответствует большее значение другого показателя — например, при сопоставлении роста
пациента и его массы тела), делается вывод о наличии прямой корреляционной связи. Если ранги
показателей имеют противоположную направленность (большему значению одного показателя
соответствует меньшее значение другого — например, при сопоставлении возраста и частоты сердечных
сокращений), то говорят об обратной связи между показателями.
При условии отсутствия связей в рангах (т.е. отсутствия повторяющихся рангов) по той и другой
переменной, формула для Пирсона может быть существенно упрощена в вычислительном отношении и
преобразована в формулу Спирмена. При этом справедливы следующие положения:
1)
коэффицент ранговой корреляции целесообразно применять при наличии небольшого
количества наблюдений.
2)
проверка на нормальность распределения не требуется, в связи с тем, что коэффициент
является методом непараметрического анализа;
3)
сопоставляемые показатели могут быть измерены как в непрерывной шкале (например, число
эритроцитов в 1 мкл крови), то есть значения определяются описательными признаками различной
интенсивности; так и в порядковой (например, баллы экспертной оценки от 1 до 5), то есть для
количественно выраженных данных;
4)
коэффициент ранговой корреляции Спирмена при большом количестве одинаковых рангов
по одной или обеим сопоставляемым переменным дает огрубленные значения. В идеале оба
коррелируемых ряда должны представлять собой две последовательности несовпадающих значений.
5)
эффективность и качество оценки методом Спирмена снижается, если разница между
различными значениями какой-либо из измеряемых величин достаточно велика. Не рекомендуется
использовать коэффициент Спирмена, если имеет место неравномерное распределение значений
измеряемой величины.
Этапы расчета коэффициента Спирмена:
1.
Сопоставить каждому из признаков их порядковый номер (ранг) по возрастанию или
убыванию.
2.
Определить разности рангов каждой пары сопоставляемых значений (d).
3.
Возвести в квадрат каждую разность и суммировать полученные результаты.
4.
Вычислить коэффициент корреляции рангов по формуле:
37
1
5.
6d2
(31)
n(n 2 1)
Определить статистическую значимость коэффициента при помощи t-критерия Стьюдента,
рассчитанного по следующей формуле: t
r n2
. Если расчитанное значение t-критерия меньше
1 r2
табличного при заданном числе степеней свободы, статистическая значимость наблюдаемой
взаимосвязи — отсутствует. Если больше, то корреляционная связь считается статистически значимой.
Свойства коэффициента корреляции Спирмена
1.
Коэффициент корреляции может принимать значения от минус единицы до единицы, причем
при ρ = 1 имеет место строго прямая связь, а при ρ = –1 – строго обратная связь.
2.
Если коэффициент корреляции отрицательный, то имеет место обратная связь, если
положительный,
то – прямая связь.
3.
Если коэффициент корреляции равен нулю, то связь между величинами практически
отсутствует.
4.
Чем ближе модуль коэффициента корреляции к единице, тем более сильной является связь
между измеряемыми величинами.
5.
Мощность коэффициента ранговой корреляции Спирмена несколько уступает мощности
параметрического коэффициента корреляции.
При использовании коэффициента ранговой корреляции условно оценивают тесноту связи между
признаками, считая значения коэффициента равные 0,3 и менее — показателями слабой тесноты связи;
значения более 0,4, но менее 0,7 — показателями умеренной тесноты связи, а значения 0,7 и более показателями высокой тесноты связи.
Пп 2. Коэффициент ранговой корреляции τ-Кендалла
Данный критерий ранговой корреляции был разработан и предложен для проведения
корреляционного анализа английским статистиком Морисом Джорджем Кендаллом.
Данный коэффициент (обозначение: τ) является альтернативой методу определения корреляции
Спирмана. Он предназначен для определения взаимосвязи между двумя ранговыми (метрческими)
переменными. В основе данной корреляции лежит идея о том, что о направлении связи можно судить,
попарно сравнивая между собой испытуемых: если у пары испытуемых изменение по x совпадает по
направлению с изменением по y, то это свидетельствует о положительной связи, если не совпадает — то
об отрицательной связи. Максимальной силе связи соответствуют значения корреляции +1 (строгая
прямая или прямо пропорциональная связь) и –1 (строгая обратная или обратно пропорциональная
связь), отсутствию связи соответствует корреляция, равная нулю.
Метод вычисления коэффициента корреляции зависит от вида шкалы, к которой относятся
переменные.
Шкала, в которой измеряется переменная
Коэффициент корреляции
интервальная и номинальная
Пирсона
одна из двух переменных измеряется в порядковой ранговая корреляция по Спирмену или
шкале
τ-Кендала.
одна из двух переменных не является нормально
распределенной
ранговая корреляция по Спирмену или
τ-Кендала.
одна из двух переменных не является
дихотомической
ранговая корреляция по Спирмену
38
Замечание 1. Дополнительную информацию о силе связи дает значение коэффициента
детерминации, который показывает, в какой степени изменчивость одной переменной обусловлена
(детерминирована) влиянием другой переменной.
Определение 45. Квадрат коэффициента корреляции зависимой и независимой переменных
представляет долю дисперсии зависимой переменной, обусловленной влиянием независимой
переменной, и называется коэффициентом детерминации. Иначе, это часть дисперсии одной
переменной, которая может быть объяснена влиянием другой переменной.
Коэффициент детерминации обладает важным преимуществом по сравнению с коэффициентом
корреляции. Корреляция не является линейной функцией связи между двумя переменными. Поэтому,
среднее арифметическое коэффициентов корреляции для нескольких выборок не совпадает с
корреляцией, вычисленной сразу для всех испытуемых из этих выборок (т.е. коэффициент корреляции
не аддитивен). Напротив, коэффициент детерминации отражает связь линейно (линейно возрастает с
увеличением силы) и поэтому является аддитивным: допускается его усреднение для нескольких
выборок.
Замечание 2. Существуют и другие коэффициенты корреляции, применяющиеся для разных типов
данных. Расчѐт коэффициента корреляции между двумя недихотомическими переменными не лишѐн
смысла только тогда, кода связь между ними линейна (однонаправлена). Если связь, к примеру, Uобразная (неоднозначная), то коэффициент корреляции непригоден для использования в качестве меры
силы связи: его значение стремится к нулю.
Например. Экзамен. Введем две переменные: «нервное возбуждение перед экзаменом» и «балл
экзамена», измеряемые по 3 и 5-бальной шкале соответственно. Студенты, испытывающие умеренное
нервное возбуждение, имеют наилучшие результаты на экзаменах, в то время как очень спокойные или
очень нервные студенты сдают экзамены значительно хуже. Если по оси абсцисс отложить степень
нервного возбуждения, а по оси ординат — результаты сдачи экзаменов, график зависимости между
ними примет вид, близкий к перевернутой букве U. При этом любой коэффициент корреляции,
вычисленный для этих величин, окажется весьма низким. Это объясняется тем, что для немонотонных
отношений нужны другие методы оценки корреляции (регрессионного анализ).
§ 5. Сглаживание экспериментальных зависимостей.
Метод наименьших квадратов
При обработке опытных данных часто приходится решать задачу, в которой необходимо
исследовать зависимость одной физической величины у от другой физической величины х. Например,
исследование величины погрешности размера изделия от температуры, величины износа резца от
времени и т.д.
39
Пусть в результате опыта был получен ряд экспериментальных точек (х1, у1), (х2, у2),…, (хn, уn). Если
построить примерный график зависимости переменной
величины у от независимой переменной х, то ясно, что он
у
(2)
не будет проходить через все полученные точки, но, по
возможности, рядом с ними. По возможности, потому что
(1)
производимые в ходе опыта измерения связаны с
ошибками случайного характера, то и экспериментальные
О
х
точки на графике обычно имеют некоторый разброс
относительно общей закономерности. В силу случайности
ошибок измерения этот разброс или уклонения точек от общей закономерности также являются
случайными.
Задача сглаживания экспериментальной зависимости состоит в такой обработке экспериментальных
данных, при которой по возможности точно была бы отражена тенденция зависимости у от х и
возможно полнее исключено влияние случайных, незакономерных уклонений (1 и 2), связанных с
погрешностями опыта.
Если вид зависимости у = f(x) до опыта известен из физических соображений, и на основании
опытных данных требуется только определить некоторые ее параметры, чтобы зависимость сгладить, то
обычно применяют «метод наименьших квадратов».
Итак, метод наименьших квадратов применяется для решения задач, связанных с обработкой
результатов опыта, особенно важным его приложением является решение задачи сглаживания
экспериментальной зависимости, т.е. изображения опытной функциональной зависимости
аналитической формулой. При этом метод не решает вопроса о выборе общего вида аналитической
функции, а дает возможность при заданном типе функции у = f(x) подобрать наиболее вероятные
значения для параметров этой функции.
Сущность метода.
Пусть в результате опыта получены точки (х1, у1), (х2, у2),…, (хn, уn). Зависимость у от x ,
изображаемая аналитической функцией у = f(x) не может совпадать с экспериментальными значениями
уi во всех n точках, т.е разность i yi f ( xi ) 0 . Требуется подобрать параметры функции у = f(x)
таким образом, чтобы сумма квадратов этих разностей
n
n
i 1
i 1
z 2i [ yi f ( xi )]2
(32)
была наименьшей. Таким образом, при методе наименьших квадратов приближение аналитической
функции у = f(x) к экспериментальной зависимости считается наилучшим, если выполняется условие
минимума суммы квадратов отклонений искомой аналитической функции от экспериментальной
зависимости.
Рассмотрим два случая: 1) когда для изображения экспериментальной зависимости выбирается
прямая, 2) когда для изображения экспериментальной зависимости выбирается парабола.
1) Рассмотрим случай, когда r ( x, y) 1 и r * 0,4 , следовательно, связь между Х и У близка к
линейной, то есть рассматриваем функцию y ax b , которая наилучшим образом выражала бы
зависимость у от х. Найдем коэффициенты а и b. Для этого существует метод наименьших квадратов.
Пусть над системой (х, у) произведено n независимых опытов, в результате которых имеем (х1, у1), (х2,
у2),…, (хn, уn). Требуется найти а и b такие, чтобы сумма квадратов отклонений экспериментальных
y ax b была наименьшей, то есть, чтобы (по 32 формуле)
точек от прямой
n
n
i 1
i 1
z 2i [ yi (axi b)]2 была наименьшей. Из геометрических соображений ясно, что минимум z
40
существует и реализуется в критических точках: дифференцируем эту функцию z по неизвестным
параметрам a, b и приравнивая производные к нулю, получим систему двух линейных уравнений с
двумя неизвестными a, b:
n
n
n
/
n
2
za 2[ yi (axi b)]xi 0
xi yi a xi b xi 0
i 1
i 1
i 1
i 1
.
Преобразуем: n
.
n
n
z / 2 [ y (ax b)] 0
y a
i
i
i
i x nb 0
b
i 1
i 1
i 1
Разделим оба уравнения на n, заменим суммы по определению и получим:
M XY aM ( x 2 ) bM ( x) 0
, отсюда
M
(
y
)
a
M
(
x
)
b
a a* a
M XY M X M Y
r Y ,
2
2
M ( x ) M ( x)
X
b b* b M Y a M X .
Таким образом, искомая линейная зависимость у от х имеет вид
выборочным (эмпирическим) уравнением регрессии у на х.
2) Рассмотрим случай, когда
парабола у = аx2 + bх + с.
(33)
y a x b и называется
для изображения экспериментальной зависимости выбирается
n
Тогда z [ yi axi2 bxi c]2 . Дифференцируя эту функцию по
i 1
неизвестным параметрам a, b, c и приравнивая производные к нулю, получим систему трех линейных
уравнений с тремя неизвестными a, b, c:
n
n
n
n 4
3
2
2
a xi b xi c xi xi yi
i 1
i 1
i 1
i 1
n
n
n
n
3
2
a
x
b
x
c
x
xi yi .
i
i
i
i
1
i
1
i
1
i
1
n
n
n 2
a xi b xi cn yi
i 1
i 1
i 1
Решая систему с помощью методов Крамера или Гаусса, получим значение неизвестных параметров
a, b, c, а значит, уравнение параболы.
§ 6. Проверка статистических гипотез
П. 1. Понятие о статистических гипотезах. Критерии согласия
Прежде, чем перейти к рассмотрению понятия статистической гипотезы, сформулируем так
называемый принцип практической уверенности, лежащий в основе применения выводов и
рекомендаций, полученных с помощью теории вероятностей и математической статистики: если
вероятность события в данном испытании очень мала, то при однократном испытании можно быть
уверенным в том, что событие не произойдет, и в практической деятельности вести себя так, как будто,
событие вообще невозможно.
Вопрос о том, насколько малой должна быть вероятность события, чтобы его можно было считать
практически невозможным, выходит за рамки математической теории и решается в каждом отдельном
случае с учетом важности последствий, вытекающих из наступления события. В ряде случаев можно
пренебречь событиями, вероятность которых меньше 0,05, а в других, когда речь идет, например, о
разрушении сооружений, гибели судна и т.п. нельзя пренебрегать событиями, которые могут появиться
с вероятностью, равной
0,001. Задача статистика – ответить на данный вопрос.
Обычно в практических задачах не встречаются случайные величины, распределения которых точно
41
соответствовали бы теоретическим распределениям. Последние являются математическими моделями
реальных распределений. Подбор таких моделей и анализ их адекватности моделируемым случайным
величинам, что является одной из основных задач математической статистики, которая, в свою очередь,
сводится к проверке предположений (гипотез) о виде модели распределения и о его параметрах.
Определение 39. Статистической гипотезой называется любое предположение о виде неизвестного
закона распределения, о параметрах известного распределения, об отношениях между случайными
величинами и т.д. (иначе, статистическая гипотеза – это предположение о свойствах случайных величин
или событий, которое мы хотим проверить по имеющимся данным).
Примеры статистических гипотез: 1) успеваемость группы вероятностно (стохастически) зависит от
уровня обучаемости студентов, 2) усвоение начального курса математики в школе не имеет
существенных различий у школьников, начавших обучение с 6 или с 7 лет.
Виды статистических гипотез
Сформулированных гипотез – две: основная и альтернативная.
Определение 40. Проверяемую гипотезу называют нулевой или основной и обозначают Н0.
Нулевая гипотеза – это основное проверяемое предположение, которое обычно формулируется как
отсутствие различий, отсутствие влияние фактора, отсутствие эффекта, равенство нулю значений
выборочных характеристик и т.п.
Примером нулевой гипотезы является утверждение о том, что различие в результатах выполнения
двумя группами студентами одной и той же контрольной работы вызвано лишь случайными причинами.
Определение 41. Противоположную или противоречащую выдвинутой гипотезе Н0 гипотезу Н1
называют альтернативной или конкурирующей.
Альтернативная или конкурирующая гипотеза — это другое проверяемое предположение (не всегда
строго противоположное или обратное первому). Так, для упомянутого выше примера гипотезы Н0 в
педагогике одна из возможных альтернатив Н1 будет определена как: уровни выполнения работы в
двух группах студентов различны, и это различие определяется влиянием неслучайных факторов,
например, тех или других методов обучения.
Например, гипотеза Н0 имеет вид: генеральная средняя а = 2. Альтернативная гипотеза Н1 в этом
примере может быть сформулирована любым из трех следующих способов:
1) Н1 : а > 2 (правосторонняя проверка),
2) Н1 : а < 2 (левосторонняя проверка),
3) Н1 : а ≠ 2 (двусторонняя проверка).
Пример 31. Основная гипотеза Н0 имеет вид: а = 10. То конкурирующей может быть гипотеза:
1) Н1 : а > 10 , 2) Н1 : а ≥ 10; 3) Н1 : а ≥ 5 4) Н1 : а ≤ 10. Выбрать правильный ответ или ответы.
Ответ. № 1. Н1 : а > 10. Остальные гипотезы не противоречат нулевой.
Гипотезы различают на простые (состоящие только из одного предложения) и сложные (состоящие
из конечного или бесконечного числа простых гипотез).
Наиболее распространенными являются два типа гипотез:
1.
Параметрические гипотезы: при известном виде распределения предположения о
неизвестных характеристиках этого распределения.
2.
Для известной случайной величины (выборки) предположения о виде ее распределения.
Общая схема проверки статистических гипотез
Выдвинутая гипотеза может быть правильной или неправильной, поэтому возникает необходимость
проверить ее. Так как проверку производят статистическими методами, то данная проверка называется
статистической.
42
Проверка статистических гипотез тесно связана с теорией статистического оценивания параметров.
Поскольку статистика как метод исследования имеет дело с данными, в которых интересующие
исследователя
закономерности
искажены различными случайными факторами, большинство
статистических вычислений сопровождается проверкой некоторых предположений или гипотез об
источнике этих данных. Например, фасовочная машина должна наполнять пакеты сахаром по 1 кг. Как
узнать, действительно ли генеральная совокупность подчиняется этим ограничениям? С этой целью
проводят испытание гипотез. Из генеральной совокупности проводят выборку объема n. Для этой
выборки вычисляют нужные характеристики. Затем формулируют гипотезы.
Теория статистического оценивания используется всякий раз, когда необходим обоснованный вывод
о преимуществах того или иного способа инвестиций, измерений, стрельбы, технологического процесса,
об эффективности нового метода обучения, управления, о пользе вносимого удобрения, принимаемого
лекарства, о значимости математической модели и т.д.
Общая постановка задачи проверки гипотез. Имеются две противоположные гипотезы Н0 и Н1 и
некоторая связанная с ними случайная величина У. Пусть у обозначает числовое значение случайной
величины У, полученное в результате испытания, Δ – множество всех возможных значений СВ У.
Требуется произвести проверку нулевой гипотезы относительно конкурирующей на основании
результатов испытания. Разобьем множество Δ на две части Δ1 и Δ2 с условием принятия гипотезы Н0
при попадании значения у СВ У в результате опыта в Δ1 и гипотезы Н1 – при попадании у в Δ2. Выбор
решающего правила разбиения множества Δ на две части Δ1 и Δ2 в любой задаче проверки гипотез
возможен больше, чем одним способом. Спрашивается: какое из всех возможных разбиений считать
наилучшим?
Для проверки нулевой гипотезы используют специально подобранную случайную величину, точное
или приближенное распределение которой известно.
Определение 46. Статистическим критерием (или просто критерием) называют случайную
величину Т, которая служит для проверки статистических гипотез. Иначе, статистический критерий –
это строгое математическое правило, которое сопоставляет каждому возможному значению или всему
множеству возможных значений случайной величины У, связанной с двумя противоположными
гипотезами Н0 и Н1, одну из гипотез, то есть правило, на основе которого отклоняется или принимается
нулевая гипотеза.
Определение 47. Статистика критерия или тест — некоторая функция Т от исходных данных (от
результатов наблюдений х1, х2,…, хn), по значению которой проверяется нулевая гипотеза. Чаще всего
статистика критерия является числовой функцией, но она может быть и любой другой функцией,
например, многомерной функцией.
На основе статистики строятся статистические критерии.
Определение 48. Критерии значимости (критерии проверки гипотез, иногда – просто тесты) – это
простейшие, но, наиболее широко используемые статистические средства.
Критерий значимости дает возможность статистику найти разумный ответ на вопрос, подобный
следующим: 1) Превосходит ли по эффективности одно противогриппозное средство другое? 2)
Способствует ли отказ от курения снижению вероятности раковых заболеваний? 3) Превосходит ли по
воздействию
одно
удобрение
другое
при
выращивании
овощей?
Основные моменты (пункты) проверки статистических гипотез.
Пункт 1. Для основной гипотезы Н0 формулируется альтернативная гипотеза Н1.
Пункт 2. Выбирается малое положительное число α, которое называется уровнем значимости
проверки.
43
Определение 49. Уровень значимости α — это такое (достаточно малое) значение вероятности
события, при котором событие уже можно считать неслучайным, или вероятность, использованная при
испытании гипотез.
В стандартной методике проверки статистических гипотез уровень значимости фиксируется
заранее, до того, как становится известной выборка. Обычно рекомендуется выбирать уровень
значимости из априорных соображений. Однако на практике не вполне ясно, какими именно
соображениями надо руководствоваться, и выбор часто сводится к назначению одного из популярных
вариантов: α = 0,005; 0,01; 0,05; 0,1. В докомпьютерную эпоху эта стандартизация позволяла сократить
объѐм справочных статистических таблиц. Теперь нет никаких специальных причин для выбора именно
этих значений. Для каждого критерия имеются таблицы, по которым и находят приближенную точку,
удовлетворяющую необходимому требованию.
α = 1 – р, где р (другое обозначение β) – доверительная вероятность (задается исследователем), то
есть величина которая отражает степень уверенности исследователя в результатах испытаний.
Пункт 3. Рассматриваются теоретические выборки значений случайных величин, о которых
сформулирована гипотеза Н0 и выбирается (формируется) случайная величина Т – статистика критерия.
Значение и распределение Т полностью определяются по выборкам при предположении о верности
гипотезы Н0.
Пункт 4. На числовой оси задают интервал D такой, что вероятность попадания статистики Т в этот
интервал равна р = β = 1 – α: P(T D) 1 , где D — область принятия гипотезы.
Определение 50. Областью принятия гипотезы называют совокупность значений критерия, при
которых нулевая гипотеза принимается.
Оставшаяся область числовой оси – критическая.
Определение 51. Критической областью называют совокупность значений критерия, при которых
нулевая гипотеза отвергается и принимается альтернативная.
За область D принимают один из интервалов: (–∞, tкр], [–tкр, tкр], [tкр, +∞), где число tкр – критическое
значение статистики.
Определение 52. Точки, отделяющие критическую область от области принятия гипотезы, называют
критическими (граничными) точками и обозначают tкр.
Соответственно этим промежуткам критерий проверки называется правосторонним, двусторонним
или левосторонним.
Соответствующие области отклонения гипотезы Н0 называются критическими областями:
1) правосторонняя (tкр; +∞), 2) левосторонняя (–∞; tкр), 3) двусторонняя (–∞; -tкр) U (t; +∞).
Критические (граничные) точки, одну для односторонней проверки или две для двусторонней,
находят по специальным таблицам в зависимости от объема выборки n и значения достаточно малой
вероятности — уровня значимости α, исходя из требования:
1) для правосторонней критической области P(T > tкр.) = α,
2) для левосторонней критической области P(T < tкр.) = α,
3) для двусторонней критической области P(T < -tкр.) + P(T > tкр.) = α.
Для односторонней проверки уровень значимости α = 1 – р, (р = β – доверительная вероятность);
для двусторонней проверки α = (1 – р)/2 = (1 – β)/2.
Пункт 5. Для проверки гипотезы по результатам теоретических выборки вычисляют конкретное
(наблюдаемое) значение критерия (статистики Т) и получают так называемое наблюдаемое значение
критерия tнабл. Проверяется выполнение условия P(T D) 1 . Если оно выполняется, то гипотеза Н0
принимается в том смысле, что она не противоречит опытным данным; если же условие
44
P(T D) 1 не выполняется, то полагается, что гипотеза Н0 неверна и вероятность этого события
определена неверно.
Формула для вычисления статистики зависит от вида решаемой задачи. Значение статистики также
наносят на координатную ось.
Основной принцип проверки статистических гипотез: если наблюдаемое значение критерия
принадлежит критической области, гипотезу отвергают; если наблюдаемое значение критерия
принадлежит области принятия гипотезы, гипотезу принимают.
В зависимости от взаимного расположения значения статистики и граничных точек возможен один
из трех вариантов: 1) принимается Н0, 2) отклоняется Н0 и без всякой проверки принимается Н1, 3)
доказательство является неубедительным, требуется больше данных.
Для левосторонней проверки:
Отклонение Н0
Принятие Н0
Принятие Н1
р%
(100-р)%
граничная точка
Для правосторонней проверки:
Принятие Н0
р%
Отклонение Н0
Принятие Н1
(100-р)%
граничная точка
Для двусторонней проверки:
Отклонение Н0
Принятие Н0
Отклонение Н0
Принятие Н1
р%
Принятие Н1
[(100-р)/2]%
[(100-р)/2]%
граничная точка
граничная точка
Чем выше доверительная вероятность β (р), тем шире область принятия гипотезы. Можно показать,
что в случае ограниченного интервала области принятия гипотезы Н0 (двусторонней критической
области) существует связь интервала D, определяемого по формуле P(T D) 1 с доверительным
~ ;m
~ ) или l (m
~ t ;m
~ t ) , t – критическое
интервалом, определяемым по формуле l (m
кр
kp
кр
значение статистики.
В итоге статистической проверки гипотез могут быть допущены ошибки двух типов:
1) ошибка первого рода состоит в том, что отвергнута нулевая гипотеза, когда она верна.
Вероятность этой ошибки равна α (уровню значимости).
2) ошибка второго рода состоит в том, что принята нулевая гипотеза, когда верна конкурирующая –
ложноотрицательное решение. Вероятность совершить ошибку второго рода обозначают β.
Чрезмерное уменьшение уровня значимости α может привести к увеличению вероятности ошибки
второго рода β.
Определение 53. Вероятность γ = (1 – β) того, что нулевая гипотеза будет отвергнута, если верна
конкурирующая, называют мощностью критерия.
При выбранном уровне значимости критическую область следует строить так, чтобы мощность
критерия была максимальной.
45
Следует отметить, что вероятности ошибок первого и второго рода вычисляются при разных
предположениях о распределении (если верна гипотеза и если не верна гипотеза), так что никаких раз и
навсегда фиксированных соотношений (например, независимо от вида гипотезы и вида критерия) между
ними нет. Таким образом, при фиксированном объеме выборки, мы можем сколь угодно уменьшать
ошибку первого рода, уменьшая уровень значимости. При этом, естественно, возрастает вероятность
ошибки второго рода (уменьшается мощность критерия). Чем больше мощность критерия, тем меньше
вероятность ошибки второго рода. Единственный способ одновременно уменьшить ошибки первого и
второго рода и – увеличить размер выборки. Именно такие соображения лежат в основе выбора нужного
размера выборки в статистических экспериментах.
Выбор уровня значимости требует компромисса между значимостью и мощностью или (что то же
самое, но другими словами) между вероятностями ошибок первого и второго рода.
Последствия этих ошибок могут оказаться различными, они зависят от конкретной задачи. Ошибка,
состоящая в принятии нулевой гипотезы, когда она ложна, качественно отличается от ошибки,
состоящей в отвержении гипотезы, когда она истинна. Эта разница очень существенна вследствие того,
что различна значимость этих ошибок. Проиллюстрируем вышесказанное на следующем примере.
Пример 31. Процесс производства некоторого медицинского препарата весьма сложен.
Несущественные на первый взгляд отклонения от технологии вызывают появление высокотоксичной
побочной примеси. Токсичность этой примеси может оказаться столь высокой, что даже такое ее
количество, которое не может быть обнаружено при обычном химическом анализе, может оказаться
опасным для человека, принимающего это лекарство. В результате, прежде чем выпускать в продажу
вновь произведенную партию, ее подвергают исследованию на токсичность биологическими методами.
Малые дозы лекарства вводятся некоторому количеству подопытных животных, например, мышей, и
результат регистрируют. Если лекарство токсично, то все или почти все животные гибнут. В противном
случае норма выживших велика. Исследование лекарства может привести к одному из возможных
способов действия: выпустить партию в продажу (а1), вернуть партию поставщику для доработки или,
может быть, для уничтожения (а2). Ошибки двух видов, связанные с действиями а1 и а2 совершенно
различны, различна и важность избегания их. Сначала рассмотрим случай, когда применяется действие
а1, в то время когда предпочтительнее а2. Лекарство опасно для пациента, в то время как оно признано
безопасным. Ошибка этого вида может вызвать смерть пациентов, употребляющих этот препарат. Это
ошибка первого рода, так как нам важнее ее избежать. Рассмотрим случай когда предпринимается
действие а2, в то время когда а1 является более предпочтительным. Это означает, что вследствие
неточностей в проведении эксперимента партия нетоксичного лекарства классифицировалась как
опасная. Последствия ошибки могут выражаться в финансовом убытке и в увеличении стоимости
лекарства. Однако случайное отвержение совершенно безопасного лекарства, очевидно, менее
нежелательно, чем, пусть даже изредка происходящие гибели пациентов. Отвержение нетоксичной
партии лекарства – ошибка второго рода.
Определение 54. Достигаемый уровень значимости или пи-величина р(Т) – это наименьшая
величина уровня значимости, при которой нулевая гипотеза отвергается для данного значения
статистики критерия Т. (Т принадлежит критической области).
Другая интерпретация: достигаемый уровень значимости или пи-величина— это вероятность, с
которой (при условии истинности нулевой гипотезы) могла бы реализоваться наблюдаемая выборка,
или любая другая выборка с ещѐ менее вероятным значением статистики Т.
Случайная величина р(Т(хm)) имеет равномерное распределение. Фактически, функция р(Т) приводит
значение статистики критерия Т к шкале вероятности. Маловероятным значениям (хвостам
распределения) статистики Т соответствуют значения р(Т), близкие к нулю или к единице. Вычислив
значение р(Т(хm)) на заданной выборке хm, статистик имеет возможность решить, является ли это
значение достаточно малым, чтобы отвергнуть нулевую гипотезу. Данная методика является более
46
гибкой, чем стандартная. В частности, она допускает «нестандартное решение» — продолжить
наблюдения, увеличивая объѐм выборки, если оценка вероятности ошибки первого рода попадает в зону
неуверенности, скажем, в отрезок [0,01; 0,1].
Определение 55. ROC-кривая (receiver operating characteristic) — это зависимость мощности (1 – β)
от уровня значимости α.
Методика предполагает, что статистик укажет подходящую точку на ROC-кривой, которая
соответствует компромиссу между вероятностями ошибок I и II рода.
Для того чтобы свести к минимуму ошибки, в таблицах критических значений статистических
критериев в общем количестве данных не учитывают те, которые можно вывести методом дедукции.
Оставшиеся данные составляют так называемое число степеней свободы k — число данных из
выборки, значения которых могут быть случайными, то есть могут варьироваться.
Так, если сумма трех данных равна 8, то первые два из них могут принимать любые значения, но
если они определены, то третье значение становится автоматически известным. Если, например,
значение первого данного равно 3, а второго -1, то третье может быть равным только 4. Таким образом,
в такой выборке имеются только две степени свободы. В общем случае для выборки в n данных
существует п-1 степень свободы. Если у нас имеются две независимые выборки, то число степеней
свободы для первой из них составляет n1-1, а для второй — n2-1. А поскольку при определении
достоверности разницы между ними опираются на анализ каждой выборки, число степеней свободы, по
которому нужно будет находить критерий t в таблице, будет составлять (n1+n2)-2.
Если же речь идет о двух зависимых выборках, то в основе расчета лежит вычисление суммы
разностей, полученных для каждой пары результатов (т.е., например, разностей между результатами до
и после воздействия на одного и того же испытуемого). Поскольку одну (любую) из этих разностей
можно вычислить, зная остальные разности и их сумму, число степеней свободы для определения
критерия t будет равно n-1.
Количество степеней свободы может быть не только натуральным, но и любым действительным
числом, хотя стандартные таблицы рассчитывают p-value наиболее распространѐнных распределений
только для натурального числа степеней свободы
Типы статистических критериев проверки гипотез
Пусть нулевая гипотеза принята. Ошибочно думать, что она доказана. Более правильно говорить:
данные наблюдений согласуются с нулевой гипотезой и, следовательно, не дают основания ее
опровергнуть. Иначе, любой критерий не доказывает справедливость проверяемой гипотезы Н0, а лишь
устанавливает на принятом уровне значимости ее согласие или несогласие с данными наблюдений.
На практике для большей уверенности гипотезу проверяют другими способами или повторяют
эксперимент, увеличив объем выборки.
Опровергают гипотезу более категорично, чем принимают. Действительно, достаточно привести
один пример, противоречащий некоторому общему утверждению, чтобы это утверждение опровергнуть.
Если функция распределения случайной величины (или плотность распределения) заранее
неизвестна, возникает необходимость ее определение по эмпирическим данным. В связи с чем
возникает вопрос о согласованности теоретического и статистического (эмпирического) распределения.
Допустим, что данное статистическое распределение выровнено с помощью некоторой
теоретической кривой f(x).
f(x)
O
x
47
Как бы хорошо ни была подобрана теоретическая кривая, между нею и статистическим
распределением неизбежны некоторые расхождения, которые 1) могут быть объяснены только
случайными обстоятельствами, связанными с ограничением числа наблюдений, или 2) являются
существенными и связаны с тем, что подобранная кривая плохо выравнивает данное статистическое
распределение, то есть что действительное распределение случайной величины отличается от
предполагаемого. Для ответа на вопрос, с чем связаны расхождения, служат критерии согласия.
Критерии согласия
Определение 56. Критерии, которые позволяют судить, согласуются ли значения х1, х2,…, хn
случайной величины Х с гипотезой относительно ее функции распределения, называются критериями
согласия.
Идея применения критериев согласия
Пусть на основании данного статистического материала предстоит проверить гипотезу Н,
состоящую в том, что СВ Х подчиняется некоторому определенному закону распределения. Этот закон
может быть задан либо в виде функция распределения F(x), либо в виде плотности распределения f(x),
или же в виде совокупности вероятностей pi. Так как из всех этих форм функция распределения F(x)
является наиболее общей (существует и для ДСВ и для НСВ) и определяет собой любую другую, будем
формулировать гипотезу Н, как состоящую в том, что величина Х имеет функцию распределения F(x).
Для того, чтобы принять или опровергнуть гипотезу Н, рассмотрим некоторую величину U,
характеризующую степень расхождения (отклонения) теоретического и статистического распределений.
Величина U может быть выбрана различными способами: 1) сумма квадратов отклонений
n
теоретических вероятностей pi от соответствующих частот pi* i , 2) сумма тех же квадратов с
n
некоторыми коэффициентами (весами), 3) максимальное отклонение статистической (эмпирической)
функции распределения Fn* ( x) от теоретической F(x).
Пусть величина U выбрана тем или иным способом. Очевидно, что это есть некоторая случайная
величина. Закон распределения U зависит от закона распределения случайной величины Х, над которой
производились опыты, и от числа опытов n. Если гипотеза Н верна, то закон распределения величины U
определяется законом распределения величины Х (функцией F(x)) и числом n.
Допустим, что этот закон распределения известен. В результате данной серии опытов обнаружено,
что выбранная мера расхождения U приняла некоторое значение u. Вопрос: можно ли объяснить это
случайными причинами или же это расхождение слишком велико и указывает на наличие существенной
разницы между теоретическим и статистическим (эмпирическим) распределениями и, следовательно,
на непригодность гипотезы Н? Для ответа на этот вопрос предположим, что гипотеза Н верна, и
вычислим в этом предположении вероятность того, что за счет случайных причин, связанных с
недостаточным объемом опытного материала, мера расхождения U окажется не меньше, чем
наблюдаемое в опыте значение u, то есть вычислим вероятность события: U u .
Если эта вероятность мала, то гипотезу Н следует отвергнуть как мало правдоподобную, если же эта
вероятность значительна, то делаем вывод, что экспериментальные данные не противоречат гипотезе Н.
Возникает вопрос: каким же способом следует выбирать меру расхождения (отклонения) U?
Оказывается, что при некоторых способах ее выбора закон распределения величины U обладает весьма
простыми свойствами и при достаточно большом n практически не зависит от функции F(x). Именно
такими мерами расхождения и пользуются в математической статистике в качестве критериев согласия.
Определение 56/. Критерием согласия называется критерий проверки гипотезы о предполагаемом
законе неизвестного распределения.
48
Наиболее употребительные критерии проверки статистических гипотез:
1. критерий 2 — хи-квадрат (Пирсона),
2. критерий Стьюдента,
3. критерий Фишера,
4. критерий Колмогорова.
Обычно один из указанных критериев и употребляют при составлении теста (статистики) критерия
проверки. Основой для составления соответствующих формул критериев Пирсона, Стьюдента и
Фишера являются соответствующие соотношения.
Для количественных данных при распределениях, близких к нормальным, используют
параметрические методы, основанные на таких показателях, как математическое ожидание и
стандартное отклонение. В частности, для определения достоверности разницы средних для двух
выборок применяют метод (критерий) Стьюдента, а для того чтобы судить о различиях между
тремя или большим числом выборок, — тест F, или дисперсионный анализ.
Если же имеем дело с неколичественными данными или выборки слишком малы для
уверенности в том, что популяции, из которых они взяты, подчиняются нормальному
распределению, тогда используют непараметрические методы — критерий χ2 (хи-квадрат) или
Пирсона для качественных данных и критерии знаков, рангов; Манна-Уитни, Вилкоксона и др. для
порядковых данных.
Кроме того, выбор статистического метода зависит от того, являются ли те выборки, средние
которых сравниваются, независимыми (т. е., например, взятыми из двух разных групп испытуемых) или
зависимыми (т. е. отражающими результаты одной и той же группы испытуемых до и после воздействия
или после двух различных воздействий).
Пп. 1. Критерий Пирсона ( 2 — хи-квадрат)
Пусть произведено n независимых опытов, в каждом из которых случайная величина Х приняла
определенное значение, то есть, дана выборка наблюдений случайной величины Х (генеральной
совокупности) объема n.
Рассмотрим задачу по проверке близости теоретической и эмпирической функций распределения
для дискретного распределения, то есть требуется проверить, согласуются ли экспериментальные
данные с гипотезой Н0, утверждающей, что случайная величина Х имеет закон распределения F(x) при
уровне значимости α. Назовем этот закон «теоретическим».
При получении критерия согласия для проверки гипотезы определяют меру отклонения
эмпирической функции распределения Fn* ( x) данной выборки от предполагаемой (теоретической)
функции распределения F(x).
Наиболее употребительной является мера, введенная Пирсоном. Рассмотрим эту меру. Разобьем
множество значений случайной величины Х на r множеств — групп S1, S2,…, Sr , без общих точек.
Практически такое разбиение осуществляется с помощью (r — 1) чисел c1 < c2 < … < cr-1. При этом конец
каждого интервала исключают из соответствующего множества, а левый – включают.
S1
S2
S3
Sr-1
Sr
….
c1
c2
c3
cr-1
Пусть pi, i 1, r , — вероятность того, что СВ Х принадлежит множеству Si (очевидно
r
p
i 1
ni, i 1, r , — количество
i
1 ). Пусть
величин (вариант) из числа наблюдаемых, принадлежащих множеству Si
49
ni
относительная частота попадания СВ Х во множество Si при n
n
r
r
n
наблюдениях. Очевидно, что ni n , i 1 .
i 1
i 1 n
(эмпирические частоты). Тогда
ni
приращение
n
виде группированного
Для разбиения, приведенного выше, pi есть приращение F(x) на множестве Si, а
Fn* ( x) на этом же множестве. Cведем результаты опытов в таблицу в
статистического ряда.
Границы группы S1: x1 – x2
Относительная
n1
n
n
частота pi* i
n
S2: x2 – x3
n2
n
…
…
xr – xr+1
nr
n
Sr:
Зная теоретический закон распределения, можно найти теоретические вероятности попадания
случайной величины в каждую группу: р1, р2, …, pr. Проверяя согласованность теоретического и
эмпирического (статистического) распределений, будем исходить из расхождений между
n
теоретическими вероятностями pi и наблюдаемыми частотами pi* i .
n
За меру расхождения (отклонения) эмпирической функции распределения от теоретической
принимают сумму квадратов отклонений теоретических вероятностей pi от соответствующих частот
2
r
ni
n
, взятых с некоторыми «весами» ci: U ci i pi .
n
n
i 1
Коэффициенты ci вводятся потому, что в общем случае отклонения, относящиеся к разным группам,
нельзя считать равноправными по значимости: одно и то же по абсолютной величине отклонение
ni
pi может быть мало значительным, если сама вероятность pi велика, и очень заметным, если она
n
мала. Поэтому естественно «веса» ci взять обратно пропорциональным вероятностям. Как выбрать этот
коэффициент?
n
К.Пирсон показал, что если положить ci , то при больших n закон распределения величины U
pi
pi*
обладает весьма простыми свойствами: он практически не зависит от функции распределения F(x) и от
числа опытов n, а зависит только от количества групп r, а именно, этот закон при увеличении n
приближается к так называемому распределению «хи-квадрат» 2 .
Напомним, что распределением «хи-квадрат» 2 с k степенями свободы называется распределение
суммы квадратов k независимых случайных величин, каждая из которых подчинена нормальному
закону с математическим ожиданием, равным нулю, и дисперсией, равной единице.
То есть при таком выборе коэффициентов 2 обозначает меру расхождения (отклонения) U:
r
U
2
i 1
r
n ni
(n npi ) 2
.
pi i
pi n
npi
i 1
2
Величины npi n называются теоретическими частотами. Тогда
/
i
(ni ni/ ) 2
. (*)
ni/
i 1
r
2
Величина 2 случайная, определим ее распределение в предположении, что принятая гипотеза Н0
верна.
50
Теорема Пирсона. Какова бы ни была функция распределения F(x) случайной величины Х, при
n распределение величины 2 стремиться к 2 — распределению с k степенями свободы, то есть
x
при n P( x) f ( x)dx в каждой точке х, где f(x) – плотность распределения случайной
2
величины с k степенями свободы.
2
Распределение
2
Нахождение степеней свободы
зависит от параметра k – числа степеней свободы, которое определяется как
k r s 1, где s – число неизвестных параметров распределения случайной величины Х, r — число
интервалов группировки. Если предполагаем закон распределения Х полностью определенным, то
k r 1 . Если, например, выдвигаем гипотезу о том, что закон распределения Х – нормальный, а его
параметры m и определяем по выборке, то k r 2 1 r 3 .
Обычно с помощью теоремы Пирсона вводят критерий для поверки выдвинутой гипотезы Н0: СВ Х
распределена по нормальному закону, так как с увеличением степеней свободы распределение 2
стремится к нормальному закону.
Для распределения 2 составлены специальные таблицы (Таблица П5, стр. 412-413 задачника
Ефимова), пользуясь которыми можно для каждого значения 2 и числа степеней свободы k найти
вероятность р того, что величина, распределенная по закону 2 , превзойдет это значение.
Распределение
2 дает
возможность
оценить
степень
согласованности
теоретического
и
статистического распределений.
Будем исходить из того, что величина Х действительно распределена по закону F(x) . Тогда
вероятность р, определенная по таблице, есть вероятность того, что за счет чисто случайных причин
мера расхождения (отклонения) теоретического и статистического распределений U будет не меньше,
чем фактически наблюдаемое в данной серии опытов значение 2 . Если эта вероятность р весьма мала
(настолько, что событие с такой вероятностью можно считать практически невозможным), то результат
опыта следует считать противоречащим гипотезе Н0 о том, что закон распределения величины Х есть
F(x). Эту гипотезу следует отбросить как неправдоподобную. Напротив, если вероятность р
сравнительно велика, можно признать расхождения между теоретическим и статистическим
распределениями несущественными и отнести их за счет случайных причин. Гипотезу Н0 о том, что
величина Х распределена по закону F(x) можно считать правдоподобной или, по крайней мере, не
противоречащей опытным данным.
Схема применения критерия 2 к оценке согласованности теоретического и статистического
(эмпирического) распределений:
Дан статистический ряд:
zi
ni
z1
n1
z2
n2
…
…
zr
nr
…
xr-1 — xr
nr
Замечание. Если дан группированный статистический ряд
Интервалы
ni
x1 — x2
n1
x2 – x3
n2
…
51
то переписывают его в виде статистического ряда:
Середины
z1
интервалов
n1
ni
zi – середина интервала
…
z2
zr
…
n2
nr
Если задан вариационный ряд, то данные представляются в виде статистического ряда.
1) Задают уровень значимости α.
2) Находят оценки параметров нормального закона: выборочное среднее x и выборочное среднее
квадратическое :
n
x
xn
i i
i 1
n
xB m*X
или
1 n
( zi ni ) , где zi – середина интервала.
n i 1
1 n
n i 1
DX* DB , DB DX* xi2 ni n m*X
2
2
1 n 2
xi ni m*X или
n i 1
2
2
1 n
1 n
DB DX* zi2 ni n m*X zi2 ni m*X .
n i 1
n i 1
3) Вычисляют теоретические частоты по формуле npi ni/ , где pi P(ci 1 X ci ) , i 1, r
и
c x
c x
i 1 , примем c0 , cr . (x) — функция Лапласа.
P(ci 1 X ci ) i
Замечание 1. Если статистическое распределение выборки задано в виде последовательности
равноотстоящих вариант и соответствующих им эмпирических частот:
x1
n1
xi
ni
x2
n2
…
…
то в этом случае теоретические частоты вычисляются по формуле:
xr
nr
ni npi , где pi
x xB
,
f i
B B
h
x2
где h – шаг (разность между двумя соседними вариантами),
1 2
f ( x)
e — функция Гаусса
2
(плотность) вычисляется при помощи таблиц.
(ni ni/ ) 2
4) По формуле (*)
находится величина 2 набл. – наблюдаемое значение критерия
/
ni
i 1
r
2
r
r
(ni ni/ ) 2
ni2
/
2
n
n
.
i
/
ni/
i 1
i 1
i 1 ni
r
Пирсона. Контроль:
5) Находят число степеней свободы k r 3 .
6) По таблице критических точек распределения 2 , по заданному уровню значимости α и числу
степеней свободы k находят критическую точку правосторонней критической области кр2 ( , k ) .
2
2
7) Если набл
. кр , то нет оснований отвергнуть гипотезу о нормальном распределении случайной
2
2
величины Х. Если набл
. кр , то гипотезу отвергают.
52
Насколько мала должна быть вероятность р для того, чтобы отбросить или пересмотреть гипотезу, вопрос неопределенный, он не может быть решен из математических соображений, так же как и вопрос
о том, насколько мала должна быть вероятность события для того, чтобы считать его практически
невозможным. На практике, если р оказывается меньшим, чем 0,1, рекомендуется проверить
эксперимент, если возможно – повторить его и в случае, если заметные расхождения снова появятся,
пытаться искать более подходящий для описания статистических данных закон распределения.
С помощью критерия 2 (или любого другого критерия согласия) можно только в некоторых
случаях опровергнуть выбранную гипотезу или отбросить ее как явно несогласную с опытными
данными. Если же вероятность р велика, то этот факт сам по себе ни в коем случае не может считаться
доказательством справедливости гипотезы, а указывает только на то, что гипотеза не противоречит
опытным данным.
Замечание 2. Асимптотический характер теоремы Пирсона, лежащий в основе этого правила,
требует осторожности при его практическом использовании. На него можно полагаться только при
больших n. Достаточно велико должно быть и n, и все и произведения npi. На практике рекомендуется
иметь в каждом интервале не менее 5-10 наблюдений. Критерий 2 использует тот факт, что случайная
величина
ni npi
, i 1, r , имеет закон распределения близкий к нормальному N(0, 1). Проблема
npi
применимости аппроксимации 2 (непрерывное распределение) к статистике, распределение которой
дискретно, оказалась сложной. Согласно имеющемуся опыту, аппроксимация применима, если все
ожидаемые частоты npi > 10. Если число различных исходов велико, граница для npi может быть
снижена: необходимо, чтобы для всех интервалов выполнялось условие npi 5 . Если в некоторых
интервалах это условие не выполняется, то их следует объединить с соседними.
xi
ni
Пример 32. Дан статистический ряд:
2,5
3,0
3,5
4,0
4,5
5,0
5,5
6,0
6,5
7
xi
5
7
8
18
20
15
10
7
6
4
ni
Проверить гипотезу о нормальном распределении данной генеральной совокупности. Уровень
значимости α = 0,01.
Решение.
10
Найдем x
1)
x
xn
i i
i 1
n
10
, где n ni .
i 1
2,5 5 3 7 3,5 8 4 18 4,5 20 5 15 5,5 10 6 7 6,5 6 7 4 462,5
4,625 .
5 7 8 18 20 15 10 7 6 4
100
2) Найдем DX* DB :
2
2
1 n
1 n
DB DX* xi2 ni n m*X xi2 ni m*X =1,25. Тогда 1,12 .
n i 1
n i 1
nh xi xB
.
f
B B
nh
44,64 .
n = 100, разность между соседними вариантами h = 0,5, 1,12 , тогда
3) Вычислим теоретические частоты по замечанию 1: ni npi
B
Составим таблицу:
53
i
xi xB
xi
B
1
2
3
4
5
6
7
8
9
10
2,5
3
3,5
4
4,5
5
5,5
6
6,5
7
-1,9
-1,45
-1
-0,56
-0,11
0,33
0,78
1,23
1,67
2,12
x xB
f i
B
0,0656
0,1394
0,242
0,341
0,3965
0,3778
0,2943
0,1872
0,0989
0,0422
x xB
ni 44,64 f i
B
2,93
6,22
10,8
15,22
17,7
16,86
13,14
8,36
4,41
1,88
(ni ni/ ) 2
4) По формуле (*)
найдем величину 2 набл. – наблюдаемое значение критерия
/
ni
i 1
r
2
Пирсона. Для удобства вычислений составим таблицу (или продолжить предыдущую):
i
ni
ni
(ni ni/ ) 2
ni2
1
2
3
4
5
6
7
8
9
10
Σ
5
7
8
18
20
15
10
7
6
4
n = 100
2,93
6,22
10,8
15,22
17,7
16,86
13,14
8,36
4,41
1,88
97,52
ni/
ni/
1,46
0,1
0,73
0,51
0,3
0,21
0,75
0,22
0,57
2,39
7,24
8,53
7,88
5,93
21,29
22,6
13,35
7,61
5,86
8,16
8,51
109,72
(ni ni/ )2
7,24 .
ni/
i 1
10
2
2
набл
.
10
10
(ni ni/ ) 2
ni2
/
2
n
n
200 97,52 109,72 7,24 .
i
/
ni/
i 1
i 1
i 1 ni
10
Контроль:
5) Найдем число степеней свободы. Число групп выборки r =10, тогда k r 3 10 3 7 .
6) Найдем кр2 по таблицам. Уровень значимости α = 0,01, число степеней свободы k = 7, тогда
кр2 ( , k ) кр2 (0,01; 7) 18,5 .
7) Сравним
2
2
набл
. и кр :
2
2
2
2
набл
. 7,24 кр 18,5 . Так как набл. кр , то гипотезу о нормальном
распределении генеральной совокупности принимаем. Эмпирические и теоретические частоты
различаются незначимо.
Ответ: генеральная совокупность распределена нормально.
Пп. 2. Двусторонние и односторонние гипотезы. Критерий Стьюдента (t – критерий).
Пусть случайная величина Х имеет нормированное нормальное распределение, то есть М(Х) = 0,
σХ = 1.
54
Напомним, что распределением Стьюдента с n-1 степенью свободы называется распределение
n
~m
m
~
случайной величины T n ~ , где m
n
xi
i 1
~
D
( x m~ )
i 1
2
i
, где Х подчинена нормальному
n 1
n
закону с математическим ожиданием, равным нулю, и дисперсией, равной единице.
,
Условия использования коэффициента Стьюдента: 1) исследуемые данные подчиняются
нормальному закону распределения; 2) равенство дисперсий (при сравнении двух выборок)
Метод (критерий) Стьюдента или t – критерий применяют в практике для проверки статистических
гипотез о равенстве средних значений двух выборок или среднего значения выборки с неким значением
(целевым показателем). В последнем случае различают двухсторонние (предположение о равенстве
среднего и целевого значений) и односторонние (предположение, что среднее арифметическое значение
больше или меньше целевого) гипотезы. От типа гипотезы зависит выбор статистической значимости.
Если цель исследования в том, чтобы выявить различие параметров двух генеральных совокупностей,
которые соответствуют различным ее естественным условиям (условия жизни, возраст испытуемых и т.
п.), то часто неизвестно, какой из этих параметров будет больше, а какой меньше. Например, если
интересуются вариативностью результатов в контрольной и экспериментальной группах, то, как
правило, нет уверенности в знаке различия дисперсий или стандартных отклонений результатов, по
которым оценивается вариативность. Или требуется проверить, различается ли уровень дохода
населения в разных регионах. В этом случае нулевая гипотеза состоит в том, что дисперсии равны
между собой ( Н 0 : 12 22 ), а цель исследования — доказать обратное ( Н1 : 12 22 ), т.е. наличие
различия между дисперсиями. При этом допускается, что различие может быть любого знака. Такие
гипотезы называются двусторонними.
Если гипотеза двухсторонняя, т.е. важно выявить различия в группах, а знак различий не важен, то
решение принимается на основе двухсторонней значимости.
Но иногда задача состоит в том, чтобы доказать увеличение или уменьшение параметра; например,
средний результат в экспериментальной группе выше, чем контрольной. Или требуется проверить
тот факт, что в регионе А уровень дохода населения выше, чем в регионе В. При этом уже не
допускается, что различие может быть другого знака. Тогда альтернативная гипотеза Н1 : 2 1 (или
Н1 : 2 1 ), а обратное ей утверждение Н 0 : 2 1 (или Н 0 : 2 1 ). Такие гипотезы называются
односторонними.
Если гипотеза односторонняя, т.е. важно выявить различия со знаком, то решение принимается на
основе односторонней значимости.
Определение 57. Критерии значимости, служащие для проверки двусторонних гипотез, называются
двусторонними, а для односторонних — односторонними.
Возникает вопрос о том, какой из критериев следует выбирать в том или ином случае. Ответ на
этот вопрос находится за пределами формальных статистических методов и полностью зависит от целей
исследования. Ни в коем случае нельзя выбирать тот или иной критерий после проведения
эксперимента на основе анализа экспериментальных данных, поскольку это может привести к неверным
выводам.
Если до проведения эксперимента допускается, что различие сравниваемых параметров может быть
как положительным, так и отрицательным, то следует использовать двусторонний критерий.
55
Если же есть дополнительная информация, например, из предшествующих экспериментов, на
основании которой можно сделать предположение, что один из параметров больше или меньше
другого, то используется односторонний критерий.
Когда имеются основания для применения одностороннего критерия, его следует предпочесть
двустороннему, потому что односторонний критерий полнее использует информацию об изучаемом
явлении и поэтому чаще дает правильные результаты.
Например, необходимо доказать различие средних значений генеральных совокупностей (средних
значений некоторого результата исследований) при двух различных методиках применяемых в
контрольной и экспериментальной группах. Если есть данные, что экспериментальная группа покажет в
среднем лучший результат, то нужно выдвинуть нулевую гипотезу Н 0 : 2 1 против двусторонней
альтернативы Н1 : 2 1 . Различие доказывается по разности средних арифметических в контрольной
и экспериментальной группах ( х2 х1 ). Распределение разности х2 х1 при условии, что верна нулевая
гипотеза Н0 схематично представлено на рис. а.
Рис. Уровни значимости при двустороннем (а) и одностороннем (б) критериях
Решение об отклонении гипотезы Н0 принимается в том случае, если разность х2 х1 выходит за
пределы некоторого значения Кдвух (допустимы отклонения в обе стороны от нуля). Ошибка, которая
при этом допускается, равна, как известно, уровню значимости .
Но поскольку отклонения возможны в обе стороны, то при симметричном распределении
вероятности отклонений, больших Кдвух и меньших Кдвух, будут одинаковы и составят
.
2
Если предположить, что в экспериментальной группе будут показаны в среднем более высокие
результаты, то можно выдвинуть одностороннюю альтернативу Н1 : 2 1 . В этом случае при той же
нулевой гипотезе Н 0 : 2 1 распределение разности х2 х1 будет таким же, как и для двустороннего
критерия (см. рис. б). Но теперь представляют интерес только положительные значения разности
х2 х1 . Решение об отклонении Н0 принимается, когда х2 х1 окажется больше некоторого Кодн. При
том же уровне значимости Кодн будет всегда меньше Кдвух, поэтому нулевая гипотеза будет при
одностороннем критерии отклоняться чаще.
Таким образом, двусторонние критерии оказываются более консервативными, чем
односторонние. В этом нет никакого противоречия или доказательства несостоятельности
статистических методов. Просто в первом случае, используя двустороннюю гипотезу, мы допускали и
отрицательный эффект новой программы. В такой ситуации выводы должны быть более осторожными,
чем в случае односторонней гипотезы, когда имеется дополнительная информация, позволяющая
сделать предположение о положительном эффекте новой программы, что, естественно, дает
возможность сделать более точный вывод. Правда, следует отметить, что если превышение
критического значения в каком-либо исследовании незначительно, то в достоверности вывода о
наличии положительного эффекта можно усомниться. В такой ситуации следует провести
дополнительные исследования.
56
Использование критерия Стьюдента предполагает сравнение распределения наблюдаемой
величины с распределением Стьюдента. Квантили этого распределения (квантилем порядка p (0 < p < 1)
называется величина xp, определяемая из соотношения P{X < xp} = F(xp) = p) приведены в специальной
таблице: критические точки распределения находятся обычно по заданному уровню значимости (для
односторонних (α) и двусторонних (α/2) гипотез) и числу степеней свободы. (Табличные значения
коэффициента Стьюдента в учебнике Ефимова-Демидовича находятся на стр. 414 и вычисляются по
заданной вероятности и числу степеней свободы для tk(p) = tα/2,n-1)).
По заданному уровню значимости и числу степеней свободы из таблиц распределения
Стьюдента находят критическое значение tкр. Далее необходимо сравнить полученное значение t с
теоретическим значением tкр. При односторонних альтернативных гипотезах, если t < tкр, то гипотеза
H0 принимается, в противном случае нулевая гипотеза отвергается и принимается альтернативная
гипотеза. При двусторонних: если |t| > tкр, то гипотезу однородности (отсутствия различия)
отклоняют, если же
|t| < tкр, то принимают.
Замечание. Односторонний критерий значимости легко получать из двустороннего. Критическая
область гипотезы (заштрихованная на рис. а) состоит из двух частей. Каждая часть соответствует своему
неравенству. Если заранее известно, что возможно лишь одно из этих неравенств, то и рассматривать
должны лишь одну из половин критической области. Вероятность попадания в критическую область
уменьшится, тем самым, ровно вдвое и станет равна р/2.
Таким образом, при одностороннем критерии значимости можно использовать те же
критические значения, что и при двустороннем, однако этим значениям будет соответствовать
вдвое меньший уровень значимости.
Например, уровню значимости 0,05 при двустороннем критерии соответствуют критические
значения ξ0,025 и ξ0,975 , т.е. значимыми (неслучайными) считаются значения ξо,, удовлетворяющие
неравенствам ξо < ξ0,025 и ξо > ξ0,975 . Если же перейти к одностороннему критерию, то одно из этих
неравенств (например, ξо < ξ0,025) заведомо невозможно и значимыми будут лишь значения ξо
удовлетворяющие другому неравенству (ξо > ξ0,975). Вероятность последнего неравенства равна 0,025,
таков и будет уровень значимости одностороннего критерия.
Обычно для одностороннего критерия берут тот же уровень значимости, что и для
двустороннего, так как ошибка первого рода в обоих случаях нежелательна совершенно одинаково.
Для этого нужно выводить односторонний критерий из двустороннего, соответствующего вдвое
большему уровню значимости, чем тот, что нами принят.
Так, в предыдущем примере, желая сохранить уровень значимости 0,05 для одностороннего
критерия, для двустороннего должны были бы взять уровень 0,10, что дало бы критические значения
ξ0,05 и ξ0,95 . Из этих значений для одностороннего критерия сохраняется одно (скажем, ξ0,95), которое и
будет окончательным критическим значением, соответствующим одностороннему критерию при
уровне значимости 0,05.
Итак, при одном и том же уровне значимости 0,05 одному и тому же неравенству A1 >A2 в случае
двустороннего критерия соответствует критическое значение ξ0,975, а одностороннего — ξ0,95 . Но ξ0,95 <
ξ0,975 , значит, при одностороннем критерии большее число значений ξо придется считать не
случайными (значимыми), большее число гипотез будет отвергнуто. Тем самым уменьшится вероятность принять неверную гипотезу, допустить ошибку второго рода. А вероятность ошибки первого
рода как для одностороннего, так и для двустороннего критерия остается одинаковой, ибо она равна
уровню значимости.
Пример 33. (наглядно подчеркивающий преимущества одностороннего критерия значимости перед
двусторонним). Сталеплавильный завод изготовляет специальную сталь, которая должна содержать
40% ванадия. Контроль ведется на уровне значимости 0,05; методика контроля дает нормальное
57
распределение результатов со стандартом σ = 2%. Контрольный анализ партии стали дал для
содержания ванадия значение 36,4 %. Достаточно ли этого результата, чтобы забраковать партию?
Решение.
Обозначим через ξ результат произвольного анализа над доброкачественной сталью. Согласно
условиям задачи величина ξ имеет нормальное распределение с параметрами m = 40 и σ = 2. Используя
формулы для нахождения доверительного интервала, получим точность εβ =2·1,96 = 3,92 и
доверительный интервал равен lβ =(36,08; 43,92).
В качестве нулевой гипотезы здесь нужно взять гипотезу о том, что исследуемая сталь
доброкачественна и, следовательно, значение ξо = 36,4 появилось в результате случайностей анализа.
Критическими значениями такой гипотезы при двустороннем критерии (смотрим по таблице) будут
числа t0,025 = 36,08 и t0,975 = 43,92; критическая область образуется неравенствами ξ < 36,08 и ξ > 43,92.
Значение ξо =36,4 не попадает в эту критическую область, следовательно, двусторонний критерий не
позволяет отвергнуть нулевую гипотезу и считать сталь недоброкачественной.
Условия задачи позволяют применить односторонний критерий значимости. Действительно,
найденное значение ξо =36,4 меньше медианы υ0,50 = 40, поэтому его можно сравнивать только с теми
критическими значениями, которые меньше 40. Уровень значимости 0,05 · 2 = 0,1. Критическим
значением проверяемой нулевой гипотезы при одностороннем критерии является квантиль:
t = 40 – εβ = 40 – 2 · Ф -1 (0,95) = 40 – 2 · 1,64 = 36,72. Видно, что ξо < 36,72, т. е. ξо попадает в
критическую область. Таким образом, односторонний критерий, как более точный, сумел, при тех же
исходных данных выявить недоброкачественность стали
Использование критерия Стьюдента
1) Испытание гипотез на основе выборочной средней при известной генеральной дисперсии
Для выборки объема n вычисляется выборочная средняя х , a~ — предполагаемое значение
~ ). Граничные точки t = (для правосторонней проверки), t = — (для
генеральной средней (или m
кр
кр
левосторонней проверки), tкр= ± (для двусторонней проверки). В качестве критерия проверки
x a~
принимается случайная величина статистика T
, которая имеет распределение Стьюдента с n-1
/ n
степенями свободы.
Пример 34. Автомат, работающий со стандартным отклонением σ = 1 г, фасует чай в пачки со
средним весом a~ = 100 г. В случайной выборке объема n = 25 пачек средний вес х =101,5 г. Надо ли
отрегулировать автомат, если доверительная вероятность р = 95%?
Решение.
Н0: для нормальной совокупности генеральная средняя a~ = 100 г. Тогда Н1: a~ ≠ 100 г. Проведем
двустороннюю проверку. Область принятия гипотезы (–tкр, tкр.)
Найдем уровень значимости. Доверительная вероятность p 0,95 уровень значимости для
двусторонней проверки (1 p) / 2 (1 0,95) / 2 0,025 .
x a~ 101,5 100
Найдем значение статистики: T
7,5 = tнабл. – наблюдаемое значение критерия.
/ n
1 / 25
Найдем область принятия гипотезы, то есть найдем критические точки.
1 способ. Найдем значения критических точек при помощи доверительного интервала
~ ;m
~ ) . Найдем значение = t :
l ( m
кр
1
, по условию m~ 1, тогда
2
m~ Ф-1
1 0,95
-1
= Ф 0,975 = 1,96.
2
1 Ф-1
58
То есть, tкр 1,96 для двусторонней области критические точки равны ± 1,96.
Отметим значения на числовой оси:
Отклонение Н0
Принятие Н0
Отклонение Н0
Принятие Н1
95%
Принятие Н1
2,5%
2,5 %
-1,96
1,96
7,5
Наблюдаемое значение статистики (критерия) принадлежит критической области, следовательно,
гипотезу отвергают.
2 способ. Найдем значения критических точек t кр , используя таблицы распределения Стьюдента:
для уровня значимости α = 1– –0,95 = 0,05 и двадцати четырех степеней свободы по таблицам
распределения Стьюдента находим, что t кр = t,n1 2, 064 ( в учебнике Ефимова-Демидовича t
1 , n 1
2
)и
t < tкр.
Ответ: Отклоняем гипотезу Н0 и принимаем гипотезу Н1 на уровне значимости 5 %. Автомат нужно
отрегулировать.
2) Для проверки гипотезы: «Средние двух выборок относятся к одной и той же совокупности»
Данный критерий наиболее часто используется для проверки гипотезы: «Средние двух выборок
относятся к одной и той же совокупности». При использовании критерия можно выделить два случая. В
первом случае его применяют для проверки гипотезы о равенстве генеральных средних двух независимых, несвязанных выборок (так называемый двухвыборочный t-критерий). В этом случае есть
контрольная группа и экспериментальная (опытная) группа, количество испытуемых в группах может
быть различно.
Во втором случае, когда одна и та же группа объектов порождает числовой материал для проверки
гипотез о средних (результаты одной и той же группы испытуемых до и после воздействия независимой
переменной), используется так называемый парный t-критерий. Выборки при этом называют
зависимыми, связанными.
а) случай независимых выборок.
Критерий Стьюдента — метод проверки однородности двух независимых выборок (то есть нет
различий). В математико-статистических терминах постановка задачи такова: имеются две выборки x1,
x2,…, xm и y1, y2,…,yn (m и n соответственно величины первой и второй выборки), требуется проверить
их однородность. Можно переформулировать задачу: требуется проверить, есть ли различие между
выборками. Если различия нет, то для дальнейшего изучения часто выборки объединяют.
Опишем традиционный статистический метод проверки однородности. Вычисляют средние
m
арифметические
в
каждой
m
DX
(x x)
i 1
i
m 1
n
2
, DY
( y
i 1
i
выборке:
x
n
xi
i 1
m
,
y
y
i 1
n
i
,
затем
выборочные
дисперсии:
y )2
n 1
, затем статистику t для случая несвязных независимых выборок,
на основе которой принимают решение: t
xy
(m 1) DX (n 1) DY
mn(m n 2)
.
mn
Подсчет числа степеней свободы осуществляется по формуле: k = m + n – 2. При
равенстве выборок k = 2n — 2.
численном
59
Пример 35. В двух группах учащихся — экспериментальной и контрольной — получены
следующие результаты по учебному предмету (тестовые баллы; см. табл)
Первая группа (экспериментальная) m = 11 человек
Вторая группа (контрольная)
n = 9 человек
13 9 11 10 7 6 8 10 11
12 14 13 16 11 9 13 15 15 18 14
Какой метод имеет преимущество (экспериментальный или традиционный)?
Решение.
Нулевая гипотеза H0 — учащиеся контрольной группы показывают в среднем более высокий
уровень знаний; альтернативная гипотеза (H1) — учащиеся экспериментальной группы показывают в
среднем более высокий уровень знаний.
H0: mX > mY, H1: mX ≤ mY, область принятия гипотезы (–∞, tкр.) . Проведем одностороннюю
проверку.
Общее количество членов выборки: m = 11, n = 9.
m
Расчет средних арифметических: x
x
i 1
m
i
12 14 13 16 11 9 13 15 15 18 14
13,636 ,
11
n
y
y
i 1
n
i
13 9 11 10 7 6 8 10 11
9,444 ,
9
m
выборочных дисперсий: DX
( xi x )2
i 1
m 1
Считаем статистику критерия: t
n
6,0516 , DY
xy
(m 1) DX (n 1) DY
( y
i 1
i
y )2
n 1
4,778596 ,
mn(m n 2)
3,981 = tнабл.
mn
Найдем число степеней свободы по формуле: k = m + n – 2 = 11+ 9 – 2 = 18.
Возьмем уровень значимости равным 5 % или 0,05, то есть допускаем возможность риска сделать
ошибочное суждение в пяти случаях из ста.
Для односторонней проверки доверительная вероятность равна p 1 1 0,05 0,95 .
Табличное значение tкр =1,73. Область принятия гипотезы (–∞, 1,73).
Сравниваем полученное в эксперименте значение t с табличным значением с учетом степеней
свободы. Если полученное в эксперименте эмпирическое значение t превышает табличное, то есть
основания принять альтернативную гипотезу (H1) о том, что учащиеся экспериментальной группы
показывают в среднем более высокий уровень знаний. В эксперименте t = 3,981, табличное t = 1,73,
3,981 > 1,73, откуда следует вывод о преимуществе экспериментального обучения.
Отметим значения на оси:
Принятие Н0
Отклонение Н0
95%
Принятие Н1
1,73
3,981
Ответ: Экспериментальный метод имеет преимущество.
При решении задачи могут возникнуть такие вопросы:
60
1. Что если полученное в опыте значение t окажется меньше табличного? Тогда надо принять
нулевую гипотезу.
2. Доказано ли преимущество экспериментального метода? Не столько доказано, сколько
показано, потому что с самого начала допускается риск ошибиться в пяти случаях из ста (р = 0,05).
Наш эксперимент мог быть одним из этих пяти случаев. Но 95% возможных случаев говорит в пользу
альтернативной гипотезы, а это достаточно убедительный аргумент в статистическом доказательстве.
3. Что если в контрольной группе результаты окажутся выше, чем в экспериментальной?
Поменяем, например, местами, сделав средней арифметической экспериментальной группы, a —
контрольной, получим, что t = — 3,981. Отсюда следует вывод, что новый метод пока не проявил себя с
хорошей стороны по разным, возможно, причинам. Поскольку абсолютное значение 3,9811>2,1,
принимается вторая альтернативная гипотеза (Н2) о преимуществе традиционного метода.
Замечание. Для обоснованного применения математико-статистических методов необходимо,
прежде всего, построить и обосновать вероятностную модель порождения данных. При проверке
однородности двух выборок общепринята модель, в которой x1, x2,…, xm рассматриваются как
результаты m независимых наблюдений некоторой случайной величины Х с функцией распределения
F(x), неизвестной статистику, а y1, y2,…,yn — как результаты n независимых наблюдений, вообще
говоря, другой случайной величины Y с функцией распределения G(у), также неизвестной статистику.
Предполагается также, что наблюдения в одной выборке не зависят от наблюдений в другой, поэтому
выборки и называют независимыми.
Возможность применения модели в конкретной реальной ситуации требует обоснования.
Независимость и одинаковая распределенность результатов наблюдений, входящих в выборку, могут
быть установлены или исходя из методики проведения конкретных наблюдений, или путем проверки
статистических гипотез независимости и одинаковой распределенности с помощью соответствующих
критериев.
Если проведено (m+n) измерений линейных размеров деталей, то описанную выше модель, как
правило, можно применять. Если же, например, xi и yi — результаты наблюдения одного и того же
образца до и после определенного технологического воздействия, то рассматриваемую модель
применять нельзя. (В этом случае используют модель так называемых связанных выборок, в которой
обычно строят новую выборку zi = xi — yi и используют статистические методы анализа одной выборки,
а не двух.)
b) случай зависимых связанных (парных) выборок.
Для определения достоверности разницы средних в случае зависимых выборок применяется
n
следующая формула: t
d
i 1
n
n d 2 d
i 1
i 1
n 1
n
di xi yi ;
n
2
, где d — разность между результатами в каждой паре:
di — сумма этих частных разностей;
i 1
n
d
i 1
2
i
— сумма квадратов частных разностей.
Число степеней свободы k определяется по формуле k = n – 1, где n — это в данном случае число пар
данных. Полученные результаты сверяют с таблицей t, отыскивая в ней значения, соответствующие
n-1 степени свободы. Если t < tкр, то нулевая гипотеза принимается, в противном случае принимается
альтернативная.
Перед тем как использовать формулу, необходимо вычислить для каждой группы частные разности
между результатами во всех парах, квадрат каждой из этих разностей, сумму этих разностей и сумму
их квадратов.
61
Пример 36. Изучался уровень ориентации учащихся на художественно-эстетические ценности. С
целью активизации формирования этой ориентации в экспериментальной группе проводились беседы,
выставки детских рисунков, были организованы посещения музеев и картинных галерей, проведены
встречи с музыкантами, художниками и др. С целью проверки эффективности этой работы до начала
эксперимента и после давался тест. В таблице приведены результаты небольшого числа испытуемых.
Ученики
(n=10)
до
Баллы
В начале эксперимента (Х)
В конце эксперимента (У)
Иванов
14
18
Новиков
Сидоров
Пирогов
Агапов
Суворов
Рыжиков
Серов
Топоров
Быстров
Среднее
20
15
11
16
13
16
19
15
9
148
19
22
17
24
21
25
26
24
15
211
14,8
21,1
Вспомогательные расчеты
d
d2
4
-1
7
6
8
8
9
7
9
6
63
16
1
49
36
64
64
81
49
81
36
477
Вопрос: какова эффективность проведенной работы? Уровень значимости равен 0,05.
Решение.
Нулевая гипотеза (H0) – проведенная работа не эффективна; альтернативная гипотеза (H1) –
экспериментальное воздействие эффективно. H0: mX = mY, H1: mX ≠ mY, это двусторонняя проверка.
Область принятия гипотезы (–tкр; tкр).
Количество пар n = 10.
Для определения достоверности разницы средних произведем расчет по формуле:
n
d
t
i 1
2
63
10 477 63 2
10 1
6,678 = tнабл..
n d 2 d
i 1
i 1
n 1
Число степеней свободы: k = 10 — 1 = 9, уровень значимости α = 0,05. По таблице находим для
двусторонней области tкр = 2,262.
Экспериментальное tнабл. = 6,678, tкр = 2,263, очевидно, что t > tкр, откуда следует возможность
принятия альтернативной гипотезы (H1) о достоверных различиях средних арифметических, т. е.
делается вывод об эффективности экспериментального воздействия. В терминах статистических
гипотез полученный результат будет звучать так: на 5% уровне гипотеза Н0 отклоняется и принимается
гипотеза Н1 .
Отметим значения на оси:
Отклонение Н0
Принятие Н0
Отклонение Н0
Принятие Н1
95%
Принятие Н1
2,5%
2,5 %
-2, 262
2,262
6,678
n
n
Ответ: экспериментальное воздействие эффективно.
62
Проверка на значимость коэффициента корреляции r * r
Проверка на значимость вычисленных выборочных коэффициентов корреляции представляет собой
проверку следующей гипотезы: существенно ли (значимо ли) отличается от нуля рассчитанный по ряду
измерений объема эмпирический коэффициент корреляции?
Процедура проверки значимости начинается с формулировки нулевой гипотезы Н0.
Формулировка нулевой гипотезы Н0: = 0, то есть между параметром выборки и параметром
генеральной совокупности есть существенные различия. В генеральной совокупности отсутствует
корреляция, и от нуля выборочного коэффициента корреляции объясняется только случайностью
выборки.
Альтернативная гипотеза Н1: может быть одной из видов: двусторонней Н1: ≠ 0 (если не
известен знак корреляции) и односторонней Н1: > 0 или < 0 (если знак корреляции определен) и ее
формулировка: между этими параметрами существенных различий нет.
Например, при проверке наличия корреляции в генеральной совокупности нулевая гипотеза Н0
заключается в том, что истинный коэффициент корреляции равен нулю: 0 . Если в результате
проверки окажется, что нулевая гипотеза не приемлема, то выборочный коэффициент корреляции
значимо отличается от нуля r * r 0 (нулевая гипотеза отвергается и принимается альтернативная),
предложение о некоррелированности случайных переменных в генеральной совокупности следует
признать необоснованным. И наоборот, если нулевая гипотеза принимается, то есть r * лежит в зоне
случайного рассеивания, то нет оснований считать сомнительным предположение о
некоррелированности случайных переменных в генеральной совокупности.
При проверке гипотезы следует воспользоваться двусторонней критической областью.
При проверке значимости исследователь устанавливает уровень значимости α, который дает
определенную практическую уверенность в том, что ошибочные заключения будут сделаны только в
очень редких случаях (уровень значимости выражает вероятность в том, что нулевая гипотеза
отвергается в то время, когда она верна). Ясно, что имеет смысл выбирать эту вероятность как можно
меньшей.
Для проверки гипотезы используется t-критерий Стьюдента. Вычисленная по результатам
выборки статистика t набл.
r* n 2
1 r
*2
сравнивается с критическим значением, определяемым по
таблицам распределения Стьюдента при заданном уровне значимости (или заданной доверительной
внероятности) и с (n – 2) степенями свободы.
Для двусторонней проверки: если tнабл. tα,n-2, то нулевая гипотеза на уровне значимости
отвергается. Если t tα,n-2, то принимается.
Для односторонней проверки: если tэмпир.= tнабл. > tкрит, то нулевая гипотеза отклоняется, то есть
происходит маловероятное событие, предположение о некоррелированности признаков не обосновано и
коэффициент корреляции считается значимым. Если tэмпир. < tкрит, то принимается нулевая гипотеза,
значит в в генеральной совокупности отсутствует значимая корреляция, а отличие от нуля выборочного
коэффициента корреляции объясняется только случайностью выборки, и коэффициент корреляции
считается незначимым. Данные выборки характеризуют рассматриваемую гипотезу как весьма
возможную и правдоподобную, то есть гипотеза об отсутствии связи не вызывает возражений.
Выводы: для двусторонней альтернативной гипотезы – коэффициент корреляции значимо
отличается от нуля; для односторонней гипотезы – существует статистически значимая положительная
(или отрицательная) корреляция.
63
Пример 37. Проверим гипотезу о независимости производительности труда от уровня механизации
работ при уровне значимости α = 0,05.
Предприятие i
1
2
3
4
5
6
7
8
9
10
11
12
13
14
i
Производительность 20
Труда yi
Коэффициент
32
Механизации % xj
24
28
30
31
33
34
37
38
40
41
43
45
48
492
30
36
40
41
47
56
54
60
55
61
67
69
76
724
Решение.
Гипотеза Н0 — производительность труда не зависит от уровня механизации работ, тогда
альтернативная гипотеза Н1 — производительность труда зависит от уровня механизации работ.
Вычислим выборочный коэффициент корреляции по формуле:
M M X MY
r * r ( x, y) XY
= 0,9687.
XY
Вычислим значение статистики: t
r* n 2
*2
= 13,52 = tнабл.
1 r
Число степеней свободы n – 2 = 14 – 2 = 12.
Найдем критическое значение по таблице распределения Стьюдента при заданном уровне
значимости α = 0,05 и с 12 степенях свободы: tα,n-2 = t0,05, 12 = 2,79 = tкрит..
Сравним t и tкрит:
13,52 > 2,79, то есть tнабл. tα,n-2, следовательно, нулевую гипотезу отвергаем,
допуская ошибку лишь в 5% случаев, и принимаем альтернативную гипотезу.
Отметим значения на оси значимости:
Отклонение Н0
Принятие Н0
Отклонение Н0
Принятие Н1
95%
Принятие Н1
2,5%
2,5 %
-2,79
2,79
13,52
Замечание. Распределение Стьюдента используется при проверке статистических гипотез при
небольшом объѐме выборки. Изучать малые выборки начал английский статистик В.С. Госсет
(псевдоним Стьюдент) в 1908 году. Он доказал, что оценка расхождения между средней малой выборки
и генеральной средней подчинена особому закону распределения.
Пп. 3. Критерий Фишера (F-критерий)
Критерий Фишера позволяет сравнивать величины выборочных дисперсий двух независимых
выборок. Для вычисления F нужно найти отношение дисперсий двух выборок, причем так, чтобы
большая по величине дисперсия находилась бы в числителе, а меньшая – в знаменателе. Формула
D
вычисления критерия Фишера такова: F X , где DX и DY — дисперсии первой и второй выборки
DY
соответственно.
Так как, согласно условию критерия, величина числителя должна быть больше или равна величине
знаменателя, то значение F всегда будет больше или равно единице.
Число степеней свободы определяется также просто: k1=m — 1 для первой выборки (т.е. для той
выборки, величина дисперсии которой больше) и k2=n — 1 для второй выборки.
64
В таблице учебника критические значения критерия Фишера находятся по величинам k1 (верхняя
строчка таблицы) и k2 (левый столбец таблицы).
Если t > tкр, то нулевая гипотеза принимается, в противном случае принимается альтернативная.
Пример 38. В двух третьих классах проводилось тестирование умственного развития по тесту
ТУРМШ десяти учащихся. Полученные значения величин средних достоверно не различались, однако
психолога интересует вопрос — есть ли различия в степени однородности показателей умственного
развития между классами.
Решение.
Н0 – гипотеза о сходстве, то есть нет различий; Н1 – различия имеются.
Для критерия Фишера необходимо сравнить дисперсии тестовых оценок в обоих классах. Результаты тестирования представлены в таблице:
№№ учащихся
класс
1
2
3
4
5
6
7
8
9
10
Суммы
Среднее
Первый
класс
90
29
39
79
88
53
34
40
75
79
606
60,6
Второй
41
49
56
64
72
65
63
87
77
62
636
63,6
Рассчитаем дисперсии для переменных X и Y, получим: DX = 572,83 и DY = 174,04.
D
По формуле для расчета по F — критерию Фишера находим: F X 3,29 .
DY
По таблице из учебника для F -критерия при степенях свободы в обоих случаях равных k =10 — 1 = 9
и уровне значимости 0,05 находим Fкр= 3,18 (< 3.29), следовательно, в терминах статистических гипотез
можно утверждать, что Н0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в
этом случае гипотеза Н1. Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
Пп. 4. Критерий Колмогорова.
Данный критерий, как и критерий 2 , применяется для оценки степени согласованности
теоретического и статистического распределений. В качестве меры расхождения между теоретическим
и статистическим распределениями А.Н.Колмогоров рассматривает максимальное значение модуля
разности между статистической (эмпирической) функцией распределения Fn* ( x) и соответствующей
теоретической функцией распределения F(x): D max Fn* ( x) F ( x) .
65
Теорема Колмогорова. Какова бы ни была функция распределения F(x) непрерывной случайной
величины Х, при неограниченном возрастании числа независимых наблюдений n (то есть при n )
вероятность неравенства D n стремится к пределу P( ) 1
(1) e
k
2 k 2 2
.
k
Значения вероятности P( ) приведены в таблице.
P( )
0,1
0,2
0,3
0,4
0,5
0,6
1
1
1
1
0,997
0,964
0,864
P( )
0,7
0,8
0,9
1
1,1
1,2
1,3
0,711
0,544
0,393
0,27
0,178
0,112
0,068
1,4
1,5
1,6
1,7
1,8
1,9
2
P( )
0,04
0,022
0,012
0,006
0,003
0,002
0,001
Схема применения критерия Колмогорова следующая: строятся статистическая функция
распределения Fn* ( x) и предполагаемая теоретическая функция распределения F(x), и определяется
максимум D модуля разности между ними.
F(х)
1
F(x)
Fn*(х)
D
O
х
Далее определяется величина D n и по таблице находится вероятность P( ) — вероятность
того, что (если величина Х действительно распределена по закону F(x)) за счет чисто случайных причин
максимальное расхождение между F(x) и Fn* ( x) будет не меньше, чем фактически наблюдаемое. Если
вероятность P( ) весьма мала, гипотезу следует отвергнуть как неправдоподобную, при сравнительно
больших P( ) ее можно считать совместимой с опытными данными.
Критерий А.Н. Колмогорова своей простотой выгодно отличается от критерия 2 , поэтому его
охотно применяют на практике. Но этот критерий можно применять только в случае, когда
гипотетическое распределение F(x) полностью известно заранее из каких-нибудь теоретических
соображений, то есть когда известен не только вид функции распределения F(x), но и все входящие в
нее параметры. Такой случай редко встречается на практике. Обычно из теоретических соображений,
известен только общий вид функции F(x), а входящие в нее числовые параметры определяются по
данному статистическому материалу. При применении критерия 2 это обстоятельство учитывается
соответствующим уменьшением числа степеней свободы распределения 2 . Критерий Колмогорова
такого согласования не предусматривает. Если все же применять этот критерий в тех случаях, когда
параметры теоретического распределения выбираются по статистическим данным, критерий дает
заведомо завышенные значения вероятности P( ) , поэтому в ряде случаев рискуем принять как
правдоподобную гипотезу, в действительности плохо согласующуюся с опытными данными.
66
Проверка корректности А/Б тестов
Хабр, привет! Сегодня поговорим о том, что такое корректность статистических критериев в контексте А/Б тестирования. Узнаем, как проверить, является критерий корректным или нет. Разберём пример, в котором тест Стьюдента не работает.

Меня зовут Коля, я работаю аналитиком данных в X5 Tech. Мы с Сашей продолжаем писать серию статей по А/Б тестированию, это наша третья статья. Первые две можно посмотреть тут:
-
Стратификация. Как разбиение выборки повышает чувствительность A/Б теста
-
Бутстреп и А/Б тестирование
Корректный статистический критерий
В А/Б тестировании при проверке гипотез с помощью статистических критериев можно совершить одну из двух ошибок:
-
ошибку первого рода – отклонить нулевую гипотезу, когда на самом деле она верна. То есть сказать, что эффект есть, хотя на самом деле его нет;
-
ошибку второго рода – не отклонить нулевую гипотезу, когда на самом деле она неверна. То есть сказать, что эффекта нет, хотя на самом деле он есть.
Совсем не ошибаться нельзя. Чтобы получить на 100% достоверные результаты, нужно бесконечно много данных. На практике получить столько данных затруднительно. Если совсем не ошибаться нельзя, то хотелось бы ошибаться не слишком часто и контролировать вероятности ошибок.
В статистике ошибка первого рода считается более важной. Поэтому обычно фиксируют допустимую вероятность ошибки первого рода, а затем пытаются минимизировать вероятность ошибки второго рода.
Предположим, мы решили, что допустимые вероятности ошибок первого и второго рода равны 0.1 и 0.2 соответственно. Будем называть статистический критерий корректным, если его вероятности ошибок первого и второго рода равны допустимым вероятностям ошибок первого и второго рода соответственно.
Как сделать критерий, в котором вероятности ошибок будут равны допустимым вероятностям ошибок?
Вероятность ошибки первого рода по определению равна уровню значимости критерия. Если уровень значимости положить равным допустимой вероятности ошибки первого рода, то вероятность ошибки первого рода должна стать равной допустимой вероятности ошибки первого рода.
Вероятность ошибки второго рода можно подогнать под желаемое значение, меняя размер групп или снижая дисперсию в данных. Чем больше размер групп и чем ниже дисперсия, тем меньше вероятность ошибки второго рода. Для некоторых гипотез есть готовые формулы оценки размера групп, при которых достигаются заданные вероятности ошибок.
Например, формула оценки необходимого размера групп для гипотезы о равенстве средних:
![n > frac{left[ Phi^{-1} left( 1-alpha / 2 right) + Phi^{-1} left( 1-beta right) right]^2 (sigma_A^2 + sigma_B^2)}{varepsilon^2}](https://habrastorage.org/getpro/habr/upload_files/5d2/f18/735/5d2f18735269b594598add742c905d53.svg)
где ![]() и
и ![]() – допустимые вероятности ошибок первого и второго рода,
– допустимые вероятности ошибок первого и второго рода, ![]() – ожидаемый эффект (на сколько изменится среднее),
– ожидаемый эффект (на сколько изменится среднее), ![]() и
и ![]() – стандартные отклонения случайных величин в контрольной и экспериментальной группах.
– стандартные отклонения случайных величин в контрольной и экспериментальной группах.
Проверка корректности
Допустим, мы работаем в онлайн-магазине с доставкой. Хотим исследовать, как новый алгоритм ранжирования товаров на сайте влияет на среднюю выручку с покупателя за неделю. Продолжительность эксперимента – одна неделя. Ожидаемый эффект равен +100 рублей. Допустимая вероятность ошибки первого рода равна 0.1, второго рода – 0.2.
Оценим необходимый размер групп по формуле:
import numpy as np
from scipy import stats
alpha = 0.1 # допустимая вероятность ошибки I рода
beta = 0.2 # допустимая вероятность ошибки II рода
mu_control = 2500 # средняя выручка с пользователя в контрольной группе
effect = 100 # ожидаемый размер эффекта
mu_pilot = mu_control + effect # средняя выручка с пользователя в экспериментальной группе
std = 800 # стандартное отклонение
# исторические данные выручки для 10000 клиентов
values = np.random.normal(mu_control, std, 10000)
def estimate_sample_size(effect, std, alpha, beta):
"""Оценка необходимого размер групп."""
t_alpha = stats.norm.ppf(1 - alpha / 2, loc=0, scale=1)
t_beta = stats.norm.ppf(1 - beta, loc=0, scale=1)
var = 2 * std ** 2
sample_size = int((t_alpha + t_beta) ** 2 * var / (effect ** 2))
return sample_size
estimated_std = np.std(values)
sample_size = estimate_sample_size(effect, estimated_std, alpha, beta)
print(f'оценка необходимого размера групп = {sample_size}')оценка необходимого размера групп = 784Чтобы проверить корректность, нужно знать природу случайных величин, с которыми мы работаем. В этом нам помогут исторические данные. Представьте, что мы перенеслись в прошлое на несколько недель назад и запустили эксперимент с таким же дизайном, как мы планировали запустить его сейчас. Дизайн – это совокупность параметров эксперимента, таких как: целевая метрика, допустимые вероятности ошибок первого и второго рода, размеры групп и продолжительность эксперимента, техники снижения дисперсии и т.д.
Так как это было в прошлом, мы знаем, какие покупки совершили пользователи, можем вычислить метрики и оценить значимость отличий. Кроме того, мы знаем, что эффекта на самом деле не было, так как в то время эксперимент на самом деле не запускался. Если значимые отличия были найдены, то мы совершили ошибку первого рода. Иначе получили правильный результат.
Далее нужно повторить эту процедуру с мысленным запуском эксперимента в прошлом на разных группах и временных интервалах много раз, например, 1000.
После этого можно посчитать долю экспериментов, в которых была совершена ошибка. Это будет точечная оценка вероятности ошибки первого рода.
Оценку вероятности ошибки второго рода можно получить аналогичным способом. Единственное отличие состоит в том, что каждый раз нужно искусственно добавлять ожидаемый эффект в данные экспериментальной группы. В этих экспериментах эффект на самом деле есть, так как мы сами его добавили. Если значимых отличий не будет найдено – это ошибка второго рода. Проведя 1000 экспериментов и посчитав долю ошибок второго рода, получим точечную оценку вероятности ошибки второго рода.
Посмотрим, как оценить вероятности ошибок в коде. С помощью численных синтетических А/А и А/Б экспериментов оценим вероятности ошибок и построим доверительные интервалы:
def run_synthetic_experiments(values, sample_size, effect=0, n_iter=10000):
"""Проводим синтетические эксперименты, возвращаем список p-value."""
pvalues = []
for _ in range(n_iter):
a, b = np.random.choice(values, size=(2, sample_size,), replace=False)
b += effect
pvalue = stats.ttest_ind(a, b).pvalue
pvalues.append(pvalue)
return np.array(pvalues)
def print_estimated_errors(pvalues_aa, pvalues_ab, alpha):
"""Оценивает вероятности ошибок."""
estimated_first_type_error = np.mean(pvalues_aa < alpha)
estimated_second_type_error = np.mean(pvalues_ab >= alpha)
ci_first = estimate_ci_bernoulli(estimated_first_type_error, len(pvalues_aa))
ci_second = estimate_ci_bernoulli(estimated_second_type_error, len(pvalues_ab))
print(f'оценка вероятности ошибки I рода = {estimated_first_type_error:0.4f}')
print(f' доверительный интервал = [{ci_first[0]:0.4f}, {ci_first[1]:0.4f}]')
print(f'оценка вероятности ошибки II рода = {estimated_second_type_error:0.4f}')
print(f' доверительный интервал = [{ci_second[0]:0.4f}, {ci_second[1]:0.4f}]')
def estimate_ci_bernoulli(p, n, alpha=0.05):
"""Доверительный интервал для Бернуллиевской случайной величины."""
t = stats.norm.ppf(1 - alpha / 2, loc=0, scale=1)
std_n = np.sqrt(p * (1 - p) / n)
return p - t * std_n, p + t * std_n
pvalues_aa = run_synthetic_experiments(values, sample_size, effect=0)
pvalues_ab = run_synthetic_experiments(values, sample_size, effect=effect)
print_estimated_errors(pvalues_aa, pvalues_ab, alpha)оценка вероятности ошибки I рода = 0.0991
доверительный интервал = [0.0932, 0.1050]
оценка вероятности ошибки II рода = 0.1978
доверительный интервал = [0.1900, 0.2056]Оценки вероятностей ошибок примерно равны 0.1 и 0.2, как и должно быть. Всё верно, тест Стьюдента на этих данных работает корректно.
Распределение p-value
Выше рассмотрели случай, когда тест контролирует вероятность ошибки первого рода при фиксированном уровне значимости. Если решим изменить уровень значимости с 0.1 на 0.01, будет ли тест контролировать вероятность ошибки первого рода? Было бы хорошо, если тест контролировал вероятность ошибки первого рода при любом заданном уровне значимости. Формально это можно записать так:
Для любого ![]() выполняется
выполняется ![]() .
.
Заметим, что в левой части равенства записано выражение для функции распределения p-value. Из равенства следует, что функция распределения p-value в точке X равна X для любого X от 0 до 1. Эта функция распределения является функцией распределения равномерного распределения от 0 до 1. Мы только что показали, что статистический критерий контролирует вероятность ошибки первого рода на заданном уровне для любого уровня значимости тогда и только тогда, когда при верности нулевой гипотезы p-value распределено равномерно от 0 до 1.
При верности нулевой гипотезы p-value должно быть распределено равномерно. А как должно быть распределено p-value при верности альтернативной гипотезы? Из условия для вероятности ошибки второго рода ![]() следует, что
следует, что ![]() .
.
Получается, график функции распределения p-value при верности альтернативной гипотезы должен проходить через точку ![]() , где
, где ![]() и
и ![]() – допустимые вероятности ошибок конкретного эксперимента.
– допустимые вероятности ошибок конкретного эксперимента.
Проверим, как распределено p-value в численном эксперименте. Построим эмпирические функции распределения p-value:
import matplotlib.pyplot as plt
def plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, beta):
"""Рисует графики распределения p-value."""
estimated_first_type_error = np.mean(pvalues_aa < alpha)
estimated_second_type_error = np.mean(pvalues_ab >= alpha)
y_one = estimated_first_type_error
y_two = 1 - estimated_second_type_error
X = np.linspace(0, 1, 1000)
Y_aa = [np.mean(pvalues_aa < x) for x in X]
Y_ab = [np.mean(pvalues_ab < x) for x in X]
plt.plot(X, Y_aa, label='A/A')
plt.plot(X, Y_ab, label='A/B')
plt.plot([alpha, alpha], [0, 1], '--k', alpha=0.8)
plt.plot([0, alpha], [y_one, y_one], '--k', alpha=0.8)
plt.plot([0, alpha], [y_two, y_two], '--k', alpha=0.8)
plt.plot([0, 1], [0, 1], '--k', alpha=0.8)
plt.title('Оценка распределения p-value', size=16)
plt.xlabel('p-value', size=12)
plt.legend(fontsize=12)
plt.grid()
plt.show()
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, beta)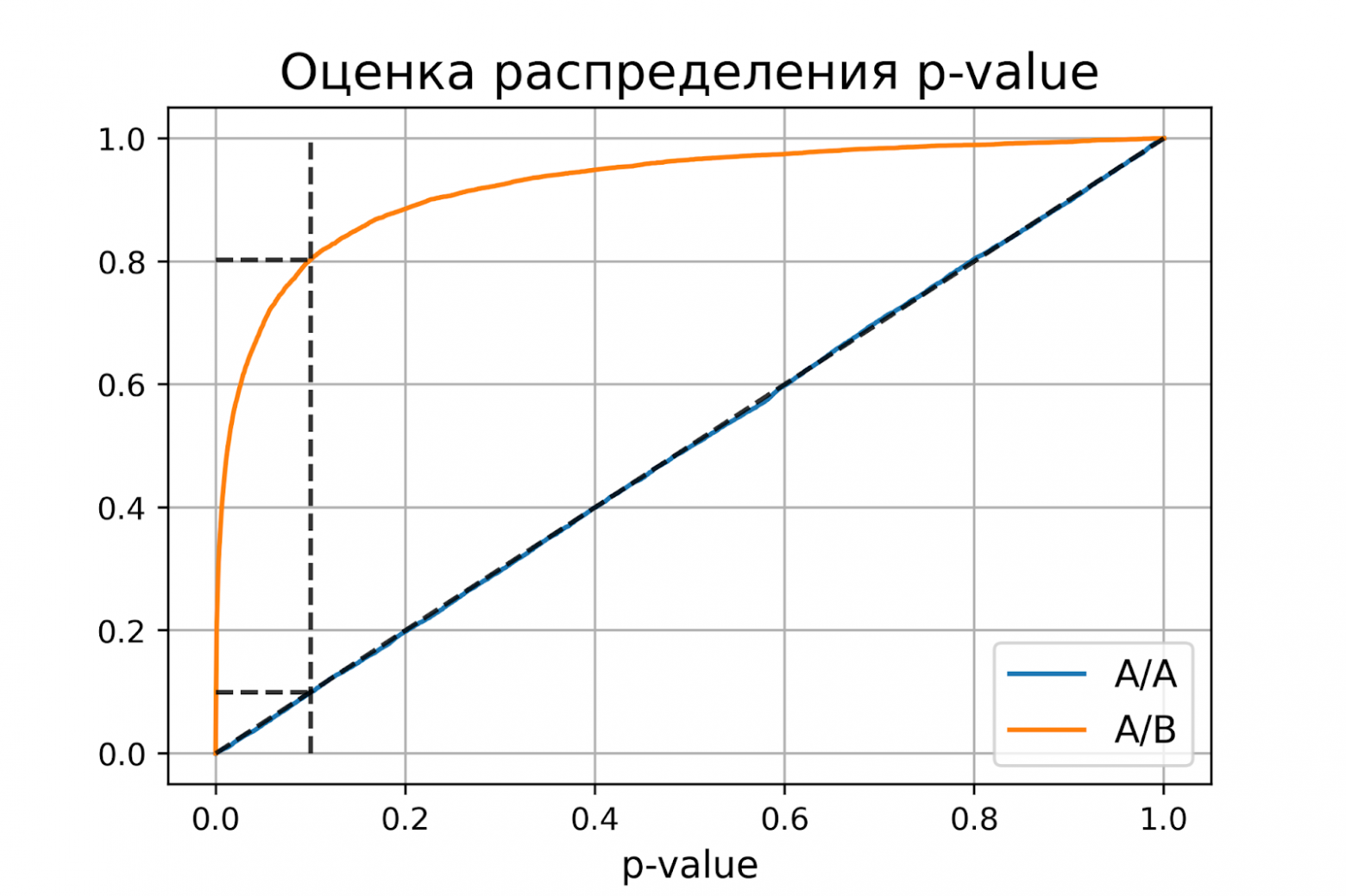
P-value для синтетических А/А тестах действительно оказалось распределено равномерно от 0 до 1, а для синтетических А/Б тестов проходит через точку ![]() .
.
Кроме оценок распределений на графике дополнительно построены четыре пунктирные линии:
-
диагональная из точки [0, 0] в точку [1, 1] – это функция распределения равномерного распределения на отрезке от 0 до 1, по ней можно визуально оценивать равномерность распределения p-value;
-
вертикальная линия с
 – пороговое значение p-value, по которому определяем отвергать нулевую гипотезу или нет. Проекция на ось ординат точки пересечения вертикальной линии с функцией распределения p-value для А/А тестов – это вероятность ошибки первого рода. Проекция точки пересечения вертикальной линии с функцией распределения p-value для А/Б тестов – это мощность теста (мощность = 1 —
– пороговое значение p-value, по которому определяем отвергать нулевую гипотезу или нет. Проекция на ось ординат точки пересечения вертикальной линии с функцией распределения p-value для А/А тестов – это вероятность ошибки первого рода. Проекция точки пересечения вертикальной линии с функцией распределения p-value для А/Б тестов – это мощность теста (мощность = 1 —  ).
). -
две горизонтальные линии – проекции на ось ординат точки пересечения вертикальной линии с функцией распределения p-value для А/А и А/Б тестов.
График с оценками распределения p-value для синтетических А/А и А/Б тестов позволяет проверить корректность теста для любого значения уровня значимости.
Некорректный критерий
Выше рассмотрели пример, когда тест Стьюдента оказался корректным критерием для случайных данных из нормального распределения. Может быть, все критерии всегда работаю корректно, и нет смысла каждый раз проверять вероятности ошибок?
Покажем, что это не так. Немного изменим рассмотренный ранее пример, чтобы продемонстрировать некорректную работу критерия. Допустим, мы решили увеличить продолжительность эксперимента до 2-х недель. Для каждого пользователя будем вычислять стоимость покупок за первую неделю и стоимость покупок за второю неделю. Полученные стоимости будем передавать в тест Стьюдента для проверки значимости отличий. Положим, что поведение пользователей повторяется от недели к неделе, и стоимости покупок одного пользователя совпадают.
def run_synthetic_experiments_two(values, sample_size, effect=0, n_iter=10000):
"""Проводим синтетические эксперименты на двух неделях."""
pvalues = []
for _ in range(n_iter):
a, b = np.random.choice(values, size=(2, sample_size,), replace=False)
b += effect
# дублируем данные
a = np.hstack((a, a,))
b = np.hstack((b, b,))
pvalue = stats.ttest_ind(a, b).pvalue
pvalues.append(pvalue)
return np.array(pvalues)
pvalues_aa = run_synthetic_experiments_two(values, sample_size)
pvalues_ab = run_synthetic_experiments_two(values, sample_size, effect=effect)
print_estimated_errors(pvalues_aa, pvalues_ab, alpha)
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, beta)оценка вероятности ошибки I рода = 0.2451
доверительный интервал = [0.2367, 0.2535]
оценка вероятности ошибки II рода = 0.0894
доверительный интервал = [0.0838, 0.0950]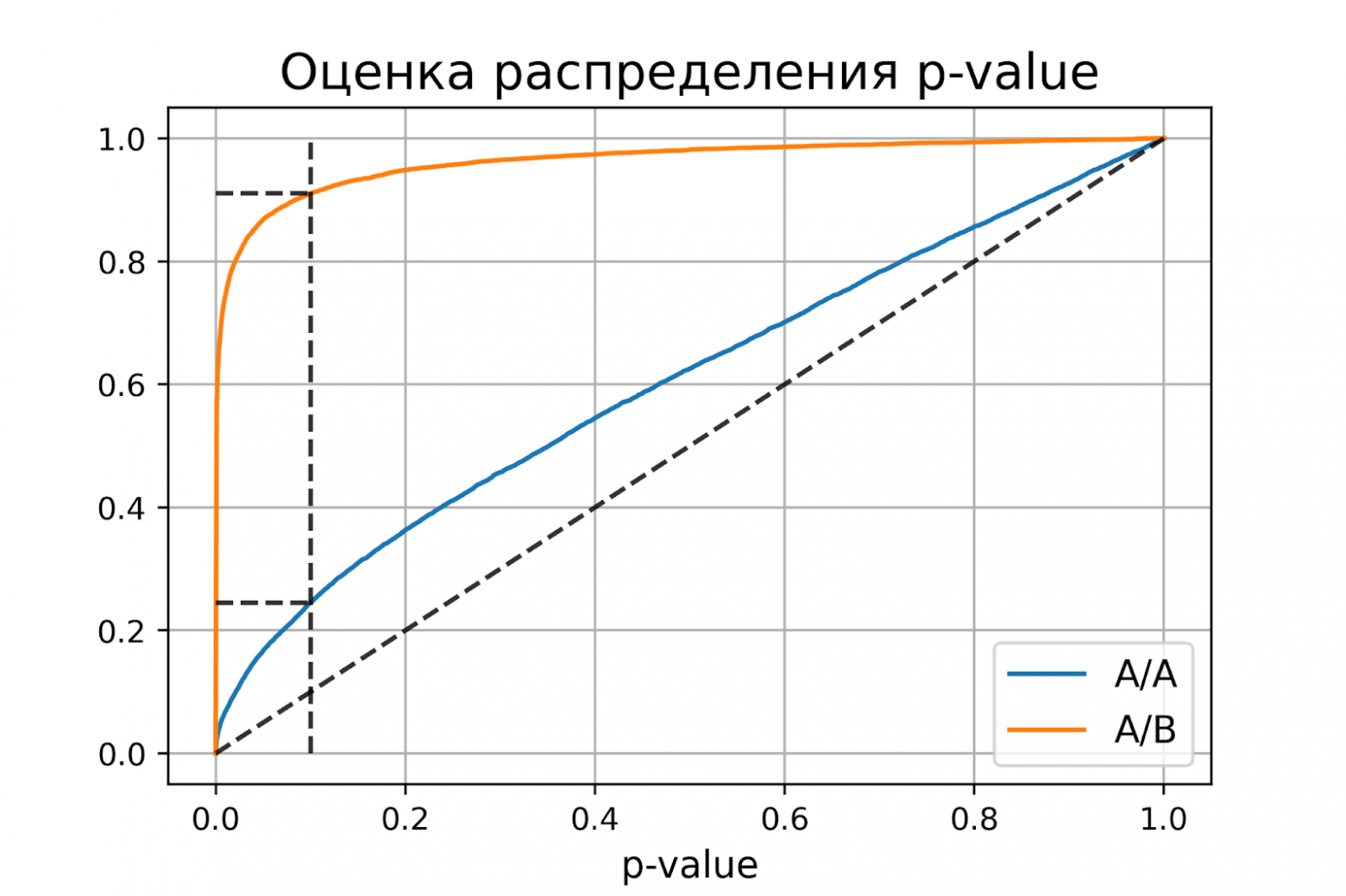
Получили оценку вероятности ошибки первого рода около 0.25, что сильно больше уровня значимости 0.1. На графике видно, что распределение p-value для синтетических А/А тестов не равномерно, оно отклоняется от диагонали. В этом примере тест Стьюдента работает некорректно, так как данные зависимые (стоимости покупок одного человека зависимы). Если бы мы сразу не догадались про зависимость данных, то оценка вероятностей ошибок помогла бы нам понять, что такой тест некорректен.
Итоги
Мы обсудили, что такое корректность статистического теста, посмотрели, как оценить вероятности ошибок на исторических данных и привели пример некорректной работы критерия.
Таким образом:
-
корректный критерий – это критерий, у которого вероятности ошибок первого и второго рода равны допустимым вероятностям ошибок первого и второго рода соответственно;
-
чтобы критерий контролировал вероятность ошибки первого рода для любого уровня значимости, необходимо и достаточно, чтобы p-value при верности нулевой гипотезы было распределено равномерно от 0 до 1.
Ошибки первого и второго рода
Выдвинутая гипотеза
может быть правильной или неправильной,
поэтому возникает необходимость её
проверки. Поскольку проверку производят
статистическими методами, её называют
статистической. В итоге статистической
проверки гипотезы в двух случаях может
быть принято неправильное решение, т.
е. могут быть допущены ошибки двух родов.
Ошибка первого
рода состоит в том, что будет отвергнута
правильная гипотеза.
Ошибка второго
рода состоит в том, что будет принята
неправильная гипотеза.
Подчеркнём, что
последствия этих ошибок могут оказаться
весьма различными. Например, если
отвергнуто правильное решение «продолжать
строительство жилого дома», то эта
ошибка первого рода повлечёт материальный
ущерб: если же принято неправильное
решение «продолжать строительство»,
несмотря на опасность обвала стройки,
то эта ошибка второго рода может повлечь
гибель людей. Можно привести примеры,
когда ошибка первого рода влечёт более
тяжёлые последствия, чем ошибка второго
рода.
Замечание 1.
Правильное решение может быть принято
также в двух случаях:
-
гипотеза принимается,
причём и в действительности она
правильная; -
гипотеза отвергается,
причём и в действительности она неверна.
Замечание 2.
Вероятность совершить ошибку первого
рода принято обозначать через
![]() ;
;
её называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0,05 или 0,01. Если, например, принят
уровень значимости, равный 0,05, то это
означает, что в пяти случаях из ста
имеется риск допустить ошибку первого
рода (отвергнуть правильную гипотезу).
Статистический
критерий проверки нулевой гипотезы.
Наблюдаемое значение критерия
Для проверки
нулевой гипотезы используют специально
подобранную случайную величину, точное
или приближённое распределение которой
известно. Обозначим эту величину в целях
общности через
![]() .
.
Статистическим
критерием
(или просто критерием) называют случайную
величину
![]() ,
,
которая служит для проверки нулевой
гипотезы.
Например, если
проверяют гипотезу о равенстве дисперсий
двух нормальных генеральных совокупностей,
то в качестве критерия
![]() принимают отношение исправленных
принимают отношение исправленных
выборочных дисперсий: .
.
Эта величина
случайная, потому что в различных опытах
дисперсии принимают различные, наперёд
неизвестные значения, и распределена
по закону Фишера – Снедекора.
Для проверки
гипотезы по данным выборок вычисляют
частные значения входящих в критерий
величин и таким образом получают частное
(наблюдаемое) значение критерия.
Наблюдаемым
значением
![]() называют значение критерия, вычисленное
называют значение критерия, вычисленное
по выборкам. Например, если по двум
выборкам найдены исправленные выборочные
дисперсии![]() и
и![]() ,
,
то наблюдаемое значение критерия .
.
Критическая
область. Область принятия гипотезы.
Критические точки
После выбора
определённого критерия множество всех
его возможных значений разбивают на
два непересекающихся подмножества:
одно из них содержит значения критерия,
при которых нулевая гипотеза отвергается,
а другая – при которых она принимается.
Критической
областью называют совокупность значений
критерия, при которых нулевую гипотезу
отвергают.
Областью принятия
гипотезы (областью допустимых значений)
называют совокупность значений критерия,
при которых гипотезу принимают.
Основной принцип
проверки статистических гипотез можно
сформулировать так: если наблюдаемое
значение критерия принадлежит критической
области – гипотезу отвергают, если
наблюдаемое значение критерия принадлежит
области принятия гипотезы – гипотезу
принимают.
Поскольку критерий
![]() — одномерная случайная величина, все её
— одномерная случайная величина, все её
возможные значения принадлежат некоторому
интервалу. Поэтому критическая область
и область принятия гипотезы также
являются интервалами и, следовательно,
существуют точки, которые их разделяют.
Критическими
точками (границами)
![]() называют точки, отделяющие критическую
называют точки, отделяющие критическую
область от области принятия гипотезы.
Различают
одностороннюю (правостороннюю или
левостороннюю) и двустороннюю критические
области.
Правосторонней
называют критическую область, определяемую
неравенством
![]() >
>![]() ,
,
где![]() — положительное число.
— положительное число.
Левосторонней
называют критическую область, определяемую
неравенством
![]() <
<![]() ,
,
где![]() — отрицательное число.
— отрицательное число.
Односторонней
называют правостороннюю или левостороннюю
критическую область.
Двусторонней
называют критическую область, определяемую
неравенствами
![]() где
где![]() .
.
В частности, если
критические точки симметричны относительно
нуля, двусторонняя критическая область
определяется неравенствами ( в
предположении, что
![]() >0):
>0):
![]() ,
,
или равносильным неравенством
![]() .
.
Отыскание
правосторонней критической области
Как найти критическую
область? Обоснованный ответ на этот
вопрос требует привлечения довольно
сложной теории. Ограничимся её элементами.
Для определённости начнём с нахождения
правосторонней критической области,
которая определяется неравенством
![]() >
>![]() ,
,
где![]() >0.
>0.
Видим, что для отыскания правосторонней
критической области достаточно найти
критическую точку. Следовательно,
возникает новый вопрос: как её найти?
Для её нахождения
задаются достаточной малой вероятностью
– уровнем значимости
![]() .
.
Затем ищут критическую точку![]() ,
,
исходя из требования, чтобы при условии
справедливости нулевой гипотезы
вероятность того, критерий![]() примет значение, большее
примет значение, большее![]() ,
,
была равна принятому уровню значимости:
Р(![]() >
>![]() )=
)=![]() .
.
Для каждого критерия
имеются соответствующие таблицы, по
которым и находят критическую точку,
удовлетворяющую этому требованию.
Замечание 1.
Когда
критическая точка уже найдена, вычисляют
по данным выборок наблюдаемое значение
критерия и, если окажется, что
![]() >
>![]() ,
,
то нулевую гипотезу отвергают; если же![]() <
<![]() ,
,
то нет оснований, чтобы отвергнуть
нулевую гипотезу.
Пояснение. Почему
правосторонняя критическая область
была определена, исходя из требования,
чтобы при справедливости нулевой
гипотезы выполнялось соотношение
Р(![]() >
>![]() )=
)=![]() ?
?
(*)
Поскольку вероятность
события
![]() >
>![]() мала (
мала (![]() — малая вероятность), такое событие при
— малая вероятность), такое событие при
справедливости нулевой гипотезы, в силу
принципа практической невозможности
маловероятных событий, в единичном
испытании не должно наступить. Если всё
же оно произошло, т.е. наблюдаемое
значение критерия оказалось больше![]() ,
,
то это можно объяснить тем, что нулевая
гипотеза ложна и, следовательно, должна
быть отвергнута. Таким образом, требование
(*) определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
Замечание 2.
Наблюдаемое значение критерия может
оказаться большим
![]() не потому, что нулевая гипотеза ложна,
не потому, что нулевая гипотеза ложна,
а по другим причинам (малый объём выборки,
недостатки методики эксперимента и
др.). В этом случае, отвергнув правильную
нулевую гипотезу, совершают ошибку
первого рода. Вероятность этой ошибки
равна уровню значимости![]() .
.
Итак, пользуясь требованием (*), мы с
вероятностью![]() рискуем совершить ошибку первого рода.
рискуем совершить ошибку первого рода.
Замечание 3. Пусть
нулевая гипотеза принята; ошибочно
думать, что тем самым она доказана.
Действительно, известно, что один пример,
подтверждающий справедливость некоторого
общего утверждения, ещё не доказывает
его. Поэтому более правильно говорить,
«данные наблюдений согласуются с нулевой
гипотезой и, следовательно, не дают
оснований её отвергнуть».
На практике для
большей уверенности принятия гипотезы
её проверяют другими способами или
повторяют эксперимент, увеличив объём
выборки.
Отвергают гипотезу
более категорично, чем принимают.
Действительно, известно, что достаточно
привести один пример, противоречащий
некоторому общему утверждению, чтобы
это утверждение отвергнуть. Если
оказалось, что наблюдаемое значение
критерия принадлежит критической
области, то этот факт и служит примером,
противоречащим нулевой гипотезе, что
позволяет её отклонить.
Отыскание
левосторонней и двусторонней критических
областей***
Отыскание
левосторонней и двусторонней критических
областей сводится (так же, как и для
правосторонней) к нахождению соответствующих
критических точек. Левосторонняя
критическая область определяется
неравенством
![]() <
<![]() (
(![]() <0).
<0).
Критическую точку находят, исходя из
требования, чтобы при справедливости
нулевой гипотезы вероятность того, что
критерий примет значение, меньшее![]() ,
,
была равна принятому уровню значимости:
Р(![]() <
<![]() )=
)=![]() .
.
Двусторонняя
критическая область определяется
неравенствами
![]() Критические
Критические
точки находят, исходя из требования,
чтобы при справедливости нулевой
гипотезы сумма вероятностей того, что
критерий примет значение, меньшее![]() или большее
или большее![]() ,
,
была равна принятому уровню значимости:
![]() .
.
(*)
Ясно, что критические
точки могут быть выбраны бесчисленным
множеством способов. Если же распределение
критерия симметрично относительно нуля
и имеются основания (например, для
увеличения мощности) выбрать симметричные
относительно нуля точки (-
![]() )и
)и![]() (
(![]() >0),
>0),
то
![]() Учитывая (*), получим
Учитывая (*), получим
![]() .
.
Это соотношение
и служит для отыскания критических
точек двусторонней критической области.
Критические точки находят по соответствующим
таблицам.
Дополнительные
сведения о выборе критической области.
Мощность критерия
Мы строили
критическую область, исходя из требования,
чтобы вероятность попадания в неё
критерия была равна
![]() при условии, что нулевая гипотеза
при условии, что нулевая гипотеза
справедлива. Оказывается целесообразным
ввести в рассмотрение вероятность
попадания критерия в критическую область
при условии, что нулевая гипотеза неверна
и, следовательно, справедлива конкурирующая.
Мощностью критерия
называют вероятность попадания критерия
в критическую область при условии, что
справедлива конкурирующая гипотеза.
Другими словами, мощность критерия есть
вероятность того, что нулевая гипотеза
будет отвергнута, если верна конкурирующая
гипотеза.
Пусть для проверки
гипотезы принят определённый уровень
значимости и выборка имеет фиксированный
объём. Остаётся произвол в выборе
критической области. Покажем, что её
целесообразно построить так, чтобы
мощность критерия была максимальной.
Предварительно убедимся, что если
вероятность ошибки второго рода (принять
неправильную гипотезу) равна
![]() ,
,
то мощность равна 1-![]() .
.
Действительно, если![]() — вероятность ошибки второго рода, т.е.
— вероятность ошибки второго рода, т.е.
события «принята нулевая гипотеза,
причём справедливо конкурирующая», то
мощность критерия равна 1 —![]() .
.
Пусть мощность 1
—
![]() возрастает; следовательно, уменьшается
возрастает; следовательно, уменьшается
вероятность![]() совершить ошибку второго рода. Таким
совершить ошибку второго рода. Таким
образом, чем мощность больше, тем
вероятность ошибки второго рода меньше.
Итак, если уровень
значимости уже выбран, то критическую
область следует строить так, чтобы
мощность критерия была максимальной.
Выполнение этого требования должно
обеспечить минимальную ошибку второго
рода, что, конечно, желательно.
Замечание 1.
Поскольку вероятность события «ошибка
второго рода допущена» равна
![]() ,
,
то вероятность противоположного события
«ошибка второго рода не допущена» равна
1 —![]() ,
,
т.е. мощности критерия. Отсюда следует,
что мощность критерия есть вероятность
того, что не будет допущена ошибка
второго рода.
Замечание 2. Ясно,
что чем меньше вероятности ошибок
первого и второго рода, тем критическая
область «лучше». Однако при заданном
объёме выборки уменьшить одновременно
![]() и
и![]() невозможно; если уменьшить
невозможно; если уменьшить![]() ,
,
то![]() будет возрастать. Например, если принять
будет возрастать. Например, если принять![]() =0,
=0,
то будут приниматься все гипотезы, в
том числе и неправильные, т.е. возрастает
вероятность![]() ошибки второго рода.
ошибки второго рода.
Как же выбрать
![]() наиболее целесообразно? Ответ на этот
наиболее целесообразно? Ответ на этот
вопрос зависит от «тяжести последствий»
ошибок для каждой конкретной задачи.
Например, если ошибка первого рода
повлечёт большие потери, а второго рода
– малые, то следует принять возможно
меньшее![]() .
.
Если
![]() уже выбрано, то, пользуясь теоремой Ю.
уже выбрано, то, пользуясь теоремой Ю.
Неймана и Э.Пирсона, можно построить
критическую область, для которой![]() будет минимальным и, следовательно,
будет минимальным и, следовательно,
мощность критерия максимальной.
Замечание 3.
Единственный способ одновременного
уменьшения вероятностей ошибок первого
и второго рода состоит в увеличении
объёма выборок.
Соседние файлы в папке Лекции 2 семестр
- #
- #
- #
- #
Ошибки I и II рода при проверке гипотез, мощность
Общий обзор
Принятие неправильного решения
Мощность и связанные факторы
Проверка множественных гипотез
Общий обзор
Большинство проверяемых гипотез сравнивают между собой группы объектов, которые испытывают влияние различных факторов.
Например, можно сравнить эффективность двух видов лечения, чтобы сократить 5-летнюю смертность от рака молочной железы. Для данного исхода (например, смерть) сравнение, представляющее интерес (например, различные показатели смертности через 5 лет), называют эффектом или, если уместно, эффектом лечения.
Нулевую гипотезу выражают как отсутствие эффекта (например 5-летняя смертность от рака молочной железы одинаковая в двух группах, получающих разное лечение); двусторонняя альтернативная гипотеза будет означать, что различие эффектов не равно нулю.
Критериальная проверка гипотезы дает возможность определить, достаточно ли аргументов, чтобы отвергнуть нулевую гипотезу. Можно принять только одно из двух решений:
- отвергнуть нулевую гипотезу и принять альтернативную гипотезу
- остаться в рамках нулевой гипотезы
Важно: В литературе достаточно часто встречается понятие «принять нулевую гипотезу». Хотелось бы внести ясность, что со статистической точки зрения принять нулевую гипотезу невозможно, т.к. нулевая гипотеза представляет собой достаточно строгое утверждение (например, средние значения в сравниваемых группах равны ![]() ).
).
Поэтому фразу о принятии нулевой гипотезы следует понимать как то, что мы просто остаемся в рамках гипотезы.
Принятие неправильного решения
Возможно неправильное решение, когда отвергают/не отвергают нулевую гипотезу, потому что есть только выборочная информация.
| Верная гипотеза | |||
|---|---|---|---|
| H0 | H1 | ||
| Результат
применения критерия |
H0 | H0 верно принята | H0 неверно принята
(Ошибка второго рода) |
| H1 | H0 неверно отвергнута
(Ошибка первого рода) |
H0 верно отвергнута |
Ошибка 1-го рода: нулевую гипотезу отвергают, когда она истинна, и делают вывод, что имеется эффект, когда в действительности его нет. Максимальный шанс (вероятность) допустить ошибку 1-го рода обозначается α (альфа). Это уровень значимости критерия; нулевую гипотезу отвергают, если наше значение p ниже уровня значимости, т. е., если p < α.
Следует принять решение относительно значения а прежде, чем будут собраны данные; обычно назначают условное значение 0,05, хотя можно выбрать более ограничивающее значение, например 0,01.
Шанс допустить ошибку 1-го рода никогда не превысит выбранного уровня значимости, скажем α = 0,05, так как нулевую гипотезу отвергают только тогда, когда p< 0,05. Если обнаружено, что p > 0,05, то нулевую гипотезу не отвергнут и, следовательно, не допустят ошибки 1-го рода.
Ошибка 2-го рода: не отвергают нулевую гипотезу, когда она ложна, и делают вывод, что нет эффекта, тогда как в действительности он существует. Шанс возникновения ошибки 2-го рода обозначается β (бета); а величина (1-β) называется мощностью критерия.
Следовательно, мощность — это вероятность отклонения нулевой гипотезы, когда она ложна, т.е. это шанс (обычно выраженный в процентах) обнаружить реальный эффект лечения в выборке данного объема как статистически значимый.
В идеале хотелось бы, чтобы мощность критерия составляла 100%; однако это невозможно, так как всегда остается шанс, хотя и незначительный, допустить ошибку 2-го рода.
К счастью, известно, какие факторы влияют на мощность и, таким образом, можно контролировать мощность критерия, рассматривая их.
Мощность и связанные факторы
Планируя исследование, необходимо знать мощность предложенного критерия. Очевидно, можно начинать исследование, если есть «хороший» шанс обнаружить уместный эффект, если таковой существует (под «хорошим» мы подразумеваем, что мощность должна быть по крайней мере 70-80%).
Этически безответственно начинать исследование, у которого, скажем, только 40% вероятности обнаружить реальный эффект лечения; это бесполезная трата времени и денежных средств.
Ряд факторов имеют прямое отношение к мощности критерия.
Объем выборки: мощность критерия увеличивается по мере увеличения объема выборки. Это означает, что у большей выборки больше возможностей, чем у незначительной, обнаружить важный эффект, если он существует.
Когда объем выборки небольшой, у критерия может быть недостаточно мощности, чтобы обнаружить отдельный эффект. Эти методы также можно использовать для оценки мощности критерия для точно установленного объема выборки.
Вариабельность наблюдений: мощность увеличивается по мере того, как вариабельность наблюдений уменьшается.
Интересующий исследователя эффект: мощность критерия больше для более высоких эффектов. Критерий проверки гипотез имеет больше шансов обнаружить значительный реальный эффект, чем незначительный.
Уровень значимости: мощность будет больше, если уровень значимости выше (это эквивалентно увеличению допущения ошибки 1-го рода, α, а допущение ошибки 2-го рода, β, уменьшается).
Таким образом, вероятнее всего, исследователь обнаружит реальный эффект, если на стадии планирования решит, что будет рассматривать значение р как значимое, если оно скорее будет меньше 0,05, чем меньше 0,01.
Обратите внимание, что проверка ДИ для интересующего эффекта указывает на то, была ли мощность адекватной. Большой доверительный интервал следует из небольшой выборки и/или набора данных с существенной вариабельностью и указывает на недостаточную мощность.
Проверка множественных гипотез
Часто нужно выполнить критериальную проверку значимости множественных гипотез на наборе данных с многими переменными или существует более двух видов лечения.
Ошибка 1-го рода драматически увеличивается по мере увеличения числа сравнений, что приводит к ложным выводам относительно гипотез. Следовательно, следует проверить только небольшое число гипотез, выбранных для достижения первоначальной цели исследования и точно установленных априорно.
Можно использовать какую-нибудь форму апостериорного уточнения значения р, принимая во внимание число выполненных проверок гипотез.
Например, при подходе Бонферрони (его часто считают довольно консервативным) умножают каждое значение р на число выполненных проверок; тогда любые решения относительно значимости будут основываться на этом уточненном значении р.
Связанные определения:
p-уровень
Альтернативная гипотеза, альтернатива
Альфа-уровень
Бета-уровень
Гипотеза
Двусторонний критерий
Критерий для проверки гипотезы
Критическая область проверки гипотезы
Мощность
Мощность исследования
Мощность статистического критерия
Нулевая гипотеза
Односторонний критерий
Ошибка I рода
Ошибка II рода
Статистика критерия
Эквивалентные статистические критерии
В начало
Содержание портала
5.6. Вероятность ошибки р
Если следовать подразделению статистики на описательную и аналитическую, то задача аналитической статистики — предоставить методы, с помощью которых можно было бы объективно выяснить,
например, является ли наблюдаемая разница в средних значениях или взаимосвязь (корреляция) выборок случайной или нет.
Например, если сравниваются два средних значения выборок, то можно сформулировать две предварительных гипотезы:
-
Гипотеза 0 (нулевая): Наблюдаемые различия между средними значениями выборок находятся в пределах случайных отклонений.
-
Гипотеза 1 (альтернативная): Наблюдаемые различия между средними значениями нельзя объяснить случайными отклонениями.
В аналитической статистике разработаны методы вычисления так называемых тестовых (контрольных) величин, которые рассчитываются по определенным формулам на основе данных,
содержащихся в выборках или полученных из них характеристик. Эти тестовые величины соответствуют определенным теоретическим распределениям
(t-pacnpeлелению, F-распределению, распределению X2 и т.д.), которые позволяют вычислить так называемую вероятность ошибки. Это вероятность равна проценту ошибки,
которую можно допустить отвергнув нулевую гипотезу и приняв альтернативную.
Вероятность определяется в математике, как величина, находящаяся в диапазоне от 0 до 1. В практической статистике она также часто выражаются в процентах. Обычно вероятность обозначаются буквой р:
0 < р < 1
Вероятности ошибки, при которой допустимо отвергнуть нулевую гипотезу и принять альтернативную гипотезу, зависит от каждого конкретного случая.
В значительной степени эта вероятность определяется характером исследуемой ситуации. Чем больше требуемая вероятность, с которой надо избежать ошибочного решения,
тем более узкими выбираются границы вероятности ошибки, при которой отвергается нулевая гипотеза, так называемый доверительный интервал вероятности.
Обычно в исследованиях используют 5% вероятность ошибки.
Существует общепринятая терминология, которая относится к доверительным интервалам вероятности:
- Высказывания, имеющие вероятность ошибки р <= 0,05 — называются значимыми.
- Высказывания с вероятностью ошибки р <= 0,01 — очень значимыми,
- А высказывания с вероятностью ошибки р <= 0,001 — максимально значимыми.
В литературе такие ситуации иногда обозначают одной, двумя или тремя звездочками.
| Вероятность ошибки | Значимость | Обозначение |
| р > 0.05 | Не значимая | ns |
| р <= 0.05 | Значимая | * |
| р <= 0.01 | Очень значимая | ** |
| р <= 0.001 | Максимально значимая | *** |
В SPSS вероятность ошибки р имеет различные обозначения; звездочки для указания степени значимости применяются лишь в немногих случаях. Обычно в SPSS значение р обозначается Sig. (Significant).
Времена, когда не было компьютеров, пригодных для статистического анализа, давали практикам по крайней мере одно преимущество. Так как все вычисления надо было выполнять вручную,
статистик должен был сначала тщательно обдумать, какие вопросы можно решить с помощью того или иного теста. Кроме того, особое значение придавалось точной формулировке нулевой гипотезы.
Но с помощью компьютера и такой мощной программы, как SPSS, очень легко можно провести множество тестов за очень короткое время. К примеру, если в таблицу сопряженности свести 50 переменных
с другими 20 переменными и выполнить тест X2, то получится 1000 результатов проверки значимости или 1000 значений р. Некритический подбор значимых величин может
дать бессмысленный результат, так как уже при граничном уровне значимости р = 0,05 в пяти процентах наблюдений, то есть в 50 возможных наблюдениях, можно ожидать значимые результаты.
Этим ошибкам первого рода (когда нулевая гипотеза отвергается, хотя она верна) следует уделять достаточно внимания. Ошибкой второго рода называется ситуация,
когда нулевая гипотеза принимается, хотя она ложна. Вероятность допустить ошибку первого рода равна вероятности ошибки р. Вероятность ошибки второго рода тем меньше, чем больше вероятность ошибки р.
Определим выражение для вычисления ошибки второго рода и мощности теста, построим в
MS
EXCEL
кривые оперативной характеристики (Operating-characteristic curves).
Тема этой статьи – вычисление
ошибки второго рода
(type II error) при
проверке гипотез
. Основная статья про
проверку гипотез
находится здесь
.
Напомним, что процедура
проверки гипотез
состоит из следующих шагов:
- из исследуемого распределения берется
выборка
; - на основании значений
выборки
вычисляется
тестовая статистика
; - значение
тестовой статистики
сравнивается со значениями, соответствующим заданномууровню значимости (ошибке первого рода)
;
- по результату сравнения делается вывод об отклонении (или не отклонении)
нулевой гипотезы
.
Обычно с
проверкой гипотез
связывают 2 типа ошибок. Если
нулевая гипотеза
отклоняется, когда она верна – это
ошибка первого рода
(обозначается α,
альфа
). Если нулевая гипотеза не отклоняется, когда она неверна, то это
ошибка второго рода
(обозначается β,
бета
).
Ошибка первого рода
часто называется риском производителя. Это осознанный риск, на который идет производитель продукции, т.к. он определяет вероятность того, что годная продукция может быть забракована, хотя на самом деле она таковой не является. Величина
ошибки первого рода
задается перед
проверкой гипотезы
, таким образом, она контролируется исследователем напрямую и может быть задана в соответствии с условиями решаемой задачи. После этого, процедура проверки гипотезы составляется таким образом, чтобы вероятность
ошибки второго рода
была как можно меньше.
Ошибка второго рода
β
зависит от размера
выборки
n и
уровня значимости α
, и поэтому контролируется косвенно. Чем больше размер
выборки
, тем меньше
ошибка второго рода
(при прочих равных).
Часто также используют величину
1-β
, которая называется
мощностью статистического критерия
(мощностью теста, мощностью исследования, англ. power of a statistical test).
Мощность статистического критерия
— это вероятность правильно отклонить нулевую гипотезу. Чем ближе эта величина к единице, тем меньше у нас шансов ошибиться при проверке гипотезы (тем лучше критерий различает гипотезы Н
0
и Н
1
).
Ошибку второго рода
вычисляют для каждого вида
проверки гипотез
по-разному. Получим выражение для вычисления
ошибки второго рода
для
проверки двусторонней гипотезы о равенстве среднего значения распределения некоторой величине (стандартное отклонение известно)
.
Для
проверки гипотезы
этого типа используется
тестовая статистика
Z
0
:
![]()
которая имеет
стандартное нормальное распределение
.
Чтобы найти
Ошибку второго рода
необходимо предположить, что гипотеза Н
0
: μ=μ
0
не верна, и соответственно истинное
среднее значение распределения
μ=μ
0
+Δ, где Δ>0. В этом случае,
тестовая статистика
Z
0
будет иметь
нормальное распределение
N(Δ√n/σ;1), т.е. будет смещено вправо на Δ√n/σ (см.
файл примера на листе Бета
).
Согласно определения,
ошибка второго рода
равна вероятности, принять нулевую гипотезу, если на самом деле справедлива Н
1
. Эта вероятность соответствует выделенной на рисунке области.
Статистика
Z
0
, в этом случае, примет значение между -Z
α/2
и Z
α/2
(эти значения соответствуют границам
доверительного интервала
). Z
α/2
– это
верхний α/2-квантиль стандартного нормального распределения
.
Определим
ошибку второго рода
в терминах
стандартного нормального распределения
:
![]()
Это выражение будет работать и для Δ<0. Как видно из выражения,
ошибка второго рода
является функцией от α, Δ и n. В
файле примера на листе Бета
можно быстро рассчитать β и
мощность теста
в зависимости от этих параметров. Диаграмма, приведенная выше, будет автоматически перестроена.
Для заданного значения α часто строят семейство кривых, которые иллюстрируют зависимость
ошибки второго рода
от Δ и n. Такие кривые называются
операционными характеристиками
(Operating-characteristic curves).
Как видно из рисунка, чем дальше истинное значение
среднего
от μ
0
, т.е. чем больше Δ, тем меньше
ошибка второго рода.
Таким образом, для заданных α и n, тест легче определит большие отклонения от
среднего
, чем малые (тест обладает, в данном случае, большей
мощностью
). При росте n
мощность теста
также растет.
Кривые
операционных характеристик
используются для оценки размера
выборки
, достаточного для определения заданной разницы между истинным значением
среднего
μ
от μ
0
с требуемой вероятностью.
В
файле примера на листе ОХ
создана форма для определения размера
выборки
, достаточного для обеспечения заданной
мощности теста
.
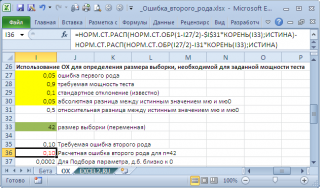
Например, Н
0
: μ
0
=20, истинное значение μ=20,05,
стандартное отклонение
=0,1, α=0,05. Чтобы вероятность правильно отклонить гипотезу H
0
была равна 0,9 (
мощность теста
), размер
выборки
должен быть 42 или более.
Примечание
:
Для нахождения размера
выборки
потребуется использование инструмента MS EXCEL
Подбор параметра
.
![]()
|
Балаховский Введение в статконтроль. |
11 |
Если какое-то измерение повторить несколько раз, получается серия результатов измерений или другими словами серия экземпляров случайной величины. Среднее бесконечного числа повторных измерений (что, конечно же, невозможно!), называется математическим ожиданием, это и есть истинное значение измеряемой величины. Чем больше измерений в серии, тем ближе ее среднее к математическому ожиданию – идеалу, к которому можно стремиться, но который нельзя достичь! Обычно математическое ожидание обозначают буквой М, результаты отдельных измерений Х1, Х2,…,Xn , а среднее серии, ко-
торое также называется выборочной оценкой среднего или просто оценкой – Х . Разброс экземпляров случайной величины (например, результатов повторных анали-
зов) характеризуется дисперсией – средним квадратом отклонения, которая обозначается σ2. На практике в ряде случаев удобнее пользоваться средним квадратичным, которое равно квадратному корню из дисперсии и обозначается σ. Дисперсия это средний квадрат всех возможных экземпляров случайной величины – т.е. в нашем случае бесконечного числа повторных анализов, такая же абстракция, как и математическое ожидание. На практике оно тоже оценивается по среднему квадратичному отклонению выборки и обозначается S. Таким образом, мы всегда имеем дело как с идеальными значениями параметров распределения M и σ, так и с их, полученными в эксперименте, выборочными
оценками Х и S.
Вероятность – это абстрактное понятие, которое касается возможности появления какого-либо события (например, того, что ошибка больше некоторой величины), обычно она заранее неизвестна. Ее можно оценить только, когда накоплен определенный опыт и частота появления события известна. Это называется оценкой вероятности по частоте.
Вероятность события недоступна непосредственному наблюдению, мы видим только его частоту. Например, если в крови пациента 25% всех лейкоцитов это лимфоциты, то вероятность P при подсчете лейкоцитарной формулы встретить лимфоцит составляет 0,25. Однако, при просмотре 100 клеток мы не обязательно встретим точно P*=25 лимфоцитов, их может быть и P*=24 и P*=26 и даже P*=30, не зависимо от опыта или прилежания работника, а только от случая. Как же узнать, сколько их могло бы быть, если бы можно было просмотреть все клетки? Прямо на этот вопрос ответить нельзя, зная частоту можно только указать диапазон в котором с заданной вероятностью находится ответ.
Каждая клетка либо лимфоцит, либо не лимфоцит, подобно тому, как брошенная монета падает либо орлом, либо решеткой. Такое распределение называется биноминальным. Среднее квадратичное отклонение вычисляется по формуле:
Здесь P – вероятность того, что в поле зрения именно клетка данного вида (т.е. истинная их доля), 1-P -вероятность что это другая клетка, n – число посчитанных клеток. Зная эти параметры, можно оценить каких результатов следует ожидать при подсчете формулы. На практике обычно приходится решать обратную задачу – при просмотре мазка получились такие-то результаты (известна частота события), что можно сказать о вероятности? Более подробные расчеты показывают, что если событий больше 10% и меньше 90%, границы доверительного интервала математического ожидания (т.е. истинного значения) достаточно точно можно найти по формулам:
|
P |
= P* −t P* (1 − P*) |
Р |
в |
= P* + t P* (1 − P* ) |
|
н |
n |
n |
||
Здесь Рн и Рв нижняя и верхняя границы доверительного интервала, Р* частота (найденная доля клеток) , n общее число событий (число просмотренных клеток), t – коэффициент, который зависит от доверительной вероятности:

|
Балаховский Введение в статконтроль. |
12 |
||
|
Доверительная вероятность |
t |
||
|
0,90 |
1,643 |
||
|
0,95 |
1,960 |
||
|
0,99 |
2,576 |
Так, если при подсчете лейкоцитарной формулы посчитано 100 клеточных элементов, и из них Р* оказались лимфоцитами, то с 95% вероятностью их истинная доля находится между:
|
P * −1,96 |
P* (P* −1) |
и P * +1,96 |
P* (P* −1) |
|
|
n |
n |
|||
То же самое относится и к любым другим событиям или явлениям, например результатам опытов или числу заболеваний данной болезнью – Р* наблюдаемая доля (частота), n общее число наблюдений или опытов.
2.3. Нормальное распределение и распределение хи-квадрат
Теория нормального распределения бала заложена еще Гауссом в 18 веке, затем развита и разработана Лапласом, однако условия его возникновения раскрыл только Ляпунов, который доказал центральную предельную теорему. Суть ее заключается в том, что если какая-то величина есть результат сложения многих независимых случайных величин, она распределена нормально, не зависимо от того, по какому закону распределены составляющие ее слагаемые. В качестве примера можно привести время ожидания поезда метро. Каждый пассажир приходит независимо от других и имеет равную вероятность прождать любой отрезок времени между поездами. Такое распределение называется равномерным. Легко убедиться на примерах, что среднее время ожидание двумя случайными пассажирами уже не распределено равномерно, а имеет пик в середине интервала. Если же наблюдать за 6 или 7 пассажирами, то распределение их среднего времени ожидания практически не отличается от нормального.
Аналогичная картина складывается и при выполнении лабораторных анализов – если грубые погрешности исключены, а результаты не совпадают в силу мелких случайных причин: легкой липемичности, хлопьев белка или инородных частиц, пузырьков воздуха, загрязнения реактивов, мерцаний источника света, контаминации предыдущей пробой и т.д. , распределение результатов повторных исследований одного и того же материала должно подчиняться нормальному закону. Если этого нет, вероятнее всего, имеется какаято доминирующая погрешность, которая может быть устранена.
Плотность нормального распределения задается функцией:
|
1 |
− |
1 |
x −M 2 |
||||
|
f ( x) = |
e |
2 |
σ |
||||
|
σ |
2π |
||||||
Вероятность, что случайная величина больше X1 и меньше X2 равна соответствующему участку площади под кривой, т.е. интегралу. Он называется функцией Лапласа, обозначается греческой буквой Φ, не может быть выражен в элементарных функциях, но опубликован в специальных таблицах. Обычно, когда говорят о нормальном распределении, имеют в виду одномерное нормальное распределение, это значит, что речь идет об одной случайной величине. График плотности ее распределения можно нарисовать на плоскости. Если же случайных величин две, например, выполнено два анализа одного и того же контрольного материала, распределение результатов описывается двумерным нормальным распределением, вид которого представлен на рис. 2.

|
Балаховский Введение в статконтроль. |
13 |
Это уже пространственная фигура, она показывает плотность вероятности всех возможных комбинаций обоих величин, в этом случае говорят об их совместном распределении.Аналогично, если случайных величин три речь идет о трехмерном нормальном распределении, в общем случае о многомерном распределении. Естественно встает вопрос как посчитать вероятности таких комплексных событий. Оказывается, что если все случайные величины распределены по нормальному закону с одинаковыми параметрами, т.е. являются разными экземплярами одной и той же нормально распределенной случайной величины, вероятность каждой их комбинации определяется суммой квадратов. Если известны среднее значение M и средняя квадратичная σ, которые должны получиться при анализе данного контрольного материала, то статистики говорят, что математическое ожидание генеральной совокупности всех правильно выполненных анализов M , а дисперсия σ2. Допустим, выполнено три анализа, результаты которых X1, X2 и X3 несколько отличаются от M. Чтобы определить, случайное это отличие или неслучайное, надо узнать совместную вероятность того, что X1, X2 и X3 взяты именно из генеральной совокупности всех правильно выполненных анализов. Если она больше чем 0,05 (или при более строгом подходе больше чем 0,01), считается что различие случайно (не значимо), и результаты контроля хорошие. В противном случае считается, что полученные результаты не являются случайной выборкой из совокупности всех правильно выполненных анализов. О вероятности судят по сумме квадратов отклонений, которая по традиции обозначается греческой буквой хи во второй степени χ2 (читается хи-квадрат) и вычисляется по формуле:
|
χ2 = |
(X1 − M )2 |
+ |
(X 2 − M )2 |
+ |
(X 3 − M )2 |
…. |
|
σ 2 |
σ 2 |
|||||
|
σ 2 |
Вычислив χ2 по таблицам распределения хи-квадрат, находят искомую вероятность.
2.4. Погрешности
Никакое измерение не может быть абсолютно точным, всякое таит в себе возможность ошибки или погрешности, это одно и тоже. Аналитик всегда имеет определенное мнение о вероятности ошибки, даже если он его четко не формулирует – кто бы стал выполнять анализ, если бы считал, что результат может быть любым, ошибка не предсказуема!
Разрабатывая научные методы статистического контроля качества, надо четко формулировать законы распределения погрешностей измерения. Весь опыт работы аналити-
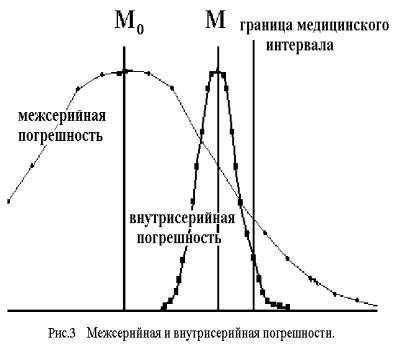
|
Балаховский Введение в статконтроль. |
14 |
ческих лабораторий говорит о том, что чаще всего результаты повторный анализов распределены по нормальному закону, а также что существует два типа погрешностей – внутри серии (быстрые) и между сериями (медленные). Погрешность внутри серии при
каждом повторном измерении своя, она характеризуется дисперсией σr2 и средней 0, погрешность между сериями характеризуется дисперсией σd2 средней 0, внутри каждой се-
рии она одинаковая. Реальная погрешность анализа есть сумма этих двух погрешностей. Иногда ошибки
делят на случайные и систематические, Систематические называют также сдвиг и биос, понимая под этим различие между средней многократно повторенного анализа и истинным значением. Такое разделение неоправданно, так как систематическая ошибка непостоянна: она может увеличиваться или уменьшаться в зависимости от обстоятельств, поэтому тоже является случайной величиной. Правильнее говорить не о систематической, а о межсерийной ошибке.
Конечно, никто не может утверждать, что погрешности медицинских лабораторных анализов всегда распределены по нормальному закону, тут возможны любые ситуации, поэтому контроль работы лаборатории должен начинаться с того, чтобы проверить, действительно ли результаты повторных анализов одного и того же материала распределены по нормальному закону. К сожалению, это сделать трудно – когда материала мало, заподозрить, что распределение ненормальное можно только, если оно явно асимметрично.
3. Контроль качества по данным анализов пациентов
Использование контрольных образцов для проверки качества работы всегда дорого – надо покупать сами образцы, требуются затраты на реактивы и работу, поэтому объем проверок неизбежно ограничен и возникает вопрос о статистической достоверности. Контроль по данным пациентов практически ничего не стоит – анализы ведь все равно выполняются, надо только иметь достаточно материала, компьютерную программу и умение. В большой лаборатории, которая ежедневно обслуживает сотню пациентов, контроль по их данным статистически очень достоверен, но не дает абсолютных величин и сопоставление результатов разных лабораторий (контингенты которых могут различаться) затруднено. Поэтому надо использовать оба варианта, разумно комбинируя их. Есть еще и промежуточный подход – так называемый метод «расщепленных» проб – когда несколько образцов проанализированного биологического материала, повторно исследуют на следующий день, это очень хороший способ оценить воспроизводимость результатов в разные дни.
Ниже описаны три способа использования данных пациентов для контроля качества.
3.1. Гистограммы
Просто и наглядно можно судить о качестве работы по данным пациентов строя гистограммы. В лаборатории, где ежемесячно выполняется несколько тысяч однотипных ис-

|
Балаховский Введение в статконтроль. |
15 |
следований, и данные находятся в компьютере, это легко сделать. Чтобы построить гистограмму, все результаты разбивают на разряды, желательно одинаковой ширины, подсчитывают число случаев в каждом из них и рисуют столбики. Число случаев в каждом разряде это частота событий, руководствуясь описанными выше общими правилами по ней можно вычислить доверительный интервал вероятности и отложить его на графике. Это облегчает сравнение данных. Такая гистограмма приведена на рис.4.
Самое сложное это удачно выбрать ширину разряда – если она широка – теряется информативность, если узка – в каждом разряде мало случаев и различия могут быть случайными. Чтобы обойти эту трудность можно заменить гистограмму функцией распределения (рис. 5), когда на графике откладывается не доля анализов, которые попали в данный диапазон
значений, а доля результатов, которые меньше данной величины. В отличие от гистограммы, функция распределения практически непрерывна, она получается более плавной,
но различия не так бросаются в глаза.
Чтобы сделать гистограмму стандартной и «сглаженной» без потери информативности можно использовать следующий прием. Диапазоны разрядов выбираются так, чтобы в первые 15 разрядов попала половина результатов. Для этого находят такой результат анализа m, чтобы n1 – число результатов меньше m , было по возможности равно n3 – числу результатов, которые больше m. Понятно, что точно они редко совпадают, так как каждый результат – это дискретное число, которое встречаются много раз. В том случае, когда результат анализа m встречается n2 раз, мы делим n2 на две части αn2 и —(1α)n2 , чтобытак выполнилось равенство:
n1+ αn2 =n3+ (1α–)n2
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание:
Центральная предельная теорема:
Формулировка центральной предельной теоремы (для одинаково распределенных слагаемых).
Пусть 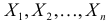

сколь угодно близок к нормальному закону распределения.
В условиях теоремы имеет место предельное соотношение 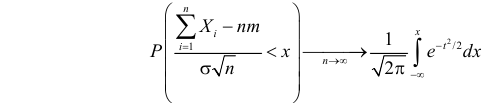
где 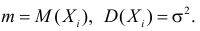
Пример:
Стрелок в десятку попадает с вероятностью 0,4, в девятку – с вероятностью 0,3, в восьмерку – с вероятностью 0,2, в семерку – с вероятностью 0,1. Какова вероятность того, что при 25 выстрелах стрелок наберет от 220 до 240 очков?
Решение. Пусть при  м выстреле стрелок выбивает
м выстреле стрелок выбивает  очков. Величины
очков. Величины 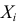 независимы и имеют одно и то же распределение
независимы и имеют одно и то же распределение
Заметим, что 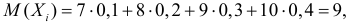 а ( )
а ( ) 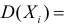
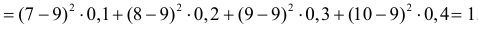 .
.
Сумма очков 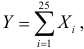 будучи суммой большого числа независимых одинаково распределенных слагаемых с ограниченными дисперсиями, имеет закон распределения близкий к нормальному с параметрами
будучи суммой большого числа независимых одинаково распределенных слагаемых с ограниченными дисперсиями, имеет закон распределения близкий к нормальному с параметрами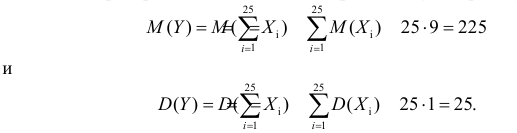
В итоге 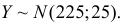 Поэтому по формуле (2.9.2)
Поэтому по формуле (2.9.2)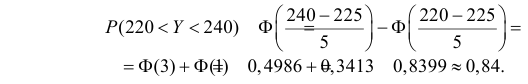
Ответ. 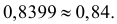
Пример:
Регулировка прибора занимает время от 4 до 10 мин. Регулировщику предстоит отрегулировать 50 приборов. Считая для каждого прибора равновозможными все значения времени регулировки в указанных пределах, оценить вероятность того, что регулировщик справится с работой за шесть часов.
Решение. Пусть 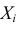 – время регулировки го прибора, а
– время регулировки го прибора, а 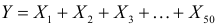 – время выполнения работы рабочим. Требуется найти
– время выполнения работы рабочим. Требуется найти 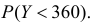 Величина Y является суммой большого числа одинаково распределенных независимых случайных величин, каждая из которых ограничена. По центральной предельной теореме Y имеет закон распределения близкий к нормальному закону распределения. Найдем параметры этого закона, т.е. математическое ожидание и дисперсию величины Y. Так как случайные величины независимы, то
Величина Y является суммой большого числа одинаково распределенных независимых случайных величин, каждая из которых ограничена. По центральной предельной теореме Y имеет закон распределения близкий к нормальному закону распределения. Найдем параметры этого закона, т.е. математическое ожидание и дисперсию величины Y. Так как случайные величины независимы, то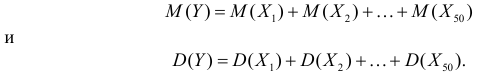
Вычислим  и
и 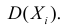 По условию все значения случайной величины равновозможны в отрезке [4,10]. Поэтому функция плотности вероятности этой случайной величины в указанном отрезке постоянна. Чтобы площадь, заключенная между графиком функции плотности вероятности и осью абсцисс, равнялась единице, следует положить
По условию все значения случайной величины равновозможны в отрезке [4,10]. Поэтому функция плотности вероятности этой случайной величины в указанном отрезке постоянна. Чтобы площадь, заключенная между графиком функции плотности вероятности и осью абсцисс, равнялась единице, следует положить 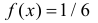 при
при 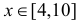 и
и 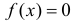 при остальных
при остальных  С учетом этого имеем
С учетом этого имеем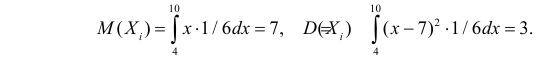
Поэтому 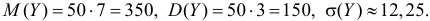
Итак, 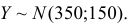 Для вычисления искомой вероятности воспользуемся формулой (2.9.2) и таблицей функции Лапласа (см. прил., табл. П2):
Для вычисления искомой вероятности воспользуемся формулой (2.9.2) и таблицей функции Лапласа (см. прил., табл. П2):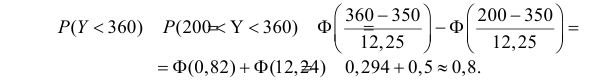
Ответ. 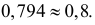
Пример:
Жетон для игрального автомата стоит 10 рублей. При использовании одного жетона (в отдельной игре) вероятность не получить ничего равна 0,8, вероятность получить 20 рублей равна 0,15, вероятность получения 50 рублей равна 0,04 и вероятность получения 100 рублей равна 0,01. Игрок купил жетонов на 1000 рублей. Какова вероятность того, что игрок не окажется в проигрыше?
Решение. Игрок купил 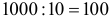 жетонов. Результат каждой игры (использование одного жетона) является случайной величиной с законом распределения
жетонов. Результат каждой игры (использование одного жетона) является случайной величиной с законом распределения

Выигрыш указан с учетом стоимости жетона.
Результат 100 игр обозначим через 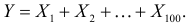 Величина Y является суммой большого числа одинаково распределенных независимых случайных величин, каждая из которых ограничена. По центральной предельной теореме Y имеет закон распределения близкий к нормальному закону распределения. Найдем параметры этого закона, т.е. математическое ожидание и дисперсию величины Y. Так как случайные величины независимы, то
Величина Y является суммой большого числа одинаково распределенных независимых случайных величин, каждая из которых ограничена. По центральной предельной теореме Y имеет закон распределения близкий к нормальному закону распределения. Найдем параметры этого закона, т.е. математическое ожидание и дисперсию величины Y. Так как случайные величины независимы, то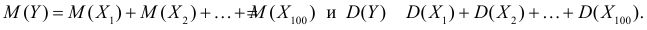
Так как
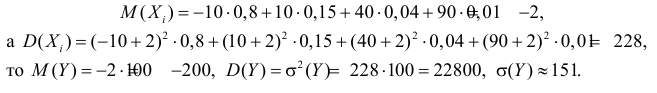
Итак, Y имеет примерно нормальный закон распределения 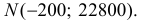 Игрок не окажется в проигрыше, если
Игрок не окажется в проигрыше, если 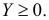 По формуле (2.9.2) имеем
По формуле (2.9.2) имеем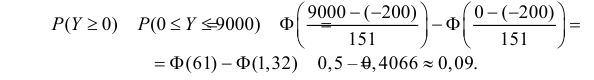
Ответ. 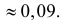
Пример:
Вероятность рождения мальчика равна 0,514. Определить вероятность того, что доля мальчиков среди 400 новорожденных будет отличаться от вероятности рождения мальчика не более чем на 0,05 в ту или другую сторону.
Решение. Рождение ребенка можно рассматривать как независимый опыт с вероятностью «успеха» 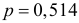 (по данным статистики на каждую тысячу новорожденных приходится 514 мальчиков). Тогда по формуле (2.13.1)
(по данным статистики на каждую тысячу новорожденных приходится 514 мальчиков). Тогда по формуле (2.13.1)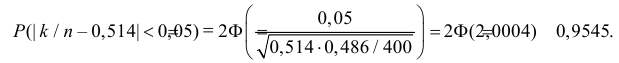
Ответ. 0,9545.
Пример:
Вероятность события 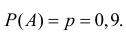 Сколько независимых опытов нужно проделать, чтобы с вероятностью 0,95 быть уверенным, что частота появления события в этих опытах будет отличаться от вероятности события не более чем на 0,05 в ту или другую сторону?
Сколько независимых опытов нужно проделать, чтобы с вероятностью 0,95 быть уверенным, что частота появления события в этих опытах будет отличаться от вероятности события не более чем на 0,05 в ту или другую сторону?
Решение. Запишем формулу (2.13.1) для нашего случая: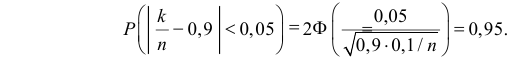
По таблице функции Лапласа находим, что 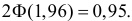 Поэтому
Поэтому 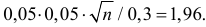 Откуда
Откуда 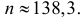 Условия задачи выполняются при
Условия задачи выполняются при 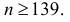
Ответ. 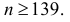
Центральная предельная теорема. Систематические изменения или случайность
Мы уже знаем, что нормальное распределение — особенное. Некоторые его свойства мы сможем использовать и для распределений, которые, строго говоря, нормальными не назовешь. Задача, которую мы рассмотрим в этом разделе имеет чрезвычайно важное значение для бизнеса, это задача о диагностировании тенденций к изменению показателей.
Удобство использование нормального распределения некоторых случайных величин и особые возможности, которые закон нормального распределения предоставляет исследователю, породили ряд теорем, которые позволяют пользоваться этими свойствами даже, если генеральная совокупность представляет собой «не вполне нормальное распределение».
Центральная предельная теорема имеет несколько формулировок, мы не будем их здесь полностью приводить и доказывать. Для нас важно знать только то, что в большинстве случаев среднее арифметическое выборки, взятой из генеральной совокупности (напомним, что это среднее арифметическое — тоже случайная величина), ложится на нормальное распределение гораздо лучше, чем исходная генеральная совокупность.
Другими словами, если мы возьмем несколько выборок из генеральной совокупности, то средние арифметические величины этих выборок будут представлять собой новую случайную величину с практически нормальным распределением. Именно эта теорема и позволит нам проверять так называемые статистические гипотезы, т.е. делать заключение о наличии тенденции к изменению показателей деятельности, которые сами по себе, являясь случайными величинами, имеют право на некоторый разброс.
Пример:
Фирма поместила информацию о своей продукции в каталоге. Был указан один из двух номеров телефона отдела продаж, на который и раньше поступали звонки потенциальных покупателей. Другой номер телефона в каталоге не упоминался. За два месяца до выхода каталога и в течение двух месяцев после было зарегистрировано следующее количество звонков на эти телефоны (два столбца в таблице). Как нам определить, подействовала ли информация, данная в каталоге, или мы имеем дело со случайным оживлением на рынке, а деньги на рекламу потрачены напрасно?
Последний столбец в таблице — ожидаемые величины. Это наши оценки, сделанные из предположения, что ничего не изменилось, и реклама не оказала никакого действия, т.е. произошло общее оживление на рынке и больше ничего, а пропорции между числом звонков на оба телефона должны сохраниться в точности. {Ожидаемая величина для телефона из каталога} = 455r216/358=274,5 {Ожидаемая величина для другого телефона} = 455r142/358=180,5. Наше предположение, о том, что реклама не оказала никакого воздействие на изменение числа покупателей, носит название нулевой гипотезы. Альтернативная гипотеза заключается в предположении о наличии такого влияния. Наша задача — выбрать более достоверную из двух этих гипотез. Чтобы оценить, насколько значимы отклонения реальной ситуации от ожидания по нулевой гипотезе, для обоих телефонов мы должны посчитать величину:

поставить их в таблицу и просуммировать.
Дальнейшие наши действия — определить, с какой вероятностью посчитанные отклонения «ложатся» на соответствующую кривую. Для такой оценки можно воспользоваться значениями так называемого  -критерия Пирсона. Обычно эти значения задаются в виде стандартных таблиц в книгах по статистике. Дадим и мы такую таблицу (X-греческая буква «хи»):
-критерия Пирсона. Обычно эти значения задаются в виде стандартных таблиц в книгах по статистике. Дадим и мы такую таблицу (X-греческая буква «хи»):
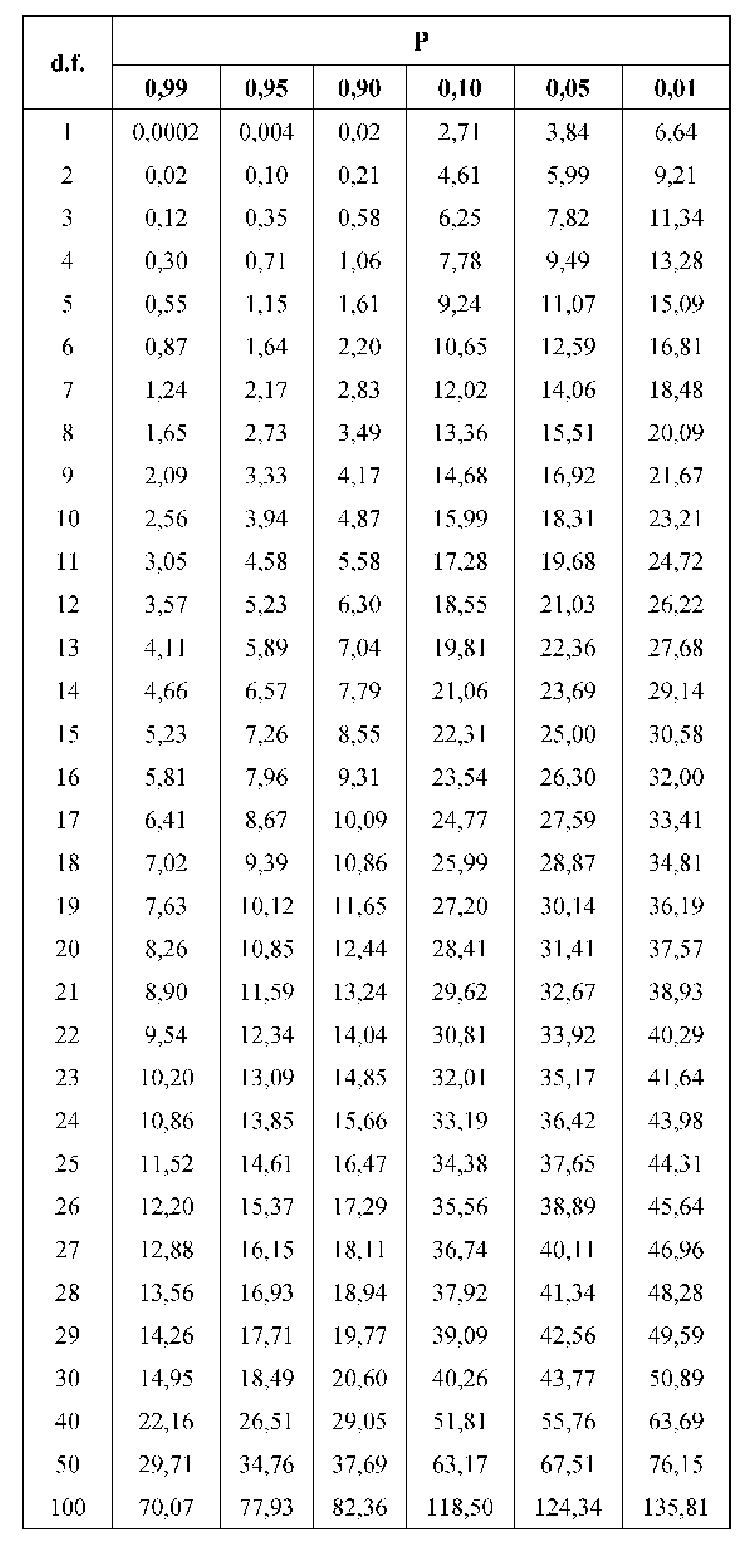
Теперь несколько слов о том, как пользоваться этой таблицей. Буквы d.f. означают число степеней свободы.
Чтобы посчитать степени свободы нужно просто брать в таблице с исходными данными количество строк n и столбцов m, и посчитать величину 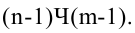 Это и будет количество степеней свободы в каждом конкретном случае. Правда, строки и столбцы берутся только для самих исходных данных, ни строка суммирования (всего), ни столбец подсчета ожидаемых величин при определении степени свободы не учитывается. В нашем случае
Это и будет количество степеней свободы в каждом конкретном случае. Правда, строки и столбцы берутся только для самих исходных данных, ни строка суммирования (всего), ни столбец подсчета ожидаемых величин при определении степени свободы не учитывается. В нашем случае 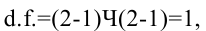 это означает, что степень свободы равна единице, и в таблице
это означает, что степень свободы равна единице, и в таблице  мы должны пользоваться соответствующей строкой (верхней).
мы должны пользоваться соответствующей строкой (верхней).
Теперь о столбцах этой таблицы. Цифры 0,99; 0,95; и т.д. означают, что величины отклонений 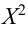 , стоящие в этих столбцах с вероятностью 0,99; 0,95; и т.д. возникли случайно. В нашем примере, вероятность случайного происхождения отклонения составляет менее 0,01 (т.е. меньше одного шанса из ста!). Мы вполне можем считать, что реклама оказала воздействие. Обратите внимание, что критерий.
, стоящие в этих столбцах с вероятностью 0,99; 0,95; и т.д. возникли случайно. В нашем примере, вероятность случайного происхождения отклонения составляет менее 0,01 (т.е. меньше одного шанса из ста!). Мы вполне можем считать, что реклама оказала воздействие. Обратите внимание, что критерий. 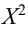 не говорит категорически, что случайность тут невозможна, просто вероятность этого очень мала. Другими словами, если мы отбросим нулевую гипотезу и выберем альтернативную, то вероятность ошибки будет меньше одного процента.
не говорит категорически, что случайность тут невозможна, просто вероятность этого очень мала. Другими словами, если мы отбросим нулевую гипотезу и выберем альтернативную, то вероятность ошибки будет меньше одного процента.
Если Вы будете пользоваться этим методом, совсем не нужно считать каждый раз вручную все отклонения. Подсчеты можно проводить в Excel автоматически.
Сначала запишите известные Вам показатели в виде таблицы. Затем посчитайте в Excel столбец ожидаемых величин. После этого нажмите в верхнем меню кнопку 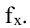
Затем, выберите среди функций тип «статистические», и из предложенного перечня в окошке — ХИ2ТЕСТ.
Затем, по подсказке, поставив курсор в поле «ожидаемый интервал» выделите мышью столбец ожидаемых значений (но не захватывайте сумму в нижней строке). Аналогично в поле «фактический интервал» введите массив из столбика фактических данных после рекламы. Программа сама посчитает граничную вероятность того, что отклонение было случайным.
Так в нашем варианте более точное значение вероятности составляет примерно 0,0035. В таблице мы попали по значению между столбцами и посчитать вероятность с такой точностью не смогли. Видимо для того, чтобы Вы привыкли пользоваться подобными оценками, имеет смысл обсудить вопрос о «степени свободы». Что это такое и какие степени свободы вообще могут быть? Понятно, что оценка значимости происходящих изменений может происходить только при наличии данных, как полученных при гипотетическом воздействии этих изменений, так и свободных от изменений.
В качестве заведомо не подверженных изменениям данных в нашем примере выступали показания числа звонков на оба телефона до публикации каталога. Кроме того, для дополнительной объективности данных, мы использовали один телефон как неизвестный в рекламе. Это позволило нам исключить возможное влияние сезонных изменений спроса или другие подобные факторы. В других ситуациях, мы можем сравнивать динамику спроса на один товар с динамикой спроса на другой, если идет целевая раскрутка этого товара, или же товар входит в моду. И в этой ситуации свойства нормального распределения помогут нам сделать вывод о значимости происходящих изменений.
Предельные теоремы теории вероятностей
Сходимость по вероятности
Согласно молекулярно-кинетической теории все газы состоят из большого числа атомов и молекул, которые движутся хаотически в разных направлениях и с разными скоростями. Заранее нельзя указать, где в определенный момент времени, и с какой скоростью будет двигаться та или иная частица. Однако при измерении давления газа измерительный прибор показывает постоянную величину при неизменных внешних условиях. Это показание прибора зависит от числа ударяющихся частиц, от направления их движения и величины скорости частицы. Однако ввиду огромного числа частиц их суммарное действие оказывается постоянным. Этот опыт долгое время использовался как аргумент против молекулярно-кинетической теории. Но, когда был поставлен опыт с “небольшим” числом частиц, то давление при неизменных внешних условиях стало колеблющейся величиной. Этот опыт является иллюстрацией “закона больших чисел”, который будет рассмотрен ниже.
Пусть дана последовательность случайных величин 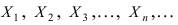 и некоторое постоянное число С.
и некоторое постоянное число С.
Определение: Сходимостью по вероятности последовательности случайных величин 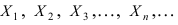 к постоянному числу С называется тот факт, когда для любого положительного числа
к постоянному числу С называется тот факт, когда для любого положительного числа 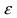 имеет место предельное соотношение:
имеет место предельное соотношение: 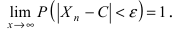
В дальнейшем рассмотрим теоремы, которые устанавливают сходимость некоторых последовательностей случайных величин к постоянному числу. Этими теоремами являются предельные теоремы теории вероятностей. Они разделяются на 2 группы. Первая группа объединяется под общим названием “закон больших чисел”. Эти теоремы доказывают устойчивость средних значений случайных величин и выявляют общие условия, выполнение которых приводит к устойчивости случайных процессов и явлений. Вторая группа теорем получила общее название “центральной предельной теоремы”, которая рассматривает предельные законы распределения. Примером этой группы теорем могут служить дифференциальная и интегральная формулы Муавра-Лапласа, которые были приведены в Лекции № 3. Поэтому в этой Лекции остановимся на теореме Чебышева, которая дает изящную и наиболее общую формулировку “закона больших чисел”.
Неравенство и теорема Чебышева
Прежде, чем рассматривать теорему Чебышева, сформулируем его важное неравенство, которое справедливо как дискретных, так и случайных непрерывных величин.
Теорема: Вероятность того, что отклонение случайной величины X от её математического ожидания по абсолютной величине меньше любого заранее заданного положительного числа 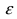 , не меньше, чем
, не меньше, чем 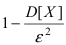 .
.
Доказательство: Пусть X — случайная дискретная величина, для которой дисперсия равна 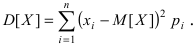 В этой сумме отбросим все те слагаемые, для которых выполняется неравенство
В этой сумме отбросим все те слагаемые, для которых выполняется неравенство 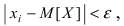 и оставим только те слагаемые, для которых выполняется неравенство
и оставим только те слагаемые, для которых выполняется неравенство 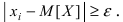 В результате этих действий сумма может только уменьшиться, т.е.
В результате этих действий сумма может только уменьшиться, т.е. 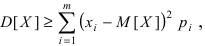 где
где 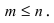 Эта сумма еще больше уменьшится, если в ней заменить выражения
Эта сумма еще больше уменьшится, если в ней заменить выражения 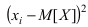 на малое число
на малое число 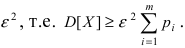 В этом неравенстве под знаком суммы стоят вероятности тех значений случайной величины X, для которых выполняется неравенство
В этом неравенстве под знаком суммы стоят вероятности тех значений случайной величины X, для которых выполняется неравенство 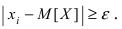 Тогда сумма
Тогда сумма 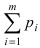 по теореме сложения случайных величин есть вероятность того, что случайная величина X принимает значения, при которых выполняется неравенство
по теореме сложения случайных величин есть вероятность того, что случайная величина X принимает значения, при которых выполняется неравенство 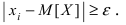 Следовательно, выполняется равенство:
Следовательно, выполняется равенство: 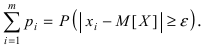 Вероятность противоположного события равна
Вероятность противоположного события равна 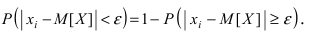 Подставив полученное равенство в неравенство для дисперсии, получим
Подставив полученное равенство в неравенство для дисперсии, получим 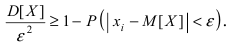
Отсюда и следует неравенство Чебышева. Аналогично теорема доказывается для случайной непрерывной величины.
Используя полученное неравенство, докажем теорему Чебышева:
Теорема: Пусть случайные величины 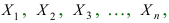 … попарно независимы, а их дисперсии ограничены (
… попарно независимы, а их дисперсии ограничены (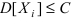 ). Тогда для любого заранее заданного положительного числа
). Тогда для любого заранее заданного положительного числа 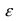 имеет место неравенство
имеет место неравенство 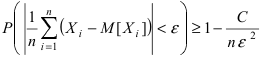 что иначе можно записать в виде
что иначе можно записать в виде
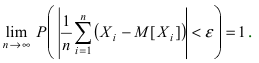
Доказательство: Рассмотрим случайную величину 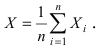 Так как по условию теоремы случайные величины
Так как по условию теоремы случайные величины 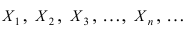 попарно-независимы, то математическое ожидание случайной величины X равно
попарно-независимы, то математическое ожидание случайной величины X равно 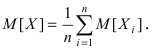
Аналогично для дисперсии имеет место равенство 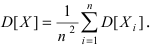 Так как по условию теоремы
Так как по условию теоремы 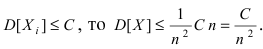 Воспользуемся неравенством Чебышева для случайной величины X, т.е.
Воспользуемся неравенством Чебышева для случайной величины X, т.е.
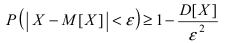 или с учетом ограниченности дисперсии
или с учетом ограниченности дисперсии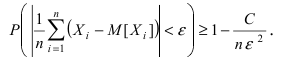
Отсюда следует, что при неограниченном росте  вероятность события, указанного в круглых скобках, будет стремиться к 1, т.е. при
вероятность события, указанного в круглых скобках, будет стремиться к 1, т.е. при  указанное событие будет становиться все более достоверным.
указанное событие будет становиться все более достоверным.
Оценка точности и надежности измерений с помощью теоремы Чебышева
Пусть 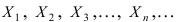 результаты n измерений случайной величины X. Очевидно, что
результаты n измерений случайной величины X. Очевидно, что 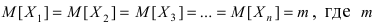 — истинное значение случайной величины X. Примем за приближенное значение измеряемой величины среднее арифметическое измеренных значений
— истинное значение случайной величины X. Примем за приближенное значение измеряемой величины среднее арифметическое измеренных значений 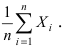 Измерение имеет точность
Измерение имеет точность 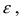 если выполняется неравенство
если выполняется неравенство 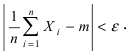 Измерение имеет точность
Измерение имеет точность 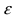 с надежностью
с надежностью 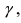 если выполняется вероятностное неравенство
если выполняется вероятностное неравенство 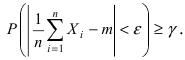 Согласно теореме Чебышева
Согласно теореме Чебышева 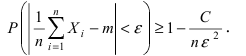
Для выполнения предыдущего неравенство должно выполняться соотношение: Отсюда найдем, какое количество опытов надо провести, чтобы получить заданную точность измерений 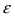 с заданной надежностью
с заданной надежностью 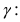
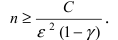
Теорема Ляпунова
В качестве “центральной предельной теоремы» рассмотрим теорему Ляпунова (без доказательства), которая объясняет особое место нормального закона распределения.
Теорема: Если случайные величины 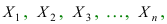 … попарно независимы и удовлетворяют условию
… попарно независимы и удовлетворяют условию 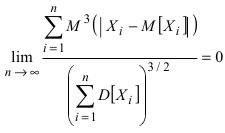 , то
, то 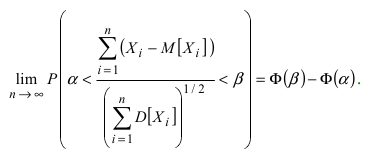 Смысл этой теоремы состоит в том, что при достаточно больших значениях n случайная величина
Смысл этой теоремы состоит в том, что при достаточно больших значениях n случайная величина 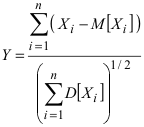 распределена почти по нормальному закону распределения с математическим ожиданием
распределена почти по нормальному закону распределения с математическим ожиданием 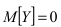 и средне-квадратичным отклонением
и средне-квадратичным отклонением 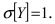 “Закон больших чисел” проявляется здесь в том, что несмотря на то, что о слагаемых случайных величинах
“Закон больших чисел” проявляется здесь в том, что несмотря на то, что о слагаемых случайных величинах 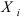 почти ничего неизвестно, но об их сумме известно всё, так как определен закон распределения.
почти ничего неизвестно, но об их сумме известно всё, так как определен закон распределения.
Применим эту теорему для оценки точности и надежности измерений. Пусть 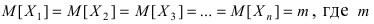 — истинное значение случайной величины X, а
— истинное значение случайной величины X, а 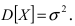 Тогда согласно теореме Ляпунова случайная величина
Тогда согласно теореме Ляпунова случайная величина
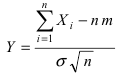
распределена почти по нормальному закону. Так как величины  не являются случайными, то случайная величина
не являются случайными, то случайная величина 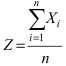 распределена также по нормальному закону. Вычислим её математическое ожидание и дисперсию
распределена также по нормальному закону. Вычислим её математическое ожидание и дисперсию 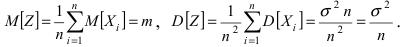 Тогда среднее квадратичное отклонение равно
Тогда среднее квадратичное отклонение равно 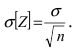 Используя формулу вероятности отклонения нормальной случайной величины от ее математического ожидания, получим
Используя формулу вероятности отклонения нормальной случайной величины от ее математического ожидания, получим 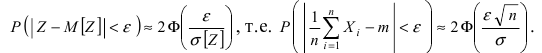 Следовательно, чтобы получить заданную точность измерений
Следовательно, чтобы получить заданную точность измерений 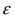 с заданной надежностью
с заданной надежностью 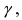 надо потребовать выполнение неравенства
надо потребовать выполнение неравенства 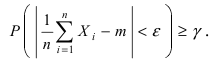 Поэтому
Поэтому 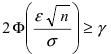 или
или 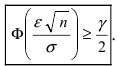
Это неравенство и есть условие достижения заданной точности измерений 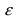 с заданной надежностью
с заданной надежностью 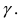
Пример:
Сколько измерений нужно провести, чтобы их среднее арифметическое значение дало измеряемую величину с точностью ε = 0.05 и надежностью γ = 0.9 , если дисперсия измеряемой величины меньше 2 . Необходимое число измерений равно 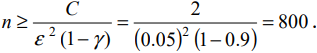
Решение:
По условию задачи точность 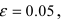 надежность
надежность 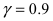 и дисперсия измеряемой величины меньше 2. Следовательно,
и дисперсия измеряемой величины меньше 2. Следовательно, 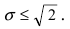 Таким образом, согласно теореме Ляпунова должно выполняться неравенство
Таким образом, согласно теореме Ляпунова должно выполняться неравенство 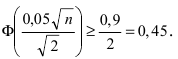
Из таблицы для функции Лапласа находим, что если 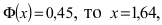 следовательно,
следовательно,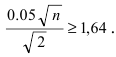 Отсюда находим, что
Отсюда находим, что 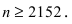
Теорема Бернулли
Пусть проводится n независимых испытаний, в каждом из которых вероятность появления события А постоянна и равна р.
Теорема: Вероятность отклонения частоты m/n от вероятности р в схеме Бернулли на сколь угодно малую положительную величину 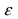 стремится к единице при достаточно большом числе испытаний, т.е.
стремится к единице при достаточно большом числе испытаний, т.е. 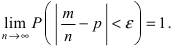
Доказательство: Обозначим через 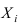 , число появлений события А в испытании i. Закон распределения для каждого испытания одинаков и имеет вид:
, число появлений события А в испытании i. Закон распределения для каждого испытания одинаков и имеет вид: 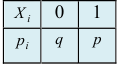
Поэтому математическое ожидание и дисперсия равны: 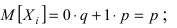
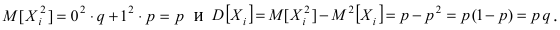 В силу того, что
В силу того, что 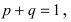 то дисперсия
то дисперсия 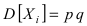 ограниченна. Так как испытания независимы, то и случайные величины
ограниченна. Так как испытания независимы, то и случайные величины 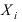 также независимы и к ним применима теорема Чебышева, т.е.
также независимы и к ним применима теорема Чебышева, т.е. 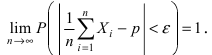 Величина
Величина 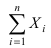 дает число случаев, благоприятствующих появлению события А, т.е. равно m, следовательно,
дает число случаев, благоприятствующих появлению события А, т.е. равно m, следовательно, 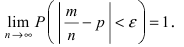
Замечание: Из последней формулы не следует, что 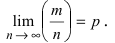 Теорема утверждает только тот факт, что вероятность этого события с ростом n стремится к единице.
Теорема утверждает только тот факт, что вероятность этого события с ростом n стремится к единице.
Замечание: Теорема Бернулли является частным случаем теоремы Чебышева и обосновывает возможность приближенной замены вероятности события A относительной частотой его появления, что находит свое применение в математической статистике.
- Ковариация в теории вероятности
- Функциональные преобразования двухмерных случайных величин
- Правило «трех сигм» в теории вероятности
- Производящие функции
- Нормальный закон распределения
- Основные законы распределения вероятностей
- Асимптотика схемы независимых испытаний
- Функции случайных величин