
-
Оценка достоверности результатов исследования. Ошибка средней арифметической и относительных показателей.
Достоверность
результатов исследования — рассчитываются:
-
ошибка
средней арифметической -
доверительные
границы средней арифметической -
достоверность
разности результатов исследования
Ошибка
средней арифметической
— это поправка к результату выборочного
исследования. Величина ошибки (m)
показывает на сколько М отличается от
результата, который был бы получен при
исследовании всей генеральной
совокупности. Ошибка
рассчитывается по формуле:

Оценка
достоверности результатов исследования.
В
своих исследованиях врачу, как правило,
приходится иметь дело с частью изучаемого
явления (выборочной совокупностью), а
выводы переносить на все явление в целом
(генеральную совокупность). Для
этого рассчитываются:
Ошибка
относительного показателя
— это поправка к результату выборочного
исследования (Р). Величина ошибки (mp)
показывает на сколько Р отличается от
результата, который был бы получен при
исследовании всей генеральной
совокупности. Ошибка
рассчитывается по формуле:

-
Оценка достоверности результатов исследования. (Доверительные границы средних и относительных величин, их применение в медицине.)
Формулы
определения доверительных границ
представлены следующим образом:
для
средних величин (М):
Мген = Мвыб ± tm
для
относительных показателей (Р):
Рген = Рвыб ± tm
где
Мген и Рген — соответственно, значения
средней величины и относительного
показателя генеральной совокупности;
Мвы6
и
Рвы6
— значения средней величины и относительного
показателя выборочной совокупности;
m
— ошибка репрезентативности;
t
— критерий достоверности (доверительный
коэффициент).
Для
большинства медико-биологических
исследований
считается достаточной степень вероятности
безошибочного прогноза, равная 95%, а
число случаев генеральной совокупности,
в котором могут наблюдаться отклонения
от закономерностей, установленных при
выборочном исследовании, не будут
превышать 5%. При ряде исследований,
связанных, например, с применением
высокотоксичных веществ, вакцин,
оперативного лечения и т.п., в результате
чего возможны тяжелые заболевания,
осложнения, летальные исходы, применяется
степень вероятности Р = 99,7%, т.е. не более
чем у 1% случаев генеральной совокупности
возможны отклонения от закономерностей,
установленных в выборочной совокупности.
Ошибка
средней арифметической(М)=Q(cреднее
квадротичное отклонение)корень из
n(число наблюдений)
Ошибка
относительного показателя
(m)=кореню из отношения произведения
P(показателя выр в проц) и q(выраженном
в зависимотси от того в чём выражено Р)
к n.
Доверительные
границы относительного
показателя показывают в каких пределах
можно доверять результатам выборочного
исследования ( как он будет колебаться
) при переносе его на всю генеральную
совокупность ( Р ) с определенной долей
вероятности (t).
Коэффициент
достоверности (вероятности) может
выражаться в единицах или в процентах:
t
— 1 = 68,3%
t
— 2 = 95,5 %
t
— 3 = 99,7%
Для
большинства медико-биологических
исследований достаточной считается
вероятность равная 95,5%.
Доверительные
границы рассчитываются по формуле
Р
= Р ±
tm
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Вариант 1
Задание 1. Модель парной линейной регрессии.
Имеются данные о размере среднемесячных доходов в разных группах семей
|
Номер группы |
Среднедушевой денежный доход в месяц, руб., X |
Доля оплаты труда в структуре доходов семьи, %, Y |
|
1 |
79,8 |
64,2 |
|
2 |
152,1 |
66,1 |
|
3 |
199,3 |
69,0 |
|
4 |
240,8 |
70,6 |
|
5 |
282,4 |
72,4 |
|
6 |
301,8 |
74,3 |
|
7 |
385,3 |
76,0 |
|
8 |
457,8 |
77,1 |
|
9 |
577,4 |
78,4 |
Задания:
1. Рассчитать линейный коэффициент парной корреляции, оценить его статистическую значимость и построить для него доверительный интервал с уровнем значимости a =0,05. Сделать выводы
2. Построить линейное уравнение парной регрессии Y на X и оценить статистическую значимость параметров регрессии. Сделать рисунок.
3. Оценить качество уравнения регрессии при помощи коэффициента детерминации. Сделать выводы. Проверить качество уравнения регрессии при помощи F-критерия Фишера.
4. Выполнить прогноз доли оплаты труда структуре доходов семьи Y при прогнозном значении среднедушевого денежного дохода X, составляющем 111% от среднего уровня. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал для уровня значимости a =0,05. Сделать выводы.
Решение: Построим поле корреляции зависимости доли оплаты труда в структуре доходов семьи от среднедушевого денежного дохода в месяц.
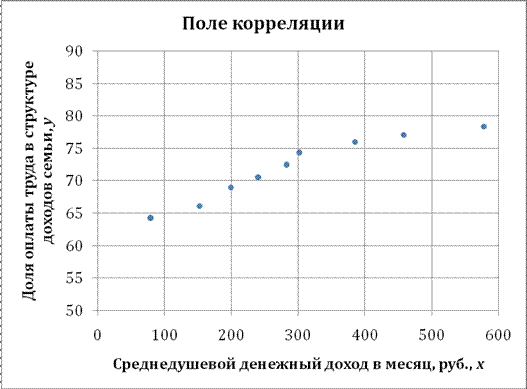
Точки на построенном графике размещаются вблизи кривой, напоминающей по форме Прямую, поэтому можно предположить, что между указанными величинами существует Линейная зависимость вида ![]() .
.
Для расчета линейного коэффициента парной корреляции и параметров линейной регрессии составим вспомогательную таблицу.
|
№ п/п |
X |
Y |
X×Y |
X2 |
Y2 |
|
1 |
79,8 |
64,2 |
5123,16 |
6368,04 |
4121,64 |
|
2 |
152,1 |
66,1 |
10053,81 |
23134,41 |
4369,21 |
|
3 |
199,3 |
69,0 |
13751,70 |
39720,49 |
4761,00 |
|
4 |
240,8 |
70,6 |
17000,48 |
57984,64 |
4984,36 |
|
5 |
282,4 |
72,4 |
20445,76 |
79749,76 |
5241,76 |
|
6 |
301,8 |
74,3 |
22423,74 |
91083,24 |
5520,49 |
|
7 |
385,3 |
76,0 |
29282,80 |
148456,09 |
5776,00 |
|
8 |
457,8 |
77,1 |
35296,38 |
209580,84 |
5944,41 |
|
9 |
577,4 |
78,4 |
45268,16 |
333390,76 |
6146,56 |
|
S |
2676,7 |
648,1 |
198645,99 |
989468,27 |
46865,43 |
|
Среднее |
297,41 |
72,01 |
22071,78 |
109940,92 |
5207,27 |
Вычислим коэффициент корреляции. Используем следующую формулу:

![]() = 0,9568.
= 0,9568.
Можно сказать, что между рассматриваемыми признаками существует Прямая тесная Корреляционная связь.
Среднюю ошибку коэффициента корреляции определим по формуле:
![]() = 0,032.
= 0,032.
Найдем табличное значение TТабл по таблице распределения Стьюдента для
a = 0,05 и числе степеней свободы K = N – M – 1 = 9 – 1 – 1 = 7.
TТабл(0,05; 7) = 2,36.
Запишем доверительный интервал для коэффициента корреляции.
![]()
![]()
Доверительный интервал не включает число 0, поэтому при заданном уровне значимости коэффициент корреляции является статистически значимым.
Вычислим параметры уравнения регрессии.
![]() = 0,03.
= 0,03.
![]() = 72,01 – 0,03×297,41 = 63,09.
= 72,01 – 0,03×297,41 = 63,09.
Получим следующее уравнение: ![]() .
.
Для проверки статистической значимости (существенности) линейного коэффициента парной корреляции рассчитаем T-критерий Стьюдента по формуле:
 = 23,04.
= 23,04.
Фактическое значение по абсолютной величине больше табличного, что свидетельствует о значимости линейного коэффициента корреляции и существенности связи между рассматриваемыми признаками.
Проверим значимость оценок теоретических коэффициентов регрессии с помощью t-статистики Стьюдента и сделаем соответствующие выводы о значимости этих оценок.
Для определения статистической значимости коэффициентов A и B найдем T-статистики Стьюдента:
Рассчитаем по полученному уравнению теоретические значения![]() . Составим вспомогательную таблицу.
. Составим вспомогательную таблицу.
|
№ п/п |
X |
Y |
|
|
|
|
1 |
79,8 |
64,2 |
65,48 |
1,6384 |
47354,1 |
|
2 |
152,1 |
66,1 |
67,65 |
2,4025 |
21115,0 |
|
3 |
199,3 |
69,0 |
69,07 |
0,0049 |
9625,6 |
|
4 |
240,8 |
70,6 |
70,31 |
0,0841 |
3204,7 |
|
5 |
282,4 |
72,4 |
71,56 |
0,7056 |
225,3 |
|
6 |
301,8 |
74,3 |
72,14 |
4,6656 |
19,3 |
|
7 |
385,3 |
76,0 |
74,65 |
1,8225 |
7724,7 |
|
8 |
457,8 |
77,1 |
76,82 |
0,0784 |
25725,0 |
|
9 |
577,4 |
78,4 |
80,41 |
4,0401 |
78394,4 |
|
S |
2676,7 |
648,1 |
648,09 |
15,4421 |
193388,1 |
Вычислим стандартные ошибки коэффициентов уравнения.
 = 1,2.
= 1,2.
 = 0,003.
= 0,003.
Вычислим T-статистики.
![]()
![]()
Сравнение расчетных и табличных величин критерия Стьюдента показывает, что ![]() и
и ![]() , т. е. оценки A и B теоретических коэффициентов регрессии статистически значимы.
, т. е. оценки A и B теоретических коэффициентов регрессии статистически значимы.
Сделаем рисунок.

Рассчитаем коэффициент детерминации: ![]() = 0,95682= 0,915 = 91,5%.
= 0,95682= 0,915 = 91,5%.
Таким образом, вариация результата Y на 91,5% объясняется вариацией фактора X.
Оценку значимости уравнения регрессии проведем с помощью F-критерия Фишера:
 = 75,81.
= 75,81.
Найдем табличное значение Fтабл по таблице критических точек Фишера для
a = 0,05; K1 = M = 1 (число факторов), K2 = N – M – 1 = 9 – 1 – 1 = 7.
Fтабл(0,05; 1; 7) = 5,59.
Поскольку F > FТабл, уравнение регрессии с вероятностью 0,95 в целом Является статистически значимым.
Выполним прогноз доли оплаты труда структуре доходов семьи y при прогнозном значении среднедушевого денежного дохода x, составляющем 111% от среднего уровня.
XP = 297,41 × 1,11 = 330,1.
Вычислим прогнозное значение Yp с помощью уравнения регрессии.
![]() » 73%.
» 73%.
Доверительный интервал прогноза имеет вид
(УP – Tкр×My, УP + Tкр×My),
Где  , M = 2 – число параметров уравнения.
, M = 2 – число параметров уравнения.
 = 1,695 » 1,7.
= 1,695 » 1,7.
Запишем доверительный интервал прогноза:
![]() Þ
Þ ![]()
Данный прогноз является надежным, поскольку доверительный интервал не включает число 0, точность прогноза составляет 4.
Задание 2. Модель парной нелинейной регрессии.
По территориям Центрального района известны данные за 1995 г.
|
Район |
Прожиточный минимум в среднем на одного пенсионера в месяц, тыс. руб., X |
Средний размер назначенных ежемесячных пенсий, тыс. руб., Y |
|
Брянская обл. |
178 |
240 |
|
Владимирская обл. |
202 |
226 |
|
Ивановская обл. |
197 |
221 |
|
Калужская обл. |
201 |
226 |
|
Костромская обл. |
189 |
220 |
|
Орловская обл. |
166 |
232 |
|
Рязанская обл. |
199 |
215 |
|
Смоленская обл. |
180 |
220 |
|
Тверская обл. |
181 |
222 |
|
Тульская обл. |
186 |
231 |
|
Ярославская обл. |
250 |
229 |
Задания:
1. Построить поле корреляции и сформулируйте гипотезу о форме связи. Рассчитать параметры уравнений полулогарифмической (![]() ) и степенной (
) и степенной (![]() ) парной регрессии. Сделать рисунки.
) парной регрессии. Сделать рисунки.
2. Дать с помощью среднего коэффициента эластичности сравнительную оценку силы связи фактора с результатом для каждой модели. Сделать выводы. Оценить качество уравнений регрессии с помощью средней ошибки аппроксимации и коэффициента детерминации. Сделать выводы.
3. По значениям рассчитанных характеристик выбрать лучшее уравнение регрессии. Дать экономический смысл коэффициентов выбранного уравнения регрессии
4. Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости a =0,05. Сделать выводы.
Решение: Решение: Для предварительного определения вида связи между указанными признаками построим поле корреляции. Для этого построим в системе координат точки, у которых первая координата X, а вторая – Y.
Получим следующий рисунок.

По внешнему виду диаграммы рассеяния трудно предположить, какая зависимость существует между указанными показателями.
Построение полулогарифмической модели регрессии.
Уравнение логарифмической кривой: ![]() .
.
Обозначим: ![]()
Получим линейное уравнение регрессии:
Y = A + B×X.
Произведем линеаризацию модели путем замены ![]() . В результате получим линейное уравнение
. В результате получим линейное уравнение ![]() .
.
Рассчитаем его параметры, используя данные таблицы.
|
№ п/п |
X |
Y |
X = ln(X) |
Xy |
X2 |
Y2 |
|
|
|
Ai |
|
1 |
178 |
240 |
5,1818 |
1243,63 |
26,85 |
57600 |
226,40 |
206,314 |
184,904 |
6,006 |
|
2 |
202 |
226 |
5,3083 |
1199,67 |
28,18 |
51076 |
225,17 |
0,132 |
0,694 |
0,370 |
|
3 |
197 |
221 |
5,2832 |
1167,59 |
27,91 |
48841 |
225,41 |
21,496 |
19,464 |
1,957 |
|
4 |
201 |
226 |
5,3033 |
1198,55 |
28,13 |
51076 |
225,22 |
0,132 |
0,615 |
0,348 |
|
5 |
189 |
220 |
5,2417 |
1153,18 |
27,48 |
48400 |
225,82 |
31,769 |
33,833 |
2,576 |
|
6 |
166 |
232 |
5,1120 |
1185,98 |
26,13 |
53824 |
227,08 |
40,496 |
24,172 |
2,165 |
|
7 |
199 |
215 |
5,2933 |
1138,06 |
28,02 |
46225 |
225,31 |
113,132 |
106,362 |
4,577 |
|
8 |
180 |
220 |
5,1930 |
1142,45 |
26,97 |
48400 |
226,29 |
31,769 |
39,601 |
2,781 |
|
9 |
181 |
222 |
5,1985 |
1154,07 |
27,02 |
49284 |
226,24 |
13,223 |
17,968 |
1,874 |
|
10 |
186 |
231 |
5,2257 |
1207,15 |
27,31 |
53361 |
225,97 |
28,769 |
25,273 |
2,225 |
|
11 |
250 |
229 |
5,5215 |
1264,41 |
30,49 |
52441 |
223,09 |
11,314 |
34,980 |
2,651 |
|
Итого |
2129 |
2482 |
57,862 |
13054,74 |
304,48 |
560528 |
2482,00 |
498,545 |
487,867 |
27,530 |
|
Среднее |
193,5 |
225,6 |
5,260 |
1186,79 |
27,68 |
50957,091 |
225,636 |
45,322 |
44,352 |
2,503 |
![]() = -9,76.
= -9,76.
![]() = 225,6 – (-9,76)×5,26 = 276,99.
= 225,6 – (-9,76)×5,26 = 276,99.
Уравнение модели имеет вид: ![]()
Определим индекс корреляции 
Используя данные таблицы, получим:
 .
.
Рассчитаем коэффициент детерминации: ![]() = 0,14642= 0,021 = 2,1%.
= 0,14642= 0,021 = 2,1%.
Вариация результата Y всего на 2,1% объясняется вариацией фактора X.
Сделаем рисунок.

Рассчитаем средний коэффициент эластичности по формуле:
![]() = -0,04%.
= -0,04%.
Коэффициент эластичности ![]() показывает, что при среднем росте признака X на 1% признак Y снижается на 0,04%.
показывает, что при среднем росте признака X на 1% признак Y снижается на 0,04%.
Вычислим среднюю ошибку аппроксимации. Используя данные расчетной таблицы, получаем:
![]() = 2,5%.
= 2,5%.
Построение степенной модели парной регрессии.
Уравнение степенной модели имеет вид: ![]() .
.
Для построения этой модели необходимо произвести линеаризацию переменных. Для этого произведем логарифмирование обеих частей уравнения:
![]() .
.
Произведем линеаризацию модели путем замены ![]() и
и ![]() . В результате получим линейное уравнение
. В результате получим линейное уравнение ![]() .
.
Рассчитаем его параметры, используя данные таблицы.
|
№ п/п |
X |
Y |
X = ln(X) |
Y = ln(Y) |
XY |
X2 |
Y2 |
|
|
|
|
Ai |
|
1 |
178 |
240 |
5,1818 |
5,4806 |
28,3995 |
26,851 |
30,037 |
226,3 |
206,3 |
188,391 |
241,661 |
6,07 |
|
2 |
202 |
226 |
5,3083 |
5,4205 |
28,7737 |
28,178 |
29,382 |
225,1 |
0,132 |
0,835 |
71,479 |
0,406 |
|
3 |
197 |
221 |
5,2832 |
5,3982 |
28,5196 |
27,912 |
29,140 |
225,3 |
21,496 |
18,671 |
11,934 |
1,918 |
|
4 |
201 |
226 |
5,3033 |
5,4205 |
28,7467 |
28,125 |
29,382 |
225,1 |
0,132 |
0,753 |
55,570 |
0,385 |
|
5 |
189 |
220 |
5,2417 |
5,3936 |
28,2720 |
27,476 |
29,091 |
225,7 |
31,769 |
32,607 |
20,661 |
2,530 |
|
6 |
166 |
232 |
5,1120 |
5,4467 |
27,8437 |
26,132 |
29,667 |
226,9 |
40,496 |
25,675 |
758,752 |
2,233 |
|
7 |
199 |
215 |
5,2933 |
5,3706 |
28,4284 |
28,019 |
28,844 |
225,2 |
113,132 |
104,576 |
29,752 |
4,540 |
|
8 |
180 |
220 |
5,1930 |
5,3936 |
28,0089 |
26,967 |
29,091 |
226,2 |
31,769 |
38,059 |
183,479 |
2,728 |
|
9 |
181 |
222 |
5,1985 |
5,4027 |
28,0858 |
27,024 |
29,189 |
226,1 |
13,223 |
16,950 |
157,388 |
1,821 |
|
10 |
186 |
231 |
5,2257 |
5,4424 |
28,4407 |
27,308 |
29,620 |
225,9 |
28,769 |
26,413 |
56,934 |
2,275 |
|
11 |
250 |
229 |
5,5215 |
5,4337 |
30,0021 |
30,487 |
29,525 |
223,1 |
11,314 |
34,846 |
3187,116 |
2,646 |
|
Итого |
2129 |
2482 |
57,862 |
59,603 |
313,521 |
304,479 |
322,969 |
2480,927 |
498,545 |
487,777 |
4774,727 |
27,548 |
|
Среднее |
193,5 |
225,6 |
5,260 |
5,418 |
28,502 |
27,680 |
29,361 |
225,539 |
45,322 |
44,343 |
434,066 |
2,504 |
С учетом введенных обозначений уравнение примет вид: Y = A + BX – линейное уравнение регрессии. Рассчитаем его параметры, используя данные таблицы.
![]() = -0,042.
= -0,042.
![]() = 5,418 – 0,959×5,26 = 5,637.
= 5,418 – 0,959×5,26 = 5,637.
Перейдем к исходным переменным X и Y, выполнив потенцирование данного уравнения.
A = eA = e5,637 = 280,76
Получим уравнение степенной модели регрессии: ![]() .
.
Определим индекс корреляции
Используя данные таблицы, получим:
 .
.
Рассчитаем коэффициент детерминации: ![]() = 0,1472= 0,021 = 2,1%.
= 0,1472= 0,021 = 2,1%.
Вариация результата Y всего на 2,1% объясняется вариацией фактора X.
Сделаем рисунок.

Для степенной модели средний коэффициент эластичности равен коэффициенту B.
![]() = -0,042%.
= -0,042%.
Коэффициент эластичности ![]() показывает, что при среднем росте признака X на 1% признак Y снижается на 0,042%.
показывает, что при среднем росте признака X на 1% признак Y снижается на 0,042%.
Вычислим среднюю ошибку аппроксимации. Используя данные расчетной таблицы, получаем:
![]() = 2,5%.
= 2,5%.
Сводная таблица вычислений
|
Параметры |
Модель |
|
|
Полулогарифмическая |
Степенная |
|
|
Уравнение связи |
|
|
|
Индекс корреляции |
0,1464 |
0,147 |
|
Коэффициент детерминации |
0,021 |
0,021 |
|
Средняя ошибка аппроксимации, % |
2,5 |
2,5 |
Для выявления формы связи между указанными признаками были построены полулогарифмическая и степенная модели регрессии. Анализ показателей корреляции, а также оценка качества моделей с использованием средней ошибки аппроксимации позволил предположить, что из перечисленных моделей более адекватной является степенная модель, поскольку для нее индекс корреляции принимает наибольшее значение R = 0,147, свидетельствующий о том, что между рассматриваемыми признаками наблюдается Слабая корреляционная связь.
Рассчитаем прогнозное значение результата по степенной модели регрессии, если прогнозируется увеличение значения фактора на 10% от среднего уровня.
Прогнозное значение составит:
![]() = 193,5 × 1,1 = 212,9 тыс. р., тогда прогнозное значение Y составит:
= 193,5 × 1,1 = 212,9 тыс. р., тогда прогнозное значение Y составит:
![]() = 224,6 тыс. р.
= 224,6 тыс. р.
Определим доверительный интервал прогноза для уровня значимости a = 0,05.
Вычислим Среднюю стандартную ошибку прогноза ![]() По следующей формуле:
По следующей формуле:
 , где
, где ![]()
Получаем:  = 7,55.
= 7,55.
Найдем предельную ошибку прогноза ![]() , где для доверительной вероятности 0,95 значение T составляет 1,96.
, где для доверительной вероятности 0,95 значение T составляет 1,96.
![]() = 14,8.
= 14,8.
Запишем доверительный интервал прогноза.
![]() = 224,6 – 14,8 = 209,8 тыс. р.
= 224,6 – 14,8 = 209,8 тыс. р.
![]() = 224,6 + 14,8 = 239,4 тыс. р.
= 224,6 + 14,8 = 239,4 тыс. р.
Таким образом, с вероятностью 0,95 можно утверждать, что прогнозное значение среднего размера назначенных ежемесячных пенсий будет находиться в пределах от 209,8 тыс. р. до 239,4 тыс. р.
Задание 3. Моделирование временных рядов
Имеются поквартальные данные по розничному товарообороту России в 1995-1999 гг.
|
Номер квартала |
Товарооборот % к предыдущему периоду |
Номер квартала |
Товарооборот % к предыдущему периоду |
|
1 |
100 |
11 |
98,8 |
|
2 |
93,9 |
12 |
101,9 |
|
3 |
96,5 |
13 |
113,1 |
|
4 |
101,8 |
14 |
98,4 |
|
5 |
107,8 |
15 |
97,3 |
|
6 |
96,3 |
16 |
112,1 |
|
7 |
95,7 |
17 |
97,6 |
|
8 |
98,2 |
18 |
93,7 |
|
9 |
104 |
19 |
114,3 |
|
10 |
99 |
20 |
108,4 |
Задания:
1. Построить график данного временного ряда. Охарактеризовать структуру этого ряда.
2. Рассчитать сезонную компоненты временного ряда и построить его Мультипликативную Модель.
3. Рассчитать трендовую компоненту временного ряда и построить его график
4. Оценить качество модели через показатели средней абсолютной ошибки и среднего относительного отклонения.
Решение: Пронумеруем указанные месяцы от 1 до 24 и построим график временного ряда.

Полученный график показывает, что а данном временном ряду присутствуют сезонные колебания.
Построим мультипликативную модель временного ряда.
Эта модель предполагает, что каждый уровень временного ряда может быть представлен как произведение трендовой (T), сезонной (S) и случайной (E) компонент.
Построение мультипликативной моделей сведем к расчету значений T, S и E для каждого уровня ряда.
Процесс построения модели включает в себя следующие шаги.
1) Выравнивание исходного ряда методом скользящей средней.
2) Расчет значений сезонной компоненты S.
3) Устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных T×E.
4) Аналитическое выравнивание уровней T×E и расчет значений T с использованием полученного уравнения тренда.
5) Расчет полученных по модели значений T×E.
6) Расчет абсолютных и/или относительных ошибок.
Шаг 1. Проведем выравнивание исходных уровней ряда методом скользящей средней. Для этого:
1.1. Просуммируем уровни ряда последовательно за каждые четыре месяца со сдвигом на один момент времени и определим условные годовые уровни объема продаж (гр. 3 табл. 2.1).
1.2. Разделив полученные суммы на 4, найдем скользящие средние (гр. 4 табл. 2.1). Полученные таким образом выровненные значения уже не содержат сезонной компоненты.
1.3. Приведем эти значения в соответствие с фактическими моментами времени, для чего найдем средние значения из двух последовательных скользящих средних – центрированные скользящие средние (гр. 5 табл. 2.1).
Таблица 2.1
|
№ месяца, T |
Товарооборот, Yi |
Итого за четыре месяца |
Скользящая средняя за четыре месяца |
Центрированная скользящая средняя |
Оценка сезонной компоненты |
|
1 |
2 |
3 |
4 |
5 |
6 |
|
1 |
100,0 |
– |
– |
– |
– |
|
2 |
93,9 |
392 |
98 |
– |
– |
|
3 |
96,5 |
400 |
100 |
99 |
0,975 |
|
4 |
101,8 |
402 |
100,5 |
100,25 |
1,015 |
|
5 |
107,8 |
402 |
100,5 |
100,5 |
1,073 |
|
6 |
96,3 |
398 |
99,5 |
100 |
0,963 |
|
7 |
95,7 |
394 |
98,5 |
99 |
0,967 |
|
8 |
98,2 |
397 |
99,25 |
98,875 |
0,993 |
|
9 |
104,0 |
400 |
100 |
99,625 |
1,044 |
|
10 |
99,0 |
404 |
101 |
100,5 |
0,985 |
|
11 |
98,8 |
413 |
103,25 |
102,125 |
0,967 |
|
12 |
101,9 |
412 |
103 |
103,125 |
0,988 |
|
13 |
113,1 |
411 |
102,75 |
102,875 |
1,099 |
|
14 |
98,4 |
309 |
77,25 |
90 |
1,093 |
|
15 |
97,3 |
196 |
49 |
63,125 |
1,541 |
|
16 |
112,1 |
303 |
75,75 |
62,375 |
1,797 |
|
17 |
97,6 |
418 |
104,5 |
90,125 |
1,083 |
|
18 |
93,7 |
414 |
103,5 |
104 |
0,901 |
|
19 |
114,3 |
– |
– |
– |
– |
|
20 |
108,4 |
– |
– |
– |
– |
Шаг 2. Найдем оценки сезонной компоненты как частное от деления фактических уровней ряда на центрированные скользящие средние (гр. 6 табл. 2.1). Эти оценки используются для расчета сезонной компоненты S (табл. 2.2). Для этого найдем средние за каждый месяц оценки сезонной компоненты Si. Так же как и в аддитивной модели считается, что сезонные воздействия за период взаимопогашаются. В мультипликативной модели это выражается в том, что сумма значений сезонной компоненты по всем месяцам должна быть равна числу периодов в цикле. В нашем случае число периодов одного цикла равно 4.
Таблица 2.2
|
Показатели |
Год |
№ квартала, I |
|||
|
I |
II |
III |
IV |
||
|
1 |
– |
– |
0,975 |
1,015 |
|
|
2 |
1,073 |
0,963 |
0,967 |
0,993 |
|
|
3 |
1,044 |
0,985 |
0,967 |
0,988 |
|
|
4 |
1,099 |
1,093 |
1,541 |
1,797 |
|
|
5 |
1,083 |
0,901 |
– |
– |
|
|
Всего за I-й квартал |
4,299 |
3,942 |
4,45 |
4,793 |
|
|
Средняя оценка сезонной компоненты для I-го квартала, |
0,860 |
0,788 |
0,890 |
0,959 |
|
|
Скорректированная сезонная компонента, |
0,984 |
0,901 |
1,018 |
1,097 |
Имеем: 0,860 + 0,788 + 0,890 + 0,959 = 3,497.
Определяем корректирующий коэффициент: K = 4 : 3,497 = 1,144.
Скорректированные значения сезонной компоненты ![]() получаются при умножении ее средней оценки
получаются при умножении ее средней оценки ![]() на корректирующий коэффициент K.
на корректирующий коэффициент K.
Проверяем условие: равенство 4 суммы значений сезонной компоненты:
0,984 + 0,901 + 1,018 + 1,097 = 4.
Шаг 3. Разделим каждый уровень исходного ряда на соответствующие значения сезонной компоненты. В результате получим величины ![]() (гр. 4 табл. 2.3), которые содержат только тенденцию и случайную компоненту.
(гр. 4 табл. 2.3), которые содержат только тенденцию и случайную компоненту.
Таблица 2.3
|
T |
Yt |
St |
|
T |
T×S |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
1 |
100,0 |
0,984 |
101,6 |
100,02 |
98,42 |
1,016 |
|
2 |
93,9 |
0,901 |
104,2 |
100,19 |
90,27 |
1,040 |
|
3 |
96,5 |
1,018 |
94,8 |
100,36 |
102,17 |
0,945 |
|
4 |
101,8 |
1,097 |
92,8 |
100,53 |
110,28 |
0,923 |
|
5 |
107,8 |
0,984 |
109,6 |
100,7 |
99,09 |
1,088 |
|
6 |
96,3 |
0,901 |
106,9 |
100,87 |
90,88 |
1,060 |
|
7 |
95,7 |
1,018 |
94,0 |
101,04 |
102,86 |
0,930 |
|
8 |
98,2 |
1,097 |
89,5 |
101,21 |
111,03 |
0,884 |
|
9 |
104,0 |
0,984 |
105,7 |
101,38 |
99,76 |
1,043 |
|
10 |
99,0 |
0,901 |
109,9 |
101,55 |
91,50 |
1,082 |
|
11 |
98,8 |
1,018 |
97,1 |
101,72 |
103,55 |
0,954 |
|
12 |
101,9 |
1,097 |
92,9 |
101,89 |
111,77 |
0,912 |
|
13 |
113,1 |
0,984 |
114,9 |
102,06 |
100,43 |
1,126 |
|
14 |
98,4 |
0,901 |
109,2 |
102,23 |
92,11 |
1,068 |
|
15 |
97,3 |
1,018 |
95,6 |
102,4 |
104,24 |
0,933 |
|
16 |
112,1 |
1,097 |
102,2 |
102,57 |
112,52 |
0,996 |
|
17 |
97,6 |
0,984 |
99,2 |
102,74 |
101,10 |
0,965 |
|
18 |
93,7 |
0,901 |
104,0 |
102,91 |
92,72 |
1,011 |
|
19 |
114,3 |
1,018 |
112,3 |
103,08 |
104,94 |
1,089 |
|
20 |
108,4 |
1,097 |
98,8 |
103,25 |
113,27 |
0,957 |
|
Среднее |
101,4 |
1,0011 |
Шаг 4. Определим компоненту T в мультипликативной модели. Для этого рассчитаем параметры линейного тренда, используя уровни T×E. Составим вспомогательную таблицу.
Таблица 2.4
|
T |
|
T2 |
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
1 |
101,6 |
1 |
101,6 |
2,5 |
1,58 |
2,0 |
|
|
2 |
104,2 |
4 |
208,4 |
13,2 |
3,87 |
56,3 |
|
|
3 |
94,8 |
9 |
284,4 |
32,1 |
5,88 |
24,0 |
|
|
4 |
92,8 |
16 |
371,2 |
71,9 |
8,33 |
0,2 |
|
|
5 |
109,6 |
25 |
548 |
75,9 |
8,08 |
41,0 |
|
|
6 |
106,9 |
36 |
641,4 |
29,4 |
5,63 |
26,0 |
|
|
7 |
94,0 |
49 |
658 |
51,3 |
7,48 |
32,5 |
|
|
8 |
89,5 |
64 |
716 |
164,6 |
13,07 |
10,2 |
|
|
9 |
105,7 |
81 |
951,3 |
18,0 |
4,08 |
6,8 |
|
|
10 |
109,9 |
100 |
1099 |
56,3 |
7,58 |
5,8 |
|
|
11 |
97,1 |
121 |
1068,1 |
22,6 |
4,81 |
6,8 |
|
|
12 |
92,9 |
144 |
1114,8 |
97,4 |
9,69 |
0,3 |
|
|
13 |
114,9 |
169 |
1493,7 |
160,5 |
11,20 |
136,9 |
|
|
14 |
109,2 |
196 |
1528,8 |
39,6 |
6,39 |
9,0 |
|
|
15 |
95,6 |
225 |
1434 |
48,2 |
7,13 |
16,8 |
|
|
20 |
102,2 |
400 |
2044 |
0,2 |
0,37 |
114,5 |
|
|
21 |
99,2 |
441 |
2083,2 |
12,3 |
3,59 |
14,4 |
|
|
22 |
104,0 |
484 |
2288 |
1,0 |
1,05 |
59,3 |
|
|
23 |
112,3 |
529 |
2582,9 |
87,6 |
8,19 |
166,4 |
|
|
24 |
98,8 |
576 |
2371,2 |
23,7 |
4,49 |
49,0 |
|
|
Сумма |
230 |
2035,2 |
3670 |
23588 |
1008,3 |
122,49 |
778,2 |
|
Среднее |
11,5 |
101,8 |
183,5 |
1179,4 |
50,4 |
6,12 |
38,91 |
Вычислим параметры уравнения тренда.
 = 0,17.
= 0,17.
![]() = 99,85.
= 99,85.
В результате получим уравнение тренда:
T = 99,85 + 0,17×T.
Подставляя в это уравнение значения T = 1,2,…,16, найдем уровни T для каждого момента времени (гр. 5 табл. 2.3).
Шаг 5. Найдем уровни ряда, умножив значения T на соответствующие значения сезонной компоненты (гр. 6 табл. 2.3). На одном графике откладываем фактические значения уровней временного ряда и теоретические, полученные по мультипликативной модели.

Расчет ошибки в мультипликативной модели произведем по формуле:
![]()
Средняя абсолютная ошибка составила 1,0011 (см. гр. 7 табл. 2.3).
Рассчитаем сумму квадратов абсолютных ошибок ![]() .
.
Используя 5-й столбец таблицы 2.4, получим:
 = 7,099.
= 7,099.
Рассчитаем среднюю относительную ошибку: ![]() .
.
Используя 6-й столбец таблицы 2.4, получим, что средняя относительная ошибка составила 6,12%, т. е. построенная модель достаточно точно описывает динамику данного явления.
| < Предыдущая | Следующая > |
|---|
Дифференциальный метод анализа используют для повышения точности спектрофотометрических и фотоколориметрических измерений при определении высоких концентраций веществ (от 10 до 100%). Сущность метода заключается в измерении светопоглощения анализируемого раствора относительно раствора сравнения, содержащего определенное количество испытуемого вещества это приводит к изменению рабочей области шкалы прибора и снижению относительной ошибки анализа до 0,5—1%. [c.40]
Стандартное отклонение, дисперсия, коэффициент вариации — характеризуют случайную ошибку анализа. Граница разброса отдельных измерений относительно X характеризуется квадратичной ошибкой или стандартным отклонением отдельного измерения 5. Выборочное стандартное отклонение определяется по формуле [c.194]
Использование при спектральном анализе относительной интенсивности позволяет повысить его точность и упрощает технику измерений. Повышение точности связано не только с учетом нестабильности источника света, она возрастает также благодаря тому, что автоматически учитываются многие ошибки, связанные как со спектральным аппаратом, так и с регистрирующим устройством. Действительно, если случайно сдвинется или запылится конденсор или другая оптическая деталь, то это приведет к изменению интенсивности каждой спектральной линии в фокальной поверхности прибора, но благодаря использованию для анализа относительных величин это мало влияет на точность. [c.152]
В спектральном анализе обычно используют не абсолютные ошибки, а относительные, которые показывают, какой процент составляет ошибка от измеряемой величины. При спектральном анализе относительная ошибка обычно мало зависит от концентрации и поэтому ее использование для характеристики методик значительно более удобно, чем абсолютной. [c.228]
Различают прямое титрование, основанное на непосредственном взаимодействии анализируемого вещества и титранта, и обратное титрование, в котором процессу титрования предшествует вспомогательная реакция. Последний метод характеризуется несколько более высокой ошибкой, так как количество измерений при его выполнении возрастает. Для уменьшения суммарной ошибки анализа необходимо, чтобы объем раствора титранта (при выбранной навеске анализируемого вещества) был возможно большим, а ошибка в определении концентрации этого раствора— возможно меньшей. Обычно относительная средняя квадратичная ошибка результатов анализа титриметрическим методом составляет 0,1—0,5%. [c.342]
Оценим вклад этих ошибок в общую ошибку анализа. Относительные интенсивности пиков в масс-спектре довольно сильно зависят от условий анализа (температура источника ионов и системы напуска, загрязнение прибора, материал поверхности системы напуска и коммуникаций, юстировка прибора и т. п.). В табл. 9 показано изменение аналитических характеристик масла марки РМ при измерении на одном и том же масс-спектрометре МХ 1303 в течение-года. [c.83]
Подставив полученное значение т в уравнение (УП-19), можно получить приближенные величины молекулярных весов и мольных долей. Подстановка приближенных величин ТУ,- в уравненне (УП-23) дает новую уточненную величину т.. Приближение можно продолжать до тех пор, пока отклонение величины N от единицы не станет соизмеримым с относительными ошибками анализов. [c.198]
Формулы (1.12) и (1.13) показывают, что ошибка анализа, подсчитываемая из приближенного значения дисперсии Оу , определяется суммой соответствующих дисперсий при суммах или разностях измеряемых величин складываются дисперсии абсолютных ошибок (1.12), при произведениях или частных измеряемых величин складываются дисперсии относительных ошибок (1.13). [c.8]
Если предположить, что превалирующий вклад в ошибку анализа вносит ошибка измерения высот пиков, то используя уравнение (35) для уравнения (18) найдем, что относительная ошибка определения в методе стандартной добавки определяется следующим выражением [c.14]
В описанном методе контрольных карт предполагается значимость стандартного отклонения временного ряда, т. е. флуктуации внутри временного ряда должны быть в основном обусловлены стандартным отклонением Сх (например, флуктуации показателей качества). Относительно сг ошибка анализа д. (с /а степенями свободы) должна быть пренебрежимо мала. В предположении А < (Тх проверяют в соответствии с неравенством (7.36) гипотезы [c.208]
При выполнении этого неравенства можно считать с вероятностью Р, что ошибка анализа а относительно (Тх пренебрежимо мала. Если вместо Сх известна только ее оценка (с Д степенями свободы), проводят проверку по F = зх/заУ и сравнивают с Г = Р = 0,99 /г /л) [уравнение (7.1)]. Толь- [c.208]
Из таблицы видно, что относительная ошибка анализа колеблется в пределах 0—13% и в среднем составляет 5,8%. [c.170]
Содержание компонента (в процентах) указано относительно суммарного содержания липидов. Возможное отклонение от 100% обусловлено ошибками анализа. [c.35]
Методика позволяет определять 0,5—25 мг Р при низки.х содержаниях относительная ошибка анализа составляет 20°о, пр 1 более высоки.х ,3,5 о. [c.46]
Достоинство метода быстрота выполнения анализа, простота аппаратуры. Метод пригоден для серийных массовых анализов. Относительные ошибки составляют 2%. [c.344]
Воспроизводимость, время анализа. Относительная ошибка метода при содержании оснований выше 1 % составляет 2,4%, в пределах от 0,1 до 1% —10%. Оро-должительность анализа 15 мин без учета времени на разогрев пробы. [c.82]
Кривые / и 2 на рис. 5.2 соответствуют области мгновенной реакции, в которой следует ожидать большей зависимости ф от Вож, чем от Вог. Из рис. 5.2 видно, например, для кривой 1, что изменение Во от 100 до 0,5 приводит к увеличению ф больше чем вдвое. В то же время результаты решения показали, что изменение Вог от 50 до 0,5 практически не сказывается на величине ф. Данные рис. 5.2 свидетельствуют также о том, что при определенных условиях перемешивание жидкости заметно влияет на ф уже при сравнительно высоких значениях Вож (5—10), и, следовательно, расчет по уравнению для случая идеального вытеснения жидкости может привести к заметной ошибке. Анализ результатов решения показал также возможность появления заметной погрешности при использовании уравнения для случая полного перемешивания жидкости даже при относительно малых значениях Вож (0,5—1). [c.148]
Как показали исследования А. К. Виноградовой, Е. Б. Геркен и Л. М. Иванцова [27], дополнительная нестабильность относительной интенсивности аналитической линии вносится за счет неконтролируемого виньетирования излучения источника электродами и оптикой спектральной установки в процессе разрушения электродов разрядом и блуждания разряда по электродам. Излучение линий разной природы локализовано в различных зонах разряда. Поэтому возникновение непрозрачного экрана на пути световых лучей в различной степени ослабляет линии с различными потенциалами возбуждения. Эффект неконтролируемого избирательного виньетирования излучения источника может быть подавлен в значительной мере путем рационального выбора осветителя. А. К- Виноградовой и Л. М. Иванцовым [28] установлено, что лучшие результаты дает растровый осветитель. Особенно важно то, что осветители такого типа позволяют получить ту же ошибку анализа при менее строгой локализации положения источника относительно спектрального аппарата. Серийная фотоэлектрическая аппаратура пока укомплектована растровым осветителем со сферической оптикой. Более перспективные растровые осветители с цилиндрической оптикой известны только по опытным установкам [28]. [c.27]
Следовательно, ошибка анализа 14,75% — 14,73% =0,02%. Относительная ошибка составляет [c.159]
Если Ох Оф, то относительная ошибка определения сравнительно невелика. Однако с уменьшением величины Ох и ее приближением к величине Оф ошибка становится относительно большой вследствие колебаний значений Ох и Оф. Для повышения точности анализа выполняют несколько определений Ох+ф и Оф, вычисляют средние значения Б и находят среднее квадратичное отклонение а . Используя эту величину, можно представить [c.35]
При фотоэлектрической регистрации точность определений больше, чем при фотографической и визуальной регистрации. Во многих случаях относительная квадратичная ошибка анализа не превышает 2—3%, в благоприятных случаях она снижается до 1—2%. Фотоэлектрические методы анализа отличаются, как правило, наиболее высокой производительностью. В течение нескольких минут можно определить концентрации десятков компонентов пробы. [c.231]
Рентгенофлуоресцентный метод обладает рядом возможностей практически полная сохранность пробы (неразрушающий метод), широкий интервал определяемых концентраций (от 10- до 100%) при определении более 80 элементов, достаточная для многих целей точность анализа (относительная ошибка до 1%), мгновенное получение сигнала, вообще экспрессность анализа. На современных многоканальных рентгеновских квантометрах проводят анализ пород и минералов на основные породообразующие элементы [c.71]
Также успешно внедряются и рентгенофлуоресцентные квантометры, обеспечивающие высокую точность анализа (относительная ошибка не превышает 0,2—0,3%). Распространенный спектрометр УКА-2 производства ГДР будет применен для анализа ферросплавов, а анализы руд, концентратов, агломерата, чугуна, сложных сплавов и высоколегированных сталей будут выполняться на многоканальных квантометрах типа АРЛ-72000 и на отечественных квантометрах КРФ-18. У рентгенофлуоресцентного метода в черной металлургии большое будущее, поскольку он обеспечивает определение основных макрокомпонентов и легирующих добавок. Удобен этот метод не только в собственно металлургическом производстве, но и для анализа руд и концентратов. [c.145]
Освоен и применялся рентгенофлуоресцентный метод анализа продуктов цеха —шихты, шлаков, штейнов, руды. Лаборатория, размешенная в здании цеха, была оснащена двумя рентгеновскими анализаторами ФРА-Ш и двумя рентгеновскими квантометрами ФРК-2, рентгеновским спектрометром РС-5700. Медь в шлаках и штейне определяли при помощи прибора ФРА-1М. Результат анализа можно было иметь через 3—5 мин после доставки пробы. Кремний, железо, кальций и серу определяли на квантометре ФРК-2 в этом случае продолжительность анализа одной пробы — 15 мин. Правильность анализа обеспечивалась применением стандартных образцов, химический, вещественный и гранулометрический состав которых близок к составу анализируемых проб. Относительная ошибка рентгенофлуоресцентных определений меди составляла 7% при содержаниях ее 0,05—0,15% и до 2,5% при содержаниях 8—30%. Между прочим, относительная ошибка анализа тех же проб химическими методами составляла соответственно 16 и 2%. Результаты рентгенофлуоресцентных анализов использовали для оперативного управления производством и составления балансов. [c.151]
Если молекулярный вес определять экспериментально, ошибка анализа возрастает не намного по сравнению с анализом по фракциям. Наибольшая неточность приходится на относительное содержание нафтеновых и парафиновых углеводородов, поэтому часто ограничиваются указанием их суммарного содержания. Такой анализ может быть выполнен в течение одного дня, при необходимости его можно сочетать с определением ароматических углеводородов криоскопическим методом. [c.224]
Как выше отмечалось, при измерении на спектрофотометрах с электрической компенсацией инструментальная ошибка а р является постоянной величиной, имеющей различные значения для каждого прибора. Ошибка измерения показания шкалы пропускания зависит от самого показания т. Кюветная ошибка тоже очень сильно зависит от величины т. Для нахождения оптимальных условий спектрофотометрии в зависимости от кюветной ошибки необходимо проанализировать относительную среднюю квадратичную ошибку анализа [c.235]
При осуществлении потока газа через разрядную трубку можно возбуждать смесь азота с аргоном не только в высокочастотном разряде, но и в положительном столбе разряда переменного тока Р ] или в полом катоде Р ]. Однако относительная чувствительность определения азота в этих источниках не превышает сотой доли процента при средней ошибке анализа порядка 20%. [c.186]
Несомненным достоинством метода просыпки-вдувания при тщательном его техническом выполнении является высокая воспроизводимость результатов анализа (относительная стандартная ошибка порядка нескольких процентов). [c.151]
Ошибка анализа может быть выражена двумя способами в виде абсолютной и относительной величины. [c.17]
В некоторых методах анализа относительная ошибка Оу1у постоянна во всем интервале измерений. Поэтому эти методы особенно эффективны для исследования небольших количеств пробы, например в анализе следовых количеств вешеств. [c.452]
Применение количественного спектрального анализа фактически началось после 1926г., когда впервые было предложено использовать для анализа относительную интенсивность спектральных линий. Даже если эти линии выбраны негомологичными, то и тогда введение относительной интенсивности существенно повышает точность анализа, так как позволяет устранить ошибки, связанные со случайным изменением количества света, попадаемого в спектральный аппарат, с разбросом чувствительности регистрирующего устройства и с другими причинами. Выбор гомологической пары линий позволяет полностью компенсировать или сильно уменьшать важнейший источник ошибок — изменение параметров источника света. [c.224]
Пример. При анализе на многоканальном приборе с фотоэлектрической регистрацией, для того чтобы определить ошибку анализа, связанную с нестабильностью самого нсточника света, нужно сначала определить общую ошибку, которую вносит регистрирующее устройство, спектральный аппарат и осветительная система. Для этого многократно определяют на приборе относительную интенсивность двух гомологических спектральных линий одного элемента и подсчитывают ошибку т . Затем в тех же условиях многократно определяют относительную интенсивность аналитической пары линий в одном образце нли эталоне и подсчитывают ошибку этого измерегшя т. Искомую ошибку /Ид, связанную только с нестабильностью самого источника света, подсчитывают по формуле [c.232]
В скобках показана возможная ошибка анализа в абсолютных процентах (относительная точность определения для ЗЮз равна 0,02 -100 25,37= 0,1% ТЮз —0, М001 2,3 -4%). [c.19]
Первому случаю отвечает несомненно идеализированный пример прямого объемного определения компонента безупречным аналитиком при использовании идеально точной мерной посуды, раствора титранта с идеально точно установленной концентрацией Ст (ДСт=0), идеального индикатора. Это случай, когда вся ошибка определения сводится к ошибке фиксирования объема титранта AVt. При АУт = onst относительная ошибка анализа обратно пропорциональна исходной массе (аликвотному объему Vx) анализируемой пробы [c.25]
Относительная ошибка анализов 1,4—4,5% серусодержащие органические соединения, меркаптаны не мешают [1182]. [c.185]
При определении чистоты достаточно концентрированных фенолов (выше 85—90%) одним из наиболее надежных методов анализа оказывается определение температуры плавления (при приблизительно постоянном составе примесей). Так определяют содержание фенола по Рашигу, о-крезола, п-крезола, нафтолов, фенилфенолов, резорцина и некоторых других. Другие крезолы в условиях анализа окисляются азотной кислотой до щавелевой кислоты и двуокиси углерода. Широко известен [58, 59] метод анализа -крезола, основанный на линейной зависимости температуры затвердевания кристаллического аддукта -крезола с мочевиной. Комплексы других фенолов, например п-крезола с бензи-дином [60], фенола с 2,5-диметилпиридином, о-крезола с лепи-дином [61], также используют для количественного анализа. Относительная ошибка указанных способов составляет 2—3%. [c.50]
Относительно суммарного содержаиня липидов возможное отклонение от 100% обусловлено ошибками анализа. [c.37]
На основании анализа ряда искусственных см ей относительная среднеквадратичная ошибка анализа кислот на по гоке составила [c.207]
Квантометры снабжены специальными осветительными линзами—растровыми конденсорами, уменьшающими ошибку анализа, которую могло бы вызвать обычное перемещение ( бегание ) светящегося облака источника света относительно оси межэлек-тродного промежутка. [c.242]
Для количественного определения смеси антиоксидантов иеозона Д, 4010 КА и п-оксинеозона в сырых резиновых смесях и вулканизатах использовано сочетание тонкослойной хроматографии и спектрофотометрии. Разделение ведут в тонком слое силикагеля КСК или окиси алюминия (ТУ 29В2-54) используют смесь растворителей бензол, ацетон, аммиак в соотношении (100 5 0,1) (или чистый растворитель-бензол). Относительная ошибка анализа смеси чистых антиоксидантов пс превышает 10%. [c.341]
Выбор растворителей, имеющих идеальную избирательность, невозможен, так как любой из них в той или иной мере обязательно будет растворять каждое из определяемых соединений. Поэтому при разработке методик вещественного анализа выбирают растворитель с максимально возможной избирательностью действия. Даже при максимально возможной избирательности при некоторых условиях относительная погрешность определения форм может оказаться значительно больше 10%. Результаты с повышенной погрешностью чаще всего получаются при раздельном определении срединений с весьма близкими химическими свойствами. Так, например, в течение многих лет ведутся работы по изучению возможности раздельного определения шеелита и вольфрамита, ферберита и вольфрамита и т. д. [12, 43—50 и др.], так как химические свойства этих минералов и энергия их кристаллической решетки близки [28, 44]. Повышенные ошибки анализа почти всегда получаются при определении малых количеств одной формы в присутствии относительно больших второй. Частичное растворение второй формы растворителем, предназначенным для первой, не сказывается заметно на результатах ее определения, но весьма значительно (иногда в 5—10 раз) увеличивает результаты определения первой формы. Такие примеры многочислены. Некоторые из них подробно рассмотрены ниже. [c.37]
Для вычисления результатов анализа использовали калибровочную кривую высота пика двуокиси углерода — концентрация углерода. 1 1етод был успешно применен для анализа образцов, содержаш их углерод в области концентраций 1-10 — 200-10″ 6. Однако метод может быть использован также для анализа образцов, содержащих до 0,5% углерода. Относительная ошибка анализа составляет 5% (при концентрации углерода 100-10 — 200-10 %). Продолжательность анализа 15 мин. Разработанный метод заменил более сложный метод Либиха. [c.95]
Для полного анализа необходимо 5—200 мл анализируемой смеси в зависимости от требуемой чувствительности анализа. Продолжительность анализа, в зависимости от состава газа, 15—60 мин. Чувствительность анализа 0,05—0,1%. Относительная ошибка анализа 4% от верхнего предела изд1еряемой концентрации. Габариты прибора 78 X 56 X 25 см (без колонок). [c.306]
Табл. 1 содержит данные, касающиеся воспроизводимости таких анализов. Относительно высокая ошибка (2—3%) может быть отнесена главным образом за счет ненравильной работы пламенно-ионизационного детектора, который, к сожалению, во время опытов обнаруживал некоторую неисправность. [c.153]
In statistics, a relative standard error (RSE) is equal to the standard error of a survey estimate divided by the survey estimate and then multiplied by 100. The number is multiplied by 100 so it can be expressed as a percentage. The RSE does not necessarily represent any new information beyond the standard error, but it might be a superior method of presenting statistical confidence.
Relative Standard Error vs. Standard Error
Standard error measures how much a survey estimate is likely to deviate from the actual population. It is expressed as a number. By contrast, relative standard error (RSE) is the standard error expressed as a fraction of the estimate and is usually displayed as a percentage. Estimates with an RSE of 25% or greater are subject to high sampling error and should be used with caution.
Survey Estimate and Standard Error
Surveys and standard errors are crucial parts of probability theory and statistics. Statisticians use standard errors to construct confidence intervals from their surveyed data. The reliability of these estimates can also be assessed in terms of a confidence interval. Confidence intervals are important for determining the validity of empirical tests and research.
A confidence interval is a type of interval estimate, computed from the statistics of the observed data, that might contain the true value of an unknown population parameter. Confidence intervals represent the range in which the population value is likely to lie. They are constructed using the estimate of the population value and its associated standard error. For example, there is approximately a 95% chance (i.e. 19 chances in 20) that the population value lies within two standard errors of the estimates, so the 95% confidence interval is equal to the estimate plus or minus two standard errors.
In layman’s terms, the standard error of a data sample is a measurement of the likely difference between the sample and the entire population. For example, a study involving 10,000 cigarette-smoking adults may generate slightly different statistical results than if every possible cigarette-smoking adult was surveyed.
Smaller sample errors are indicative of more reliable results. The central limit theorem in inferential statistics suggests that large samples tend to have approximately normal distributions and low sample errors.
Standard Deviation and Standard Error
The standard deviation of a data set is used to express the concentration of survey results. Less variety in the data results in a lower standard deviation. More variety is likely to result in a higher standard deviation.
The standard error is sometimes confused with the standard deviation. The standard error actually refers to the standard deviation of the mean. Standard deviation refers to the variability inside any given sample, while a standard error is the variability of the sampling distribution itself.
Relative Standard Error
The standard error is an absolute gauge between the sample survey and the total population. The relative standard error shows if the standard error is large relative to the results; large relative standard errors suggest the results are not significant. The formula for relative standard error is:
Relative Standard Error
=
Standard Error
Estimate
×
1
0
0
where:
Standard Error
=
standard deviation of the mean sample
Estimate
=
mean of the sample
begin{aligned} &text{Relative Standard Error} = frac { text{Standard Error} }{ text{Estimate} } times 100 \ &textbf{where:} \ &text{Standard Error} = text{standard deviation of the mean sample} \ &text{Estimate} = text{mean of the sample} \ end{aligned}
Relative Standard Error=EstimateStandard Error×100where:Standard Error=standard deviation of the mean sampleEstimate=mean of the sample
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.









Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.