
SQL Server 2012 Enterprise SQL Server 2008 R2 Enterprise SQL Server 2012 Developer SQL Server 2012 Standard SQL Server 2014 Developer SQL Server 2014 Enterprise SQL Server 2014 Standard Еще…Меньше
Проблемы
Рассмотрим следующий сценарий.
-
У вас есть Microsoft SQL Server доставки журналов или резервное копирование и восстановление настройки между двумя серверами.
-
База данных-источник содержит его файл журнала транзакций (.ldf) хранится на диске с «Байт на каждый физический сектор» по 512 байт.
-
Выполнить транзакции резервных копий журналов базы данных, а затем повторите его восстановления с помощью перехода в ждущий режим на базу данных-получатель.
-
База данных-получатель журнала транзакций (.ldf) находится на диске, который содержит «Байт на каждый физический сектор» по 4096 байт.
В этом случае операция восстановления завершается неудачей и возвращает следующее сообщение об ошибке:
Ошибка: 9004, уровень серьезности: 16, состояние: 6.
Произошла ошибка во время обработки журнала для базы данных, имя базы данных. Если возможно восстановите из резервной копии. Если резервная копия недоступна, возможно, понадобится перестроить журнал.
После появления этой ошибки, база данных-получатель переходит в состояние SUSPECT установлено.
Решение
Накопительное обновление
Сначала эта проблема была исправлена в следующем накопительном обновлении SQL Server:
-
Накопительное обновление 2 для SQL Server SP1 2014 г
-
Накопительное обновление 7 для SQL Server 2012 с пакетом обновления 2
Примечание. После установки этого обновления для активации этого исправления необходимо включить флаг трассировки 3057. Чтобы включить флаг трассировки 3057, приведены в разделе Флаги трассировки (Transact-SQL) на веб-узле Microsoft Developer Network (MSDN).
Примечание Для экземпляров SQL Server 2008 R2 с пакетом обновления 3 необходимо обновить сервер до последнего обновления безопасности доступны на:

Загрузите обновление безопасности для SQL Server 2008 R2 с пакетом обновления 3
Исправление для SQL Server 2008 R2 с пакетом обновления 2Существует исправление от корпорации Майкрософт. Однако данное исправление предназначено для устранения только проблемы, описанной в этой статье. Применяйте данное исправление только в тех системах, которые имеют данную проблему. Если исправление доступно для скачивания, имеется раздел «Пакет исправлений доступен для скачивания» в верхней части этой статьи базы знаний. Если этого раздела нет, отправьте запрос в службу технической поддержки для получения исправления. Примечание. Если наблюдаются другие проблемы или необходимо устранить неполадки, вам может понадобиться создать отдельный запрос на обслуживание. Стандартная оплата за поддержку будет взиматься только за дополнительные вопросы и проблемы, которые не соответствуют требованиям конкретного исправления. Полный список телефонов поддержки и обслуживания клиентов корпорации Майкрософт или создать отдельный запрос на обслуживание посетите следующий веб-узел корпорации Майкрософт:
http://support.microsoft.com/contactus/?ws=supportПримечание. В форме «Пакет исправлений доступен для скачивания» отображаются языки, для которых доступно исправление. Если нужный язык не отображается, значит исправление для данного языка отсутствует.
Обходное решение
Корпорация Майкрософт подтверждает, что это проблема продуктов Майкрософт, перечисленных в разделе «Относится к». Для решения этой проблемы воспользуйтесь одним из следующих возможных решений.
-
Перемещение файла журнала транзакций в месте назначения на диске с «Байт на каждый физический сектор» по 512 байт. Примечание. Резервный файл можно по-прежнему находиться на диске с «Байт на каждый физический сектор» по 4096 байт.
-
Восстановите резервные копии журнала без использования перехода в ждущий режим. Переключатель режима ОЖИДАНИЯ используйте параметр WITH NORECOVERY во время операции восстановления.
Дополнительная информация
Для определения значения «Байт на каждый физический сектор» можно использовать программы командной строки Fsutil . Если этот параметр не отображается в выходных данных, необходимо применить исправление, указанное в KB982018. Чтобы проверить тип диска, у вас, выполните следующие действия.
-
В командной строке с повышенными привилегиями выполните следующую команду:Fsutil fsinfo ntfsinfo x : Примечание. В этой команде < x > представляет диск, на котором выполняется проверка.
-
Позволяет определить тип диска, у вас есть значения «Байт на сектор» и «Байт на каждый физический сектор». Чтобы сделать это, воспользуйтесь следующей таблицей.
Значение «Байт в секторе»
Значение «Байт на физический сектор»
Тип диска
4096
4096
4K в машинном коде
512
4096
Расширенный формат (также известный как 512E)
512
512
машинный код 512 байт
Нужна дополнительная помощь?
Если восстановление журнала с CONTINUE_AFTER_ERROR (либо со STOP_ON_ERROR)
RESTORE LOG [ka]
FROM DISK = N'D:Tail.bak'
WITH FILE = 1, CONTINUE_AFTER_ERROR, NORECOVERY
GO
завершается с ошибкой, после которой невозможно выполнить
RESTORE DATABASE [ka]
WITH RECOVERY
GO
то можно попытаться восстановиться до какого-то LSN в журнале (максимально возможного), при котором RESTORE LOG ещё не вызывает ошибок.
Для этого читаем заголовки бэкапов БД и журнала
RESTORE HEADERONLY FROM DISK = N'C:2016.Bak'
RESTORE HEADERONLY FROM DISK = N'D:Tail.bak'
в которых сверяем значения столбцов FirstLSN и LastLSN (убеждаемся, что цепочка LSN не разорвана, и в журнале действительно есть дополнительная информация).
Допустим, получили:
C:2016.Bak
FirstLSN LastLSN
----------------- -----------------
64000000005600195 64000000017600001
D:Tail.bak
FirstLSN LastLSN
----------------- -----------------
64000000005600195 66000000025600001
сравниваем LSN: 64000000005600195 <= 64000000017600001 < 66000000025600001 — OK.
Значение LastLSN из заголовка БД (равное 64000000017600001) переводим из десятичного представления в двоичное (см. здесь, функция fn_convertnumericlsntobinary), получаем 00000040:000000B0:0001.
Теперь с помощью sys.fn_dump_dblog читаем последовательность LSN из дампа лога (можно отфильтровать только операции завершения транзакций Operation = 'LOP_COMMIT_XACT'):
select [Current LSN]
from sys.fn_dump_dblog(
NULL, NULL, N'DISK', 1, N'D:Tail.bak',
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default)
where Operation = 'LOP_COMMIT_XACT';
Допустим, получили, следующий список:
Current LSN
-----------------------
00000040:000000a0:0002
00000040:000000b8:0001 <-- сначала восстанавливаем журнал к этой отметке
00000040:000000c8:000b <-- потом к этой
00000040:000000d0:000a <-- ...
00000040:000000d8:000a <-- ...
00000040:000000e0:000a <-- ...
00000040:000000e8:000a <-- ...
00000040:000000f0:000b <-- ...
00000040:000000f8:0010 <-- ...
00000040:000000f8:0021 <-- и т.д, пока не встретим ошибку
00000040:000000f8:0027 <-- ERROR
00000040:00000110:0017
00000040:00000130:001b
00000040:00000130:001d
00000040:00000140:000a
Заново инициализируем восстановление:
RESTORE DATABASE [ka]
FROM DISK = N'D:2016.bak'
WITH NORECOVERY, REPLACE
GO
Теперь берём из списка первое значение LSN, которое следует позднее, чем LastLSN в бэкапе БД (позднее чем 00000040:000000B0:0001) и делаем RESTORE LOG к этой отметке:
RESTORE LOG [ka]
FROM DISK = N'D:Tail.bak'
WITH FILE = 1, STOPATMARK = 'lsn:0x00000040:000000b8:0001', NORECOVERY
GO
Если операция прошла без ошибок, повторяем то же самое для следующей отметки, и т.д., пока не дойдём до отметки, восстановление к которой будет вызывать ошибку.
Если отметок много, то можно применить дихотомический поиск, учитывая, однако, что при движении вперёд достаточно выполнять лишь RESTORE LOG к новой отметке, но если необходимо вернуться назад, то цепочку восстановления нужно выполнять заново (RESTORE DATABASE ... WITH REPLACE ..., затем RESTORE LOG ... к нужной отметке).
После того как последняя не вызвавшая ошибку отметка определена, заново восстановим БД и журнал до этой отметки:
RESTORE DATABASE [ka]
FROM DISK = N'D:2016.bak'
WITH NORECOVERY, REPLACE
GO
RESTORE LOG [ka]
FROM DISK = N'D:Tail.bak'
WITH STOPATMARK = 'lsn:0x00000040:000000f8:0021', NORECOVERY
GO
После чего завершаем восстановление:
RESTORE DATABASE [ka]
WITH RECOVERY
GO
Если восстановление журнала с CONTINUE_AFTER_ERROR (либо со STOP_ON_ERROR)
RESTORE LOG [ka]
FROM DISK = N'D:Tail.bak'
WITH FILE = 1, CONTINUE_AFTER_ERROR, NORECOVERY
GO
завершается с ошибкой, после которой невозможно выполнить
RESTORE DATABASE [ka]
WITH RECOVERY
GO
то можно попытаться восстановиться до какого-то LSN в журнале (максимально возможного), при котором RESTORE LOG ещё не вызывает ошибок.
Для этого читаем заголовки бэкапов БД и журнала
RESTORE HEADERONLY FROM DISK = N'C:2016.Bak'
RESTORE HEADERONLY FROM DISK = N'D:Tail.bak'
в которых сверяем значения столбцов FirstLSN и LastLSN (убеждаемся, что цепочка LSN не разорвана, и в журнале действительно есть дополнительная информация).
Допустим, получили:
C:2016.Bak
FirstLSN LastLSN
----------------- -----------------
64000000005600195 64000000017600001
D:Tail.bak
FirstLSN LastLSN
----------------- -----------------
64000000005600195 66000000025600001
сравниваем LSN: 64000000005600195 <= 64000000017600001 < 66000000025600001 — OK.
Значение LastLSN из заголовка БД (равное 64000000017600001) переводим из десятичного представления в двоичное (см. здесь, функция fn_convertnumericlsntobinary), получаем 00000040:000000B0:0001.
Теперь с помощью sys.fn_dump_dblog читаем последовательность LSN из дампа лога (можно отфильтровать только операции завершения транзакций Operation = 'LOP_COMMIT_XACT'):
select [Current LSN]
from sys.fn_dump_dblog(
NULL, NULL, N'DISK', 1, N'D:Tail.bak',
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default,
default, default, default, default, default, default, default)
where Operation = 'LOP_COMMIT_XACT';
Допустим, получили, следующий список:
Current LSN
-----------------------
00000040:000000a0:0002
00000040:000000b8:0001 <-- сначала восстанавливаем журнал к этой отметке
00000040:000000c8:000b <-- потом к этой
00000040:000000d0:000a <-- ...
00000040:000000d8:000a <-- ...
00000040:000000e0:000a <-- ...
00000040:000000e8:000a <-- ...
00000040:000000f0:000b <-- ...
00000040:000000f8:0010 <-- ...
00000040:000000f8:0021 <-- и т.д, пока не встретим ошибку
00000040:000000f8:0027 <-- ERROR
00000040:00000110:0017
00000040:00000130:001b
00000040:00000130:001d
00000040:00000140:000a
Заново инициализируем восстановление:
RESTORE DATABASE [ka]
FROM DISK = N'D:2016.bak'
WITH NORECOVERY, REPLACE
GO
Теперь берём из списка первое значение LSN, которое следует позднее, чем LastLSN в бэкапе БД (позднее чем 00000040:000000B0:0001) и делаем RESTORE LOG к этой отметке:
RESTORE LOG [ka]
FROM DISK = N'D:Tail.bak'
WITH FILE = 1, STOPATMARK = 'lsn:0x00000040:000000b8:0001', NORECOVERY
GO
Если операция прошла без ошибок, повторяем то же самое для следующей отметки, и т.д., пока не дойдём до отметки, восстановление к которой будет вызывать ошибку.
Если отметок много, то можно применить дихотомический поиск, учитывая, однако, что при движении вперёд достаточно выполнять лишь RESTORE LOG к новой отметке, но если необходимо вернуться назад, то цепочку восстановления нужно выполнять заново (RESTORE DATABASE ... WITH REPLACE ..., затем RESTORE LOG ... к нужной отметке).
После того как последняя не вызвавшая ошибку отметка определена, заново восстановим БД и журнал до этой отметки:
RESTORE DATABASE [ka]
FROM DISK = N'D:2016.bak'
WITH NORECOVERY, REPLACE
GO
RESTORE LOG [ka]
FROM DISK = N'D:Tail.bak'
WITH STOPATMARK = 'lsn:0x00000040:000000f8:0021', NORECOVERY
GO
После чего завершаем восстановление:
RESTORE DATABASE [ka]
WITH RECOVERY
GO
BlackMak
06.07.10 — 12:50
Ночью на сервере заглючил контроллер RAID-массива. Массив RAID5 перешел в состояние Degraded. Сейчас массив восстановлен (вроде бы, проверка целостности еще продолжается). На массиве находятся несколько баз SQL. Все, кроме одной, пережили инцидент нормально. Проблемная база — исчезла из списка баз SQL Server. При попытке подключения получаем сообщение:
ЗАГОЛОВОК: Microsoft SQL Server Management Studio
——————————
Действие Присоединить базу данных завершилось неудачно для объекта «Сервер» «DBS». (Microsoft.SqlServer.Smo)
——————————
ДОПОЛНИТЕЛЬНЫЕ СВЕДЕНИЯ:
При выполнении инструкции или пакета Transact-SQL возникло исключение. (Microsoft.SqlServer.ConnectionInfo)
——————————
Невозможно повторить запись журнала (418450:16:1) для идентификатора транзакции (0:33735178) на странице (1:173131) базы данных «VM» (идентификатор базы данных — 7). Страница: номер LSN = (418447:559:243), тип = 2. Журнал: OpCode = 3, контекст 19, PrevPageLSN: (418449:1401:20). Восстановите базу данных из резервной копии или исправьте базу данных.
Произошла ошибка во время обработки журнала для базы данных «VM». Если возможно, восстановите из резервной копии. Если резервная копия недоступна, возможно, понадобится перестроить журнал.
Произошла ошибка во время обработки журнала для базы данных «VM». Если возможно, восстановите из резервной копии. Если резервная копия недоступна, возможно, понадобится перестроить журнал.
При повторном выполнении запротоколированной операции в базе данных «VM» произошла ошибка в записи журнала с идентификатором (418450:16:1). Как правило, конкретный сбой предварительно протоколируется как ошибка в журнале событий Windows. Восстановите базу данных из полной резервной копии или исправьте базу данных.
Произошла ошибка во время обработки журнала для базы данных «VM». Если возможно, восстановите из резервной копии. Если резервная копия недоступна, возможно, понадобится перестроить журнал.
Невозможно открыть новую базу данных «VM». Операция CREATE DATABASE прервана. (Microsoft SQL Server, ошибка: 3456)
Если из списка присоединяемых файлов удалить файл журнала (т.е., предложить SQL Server перестроить его), то получаем тоже самое сообщение сообщение. Если ручками перед этим удалить файл журнала — получаме сообщение «Файл не найден».
SQL Server 2005 SP2, проблемная база была в Simple.
Восстанавливаться из резервной копии очень не хочется — теряем день. Есть еще какие-то варианты потрепыхаться или все, база умерла?
BlackMak
1 — 06.07.10 — 13:02
ап
leshikkam
2 — 06.07.10 — 13:05
1) Сделайте копии файла базы данных и файла журнала транзакций;
2) Попробуйте подцепить базу без LDF:
http://www.sql.ru/faq/faq_topic.aspx?fid=123
Umka2008
3 — 06.07.10 — 13:07
Восстанавливаться из резервной копии очень не хочется — теряем день. Это почему?
Загружал 23 гб — минут 15
Любитель XML
4 — 06.07.10 — 13:09
(3) данные за день потеряны будут.
Любитель XML
5 — 06.07.10 — 13:09
+(4) архив то вчерашний
Lionee
6 — 06.07.10 — 13:12
или есть что то , или ваще нет , нечего страшного бухам делать нечегозанового набьют докию(5)
Это_mike
7 — 06.07.10 — 13:13
ПОхоже, гикнулся только ldf. присоединюсь к (2)
BlackMak
8 — 06.07.10 — 13:13
(2) — пробую.
(3) — см. 4.
(6) — еще раз, плиз.
Любитель XML
9 — 06.07.10 — 13:14
(8) отпишись о результатах
Это_mike
10 — 06.07.10 — 13:14
(6) хм. есть разные предприятия. На некоторых и тысячи документов в день бывают…
vde69
11 — 06.07.10 — 13:14
(0) есть спецы по востановление, если нужно напиши письмо вечером скину контакты.
BlackMak
12 — 06.07.10 — 13:19
(9) — ок.
(10) — тут случай попроще, но документов все равно много.
(11) — спасибо, но если все будет плохо — проще все же вчерашний бэкап поднять.
Злой Бобр
13 — 06.07.10 — 13:22
(0) Протелепартирую — рейд был на 3 дисках и диск Hot Spare конечно же непользовался. И база видимо была не Full а Simple.
Скупой платит дважды. Экономия на рейде никогда ничего хорошего недавала. Ну а поскольку база не Full — восстанавливайте из бекапа и набивайте день снова.
BlackMak
14 — 06.07.10 — 13:22
(13) — неверно телепатируете — массив был на 4-х дисках.
Ёпрст
15 — 06.07.10 — 13:25
(14) жесть.. и кто вам советовал 5 рейд на 4 дисках ?
BlackMak
16 — 06.07.10 — 13:26
(15) — дела давно минувших дней. Все руки не доходят в RAID10 его превратить.
Это_mike
17 — 06.07.10 — 13:31
А в момент падения что с базой творилось?
BlackMak
18 — 06.07.10 — 13:32
(17) — точно не скажу, но думаю, что к ней был подключен 1 пользователь из 1С:Предприятия. Работы не велись (скорее всего).
МихаилМ
19 — 06.07.10 — 14:22
если делали архив раз в сутки — значит готовы пожертвовать сутками.
BlackMak
20 — 06.07.10 — 18:23
(2) — Большое. Человеческое. Спасибо. Будете в Краснодаре — налью Вам кружечку хорошего пива
(9) — отписываюсь — рекомендации по ссылке в (2) помогли. База поднялась. При проверке были найдены несколько некритичных ошибок (у одного документа была нарушена нумерация табличной части, несколько документов были не зарегистрированы в журналах).
leshikkam
21 — 06.07.10 — 18:31
(20) Рад что смог помочь. Буду в ваших краях обязательно воспользуюсь предложением
Любитель XML
22 — 06.07.10 — 18:38
(20) рад что получилось. А вот ссылочку пожалуй сохраню ))
BlackMak
23 — 06.07.10 — 18:45
(22) — да, ссылочка неплоха. Судя по комментариям, она уже у многих вызвала слезы счастья.
SMAlik
24 — 06.07.10 — 18:55
- Remove From My Forums
-
General discussion
-
I am using SQL-Server 2000 . when i try to attach the mdf file it gives error message Error 9004: an error occurred while processing the log for database . please help me out..
All replies
-
Refer this url.
http://social.msdn.microsoft.com/Forums/sqlserver/en-US/48cf82c9-2179-46f3-b009-11416a90d248/attach-database-failed-error-9004
Srinivasan
-
Its a known issue …try below:
Create an empty SQL server database with same name & layout.
Now shutdown the services of SQL server.
Move the database file into newly created empty database file that you want to attach.
Start the SQL server database.
Probably, your database will go in suspect mode.
Now ALTER your database and set database in emergency mode.
Run DBCC CHECKDB command on your database with and repair clause, It will give you a repair clause and again run DBCC CHECKDB with repair_allow_data_loss. You will probably loose some data or records of your SQL server database.
Please click the Mark as answer button and vote as helpful if this reply solves your problem
- Remove From My Forums
-
General discussion
-
I am using SQL-Server 2000 . when i try to attach the mdf file it gives error message Error 9004: an error occurred while processing the log for database . please help me out..
All replies
-
Refer this url.
http://social.msdn.microsoft.com/Forums/sqlserver/en-US/48cf82c9-2179-46f3-b009-11416a90d248/attach-database-failed-error-9004
Srinivasan
-
Its a known issue …try below:
Create an empty SQL server database with same name & layout.
Now shutdown the services of SQL server.
Move the database file into newly created empty database file that you want to attach.
Start the SQL server database.
Probably, your database will go in suspect mode.
Now ALTER your database and set database in emergency mode.
Run DBCC CHECKDB command on your database with and repair clause, It will give you a repair clause and again run DBCC CHECKDB with repair_allow_data_loss. You will probably loose some data or records of your SQL server database.
Please click the Mark as answer button and vote as helpful if this reply solves your problem
Мы используем доставку журналов и RESTORE WITH STANDBYна SQL Server 2012, чтобы восстановить базу данных в режиме только для чтения для целей отчетности. Однако настройка доставки журналов не работает после восстановления одной или двух резервных копий журналов. Доставка журналов прерывается только тогда, когда она работает как RESTORE WITH STANDBY; RESTORE WITH NORECOVERYне вызывает никаких проблем.
Моя единственная интуиция в том, что первичная база данных не так динамична. Поэтому, когда нет транзакций, это может вызвать проблемы с RESTOREпроцессом, может быть?
Есть идеи, известные исправления?
Я работал в течение нескольких дней, выполняя обычную работу, которая выполняет тяжелое обновление для двух таблиц. Когда задание перестало выполняться, настройка доставки журналов быстро завершилась неудачно, не удалось обработать файл .trn. Я сбросил доставку журналов и попытался выяснить, будет ли он продолжать работать, просто выполнив небольшое обновление, изменив значение одного столбца одной записи в таблице, независимо от того, что это все-таки не удалось.
Спасибо за все ваши ответы.
PS: выдержка из нашего журнала
25.02.2013 13: 00: 00, LSRestore_DBDB01-A_BulldogDB, Выполняется, 1, DBREPORTS, LSRestore_DBDB01-A_BulldogDB, шаг задания журнала восстановления доставки журналов. ,, 2013-02-25 13: 00: 12.31 *** Ошибка: Не удалось применить файл резервной копии журнала ' dbsan01 DBBackups LSBackup_BulldogDB BulldogDB_20130225180000.trn' к вторичной базе данных "BulldogDB". (Microsoft.SqlServer.Management.LogShipping) *** 2013-02-25 13: 00: 12.31 *** Ошибка: произошла ошибка при обработке журнала для базы данных «BulldogDB». Если возможно восстановить из резервной копии. Если резервная копия недоступна, может потребоваться перестроить журнал. Во время восстановления произошла ошибка, препятствующая перезапуску базы данных BulldogDB (8: 0). Диагностируйте ошибки восстановления и исправляйте их или восстанавливайте из заведомо исправной резервной копии. Если ошибки не исправлены или ожидаются, обратитесь в службу технической поддержки. RESTORE LOG завершается ненормально. Обработано 0 страниц для базы данных «BulldogDB», файла «BulldogDB» для файла 1. Обработано 1 страниц для базы данных «BulldogDB», файла «BulldogDB_log» в файле 1. (. Net SqlClient Data Provider) *** 2013-02-25 13: 00: 12.32 *** Ошибка: не удалось записать историю / сообщение об ошибке. (Microsoft.SqlServer.Management.LogShipping) *** 2013-02-25 13: 00: 12.32 *** Ошибка: ExecuteNonQuery требует открытого и доступного соединения. Текущее состояние соединения закрыто. (System.Data) *** 2013-02-25 13: 00: 12.32 Пропуск файла резервной копии журнала ' dbsan01 DBBackups LSBackup_BulldogDB BulldogDB_20130225180000.trn' для вторичной базы данных BulldogDB, так как файл не может быть проверен. 2013-02-25 13: 00: 12.32 *** Ошибка: не удалось записать историю / сообщение об ошибке. (Microsoft.SqlServer.Management.LogShipping) *** 2013-02-25 13: 00: 12.32 *** Ошибка: ExecuteNonQuery требует открытого и доступного соединения. Текущее состояние соединения закрыто. (System.Data) *** 2013-02-25 13: 00: 12.33 *** Ошибка: при восстановлении режима доступа к базе данных произошла ошибка (Microsoft.SqlServer.Management.LogShipping) *** 2013-02-25 13: 00: 12.33 *** Ошибка: ExecuteScalar требует открытого и доступного соединения. Текущее состояние соединения закрыто. (System.Data) *** 2013-02-25 13: 00: 12.33 *** Ошибка: не удалось записать историю / сообщение об ошибке (Microsoft.SqlServer.Management.LogShipping) *** 2013-02-25 13: 00: 12.33 *** Ошибка: ExecuteNonQuery требует открытого и доступного соединения. Текущее состояние соединения закрыто. (System.Data) *** 2013-02-25 13: 00: 12.33 *** Ошибка: при восстановлении режима доступа к базе данных произошла ошибка (Microsoft.SqlServer.Management.LogShipping) *** 2013-02-25 13: 00: 12.33 *** Ошибка: ExecuteScalar требует открытого и доступного соединения. Текущее состояние соединения закрыто. (System.Data) *** 2013-02-25 13: 00: 12.33 *** Ошибка: не удалось записать историю / сообщение об ошибке (Microsoft.SqlServer.Management.LogShipping) *** 2013-02-25 13: 00: 12.33 *** Ошибка: ExecuteNonQuery требует открытого и доступного соединения. Текущее состояние соединения закрыто. (System.Data) *** 2013-02-25 13: 00: 12.33 Удаление старых файлов резервных копий журнала. Основная база данных: 'BulldogDB' 2013-02-25 13: 00: 12.33 *** Ошибка: не удалось записать историю / сообщение об ошибке (Microsoft.SqlServer.Management.LogShipping) *** 2013-02-25 13: 00: 12.33 *** Ошибка: ExecuteNonQuery требует открытого и доступного соединения. Текущее состояние соединения закрыто. (System.Data) ***, 00: 00: 12,0,0 ,,,, 0
Содержание:
1. Журнал транзакций в 1С
2. Ошибка Журнал транзакций переполнен
1. Журнал транзакций в 1С
В данной статье будет описана возможная ошибка в системе 1С, а именно – в СУБД, которая связана с переполнением журнала транзакций в 1С. Далее будут приведены возможные методы устранения данной неполадки, среди которых уменьшение журнала транзакций для базы данных.
Сначала следует выяснить, что такое журнал транзакций в 1С. Журнал транзакций является одной из основных составляющих в базе данных. При помощи журнала транзакций для базы данных создаётся резервная копия, которая в случае сбоя системы вернёт базу в нужное состояние, которое изначально было согласовано.
При помощи журнала транзакций можно выполнить такие действия:
1. Восстановление транзакций;
2. Восстановление транзакций, которые не были окончены;
3. Поддерживать повторения транзакций;
4. Производить восстановление базы данных, из-за системного сбоя.
2. Ошибка Журнал транзакций переполнен
В СУБД 1С может появляться ошибка, которая содержит следующий текст: «Журнал транзакций для базы данных «zup» заполнен». Также, в тексте ошибки может приводиться столбец и таблица, к которым следует обратиться.
Такая ошибка возникает в тех случаях, когда в журнале транзакций находится слишком много данных, то есть, он переполнен.
Рассмотрим два возможных способа для устранения ошибки «Журнал транзакций для базы данных переполнен»:
· В первом способе будем следовать такому алгоритму:
1. Проверить наличие и величину свободного места на дисках, в случае, когда места нет – соответственно, нет места и для записи лога;
2. Если место есть, то ошибка «Журнал транзакций для базы переполнен» является ошибкой MicrosoftSQLServer, то есть – лог с транзакциями был полностью заполнен, но не очищен. Это можно исправить при помощи очистки, которая является стандартной, но эта опция не всегда может помочь устранить неполадку. В случае, если она не сработала – стоит использовать следующий код SQLServer:

код SQLServer
В данном коде: 20 – это величина лога в Мб, а «myDataBase» — название нужной базы с данными.
· Следующий способ – это сразу приступить к уменьшению размера журнала с транзакциями.
Так как с журналом транзакций в SQLServer часто проводится много довольно весомых манипуляций, которые связаны с модификацией данных в СУБД, то такие действия приводят к увеличению размеров файловых данных внутри журнала с транзакциями. В данном случае очень важно вовремя удалять не нужные записи из журнала транзакций SQL, в связи с созданием более актуальных. Если не проводить удаления вовремя, то прошлые файлы в журнале транзакций начинают заполнять всё место на диске и далее станет невозможно работать с СУБД.
Так что, в своём роде, данный способ – это предотвращение ошибки «Журнал транзакций переполнен» в 1С.
В таком случае, удаляем те записи, которые больше не нужны, при помощи команды «BACKUPLOG», следующий шаг – это сделать меньше файл из журнала транзакций MSSQL– при помощи команды «DBCCSHRINKFILE». Таким образом, нужный нам код, для предотвращения ошибки, будет выглядеть таким образом:

Предотвращение ошибки Журнал транзакций переполнен
В данной статье были приведены общие данные о том, что такое журнал транзакций, а также проведена диагностика ошибки «Журнал транзакций переполнен» в 1С. Далее было описано, как устранить данную ошибку и дан способ для предотвращения данной неполадки.
Специалист компании «Кодерлайн»
Айдар Фархутдинов
SQL Server 2008 полная обработка журнала транзакций
- Описание ошибки
- Причина ошибки
- Введение в журналы транзакций
- Устранить неполадки журнала полны
- Решения
- Способ 1: сжать логи в режиме интерфейса
- Шаг первый: Настройте модель восстановления
- Шаг 2: Уменьшите файл журнала
- Описание варианта
- Шаг 3: Настройте режим восстановления
- Способ второй: сжать журнал из командной строки
- Смотрите также
Описание ошибки
Описание ошибки: журнал транзакций базы данных заполнен. Чтобы выяснить, почему пространство в журнале нельзя использовать повторно, см. Столбец log_reuse_wait_desc в sys.databases.
Причина ошибки
Введение в журналы транзакций
Официальная документация имеет следующие инструкции:
Особенности журнала транзакций ядра СУБД SQL Server:
Журнал транзакций реализован в виде отдельного файла или группы файлов в базе данных. Кэш журналов управляется отдельно от буферного кэша страниц данных, поэтому простой, быстрый и мощный код может быть сгенерирован в ядре базы данных SQL Server. Для получения дополнительной информации см. Физическая архитектура журнала транзакций.
Формат записей журнала и страниц не обязательно должен соответствовать формату страницы данных.
Журнал транзакций может быть реализован в нескольких файлах. Эти файлы могут быть определены для автоматического расширения путем установки значения FILEGROWTH журнала. Это уменьшает вероятность нехватки места в журнале транзакций и снижает административные издержки. Для получения дополнительной информации см. Параметры файла ALTER DATABASE (Transact-SQL) и файловой группы.
Механизм повторного использования пространства в файлах журналов быстр и оказывает минимальное влияние на пропускную способность транзакций.
Усечение журнала освобождает место в файле журнала для повторного использования журналом транзакций. Журнал транзакций должен периодически обрезаться, чтобы предотвратить выделение выделенного пространства. Несколько факторов могут задержать усечение журнала, поэтому важно следить за размером журнала. Некоторые операции могут быть записаны с минимальным количеством журналов, чтобы уменьшить их влияние на размер журнала транзакций.
Усечение журнала удаляет неактивные файлы виртуального журнала (VLF) из журнала логических транзакций базы данных SQL Server, освобождая пространство в логическом журнале, чтобы журнал физических транзакций мог повторно использовать это пространство. Если журнал транзакций никогда не усекается, он в конечном итоге заполнит все дисковое пространство, выделенное для физического файла журнала.
Чтобы избежать нехватки места, если усечение журнала по какой-либо причине не отложено, оно будет усечено автоматически после следующих событий:
В простом режиме восстановления происходит после контрольной точки.
В режиме полного восстановления или в режиме массового восстановления журнала, если с момента последнего резервного копирования была создана контрольная точка, усечение выполняется после резервного копирования журнала (если только это не резервная копия только для журнала).
Усечение журнала не уменьшает размер физического файла журнала. Чтобы уменьшить физический размер физического файла журнала, необходимо сжать файл журнала. Информацию об уменьшении размера файлов физического журнала смотрите в разделе Управление размером файлов журнала транзакций. Однако имейте в виду факторы, которые могут задержать усечение журнала. Если после сжатия журнала требуется место для хранения, журнал транзакций будет снова увеличен, что приведет к снижению производительности во время операции увеличения журнала.
Когда записи журнала активны в течение длительного времени, усечение журнала транзакций задерживается, и журнал транзакций может заполниться.
На самом деле усечение журнала может быть отложено по ряду причин. Запросите столбцы log_reuse_wait и log_reuse_wait_desc в представлении каталога sys.databases, чтобы увидеть, какие факторы, если таковые имеются, препятствуют усечению журнала. В следующей таблице описаны значения этих столбцов.
| значение log_reuse_wait | значение log_reuse_wait_desc | описание |
|---|---|---|
| 0 | NOTHING | В настоящее время существует один или несколько повторно используемых файлов виртуальных журналов (VLF). |
| 1 | CHECKPOINT | Контрольные точки не были созданы с момента последнего усечения журнала, или заголовок журнала не был перемещен в файл виртуального журнала (VLF). (Все модели восстановления) Это частая причина задержек усечения журнала. Для получения дополнительной информации см. Контрольная точка базы данных (SQL Server). |
| 2 | LOG_BACKUP | Перед усечением журнала транзакций требуется резервная копия журнала. (Только модель полного восстановления или модель массового восстановления) После завершения резервного копирования следующего журнала некоторое пространство журнала может быть использовано повторно. |
| 3 | ACTIVE_BACKUP_OR_RESTORE | Выполняется резервное копирование или восстановление данных (все модели восстановления). Если резервные копии данных препятствуют усечению журнала, отмена операции резервного копирования может помочь решить проблему, непосредственно вызванную резервным копированием. |
| 4 | ACTIVE_TRANSACTION | Транзакция активна (все модели восстановления): в начале резервного копирования журнала может существовать длительная транзакция. В этом случае может потребоваться другая резервная копия журнала, чтобы освободить место. Обратите внимание, что длительные транзакции предотвратят усечение журналов во всех моделях восстановления, включая простую модель восстановления, где журналы транзакций обычно усекаются на каждой автоматической контрольной точке. Отложенные транзакции. «Отложенная транзакция» является допустимой активной транзакцией, поскольку некоторые ресурсы недоступны и ее откат заблокирован. Сведения о том, что вызывает задержки транзакций и как вывести их из отложенного состояния, см. В разделе Отложенные транзакции (SQL Server). Длительные транзакции могут также заполнять журнал транзакций tempdb. Tempdb неявно используется пользовательскими транзакциями для внутренних объектов, таких как рабочие таблицы для сортировки, рабочие файлы для хеширования, рабочие таблицы курсоров и управление версиями строк. Даже если пользовательская транзакция включает только чтение данных (запросы SELECT), внутренние объекты могут создаваться и использоваться в имени пользовательской транзакции, а затем заполняется журнал транзакций tempdb. |
| 5 | DATABASE_MIRRORING | Зеркальное отображение базы данных приостановлено, или в высокопроизводительном режиме зеркальная база данных значительно отстает от основной базы данных. (Только модель полного восстановления). Дополнительные сведения см. В разделе Зеркалирование базы данных (SQL Server). |
| 6 | REPLICATION | Во время репликации транзакций связанные с публикацией транзакции еще не были переданы в базу данных распространителя. (Только модель полного восстановления). Сведения о репликации транзакций см. В разделе Репликация SQL Server. |
| 7 | DATABASE_SNAPSHOT_CREATION | Создание снимка базы данных. (Все модели восстановления) Это частая причина задержек усечения журнала, и часто она является основной причиной. |
| 8 | LOG_SCAN | Произошло сканирование журнала. (Все модели восстановления) Это частая причина задержек усечения журнала, и часто она является основной причиной. |
| 9 | AVAILABILITY_REPLICA | Вторичная копия группы доступности применяет ведение журнала транзакций для этой базы данных к соответствующей вторичной базе данных. (Модель полного восстановления) Дополнительные сведения см. В разделе: Обзор группы доступности AlwaysOn (SQL Server). |
| 10 | — | Только для внутреннего использования |
| 11 | — | Только для внутреннего использования |
| 12 | — | Только для внутреннего использования |
| 13 | OLDEST_PAGE | Если база данных настроена на использование косвенных контрольных точек, самые ранние страницы в базе данных могут быть раньше, чем порядковый номер журнала контрольных точек (LSN). В этом случае самая ранняя страница может задержать усечение журнала. (Все модели восстановления). Сведения о косвенных контрольных точках см. В разделе Контрольные точки базы данных (SQL Server). |
| 14 | OTHER_TRANSIENT | Это значение в настоящее время не используется. |
Устранить неполадки журнала полны
Официальная документация:Разрешение полного журнала транзакций (ошибка SQL Server 9002)
Решения
В SQL 2008 очистка журнала должна выполняться в простом режиме, а после завершения операции очистки она переводится обратно в полный режим (в противном случае база данных не поддерживает резервное копирование на определенный момент времени)
- Просмотр статуса файла журнала
use dbname
dbcc shrinkfile('logname') --like XXXX_log
Способ 1: сжать логи в режиме интерфейса
Шаг первый: Настройте модель восстановления
Выберите База данных-Свойства-Параметры-Режим восстановления-Простой выбор


В режиме полного восстановления все массовые операции полностью записываются. Однако вы можете свести к минимуму записи журнала для набора массовых операций, временно переключив базу данных на модель восстановления массового журнала для массовых операций. Минимальное ведение журнала более эффективно, чем полное ведение журнала, и уменьшает вероятность крупномасштабных массовых операций, заполняющих доступное пространство журнала транзакций во время массовых транзакций. Однако, если база данных повреждена или потеряна во время минимального ведения журнала, ее невозможно восстановить до точки сбоя.
Шаг 2: Уменьшите файл журнала
Выберите файл базы данных задач


Описание варианта
«База данных»
отображает имя выбранной базы данных.
Тип файла
Выберите тип файла для файла. Доступные опции включают файлы данных и журналов. Опция по умолчанию — Данные. Выберите другой тип файловой группы, и параметры в других полях изменятся соответственно.
Файловая группа
Выберите файловую группу в списке файловых групп, связанных с выбранным выше «типом файла». Выберите другую группу файлов, и параметры в других полях изменятся соответственно.
Имя файла
Выберите файл из списка доступных файлов для выбранной файловой группы и типа файла.
расположение
отображает полный путь к выбранному в данный момент файлу. Этот путь не может быть отредактирован, но может быть скопирован в буфер обмена.
В настоящее время выделено пространство
Для файлов данных отображается текущее выделенное пространство. Для файлов журнала отображается выделенное в настоящее время пространство, рассчитанное на основе вывода DBCC SQLPERF (LOGSPACE).
Свободное пространство
Для файлов данных отображается текущее свободное пространство, рассчитанное на основе вывода SHOWFILESTATS (fileid). Для файлов журнала отображается текущее свободное пространство, рассчитанное на основе выходных данных DBCC SQLPERF (LOGSPACE).
Освободить неиспользуемое пространство
Освобождает неиспользуемое пространство в любом файле для операционной системы и сжимает файл до последней выделенной области, поэтому вы можете уменьшить размер файла без перемещения каких-либо данных. Строки не перемещаются на нераспределенные страницы.
Реорганизовать страницы перед освобождением неиспользуемого пространства
эквивалентно выполнению DBCC SHRINKFILE, который определяет размер целевого файла. Если выбран этот параметр, пользователь должен указать размер файла назначения в поле «Сжать файл в».
«Сжать файл до»
Укажите размер файла назначения для операции сжатия. Это значение размера не должно быть меньше текущего выделенного пространства или больше размера всего экстента, выделенного для файла. Если введенное значение превышает минимальное или максимальное значение, оно вернется к минимальному или максимальному значению после изменения фокуса или нажатия кнопки на панели инструментов.
Очистите файлы, перенеся данные в другие файлы в той же файловой группе
Перенос всех данных из указанного файла. Эта опция позволяет удалять файлы с помощью оператора ALTER DATABASE. Эта опция эквивалентна выполнению DBCC SHRINKFILE с опцией EMPTYFILE.
Шаг 3: Настройте режим восстановления
Выберите База данных-Свойства-Параметры-Режим восстановления-Простой выбор

Способ второй: сжать журнал из командной строки
Этот метод не практичен
USE [master]
GO
ALTER DATABASE DNName SET RECOVERY SIMPLE WITH NO_WAIT
GO
ALTER DATABASE DNName SET RECOVERY SIMPLE- простой режим
GO
USE DNName
GO
DBCC SHRINKFILE(N'DNName_Log',11,TRUNCATEONLY)
GO
USE [master]
GO
ALTER DATABASE DNName SET RECOVERY FULL WITH NO_WAIT
GO
ALTER DATABASE DNName SET RECOVERY FULL- вернуться в полный режим
GO
Смотрите также
Руководство по архитектуре и управлению журналом транзакций SQL Server
Управление размером файлов журнала транзакций
Журнал транзакций
Сжать файл
Исследование в файлах виртуального журнала SQL Server
Sql2008r2 файл журнала проблем сокращения базы данных не становится меньше
Я предлагаю создать простой экземпляр-обертку для вашего AjaxAppender, который хранит события журнала в массиве и присоединяется к обернутому массиву, например следующий (непроверенный):
function WrappedAppender(appender) {
this.appender = appender;
this.loggingEvents = [];
}WrappedAppender.prototype = new log4javascript.Appender();
WrappedAppender.prototype.append = function(loggingEvent) {
this.loggingEvents.push(loggingEvent);
this.appender.append(loggingEvent);
};var ajaxAppender = new log4javascript.AjaxAppender("some_server_page");
ajaxAppender.setThreshold(log4javascript.Level.ERROR);
var wrappedAppender = new WrappedAppender(ajaxAppender);
var log = log4javascript.getLogger("main");
log.addAppender(wrappedAppender);
Затем вы можете просмотреть wrappedAppender.loggingEvents в любой момент, чтобы получить wrappedAppender.loggingEvents ко всем событиям регистрации.
Обновлено 07.09.2022
![]()
Добрый день! Уважаемые читатели и гости IT блога Pyatilistnik.org. В минувший раз мы с вами устранили ошибки оборудования с кодом 10 и кодом 43, вернув нормальное функционирование сервера. Идем далее и сегодня я хочу вас научить делать штатными средствами удобный сервер по сбору логов Windows, за счет пересылки нужных событий с нужных серверов. В результате чего получите единую точку для анализа событий происходящих в нужных системах.
Централизованный сбор логов в Windows
Когда что-то случается в операционной системе Windows или Windows Server, то первым делом куда должен зайти системный администратор после сбоя, это журнал событий с логами. Все это не сложно если у вас 5-10 серверов, а что делать когда их сотни, правильно для таких масштабов нужно иметь централизованный сервер по сбору и хранению логов, например elasticsearch. В случае с elasticsearch, это наикрутейший сервис, но его минус в том, что не все его могут правильно поднять, и нужно иметь приличный запас ресурсов под него.
Но не спешите расстраиваться Билли Гейтс позаботился о своем детище и встроил подобный функционал для реализации нашей задачи прямо по умолчанию в Windows. По умолчанию любой Windows Server умеет, как отправлять события, так и принимать их от других серверов.
Что я хочу:
- 1️⃣Иметь один сервер на который будут складываться все события с контроллеров домена и нужного мне списка серверов
- 2️⃣Настроить нужные мне серверы на отправку определенных событий на заданный сервер
- 3️⃣Возможность предоставления прав на централизованный сервер хранения логов для представителей хелпдеска
- 4️⃣Не устанавливать никакой дополнительный софт
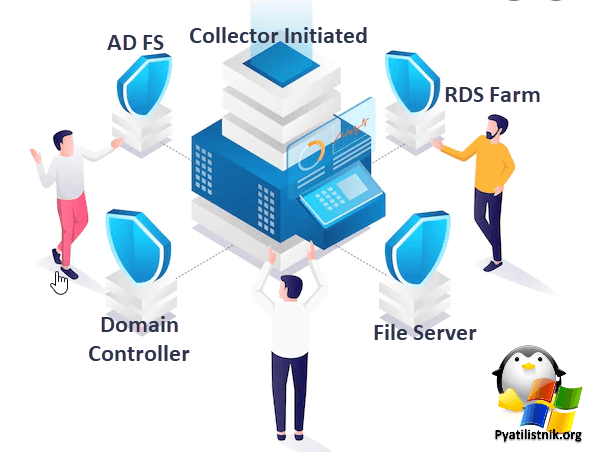
Выглядит схематично это вот так. Тут у нас будут вот такие сущности:
- Сервер собирающий события (Collector Initiated) — Это и есть наш центральный сервер по сбору событий, мы будим его еще называть коллектор логов. В качестве данного сервера будет выступать виртуальная машина с Windows Server 2022.
- Сервер отправляющий события на центральный сервер (Source initiated). Тут по сути может выступать любая операционная система Windows.
Настройка сервера для отправки логов на центральный сервер
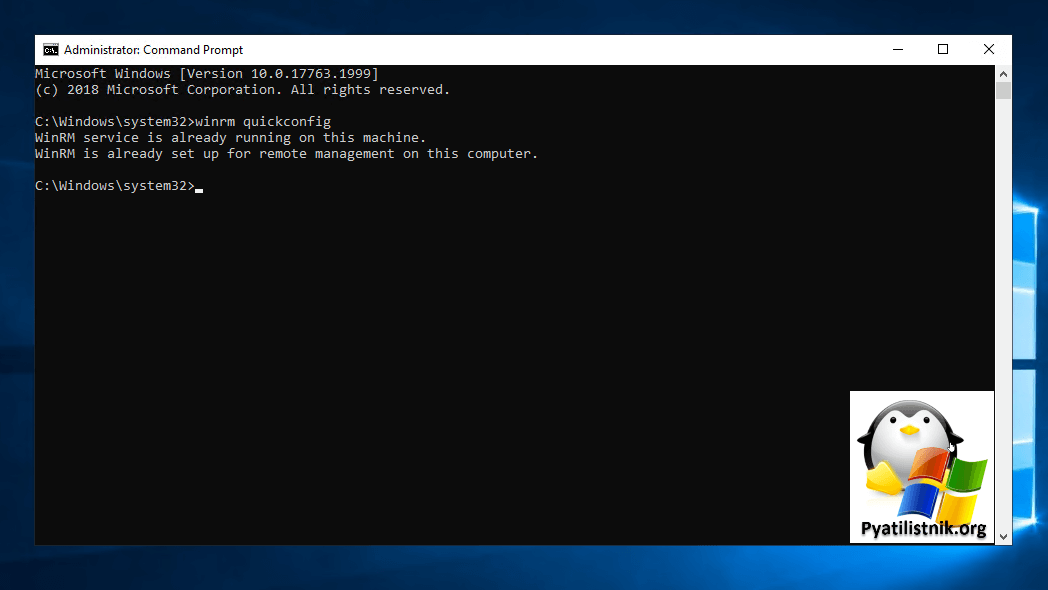
Первым делом вы должны настроить ваши сервера на отправку событий. Я для примера это буду делать для контроллеров домена. Чтобы у вас все работало, вам нужно включить службу для удаленного управления WinRM. Открывайте командную строку от имени администратора и введите команду:
winrm qc или winrm quickconfig
Либо так же через PowerShell:
Теперь нам нужно предоставить права от имени кого вы будите производить подключение к серверам откуда будите брать логи. На выбор у вас два варианта:
- Вы предоставите нужные права учетной записи компьютера, что по мне правильнее
- Либо можно производить подключение от имени доменной учетной записи (Можно и не доменной, но я рассматриваю исключительно окружение Active Directory)
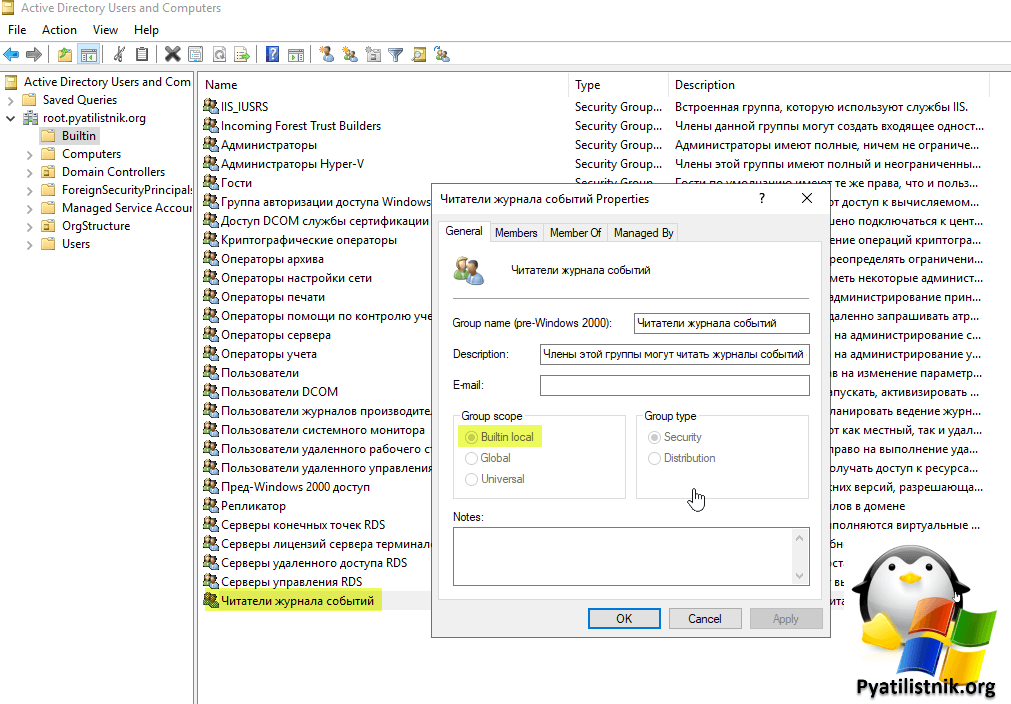
Все, что нам нужно это предоставить учетной записи членство в локальной группе «Читатели журнала событий (Event Log Readers)«
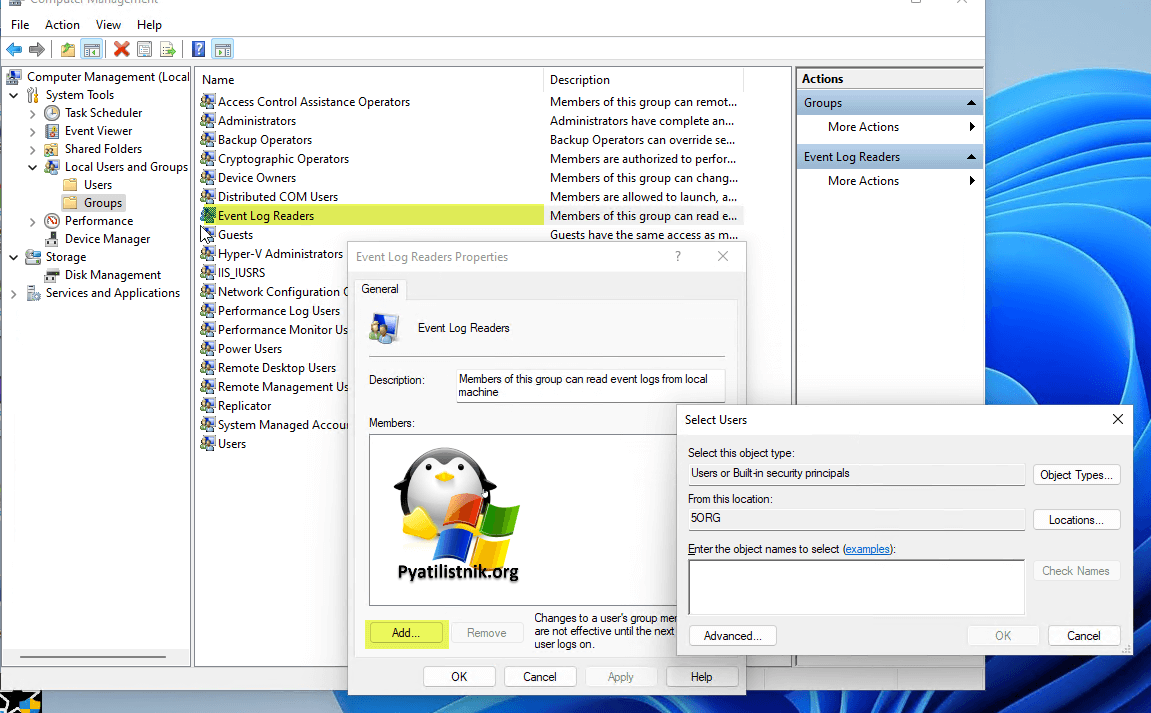
Но если мы говорим про контроллер домена, то там локально вы не сможете увидеть данную оснастку с группами, она просто скрыта из соображений безопасности.
Для того чтобы дать права, откройте оснастку «Active Directory — Пользователи и компьютеры» и перейдите в раздел Bultin. Тут будет группа «Читатели журнала событий (Event Log Readers)«. Добавьте в нее пользователя или учетную запись компьютера, кому вы назначаете права (Члены этой группы могут читать журналы событий с локального компьютера)
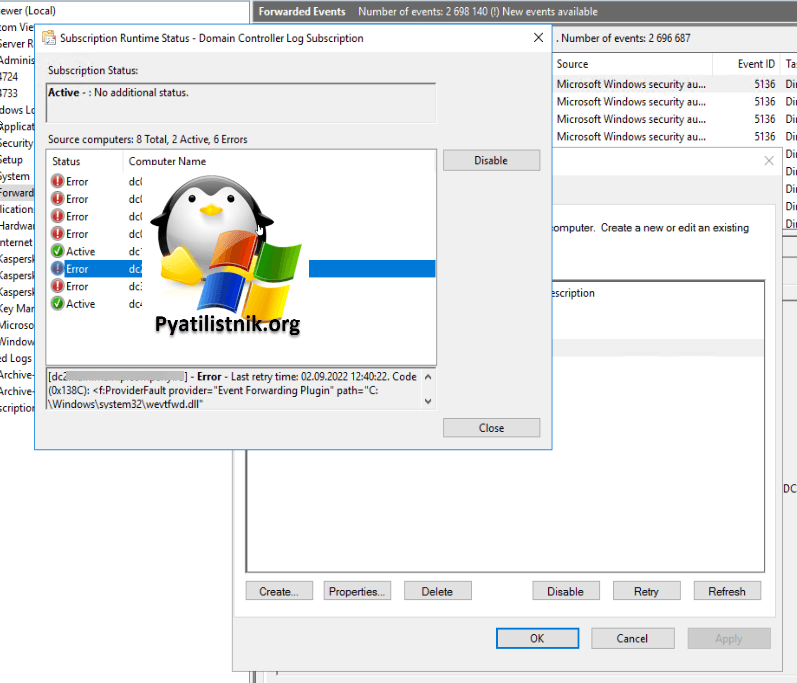
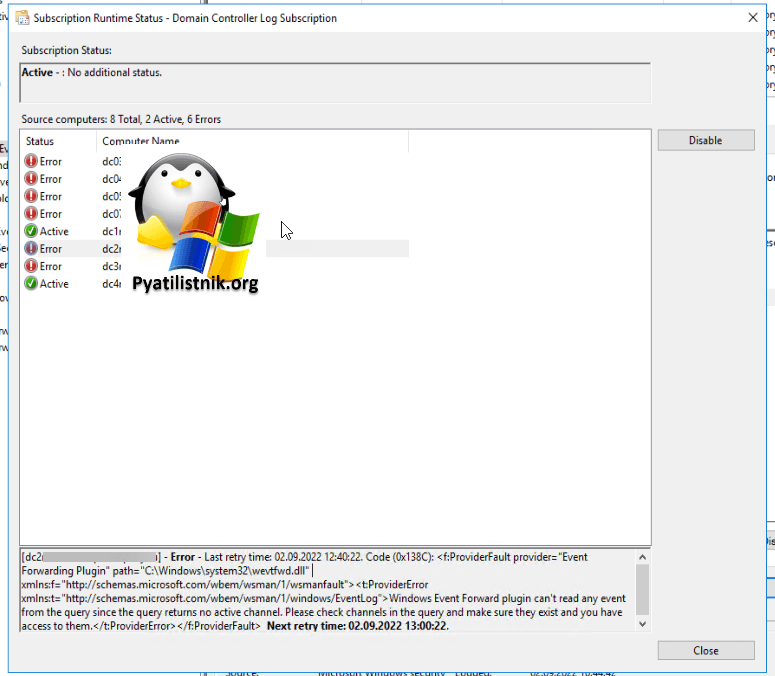
Еще очень важно дать учетной записи Network Service право на чтение, иначе вы будите получать ошибку 0x138C:
Error — Last retry time: 02.09.2022 12:40:22. Code (0x138C): <f:ProviderFault provider=»Event Forwarding Plugin» path=»C:Windowssystem32wevtfwd.dll» xmlns:f=»http://schemas.microsoft.com/wbem/wsman/1/wsmanfault»><t:ProviderError xmlns:t=»http://schemas.microsoft.com/wbem/wsman/1/windows/EventLog»>Windows Event Forward plugin can’t read any event from the query since the query returns no active channel. Please check channels in the query and make sure they exist and you have access to them.</t:ProviderError></f:ProviderFault> Next retry time: 02.09.2022 13:00:22.
Причина ошибки 0x138C, заключается в том, что служба удаленного управления Windows запускается под учетной записью сетевой службы. Нужно добавить SID учетной записи сетевой службы в разрешения на доступ к каналу журнала событий безопасности. Для начала давайте на контроллере домена, с которого я буду отправлять логи посмотрим текущие разрешения, сделать это можно в командной строке Windows.
wevtutil gl security или Wevtutil get-log security
Видим текущий канал безопасности:
channelAccess: O:BAG:SYD:(A;;0xf0005;;;SY)(A;;0x5;;;BA)(A;;0x1;;;S-1-5-32-573)
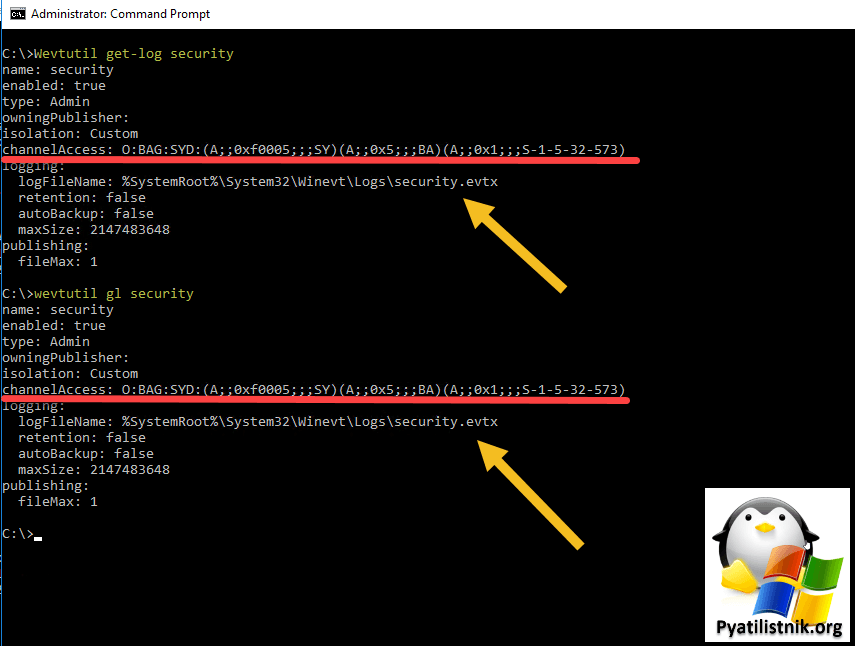
Нам нужно в самый конец добавить SID Network Service. Это стандартный SID (A;;0x1;;;S-1-5-20). Команда будет выглядеть вот так:
wevtutil set-log security /ca:O:BAG:SYD:(A;;0xf0005;;;SY)(A;;0x5;;;BA)(A;;0x1;;;S-1-5-32-573)(A;;0x1;;;S-1-5-20)
или
wevtutil sl security /ca:O:BAG:SYD:(A;;0xf0005;;;SY)(A;;0x5;;;BA)(A;;0x1;;;S-1-5-32-573)(A;;0x1;;;S-1-5-20)
После добавления проверьте, что новый SID добавился в канал доступа. Примерно через 20 минут вы должны начать видеть события в перенаправленных событиях.
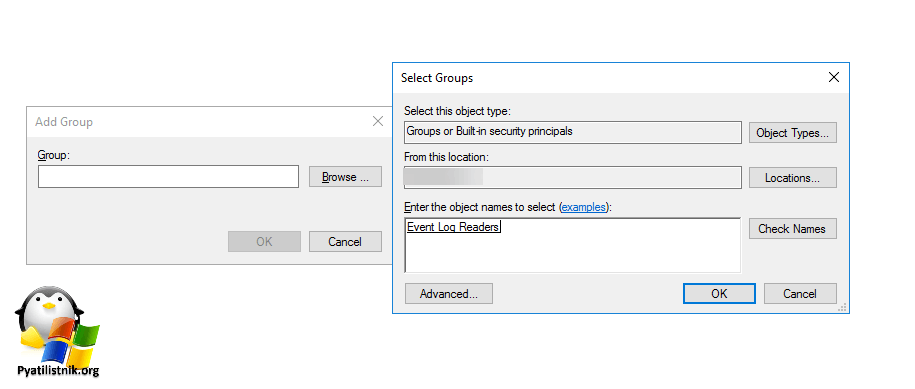
Чтобы назначить массово права для Network Service, вы можете воспользоваться преимуществами Active Directory и создать на нужном OU групповую политику, в которой нужно перейти:
(Computer Configuration — Policies — Windows Settings — Security Settings — Restricted Groups)
Тут вам нужно через правый клик добавить группу «Event Log Readers«.
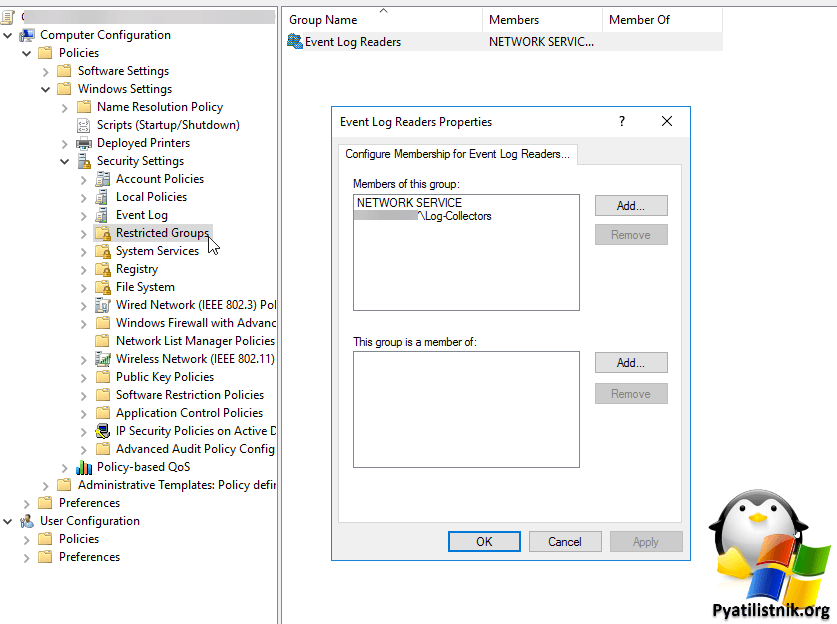
Далее вам нужно ее отредактировать, добавив туда Network Service и все остальные группы, для которых вы выдаете права.
Чем лучше данный метод, это централизацией, что вы легко меняете настройки на нужной группе компьютеров и любой коллега в случае вашего отпуска или иной причины сможет легко все понять и изменить в случае необходимости. Круто будет если вы еще не забудете добавить комментарии к групповой политике.
Те же манипуляции вы можете сделать через реестр Windows, так как я не перестаю вам напоминать, что любая настройка групповой политики меняет именно его. Откройте реестр Windows и перейдите в куст:
HKEY_LOCAL_MACHINESYSTEMCurrentControlSet ServicesEventLogSecurity
Тут будет ключ реестра CustomSD. В CustomSD вы увидите ту самую строку channelAccess. При желании вы можете отредактировать ключ, добавив нужный SID. Так же данный ключ можно менять централизованно через GPO, но это сложнее, чем Restricted Groups.

На этом настройка серверов отдающих логи Windows можно считать законченным, переходим к настройке сервера сборщика логов.
Настройка сервера получающего логи
Теперь давайте проведем настройку на сервере, куда будут складываться централизованно пересланные события. На сервере-коллекторе логов в командной строке от имени администратора введите команду:
Теперь данная служба будет автоматически запускаться при старте системы.
Далее откройте оснастку просмотра событий (eventvwr.msc) и перейдите в раздел «Windows Logs — Forwarded Events«, вызовите его свойства через правый клик.
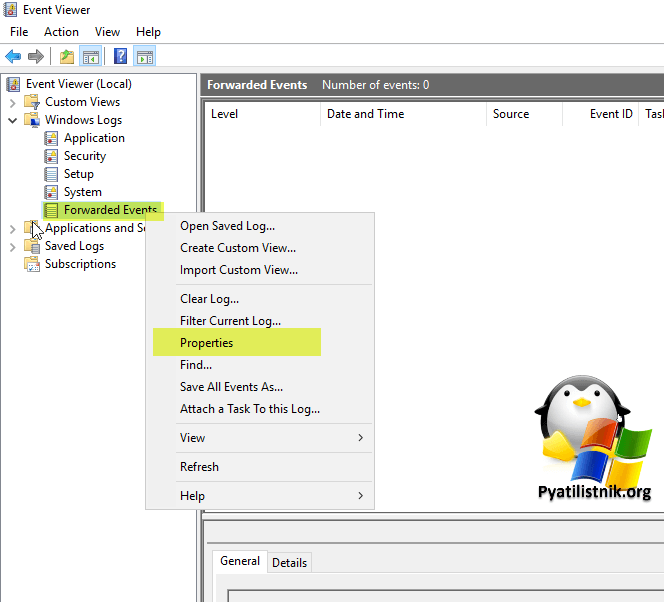
У вас откроется окно с основными настройками сервера-коллектора логов. Первым делом нужно понимать, что для хранения ваших событий вы должны располагать дисковым пространством, в идеале вообще отдельный раздел для этого. По умолчанию все хранится по пути:
%SystemRoot%System32WinevtLogs ForwardedEvents.evtx
- 1️⃣Увеличьте размер текущего журнала исходя из ваших требования, если слишком большой будет журнал, то могут быть сложности с поиском и фильтрацией событий, так как их может быть более нескольких миллионов и дисковая подсистема должна с этим справляться.
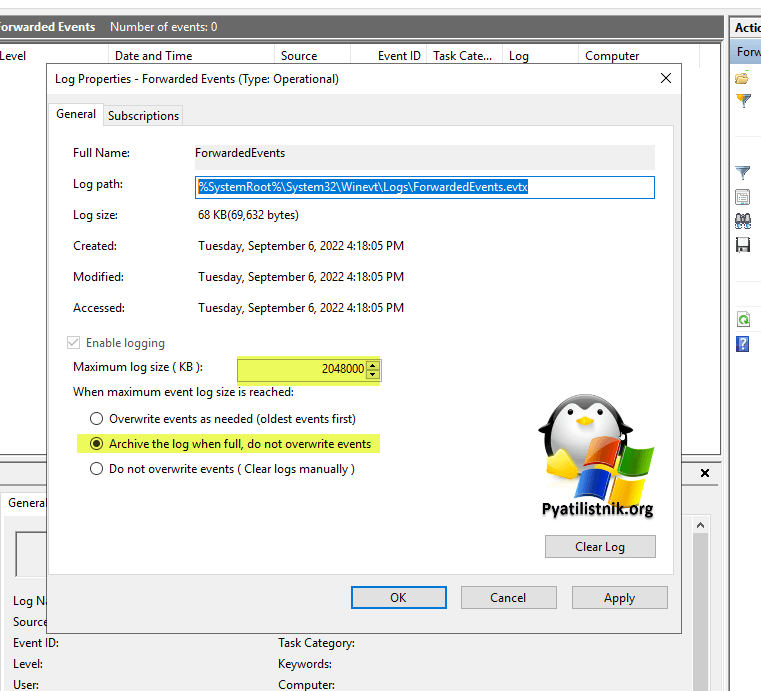
- 2️⃣Выставите опцию для архивирования журнала в случае достижения нужного размера, для этого активируйте «Archive the log when full, do not overwrite evwents«
- 3️⃣Перейдите на вкладку «Subscriptions«. Создаем новую подписку.

- 4️⃣Укажите нужное имя для подписки, это ни на что не влияет, кроме вашего удобства. Описание так же можете указать, чтобы например описать список событий или еще какие-то критерии. Оставляем выбранным пункт «Collector initiated«. После чего нажмите кнопку «Select Computers«, чтобы указать с каких компьютеров нам нужно получать логи.
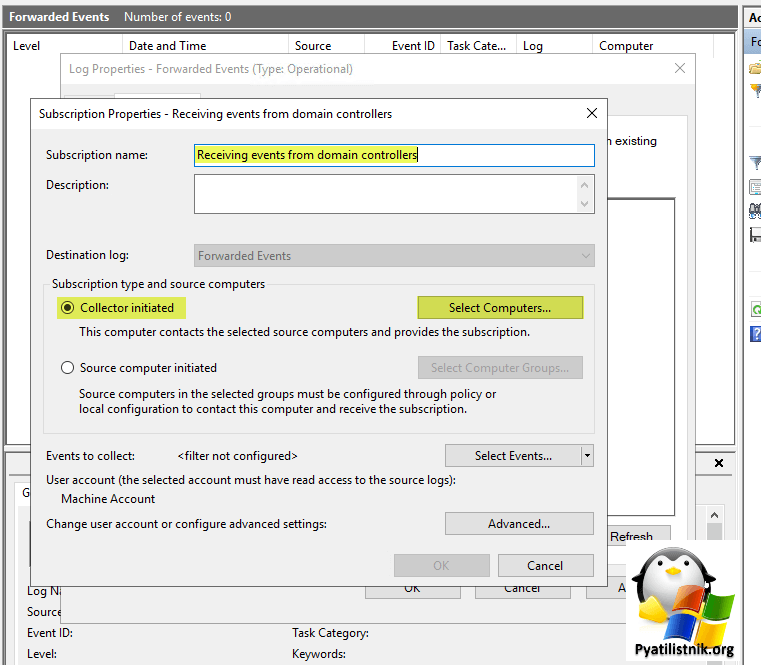
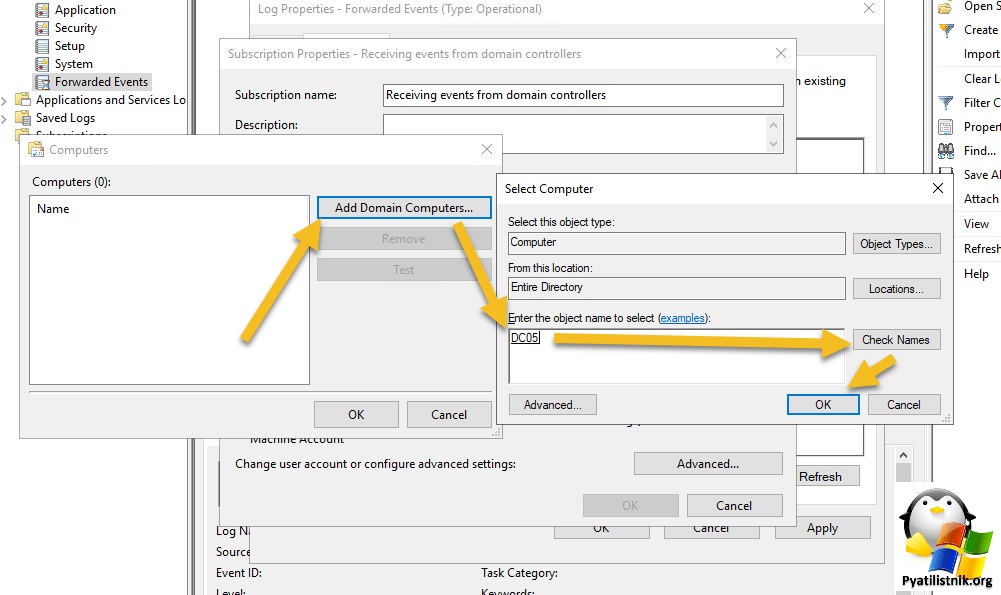
- 5️⃣Добавьте в список интересующие вас компьютеры. Небольшой лайфхак, группы безопасности тут так же работают, так что смело создавайте группу и добавляйте в нее все компьютеры, что нужно логировать.
- 6️⃣Обратите внимание, что у вас тут будет возможность провести небольшое тестирование на доступность удаленного управления и получения событий из журналов.
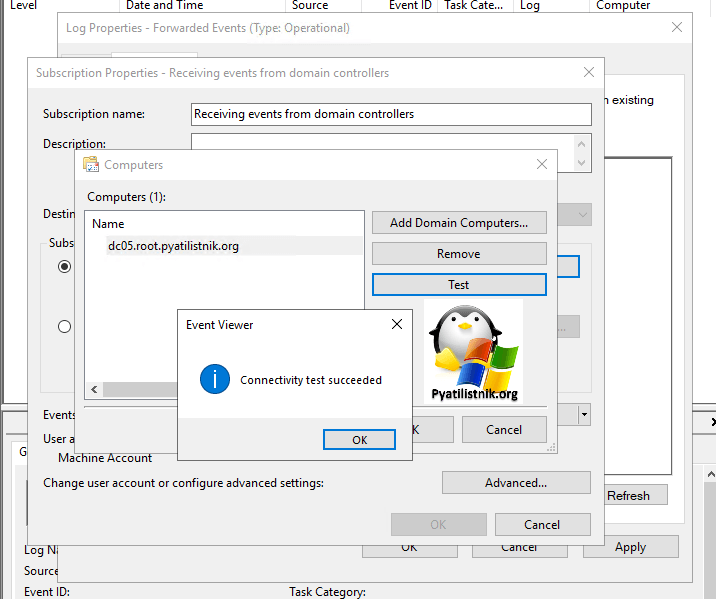
- 7️⃣Теперь перейдите в раздел «Select Events«, он нужен для фильтрации тех событий, что вы хотите отслеживать, так как нет смысла пересылать все, на это не хватит ни каких дисков. Для примера я хочу получать события связанные с блокировкой учетной записи пользователя в домене.
4723,4724,4725,4726,4740,5139,5141,4739,1102,4735,4737, 4730,4734,5136,5137
Выберите дату логирования, я оставляю всегда «Any time«, тип событий будет информационным. В Event logs я указываю стандартный набор журналов, но как вы можете обратить внимание, можно выбрать и более расширенные, например для мониторинга RDS фермы.
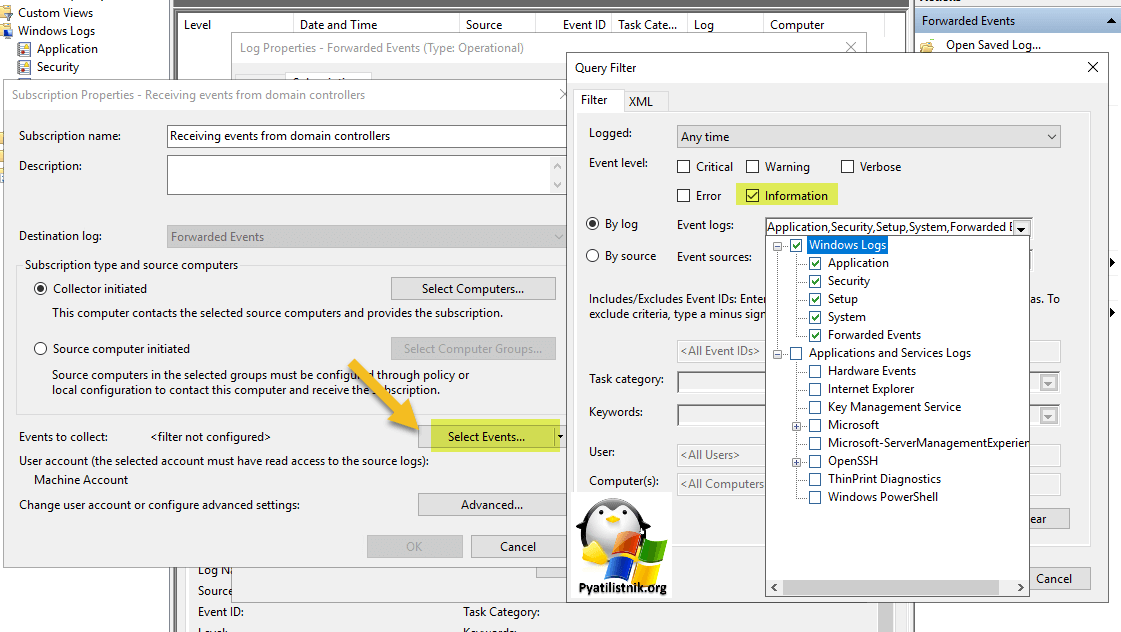
Выставите нужные ID событий, что вы собираетесь получать. При желании вы можете задать еще более точный фильтр, указав ключевые слова.
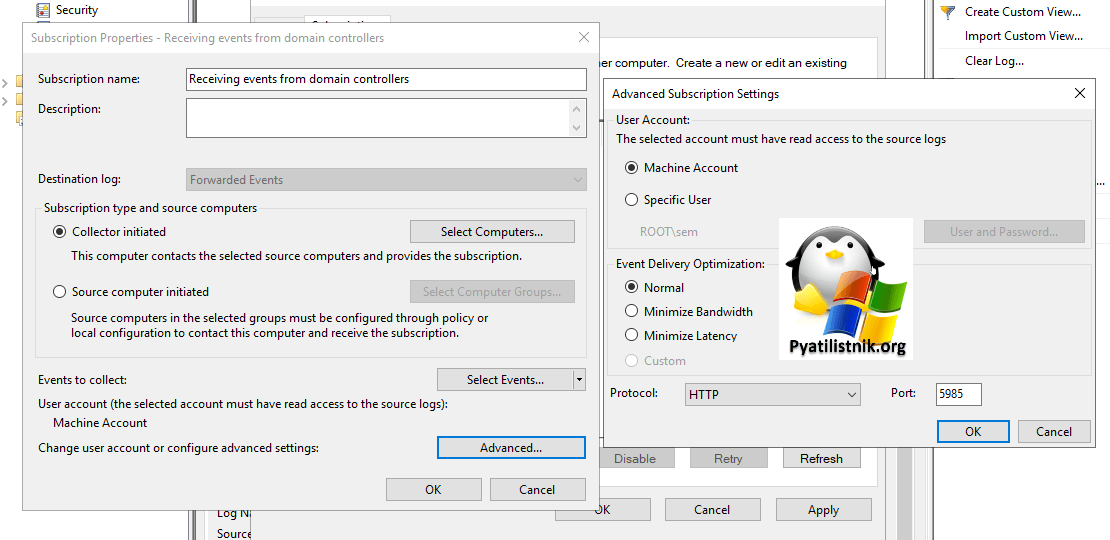
- 8️⃣Сохраните настройки. Остается теперь указать от имени какой учетной записи мы будим работать. Для этого есть пункт «Advanced«. Тут я оставляю работать от имени учетной записи текущего компьютера, но вы можете смело поменять и на пользовательскую учетку. Если вы используете нестандартный порт подключения, а это 5985, то вы смело его можете тут поменять.
- 9️⃣Давайте сразу протестируем доступность получения событий по подписке. Для этого в контекстном меню вызовите пункт «Runtime Status«.
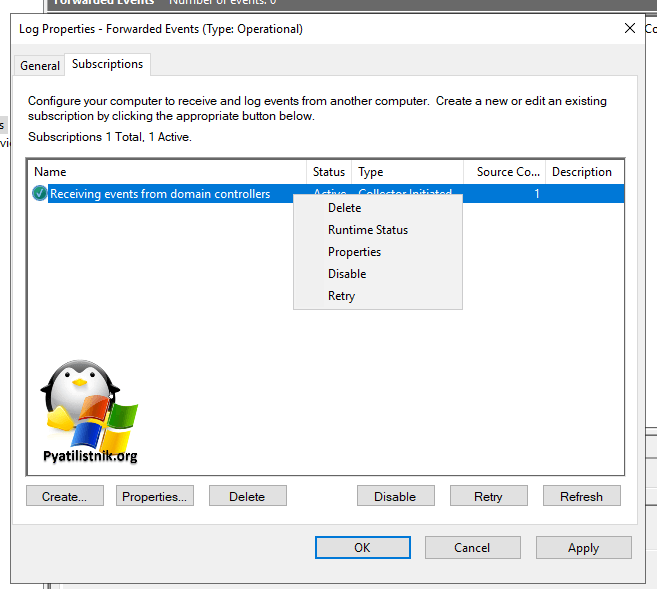
Везде должен быть статус «Active«.
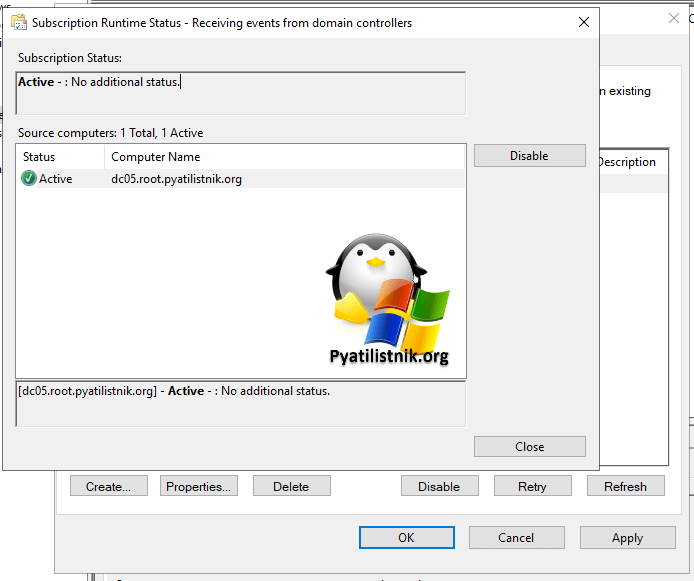
Как я и писал выше, минут через 10-15 логи начнут поступать.
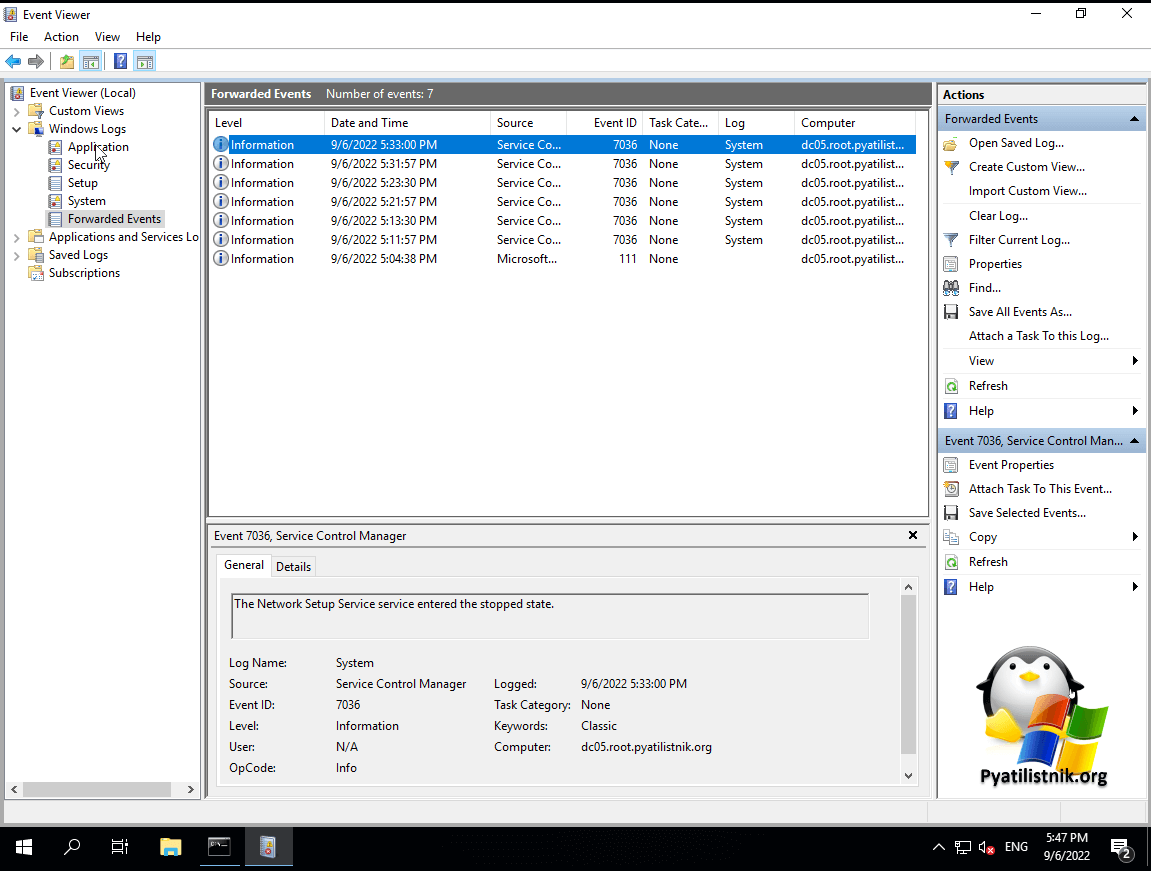
Траблшутинг сервера-коллектора логов
Очень часто тут бывают ошибки 0x138C, как ее решать я описал выше.
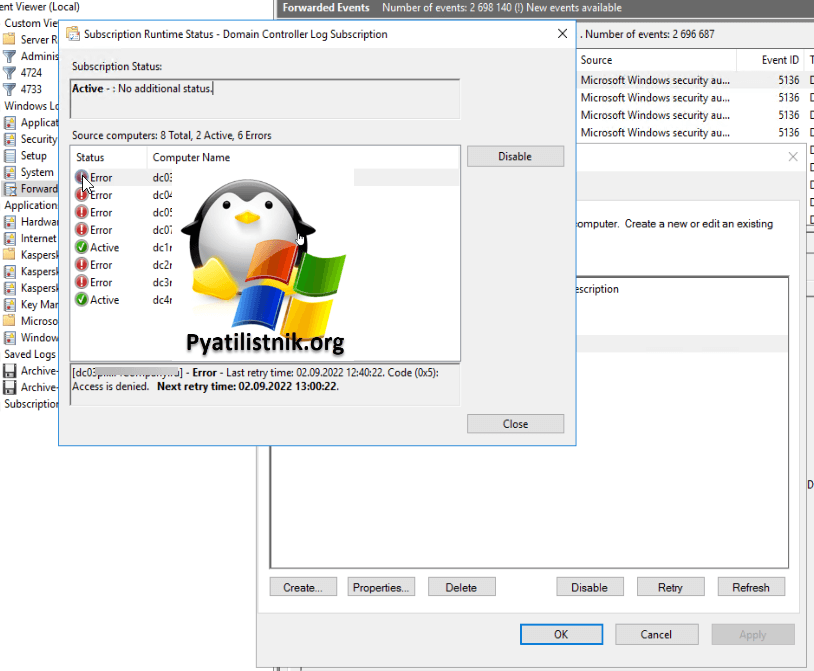
Еще если вы не дали права, то получите «Access is denied«.
Еще если вы выбрали слишком много событий, то можете увидеть ошибку:
Error – Last retry time: 2022-08-28 16:43:18. Code (0×7A): The data area passed to a system call is too small. Next retry time
Если у вас есть такие крупные продукты, как SharePoint, MS Exchange, MS CRM, то получая с них события, вы можете видеть ошибку ID 6398:
The description for Event ID 6398 from source A cannot be found. Either the component that raises this event is not installed on your local computer or the installation is corrupted. You can install or repair the component on the local computer.
Как я вам выше показал в реестре Windows каждый журнал описан в своей ветке и за него отвечает определенная DLL библиотека, если такого источника не будет на вашем коллекторе, то и могут возникать подобного рода ошибки. Для крупных приложений очень сложно произвести перенос в другое место, так как очень много источников, кто туда пишет. Поэтому PowerShell нам в помощью.
На просторах интернета есть добрые люди, кто столкнулся с такой задачей и ее прекрасно выполнил, и самое прекрасное, что человек поделился решением со всем интернетом.
https://github.com/sanglyb/ps-copy-log-source если вдруг по какой-то причине скриптов не будет в доступе, то можете скачать их тут
Тут два скрипта:
- export-log — Для экспорта данных с серверов откуда собираем данные
- import-log — Для импорта на сервере-коллекторе недостающих данных
Алгоритм такой, копируем скрипт export-log на сервер со специфическим ПО, у меня это будет Dynamic CRM. Запустите PowerShell и перейдите в расположение вашего скрипта, выберите его и добавьте ключ, являющийся частью источника событий, например crm.
Данный скрипт создаст папку с названием ключа, далее просканирует все журналы событий, если найдет среди них похожий на crm, то сделает их дамп и создаст текстовый файл со списком сдампленных разделов.
Вот еще пример с Kaspersky.
Теперь идем на сервер коллектор и копируем туда созданную ранее папку. После чего открываем PowerShell так же в режиме администратора и импортируем все, что до этого получили.
В скрипте изначально задан каталог C:CustomEvents, так что создайте его заранее иначе будете получать ошибку. После этого все логи будут корректно отображаться.
Еще из проблем может быть недоступность порта 5985, который должна слушать служба winrm. Проверяем порт, как я рассказывал ранее. Может получиться так, что какая-то из служб может его занять, как в случае с 1С или IIS.
Посмотреть кто слушает и что netstat -ant, далее netsh http show iplisten
И удаляем:
netsh http delete iplisten ipaddress=ip
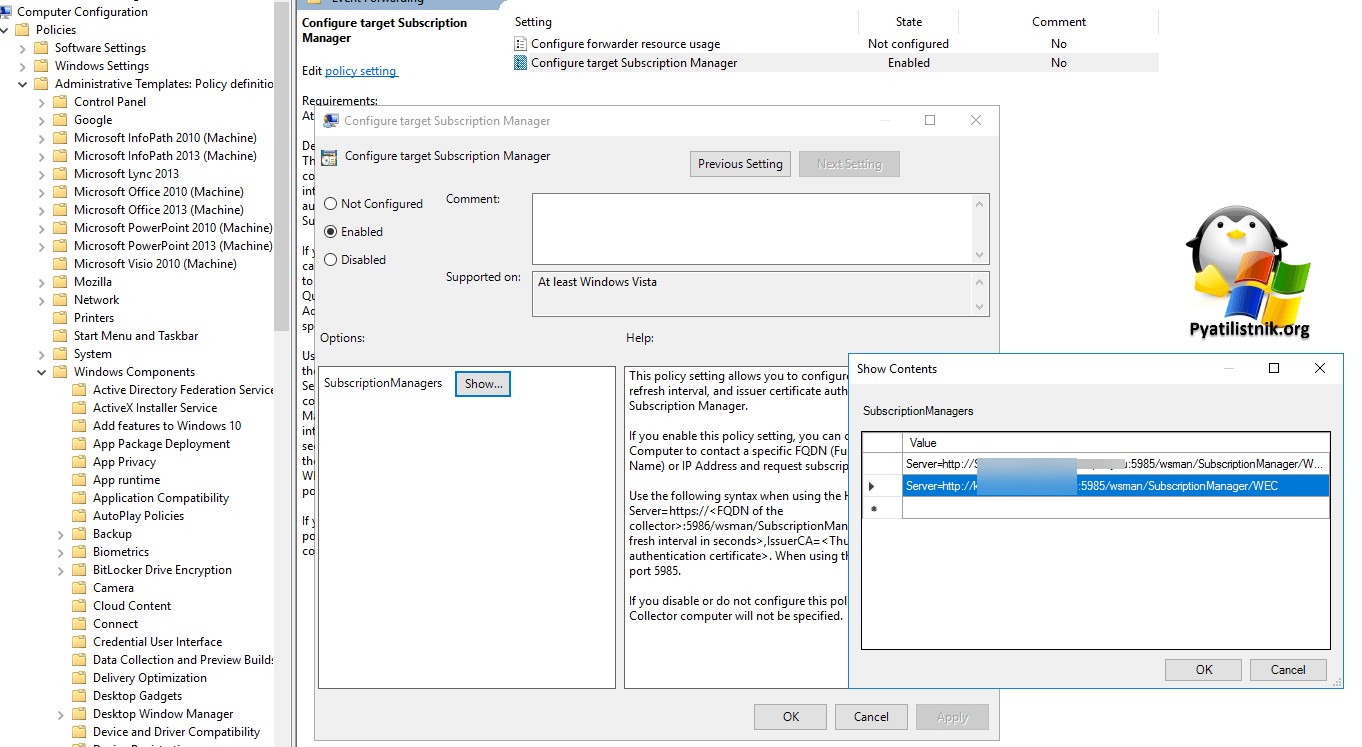
Что делать если у вас несколько серверов коллекторов
Такое то же бывает, когда в компании есть несколько систем мониторинга и аудита, да еще и у разных направлений, для такой ситуации лучше использовать настройку:
Конфигурация компьютера — Политики — Административные шаблоны — Компоненты Windows — Пересылка событий (Computer Confiruration — Policies — Administrative Tempates — Windows Components — Event Forwarding)
Включаем параметр «Configure target Subscription Manager«. Тут задаем нужное количество серверов вы формате:
Server=http://FQDN:5985/wsman/SubscriptionManager/WEC
Еще тут через запятую можно добавить интервальность Refresh=10.
Можно сказать это как зеркалирование портов.
На этом у меня все. Я попытался описать полностью процесс настройки централизованного сервера коллектора логов на базе Windows Server 2022. Рассказал, про подводные камни и как их обходить. С вами был Иван Сёмин, автор и создатель IT блога Pyatilistnik.org. Если у вас остались вопросы, то жду их в комментариях.
Про большую часть проблем, которые происходят с операционной системой и оборудованием, можно узнать через логи и журналы. В Windows, логи, называются так же событиями (events), а для их просмотра используется интерфейс под названием «Просмотр событий» (Event Viewer). События хранятся на компьютере, на котором они же и создаются. Такая ситуация может вызвать неудобства, если вы работаете со множеством серверов. Мы можем использовать функционал, который называется «Подписки» (Event Subscription) для сбора таких логов в одном месте. Как это можно сделать и будет рассмотрено, на примерах, в этой статье.
Как работают подписки на события
Главный компьютер (сервер), который будет получать и хранить события с других хостов, называют «сборщиком» (collector). Он может работать в двух режимах:
- Коллектор может подключаться к выбранным компьютерам сам и забирать с них обновления (в GUI называется «Инициировано сборщиком»/ «Colletor Initiated»). Так же называют pull подпиской;
- Компьютеры (клиенты) сами отправляют события на сборщик (сервер) (в GUI «Инициировано исходным компьютером»/»Source Computer Initiated»). Так же называется «event forwarding» или push подпиской.
Моменты, которые я отмечу для «Colletor Initiated»:
- Обработка логов — ресурсоемкая задача. Если сервер-коллектор будет забирать логи одновременно — это может задействовать большое количество ресурсов;
- В подписку могут быть добавлены только доменные компьютеры. В т.ч. вы не можете указывать группы в подписке, а только отдельно компьютеры;
- Политики использовать не обязательно и общая настройка немного проще.
То что я отмечу для «Source Computer Initiated»:
- Первоначальная настройка может вызвать сложности, решение которых может занять существенное время;
- Клиенты сами отправляют логи, что делает нагрузку на сервер меньше;
- Легче автоматизируется, если вы хотите добавлять клиентов автоматически;
- Можно добавить как группы, так и компьютеры. Компьютер может быть в рабочей группе или домене.
Мой личный выбор — использовать «Collector Initiated» где количество клиентов меньше 10. Если планируется больше, то «Source Computer Initiated». С точки зрения нагрузки — количество клиентов вообще может не играть роли, если клиенты создают по одному логу в 10 минут.
Microsoft, например, рекомендует использовать 4 процессора и 16 ГБ ОЗУ для нагрузки в 2000-4000 клиентов. Как я смог понять это так же равно 3000 событий в секунду.
Логи физически хранятся на дисках. Если логов приходит много, то стоит обратить внимание на скорость дисков.
Предварительная настройка
На обоих сервере и клиенте должен быть включен сервис WinRM и выполнена первоначальная его настройка. Это можно сделать одной из следующих команд.
# cmd
winrm qc
# powershell
Enable-PSRemotingПроверить, что сервис запущен на обоих компьютерах можно с помощью одной команды.
Get-Service -ComputerName 'localhost' -Name '*WinRM*' | fl *
WinRM, в зависимости от настроек, может использовать протокол HTTP на 5985/TCP порту либо HTTPS на 5986/TCP порту. Это же касается и сбора событий с компьютеров.
Если вы используете компьютеры, которые находятся в домене, у вас по умолчанию используется Kerberos. В некоторых других случаях может использоваться NTLM. В обоих случаях (Kerberos/NTLM или HTTP/HTTPS), обмен логов зашифрован и подключения проходят аутентификацию. Случай с HTTPS используется, когда вы хотите чтобы аутентификация была так же с помощью сертификатов SSL/TLS. Это может понадобиться, когда у вас компьютер вне домена и вы будете использовать NTLM. Вариант с HTTPS, в статье, рассматривается от части.
Выбранные порт должен быть открыт на всех ПК. Проверить, что порт открыт и за ним стоит сервис можно через следующую команду Powershell.
Test-NetConnection -ComputerName 'localhost' -Port 5985
WinRM, в зависимости от настроек, может использовать протокол HTTP на 5985/TCP порту либо HTTPS на 5986/TCP порту. Это же касается и сбора событий с компьютеров.
Если вы используете компьютеры, которые находятся в домене, у вас по умолчанию используется Kerberos. В некоторых других случаях может использоваться NTLM. В обоих случаях (Kerberos/NTLM или HTTP/HTTPS), обмен логов зашифрован и подключения проходят аутентификацию. Случай с HTTPS используется, когда вы хотите чтобы аутентификация была так же с помощью сертификатов SSL/TLS. Это может понадобиться, когда у вас компьютер вне домена и вы будете использовать NTLM. Вариант с HTTPS, в статье, рассматривается от части.
Выбранные порт должен быть открыт на всех ПК. Проверить, что порт открыт и за ним стоит сервис можно через следующую команду Powershell.
Test-NetConnection -ComputerName 'localhost' -Port 5985Еще один важный момент — это работа сервиса подписок WEC (Windows Event Collector) на сервере, который будет собирать и хранить логи. По умолчанию, этот сервис, выключен. Вы должны включить его на сервере.
wecutil.exe qc
# проверяем работу службы через Powershell
Get-Service -Name 'Wecsvc' | fl *
Отправка событий на сервер-сборщик
Вариант настройки, когда клиенты сами обращаются к серверу.
Настройка отправляющего хоста
Для того, чтобы компьютер-клиент знал куда отправлять логи, ему нужно указать URL сервера. Этот url можно указать в групповой (или локальной) политике по пути:
- Конфигурация компьютера -> Административные шаблоны -> Компоненты Windows -> Пересылка событий
- Computer Configuration -> Administrative Templates -> Windows Components -> Event Forwarding
По этому пути открыть политику «Настроить конечный диспетчер подписи» и указать строку следующего типа.
Server=http://<полное доменное имя сборщика>:5985/wsman/SubscriptionManager/WEC,Refresh=60В этой строке, соответственно, нужно указать FQDN сервера, на который будут отправляться события. В моем случае это ‘sr2.domain.local’. Значение «Refresh=60» значит, что раз в 60 секунд будут проверяться новые подписки, а не время отправки логов.

Отправка событий на сервер-сборщик
Вариант настройки, когда клиенты сами обращаются к серверу.
Настройка отправляющего хоста
Для того, чтобы компьютер-клиент знал куда отправлять логи, ему нужно указать URL сервера. Этот url можно указать в групповой (или локальной) политике по пути:
- Конфигурация компьютера -> Административные шаблоны -> Компоненты Windows -> Пересылка событий
- Computer Configuration -> Administrative Templates -> Windows Components -> Event Forwarding
По этому пути открыть политику «Настроить конечный диспетчер подписи» и указать строку следующего типа.
Server=http://<полное доменное имя сборщика>:5985/wsman/SubscriptionManager/WEC,Refresh=60В этой строке, соответственно, нужно указать FQDN сервера, на который будут отправляться события. В моем случае это ‘sr2.domain.local’. Значение «Refresh=60» значит, что раз в 60 секунд будут проверяться новые подписки, а не время отправки логов.
Если вы планировали делать https сервер, то нужно будет указать иной порт (5986) и дополнительно заполнить параметр открытого ключа.
Настройка принимающего сервера
Кроме включенных сервисов (WEC и WinRM) и открытых портов нужно изменить разрешения для URL, которое настраивалось через политику выше. Разрешения по умолчанию могут не работать.
Дело в том, что в редакциях 2012 и старше, права на чтение запросов поступающих на URL ‘http://ВашСервер:5985/wsman/’, выдается только сервису — WinRM. Служба подписок ‘Wecsvs’ так же нуждается в доступе к этому URL. Эта ситуация может отличаться в разных редакциях. У Microsoft не всегда было описание этой проблемы и даже сейчас его сложно найти. Проверить есть ли права в вашем случае можно через следующую команду.
netsh http show urlacl url=http://+:5985/wsman/
Если у вас отображается один пользователь и в параметре SDDL только одна пара скобок «(…)» (как в примере выше), то это говорит об отсутствии нужных разрешений. Чтобы добавить пользователя мы должны удалить предыдущую запись и добавить новую запись.
# удаление
netsh http delete urlacl url=http://+:5985/wsman/
# добавление (рекомендую запускать в CMD, а не Powershell)
netsh http add urlacl url=http://+:5985/wsman/ sddl="D:(A;;GX;;;S-1-5-80-569256582-2953403351-2909559716-1301513147-412116970)(A;;GX;;;S-1-5-80-4059739203-877974739-1245631912-527174227-2996563517)"
Если у вас отображается один пользователь и в параметре SDDL только одна пара скобок «(…)» (как в примере выше), то это говорит об отсутствии нужных разрешений. Чтобы добавить пользователя мы должны удалить предыдущую запись и добавить новую запись.
# удаление
netsh http delete urlacl url=http://+:5985/wsman/
# добавление (рекомендую запускать в CMD, а не Powershell)
netsh http add urlacl url=http://+:5985/wsman/ sddl="D:(A;;GX;;;S-1-5-80-569256582-2953403351-2909559716-1301513147-412116970)(A;;GX;;;S-1-5-80-4059739203-877974739-1245631912-527174227-2996563517)"Создание подписки
После этого можно открыть Event Viewer и настраивать подписку нажав следующие кнопки.

В новом окне нужно указать название подписки, например «Сервера SQL». «Конечный журнал» — это место, в которое будут попадать логи. Чаще всего используется журнал «Перенаправленные события» так как он пустой и удобен для сбора логов (не будет путаницы). Часть параметров можно менять после создания подписки.
В данном случае мы используем тип подписки, где клиенты сами отправляют события. Этому типу подписки соответствует настройка «Инициировано исходным компьютером». Мы должны открыть это окно и добавить в список компьютеры, от которых ожидаем отправку событий.

В новом окне нужно указать название подписки, например «Сервера SQL». «Конечный журнал» — это место, в которое будут попадать логи. Чаще всего используется журнал «Перенаправленные события» так как он пустой и удобен для сбора логов (не будет путаницы). Часть параметров можно менять после создания подписки.
В данном случае мы используем тип подписки, где клиенты сами отправляют события. Этому типу подписки соответствует настройка «Инициировано исходным компьютером». Мы должны открыть это окно и добавить в список компьютеры, от которых ожидаем отправку событий.
В окне «Выбрать события» можно выбрать журналы, их уровень и установить разные фильтры. Для диагностики и тестирования лучше выбирать один журнал и несколько событий. Большое количество журналов может расходовать весомое количество ресурсов. Во вкладке ‘XML’ настройки так же можно менять. XML так же можно копировать и использовать в других подписках (в т.ч. импорт через wecutil.exe).

В окне «Дополнительно» указывается протокол и скорость передачи событий. Эти настройки соответствуют следующим значениям:
- Обычный (Normal) — отправка либо по достижению 5 событий либо раз в 15 минут;
- Уменьшенная пропускная способность (Minimize Bandwith) — раз в 6 часов;
- Уменьшенная задержка (Minimize Latency) — раз в 30 секунд.

В окне «Дополнительно» указывается протокол и скорость передачи событий. Эти настройки соответствуют следующим значениям:
- Обычный (Normal) — отправка либо по достижению 5 событий либо раз в 15 минут;
- Уменьшенная пропускная способность (Minimize Bandwith) — раз в 6 часов;
- Уменьшенная задержка (Minimize Latency) — раз в 30 секунд.
После нажатия кнопок «Ок» подписка будет создана.
При открытии «Состоянии выполнения» вы должны увидеть зеленные галочки у компьютеров, которые вы добавляли. Они могут появиться не сразу (в моем случае это пару минут). Все события будут попадать в журнал «Перенаправленные события».

Зеленые отметки не всегда говорят, что все работает. Например, после подобных настроек у вас будут отправляться большая часть журналов, но некоторые так и не появятся. Например, для журнала «Безопасность» (Security) нужно будет так же изменить параметры доступа.
Настройка доступа для журнала «Безопасность» (Security)
Локальный доступ, к некоторым журналам, требует отдельных прав. Эти права есть у локальных групп «Читатели журнала событий» (Event Log Readers). Журналам «Безопасность» будет читать сервис «Network Service». Т.е. мы должны добавить эту учетную запись в журнал.
Добавить учетную запись можно через политики и собственноручно. Ниже показан вариант, где пользователь «Network Service» добавлялся в группу для сбора логов с домен контроллера.

Зеленые отметки не всегда говорят, что все работает. Например, после подобных настроек у вас будут отправляться большая часть журналов, но некоторые так и не появятся. Например, для журнала «Безопасность» (Security) нужно будет так же изменить параметры доступа.
Настройка доступа для журнала «Безопасность» (Security)
Локальный доступ, к некоторым журналам, требует отдельных прав. Эти права есть у локальных групп «Читатели журнала событий» (Event Log Readers). Журналам «Безопасность» будет читать сервис «Network Service». Т.е. мы должны добавить эту учетную запись в журнал.
Добавить учетную запись можно через политики и собственноручно. Ниже показан вариант, где пользователь «Network Service» добавлялся в группу для сбора логов с домен контроллера.
Если это не домен-контроллер, то учетная запись добавляется в локальную группу через «Управление компьютером».

После добавления пользователей компьютеры нужно будет перезагрузить т.к. иначе «Network Service» не начнет работу. После перезагрузки, в моем случае, события начали приходить меньше чем за 1 минуту.
Добавить пользователя можно так же через политику, что рассмотрено на другом варианте подписки.
Сбор событий с компьютеров
Так как мы настраиваем сценарий, когда сервер-коллектор будет сам заходить на хосты и забирать логи, мы должны определиться с пользователем и правами для него.
Выдача разрешений на чтение журналов
Кроме открытия порта и запуска сервисов, в зависимости от ситуации, вам может понадобиться добавить в группу «Читатели журнала событий» разные учетные записи:
- Учетная запись пользователя или компьютера, который будет забирать логи с удаленных компьютеров. Исключение — администраторы т.к. они уже имеют эти права.
- Учетная запись «NETWORK SERVICE», если вы планируете собирать логи с журнала «Безопасность» («Security»). Даже если вы являетесь администратором — это понадобится.
Как добавляется пользователь в локальную группу — было продемонстрировано в подписке, которая рассматривалась выше. Добавить пользователей в группу можно так же скриптом или через разные политики.
Вариант, показанный на скриншоте ниже, работает через политику «Группы с ограниченным доступом» («Restricted Groups»). Будьте осторожны т.к. учетные записи, которые добавляются через эту политику, перезаписывают локальных пользователей в соответствующей группе. Чтобы добавить учетную запись — вам нужно:
- Открыть или создать политику, затем пройти по соответствующему пути (видно на скриншоте ниже), нажать правой клавишей по «Группы с ограниченным доступом» и выбрать вариант «Добавить группу»;
- Через кнопку «Обзор» выбрать локальную группу в которую вы планируете добавлять учетные записи. В нашем случае это «Читатели журнала событий» или «Event Log Readers»;
- Выбрать пользователя, которого вы планируете использовать для сбора логов. В случае, если вы хотите добавить компьютер, то в конце нужно дописать «$», как и в примере ниже с «SR2». Так же добавьте «NETWORK SERVICE», если планируете собирать события из журнала «Безопасность».

После добавления пользователей компьютеры нужно будет перезагрузить т.к. иначе «Network Service» не начнет работу. После перезагрузки, в моем случае, события начали приходить меньше чем за 1 минуту.
Добавить пользователя можно так же через политику, что рассмотрено на другом варианте подписки.
Сбор событий с компьютеров
Так как мы настраиваем сценарий, когда сервер-коллектор будет сам заходить на хосты и забирать логи, мы должны определиться с пользователем и правами для него.
Выдача разрешений на чтение журналов
Кроме открытия порта и запуска сервисов, в зависимости от ситуации, вам может понадобиться добавить в группу «Читатели журнала событий» разные учетные записи:
- Учетная запись пользователя или компьютера, который будет забирать логи с удаленных компьютеров. Исключение — администраторы т.к. они уже имеют эти права.
- Учетная запись «NETWORK SERVICE», если вы планируете собирать логи с журнала «Безопасность» («Security»). Даже если вы являетесь администратором — это понадобится.
Как добавляется пользователь в локальную группу — было продемонстрировано в подписке, которая рассматривалась выше. Добавить пользователей в группу можно так же скриптом или через разные политики.
Вариант, показанный на скриншоте ниже, работает через политику «Группы с ограниченным доступом» («Restricted Groups»). Будьте осторожны т.к. учетные записи, которые добавляются через эту политику, перезаписывают локальных пользователей в соответствующей группе. Чтобы добавить учетную запись — вам нужно:
- Открыть или создать политику, затем пройти по соответствующему пути (видно на скриншоте ниже), нажать правой клавишей по «Группы с ограниченным доступом» и выбрать вариант «Добавить группу»;
- Через кнопку «Обзор» выбрать локальную группу в которую вы планируете добавлять учетные записи. В нашем случае это «Читатели журнала событий» или «Event Log Readers»;
- Выбрать пользователя, которого вы планируете использовать для сбора логов. В случае, если вы хотите добавить компьютер, то в конце нужно дописать «$», как и в примере ниже с «SR2». Так же добавьте «NETWORK SERVICE», если планируете собирать события из журнала «Безопасность».
Результат работы политики можно увидеть после применения политики, открыв группу локально.

Для того чтобы учетная запись «NETWORK SERVICE» полноценно заработала — потребуется перезагрузка компьютера.
Создание подписки
Откройте «Event Viewer» и нажмите следующие кнопки для создания подписки:
- Переходим на страницу подписок;
- Открываем окно создания подписки;
- Выберете имя для подписки;
- Тип подписки, в этом случае, «Инициировано сборщиком»;
- Окно для добавления компьютеров.

Для того чтобы учетная запись «NETWORK SERVICE» полноценно заработала — потребуется перезагрузка компьютера.
Создание подписки
Откройте «Event Viewer» и нажмите следующие кнопки для создания подписки:
- Переходим на страницу подписок;
- Открываем окно создания подписки;
- Выберете имя для подписки;
- Тип подписки, в этом случае, «Инициировано сборщиком»;
- Окно для добавления компьютеров.
В новом окне добавьте компьютер с которого хотите собирать события.

В следующем окне выберете типы журналов, событий и т.д., которые планируете забирать с удаленного компьютера. Рекомендую не выбирать большое количество журналов так как это нагрузит систему (при выборе больше 10 штук у вас появится аналогичное предупреждение).

В следующем окне выберете типы журналов, событий и т.д., которые планируете забирать с удаленного компьютера. Рекомендую не выбирать большое количество журналов так как это нагрузит систему (при выборе больше 10 штук у вас появится аналогичное предупреждение).
В последнем окне вы можете выбрать тип учетной записи, которую настраивали в предыдущих шагах и скорость получения событий. В моем случае — это учетная запись компьютера SR2. Если вы настраивали пользователя, то вам нужно будет ввести логин и пароль.
Настройки доставки событий следующие:
- Обычная (Normal) — раз в 15 минут или по достижению 5 событий;
- Уменьшенная пропускная способность (Minimize Bandwidth) — раз в 6 часов;
- Уменьшенная задержка (Minimize Latency) — раз в 30 секунд.

Настройка завершена. Проверьте, что у вас нет ошибок в окне с подписками.
Настройка завершена. Проверьте, что у вас нет ошибок в окне с подписками.
Расширенные настройки подписок через wecutil и wevutil
Wecutil (Windows Event Collector Utility) — программа для настройки подписок, wevtutil (Windows Event Utility) — управление событиями.
Выведем более подробную информацию о конкретной подписке.
wecutil gs "Название подписки"
Мы можем изменить время отправки событий, которое в предыдущем случае равнялось 30000 миллисекундам (30 секунд). Для этого изменим профиль и установим новое значение.
wecutil ss "НазваниеПодписки" /cm:Custom
wecutil ss "НазваниеПодписки" /dmlt:"Миллисекунды"
Мы можем изменить время отправки событий, которое в предыдущем случае равнялось 30000 миллисекундам (30 секунд). Для этого изменим профиль и установим новое значение.
wecutil ss "НазваниеПодписки" /cm:Custom
wecutil ss "НазваниеПодписки" /dmlt:"Миллисекунды"Через интерфейс WEC можно увидеть данные XML, которые относятся только к событиям, но через wecutil можно экспортировать подписку полностью.
wecutil gs "Название подписки" /f:xml > filename.xml

Этот XML файл можно так же импортировать в качестве новой подписки. Вы так же можете изменить XML файл тем самым минуя некоторых настроек, которые доступны только через ‘wecutil’.
wecutil cs C:filename.xml
Этот XML файл можно так же импортировать в качестве новой подписки. Вы так же можете изменить XML файл тем самым минуя некоторых настроек, которые доступны только через ‘wecutil’.
wecutil cs C:filename.xmlОбратите внимание, что вы должны будете удалить строку с версией и кодировкой XML документа и так же изменить название. Иначе вы будете получать ошибку «Code 0x80070057 The parameter is incorrect». Так же обращайте внимание на строку «ConfigurationMode», если она стоит в «Normal». Импортируемые подписки могут быть либо в режиме «Custom» или без блока «Delivery».
Подписку можно обновить, используя измененный XML документ, но это часто приводит к ошибкам.
wecutil ss TestSubs2 /c:C:filename.xmlНекоторые подписки имеют ограничения на количество событий отправляемых за раз. В документациях есть два упоминания, как это можно изменить. Первый — через ‘wecutil’ и параметр ‘DeliveryMaxItems’.
Wecutil ss “SubscriptionNameGoesHere” /dmi:1Второй вариант — через WinRM и параметр ‘MaxBatchItems’. Сам я его не использовал если что.
# просмотр
winrm get winrm/config
# меняем на 5
winrm set winrm/config @{MaxBatchItems="5"}Поиск ошибок
Хоть и функционал подписок достаточно простой, но его настройка может привести к десяткам ошибок. Усложняет задачу то, что многие ошибки никак не отображаются — события просто не пересылаются. Ниже только часть ошибок, которую я решил на собственном опыте.
Общая диагностика
Первым, что стоит проверить — это открыты ли порты и запущены ли сервисы. Winrm должен быть запущен на обоих компьютерах. Сервис Wecsvc — собирает события и он должен работать только на сервере.
Get-Service -Name 'Winrm','Wecsvc' | select name,status
Порт должен быть открыт на обоих компьютерах.
'SR1','SR2' | Test-NetConnection -Port 5985
Порт должен быть открыт на обоих компьютерах.
'SR1','SR2' | Test-NetConnection -Port 5985Вы так же можете попробовать подключиться через Winrm используя пользователя у которого есть такие права (у группы ‘Читатели журналов событий’ таких прав нет). Таким образом вы исключите проблему с Winrm.
$cred = Get-Credential
Invoke-Command -ScriptBlock {Get-Location} -Credential $cred -ComputerName 'SR1'
Если у вас не проходит подключение по Winrm, то может проблема в TrustedHost и NTLM подключении, если вы работаете вне домена. В Trusted Host добавляются компьютеры, которым разрешено подключение к текущему. В примере ниже команда, которая разрешает подключаться любым компьютерам.
Set-Item wsman:localhost/client/trustedhosts *Самым главным окном, которое может рассказать об ошибке, является окно состояния подписки.

Если у вас не проходит подключение по Winrm, то может проблема в TrustedHost и NTLM подключении, если вы работаете вне домена. В Trusted Host добавляются компьютеры, которым разрешено подключение к текущему. В примере ниже команда, которая разрешает подключаться любым компьютерам.
Set-Item wsman:localhost/client/trustedhosts *Самым главным окном, которое может рассказать об ошибке, является окно состояния подписки.
Примерно такой же результат можно увидеть, если посмотреть на подписку через консоль.
wecutil gr "НазваниеПодписки"
Кнопка «Повторить» так же может быть полезна, после изменения настроек.
Другие кандидаты на поиск ошибок — это журналы:
- Журналы Windows -> Система;
- По пути Application and Services Logs (Журналы приложений и служб) -> Microsoft -> Windows -> журналы EventCollector / Eventlog-Forwarding / Windows Remote Management.
Ошибок нет, но логи не приходят
Ошибки могут не появляться если вы создали подписку одновременно на несколько журналов. Вам нужно отметить только один журнал и посмотреть «Состояние выполнения». У вас либо появится ошибка, либо начнут приходить события.
Такая ошибка, как минимум, может произойти когда вы выбрали журнал «Безопасность» с каким-то другим журналом, но не дали права учетной записи «Wecsvc» на чтение данных по URL «http://+:5985/wsman/».
Ошибка 0x80338095 при проверке состояния подключения

Кнопка «Повторить» так же может быть полезна, после изменения настроек.
Другие кандидаты на поиск ошибок — это журналы:
- Журналы Windows -> Система;
- По пути Application and Services Logs (Журналы приложений и служб) -> Microsoft -> Windows -> журналы EventCollector / Eventlog-Forwarding / Windows Remote Management.
Ошибок нет, но логи не приходят
Ошибки могут не появляться если вы создали подписку одновременно на несколько журналов. Вам нужно отметить только один журнал и посмотреть «Состояние выполнения». У вас либо появится ошибка, либо начнут приходить события.
Такая ошибка, как минимум, может произойти когда вы выбрали журнал «Безопасность» с каким-то другим журналом, но не дали права учетной записи «Wecsvc» на чтение данных по URL «http://+:5985/wsman/».
Ошибка 0x80338095 при проверке состояния подключения
Исчезает либо установкой «Оптимизация обработки событий» с «Уменьшенная задержка» в «Обычная» либо даем пользователю «Wecsv» читать данные с URL Wsman с помощью следующей команды (объяснение команды было в статье выше).
# удаление существующей записи
netsh http delete urlacl url=http://+:5985/wsman/
# добавление новой
netsh http add urlacl url=http://+:5985/wsman/ sddl="D:(A;;GX;;;S-1-5-80-569256582-2953403351-2909559716-1301513147-412116970)(A;;GX;;;S-1-5-80-4059739203-877974739-1245631912-527174227-2996563517)"Изменение задержки может убрать ошибку, но логи могут не появляться.

Ошибка (0x5): Отказано в доступе

Ошибка (0x5): Отказано в доступе
Связано с тем, что учетная запись компьютера или пользователя, которую настраивали для подключения, не имеет прав для подключения к компьютеру. Изменяется пользователь в следующем окне.

Ошибка 0x80338126

Ошибка 0x80338126
В этом случае либо закрыт порт/протокол на фаерволе или он указан неверный. Часть команд, которые могут помочь в диагностике.
Посмотреть, что порт открыт, на обоих компьютерах, можно с помощью следующей команды:
Test-NetConnection -ComputerName "SR1" -Port 5985
Проверим, что сервисы запущены и URL по 5985 порту принимает подключение:
Get-Service 'Winrm','Wecsvc'
netsh http show urlacl url=http://+:5985/wsman/
Проверим, что сервисы запущены и URL по 5985 порту принимает подключение:
Get-Service 'Winrm','Wecsvc'
netsh http show urlacl url=http://+:5985/wsman/В некоторых случаях нужно убедиться, что WinRM принимает подключение с любых IP и вообще прослушивает 5985 порт на loopback (127.0.0.1) интерфейсе. С этим может быть связана так же ошибка с ID 10149.
winrm enumerate winrm/config/listener
Ну и самое главное, что верный порт указан в самой подписке:

Ну и самое главное, что верный порт указан в самой подписке:
Ошибка 0x138C и 5004
Если у вас добавлен пользователь «NETWORK SERVICE» и есть нужные права на канал WSMAN, то почитайте статью на сайте Microsoft (касается Windows Server 2008-2012 R2). Она основана на добавлении прав через реестр, но в моем случае, на 2019, были использованы решения описанные выше.
Работа с другими журналами приложений и служб
Журналы так же имеют свои права на чтение и запись. Некоторые приложения могут перезаписывать эти права тем самым убирая возможность чтения у служб Windows. Я лично с такой проблемой не сталкивался, но алгоритм проверки следующий…
На компьютере клиента зайдите в свойства журнала с которым у вас есть проблемы и скопируйте его полное название.

В следующей команде замените название журнала на ваше. Эта команда выведет конфигурацию журнала.
wevtutil gl /r:localhost "НазваниеЖурнала"Если посмотреть на пример выполненной команды на скриншоте ниже, то видно, что там используется SID группы «Читатели журнала событий» («S-1-5-32-573»).

В следующей команде замените название журнала на ваше. Эта команда выведет конфигурацию журнала.
wevtutil gl /r:localhost "НазваниеЖурнала"Если посмотреть на пример выполненной команды на скриншоте ниже, то видно, что там используется SID группы «Читатели журнала событий» («S-1-5-32-573»).
Если у вас этой записи нет, то вы можете добавить ее руками. Вам нужно будет скопировать старые разрешения и добавить их к новым SDDL. Значения, которые устанавливаются перед SID значат следующее:
- 0x01: Read;
- 0x02: Write;
- 0x04: Clear;
- A — allow.
В примере ниже нужно заменить старые права. SDDL соответствует группе читателей событий.
wevtutil set-log "НазваниеЖурнала" /ca:СтарыеПрава(A;;0x1;;;S-1-5-32-573)Пример с добавлением SDDL для примера.

Такие же изменения можно посмотреть и увидеть в реестре по пути «HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindowsCurrentVersionWINEVTChannelsНазвание журнала«.

Такие же изменения можно посмотреть и увидеть в реестре по пути «HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindowsCurrentVersionWINEVTChannelsНазвание журнала«.
Эти же права можно выдать через политики и они так же могут перезатирать существующие значения:
- Computer Configuration — Policies — Administrative Templates — Windows Components — Event Log Service;
- Конфигурация компьютера — Политики — Административные шаблоны — Компоненты Windows — Службы журнала событий.

…
Теги:
#windows
#events
#события
Время на прочтение
3 мин
Количество просмотров 39K
Не так давно, для успешного прохождения аудита на соответствие стандартам PCI DSS, потребовалось включить аудит событий Windows серверов и что самое главное — настроить отправку уведомлений о критичных событиях на E-mail. Для Linux серверов вопрос решается установкой и настройкой OSSEC (ну еще могут понадобиться syslog ws loganalyzer и auditd), для Windows Server 2012 R2 да еще и русской версии он не подошел (в последствии нам таки удалось его адекватно настроить, если будет интересно — смогу описать как). Так что решили искать другие способы…
Первым дело следует включить аудит всех необходимых операций (управление учетными записями и контроль целостности файлов) в доменной политике. И если с аудитом операций над объектами Active Directory все просто, то вот с аудитом файловых операций придется повозиться. Тут, как нельзя кстати, компания Netwrix (не сочтите за рекламу, — компания автор коммерческого софта для аудита) подготовила замечательную статью: «Настройка аудита файловых серверов: подробная инструкция и шпаргалка» (.pdf).
Но вернемся к нашим «костылям». После успешной активации аудита всех необходимых операций и обнаружения в журналах Windows интересующих нас событий, встал вопрос об их отправке на сервер мониторинга… Логично было бы воспользоваться встроенными инструментами («Attach Task To This Event» не самый информативный инструмент, зато «родной» для Windows), но тут всплывает первый любопытный и не приятный момент от Microsoft — «Send an email and Display a message are deprecated for from Windows Server 2012 and Windows 8».
Send an e-mail (deprecated)

…
Согласно рекомендациям от Microsoft, как замену встроенному «deprecated» функционалу решили использовать скрипты PowerShell для фильтрации журналов и отправки по E-mail, благо есть подробные инструкции:
«Аудит Active Directory средствами Powershell с оповещением об изменениях».
«Аудит удаления и доступа к файлам и запись событий в лог-файл средствами Powershell»
Но тут возникла сложность другого характера: приведенные выше скрипты отсылали на E-mail только заголовки (темы) событий, тело письма было пустым  При всем при этом — если скрипт PowerShell запустить в PowerShell ISE «as Administrator», то приходит полное сообщение, как и было задумано!
При всем при этом — если скрипт PowerShell запустить в PowerShell ISE «as Administrator», то приходит полное сообщение, как и было задумано!
пример скрипта отправки уведомления о событии ‘Заблокирован аккаунт’ — Event ID 4725:
$time = (get-date) - (new-timespan -min 60)
$Subject = “Заблокирован аккаунт"
$Theme = “Только что был заблокирован аккаунт”
$Server = “smtp.server.local”
$From = “AD@domain.local”
$To = “support@domain.local”
$encoding = [System.Text.Encoding]::UTF8
#Выбирается последнее произошедшее событие с таким ID.
$TimeSpan = new-TimeSpan -sec 1
foreach($event in $events)
{
$PrevEvent = $Event.Запись
$PrevEvent = $PrevEvent - 1
$TimeEvent = $Event.TimeCreated
$TimeEventEnd = $TimeEvent+$TimeSpan
$TimeEventStart = $TimeEvent- (new-timespan -sec 1)
$Body=Get-WinEvent -maxevents 1 -FilterHashtable @{LogName=”Security”;ID=4725;StartTime=$TimeEventStart;} | Select TimeCreated,@{n=”Account Name”;e={([xml]$_.ToXml()).Event.EventData.Data | ? {$_.Name -eq “TargetUserName”} |%{$_.’#text’}}},@{n=”Computer”;e={([xml]$_.ToXml()).Event.EventData.Data | ? {$_.Name -eq “TargetDomainName”}| %{$_.’#text’}}}
$body = $body -replace "@{" -replace "}" -replace "=", ": " -replace ";","`n" -replace "TimeCreated","Время события" -replace "^","`n"
$BodyM = $Body
}
Send-MailMessage -From $From -To $To -SmtpServer $server -Body “$BodyM `n$Theme” -Subject $Subject -Encoding $encoding
В общем, если у вас есть реально рабочие скрипты для такого случая — милости прошу в комментарии.
Мы же перешли к другому способу (вдохновила вот эта статья: «Мониторинг и оповещение о событиях в журналах Windows: триггеры событий» и выручила эта утилита: sendEmail):
- Добавляем в Task Scheduler задание по интересующему нас событию (прямо из журнала «Security» -> «Attach Task To This Event…«

- В Actions указываем запуск скрипта, в котором с помощью утилиты wevtutil делаем выборку из журнала и сохраняем результат в файл.
пример скрипта — выборка событий с Event ID 4726
del c:Auditquery_ID4726.txt wevtutil qe Security /q:"*[System[(EventID=4726)]]" /f:text /rd:true /c:1 > c:Auditquery_ID4726.txt - Вторым действием, с помощью утилиты sendEmail отправляем сохраненный файл по назначению:
пример аргументов для команды запуска sendEmail:
-f audit_AD@domain.local -s smtp.domain.local:25 -t support@domain.local -m "AD User Account Management - Event ID 426 - Account was Deleted" -a C:Auditquery_ID4726.txt


В результате должны получать что-то типа этого:

P.S. Спасибо всем авторам источников, указанных ранее!