
Оценки параметров регрессии ненадежны, имеют большие стандартные ошибки и меняются с изменением объема наблюдений, не только по величине, но и по знаку. Это характерно для линейной модели множественной регрессии …
- гетероскедастичности остатков этой модели
- автокорреляции остатков этой модели
- при наличии в ней мультиколлинеарных факторов
- при неслучайном характере результирующей переменной
Помогли ответы? Ставь лайк 👍
Вопрос задал(а): Анонимный пользователь, 10 Ноябрь 2020 в 01:44
На вопрос ответил(а): Анастасия Степанова, 10 Ноябрь 2020 в 01:44

C 2014 года Помогаем сдавать тесты!
множественной
регрессии
Экономические
явления определяются, как правило,
большим числом совокупно действующих
факторов. В связи с этим часто возникает
задача исследования зависимости одной
переменной Y
от нескольких
объясняющих переменных X1,Х2,…Хn.
Эта задача решается с помощью множественного
регрессионного анализа.
Построение
уравнения множественной регрессии
начинается с решения вопроса о спецификации
модели, включающего отбор факторов и
выбор вида уравнения регрессии. Факторы,
включаемые во множественную регрессию,
должны отвечать следующим требованиям:
-
они
должны быть количественно измеримы
(качественным факторам необходимо
придать количественную определенность); -
между
факторами не должно быть высокой
корреляционной, а тем более функциональной
зависимости, т.е. наличия мультиколлинеарности.
Включение
в модель мультиколлинеарных факторов
может привести к следующим последствиям:
-
Затрудняется
интерпретация параметров множественной
регрессии как характеристик действия
факторов в «чистом виде», поскольку
факторы связаны между собой; параметры
линейной регрессии теряют экономический
смысл; -
Оценки параметров
ненадежны, имеют большие стандартные
ошибки и меняются с изменением объема
наблюдений.
Пусть
![]() — матрица – столбец значений зависимой
— матрица – столбец значений зависимой
переменной размераn;
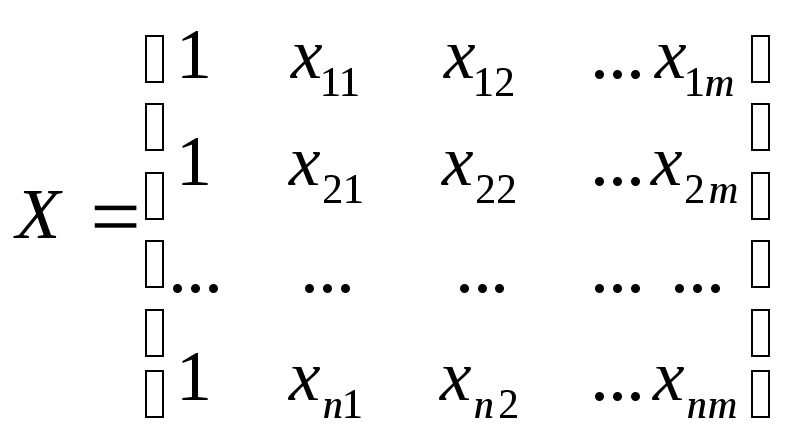 —
—
матрица значений, объясняющих переменных;
![]() —
—
матрица – столбец (вектор) параметров
размера m+1;
![]() —
—
матрица – столбец (вектор) остатков
размера n.
Тогда
в матричной форме модель множественной
линейной регрессии запишется следующим
образом:
![]() (1)
(1)
При
оценке параметров уравнения регрессии
(вектора b)
применяется метод наименьших квадратов
(МНК). При этом делаются определенные
предпосылки.
-
В
модели (1) ε
– случайный вектор, Х
— неслучайная (детерминированная)
матрица. -
Математическое
ожидание величины остатков равно нулю:
М(ε) = 0n. -
Дисперсия
остатков εi
постоянна для любого i
(условие
гомоскедастичности), остатки εi
и εj
при i≠j
не коррелированны:
 .
. -
ε
– нормально распределенный случайный
вектор, т.е. ε~N(0n;σ2
En). -
r(X)=m+1<n.
Столбцы матрицы Х
должны быть линейно независимыми (ранг
матрицы Х
максимальный, а число наблюдений n
превосходит ранг матрицы).
Модель
(1), в которой зависимая переменная,
остатки и объясняющие переменные
удовлетворяют предпосылкам 1-5 называется
классической нормальной линейной
моделью множественной регрессии
(КНЛММР). Если не выполняется только
предпосылка 4, то модель называется
классической линейной моделью
множественной регрессии (КЛММР).
Согласно
методу наименьших квадратов неизвестные
параметры выбираются таким образом,
чтобы сумма квадратов отклонений
фактических значений от значений,
найденных по уравнению регрессии, была
минимальной:
![]()
Решением
этой задачи является вектор
![]()
Одной
из наиболее эффективных оценок
адекватности модели является коэффициент
детерминации R2,
определяемый формулой:

Коэффициент
детерминации характеризует долю вариации
зависимой переменной, обусловленной
регрессией или изменчивостью объясняющих
переменных. Чем ближе R2
к единице, тем лучше построенная
регрессионная модель описывает
зависимость между объясняющими и
зависимой переменной.
Следует
иметь в виду, что при включении в модель
новой объясняющей переменной, коэффициент
детерминации увеличивается, хотя это
и не обязательно означает улучшение
качества регрессионной модели. В этой
связи лучше использовать скорректированный
(поправленный) коэффициент детерминации
R2,
пересчитываемый по формуле:
![]()
где
n
– число наблюдений,
m
– число параметров при переменных х.
Из
формулы следует, что с включением в
модель дополнительных переменных
разница между значениями
![]() и
и![]() увеличивается. Таким образом,
увеличивается. Таким образом,
скорректированный коэффициент
детерминации может уменьшаться при
добавлении в модель новой объясняющей
переменной, не оказывающей существенного
влияния на результативный признак.
Но
использование только коэффициента
детерминации для выбора наибольшего
уравнения регрессии может оказаться
недостаточным.
Средняя
относительная ошибка аппроксимации
рассчитывается по формуле:
![]()
Значимость
уравнения регрессии в целом сводиться
к проверке гипотезы об одновременном
равенстве нулю всех коэффициентов
регрессии при факторных признаках т.е.
гипотезы:
![]()
Если
данная гипотеза не отклоняется, то
делается вывод о том, что совокупное
влияние всех факторных признаков х1,
х2,
… хm
, включенных в модель, на зависимую
переменную y
можно считать статистически несущественным.
Проверка данной гипотезы осуществляется
на основе дисперсионного анализа.
Основной
идеей дисперсионного анализа является
разложение общей суммы квадратов
отклонений результативной переменной
y
от среднего значения y
на «объясненную» и «остаточную»:

Для
приведения дисперсий к сопоставимому
виду, определяют дисперсии на одну
степень свободы. Результаты вычислений
заносят в специальную таблицу
дисперсионного анализа.
Таблица 2.1.
Дисперсионный
анализ
|
Компоненты |
Сумма |
Число |
Оценка |
|
Общая |
|
m-1 |
|
|
Объясненная |
|
m |
|
|
Остаточная |
|
n-m-1 |
|
В
данной таблице n
– число наблюдений, m
– число параметров при переменных х.
Сравнивая
полученные оценки объясненной и
остаточной дисперсии на одну степень
свободы, определяют значение F
– критерия Фишера, используемого для
оценки значимости уравнения регрессии:
![]()
С
помощью F
– критерия проверяется нулевая гипотеза
о равенстве дисперсий H0:
SR2=S2.
Если
нулевая гипотеза справедлива, то
объясненная и остаточная дисперсии не
отличаются друг от друга. Для того, чтобы
уравнение регрессии было значимо в
целом (гипотеза Н0
была опровергнута) необходимо, чтобы
объясненная дисперсия превышала
остаточную в несколько раз. Критическое
значение F
– критерия определяется по таблице
Фишера – Снедекора.
Расчетное
значение сравнивается с табличным, и
если оно превышает табличное (Fрасч>Fтабл),
то гипотеза Н0
отвергается, и уравнение регрессии
признается значимым. Если Fрасч<Fтабл,
то уравнение регрессии считается
статистически незначимым. Нулевая
гипотеза Но
не может быть отклонена.
Расчетное
значение F
– критерия связано с коэффициентом
детерминации R2
следующим
соотношением:
![]()
где
m
–число параметров при переменных х;
n
– число наблюдений.
Оценка
значимости коэффициентов регрессии
сводится к проверке гипотезы о равенстве
нулю коэффициента регрессии при
соответствующем факторном признаке,
т.е. гипотезы:
Но
: bi=0
Проверка
гипотезы проводится с помощью t
– критерия Стьюдента. Для этого расчетное
значение t-критерия:
![]()
где
bi
– коэффициент регрессии при хi
mbi
– средняя квадратическая ошибка
коэффициента регрессии bi
сравнивается
с табличным tтабл
при заданном уровне значимости
![]()
(для экономических процессов и явлений)
и числе степеней свободы (n-2).
Если
расчетное значение превышает табличное,
то гипотезу о несущественности
коэффициента регрессии можно отклонить.
Рассмотрим
интерпретацию параметров модели линейной
множественной регрессии. В линейной
модели множественной регрессии
![]() коэффициенты регрессииbi
коэффициенты регрессииbi
характеризуют среднее изменение
результата с изменением соответствующего
фактора на единицу при неизменном
значении других факторов, закрепленных
на среднем уровне.
На
практике часто бывает необходимо
сравнить влияние на зависимую переменную
различных объясняющих переменных, когда
последние выражаются разными единицами
измерения. В этом случае используют
стандартизованные коэффициенты регрессии
βi
и коэффициенты эластичности Эi
(i=1,2,…,m).
Уравнение регрессии
в стандартизованной форме:
![]()
Где
![]() —
—
стандартизованные переменных.
В
результате такого нормирования средние
значения всех стандартизованных
переменных равны нулю, а дисперсии равны
единице, т.е.
![]()
![]()
Коэффициенты
«чистой» регрессии связаны со
стандартизованными коэффициентами
следующим соотношением:
![]()
Стандартизованные
коэффициенты показывают, на сколько
стандартных отклонений (сигм) изменится
в среднем результат, если соответствующий
фактор х1
изменится на одно стандартное отклонение
(одну сигму) при неизменном среднем
уровне других факторов. Сравнивая
стандартизованные коэффициенты друг
с другом, можно ранжировать факторы по
силе их воздействия на результат.
Средние коэффициенты
эластичности вычисляются по формуле:
![]()
Коэффициент
эластичности показывает, на сколько
процентов (от средней) изменится в
среднем Y
при увеличении только фактора Xi
на 1%.
При
эконометрическом моделировании реальных
экономических процессов предпосылки
КЛММР нередко оказываются нарушенными:
дисперсии остатков модели не одинаковы
(гетероскедастичность остатков), или
наблюдается корреляция между остатками
в разные моменты времени (автокоррелированные
остатки). Тогда предпосылка «3» запишется
следующим образом:
![]() где
где
Ώ – положительно определенная матрица.
Принимая,
что дисперсия объясняющих переменных
могут быть произвольными, мы получаем
обобщенную линейную модель множественной
регрессии (ОЛММР).
В
этом случае оценка параметров модели
осуществляется обобщенным методом
наименьших квадратов (ОМНК):
![]()
Если
модель гетероскедастична, то матрица
Ώ – диагональная. Тогда имеем:
![]()
В
этом случае обобщенный метод наименьших
квадратов называется взвешенным методом
наименьших квадратов, поскольку мы
«взвешиваем» каждое наблюдение с помощью
коэффициента 1/σi.
На
практике, однако, значения σi
почти никогда не бывают известны. Поэтому
сначала находят оценку вектора параметров
обычным методом наименьших квадратов.
Затем находят регрессию квадратов
остатков на квадратичные функции
объясняющих переменных, т.о. уравнение
![]()
Где
f(x)
– квадратичная функция.
Далее
по полученном уравнению рассчитывают
теоретические значения
![]() и определяют набор весов
и определяют набор весов![]() Затем
Затем
вводят новые переменных![]() и находят уравнение
и находят уравнение![]() .
.
Полученная оценка и есть оценка
взвешенного метода наименьших квадратов.
Проверить
модель на гетероскедастичность можно
с помощью следующих тестов: ранговой
корреляции Спирмена; Голдфельда-Квандта;
Уайта; Глейзера.
Рассмотрим
тест на гетероскедастичность, применяемый
в случае, если ошибки регрессии можно
считать нормально распределенными
случайными величинами, — тест
Голдфельда-Квандта.
Все
n
наблюдений упорядочиваются в порядке
возрастания значений фактора Х.
затем выбираются m
первых и m
последних наблюдений.
Гипотеза
о гомоскедастичности равносильна тому,
что значения остатков e1,…,em
и en—m+l,…,en
представляют собой выборочные наблюдения
нормально распределенных случайных
величин, имеющих одинаковые дисперсии.
Гипотеза
о равенстве дисперсий двух нормально
распределенных совокупностей проверяется
с помощью F
– критерия Фишера.
Расчетное значение
вычисляется по формуле (в числителе
всегда большая сумма квадратов):

Гипотеза
о равенстве дисперсий двух наборов по
m
наблюдений (т.е. гипотеза об отсутствии
гетероскедастичности остатков)
отвергается, если расчетное значение
превышает табличное F>Fα;m—p;m—p,
где p
– число регрессоров.
Мощность
теста (вероятность отвергнуть гипотезу
об отсутствии гетероскедастичности,
когда гетероскедастичности действительно
нет) максимальна, если выбирать m
порядка n/3.
Тест
Голдфельда – Квандта позволяет выявить
факт наличия гетероскедастичности, но
не позволяет описать характер зависимостей
дисперсий ошибок регрессии количественно.
Если
прослеживается влияние результатов
предыдущих наблюдений на результаты
последующих, случайные величины (ошибки)
εi
в регрессионной модели не оказываются
независимыми. Такие модели называются
моделями с наличием автокорреляции.
Как
правило, если автокорреляция присутствует,
то наибольшее влияние на последующее
наблюдение оказывает результат
предыдущего наблюдения. Наличие
автокорреляции между соседними уровнями
ряда можно определить с помощью теста
Дарбина-Уотсона. Расчетное значение
определяется по следующей формуле:

Значения
критерия находятся в интервале от 0 до
4. По таблицам критических точек
распределения Дарбина-Уотсона для
заданного уровня значимости
![]() ,
,
числа наблюдений (n)
и количества объясняющих переменных
(m)
находят пороговые значения dн
(нижняя
граница) и
dв
(верхняя
граница).
Если расчетное
значение:
![]() ,
,
то гипотеза об отсутствии автокорреляции
не отвергается (принимается);
![]() или
или
![]() ,
,
то вопрос об отвержении или принятии
гипотезы остается открытым (расчетное
значение попадает в зону неопределенности);
![]() ,
,
то принимается альтернативная гипотеза
о наличии положительной автокорреляции;
![]() ,
,
то принимается альтернативная гипотеза
о наличии отрицательной автокорреляции.
Таблица 2.2.
Промежутки внутри
интервала [0 — 4]
|
|
|
|
|
|
|
принимается |
вопрос |
гипотеза |
вопрос |
принимается |
Недостаток
теста Дарбина – Уотсона заключается
прежде всего в том, что он содержит зоны
неопределенности. Во-вторых, он позволяет
выявить наличие автокорреляции только
между соседними уровнями, тогда как
автокорреляция может существовать и
между более отдаленными наблюдениями.
Поэтому наряду с тестом Дарбина-Уотсона
для проверки наличия автокорреляции
используются тест серий (Бреуша –
Годфри),Q—
тест Льюинга – Бокса и другие. Наиболее
распространенным приемом устранения
автокорреляции во временных рядах
является построение авторегрессионных
моделей.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
уравнения множественной регрессии
Построение уравнения множественной регрессии начинается с решения вопроса о спецификации модели. Он включает в себя два круга вопросов: отбор факторов и выбор вида уравнения регрессии.
Включение в уравнение множественной регрессии того или иного набора факторов связано прежде всего с представлением исследователя о природе взаимосвязи моделируемого показателя с другими экономическими явлениями. Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям.
1. Они должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, не имеющий количественного измерения, то ему нужно придать количественную определенность.
2. Факторы не должны быть интеркоррелированы и тем более находиться в точной функциональной связи.
Включение в модель факторов с высокой интеркорреляцией, может привести к нежелательным последствиям – система нормальных уравнений может оказаться плохо обусловленной и повлечь за собой неустойчивость и ненадежность оценок коэффициентов регрессии.
Если между факторами существует высокая корреляция, то нельзя определить их изолированное влияние на результативный показатель и параметры уравнения регрессии оказываются неинтерпретируемыми.
Включаемые во множественную регрессию факторы должны объяснить вариацию независимой переменной. Если строится модель с набором 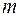 факторов, то для нее рассчитывается показатель детерминации
факторов, то для нее рассчитывается показатель детерминации 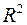 , который фиксирует долю объясненной вариации результативного признака за счет рассматриваемых в регрессии факторов. Влияние других, не учтенных в модели факторов, оценивается как
, который фиксирует долю объясненной вариации результативного признака за счет рассматриваемых в регрессии факторов. Влияние других, не учтенных в модели факторов, оценивается как 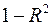 с соответствующей остаточной дисперсией
с соответствующей остаточной дисперсией  .
.
При дополнительном включении в регрессию 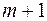 фактора коэффициент детерминации должен возрастать, а остаточная дисперсия уменьшаться:
фактора коэффициент детерминации должен возрастать, а остаточная дисперсия уменьшаться:
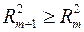 и
и 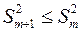 .
.
Если же этого не происходит и данные показатели практически не отличаются друг от друга, то включаемый в анализ фактор 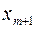 не улучшает модель и практически является лишним фактором.
не улучшает модель и практически является лишним фактором.
Насыщение модели лишними факторами не только не снижает величину остаточной дисперсии и не увеличивает показатель детерминации, но и приводит к статистической незначимости параметров регрессии по критерию Стьюдента.
Таким образом, хотя теоретически регрессионная модель позволяет учесть любое число факторов, практически в этом нет необходимости. Отбор факторов производится на основе качественного теоретико-экономического анализа. Однако теоретический анализ часто не позволяет однозначно ответить на вопрос о количественной взаимосвязи рассматриваемых признаков и целесообразности включения фактора в модель. Поэтому отбор факторов обычно осуществляется в две стадии: на первой подбираются факторы исходя из сущности проблемы; на второй – на основе матрицы показателей корреляции определяют статистики для параметров регрессии.
Коэффициенты интеркорреляции (т.е. корреляции между объясняющими переменными) позволяют исключать из модели дублирующие факторы. Считается, что две переменные явно коллинеарны, т.е. находятся между собой в линейной зависимости, если 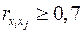 . Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии. Предпочтение при этом отдается не фактору, более тесно связанному с результатом, а тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами. В этом требовании проявляется специфика множественной регрессии как метода исследования комплексного воздействия факторов в условиях их независимости друг от друга.
. Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии. Предпочтение при этом отдается не фактору, более тесно связанному с результатом, а тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами. В этом требовании проявляется специфика множественной регрессии как метода исследования комплексного воздействия факторов в условиях их независимости друг от друга.
Пусть, например, при изучении зависимости 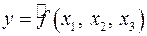 матрица парных коэффициентов корреляции оказалась следующей:
матрица парных коэффициентов корреляции оказалась следующей:
Таблица 2.1
 |
 |
 |
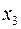 |
| |
0,8 | 0,7 | 0,6 |
| |
0,8 | 0,8 | 0,5 |
| |
0,7 | 0,8 | 0,2 |
| |
0,6 | 0,5 | 0,2 |
Очевидно, что факторы и дублируют друг друга. В анализ целесообразно включить фактор , а не , хотя корреляция с результатом слабее, чем корреляция фактора с 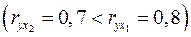 , но зато значительно слабее межфакторная корреляция
, но зато значительно слабее межфакторная корреляция  . Поэтому в данном случае в уравнение множественной регрессии включаются факторы , .
. Поэтому в данном случае в уравнение множественной регрессии включаются факторы , .
По величине парных коэффициентов корреляции обнаруживается лишь явная коллинеарность факторов. Наибольшие трудности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторов, когда более чем два фактора связаны между собой линейной зависимостью, т.е. имеет место совокупное воздействие факторов друг на друга. Наличие мультиколлинеарности факторов может означать, что некоторые факторы будут всегда действовать в унисон. В результате вариация в исходных данных перестает быть полностью независимой и нельзя оценить воздействие каждого фактора в отдельности.
Включение в модель мультиколлинеарных факторов нежелательно в силу следующих последствий:
1. Затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в «чистом» виде, ибо факторы коррелированы; параметры линейной регрессии теряют экономический смысл.
2. Оценки параметров ненадежны, обнаруживают большие стандартные ошибки и меняются с изменением объема наблюдений (не только по величине, но и по знаку), что делает модель непригодной для анализа и прогнозирования.
Для оценки мультиколлинеарности факторов может использоваться определитель матрицы парных коэффициентов корреляции между факторами.
Если бы факторы не коррелировали между собой, то матрица парных коэффициентов корреляции между факторами была бы единичной матрицей, поскольку все недиагональные элементы 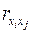
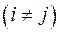 были бы равны нулю. Так, для уравнения, включающего три объясняющих переменных
были бы равны нулю. Так, для уравнения, включающего три объясняющих переменных
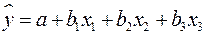
матрица коэффициентов корреляции между факторами имела бы определитель, равный единице:
 .
.
Если же, наоборот, между факторами существует полная линейная зависимость и все коэффициенты корреляции равны единице, то определитель такой матрицы равен нулю:
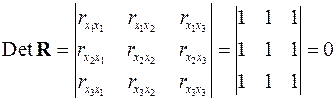 .
.
Чем ближе к нулю определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность факторов и ненадежнее результаты множественной регрессии. И, наоборот, чем ближе к единице определитель матрицы межфакторной корреляции, тем меньше мультиколлинеарность факторов.
Существует ряд подходов преодоления сильной межфакторной корреляции. Самый простой путь устранения мультиколлинеарности состоит в исключении из модели одного или нескольких факторов. Другой подход связан с преобразованием факторов, при котором уменьшается корреляция между ними.
Одним из путей учета внутренней корреляции факторов является переход к совмещенным уравнениям регрессии, т.е. к уравнениям, которые отражают не только влияние факторов, но и их взаимодействие. Так, если 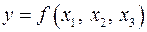 , то возможно построение следующего совмещенного уравнения:
, то возможно построение следующего совмещенного уравнения:
 .
.
Рассматриваемое уравнение включает взаимодействие первого порядка (взаимодействие двух факторов). Возможно включение в модель и взаимодействий более высокого порядка, если будет доказана их статистическая значимость по  -критерию Фишера, но, как правило, взаимодействия третьего и более высоких порядков оказываются статистически незначимыми.
-критерию Фишера, но, как правило, взаимодействия третьего и более высоких порядков оказываются статистически незначимыми.
Отбор факторов, включаемых в регрессию, является одним из важнейших этапов практического использования методов регрессии. Подходы к отбору факторов на основе показателей корреляции могут быть разные. Они приводят построение уравнения множественной регрессии соответственно к разным методикам. В зависимости от того, какая методика построения уравнения регрессии принята, меняется алгоритм ее решения на ЭВМ.
Наиболее широкое применение получили следующие методы построения уравнения множественной регрессии:
1. Метод исключения – отсев факторов из полного его набора.
2. Метод включения – дополнительное введение фактора.
3. Шаговый регрессионный анализ – исключение ранее введенного фактора.
При отборе факторов также рекомендуется пользоваться следующим правилом: число включаемых факторов обычно в 6–7 раз меньше объема совокупности, по которой строится регрессия. Если это соотношение нарушено, то число степеней свободы остаточной дисперсии очень мало. Это приводит к тому, что параметры уравнения регрессии оказываются статистически незначимыми, а -критерий меньше табличного значения.
2.2. Метод наименьших квадратов (МНК).
Свойства оценок на основе МНК
Возможны разные виды уравнений множественной регрессии: линейные и нелинейные.
Ввиду четкой интерпретации параметров наиболее широко используется линейная функция. В линейной множественной регрессии 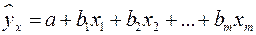 параметры при
параметры при 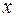 называются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизмененном значении других факторов, закрепленных на среднем уровне.
называются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизмененном значении других факторов, закрепленных на среднем уровне.
Рассмотрим линейную модель множественной регрессии
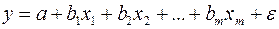 . (2.1)
. (2.1)
Классический подход к оцениванию параметров линейной модели множественной регрессии основан на методе наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака от расчетных 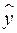 минимальна:
минимальна:
 . (2.2)
. (2.2)
Как известно из курса математического анализа, для того чтобы найти экстремум функции нескольких переменных, надо вычислить частные производные первого порядка по каждому из параметров и приравнять их к нулю.
Итак. Имеем функцию аргумента:
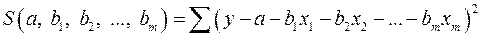 .
.
Находим частные производные первого порядка:
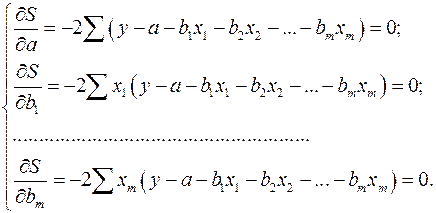
После элементарных преобразований приходим к системе линейных нормальных уравнений для нахождения параметров линейного уравнения множественной регрессии (2.1):
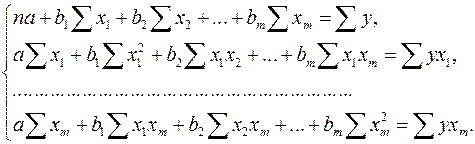 (2.3)
(2.3)
Для двухфакторной модели данная система будет иметь вид:

Метод наименьших квадратов применим и к уравнению множественной регрессии в стандартизированном масштабе:
 (2.4)
(2.4)
где 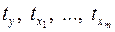 – стандартизированные переменные:
– стандартизированные переменные:  ,
, 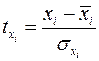 , для которых среднее значение равно нулю:
, для которых среднее значение равно нулю:  , а среднее квадратическое отклонение равно единице:
, а среднее квадратическое отклонение равно единице:  ;
; 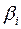 – стандартизированные коэффициенты регрессии.
– стандартизированные коэффициенты регрессии.
Стандартизованные коэффициенты регрессии показывают, на сколько единиц изменится в среднем результат, если соответствующий фактор 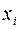 изменится на одну единицу при неизменном среднем уровне других факторов. В силу того, что все переменные заданы как центрированные и нормированные, стандартизованные коэффициенты регрессии
изменится на одну единицу при неизменном среднем уровне других факторов. В силу того, что все переменные заданы как центрированные и нормированные, стандартизованные коэффициенты регрессии 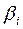 можно сравнивать между собой. Сравнивая их друг с другом, можно ранжировать факторы по силе их воздействия на результат. В этом основное достоинство стандартизованных коэффициентов регрессии в отличие от коэффициентов «чистой» регрессии, которые несравнимы между собой.
можно сравнивать между собой. Сравнивая их друг с другом, можно ранжировать факторы по силе их воздействия на результат. В этом основное достоинство стандартизованных коэффициентов регрессии в отличие от коэффициентов «чистой» регрессии, которые несравнимы между собой.
Применяя МНК к уравнению множественной регрессии в стандартизированном масштабе, получим систему нормальных уравнений вида
 (2.5)
(2.5)
где  и – коэффициенты парной и межфакторной корреляции.
и – коэффициенты парной и межфакторной корреляции.
Коэффициенты «чистой» регрессии  связаны со стандартизованными коэффициентами регрессии следующим образом:
связаны со стандартизованными коэффициентами регрессии следующим образом:
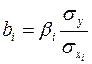 . (2.6)
. (2.6)
Поэтому можно переходить от уравнения регрессии в стандартизованном масштабе (2.4) к уравнению регрессии в натуральном масштабе переменных (2.1), при этом параметр 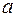 определяется как
определяется как 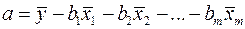 .
.
Рассмотренный смысл стандартизованных коэффициентов регрессии позволяет их использовать при отсеве факторов – из модели исключаются факторы с наименьшим значением .
На основе линейного уравнения множественной регрессии
(2.7)
могут быть найдены частные уравнения регрессии:
 (2.8)
(2.8)
т.е. уравнения регрессии, которые связывают результативный признак с соответствующим фактором при закреплении остальных факторов на среднем уровне. В развернутом виде систему (2.8) можно переписать в виде:
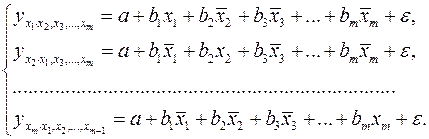
При подстановке в эти уравнения средних значений соответствующих факторов они принимают вид парных уравнений линейной регрессии, т.е. имеем
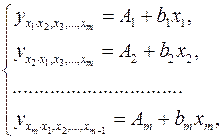 (2.9)
(2.9)
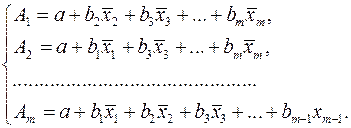
В отличие от парной регрессии частные уравнения регрессии характеризуют изолированное влияние фактора на результат, ибо другие факторы закреплены на неизменном уровне. Эффекты влияния других факторов присоединены в них к свободному члену уравнения множественной регрессии. Это позволяет на основе частных уравнений регрессии определять частные коэффициенты эластичности:
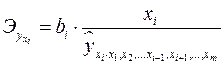 , (2.10)
, (2.10)
где – коэффициент регрессии для фактора в уравнении множественной регрессии, 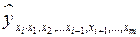 – частное уравнение регрессии.
– частное уравнение регрессии.
Наряду с частными коэффициентами эластичности могут быть найдены средние по совокупности показатели эластичности:
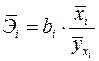 , (2.11)
, (2.11)
которые показывают на сколько процентов в среднем изменится результат, при изменении соответствующего фактора на 1%. Средние показатели эластичности можно сравнивать друг с другом и соответственно ранжировать факторы по силе их воздействия на результат.
Рассмотрим пример[4] (для сокращения объема вычислений ограничимся только десятью наблюдениями). Пусть имеются следующие данные (условные) о сменной добыче угля на одного рабочего (т), мощности пласта (м) и уровне механизации работ (%), характеризующие процесс добычи угля в 10 шахтах.
Таблица 2.2
Предполагая, что между переменными , , существует линейная корреляционная зависимость, найдем уравнение регрессии по и .
Для удобства дальнейших вычислений составляем таблицу (  ):
):
Таблица 2.3
| № | 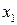 |
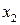 |
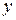 |
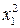 |
 |
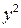 |
 |
 |
 |
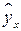 |
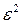 |
| 5,13 | 0,016 | ||||||||||
| 8,79 | 1,464 | ||||||||||
| 9,64 | 0,127 | ||||||||||
| 5,98 | 1,038 | ||||||||||
| 5,86 | 0,741 | ||||||||||
| 6,23 | 0,052 | ||||||||||
| 6,35 | 0,121 | ||||||||||
| 5,61 | 0,377 | ||||||||||
| 5,13 | 0,762 | ||||||||||
| 9,28 | 1,631 | ||||||||||
| Сумма | 6,329 | ||||||||||
| Среднее значение | 9,4 | 6,3 | 6,8 | 90,8 | 41,7 | 49,6 | 60,3 | 66,4 | 44,5 | – | – |
 |
2,44 | 2,01 | 3,36 | – | – | – | – | – | – | – | – |
 |
1,56 | 1,42 | 1,83 | – | – | – | – | – | – | – | – |
Для нахождения параметров уравнения регрессии в данном случае необходимо решить следующую систему нормальных уравнений:
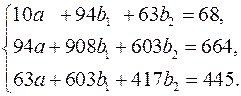
Откуда получаем, что 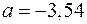 ,
,  ,
, 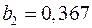 . Т.е. получили следующее уравнение множественной регрессии:
. Т.е. получили следующее уравнение множественной регрессии:
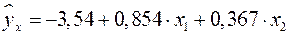 .
.
Оно показывает, что при увеличении только мощности пласта (при неизменном ) на 1 м добыча угля на одного рабочего увеличится в среднем на 0,854 т, а при увеличении только уровня механизации работ (при неизменном ) на 1% – в среднем на 0,367 т.
Найдем уравнение множественной регрессии в стандартизованном масштабе:
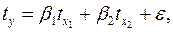
при этом стандартизованные коэффициенты регрессии будут
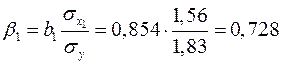 ,
,
 .
.
Т.е. уравнение будет выглядеть следующим образом:
 .
.
Так как стандартизованные коэффициенты регрессии можно сравнивать между собой, то можно сказать, что мощность пласта оказывает большее влияние на сменную добычу угля, чем уровень механизации работ.
Сравнивать влияние факторов на результат можно также при помощи средних коэффициентов эластичности (2.11):
.
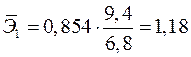 ,
, 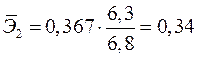 .
.
Т.е. увеличение только мощности пласта (от своего среднего значения) или только уровня механизации работ на 1% увеличивает в среднем сменную добычу угля на 1,18% или 0,34% соответственно. Таким образом, подтверждается большее влияние на результат фактора , чем фактора .
2.3. Проверка существенности факторов
Спецификация модели множественной регрессии
Множественная регрессии и корреляция
Множественная регрессия широко используется в решении проблем спроса, доходности акций, при изучении функции издержек производства, в макроэкономических расчетах и целого ряда других вопросов эконометрики. В настоящее время множественная регрессия — один из наиболее распространенных методов в эконометрике. основная цель множественной регрессии — построить модель с большим числом факторов, определив при этом влияние каждого из них в отдельности, а также совокупное их воздействие на моделируемый показатель.
Построение уравнения множественной регрессии начинается с вопроса о спецификации модели. Спецификация модели множественной регрессии, как и в случае парной регрессии, состоит из решения двух основных задач: отбора факторов и выбора вида уравнения регрессии. Однако, их решение при построении множественной регрессии имеет некоторую специфику, которая рассматривается ниже.
Отбор факторов, включаемых во множественную регрессию, является одним из важнейших этапов практического использования метода регрессии, от которого во многом зависит качество построенной модели.
Одной из основных проблем построения уравнения множественной регрессии, возникающих на этапе отбора факторов является проблема размерности модели, которая заключается в определении оптимального числа факторов. Может показаться, что чем больше факторов включено в уравнение регрессии, тем оно лучше описывает явление. Однако это справедливо лишь отчасти. Насыщение модели лишними факторами часто не только не снижают величину остаточной дисперсии и не увеличивает показатель детерминации, но и приводит к статистической незначимости некоторых параметров регрессии по t— критерию Стьюдента. Сокращение размерности модели за счет исключения второстепенных, экономически и статистически несущественных факторов способствует повышению ее качества.
Таким образом, хотя теоретически регрессионная модель позволяет учесть любое число факторов, практически в этом нет необходимости. При отборе факторов рекомендуется пользоваться следующим эмпирическим правилом: число факторов, включаемых в уравнение множественной регресии должно быть в 6-7 раз меньше объема совокупности, по которой строится регрессия. Не соблюдение этого правила приводит к тому, что некоторые параметры уравнения регрессии оказываются статистически незначимыми.
После определения размерности модели встает вопрос, какие именно факторы должны быть включены в уравнение регрессии, а какие нет. Предварительный отбор факторов обычно производится на основе качественного теоретико-экономического анализа. Однако теоретический анализ часто не позволяет однозначно ответить на вопрос о целесообразности включения того или иного фактора в модель. Поэтому на практике отбор факторов обычно осуществляется в два этапа: на первом подбираются факторы исходя из сущности проблемы; на втором — рассчитываются некоторые количественные показатели, значение которых дает возможность отобрать необходимые факторы. К таким показателям относятся частные коэффициенты корреляции и совокупный коэффициент детерминации.
На втором этапе отбора факторов обычно используют различные пошаговые процедуры (так называемый шаговый регрессионный анализ). Наиболее широкое применение получили следующие пошаговые методы отбора факторов:
* метод включения-исключения факторов.
В случае реализации метода включения, на первом шаге в уравнение регрессии включается лишь один фактор, имеющий с результативной переменной y наибольший коэффициент детерминации. На втором шаге в полученное уравнение регрессии добавляется еще один фактор, который вместе с первоначально включенным фактором образует пару объясняющих переменных имеющихс y наиболее высокий коэффициент детерминации. На третье шаге вводится в уравнение регрессии еще одна объясняющая переменная, которая вместе с двумя первоначально отобранными образует тройку факторов, имеющих с y наиболее высокий коэффициент детерминации, и т. д. Процедура введения новых переменных продолжатся до тех пор, пока возрастает значение показателя детерминации.
Процедура реализации метода исключения является обратной выше описанной. Сначала строится модель регрессии с полным набором факторов и определяется показатель детерминации.
Далее последовательно из модели регрессии исключаются факторы, устранение которых обеспечивает наименьшее снижение показателя детерминации.
Метод вкючения-исключения представляет собой комбинацию выше описанных методов.
Каждый из рассмотренных методов по-своему решает проблему отбора факторов, давая в целом близкие результаты. Однако, следует отметить, что какая бы пошаговая процедура отбора факторов не использовалась, она не гарантирует определения оптимального (в смысле получения максимального значения показателя детерминации R 2 ) набора объясняющих переменных. Однако в большинстве случаев получаемый с помощью пошаговых процедур набор переменных оказывается близким к оптимальному.
Отбор факторов для включения в уравнение множественной регрессии может быть произведен на и на основе частных коэффициентов корреляции.
Проблема отбора факторов часто усугубляется наличием взаимосвязи между независимыми переменными, включаемыми в уравнение регрессии.
Эта взаимосвязь может проявляться в виде:
Под коллинеарностью понимается тесная линейная связь между двумя факторами. Условием коллинеарности факторов xi , xj (i¹j) является .
Последствия, к которым может привести наличие тесной линейной связи между факторами легко проследить на примере линейного уравнения множественной регрессии с двумя факторами
.
Стандартные ошибки коэффициентов регрессии для этого уравнения определяются по формуле
.
Таким образом, чем теснее связь между факторами, тем ближе модуль значения парного коэффициента корреляции к единице, и тем больше стандартные ошибки коэффициентов регрессии при прочих равных условиях. Увеличение стандартных ошибок ведет к снижению статистической значимости коэффициентов регрессии.
Из приведенной выше формулы для стандартной ошибки коэффициентов регрессии видны некоторые способы устранения влияния коллинеарности факторов:
1) исключение одного из факторов, что приведет к ;
2) увеличение объема выборки n;
3) уменьшение остаточной дисперсии , путем введения дополнительных факторов, оказывающих существенное влияние на результативную переменную y;
4) формирование выборки, по которой поизводится построение уравнения регрессии, с тем расчетом, чтобы дисперсия факторов была наибольшей.
Под мультиколлинеарностью понимается тесная линейная взаимосвязь между тремя и более факторами, включенными в уравнение множественной регрессии.
Включение в модель мультиколлинеарных факторов нежелательно в силу следующих причин:
— поскольку факторы не являются независимыми, то нельзя определить их изолированное влияние на результативный признак и коэффициенты множественной регрессии становятся экономически неинтерпретируемыми;
— оценки параметров ненадежны, имеют большие стандартные ошибки и являются нестабильными, т. е. могут сильно изменятся не только по величине, но и по знаку с изменением объема наблюдений, что делает регрессионную модель непригодной для анализа и прогнозирования.
В решении проблемы мультиколлинеарности можно выделить несколько этапов:
* установление наличия мультиколлинеарности;
* определение причин возникновения мультиколлинеарности;
* разработка мер по ее устранению.
Причинами возникновения мультиколлинеарности между факторами являются:
* изучаемые факторы, характеризуют одну и ту же сторону явления или процесса. Например, показатели объема произведенной продукции и среднегодовой стоимости основных фондов одновременно включать в модель в качестве факторов не рекомендуется, так как они оба характеризуют размер предприятия;
* использование в качестве факторов показателей, суммарное значение которых представляет собой постоянную величину;
* факторы являются составными элементами друг друга;
* факторы по экономическому смыслу дублируют друг друга.
Оценка наличия мультиколлинеарности обычно производится на основе критерия Пирсона c 2 («хи-квадрат»), расчетное значение которого определяется по формуле
,
где M — матрица межфакторной корреляции (матрица парных коэффициентов корреляции между факторами):
.
Расчетное значение критерия сравнивается с табличным , найденным при заданной доверительной вероятности p и числе степеней свободы . Мультиколлинеарность присутствует и является существенной если .
Для определения факторов, являющихся причиной наличия мультиколлинеарности строятся уравнения регрессии зависимости каждого j-го фактора от остальных m-1 факторов
,
и определяются соответствующие показатели детерминации
.
Чем больше значение к единице, тем теснее фактор xj связан с другими факторами, включенными в уравнение регрессии, и именно этот фактор в наибольшей степени определяет наличие мультиколлинеарности.
Если основная задача регрессионной модели — прогноз будущих значений зависимой переменной, то при достаточно большом коэффициенте детерминации R 2 (>0.9) наличие мультиколлинеарности обычно не сказывается на прогнозных качествах модели.
Если же целью исследования является определение степени влияния каждой из объясняющих переменных на зависимую переменную, то наличие мультиколлинеарности, приводящее к увеличению стандартных ошибок, скорее всего, исказит истинные зависимости между переменными. В этой ситуации мультиколлинеарность является серьезной проблемой, которая требует своего решения.
Единого метода устранения мультиколлинеарности, пригодного в любом случае, не существует. Рассмотрим основные, наиболее широко используемые, методы.
1. Исключение переменной (-ых) из модели. Простейшим методом устранения мультиколлинеарности является исключение из модели одной или нескольких коррелированных переменных.
Однако в этой ситуации возможны ошибки спецификации модели. Например, при исследовании спроса на некоторый товар в качестве объясняющих переменных можно использовать цену данного товара и цены товаров-заменителей, которые зачастую коррелируют друг с другом. Исключив из модели цены товаров-заменителей, мы, скорее всего допустим ошибку спецификации. Вследствие чего можно получить неверные оценки параметров модели и сделать необоснованные выводы. Поэтому в прикладных эконометрических моделях желательно не исключать объясняющие переменные до тех пор, пока коллинеарность не станет серьезной проблемой.
2. Получение дополнительных данных или новой выборки. Поскольку мультиколлинеарность напрямую зависит от объема и качества выборки, то возможно, при другой выборки мультиколлинерности не будет либо она будет незначительной.
Иногда для уменьшения мультиколлинерности достаточно увеличить объем выборки. Увеличение количества данных сокращает стандартные ошибки коэффициентов регрессии и тем самым увеличивает их статистическую значимость.
Однако получение новой выборки или расширение старой не всегда возможно и/или связано с серьезными издержками.
3. Изменение спецификации модели. В ряде случаев проблема мультиколлинеарности может быть решена путем изменения спецификации модели: либо изменяется форма модели, либо добавляются объясняющие переменные, не учтенные в первоначальной модели, но существенно влияющие на зависимую переменную.
Использование данного метода может привести к уменьшению остаточной дисперсии, а следовательно и к снижению стандартных ошибок параметров уравнения регрессии.
4. Преобразование переменных. В ряде случаев минимизировать либо вообще устранить проблему мультиколлинеарности можно с помощью нелинейных преобразований переменных.
Например, пусть в линейном уравнении множественной регрессии
фактором, ответственным за наличие мультиколлинеарности, является фактор x1. Тогда устранить тесную линейную связь между фактором x1 и остальными факторами можно перейдя от исходного линейного уравнения множественной регрессии к нелинейному уравнению следующего вида:
Введем новые переменные
,
получим линейное уравнение регрессии
,
в котором факторы уже не находятся в тесной линейной связи.
Возможны и другие нелинейные преобразования переменных, близкие по своей сути к вышеописанным.
Одним из подходов к устранению влияния мультиколлинеарности на результаты регрессионного анализа является учет зависимости факторов, который может быть реализован двумя путями.
5. Учет коррелированности независимых переменных с помощью совмещенных уравнений. Одним из путей учета коррелированности факторов является переход от обычных уравнений множественной регрессии к совмещенным уравнениям регрессии, т. е. к уравнениям, которые отражают не только изолированное влияние факторов, но и совместное их влияние. Для описания взаимосвязи результативного признака с тремя факторами совмещенное уравнение регрессии может быть записано в виде
.
Как правило, взаимодействия третьего и более высоких порядков оказываются статистически незначимыми, поэтому при построении совмещенных уравнений регрессии ограничиваются взаимодействиями первого и второго порядков.
6. Учет зависимости между факторами с помощью систем совместных уравнений. Еще одним способом учета коррелированности факторов является переход от одного изолированного уравнения регрессии к системе совместных уравнений регрессии (более подробно о системах эконометрических уравнений см. 4).
Рассмотрим пример. Пусть в линейном уравнении множественной регрессии
фактор x1 является результатом действия факторов x2 и x3 . Что избежать влияния коллинеарности можно исключить фактор x1, но можно поступить и следующим образом. Вместо одного уравнения регрессии следует записать два, одно из которых описывает взаимосвязь результативного признака y с фактором x1 , а другое характеризует взаимодействие фактора x1 с факторами x2 и x3 . Полученные уравнения образуют следующую систему:
.
Таким образом, с помощью систем уравнений возможно учесть взаимодействие между факторами.
После решения проблемы отбора факторов, осуществляется выбор функциональной зависимости результативной переменой от факторов. Определение формы связи затрудняется тем, что, используя математический аппарат, теоретически зависимость между результативным и факторными признаками может быть выражена большим числом различных функций. Однако, при построении модели множественной регрессии стараются подобрать уравнение регрессии с одной стороны, по возможности, простое, с другой — с экономически интерпретируемыми параметрами. Иногда вид уравнения регрессии удается определить, исходя из сути моделируемого процесса или на основе анализа результатов аналогичных эконометрических исследований, проводившихся ранее. Но чаще всего этого сделать не получается. Наиболее приемлемым способом определения вида уравнения регрессии в этом случае является метод перебора. Данный способ является достаточно трудоемким, в связи с чем его реализация осуществляется на компьютере, оснащенным соответствующим программным обеспечением.
Практика построения многофакторных моделей взаимосвязей показывает, что почти все реально существующие зависимости между социально-экономическими явлениями можно описать, используя следующие модели:
;
;
3) экспоненциальная (показательная)
;
.
Ввиду четкой интерпретации параметров наиболее широко используется линейная и степенная функции.
Коэффициенты bi линейного уравнения множественной регрессии представляют собой коэффициенты чистой регрессии и показывают, на сколько в среднем изменится значение результативного признака у при изменении фактора xi на единицу при неизменном значении других факторов (включенных в равнение множественной регрессии), зафиксированных на среднем уровне.
Коэффициенты bi степенного уравнения множественной регрессии являются частными коэффициентами эластичности и показывают, на сколько процентов в среднем изменится значение результативного признака при изменении соответствующего фактора xi на 1 процент при неизменном значении других факторов, зафиксированных на среднем уровне. Этот вид уравнения получил наибольшее распространение в исследованиях спроса и потребления, а также в производственных функциях.
Множественная регрессия в EXCEL
history 26 января 2019 г.
-
Группы статей
- Статистический анализ
Рассмотрим использование MS EXCEL для прогнозирования переменной Y на основании нескольких переменных Х, т.е. множественную регрессию.
Перед прочтением этой статьи рекомендуется освежить в памяти простую линейную регрессию – прогнозирование на основе значений только одного фактора.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Множественного регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Статья про Множественный регрессионный анализ получилась большая, поэтому ниже для удобства приведены ее разделы:
Прогнозирование единственной переменной Y на основании значений 2-х или более переменных Х называется множественной регрессией .
Множественная линейная регрессионная модель (Multiple Linear Regression Model) имеет вид Y=β 0 +β 1 *X 1 +β 2 *X 2 +…+β k *X k +ε. В этом случае переменная Y зависит от k поясняющих переменных Х, т.е. регрессоров . ε — случайная ошибка . Модель является линейной относительно неизвестных параметров β.
Оценка неизвестных параметров
В этой статье рассмотрим модель с 2-мя регрессорами. Сначала введем необходимые обозначения и понятия множественной регрессии.
Для описания зависимости Y от 2-х переменных линейная модель имеет вид:
Параметры этой модели β i нам неизвестны, но их можно оценить, используя случайную выборку (измеренные значения переменной Y от заданных Х). Оценки параметров модели (β 0 , β 1 , β 2 ) обычно вычисляются методом наименьших квадратов (МНК) , который минимизирует сумму квадратов ошибок прогнозирования (критерий минимизации в англоязычной литературе обозначают как SSE – Sum of Squared Errors).
Ошибка ε имеет случайную природу и имеет свою функцию распределения со средним значением =0 и дисперсией σ 2 .
Оценки b 1 и b 2 называются коэффициентами регрессии , они определяют влияние соответствующей переменной X, когда все остальные независимые переменные остаются неизменными .
Сдвиг (intercept) или постоянный член b 0 , определяет прогнозируемое значение Y, когда все поясняющие переменные Х равны 0 (часто сдвиг не имеет физического смысла в рамках модели и обусловлен лишь математическими вычислениями МНК ).
Вычислив оценки, полученные методом МНК, позволяют прогнозировать значения переменной Y:
Примечание : Для случая 2-х регрессоров, все спрогнозированные значения переменной Y будут лежать в плоскости (в плоскости регрессии ).
В качестве примера рассмотрим технологический процесс изготовления нити:
Инженер, на основе имеющегося опыта, предположил, что прочность нити Y зависит от концентрации исходного раствора (Х 1 ) и температуры реакции (Х 2 ), и соответствует модели линейной регрессии. Для нахождения комбинации переменных Х, при которых Y принимает максимальное значение, необходимо определить коэффициенты регрессии, сделав выборку.
В MS EXCEL коэффициенты множественной регрессии удобнее всего вычислить с помощью функции ЛИНЕЙН() . Это сделано в файле примера на листе Коэффициенты . Чтобы вычислить оценки:
- выделите 3 ячейки в одной строке (т.к. мы рассматриваем случай 2-х регрессоров, то будут вычислены 2 коэффициента регрессии + величина сдвига = 3 значения, для вывода которых понадобится 3 ячейки). Пусть это будет диапазон С8:Е8 ;
- в Строке формул введите = ЛИНЕЙН(D20:D50;B20:C50) . Предполагается, что в столбце В содержатся прогнозируемые значения Y (в нашей модели это Прочность нити), в столбцах С и D содержатся значения контролируемых параметров Х (Х1 – Концентрация в столбце С и Х2 – Температура в столбце D).
- нажмите CTRL+SHIFT+ENTER (т.к. это формула массива ).
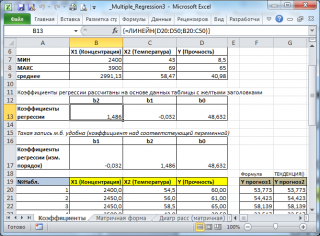
В левой ячейке будет рассчитано значение коэффициента регрессии b 2 для переменной Х2, в средней ячейке — значение коэффициента регрессии b 1 для переменной Х1, в правой – сдвиг . Обратите внимание, что порядок вывода коэффициентов регрессии обратный по отношению к расположению столбцов с данными соответствующих переменных Х (вычисленный коэффициент b 2 располагается левее по отношению к b 1 , тогда как значения переменной Х2 располагаются правее значений переменной Х1). Это может привести к путанице, поэтому лучше разместить коэффициенты над соответствующими столбцами с данными, как это сделано в строке 17 файла примера .
Примечание : В принципе без функции ЛИНЕЙН() можно обойтись, записав альтернативные формулы. Для этого в файле примера на листе Коэффициенты в столбцах I : K вычислены отклонения значений переменных Х 1i , Х 2i , Y i от их средних значений  , т.е.:
, т.е.: 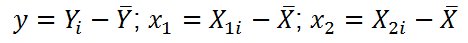
Далее коэффициенты регрессии рассчитываются по следующим формулам (эти формулы справедливы только при прогнозировании по 2-м независимым переменным Х):
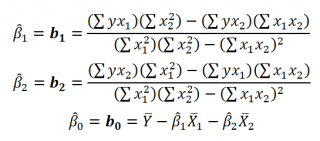
При прогнозировании по 3-м и более независимым переменным Х формулы для вычисления коэффициентов регрессии значительно усложняются, поэтому следует использовать матричный подход.
В файле примера на листе Матричная форма выполнены расчеты коэффициентов регрессии с помощью матричного подхода.
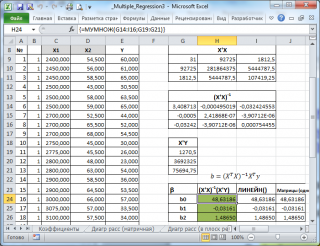
Расчет можно произвести как пошагово, так и одной формулой массива :
Коэффициенты регрессии (вектор b ) в этом случае вычисляются по формуле b =(X T X) -1 (X T Y) или в другом виде записи b =(X ’ X) -1 (X ’ Y)
Под Х подразумевается матрица, состоящая из столбцов значений переменной Х с дополнительным столбцом единиц, а под Y – вектор-столбец значений Y.
Диаграмма рассеяния
В случае простой линейной регрессии (один регрессор, т.е. одна переменная Х) для визуализации связи между прогнозируемым значением Y и переменной Х строят диаграмму рассеяния (двумерную).
В случае множественной линейной регрессии двумерную диаграмму рассеяния можно построить только для анализа влияния каждого отдельного регрессора на Y (при этом остальные Х не меняются), т.е. так называемую Матричную диаграмму рассеивания (См. файл примера лист Диагр расс (матричная) ).
К сожалению, такую диаграмму трудно интерпретировать.
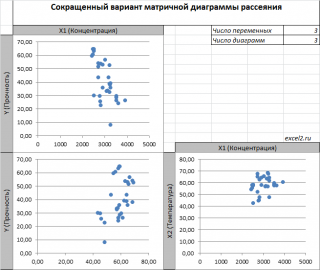
Более того, матричная диаграмма может вводить в заблуждение (см. Introduction to linear regression analysis / D . C . Montgomery , E . A . Peck , G . G . Vining , раздел 3.2.5 ), демонстрируя наличие или отсутствие линейной взаимосвязи между отдельным регрессором X i и Y.
Для случая с 2-мя регрессорами можно предложить альтернативный вид матричной диаграммы рассеяния . В стандартной диаграмме рассеяния строятся проекции на координатные плоскости Х1;Х2, Y;X1 и Y;X2. Однако, если взглянуть на точки относительно плоскости регрессии , то картину, на мой взгляд, будет проще интерпретировать.
Сравним две матричные диаграммы рассеяния (см. файл примера на листе «Диагр расс (в плоск регрессии)» , построенные для одних и тех же наблюдений. Первая – стандартная,

вторая представляет собой вид сверху на плоскость регрессии и 2 вида вдоль плоскости.
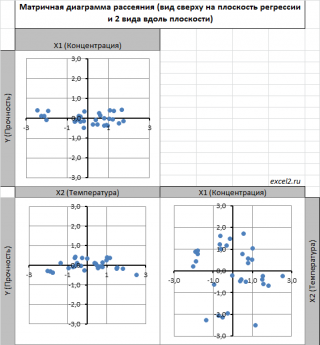
На второй диаграмме становится очевидно, что разброс точек относительно плоскости регрессии совсем не большой и поэтому, скорее всего, построенная модель является полезной, а выбранные 2 переменные Х позволяют прогнозировать Y (конечно, для подтверждения этой гипотезы нужно провести процедуру F-теста ).
Несколько слов о построении альтернативной матричной диаграммы рассеяния:
- Перед построением необходимо нормировать значения наблюдений (для каждой переменной вычесть среднее и разделить на стандартное отклонение ). В этом случае практически все точки на диаграммах будут находится в диапазоне +/-3 (по аналогии со стандартным нормальным распределением , 99% значений которого лежат в пределах +/-3 сигма). В этом случае, на диаграмме можно фиксировать мин/макс значений осей, чтобы EXCEL автоматически не модифицировал масштаб осей при изменении данных (это не всегда удобно);
- Теперь координаты точек необходимо рассчитать в системе отсчета относительно плоскости регрессии (в которой плоскость Оху’ совпадает с плоскостью регрессии). Для этого необходимо найти матрицу вращения , например, через вращение приводящее к совмещению нормали к плоскости регрессии и вектора оси Z (0;0;1);
- Новые координаты позволяют построить альтернативную матричную диаграмму. Кроме того, для удобства можно вращать систему координат вокруг новой оси Z, чтобы нагляднее представить себе распределение точек относительно плоскости регрессии (для этого использована Полоса прокрутки в ячейках Q31:S31 ).
Вычисление прогнозных значений Y (отдельное наблюдение и среднее значение) и построение доверительных интервалов
После того, как нами были найдены тем или иным способом коэффициенты регрессии можно приступать к вычислению прогнозных значений Y на основе заданных значений переменных Х.
Уравнение прогнозирования или уравнение регрессии в случае 2-х независимых переменных (регрессоров) записывается в виде:
Примечание: В MS EXCEL прогнозное значение Y для заданных Х 1 и Х 2 можно также предсказать с помощью функции ТЕНДЕНЦИЯ() . При этом 2-й аргумент будет ссылкой на столбцы, содержащие все значения переменных Х 1 и Х 2 , а 3-й аргумент функции должен быть ссылкой на диапазон ячеек, содержащий 2 значения Х (Х 1i и Х 2i ) для выбранного наблюдения i (см. файл примера, лист Коэффициенты, столбец G ). Функция ПРЕДСКАЗ() , использованная нами в простой регрессии, не работает в случае множественной регрессии .
Найдя прогнозное значение Y, мы, таким образом, вычислим его точечную оценку. Понятно, что фактическое значение Y, полученное при наблюдении, будет, скорее всего, отличаться от этой оценки. Чтобы ответить на вопрос о том, на сколько хорошо мы можем предсказывать новые значения Y, нам потребуется построить доверительный интервал этой оценки, т.е. диапазон в котором с определенной заданной вероятностью, скажем 95%, мы ожидаем новое значение Y.
Доверительные интервалы построим при фиксированном Х для:
- нового наблюдения Y;
- среднего значения Y (интервал будет уже, чем для отдельного нового наблюдения)
Как и в случае простой линейной регрессии , для построения доверительных интервалов нам потребуется сначала вычислить стандартную ошибку модели (standard error of the model) , которая приблизительно показывает насколько велика ошибка предсказания значений переменной Y на основании значений переменных Х.
Для вычисления стандартной ошибки оценивают дисперсию ошибки ε, т.е. сигма^2 (ее часто обозначают как MS Е либо MSres ) . Затем, вычислив из полученной оценки квадратный корень, получим Стандартную ошибку регрессии (часто обозначают как SEy или sey ).
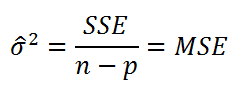
где SSE – сумма квадратов значений ошибок модели ei=yi — ŷi ( Sum of Squared Errors ). MSE означает Mean Square of Errors (среднее квадратов ошибок, точнее остатков).
Величина n-p – это количество степеней свободы ( df – degrees of freedom ), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y, р – количество оцениваемых параметров модели). В случае простой множественной регрессии с 2-мя регрессорами число степеней свободы равно n-3, т.к. при построении плоскости регрессии было оценено 3 параметра модели b (т.е. на это было «потрачено» 3 степени свободы ).
В MS EXCEL стандартную ошибку SEy можно вычислить формулы (см. файл примера, лист Статистика ):
Стандартная ошибка нового наблюдения Y при заданных значениях Х (вектор Хi) вычисляется по формуле:
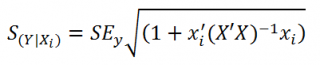
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
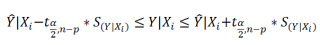
где α (альфа) – уровень значимости (обычно принимают равным 0,05=5%)
р – количество оцениваемых параметров модели (в нашем случае = 3)
n-p – число степеней свободы
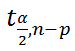 – квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
– квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
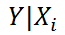 – прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
– прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
Стандартная ошибка среднего значения Y при заданных значениях Х (вектор Хi) будет меньше, чем стандартная ошибка отдельного наблюдения. Вычисления производятся по формуле:
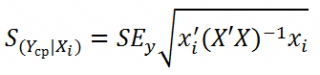
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
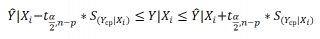
Прогнозное значение Yi (точечная оценка) используется тоже, что и для отдельного наблюдения.
Стандартные ошибки и доверительные интервалы для коэффициентов регрессии
В разделе Оценка неизвестных параметров мы получили точечные оценки коэффициентов регрессии . Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со средним значением и дисперсией . Но, чтобы перейти от точечных оценок к интервальным , необходимо вычислить соответствующие стандартные ошибки (т.е. стандартные отклонения ) коэффициентов регрессии .
Стандартная ошибка коэффициента регрессии b j (обозначается se ( b j ) ) вычисляется на основании стандартной ошибки по следующей формуле:
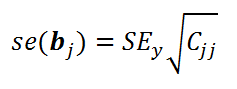
где C jj является диагональным элементом матрицы (X ’ X) -1 . Для коэффициента сдвига b 0 индекс j=1 (верхний левый элемент), для b 1 индекс j=2, b 2 индекс j=3 (нижний правый элемент).
SEy – стандартная ошибка регрессии (см. выше ).
В MS EXCEL стандартные ошибки коэффициентов регрессии можно вычислить с помощью функции ЛИНЕЙН() :
Примечание : Подробнее о функции ЛИНЕЙН() см. статью Функция MS EXCEL ЛИНЕЙН() .
Применяя матричный подход стандартные ошибки можно вычислить и через обычные формулы (точнее через формулу массива , см. файл примера лист Статистика ):
= КОРЕНЬ(СУММКВРАЗН(E13:E43;F13:F43) /(n-p)) *КОРЕНЬ (ИНДЕКС (МОБР (МУМНОЖ(ТРАНСП(B13:D43);(B13:D43)));j;j))
При построении двухстороннего доверительного интервала для коэффициента регрессии его границы определяются следующим образом:
где t – это t-значение , которое можно вычислить с помощью формулы = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) для уровня значимости 0,05.
В результате получим, что найденный доверительный интервал с вероятностью 95% (1-0,05) накроет истинное значение коэффициента регрессии b j . Здесь мы считаем, что коэффициент регрессии b j имеет распределение Стьюдента с n-p степенями свободы (n – количество наблюдений, т.е. пар Х и Y).
Проверка гипотез
Когда мы строим модель, мы предполагаем, что между Y и переменными X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X, возможен, когда все коэффициенты регрессии β равны 0.
Чтобы убедиться, что вычисленная нами оценка коэффициентов регрессии не обусловлена лишь случайностью (они не случайно отличны от 0), используют проверку гипотез . В качестве нулевой гипотезы Н 0 принимают, что линейной связи нет, т.е. ВСЕ β=0. В качестве альтернативной гипотезы Н 1 принимают, что ХОТЯ БЫ ОДИН коэффициент β <>0.
Процедура проверки значимости множественной регрессии, приведенная ниже, является обобщением дисперсионного анализа , использованного нами в случае простой линейной регрессии (F-тест) .
Если нулевая гипотеза справедлива, то тестовая F -статистика имеет F-распределение со степенями свободы k и n — k -1 , т.е. F k, n-k-1 :
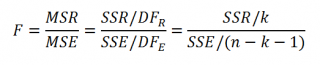
Проверку значимости регрессии можно также осуществить через вычисление p -значения . В этом случае вычисляют вероятность того, что случайная величина F примет значение F 0 (это и есть p-значение ), затем сравнивают p-значение с заданным уровнем значимости α (альфа) . Если p-значение больше уровня значимости , то нулевую гипотезу нет оснований отклонить, и регрессия незначима.
В MS EXCEL значение F 0 можно вычислить на основании значений выборки по вышеуказанной формуле или с помощью функции ЛИНЕЙН() :
В MS EXCEL для проверки гипотезы через p -значение используйте формулу =F.РАСП.ПХ(F 0 ;k;n-k-1) файл примера лист Статистика , где показано эквивалентность обоих подходов проверки значимости регрессии).
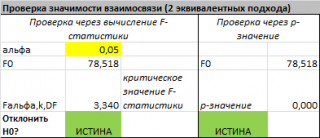
В MS EXCEL критическое значение для заданного уровня значимости F 1-альфа, k, n-k-1 можно вычислить по формуле = F.ОБР(1- альфа;k;n-k-1) или = F.ОБР.ПХ(альфа;k; n-k-1) . Другими словами требуется вычислить верхний альфа- квантиль F -распределения с соответствующими степенями свободы .
Таким образом, при значении статистики F 0 > F 1-альфа, k, n-k-1 мы имеем основание для отклонения нулевой гипотезы.
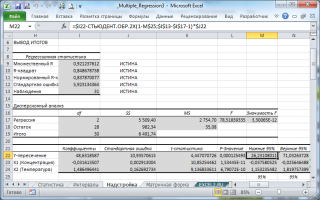
В программах статистики результаты процедуры F -теста выводят с помощью стандартной таблицы дисперсионного анализа . В файле примера такая таблица приведена на листе Надстройка , которая построена на основе результатов, возвращаемых инструментом Регрессия надстройки Пакета анализа MS EXCEL .
Генерация данных для множественной регрессии с помощью заданного тренда
Иногда, бывает удобно сгенерировать значения наблюдений, имея заданный тренд.
Для решения этой задачи нам потребуется:
- задать значения регрессоров в нужном диапазоне (значения переменных Х);
- задать коэффициенты регрессии ( b );
- задать тренд (вычислить значения Y= b0 +b1 * Х 1 + b2 * Х 2 );
- задать величину разброса Y вокруг тренда (варианты: случайный разброс в заданных границах или заданная фигура, например, круг)
Все вычисления выполнены в файле примера, лист Тренд для случая 2-х регрессоров. Там же построены диаграммы рассеяния .
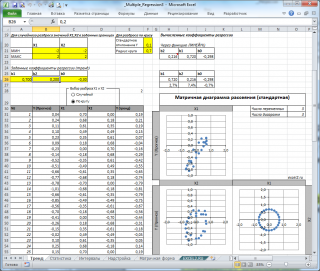
Коэффициент детерминации
Коэффициент детерминации R 2 показывает насколько полезна построенная нами линейная регрессионная модель .
По определению коэффициент детерминации R 2 равен:
R 2 = Изменчивость объясненная моделью ( SSR ) / Общая изменчивость ( SST ).
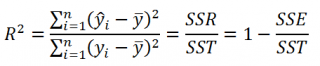
Этот показатель можно вычислить с помощью функции ЛИНЕЙН() :
При добавлении в модель новой объясняющей переменной Х, коэффициент детерминации будет всегда расти. Поэтому, рост коэффициента детерминации не может служить основанием для вывода о том, что новая модель (с дополнительным регрессором) лучше прежней.
Более подходящей статистикой, которая лишена указанного недостатка, является нормированный коэффициент детерминации (Adjusted R-squared):
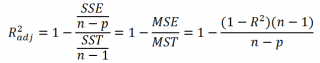
где p – число независимых регрессоров (вычисления см. файл примера лист Статистика ).
http://megaobuchalka.ru/7/5031.html
http://excel2.ru/articles/mnozhestvennaya-regressiya-v-ms-excel