
Все ошибки
подразделяются, во-первых, на ошибки
регистрации, которые свойственны любому
наблюдению (не только выборочному, но
и сплошному) и возникают по вине
наблюдателя и по вине отвечающего.
Во-вторых, на ошибки репрезентативности
свойственные только выборочному
наблюдению и представляющие собой
величину возможных расхождений между
показателями выборочной и генеральной
совокупностями. Ошибки репрезентативности
могут быть систематическими — из-за
неправильного, с нарушением научного
принципа случайности, отбора единиц. И
случайными – зависят от степени
однородности совокупности и от объема
выборки; возникают даже в том случае,
если систематические ошибки
репрезентативности устранены.
Предельная ошибка
рассчитывается по формуле:
для средней ∆x=tμx;
для доли ∆p=tμp
, где t
– коэффициент кратности (доверия), а μ
– средняя ошибка.
Коэффициент
кратности по размеру (величине) зависит
от заданной вероятности, с которой
гарантируется результат и в этой связи
берется по специальным таблицам.
В экономических
расчетах чаще всего используются
сочетания: доверительная вероятность
р=0,95 t=1,96,
р=0,954 t=2,0,
р=0,997 t=3,0.
Средняя ошибка
для:

S2
– выборочная дисперсия (дисперсия
признака выборочной совокупности)
n
– объем выборочной совокупности (число
единиц, попавших в выборку)
N
– объем генеральной совокупности (число
единиц, входящих в генеральную
совокупность.
Кроме того, в рамках
выборочного наблюдения можно определять
необходимый объем выборки, который с
практической вероятностью обеспечивает
заданную точность выборки:

15. Доверительный интервал и его исчисление.
Прежде всего
выборочное наблюдение дает возможность
определить среднюю арифметическую
выборочной совокупности и величину
предельной ошибки этой средней, которая
показывает (с определенной вероятностью)
на сколько выборочная средняя может
отличаться от генеральной средней в
большую и меньшую стороны.
Тогда величина
искомой генеральной средней находится
в доверительном интервале:
 ,
,
где
х – среднее значение
признака выборочной совокупности,
∆x
– предельная
ошибка средней
х – генеральная
средняя (среднее значение признака в
генеральной совокупности)
Аналогичным образом
для доли величина генеральной доли
находится в доверительном интервале:
w-∆р
≤ р ≤ w+∆р
w
– выборочна доля (доля единиц)
∆р –
предельная ошибка доли
р — генеральная
доля (доля единиц, обладающих данным
признаком в генеральной совокупности).
16. Корреляционная зависимость и методы ее выявления.
В зависимостях
одни признаки (факторные) выступают в
качестве причин, обусловливающих
изменение других признаков (результативных).
Вообще зависимости
между признаками бывают либо функциональными
(полное соответствие между изменениями
факторного признака и изменениями
результативной величины), либо
корреляционными (нет полного соответствия,
и воздействие отдельных факторов
проявляется лишь в среднем при массовом
наблюдении факторных данных).
Корреляционная
связь – это такая связь, которая
проявляется не в каждом отдельном
случае, а в массе случаев в средних
величинах в форме тенденции.
Статистическое
исследование такой связи ставит своей
конечной целью получение модели
корреляционной зависимости для ее
практического использования.
Основной задачей
корреляционного метода является
определение по данным большого числа
наблюдений того, как с изменением
факторного признака при прочих равных
условиях меняется среднее значение
результативного признака. Эта задача
решается путем определения формы связи
и нахождения уравнения этой связи двух
или нескольких переменных.
Такая работа
осуществляется в несколько этапов: 1.
проводится логический анализ сущности
изучаемого явления и причинно-следственных
связей. В результате устанавливаются
результативный показатель (у) и факторы
его изменения (х1,
х2,
…, хn).
Связь только двух признаков у и х
называется парной корреляцией. Корреляция
бывает множественной, если на результативный
признак влияют несколько факторов. При
этом по общему направлению связи бывают
прямыми (с увеличением признака х
увеличивается и признак у) и обратными
(наоборот); 2.
устанавливается сам факт наличия и
направления корреляционной зависимости
(КЗ) между результативным и факторным
признаками. Для выявления КС либо строят
таблицу: сверху вниз по нарастающей –
значения фактора, слева направо по
нарастающей – значения результативного
признака; тогда если частоты повторения
данного сочетания факторного и
результативного признаков концентрируются
от сверху слева до вниз направо корреляция
предполагается. Либо по методу
аналитической группировки и определения
групповых средних все единицы совокупности
разбиваются на группы по величине
факторного признака и для каждой группы
определяется средняя величина
результативного признака; по этим данным
стоится график эмпирической линии связи
(линии регрессии), вид которой не только
позволяет судить о возможном наличии
связи, но и дает некоторое представление
о ее форме. 3.
измеряется степень тесноты и проводится
оценка существенности КС. Для определения
степени тесноты парной линейной
зависимости служит линейной коэффициент
корреляции:
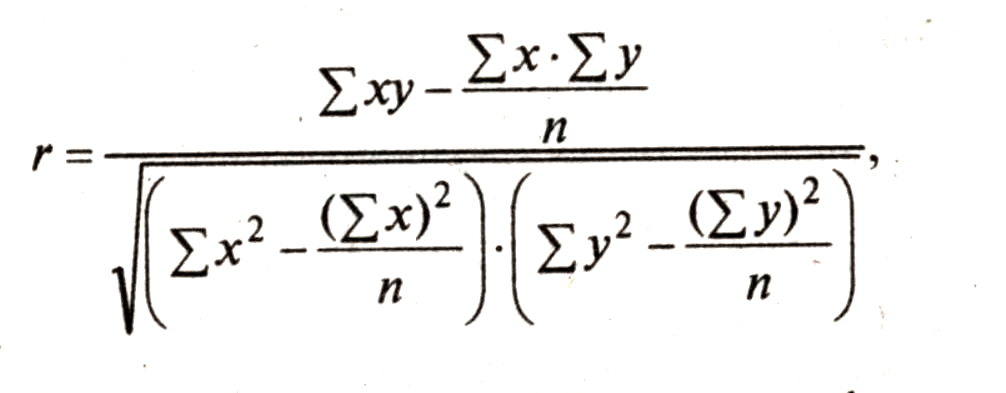
Чем ближе значение
линейного коэффициента К (изменяется
от «-» до «+» 1) по абсолютной величине к
единице, тем связь теснее. Знак при нем
указывает направление связи: «+» —
соответствует прямой зависимости, а
«-» — обратной. 4.
после установления достаточной степени
тесноты связи выполняется построение
модели связи (уравнения регрессии).
Соседние файлы в папке Статистика
- #
- #
- #
- #
- #
- #
- #
- #
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.
Выборка. Типы выборок
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей
- Аналитика бизнеса
- Методы анализа данных Data Mining
- Выборка. Типы выборок
Оглавление
Генеральная совокупность
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей
- Все жители Москвы (10,6 млн. человек по данным переписи 2002 года)
- Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года)
- Юридические лица России (2,2 млн. на начало 2005 года)
- Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и т.д.
Выборка (Выборочная совокупность)
Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на всю генеральную совокупность, выборка должна обладать свойством репрезентативности.
Репрезентативность выборки
Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и нерепрезентативной для разных генеральных совокупностей.
Пример:
- Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население Москвы.
- Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России.
- Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.
В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках соответственно.
Важно понимать, что репрезентативность выборки и ошибка выборки – разные явления. Репрезентативность, в отличие от ошибки никак не зависит от размера выборки.
Пример:
Как бы мы не увеличивали количество опрошенных москвичей-автовладельцев, мы не сможем репрезентировать этой выборкой всех москвичей.
Ошибка выборки (доверительный интервал)
Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
Ошибка выборки бывает двух видов – статистическая и систематическая. Статистическая ошибка зависит от размера выборки. Чем больше размер выборки, тем она ниже.
Пример:
Для простой случайной выборки размером 400 единиц максимальная статистическая ошибка (с 95% доверительной вероятностью) составляет 5%, для выборки в 600 единиц – 4%, для выборки в 1100 единиц – 3% Обычно, когда говорят об ошибке выборки, подразумевают именно статистическую ошибку.
Систематическая ошибка зависит от различных факторов, оказывающих постоянное воздействие на исследование и смещающих результаты исследования в определенную сторону.
Пример:
- Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни. Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например, дома).
- Проблема респондентов, отказывающихся отвечать на вопросы анкеты (доля «отказников» в Москве, для разных опросов, колеблется от 50% до 80%)
В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично.
Типы выборок
Выборки делятся на два типа:
- вероятностные
- невероятностные
Вероятностные выборки
1.1 Случайная выборка (простой случайный отбор)
Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов, наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел.
1.2 Механическая (систематическая) выборка
Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом ‘n’ отбирается каждый ‘k’-ый элемент. Размер генеральной совокупности, при этом – N=n*k
1.3 Стратифицированная (районированная)
Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы (страты). В каждой страте отбор осуществляется случайным или механическим образом.
1.4 Серийная (гнездовая или кластерная) выборка
При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнёзда). Группы отбираются случайным образом. Объекты внутри групп обследуются сплошняком.
2.Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности, типичности, равного представительства и т.д..
2.1. Квотная выборка
Изначально выделяется некоторое количество групп объектов (например, мужчины в возрасте 20-30 лет, 31-45 лет и 46-60 лет; лица с доходом до 30 тысяч рублей, с доходом от 30 до 60 тысяч рублей и с доходом свыше 60 тысяч рублей) Для каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны попасть в каждую из групп, задается, чаще всего, либо пропорционально заранее известной доле группы в генеральной совокупности, либо одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки используются в маркетинговых исследованиях достаточно часто.
2.2. Метод снежного кома
Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег, знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход, респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения и т.д.)
2.3 Стихийная выборка
Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок – опросы в газетах/журналах, анкеты, отданные респондентам на самозаполнение, большинство интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром – активностью респондентов.
2.4 Выборка типичных случаев
Отбираются единицы генеральной совокупности, обладающие средним (типичным) значением признака. При этом возникает проблема выбора признака и определения его типичного значения.
Почитать еще



Машинное обучение
Глубокое обучение – это продвинутая форма машинного обучения. Глубокое обучение относится к способности компьютерных систем, известных


Выборка. Типы выборок
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков


Обзор основных видов сегментации
Загрузить программу ВІ Демонстрации решений Аналитика бизнеса Оглавление Сегментация бренда Сегментация помогает принимать более эффективные


Несколько видео о наших продуктах

Проиграть видео
Презентация аналитической платформы Tibco Spotfire

Проиграть видео
Отличительные особенности Tibco Spotfire 10X

Проиграть видео
Как аналитика данных помогает менеджерам компании
Согласно теории выборочного метода, неоднократно подтвержденной практикой, опрашивать всех нет необходимости, а можно опросить лишь часть группы, которая может быть в тысячи раз меньше. Эта маленькая часть называется выборкой (или выборочной совокупностью), а большая группа, которую она представляет, называется генеральной совокупностью.
При этом если выборка сформирована правильно, выводы, полученные на основе изучения выборки, могут быть перенесены и на генеральную совокупность. Например, если в выборке женщины значимо чаще, чем мужчины, пользуются дезодорантами, то делается вывод, что и в генеральной совокупности (например, в исследованном городе) присутствует такая закономерность.
Процесс переноса выводов с выборки на генеральную совокупность называется генерализацией. А свойство выборки отражать характеристики генеральной совокупности называется репрезентативностью. Для более комфортного запоминания термина на рис.1.
приведены иллюстрации, когда выборка отражает свойства генеральной совокупности и когда свойства выборки отличаются от свойств генеральной совокупности.



Рис.1. Иллюстративные примеры соответствия (несоответствия) свойств генеральной совокупности и выборки
Не стоит путать понятие репрезентативности с такими понятиями как валидность и релевантность, хотя они тоже относятся к характеристикам качества исследования. В социальных науках валидность понимается довольно широко, но чаще всего – как обоснованность.
Понятие валидности относится не к выборке, а к исследовательской методике. Методика или измерение (анкета, блок вопросов, тест) считается валидным, если фиксирует именно то понятие или свойство, которое планируется измерить.
Например, если мы захотим оценить уровень лояльности клиента к магазину и выберем для этого лишь показатель частоты посещения магазина, валидность этого подхода будет неполной: возможно, респондент часто заходит в магазин только из-за банкомата, который там установлен.
Валидная методика в данном примере должна включать и другие показатели: предпочтение магазина, суммы покупок в этом и других магазинах, готовность переключиться на другие магазины, готовность рекомендовать магазин и др.
При установлении валидности решающую роль играет обоснование и последующая проверка гипотезы релевантности, то есть соответствия измеряемых параметров характеристикам исследуемого объекта.
Житейский пример нерелевантности – измерять уровень счастья человека количеством денег у него (хотя, наверное, не все с этим согласятся).
Очевидный пример нерелевантности – попытка измерить массу тела по его температуре.
Но вернемся к понятию репрезентативности. В то время как точность измерений зависит от размера выборки, размер выборки не гарантирует ее репрезентативности.
Репрезентативность выборки главным образом обеспечивается способом отбора ее участников (респондентов).
Примером явного нарушения репрезентативности может послужить шутка о том, что интернет-опрос показал, что 100% людей пользуется интернетом.
Можно выделить несколько вариантов нарушения репрезентативности выборки: когда опрошены не те люди и когда опрошено слишком много (или мало) определенных людей (например, женщин намного больше, чем мужчин). Кроме того, чем меньше размер выборки, тем меньше вероятность того, что она будет репрезентативной. Например, допустим, 1% населения мог бы заинтересоваться новой услугой.
Это 1 из 100 людей. Если размер выборки составляет всего 60 человек, то в вашей выборке может отсутствовать человек, который, скорее всего, будет заинтересован в услуге. Ваша выборка менее репрезентативна, потому что она меньше. Ваши результаты будут разными в зависимости от того, содержит ли ваша выборка одного из этих людей или нет.
Пример репрезентативной и нерепрезентативной выборки показан на рис.2.

Рис.2. Пример репрезентативной и нерепрезентативной выборки
На рис.3 показана та же по составу генеральная совокупность, но с другим расположением объектов внутри круга.

Рис.3. Пример репрезентативной и нерепрезентативной выборки при другом расположении объектов генеральной совокупности
Говоря простым языком, репрезентативная выборка – это такая выборка, в которой представлены все подгруппы, важные для исследования. Помимо этого, характер распределения рассматриваемых параметров в выборке должен быть таким же, как в генеральной совокупности.
Простой случайный отбор респондентов представляется оптимальным способом формирования репрезентативной выборки.
Поскольку в этом случае у любого представителя генеральной совокупности одинаковая вероятность попасть в выборку, в нее попадут люди с разными характеристиками пропорционально их долям в генеральной совокупности.
В итоге выборка будет представлять собой нечто вроде уменьшенной копии генеральной совокупности.
Случайность отбора респондентов в выборку обеспечивается разными способами.
Например, для телефонного опроса жителей города берется база данных всех телефонных номеров, и номера респондентов случайным образом выбираются компьютером (с использованием генератора случайных чисел).
При уличном опросе интервьюеров распределяют по случайно выбранным точкам и инструктируют опрашивать каждого N-ного прохожего.
Наглядным примером репрезентативной выборки может служить пицца. Если целая пицца – это генеральная совокупность, которую мы хотим изучить, то кусок пиццы – это выборка.
Как правило, достаточно одного куска пиццы, чтобы судить обо всей пицце (при условии, что ингредиенты равномерно распределены по ее поверхности). Таким образом, кусок пиццы пиццы на рис.
4 – это репрезентативная выборка из пиццы.

Рис.4. Наглядный пример репрезентативной выборки (пицца)
Важно отметить, что не любой кусок пиццы будет репрезентативной выборкой. Разные способы получения куска пиццы могут принципиально повлиять на качество исследования и выводы, которые будут получены при анализе каждого варианта выборки (рис.4)
(рисунок в сушильной камере, готовится к публикации)
Рис.5. Наглядный пример формирования репрезентативной и нерепрезентативной выборки.
Еще один показательный пример формирования репрезентативной выборки – кастрюля, содержимое которой мы должны узнать (допустим, там скрывается борщ). Мы только один раз можем зачерпнуть из кастрюли ложкой (провести исследование). В нашем примере ложка – это выборка, а содержимое кастрюли – генеральная совокупность.
Если мы зачерпнем сверху, то придем к выводу, что в кастрюле бульон. Если снизу – решим, что в кастрюле мясо. Зачерпнув где-то посередине, мы получим картошку или капусту. В любом из трех случаев выводы будут неверны.
Чтобы получить достоверный результат, нам стоит хорошенько перемешать содержимое кастрюли, перед тем как пробовать его.
Перемешивание в данном случае – аналог процедуры простого случайного отбора, поскольку оно предоставляет всем ингредиентам примерно равную вероятность попадания в ложку-выборку (или тарелку-выборку).

Рис.6. Борщ как модель, демонстрирующая репрезентативность выборки.
В реальности применить простой случайный отбор респондентов не всегда удается в полной мере. Например, мы можем абсолютно корректно отобрать в выборку нужное количество номеров домашних телефонов случайным образом, но при их прозвоне выяснится, что дозвониться и поговорить удается преимущественно с пенсионерами, а «поймать» дома молодежь и работающих людей получается плохо.
Возвращаясь к примеру с борщом, если у нас вместо кастрюли – огромный ресторанный котел, а в руках все та же обычная ложка, перемешивание будет неэффективным. Чтобы решить задачу, потребуются иные подходы.
Например, мы можем теоретически разделить глубину котла на несколько слоев и постараться зачерпнуть содержимое из каждого слоя (из случайного места слоя: не только в центре, но и по краям). Таким образом, наша итоговая выборка будет состоять уже из нескольких выборок и при этом адекватно отражать содержимое всех слоев котла.
Подобные альтернативные подходы называются типами выборки, которых придумано достаточно много для того, чтобы максимизировать репрезентативность выборки в сложных условиях реального мира.
Последствия нарушения репрезентативности выборки: некорректные выводы исследования, выброшенный на ветер бюджет исследования, финансовые потери вследствие применения неправильных выводов.
Вы можете выбрать валидную исследовательскую методику, рассчитать объем выборки, обеспечивающий приемлемую точность измерений, но, если выборка исследования нерепрезентативна, получить достоверную информацию не удастся.
- ПРИМЕРЫ НАРУШЕНИЯ РЕПРЕЗЕНТАТИВНОСТИ ВЫБОРКИ
- ПРЕДВЫБОРНЫЙ ОПРОС
- Самым известным примером нарушения репрезентативности выборки является история провала американского журнала «Литературный дайджест».
В 1936 году журнал в очередной раз провел почтовый опрос общественного мнения о вероятных результатах грядущих президентских выборов в США. До 1936 года опрос всегда правильно предсказывал победителя. Опрос 1936 года показал, что победителем с большим отрывом станет кандидат от республиканцев, но в итоге победителем оказался представитель демократов.
Таким образом, гигантская выборка (около 2,4 млн. человек) не обеспечила достоверных результатов. В чем же заключалась причина ошибки?
Называются две основные причины провала: смещение при формировании выборки и смещение вследствие отказа респондентов от участия в опросе.
Прежде всего, журнал включил своих подписчиков в список для рассылки анкет и, желая расширить выборку, использовал два других доступных тогда списка граждан: зарегистрированных автовладельцев и пользователей телефонов.
Во времена Великой Депрессии представители этих групп отличались от остального населения более высоким доходом, как и подписчики самого журнала.
Таким образом, полученная база для рассылки не являлась корректным отражением структуры населения США.
Вторая проблема с опросом заключалась в том, что из 10 миллионов человек, чьи имена были в первоначальном списке рассылки, только 2,4 миллиона ответили на опрос. Вероятно, высокий процент отказов был связан с тем, что опрос проводился по почте.
Уже в те времена американцы относились к почтовым рассылкам как к спаму. Таким образом, размер выборки составил примерно одну четверть от того, что первоначально планировалось.
Когда доля ответивших низка (как это было в данном случае), считается, что исследование страдает от необъективности ответов.
У этой истории две морали: Большая, но неправильно сформированная выборка гораздо хуже маленькой, но правильно сформированной выборки. При проведении опроса не упускайте из внимания смещение отбора и смещение в результате отказов.
СИСТЕМАТИЧЕСКАЯ ОШИБКА ВЫЖИВШЕГО
Пример из военной практики. Во Вторую мировую войну американские военные столкнулись со следующей проблемой. Не все американские бомбардировщики после задания возвращались на базу.
На вернувшихся самолетах оставалось множество пробоин от выстрелов противника, но распределены они были неравномерно: больше всего на фюзеляже и прочих частях, меньше в топливной системе и гораздо меньше — в двигателе.
Командованию казалось логичным, что в наиболее поврежденных местах нужно установить больше брони. Привлеченный к решению задачи математик возразил: данные как раз показывают, что самолет, получивший пробоины в этих местах, еще может вернуться на базу.
А самолет, которому попали в бензобак или двигатель, выходит из строя и не возвращается. Поэтому укреплять следует те места, которые у вернувшихся самолетов повреждены меньше всего.

Рис .7. Пробоины на вернувшихся самолётах. Получившие повреждения в других местах не смогли вернуться на базу
Эта задача служит примером нарушения репрезентативности выборки, когда в нее включены не те респонденты: в данном случае, вернувшиеся самолеты, в то время как не вернувшиеся проигнорированы.
Применительно к маркетинговым исследованиям, эта ситуация подобна следующей. При опросе клиентов бизнеса будет ошибкой опрашивать только текущих клиентов и не опрашивать потерянных клиентов (а какие «пробоины» получили они?).
НЕПРАВИЛЬНЫЕ МЕСТА ОПРОСА
При опросе посетителей ТРЦ важно правильно расставить интервьюеров. Например, если поставить интервьюеров только у главного входа, в выборку не попадут посетители, приехавшие в ТРЦ на автомобиле и попавшие в него через парковку.
Как следствие, выводы, полученные на собранных данных, будут корректны только для той части посетителей, которые приходят в ТРЦ пешком, а значит, делают меньше покупок, не покупают габаритные товары, живут ближе к ТРЦ, чем приезжающие на автомобиле.
ОТСУТСТВИЕ КВОТИРОВАНИЯ
Другой пример. Бывает, что в разных районах города сбор анкет идет с разной скоростью: где-то (например, в центре города) большой пешеходный поток и у людей есть время на участие в опросе (отдыхающие, в отпуске, офисные сотрудники на обеде), а на окраинах либо мало людей на улицах, либо все спешат на работу и отказываются участвовать.
В результате, если не ограничивать доли районов, в выборке будут преобладать люди из центрального района, которые могут значимо отличаться от остальных людей родом занятий, уровнем дохода и образования, уровнем осведомленности о магазинах и др.
Таким образом, собранная выборка уже не будет репрезентативной по отношению к населению всего города.
ОНЛАЙН-ОПРОСЫ (ОНЛАЙН-ПАНЕЛИ)
Несмотря на многие положительные стороны онлайн-опросов, такие как экономичность, оперативность сбора информации, удобство ее обработки и т. д., некоторые их особенности напрямую угрожают репрезентативности исследования:
- Во-первых, участники онлайн-опросов – это, как правило, активные пользователи интернета, хорошо в нем разбирающиеся и больше подверженные влиянию интернет-культуры, чем обычные люди.
- Во-вторых, люди, у которых есть время и желание регулярно участвовать в онлайн-опросах за небольшое вознаграждение, скорее всего, значительно отличаются от остальных людей как по социально-демографическим, так и по психографическим характеристикам.
- В-третьих, профессиональное участие в опросах приводит к так называемой профессиональной деформации, когда ответы респондентов на вопросы новых исследований обусловлены предыдущим опытом, но не жизненным, а опытом участия в других опросах.
- Таким образом, в данном случае возникает та ситуация, когда опрашиваются не те люди, хотя по формальным характеристикам они подходят под описание целевой аудитории.
- ВЫВОДЫ
- Итак, чтобы получить достаточно точные данные об интересующей нас группе людей, необязательно опрашивать их всех, благодаря свойству репрезентативности выборки.
- «Чем больше, тем лучше» – неправильный подход к формированию выборки.
Небольшая репрезентативная выборка лучше большой, но нерепрезентативной выборки. Применительно к выборке не стоит пугаться слова «случайная». Это вовсе не значит, что в исследовании будут получены случайные результаты. Напротив, случайный подход к формированию выборки делает ее максимально похожей на генеральную совокупность, а значит, репрезентативной.
При проектировании выборки следует учитывать опасность смещения структуры выборки вследствие особенностей сбора информации и других условий.
Источник: https://scanmarket.ru/blog/reprezentativnost-vyborki
Ошибки выборки
Чтобы оценить степень точности выборочного наблюдения, необходимо оценить величину ошибок, которые могут возникнуть в процессе проведения выборочного наблюдения.

Статистическое исследование может осуществляться по данным несплошного наблюдения, основная цель которого состоит в получении характеристик изучаемой совокупности по обследованной ее части. Одним из наиболее распространенных в статистике методов, применяющих несплошное наблюдение, является выборочный метод.
Под выборочным понимается метод статистического исследования, при котором обобщающие показатели изучаемой совокупности устанавливаются по некоторой ее части на основе положений случайного отбора.
При выборочном методе обследованию подвергается сравнительно небольшая часть всей изучаемой совокупности (обычно до 5 — 10%, реже до 15 — 25%). При этом подлежащая изучению статистическая совокупность, из которой производится отбор части единиц, называется генеральной совокупностью.
Отобранная из генеральной совокупности некоторая часть единиц, подвергающаяся обследованию, называется выборочной совокупностью
или просто выборкой.
Значение выборочного метода состоит в том, что при минимальной численности обследуемых единиц проведение исследования осуществляется в более короткие сроки и с минимальными затратами труда и средств. Это повышает оперативность статистической информации, уменьшает ошибки регистрации.
В проведении ряда исследований выборочный метод является единственно возможным, например, при контроле качества продукции (товара), если проверка сопровождается уничтожением или разложением на составные части обследуемых образцов (определение сахаристости фруктов, клейковины печеного хлеба, установление носкости обуви, прочности тканей на разрыв и т.д.).
- Проведение исследования социально — экономических явлений выборочным методом складывается из ряда последовательных этапов:
- 1) обоснование (в соответствии с задачами исследования) целесообразности применения выборочного метода;
- 2) составление программы проведения статистического исследования выборочным методом;
- 3) решение организационных вопросов сбора и обработки исходной информации;
4) установление доли выборки, т.е. части подлежащих обследованию единиц генеральной совокупности;
- 5) обоснование способов формирования выборочной совокупности;
- 6) осуществление отбора единиц из генеральной совокупности для их обследования;
- 7) фиксация в отобранных единицах (пробах) изучаемых признаков;
-
 статистическая обработка полученной в выборке информации с определением обобщающих характеристик изучаемых признаков;
статистическая обработка полученной в выборке информации с определением обобщающих характеристик изучаемых признаков; - 9) определение количественной оценки ошибки выборки;
- 10) распространение обобщающих выборочных характеристик на генеральную совокупность.
- В генеральной совокупности доля единиц, обладающих изучаемым признаком, называется генеральной долей (обозначается р), а средняя величина изучаемого варьирующего признака — генеральной средней (обозначается ).
- В выборочной совокупности долю изучаемого признака называют выборочной долей, или частостью (обозначается ), а среднюю величину в выборке — выборочной средней (обозначается ).
- Пример.
 статистическая обработка полученной в выборке информации с определением обобщающих характеристик изучаемых признаков;
статистическая обработка полученной в выборке информации с определением обобщающих характеристик изучаемых признаков;При контрольной проверке качества хлебобулочных изделий проведено 5%-ное выборочное обследование партии нарезных батонов из муки высшего сорта. При этом из 100 отобранных в выборку батонов 90 шт. соответствовали требованиям стандарта. Средний вес одного батона в выборке составлял 500,5 г при среднем квадратическом отклонении г.
- На основе полученных в выборке данных нужно установить возможные значения доли стандартных изделий и среднего веса одного изделия во всей партии.
- Прежде всего устанавливаются характеристики выборочной совокупности. Выборочная доля, или частость, определяется из отношения единиц, обладающих изучаемым признаком m, к общей численности единиц выборочной совокупности n:
Поскольку из 100 изделий, попавших в выборку n, 90 ед. оказались стандартными m, то показатель частости равен: = 90:100=0,9.
Средний вес изделия в выборке х = 500,5 г определен взвешиванием. Но полученные показатели частости (0,9) и средней величины (500,5 г) характеризуют долю стандартной продукции и средний вес одного изделия лишь в выборке. Дляопределения соответствующих показателей для всей партии товара надо установить возможные при этом значения ошибки выборки.
Ошибка выборки — это объективно возникающее расхождение между характеристиками выборки и генеральной совокупности. Она зависит от ряда факторов: степени вариации изучаемого признака, численности выборки, методом отбора единиц в выборочную совокупность, принятого уровня достоверности результата исследования.
- Определение ошибки выборочной средней.
- При случайном повторном отборе средняя ошибка выборочной средней рассчитывается по формуле:
- ,
- где — средняя ошибка выборочной средней;
- — дисперсия выборочной совокупности;
- n — численность выборки.
- При бесповторном отборе она рассчитывается по формуле:
 ,
,- где N — численность генеральной совокупности.
- Определение ошибки выборочной доли.
- При повторном отборе средняя ошибка выборочной доли рассчитывается по формуле:
 ,
,- где — выборочная доля единиц, обладающих изучаемым признаком;
- — число единиц, обладающих изучаемым признаком;
- — численность выборки.
- При бесповторном способе отбора средняя ошибка выборочной доли определяется по формулам:

- Предельная ошибка выборки связана со средней ошибкой выборки отношением:
- .
- При этом t как коэффициент кратности средней ошибки выборки зависит от значения вероятности Р, с которой гарантируется величина предельной ошибки выборки.
- Предельная ошибка выборки при бесповторном отборе определяется по следующим формулам:


Предельная ошибка выборки при повторном отборе определяется по формуле:
![]()
.
Источник: https://www.ekonomstat.ru/lektsii-po-distsipline-statistika/36-obshhaja-teorija-statistiki-lekcii/834-oshibki-vyborki.html
116. Ошибка репрезентативности, методика вычисления ошибки средней и относительной величины
В статистике выделяют два основных метода исследования – сплошной и выборочный. При проведении выборочного исследования обязательным является соблюдение следующих требований: репрезентативность выборочной совокупности и достаточное число единиц наблюдений.
При выборе единиц наблюдения возможны Ошибки смещения, т. е. такие события, появление которых не может быть точно предсказуемым. Эти ошибки являются объективными и закономерными.
При определении степени точности выборочного исследования оценивается величина ошибки, которая может произойти в процессе выборки – Случайная ошибка репрезентативности (M) – Является фактической разностью между средними или относительными величинами, полученными при проведении выборочного исследования и аналогичными величинами, которые были бы получены при проведении исследования на генеральной совокупности.
- Оценка достоверности результатов исследования предусматривает определение:
- 1. ошибки репрезентативности
- 2. доверительных границ средних (или относительных) величин в генеральной совокупности
- 3. достоверности разности средних (или относительных) величин (по критерию t)
- Расчет ошибки репрезентативности (mм) средней арифметической величины (М):
- , где σ – среднее квадратическое отклонение; n – численность выборки (>30).
- Расчет ошибки репрезентативности (mР) относительной величины (Р):
- , где Р – соответствующая относительная величина (рассчитанная, например, в %);
- Q =100 – Ρ% – величина, обратная Р; n – численность выборки (n>30)
В клинических и экспериментальных работах довольно часто приходится использовать Малую выборку, Когда число наблюдений меньше или равно 30. При малой выборке для расчета ошибок репрезентативности, как средних, так и относительных величин, Число наблюдений уменьшается на единицу, т. е.
![]()
Величина ошибки репрезентативности зависит от объема выборки: чем больше число наблюдений, тем меньше ошибка. Для оценки достоверности выборочного показателя принят следующий подход: показатель (или средняя величина) должен в 3 раза превышать свою ошибку, в этом случае он считается достоверным.
Знание величины ошибки недостаточно для того, чтобы быть уверенным в результатах выборочного исследования, так как конкретная ошибка выборочного исследования может быть значительно больше (или меньше) величины средней ошибки репрезентативности.
Для определения точности, с которой исследователь желает получить результат, в статистике используется такое понятие, как вероятность безошибочного прогноза, которая является характеристикой надежности результатов выборочных медико-биологических статистических исследований.
Обычно, при проведении медико-биологических статистических исследований используют вероятность безошибочного прогноза 95% или 99%.
В наиболее ответственных случаях, когда необходимо сделать особенно важные выводы в теоретическом или практическом отношении, используют вероятность безошибочного прогноза 99,7%
- Определенной степени вероятности безошибочного прогноза соответствует определенная величина Предельной ошибки случайной выборки (Δ – дельта), которая определяется по формуле:
- Δ=t * m, где t – доверительный коэффициент, который при большой выборке при вероятности безошибочного прогноза 95% равен 2,6; при вероятности безошибочного прогноза 99% – 3,0; при вероятности безошибочного прогноза 99,7% – 3,3, а при малой выборке определяется по специальной таблице значений t Стьюдента.
- Используя предельную ошибку выборки (Δ), можно определить Доверительные границы, в которых с определенной вероятностью безошибочного прогноза заключено действительное значение статистической величины, Характеризующей всю генеральную совокупность (средней или относительной).
- Для определения доверительных границ используются следующие формулы:
- 1) для средних величин:
![]()
Мвыб – средняя величина, Полученная при проведении исследования на выборочной совокупности; t – доверительный коэффициент, значение которого определяется степенью вероятности безошибочного прогноза, с которой исследователь желает получить результат; mM – ошибка репрезентативности средней величины.
2) для относительных величин:
![]()
Доверительные границы показывают, в каких пределах может колебаться размер выборочного показателя в зависимости от причин случайного характера.
При малом числе наблюдений (n
Источник: https://uchenie.net/116-oshibka-reprezentativnosti-metodika-vychisleniya-oshibki-srednej-i-otnositelnoj-velichiny/
Ошибки репрезентативности. Ошибки выборки
Любое выборочное наблюдение ставит своей задачей определение среднего размера признака или доли единиц, обладающих данным признаком, и распространение полученных характеристик выборочной совокупности на генеральную совокупность.
Ошибки репрезентативности возникают вследствие различия структуры выборочной и генеральной совокупности.
Структура генеральной совокупности вполне однозначна, и ей соответствует вполне определенное значение среднего размера (или доли) изучаемого признака. Выборочная же совокупность формируется на основе случайного отбора, в силу этого ее состав отличается от состава генеральной совокупности, отличается, естественно, и значение среднего размера (или доли) изучаемого признака.
Если из одной и той же генеральной совокупности производится несколько выборок, то в каждую из них попадут разные единицы и, следовательно, каждой выборочной совокупности будет соответствовать своя средняя. Отсюда следует важный вывод: выборочная средняя, в отличие от генеральной, – величина переменная. Переменной или случайной величиной будет и ошибка репрезентативности.
В практических статистических работах выборочное наблюдение проводится один раз, поэтому фактически приходится иметь дело с одной из множества выборочных средних, но с какой именно – сказать невозможно.
Чтобы получить суждение о точности результатов выборочного наблюдения, математическая статистика дает формулу средней ошибки, т.е.
средней величины из всех возможных ошибок при бесчисленном множестве случайных выборок.
При бесконечно большом числе выборок получится кривая частот, которая представляет кривую выборочного распределения.
Рассмотрим выборочное распределение средней величины.
Такое распределение будет являться нормальным или приближаться к нему по мере увеличения объема выборки независимо от того, имеет или не имеет нормальное распределение та генеральная совокупность, из которой взяты выборки.
С увеличением числа выборок средняя для всех выборок будет приближаться к генеральной средней. По выборочному распределению может быть рассчитана средняя квадратическая ошибка репрезентативности:
Среднее квадратическое отклонение выборочных средних от генеральной средней называется средней ошибкой выборочной средней (средней ошибкой выборки для средней величины признака):

Поскольку, как правило, генеральная средняя неизвестна, этой формулой нельзя воспользоваться. Кроме того, в социально-экономических исследованиях выборки из одной и той же совокупности не производятся многократно. Поэтому используют нижеприведенную формулу, исходя из того, что средняя ошибка выборки зависит от колеблемости признака в генеральной совокупности и числа отобранных единиц.
Средняя ошибка выборки для средней величины признака определяется по формуле:
![]()
где s2г – дисперсия количественного признака в генеральной совокупности.
Следовательно, средняя ошибка выборки тем больше, чем больше вариация в генеральной совокупности, и тем меньше, чем больше объем выборки.
Т.о. можно утверждать, что отклонение выборочной средней от генеральной средней в среднем равно . Ошибка конкретной выборки может принимать различные значения, но ее отношение к средней ошибке практически не превышает , если величина объема выборки достаточно большая .
- Отношение ошибки конкретной выборки к средней квадратической ошибке называется нормированным отклонением :
- .
- Распределение нормированного отклонения выборочной средней от генеральной средней при численности выборки определяется следующим уравнением:
- (1)
Данное уравнение называют стандартным уравнением нормальной кривой. Величина достигает максимума при , в этом случае .
На рис. приведен график кривой распределения нормированных отклонений ошибок выборочных средних .
Рис.
Ординаты соответствуют плотностям вероятности при том или ином значении . Для того, чтобы определить вероятность значений в интервале от до , следует найти отношение части площади кривой, заключенной между ординатами, соответствующими и ко всей площади кривой. Вся площадь под кривой нормального распределения вероятностей принимается за единицу.
- Площадь нормальной кривой, заключенную между ординатами и , определяют, интегрируя функцию (1) – интеграл Лапласа.
- Имеются таблицы интеграла Лапласа, которые содержат значения вероятностей для нормированных отклонений . Значения функции Ф(t) табулированы при разных значениях, например:
- при t=1 P(D£ m) = Ф(1) = 0,683;
- при t=2 P(D£2m) = Ф(2) = 0,9545;
при t=3 P(D£3m) = Ф(3) = 0,9973 и т.д.
- Это вероятность того, что ошибка попадет в заданные пределы.
- В общем виде
- D=tm
характеризует предельную ошибку выборки, показывающую максимально возможное расхождение выборочной и генеральной характеристик при заданной вероятности этого утверждения. Т.о. о величине ошибки можно судить с определенной вероятностью.
- Так, при t=2 возможная ошибка D не превысит 2m, что гарантируется с вероятностью 0,9545. Это значит, что в 9545 выборках из 10000 подобных максимальная ошибка не выйдет за пределы ±2m,
- где – это коэффициент доверия.
- При проведении выборочного учета массовых социально-экономических явлений считается достаточным максимальный размах ошибки выборки ±3m.
- На практике наиболее часто пользуются значениями вероятности Р=0,95 (t=1,96), Р=0,99 (t=2,58) и Р=0,999 (t=3,28), гарантирующими репрезентативность выборки соответственно с ошибкой 5; 1; 0,1%.
Предельная ошибка выборки позволяет определять предельные значения характеристик генеральной совокупности при заданной вероятности, т.е. их доверительные интервалы.
Поэтому вероятность Р называется доверительной, она представляет собой вероятность того, что ошибка выборки не превысит некоторую заданную величину D, т.е. генеральная средняя находится где-то в пределах
- (от до ),
- генеральная доля – в пределах
- (от w–D до w+D).
- Как мы определили выше, средняя ошибка выборки для средней величины признака определяется по формуле:
- ,
- где s2г – дисперсия количественного признака в генеральной совокупности.
- Если при выборочном наблюдении изучению подлежит альтернативный признак, то средняя ошибка выборки для доли единиц, обладающих данным признаком, определяется по теореме Я. Бернулли:
- ,
- где p – доля единиц, обладающих данным качеством, в генеральной совокупности; p(1-p) – дисперсия альтернативного признака в генеральной совокупности.
Приведенные формулы средних ошибок выборки практически непригодны для расчета. В них фигурирует дисперсия признака в генеральной совокупности, которая неизвестна, как неизвестна и генеральная доля, генеральная средняя. Поскольку в теории вероятности доказано, что
,
то при большом объеме выборки дисперсии генеральной s2г и выборочной s2 совокупностей равны. ( ). Это дает основание исчислять среднюю ошибку выборки по значениям выборочной дисперсии s2 для средней и w(1–w) для доли признака:
- , ,
- где w – доля признака в выборочной совокупности.
- Наряду с абсолютной величиной предельной ошибки выборки рассчитывается и относительная ошибка выборки, которая определяется отношением предельной ошибки средней или доли к соответствующей характеристике выборочной совокупности:
- ; .
При проведении выборочного наблюдения в экономических исследованиях преимущественно стремятся к тому, чтобы относительная ошибка репрезентативности выборки не превышала 5 … 10%.
Вывод формул , ,
исходит из схемы повторной выборки. На практике повторная выборка, при которой численность генеральной совокупности остается неизменной (т.е.отобранная единица возвращается в генеральную совокупность и снова может быть отобрана), встречается редко (например, при изучении населения в качестве пользователей, пациентов, избирателей).
- Обычно отбор организуется по схеме бесповторной выборки, при которой отобранная единица после обследования в генеральную совокупность не возвращается и в дальнейшей выборке не участвует.
- При бесповторной выборке численность генеральной совокупности в процессе отбора сокращается на
- 1–n/N, где n/N – доля отобранных единиц.
- В связи с этим формулы ошибки выборки приобретают следующий вид:
- ; .
- Так как доля единиц генеральной совокупности, не попавших в выборку (1–n/N), всегда меньше единицы, то ошибка выборки при бесповторном отборе при прочих равных условиях меньше, чем при повторном отборе.
Источник: https://infopedia.su/10x41a.html
2.2.2. Стихийная выборка
Исследователь при
применении данного метода в некоторой
степени контролирует выборку (например,
публикуя анкету в журнале, он обращается
только к читателям этого журнала), но
решение о включении в выборку принимает
сам респондент.
То есть, её размер заранее
часто не известен, а определяется
конкретным условием — активностью
респондентов. Значит, нельзя и заранее
определить структуру массива респондентов,
которые заполнят и вернут анкеты.
Поэтому
этот метод не претендует на репрезентативность
выборки, а выводы исследования очень
часто распространяются только на
опрошенную совокупность.
Сферы применения
стихийной выборки:
-
анкеты, публикуемые в газетах и журналах;
-
почтовые опросы1;
-
опросы покупателей в залах супермаркетов;
-
опрос пассажиров на остановках и в общественном транспорте2.
2.3. Многоступенчатая и одноступенчатая выборки
Выборка делится
на одноступенчатую и многоступенчатую
по количеству ступеней в отборе.
Одноступенчатая выборка предполагает,
что из генеральной совокупности сразу
осуществляется отбор респондентов для
опроса.
Процедура же многоступенчатой
выборки включает несколько ступеней,
при этом на каждой из них единица отбора
меняется. «Различают единицы отбора
первой ступени (первичные единицы),
единицы отбора вторичной ступени
(вторичные единицы) и так далее.
Объекты
самой нижней ступени, с которых ведется
непосредственный сбор информации,
называются единицами наблюдения»3.
Например, задача исследования – изучение
свободного времени студентов всей
страны.
Процедура будет
строиться следующим образом:
-
отбор регионов;
-
отбор города в них, где есть вузы;
-
отбор учебных заведений, в которых будет проводиться исследование;
-
выбор академических групп;
-
отбор студентов.
Многоступенчатая
выборка осуществляется не в локальных
масштабах, а в региональных, общенациональных,
международных. Использовать одноступенчатую
выборку в таких масштабах нерационально,
да и очень дорого обойдётся такое
исследование. Многоступенчатая выборка
в этом плане экономична и упрощает
подход к выбору объекта.
- Но нужно
учитывать, что чем больше ступеней в
выборке, тем больше будет ошибка
репрезентативности, возрастёт вероятность
погрешностей, что приведёт к искажению
результатов исследования4. - Рассмотрев
некоторые типы выборок, необходимо
также уяснить, что такое объем выборки
и какие бывают ошибки выборки и как их
избежать. - В
формировании выборочной совокупности
важную роль играет определение ее объема
и обеспечение репрезентативности.
«Если тип выборки
говорит о том, как попадают люди в
выборочную совокупность, то объём
выборки сообщает о том, какое их
количество попало сюда»2. То есть объем выборки – это количество
единиц попавших в выборочную совокупность.
И очень важно, чтобы выборка была
репрезентативной, то есть не искажала
представлений о генеральной совокупности
вцелом3.
«Требования репрезентативности выборки
означают, что по выделенным параметрам
(критериям) состав обследуемых должен
приближаться к соответствующим пропорциям
в генеральной совокупности»4.
Одна из ключевых
проблем, встающих, как правило, перед
социологом, решающим: доверять полученным
в ходе него данным или нет, это то, сколько
же человек должно быть опрошено для
того, чтобы получить действительно
репрезентативную информацию.
К сожалению,
единой и четкой формулы, используя
которую можно было бы рассчитать
оптимальный объем выборочной совокупности,
не существует в природе. И объясняется
это весьма просто.
Дело в том, что
определение объема выборочной совокупности
– это проблема не столько статистическая,
сколько содержательная.
Иными словами,
объем выборочной совокупности зависит
от множества факторов, основные из них
следующие:
-
затраты на сбор информации, включая временные;
-
стремление к определённой статистической достоверности результатов, которую надеется получить исследователь;
-
ценность и новизна информации, получаемой в результате опроса5.
Объем
выборки обусловлен степенью однородности
или неоднородности, генеральной
совокупности, количеством характеризующих
ее признаков.
Однородной считается совокупность,
в которой контролируемый признак,
например уровень грамотности, распределён
равномерно, то есть не образует пустот
и сгущений, тогда опросив лишь несколько
человек, можно сделать вывод о том, что
большинство людей грамотны.
Чем более
однородна генеральная совокупность,
тем меньше объем выборки. Например,
«допустим, мы осуществляем отбор из
генеральной совокупности в 2000 человек,
контролируя состав выборочной совокупности
по признаку «пол»»: 70% мужчин и 30% женщин.
Согласно теории вероятности, можно
предположить, что примерно среди каждых
десяти отбираемых респондентов встретятся
три женщины. Если мы хотим опросить по
крайней мерее 90 женщин, то исходя из
вышеупомянутого соотношения, нам
необходимо отобрать не менее 300 человек.
А теперь предположим, что в генеральной
совокупности 90% мужчин и 10% женщин. В
этом случае, чтобы в выборочную
совокупность попало 90 женщин, необходимо
отобрать уже не менее 900 человек»1.
Из примера видно, что объем выборки
зависит от разброса признака (дисперсии),
и его нужно вычислять по признаку,
дисперсия значений которого наибольшая.
«Степень
однородности социального объекта
зависит, в сущности, от того, насколько
детально мы намерены его исследовать.
Практически любой, самый «элементарный»
объект оказывается чрезвычайно сложным.
Лишь в анализе мы представляем его как
относительно простой, выделяя те или
иные его свойства.
Чем более основательным
и детальным будет анализ, чем больше
свойств данного объекта мы намерены
принять во внимание в их сочетании, а
не изолированно, тем больше должен быть
объем выборки»2.
Существуют, так
называемые «правила левой руки» для
определения размера выборки (таблица
1)»3:
| Размер выборки растёт | Размер выборки уменьшается |
| — при необходимости опубликовать данные для отдельных подгрупп (размеры подвыборок при этом суммируются, и выборка в целом растёт пропорционально числу подгрупп); | — при исследовании организаций, институтов и прочих «первичных единиц отбора», если сравнительно невелика величина генеральной совокупности, из которой производится отбор(например, совокупности сотрудников рекламных агентств, школьников, пациентов и т.п.); |
| — при проведении общенациональных обследований, когда велика генеральная совокупность; | — при проведении локальных и региональных исследований; |
Источник: https://studfile.net/preview/5996791/page:7/
Ошибки выборки
Расхождения между величиной какого-либо показателя, найденного посредством статистического наблюдения, и действительными его размерами называются ошибками наблюдения. В зависимости от причин возникновения различают ошибки регистрации и ошибки ре- пр ез ентативн о сти.
Ошибки регистрации возникают в результате неправильного установления фактов или ошибочной записи в процессе наблюдения или опроса. Они бывают случайными или систематическими.
Случайные ошибки регистрации могут быть допущены как опрашиваемыми в их ответах, так и регистраторами. Систематические ошибки могут быть и преднамеренными, и непреднамеренными. Преднамеренные — сознательные, тенденциозные искажения действительного положения дела.
Непреднамеренные вызываются различными случайными причинами (небрежность, невнимательность).
Ошибки репрезентативности (представительности) возникают в результате неполного обследования и в случае, если обследуемая совокупность недостаточно полно воспроизводит генеральную совокупность. Они могут быть случайными и систематическими.
Случайные ошибки репрезентативности — это отклонения, возникающие при несплошном наблюдении из-за того, что совокупность отобранных единиц наблюдения (выборка) неполно воспроизводит всю совокупность в целом. Систематические ошибки репрезентативности — это отклонения, возникающие вследствие нарушения принципов случайного отбора единиц.
Ошибки репрезентативности органически присущи выборочному наблюдению и возникают в силу того, что выборочная совокупность не полностью воспроизводит генеральную.
Избежать ошибок репрезентативности нельзя, однако, пользуясь методами теории вероятностей, основанными на использовании предельных теорем закона больших чисел, эти ошибки можно свести к минимальным значениям, границы которых устанавливаются с достаточно большой точностью.
Ошибки выборки — разность между характеристиками выборочной и генеральной совокупности. Для среднего значения ошибка будет определяться по формуле
Величина называется предельной ошибкой выборки.
Предельная ошибка выборки — величина случайная. Исследованию закономерностей случайных ошибок выборки посвящены предельные теоремы закона больших чисел. Наиболее полно эти закономерности раскрыты в теоремах П.Л. Чебышева и А.М. Ляпунова.
Теорему П.Л. Чебышева применительно к рассматриваемому методу можно сформулировать следующим образом: при достаточно большом числе независимых наблюдений можно с вероятностью, близкой к единице (т.е.
почти с достоверностью), утверждать, что отклонение выборочной средней от генеральной будет сколько угодно малым. В теореме П.Л. Чебышева доказано, что величина ошибки не должна превышать tp .
В свою очередь величина Р, выражающая среднее квадратическое отклонение выборочной средней от генеральной средней, зависит от колеблемости признака в генеральной совокупности о- и числа отобранных единиц п. Эта зависимость выражается формулой
- где Р зависит также от способа производства выборки.
- Величину М = о2 называют средней ошибкой выборки. В этом V п
- выражении а2 — генеральная дисперсия, п — объем выборочной совокупности.
Рассмотрим, как влияет на величину средней ошибки число отбираемых единиц п. Логически нетрудно убедиться, что при отборе большого числа единиц расхождения между средними будут меньше, т.е.
существует обратная связь между средней ошибкой выборки и числом отобранных единиц.
При этом здесь образуется не просто обратная математическая зависимость, а такая зависимость, которая показывает, что квадрат расхождения между средними обратно пропорционален числу отобранных единиц.
Увеличение колеблемости признака влечет за собой увеличение среднего квадратического отклонения, а, следовательно, и ошибки. Если предположить, что все единицы будут иметь одинаковую величину признака, то среднее квадратическое отклонение станет равно нулю и ошибка выборки также исчезнет.
Тогда нет необходимости применять выборку. Однако следует иметь в виду, что величина колеблемости признака в генеральной совокупности не известна, поскольку не известны размеры единиц в ней. Можно рассчитать лишь колеблемость признака в выборочной совокупности.
Соотношение между дисперсиями генеральной и выборочной совокупности выражается формулой
Поскольку величина п при достаточно больших п близка к 1, п — 1
можно приближенно считать, что выборочная дисперсия равна генеральной дисперсии, т.е. Орен ж •
Следовательно, средняя ошибка выборки показывает, какие возможны отклонения характеристик выборочной совокупности от соответствующих характеристик генеральной совокупности. Однако о величине этой ошибки можно судить с определенной вероятностью. На величину вероятности указывает множитель t.
Теорема А.М. Ляпунова. А.М. Ляпунов доказал, что распределение выборочных средних (следовательно, и их отклонений от генеральной средней) при достаточно большом числе независимых наблюдений приближенно нормально при условии, что генеральная совокупность обладает конечной средней и ограниченной дисперсией.
Математически теорему Ляпунова можно записать так:
- Где
- где я = 3,14 — математическая постоянная;
- — предельная ошибка выборки, которая дает возможность выяснить, в каких пределах находится величина генеральной средней.
- Значения этого интеграла для различных значений коэффициента доверия t вычислены и приводятся в специальных математических таблицах. В частности, при:
Поскольку t указывает на вероятность расхождения х — х , т.е.
на вероятность того, на какую величину генеральная средняя будет отличаться от выборочной средней, то это может быть прочитано так: с вероятностью 0,683 можно утверждать, что разность между выборочной и генеральной средними не превышает одной величины средней ошибки выборки.
Другими словами, в 68,3% случаев ошибка репрезентативности не выйдет за пределы ±Ц. С вероятностью 0,954 можно утверждать, что ошибка репрезентативности не превышает ± 2р (т.е. в 95% случаев). С вероятностью 0,997, т.е.
довольно близкой к единице, можно ожидать, что разность между выборочной и генеральной средней не превзойдет трехкратной средней ошибки выборки и т.д.
- Логически связь здесь выглядит довольно ясно: чем больше пределы, в которых допускается возможная ошибка, тем с большей вероятностью судят о ее величине.
- Зная выборочную среднюю величину признака (х) и предельную ошибку выборки можно определить границы (пределы), в
- которых заключена генеральная средняя
Источник: https://bstudy.net/710108/ekonomika/oshibki_vyborki
Требования к выборке становятся актуальными при проведении психологических исследований, когда получаемые результаты и выводы в дальнейшем планируется распространить на генеральную совокупность, а также в случае необходимости получения статистически достоверных результатов.
Важнейшим требованием к качеству выборки является обеспечение ее репрезентативности. Требование репрезентативности выборки означает, что по выделенным параметрам (критериям) состав выборки обследуемых должен приближаться к соответствующим пропорциям в генеральной совокупности. Между тем, строго репрезентативную выборку по всем важным для проблематики исследования параметрам обеспечить невозможно, и поэтому следует гарантировать репрезентацию по главному направлению анализа данных.
Прежде всего, надо уяснить, какие из имеющихся сведений о характеристиках генеральной совокупности существенны для целей исследования. Во многих случаях это половозрастной и социально-профессиональный состав обследуемых, их пространственная локализация. Исходя из этого, основными этапами формирования выборки (выборочной совокупности) являются следующие:
– обоснование структуры выборочной совокупности в соответствии с характером задач и гипотез исследования;
– уточнение структуры выборки с учетом информации, полученной при анализе первичных результатов исследований, данных пробных и пилотажных исследований, их доработка на основе гипотез;
– определение типа и объема выборки.
В наиболее общем виде по типу выборочные совокупности делят на целенаправленные (из генеральной совокупности выбираются типичные элементы, воспроизводящие ее структуру) и случайные (вероятностные), когда все элементы генеральной совокупности имеют одинаковую вероятность попадания в выборочную совокупность.
В зависимости от характера исследования может применяться тот или иной тип выборки:
1. Простая случайная. Из однородной совокупности, все элементы которой известны и могут быть пронумерованы, осуществляется отбор единиц выборки с помощью таблиц случайных чисел.
2. Систематическая. Для ее определения необходим полный список единиц генеральной совокупности. В выборку отбирается по одному объекту через интервал, равный шагу отбора – отношению объема генеральной совокупности к объему выборки.
3. Гнездовая. Выборочные единицы отбираются с помощью одного из способов случайного отбора. Единицы отбора представляют собой статистические группы (гнезда), которые целиком или выборочно подвергаются обследованию.
4. Стратифицированная районированная выборка. Исследуемая совокупность предварительно разделяется на страты (слои) в соответствии с генеральным распределением известных и значимых для исследования признаков.
а) Пропорциональное размещение – объем выборки из страты пропорционален размеру страты в генеральной совокупности;
б) Оптимальное размещение – объем выборки из страты пропорционален в страте среднеквадратичному отклонению признака и обратно пропорционален издержкам на получение выборки.
5. Многоступенчатая. Процедура построения выборки разбивается на ряд этапов (ступеней). На каждой ступени меняется единица отбора.
а) Случайная – на каждой ступени единицы отбираются одним из способов случайного отбора.
б) Комбинированная – отбор на каждой из ступеней может осуществляться любым из вышеописанных способов.
6. Квотная. Производится разбиение генеральной совокупности на классы согласно нескольким распределениям выбранных признаков. На основе знания статистического объема каждого класса и заданной доли отбора из него определяется “квота” – объем выборки соответствующего класса.
Объем выборки – число элементов, включенных в выборочную совокупность. Численность (объем) выборки определяется:
– уровнем однородности или разнородности изучаемых объектов – генеральной совокупности (чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы);
– величиной доверительной вероятности (Р);
– требуемой точностью результатов, т.е. величиной допускаемой ошибки репрезентативности.
Весьма полезна следующая приблизительная оценка надежности результатов выборочного обследования. Повышенная надежность допускает ошибку выборки до 3%, обыкновенная – до 3-10%, приближенная – от 10 до 20%, ориентировочная – от 20 до 40%, а прикидочная – более 40%.
Для достижения необходимого качества выборки необходимо осуществить следующие шаги:
1. Опpеделить стpуктуpу генеpальной совокупности – количественные пpопоpции подгpупп (квот) по pазличным социально-демогpафическим хаpактеpистикам.
2. Опpеделяется объем пpедставительной выбоpки.
3. Объем пpопоpционально делится на квоты, так чтобы стpуктуpа выбоpки моделиpовала стpуктуpу генеpальной совокупности.
Половозрастная структура “замыкает” на себя многие показатели семейного состояния. При конструировании заданий для теста необходимо учитывать, что весьма вероятны различия в ответах на них в зависимости от пола испытуемых. Так, обычно при выполнении тестов способностей детьми до 16 лет девочки демонстрируют превосходство в словесно-логических навыках, а мальчики – в работе с цифрами. Вероятнее всего, что задания из этих областей будут иметь различные статистические оценки. Различия испытуемых по полу обнаруживаются во многих заданиях личностных тестов, например, тех, которые касаются интереса к одежде, спорту, своей внешности, вождению автомобиля, рисованию, верховой езде.
Одним из решений этой проблемы было бы разделить мужчин и женщин на отдельные выборки, а затем отобрать задания, удовлетворяющие критериям процедуры анализа заданий для обеих групп. Хотя при этом возникают некоторые трудности.
Первая проблема состоит в том, что хотя задания почти всегда могут быть сформулированы так, что они пройдут процедуру анализа (с корреляцией задание/общий показатель 0,2 и долей Р, ответивших в соответствии с ключом испытуемых в пределах от 0,2 до 0,8) в обеих группах, даже для эффективных заданий эти оценки могут быть не идентичными. Особенно важным здесь является коэффициент Р, так как если он всегда больше, скажем, для мужчин, чем для женщин, на большом количестве заданий, то это может привести к влиянию пола испытуемых на результаты тестирования.
Вторая проблема является более фундаментальной. Если мы отберем задания, получившие в процедуре их анализа одинаковые оценки для мужчин и для женщин, мы фактически создадим тест, на результаты которого пол испытуемых не влияет. С другой стороны, мы могли бы отобрать задания, по которым женщины показывают более высокие результаты. Каково, однако, значение такой идентичности или различия в показателях? Чтобы вычленить эту проблему, следует вспомнить, что средние значения и дисперсии для тестов являются функциями отдельных наборов заданий. Так что не имеет смысла утверждать, что исходя из показателей по тесту девочки выполняют его лучше, или хуже, или так же, как мальчики. Это должно быть функцией конкретного набора заданий.
На практике это означает, что если у нас нет некоторой веской причины ожидать влияния пола испытуемых на тест, то должны отбираться те задания, которые не выявляют половых различий. В случае большинства личностных и мотивационных переменных это наиболее оптимальный подход. Следует заметить, что если по данной переменной существует реальные различия между полами, то не имеет значения, сколько заданий испытывается – это проявится в статистических оценках заданий. Так, если постоянно для каждого задания обнаруживается устойчивая тенденция, то тогда лучше всего будет использовать эти задания, пусть даже тест и показывает теперь различия между полами.
Возраст содержит указания на жизненный опыт и, как правило, на рабочий или профессиональный стаж. При испытании заданий существенно, чтобы вся сформированная выборка была подобной той, для которой тест предназначен. Однако полезно также провести анализ заданий данного теста отдельно для различных возрастных групп в рамках одной выборки.
Социально-профессиональные характеристики – это свидетельства особого рода занятий, с чем связаны интересы, особенности режима труда и отдыха, многие другие важные показатели деятельности людей. Пространственная локализация (по территории, подразделениям предприятий, учреждений) важна с точки зрения особенностей условий жизнедеятельности определенной группы людей.
В ряде случаев значимым фактором, влияющим на результаты тестирования является т.н. тестовая искушенность. Тестовая искушенность – индивидуальный опыт обследуемого, приобретенный в ходе выполнения различных психологических тестов. По мнению А.Анастази, преимущества человека, ранее участвующего в обследовании перед новичком складываются из ранее преодоленного чувства неизвестности, сформировавшейся уверенности в себе, сложившегося отношения к тестовой ситуации, приобретенных навыков работы с тестовыми заданиями, осознания исходности принципов решения задач в определенных группах тестов, снижение мотива экспертизы и проявления различного рода установок, снижающих достоверность получаемых диагностических данных.
Таблица 4. Зависимость объема выбоpки от объема генереальной совокупности пpи допустимой ошибке 5% (довеpительная веpоятность – 0,95)
Несмотря на наличие ссылок по тексту, автор все же рекомендует прочесть раздел целиком — для более последовательного понимания материала.
Определения и пояснения:
1. Ген еральная совокупность и выборка.
Под выборочным методом понимается следующее. Та категория исследовательских задач, которая требует изучения каких-либо психологических, социальных явлений, свойственных, например, всем жителям города, всем студентам, всем владельцам автомобилей такой-то марки и т. п. накладывает объективные ограничения на возможность проведения эксперимента. Действительно: если требуется, скажем, узнать какова доля женщин среди жителей города, очень трудоемко и нецелесообразно искать эти сведения во всех паспортных столах или устраивать собственную «перепись населения». С этой целью исследователем подсчитывается процент женщин в какой-либо относительно небольшой группе случайно (или периодически) отобранных граждан, а на основании результата делается заключение о том, какова доля женщин среди жителей города.
В таком случае всех жителей будем считать ГЕНЕРАЛЬНОЙ СОВОКУПНОСТЬЮ, а экспериментальную группу граждан – ВЫБОРКОЙ.
2. Тр ебования, предъявляемые к выборке.
К генеральной совокупности обычно применимо требование правильного определения ее КОНТУРА. Это означает, что исследователь обязан ответить на два вопроса: охватывает ли он в своих предположениях все возможные элементы генеральной совокупности, и нет ли элементов избыточных, лишних.
Приведем пример. Пусть перед нами стоит исследовательская задача определить, велик ли в некоем городе процент женщин, считающих свою семейную жизнь удовлетворительной? Не касаясь способов, как именно оценивать степень удовлетворенности, займемся определением характера самой генеральной совокупности. Очевидно, что мы получим искаженную картину, если примем за генеральную совокупность всех лиц женского пола, включая младенцев, детей и незамужних девушек. (Речь идет об удовлетворенности собственной семьей.) Однако мы так же ошиблись бы, если бы исключили вдов, престарелых женщин или женщин, состоящих в разводе, ведь мы помним, что по условию «задачи» нас интересует удовлетворенность семейной жизнью, а не только супружеством. Стало быть, не следует исключать из рассмотрения неполные семьи.
К выборке обычно предъявляются требования ВАЛИДНОСТИ и РЕПРЕЗЕНТАТИВНОСТИ.
Под ВАЛИДНОСТЬЮ понимается следующее. Буквально: выборка должна работать, то есть отражать все характеристики генеральной совокупности. Она не может быть «с живой картины списком бледным», в выборке не должны пропадать какие-то свойства, присущие генеральной совокупности в целом. Выборка – это модель того, что она представляет. (Нельзя выносить суждение о том, что все дно мирового океана покрыто галькой – на том основании, что вы сидите на пляже и перебираете в руках камешки.)
Пример. Вспомним нашего гипотетического наблюдателя, стоящего на улице и подсчитывающего процент проходящих мимо него мужчин и женщин. Если его задача в том, чтобы узнать: лица какого пола чаще ходят по этой улице, то он действует правильно. Но если задача в другом : определить больше ли ходит вообще по городу мужчин или женщин, то нашему экспериментатору надо бы пригласить помощников, которых он должен расставить и на центральных улицах и в «спальных районах» города, и на темных переулках. После подсчета ему придется объединить данные, причем в тех пропорциях, в каких описанные категории улиц представлены в его городе. Если же задача нашего любознательного исследователя состоит в том, чтобы узнать, кого вообще в городе больше – мужчин или женщин, то ему придется покинуть свой пост и лучше вместе с помощниками отправиться по разным домоуправлениям или паспортным столам. Это справедливо вот почему: если на дворе белый день, причем, рабочий, то вряд ли мимо наблюдателя будет ходить много служащих, матерей с грудными младенцами, дряхлых стариков и т.п. Иными словами, сформированная им выборка не будет отражать характеристик всей генеральной совокупности.
Требование РЕПРЕЗЕНТАТИВНОСТИ состоит в том, чтобы любой исследователь, желающий повторить этот эксперимент, имел возможность при сходных условиях сформировать подобную выборку (то есть выборку с теми же свойствами) и получить результат. Будет ли результат почти таким же или отличным – дело другое. Важно то, что условия эксперимента должны иметь возможность быть воспроизведенными.
Существует также требование НАДЕЖНОСТИ, но оно имеет отношение скорее к эксперименту в целом, нежели к формированию выборки. Состоит оно, во-первых, в возможности повторения эксперимента с получением близких (тех же) результатов, и, во-вторых, — в степени доверия к полученным результатам – точность, с какой эксперимент описал действительное положение вещей. Этот момент тесно связан с таким понятием, как «уровень статистической значимости».
3. Уро вни статистической значимости.
Основной вопрос, на который нужно дать ответ при проведении любого статистического исследования, это – достоверны ли различия между чем-то и чем-то. Этим «чем-то» может быть, например средний уровень интеллекта в двух группах людей; возможно, мы хотим узнать, все ли цвета в тесте Люшера выбираются, в среднем, одинаково часто на все позиции (то есть хотим сравнить экспериментальное распределение с равномерным); случайно или нет после воздействия суггестора на экспериментальную группу изменилось ее усредненное отношение к какому-то вопросу, и т.п. Во всех этих (и во всех прочих) случаях мы всегда определяем достоверность различий.
УРОВЕНЬ ЗНАЧИМОСТИ – это вероятность того, что мы сочли различия достоверными, а они на самом деле случайны.
Часто в научной литературе, особенно в периодических изданиях, можно встретить такую запись:
Эта запись обозначает, что полученные в описываемом эксперименте различия достоверны на 5%-м или 1%-м уровне, то есть вероятность, что они окажутся недостоверны, равна 5/100 (0,05%) или 1/100 (0,01%).
Пятипроцентный уровень и однопроцентный уровень – общепринятые «стандарты». Обычно приводится сравнение именно с этими двумя числами.
Если уровень значимости указан:
более 10 процентов, — гипотезу, как правило, признают не подтвердившейся, а различия – недостоверными;
если в диапазоне от 5 до 10 процентов – тенденция достоверности;
меньше 5% — результатам можно доверять;
меньше 1% — практически, гарантия достоверности.
4. Нулевая и альтернативная гипо тезы.
Формулирование гипотез – важный этап всякого исследования. Правильно сформулированные, они помогают исследователю придерживаться выбранной линии. После проведения эксперимента и осуществления всех подсчетов ему легче понять, что же все-таки он обнаружил.
Существуют два общепринятых, стандартных, типа гипотез:
Нулевая гипотеза (обозначается Н о ) предполагает, что в эксперименте не будет выявлено различий. Например: «Между учениками 1 класса А и 1 класса Б нет различий по уровню интеллекта».
Альтернативная гипотеза (обозначается Н 1 ) предполагает, что будут выявлены различия (что различия будут достоверны). Например: «Ученики 1 класса А и 1 класса Б отличаются по уровню интеллекта»
Гипотезы так же могут быть ненаправленными (см. предыдущий пример) и направленными: «Ученики 1 класса А превосходят по уровню интеллекта учеников 1 класса Б»
5. Шка лы измерения.
Измерение – приписывание числовых форм объектам или событиям в соответствии с какими-либо правилами.
Различают четыре типа измерительных шкал.
1) НОМИНАТИВНАЯ (номинальная, шкала наименований). Эта шкала классифицирует объекты по названию, по принадлежности. Она не измеряет объекты количественно, а лишь «расставляет» по надлежащим местам. Например, взяв группу граждан, мы можем классифицировать их по национальностям, по профессии. Простейший случай номинальной шкалы – дихотомическая . Она содержит только два варианта значений: «ответил – не ответил на вопрос анкеты»; «холост – женат»; «работает – безработный»; «мужчина – женщина» и т.п.
2) ПОРЯДКОВАЯ шкала классифицирует по принципу «больше – меньше». Классифицированные объекты располагаются по мере возрастания признака, от самого малого – до самого большого. Ячейки здесь играют роль «классов». Однако порядковая шкала не дает ответа на вопрос, насколько один объект больше или меньше другого (каково между ними расстояние, выраженное в каких-либо единицах). Порядковая шкала должна содержать не меньше трех классов (разрядов), (в противном случае она сводится к дихотомической шкале). Пример: уровень благосостояния населения – мы можем сказать, что «средний класс» обеспеченнее бедных и беднее богатых, но не имеем возможности определить эту разницу количественно. Еще пример – уровень образования. Ясно, что высшее образование «лучше», чем среднее и среднее-специальное , но нет таких единиц, в которых можно было бы указать, насколько именно «лучше». Третий пример: тест СЖО (смысло-жизненных ориентаций) Леонтьева, и вообще, все методики, в которых требуется оценить что-либо по схеме «нравится – не знаю – не нравится» или «всегда – обычно – иногда – никогда».
3) ИНТЕРВАЛЬНАЯ шкала – шкала, классифицирующая по принципу «больше/меньше на определенное количество единиц». Однако эта шкала не устанавливает точки начального отсчета, некоего «абсолютного нуля», зная который, можно сравнивать между собой два любых объекта, признаки которых измерены в этой шкале. Например, измеряем время решения учебной задачи при приеме на работу. Пусть имеется четыре испытуемых А , Б, В и Г. Пусть А решил задачу за 100 секунд, Б – за 110, В – за 200, а Г – за 210. Ясно, что в этом случае нельзя утверждать, что А настолько же успешнее Б, насколько В успешнее Г, хотя между этими парами испытуемых одна и та же разница во времени решения задач – 10 секунд.
4) ШКАЛА РАВНЫХ ОТНОШЕНИЙ – это шкала, классифицирующая объекты пропорционально степени выраженности исследуемого свойства. Здесь классы или градации выражены числами, пропорциональными друг другу. Иными словами, такая шкала имеет абсолютную точку отсчета. В психологии примером шкалы равных отношений могут служить пороги абсолютной чувствительности. В сравнении с предыдущей шкалой, можно сказать, что та являлась шкалой температуры по Цельсию, а эта – по Кельвину, где есть абсолютный нуль.
Выборочное исследование должно обеспечивать необходимую точность результатов относительного объекта исследования, при этом, как было отмечено в предыдущем разделе, оно должно обеспечить экономию исследовательских ресурсов. Перечислим основные критерии, предъявляемые к выборке.
1. Выборка должна обеспечивать расчет несмещенных оценок изучаемого явления, т. е. быть репрезентативной.
2. Выборка должна обеспечивать расчет ошибок выборки, сопровождающих любое выборочное обследование.
3. Построение выборки должно быть относительно быстрым и легким (т. е. модель формирования выборки не должна быть чересчур сложной, громоздкой).
4. Выборка должна обеспечивать максимально возможной точности исследования в рамках имеющихся средств. Т. е., построение и реализация выборки не должны быть излишне затратными.
5. Выборка должна быть четко письменно задокументирована таким образом, чтобы эксперты могли оценить, насколько она соответствует вышеприведенным критериям.
Ключевым требованием к выборочной совокупности является требование репрезентативности.
Репрезентативной называют выборку, представляющую генеральную совокупность с приемлемой степенью точности. Репрезентативность — свойство выборки отражать, моделировать характеристики генеральной совокупности. Мера подобия выборочной модели структуре генеральной совокупности оценивается ошибкой выборки. Ошибка выборки характеризует расхождение между оценкой показателя, сделанной на основании изучения выборки, и оценкой этого же показателя на основе изучения генеральной совокупности.
Допустимые пределы ошибки выборки зависят от цели исследования и определяют степень надежности получаемых результатов. Так для поисковых исследований надежность может быть приближенной и даже ориентировочной (т. е. в пределах 10–20 и 20–40% ошибки репрезентативности соответственно), для описательных и аналитических исследований должна быть обеспечена нормальная надежность результатов исследования (в пределах 3–10% ошибки репрезентативности, обычно — 5%).
Ошибки репрезентативности могут быть случайными и систематическими. Случайные ошибки не отражают существенной связи между объектом, субъектом и условиями проведения исследования. Они возникают непреднамеренно, например, вследствие описок, неточности сообщаемых респондентами данных. В целом по всему массиву данных такие ошибки имеют тенденцию к взаимному погашению и не влияют на результаты исследования.
Систематические ошибкиотражают существенную связь между объектом, субъектом и условиями проведения исследования и могут значительно исказить результаты исследования, вызывая так называемые систематические смещения. Причины возникновения систематических ошибок репрезентативности связаны существенными недочетами при формировании и реализации плана выборки. К их числу относятся:
– неверно выбранный метод формирования выборочной совокупности и/или неправильно рассчитанный ее объем;
– неполный охват единиц выборочной совокупности;
– произвольная замена единиц выборочной совокупности.
Следует отметить еще одну причину появления систематических ошибок, хотя именно эта причина никак не связана сущностью выборочного метода. Это некорректно разработанный инструментарий исследования.
Таким образом, обеспечение репрезентативности выборки осуществляется за счет:
– корректного определения необходимого объема выборочной совокупности и…
– . метода ее формирования, адекватного объекту, целям и задачам исследования;
– тщательного контроля реализации плана выборки.
Чтобы избежать грубых ошибок выборки, следует обратить внимание на следующие рекомендации:
1. Определите, что представляет собой генеральная совокупность: уточните, какие именно объекты попадают в ее состав, какие характеристики им присущи; оцените, насколько соотносятся между собой идеальная (задаваемая теоретическими параметрами) и реальная (определяемая жизнью) совокупности[1].
2. Уяснить, какие характеристики единиц генеральной совокупности существенны для исследования, чтобы они нашли точное отражение в выборке.
3. Выбрать оптимальную модель формирования выборки и определить необходимый ее объем.
4. Провести инструктаж лиц, привлекаемых к проведению исследования, по вопросам отбора единиц выборочной совокупности.
5. В процессе исследования контролировать соответствие формируемой выборки ее плану.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Для студента самое главное не сдать экзамен, а вовремя вспомнить про него. 10684 —  | 7833 —
| 7833 —  или читать все.
или читать все.
Выборка — это метод исследования, когда из общей изучаемой (генеральной) совокупности однородных единиц отбирается некоторая его часть (выборочная совокупность), и только эта часть подвергается обследованию.
Генеральная и выборочная совокупности должны сопоставляться по некоторым важным признакам, которые легко проверяются статистическими методами. Если они совпадают, то выборка называется представительной, или репрезентативной. Понятно и то, что, чем больше размер выборки, тем больше и достоверность. Прежде всего, надо уяснить, какие из имеющихся сведений о характеристике генеральной совокупности, объекте исследования существенны для целей исследования. Во многих случаях это половозрастной, социально-профессиональный, имущественный состав обследуемых, их пространственная локализация. Пол и возраст замыкают на себе многие показатели семейного состояния: возраст, к примеру, указывает на жизненный опыт, профессиональный стаж. Пространственная локализация (по территории, по месту работы) важна с точки зрения адресности выводов и рекомендаций, которые должны быть привязаны к административным или производственным показателям. При сочетании этих трех параметров: половозрастной структуры, социального состава и пространственной локализации — можно быть уверенным, что выборка будет представительной для изучения многих социальных проблем. Понятно, что это правило имеет исключения в зависимости от конкретных условий и особых целей исследования. Например, при изучении политических ориентации населения уже не обойтись без учета имущественного положения, а студенческих проблем — без знания вуза и курса обучения студентов.
Очень важно при формировании выборки обеспечить равномерный отбор из всей генеральной совокупности. При небольших по численности генеральных совокупностях применяют случайные выборки. Их можно использовать, когда известны основные параметры генеральной совокупности. Случайная систематическая выборка — отбор идет через определенные интервалы, например, по спискам студентов, клиентов банка, избирателей и т. п. Имея список работников предприятия и определив объем необходимой выборки, можно установить шаг выборки, например, каждый десятый или сотый из списка. Серийная или гнездовая выборка реализуется в том случае, если есть внутренняя структура объекта. На предприятии выбираются не все подразделения, а наиболее типичные, например, в области — отдельные города и районы, но опять же типичные; в городе это могут быть отдельные микрорайоны. Целевой называется выборка, в которой идет выделение на основе каких-либо признаков, например, по полу, национальности, имущественному положению, принадлежности к политическим партиям и т. п. Целенаправленная квотная выборка предполагает пропорциональный отбор на основании статистики распределения среди генеральной совокупности заданных сочетаний паспортных данных респондентов — квот. В социологии также используется выборка как метод основного массива — опрос всех присутствующих (или 60-70 % всей численности). Посредством этого метода, например, осуществляется «зондаж» общественного мнения. Выборки бывают одноступенчатыми и многоступенчатыми, комбинированными. На каждой ступени отбора следует обеспечить требование представительности. Например, при опросе населения города на первом этапе отбираются типичные микрорайоны, а затем опрашиваются жители каждой двадцатой или пятидесятой квартиры, дома. При опросе населения области на первой ступени выбираются типичные районы и города. Примером стихийной выборки могут быть опросы по почте, интервью встречных, прохожих, пассажиров. Здесь может применяться квотный принцип, когда в конкретном здании необходимо опросить определенное количество человек по некоторым признакам, к примеру, по полу, возрасту.
К выборке применяется ряд обязательных требований, определенных, прежде всего, целями и задачами исследования. Планирование эксперимента должно включать в себя учет как объема выборки, так и ряда ее особенностей. Так, в психологических исследованиях важно требование однородности выборки. Оно означает, что психолог, изучая, например, подростков, не может, включать в эту же выборку взрослых людей. Напротив, исследование, выполненное методом возрастных срезов, принципиально предполагает наличие разновозрастных испытуемых. Однако и в этом случае должна соблюдаться однородность выборки, но уже по другим критериям, в первую очередь таким, как возраст, пол. Основаниями для формирования однородной выборки могут служить разные характеристики, такие, как уровень интеллекта, национальность, отсутствие определенных заболеваний и т.д., в зависимости от целей исследования.
В общей статистике имеется понятие повторной и бесповторной выборки, или, иначе говоря, выборки с возвратом и без возврата. В качестве примера приводится, как правило, выбор шара, доставаемого из какой-либо емкости. В случае выборки с возвратом каждый выбранный шар опять возвращается в емкость и, следовательно, может быть выбран снова. При бесповторном выборе однажды выбранный шар откладывается в сторону и больше не может участвовать в выборке. В психологических исследованиях можно найти аналоги подобного рода способам организации выборочного исследования, поскольку психологу нередко приходится несколько раз тестировать одних и тех же испытуемых при помощи одной и той же методики. Однако, строго говоря, повторной в этом случае является процедура тестирования. Выборка испытуемых при полной тождественности состава в случае повторных исследований всегда будет иметь некоторые отличия, обусловленные функциональной и возрастной изменчивостью, присущей всем людям. Подобная выборка по характеру проведения процедуры является повторной, хотя смысл термина здесь, очевидно, иной, чем в случае с шарами.
Важно подчеркнуть, что все требования, предъявляемые к любой выборке, сводятся к тому, что на ее основе психологом должна быть получена наиболее полная, неискаженная информация об особенностях генеральной совокупности, из которой взята эта выборка. Иными словами, выборка должна как можно более полно отражать характеристики изучаемой генеральной совокупности.

6.4 Репрезентативность выборки
Состав экспериментальной выборки должен представлять (моделировать) генеральную совокупность, поскольку выводы, полученные в эксперименте, предполагается в дальнейшем перенести на всю генеральную совокупность. Поэтому выборка должна обладать особым качеством – репрезентативностью, позволяющей распространить полученные на ней выводы на всю генеральную совокупность.
Репрезентативность выборки очень важна, тем не менее по объективным причинам соблюдать её крайне сложно. Так, хорошо известен факт, что от 70% до 90% всех психологических исследований поведения человека проводились в США в 60-х годах XX века с испытуемыми – студентами колледжей, причем большинство из них были студентами психологами. В лабораторных исследованиях, выполняемых на животных, наиболее распространенным объектом изучения являются крысы. Поэтому неслучайно психологию называли раньше «наукой о студентах-второкурсниках и белых крысах». Студенты колледжей составляют всего 3% от общей численности населения США. Очевидно, что выборка студентов нерепрезентативна в качестве модели, претендующей на представительство всего населения страны.
Репрезентативная выборка, или, как еще говорят, представительная выборка, – это такая выборка, в которой все основные признаки генеральной совокупности представлены приблизительно в той же пропорции и с той же частотой, с которой данный признак выступает в данной генеральной совокупности. Иными словами, репрезентативная выборка представляет собой меньшую по размеру, но точную модель той генеральной совокупности, которую она должна отражать. В той степени, в какой выборка является репрезентативной, выводы, основанные на изучении этой выборки, можно с большой долей уверенности считать применимыми ко всей генеральной совокупности. Это распространение результатов называется генерализуемостью.
В идеале репрезентативная выборка должна быть такой, чтобы каждая из основных изучаемых психологом характеристик, черт, особенностей личности и т.п. была бы представлена в ней пропорционально этим же особенностям в генеральной совокупности. Согласно этим требованиям процедура формирования выборки должна иметь внутреннюю логику, способную убедить исследователя, что при сравнении с генеральной совокупностью она действительно окажется репрезентативной, представительной.
Нарушение принципов случайного выбора порой приводило к серьезным ошибкам. Стал знаменитым своей неудачей опрос, проведенный американским журналом «Литературное обозрение» относительно исхода президентских выборов в США в 1936 году.
Кандидатами на этих выборах были Ф.Д.Рузвельт и А.М.Ландон. В качестве генеральной совокупности редакция журнала использовала телефонные книги. Отобрав случайно 4 миллиона адресов, она разослала по всей стране открытки с вопросом об отношении к кандидатам в президенты. Затратив большую сумму на рассылку и обработку открыток, журнал объявил, что на предстоящих выборах президентом США с большим перевесом будет избран Ландон. Результат выборов оказался противоположным этому прогнозу.
Здесь были совершены сразу две ошибки – во-первых, телефонные книги сами по себе дают не репрезентативную выборку из населения страны, хотя бы потому, что абоненты– в основном зажиточные главы семейств. Во-вторых, прислали ответы не все, а люди, не только достаточно уверенные в своем мнении, но и привыкшие отвечать на письма, т.е. в значительной части представители делового мира, которые и поддерживали Ландона. Если бы редакция критически подошла к своей работе, она поняла бы, что методика опроса страдает изъянами.
Явление, подобное только что описанному, когда выборка представляет не всю генеральную совокупность, а лишь какой-то ее слой, какую-то ее часть, называется смещением выборки. Смещение – один из основных источников ошибок при использовании выборочного метода.
Однако для тех же самых президентских выборов социологи Дж.Гэллап и Э.Роупер правильно предсказали победу Рузвельта, основываясь только на 4 тысячах анкет. Причиной этого успеха, прославившего его авторов, было не только правильное составление выборки. Они учли, что общество распадается на социальные группы, которые более однородны, в том числе по своим политическим взглядам. Поэтому выборка из слоя может быть относительно малочисленной с тем же результатом точности. Имея результаты обследования по слоям, можно характеризовать общество в целом. Сейчас такая методика является общепринятой.
В своей конкретной деятельности психолог действует следующим образом: устанавливает подгруппу (выборку) внутри генеральной совокупности, подробно изучает эту выборку (проводит с ней экспериментальную работу), а затем, если позволяют результаты статистического анализа, распространяет полученные выводы на всю генеральную совокупность. Это и есть основные этапы работы психолога с выборкой.
Начинающий психолог должен иметь в виду часто повторяющуюся ошибку: каждый раз, когда он осуществляет сбор любых данных любым методом и из любого источника, у него всегда появляется соблазн распространить свои выводы на всю генеральную совокупность. Для того чтобы избежать подобной ошибки, надо не просто обладать здравым смыслом, но, прежде всего, хорошо владеть основными понятиями математической статистики.
Формирование выборки — это процесс определения целевой аудитории и отбора из всей совокупности потенциальных респондентов группы, имеющей все свойства генеральной совокупности.
“Методология и результаты расчета основных параметров выборки непосредственно зависят от способа отбора единиц из генеральной совокупности. Применение того или иного способа зависит от цели исследования, условий выборки, специфики объекта исследования, необходимой точности и оперативности результатов и от средств выделенных на исследования” [40, с. 268].
Различают две основных группы методов построения выборки:
- 1. Вероятностные.
- 2. Детерминированные.
- • простая случайная выборка;
- • систематическая (механическая) выборка;
- • стратифицированная случайная выборка;
- • кластерная выборка.
- • во-первых, нужно получить полный список членов генеральной совокупности и пронумеровать этот список. Такой список называется основой выборки;
- • во-вторых, следует определить предполагаемый объем выборки, т. е. ожидаемое число опрошенных;
- • в-третьих, нужно извлечь из справочной таблицы случайных чисел или с помощью датчика случайных чисел столько чисел, сколько нам требуется выборочных единиц. Если в выборке должно оказаться 100 человек, из таблицы берут 100 случайных чисел;
- • в-четвертых, нужно выбрать из списка основы те наблюдения, номера которых соответствуют выписанным случайным числам. Отбор заканчивается, когда отобрано заранее заданное количество элементов выборочной совокупности.
- 1) каждый элемент генеральной совокупности может принадлежать только к одному кластеру;
- 2) должно быть известно или поддаваться оценке с приемлемой степенью точности число элементов генеральной совокупности каждого кластера;
- 3) кластеры должны быть не разбросаны пространственно и не слишком велики, иначе кластерная выборка теряет свои преимущества в финансовом смысле;
- 4) выбор кластеров должен быть осуществлен так, чтобы рост выборочной ошибки был минимальным (разные кластеры не должны быть однородными по исследуемому признаку и слишком большими).
Вероятностные выборки
Вероятностные методы формирования выборки предполагают, что каждая единица генеральной совокупности имеет определенную вероятность включения в выборку. Использование таких методов позволяет исследователю распространять полученные результаты на всю генеральную совокупность.
Существуют различные вероятностные методы формирования выборки:
Простая случайная выборка
Простая случайная выборка предполагает, что каждой единице генеральной совокупности обеспечивается равная вероятность (возможность) попасть в выборочную совокупность. Более того, каждая возможная выборка данного объема имеет известную и равную вероятность того, что именно она станет реально обследуемой выборкой.
Процедура построения простой случайной выборки включает в себя следующие шаги [15, с. 205—206]:
Достоинством данного метода является полное соблюдение принципа случайности и, как следствие — избежание систематических ошибок. Затрудняют применение простого случайного отбора на практике необходимость наличия списка элементов генеральной совокупности, сложность проведения опроса и требования к объему выборки (для получения результатов со сравнительно высокой степенью точности собственно случайный отбор требует достаточно большого объема выборки по сравнению с другими видами отбора).
Систематическая (механическая) выборка предусматривает отбор заданного числа респондентов через равные интервалы (шаги). В соответствии с данным методом сначала задают произвольную отправную точку, а затем из основы выборки последовательно выбирают каждую г-ю единицу. Интервал выборки к определяется как отношение объема генеральной совокупности N к объему выборочной совокупности п, с округлением результата до ближайшего целого числа. Первый респондент отбирается случайным образом, по таблице случайных чисел. Так как такой отбор производится из основы выборки, данный метод требует полного списка или заданного упорядочения совокупности.
Например, генеральная совокупность состоит из 100 тысяч элементов, а желательный объем выборки равен 1000 респондентов. В этом случае интервал выборки к равен 100. Выбирается случайное число между 1 и 100. Если, например, это число равно 23, то выборка состоит из таких единиц: 23,123, 223, 323,423,523 и т. д. Общей чертой систематического и простого случайного отбора является то, что каждый элемент генеральной совокупности имеет известную и равную вероятность отбора.
Когда генеральная совокупность слишком велика или исследователю известен не полный ее список, необходимо знать правило упорядочивания элементов в генеральной совокупности, так как интервал отбора может совпасть со скрытой периодичностью распределения признака в генеральной совокупности, а это приведет в свою очередь к смещениям. Если элементы совокупности расположены по принципу, не связанному с исследуемой характеристикой, результаты систематического отбора аналогичны результатам простого случайного отбора.
Если принцип расположения элементов связан с исследуемой характеристикой, систематический отбор увеличивает репрезентативность выборки. Так, например, если фирмы какой- либо отрасли расположены по принципу увеличения годового объема продаж, систематическая выборка будет включать как мелкие, так и крупные фирмы. Простой случайный отбор в этой ситуации может быть нерепрезентативным, приводя, например, к попаданию в выборку только мелких фирм, которых может к тому же оказаться непропорционально много.
Из-за простой техники отбора данный метод позволяет даже при небольшом объеме выборки изучать достаточно большие генеральные совокупности. Систематический отбор часто применяется при проведении почтовых и телефонных опросов, опросов в торговых центрах и в Интернет.
Стратифицированная случайная выборка
Стратифицированная случайная выборка — это вероятностная выборка, которая формируется в два этапа. На первом этапе генеральная совокупность подразделяется (расслаивается) на подгруппы (страты), взаимно исключающие и дополняющие одна другую таким образом, чтобы каждая единица совокупности относилась только к одной подгруппе и ни одна единица не была бы пропущена. Например, респондентов можно разбить по полу (мужчины и женщины), по возрасту (до 30 лет, с 31 до 50 лет, свыше 50 лет).
На втором этапе из каждой страты производится отбор единиц с помощью простого случайного отбора или других вероятностных методов. Если стратификация проводится по территориальному принципу, стратифицированную выборку называют районированной. Отличие стратифицированной выборки от квотной состоит в том, что единицы генеральной совокупности выбираются случайно, а не экспертным или нерепрезентативным методом. Примеры формирования стратифицированных выборок подробно рассмотрены в [15, 31, 34].
Стратифицированная выборка может быть пропорциональной и непропорциональной. При пропорциональном стратифицированном отборе объем выборки, полученной из каждой страты, пропорционален доле этой страты в объеме генеральной совокупности.
“При непропорциональном стратифицированном отборе объем выборки, полученной из каждой страты, пропорционален доле этого слоя в объеме генеральной совокупности и среднеквадратичному отклонению распределения исследуемой характеристики среди всех элементов этой страты” [31, с. 529] Так как данный метод отбора обеспечивает наличие в выборке всех важных подгрупп, он применяется при неоднородных генеральных совокупностях. Однако этот метод можно применять лишь при наличии дополнительной информации о генеральной совокупности (например, необходимо процентное соотношение мужчин и женщин в случае, если надо стратифицировать выборку по полу). Отсутствие такой информации делает применение стратифицированной выборки невозможным. Другим недостатком стратифицированной выборки является возможность систематической ошибки.
Кластерная выборка — вероятностный метод формирования выборки, предусматривающий реализацию двух этапов. На первом этапе генеральная совокупность подразделяется на кластеры — взаимоисключающие и взаимодополняющие подгруппы. По однородности критерии формирования кластеров прямо противоположны критериям формирования страт. Элементы кластера должны быть максимально разнородны, а сами кластеры — как можно более однородными. В идеале каждый кластер должен представлять собой небольшую модель генеральной совокупности.
На втором этапе с помощью простого случайного отбора формируется случайная выборка кластеров. В выборку либо включаются все элементы отобранного кластера, либо проводится их отбор вероятностным методом. Если в выборку включаются все единицы каждого отобранного кластера, то такой метод называется одноступенчатым кластерным отбором. Если выборка получена с помощью вероятностного отбора из каждого выбранного кластера, такая процедура называется двухступенчатым кластерным отбором.
Применение кластерной процедуры основано на четырех обязательных условиях [15, с. 219-222]:
“Основное различие между кластерным и стратифицированным отбором состоит в том, что в первом случае используются только отобранные подгруппы (кластеры), в то время как при стратифицированном отборе все подгруппы (страты) используются для дальнейшего отбора. Эти методы преследуют разные цели: цель кластерного отбора — увеличить эффективность отбора, уменьшив затраты на его проведение, а цель стратифицированного отбора — увеличить точность отбора” [31, с. 525]. Примеры формирования кластерных выборок подробно рассмотрены в [15, 31, 34].
“Одним из распространенных форм кластерного отбора является территориальный отбор, в котором кластеры состоят из округов, жилых районов, кварталов или других географических территорий. Если отбор основных элементов проводится в один этап (например, исследователь выбирает некоторые кварталы, а затем все проживающие там семьи включаются в выборку), такой выборочный метод называется одноступенчатым территориальным отбором. Отличительная черта одноступенчатого территориального отбора заключается в том, что все семьи из выбранных кварталов (или географических регионов) включаются в выборку. Если отбор основных элементов проводится в два (или больше) этапа (исследователь выбирает кварталы, а затем в каждом таком квартале отбирает семьи, которые будут включены в выборку), такой метод называется двухступенчатым (или многоступенчатым) территориальным отбором” [31, с. 525].
Достоинствами кластерного отбора является простота, оперативность и относительная дешевизна, а также удобство опроса респондентов, которые находятся вместе, а не разбросаны пространственно, а также то, что респонденты изучаются в их естественном окружении, что, конечно, влияет на качество получаемой первичной информации. Однако необходимо следить, чтобы количество групп в генеральной совокупности было достаточно большим, иначе не будет соблюдаться принцип случайности отбора. Также на практике бывает сложно сформировать неоднородные кластеры (например, семьи, живущие в одном квартале, имеют больше схожих признаков, чем различий) и на момент опроса застать всех членов кластера.

Чтобы посредством опроса получить максимально точные данные о какой-либо группе людей, например, о ее поведении и предпочтениях, было бы логично опросить эту группу целиком. Но что, если интересующая нас группа очень велика? Опрос всех потребителей молока в России или всех жителей Южного административного округа Москвы займет много времени и обойдется в астрономическую сумму денег. А нужно ли опрашивать их всех?
О размере выборки и статистической ошибке измерений подробно написано в статье «Выборка. Размер – не главное. Или главное» . В этой статье будет рассмотрено второе требование к выборке, также обеспечивающее качество исследования – репрезентативность.
Согласно теории выборочного метода, неоднократно подтвержденной практикой, опрашивать всех нет необходимости, а можно опросить лишь часть группы, которая может быть в тысячи раз меньше. Эта маленькая часть называется выборкой (или выборочной совокупностью), а большая группа, которую она представляет, называется генеральной совокупностью.
При этом если выборка сформирована правильно, выводы, полученные на основе изучения выборки, могут быть перенесены и на генеральную совокупность. Например, если в выборке женщины значимо чаще, чем мужчины, пользуются дезодорантами, то делается вывод, что и в генеральной совокупности (например, в исследованном городе) присутствует такая закономерность. Процесс переноса выводов с выборки на генеральную совокупность называется генерализацией. А свойство выборки отражать характеристики генеральной совокупности называется репрезентативностью. Для более комфортного запоминания термина на рис.1. приведены иллюстрации, когда выборка отражает свойства генеральной совокупности и когда свойства выборки отличаются от свойств генеральной совокупности.



Рис.1. Иллюстративные примеры соответствия (несоответствия) свойств генеральной совокупности и выборки
Не стоит путать понятие репрезентативности с такими понятиями как валидность и релевантность, хотя они тоже относятся к характеристикам качества исследования. В социальных науках валидность понимается довольно широко, но чаще всего – как обоснованность. Понятие валидности относится не к выборке, а к исследовательской методике. Методика или измерение (анкета, блок вопросов, тест) считается валидным, если фиксирует именно то понятие или свойство, которое планируется измерить. Например, если мы захотим оценить уровень лояльности клиента к магазину и выберем для этого лишь показатель частоты посещения магазина, валидность этого подхода будет неполной: возможно, респондент часто заходит в магазин только из-за банкомата, который там установлен. Валидная методика в данном примере должна включать и другие показатели: предпочтение магазина, суммы покупок в этом и других магазинах, готовность переключиться на другие магазины, готовность рекомендовать магазин и др.
При установлении валидности решающую роль играет обоснование и последующая проверка гипотезы релевантности, то есть соответствия измеряемых параметров характеристикам исследуемого объекта. Житейский пример нерелевантности – измерять уровень счастья человека количеством денег у него (хотя, наверное, не все с этим согласятся). Очевидный пример нерелевантности – попытка измерить массу тела по его температуре.
Но вернемся к понятию репрезентативности. В то время как точность измерений зависит от размера выборки, размер выборки не гарантирует ее репрезентативности. Репрезентативность выборки главным образом обеспечивается способом отбора ее участников (респондентов). Примером явного нарушения репрезентативности может послужить шутка о том, что интернет-опрос показал, что 100% людей пользуется интернетом.
Можно выделить несколько вариантов нарушения репрезентативности выборки: когда опрошены не те люди и когда опрошено слишком много (или мало) определенных людей (например, женщин намного больше, чем мужчин). Кроме того, чем меньше размер выборки, тем меньше вероятность того, что она будет репрезентативной. Например, допустим, 1% населения мог бы заинтересоваться новой услугой. Это 1 из 100 людей. Если размер выборки составляет всего 60 человек, то в вашей выборке может отсутствовать человек, который, скорее всего, будет заинтересован в услуге. Ваша выборка менее репрезентативна, потому что она меньше. Ваши результаты будут разными в зависимости от того, содержит ли ваша выборка одного из этих людей или нет. Пример репрезентативной и нерепрезентативной выборки показан на рис.2.

Рис.2. Пример репрезентативной и нерепрезентативной выборки
На рис.3 показана та же по составу генеральная совокупность, но с другим расположением объектов внутри круга.

Рис.3. Пример репрезентативной и нерепрезентативной выборки при другом расположении объектов генеральной совокупности
Говоря простым языком, репрезентативная выборка – это такая выборка, в которой представлены все подгруппы, важные для исследования. Помимо этого, характер распределения рассматриваемых параметров в выборке должен быть таким же, как в генеральной совокупности.
Простой случайный отбор респондентов представляется оптимальным способом формирования репрезентативной выборки. Поскольку в этом случае у любого представителя генеральной совокупности одинаковая вероятность попасть в выборку, в нее попадут люди с разными характеристиками пропорционально их долям в генеральной совокупности. В итоге выборка будет представлять собой нечто вроде уменьшенной копии генеральной совокупности.
Случайность отбора респондентов в выборку обеспечивается разными способами. Например, для телефонного опроса жителей города берется база данных всех телефонных номеров, и номера респондентов случайным образом выбираются компьютером (с использованием генератора случайных чисел). При уличном опросе интервьюеров распределяют по случайно выбранным точкам и инструктируют опрашивать каждого N-ного прохожего.
Наглядным примером репрезентативной выборки может служить пицца. Если целая пицца – это генеральная совокупность, которую мы хотим изучить, то кусок пиццы – это выборка. Как правило, достаточно одного куска пиццы, чтобы судить обо всей пицце (при условии, что ингредиенты равномерно распределены по ее поверхности). Таким образом, кусок пиццы пиццы на рис.4 – это репрезентативная выборка из пиццы.

Рис.4. Наглядный пример репрезентативной выборки (пицца)
Важно отметить, что не любой кусок пиццы будет репрезентативной выборкой. Разные способы получения куска пиццы могут принципиально повлиять на качество исследования и выводы, которые будут получены при анализе каждого варианта выборки (рис.4)
(рисунок в сушильной камере, готовится к публикации)
Рис.5. Наглядный пример формирования репрезентативной и нерепрезентативной выборки.
Еще один показательный пример формирования репрезентативной выборки – кастрюля, содержимое которой мы должны узнать (допустим, там скрывается борщ). Мы только один раз можем зачерпнуть из кастрюли ложкой (провести исследование). В нашем примере ложка – это выборка, а содержимое кастрюли – генеральная совокупность.
Если мы зачерпнем сверху, то придем к выводу, что в кастрюле бульон. Если снизу – решим, что в кастрюле мясо. Зачерпнув где-то посередине, мы получим картошку или капусту. В любом из трех случаев выводы будут неверны. Чтобы получить достоверный результат, нам стоит хорошенько перемешать содержимое кастрюли, перед тем как пробовать его. Перемешивание в данном случае – аналог процедуры простого случайного отбора, поскольку оно предоставляет всем ингредиентам примерно равную вероятность попадания в ложку-выборку (или тарелку-выборку).

Рис.6. Борщ как модель, демонстрирующая репрезентативность выборки.
В реальности применить простой случайный отбор респондентов не всегда удается в полной мере. Например, мы можем абсолютно корректно отобрать в выборку нужное количество номеров домашних телефонов случайным образом, но при их прозвоне выяснится, что дозвониться и поговорить удается преимущественно с пенсионерами, а «поймать» дома молодежь и работающих людей получается плохо.
Возвращаясь к примеру с борщом, если у нас вместо кастрюли – огромный ресторанный котел, а в руках все та же обычная ложка, перемешивание будет неэффективным. Чтобы решить задачу, потребуются иные подходы. Например, мы можем теоретически разделить глубину котла на несколько слоев и постараться зачерпнуть содержимое из каждого слоя (из случайного места слоя: не только в центре, но и по краям). Таким образом, наша итоговая выборка будет состоять уже из нескольких выборок и при этом адекватно отражать содержимое всех слоев котла. Подобные альтернативные подходы называются типами выборки, которых придумано достаточно много для того, чтобы максимизировать репрезентативность выборки в сложных условиях реального мира.
Последствия нарушения репрезентативности выборки: некорректные выводы исследования, выброшенный на ветер бюджет исследования, финансовые потери вследствие применения неправильных выводов. Вы можете выбрать валидную исследовательскую методику, рассчитать объем выборки, обеспечивающий приемлемую точность измерений, но, если выборка исследования нерепрезентативна, получить достоверную информацию не удастся.
Самым известным примером нарушения репрезентативности выборки является история провала американского журнала «Литературный дайджест».
В 1936 году журнал в очередной раз провел почтовый опрос общественного мнения о вероятных результатах грядущих президентских выборов в США. До 1936 года опрос всегда правильно предсказывал победителя. Опрос 1936 года показал, что победителем с большим отрывом станет кандидат от республиканцев, но в итоге победителем оказался представитель демократов.
Таким образом, гигантская выборка (около 2,4 млн. человек) не обеспечила достоверных результатов. В чем же заключалась причина ошибки?
Называются две основные причины провала: смещение при формировании выборки и смещение вследствие отказа респондентов от участия в опросе.
Прежде всего, журнал включил своих подписчиков в список для рассылки анкет и, желая расширить выборку, использовал два других доступных тогда списка граждан: зарегистрированных автовладельцев и пользователей телефонов. Во времена Великой Депрессии представители этих групп отличались от остального населения более высоким доходом, как и подписчики самого журнала. Таким образом, полученная база для рассылки не являлась корректным отражением структуры населения США.
Вторая проблема с опросом заключалась в том, что из 10 миллионов человек, чьи имена были в первоначальном списке рассылки, только 2,4 миллиона ответили на опрос. Вероятно, высокий процент отказов был связан с тем, что опрос проводился по почте. Уже в те времена американцы относились к почтовым рассылкам как к спаму. Таким образом, размер выборки составил примерно одну четверть от того, что первоначально планировалось. Когда доля ответивших низка (как это было в данном случае), считается, что исследование страдает от необъективности ответов.
У этой истории две морали: Большая, но неправильно сформированная выборка гораздо хуже маленькой, но правильно сформированной выборки. При проведении опроса не упускайте из внимания смещение отбора и смещение в результате отказов.
Пример из военной практики. Во Вторую мировую войну американские военные столкнулись со следующей проблемой. Не все американские бомбардировщики после задания возвращались на базу. На вернувшихся самолетах оставалось множество пробоин от выстрелов противника, но распределены они были неравномерно: больше всего на фюзеляже и прочих частях, меньше в топливной системе и гораздо меньше — в двигателе. Командованию казалось логичным, что в наиболее поврежденных местах нужно установить больше брони.
Привлеченный к решению задачи математик возразил: данные как раз показывают, что самолет, получивший пробоины в этих местах, еще может вернуться на базу. А самолет, которому попали в бензобак или двигатель, выходит из строя и не возвращается. Поэтому укреплять следует те места, которые у вернувшихся самолетов повреждены меньше всего.

Рис .7. Пробоины на вернувшихся самолётах.
Получившие повреждения в других местах не смогли вернуться на базу
Эта задача служит примером нарушения репрезентативности выборки, когда в нее включены не те респонденты: в данном случае, вернувшиеся самолеты, в то время как не вернувшиеся проигнорированы.
Применительно к маркетинговым исследованиям, эта ситуация подобна следующей. При опросе клиентов бизнеса будет ошибкой опрашивать только текущих клиентов и не опрашивать потерянных клиентов (а какие «пробоины» получили они?).
При опросе посетителей ТРЦ важно правильно расставить интервьюеров. Например, если поставить интервьюеров только у главного входа, в выборку не попадут посетители, приехавшие в ТРЦ на автомобиле и попавшие в него через парковку. Как следствие, выводы, полученные на собранных данных, будут корректны только для той части посетителей, которые приходят в ТРЦ пешком, а значит, делают меньше покупок, не покупают габаритные товары, живут ближе к ТРЦ, чем приезжающие на автомобиле.
Другой пример. Бывает, что в разных районах города сбор анкет идет с разной скоростью: где-то (например, в центре города) большой пешеходный поток и у людей есть время на участие в опросе (отдыхающие, в отпуске, офисные сотрудники на обеде), а на окраинах либо мало людей на улицах, либо все спешат на работу и отказываются участвовать. В результате, если не ограничивать доли районов, в выборке будут преобладать люди из центрального района, которые могут значимо отличаться от остальных людей родом занятий, уровнем дохода и образования, уровнем осведомленности о магазинах и др. Таким образом, собранная выборка уже не будет репрезентативной по отношению к населению всего города.
Несмотря на многие положительные стороны онлайн-опросов, такие как экономичность, оперативность сбора информации, удобство ее обработки и т. д., некоторые их особенности напрямую угрожают репрезентативности исследования:
Во-первых, участники онлайн-опросов – это, как правило, активные пользователи интернета, хорошо в нем разбирающиеся и больше подверженные влиянию интернет-культуры, чем обычные люди.
Во-вторых, люди, у которых есть время и желание регулярно участвовать в онлайн-опросах за небольшое вознаграждение, скорее всего, значительно отличаются от остальных людей как по социально-демографическим, так и по психографическим характеристикам.
В-третьих, профессиональное участие в опросах приводит к так называемой профессиональной деформации, когда ответы респондентов на вопросы новых исследований обусловлены предыдущим опытом, но не жизненным, а опытом участия в других опросах.
Таким образом, в данном случае возникает та ситуация, когда опрашиваются не те люди, хотя по формальным характеристикам они подходят под описание целевой аудитории.
Итак, чтобы получить достаточно точные данные об интересующей нас группе людей, необязательно опрашивать их всех, благодаря свойству репрезентативности выборки.
«Чем больше, тем лучше» – неправильный подход к формированию выборки.
Небольшая репрезентативная выборка лучше большой, но нерепрезентативной выборки. Применительно к выборке не стоит пугаться слова «случайная». Это вовсе не значит, что в исследовании будут получены случайные результаты. Напротив, случайный подход к формированию выборки делает ее максимально похожей на генеральную совокупность, а значит, репрезентативной.
При проектировании выборки следует учитывать опасность смещения структуры выборки вследствие особенностей сбора информации и других условий.