
Следует
отметить, что истинным показателем
степени линейной связи переменных
является теоретический
коэффициент корреляции,
который рассчитывается на основании
данных всей генеральной совокупности
(т.е. всех возможных значений показателей):
![]() ,
,
где
![]()
— теоретический
показатель ковариции,
который вычисляется как математическое
ожидание произведений отклонений СВ
![]() и
и![]() от их математических ожиданий.
от их математических ожиданий.
Как
правило, теоретический коэффициент
корреляции мы рассчитать не можем.
Однако из того, что выборочный коэффициент
не равен нулю
![]() не следует, что теоретический коэффициент
не следует, что теоретический коэффициент
также![]() (т.е. показатели могут быть линейно
(т.е. показатели могут быть линейно
независимыми). Т.о. по данным случайной
выборки нельзя утверждать, что связь
между показателями существует.
Выборочный
коэффициент корреляции является оценкой
теоретического коэффициента, т.к. он
рассчитывается лишь для части значений
переменных.
Всегда
существует ошибка
коэффициента корреляции.
Эта ошибка — расхождение между коэффициентом
корреляции выборки объемом
![]() и коэффициентом корреляции для генеральной
и коэффициентом корреляции для генеральной
совокупности
определяется формулами:
![]() при
при
![]() ;
;
и![]() при
при![]() .
.
Проверка
значимости коэффициента линейной
корреляции означает проверку того,
насколько мы можем доверять выборочным
данным.
С
этой целью проверяется нулевая гипотеза
![]() о том, что значение коэффициента
о том, что значение коэффициента
корреляции для генеральной совокупности
равно нулю, т.е.в
генеральной совокупности отсутствует
корреляция.
Альтернативной является гипотеза
![]() .
.
Для
проверки этой гипотезы рассчитывается
![]() —
—
статистика (![]() -критерий)
-критерий)
Стьюдента:
![]() .
.
Которая
имеет распределение Стьюдента с
![]() степенями свободы1.
степенями свободы1.
По
таблицам распределения Стьюдента
определяется критическое значение
![]() .
.
Если
рассчитанное значение критерия
![]() ,
,
то нуль-гипотеза отвергается, то есть
вычисленный коэффициент корреляции
значимо отличается от нуля с вероятностью![]() .
.
Если
же
![]() ,
,
тогда нулевая гипотеза не может быть
отвергнута. В этом случае не исключается,
что истинное значение коэффициента
корреляции равно нулю, т.е. связь
показателей можно считать статистически
незначимой.
Пример
1. В таблице
приведены данные за 8 лет о совокупном
доходе
![]() и расходах на конечное потребление
и расходах на конечное потребление![]() .
.
|
|
10 |
12 |
11 |
12 |
14 |
15 |
17 |
20 |
|
|
7 |
8 |
8 |
10 |
11 |
12 |
14 |
16 |
Изучить
и измерить тесноту взаимосвязи между
заданными показателями.
Тема 4. Парная линейная регрессия. Метод наименьших квадратов
Коэффициент
корреляции указывает на степень тесноты
взаимосвязи между двумя признаками, но
он не дает ответа на вопрос, как изменение
одного признака на одну единицу его
размерности влияет на изменение другого
признака. Для того чтобы ответить на
этот вопрос, пользуются методами
регрессионного анализа.
Регрессионный
анализ устанавливает
форму
зависимости между случайной величиной
![]() и значениями переменной величины
и значениями переменной величины![]() ,
,
причем, значения![]() считаются точно заданными.
считаются точно заданными.
Уравнение
регрессии
– это формула статистической связи
между переменными.
Если
эта формула линейна, то речь идет о
линейной
регрессии.
Формула статистической связи двух
переменных называется парной
регрессией
(нескольких переменных – множественной).
Выбор
формулы зависимости называется
спецификацией
уравнения регрессии. Оценка значений
параметров выбранной формулы называется
параметризацией.
Как же оценить
значения параметров и проверить
надёжность сделанных оценок?
Рассмотрим рисунок

-
На
графике (а) взаимосвязь х
и у
близка к линейной, прямая линия 1 здесь
близка к точкам наблюдений и последние
отклоняются от неё лишь в результате
сравнительно небольших случайных
воздействий. -
На
графике (б) реальная взаимосвязь величин
х
и у
описывается нелинейной функцией 2, и
какую бы мы ни провели прямую линию
(например, 1), отклонения точек от неё
будут неслучайными. -
На
графике (в) взаимосвязь между переменными
х
и у
отсутствует, и результаты параметризации
любой формулы зависимости будут
неудачными.
Начальным
пунктом эконометрического анализа
зависимостей обычно является оценка
линейной зависимости переменных. Всегда
можно попытаться провести такую прямую
линию, которая будет «ближайшей» к
точкам наблюдений по их совокупности
(например, на рисунке (в) лучшей будет
прямая 1, чем прямая 2).
Теоретическое
уравнение парной линейной регрессии
имеет вид:
![]() ,
,
где
![]() называютсятеоретическими
называютсятеоретическими
параметрами
(теоретическими
коэффициентами)
регрессии;
![]() —случайным
—случайным
отклонением (случайной
ошибкой).
В общем виде
теоретическую модель будем представлять
в виде:
![]() .
.
Для
определения значений теоретических
коэффициентов регрессии необходимо
знать все значения переменных Х
и Y,
т.е. всю генеральную совокупность, что
практически невозможно.
Задача
состоит в следующем: по имеющимся данным
наблюдений
![]() ,
,![]() необходимо оценить значения параметров
необходимо оценить значения параметров![]() .
.
Пусть
а
– оценка
параметра
![]() ,b
,b
– оценка
параметра
![]() .
.
Тогда
оценённое уравнение регрессии имеет
вид: ![]() ,
,
где
![]() теоретические
теоретические
значения зависимой переменнойy,
![]() — наблюдаемые значения ошибок
— наблюдаемые значения ошибок![]() .
.
Это уравнение называетсяэмпирическим
уравнением регрессии.
Будем его записывать в виде ![]() .
.
В
основе оценки параметров линейной
регрессии лежит Метод
Наименьших Квадратов
(МНК)
– это метод оценивания параметров
линейной регрессии, минимизирующий
сумму квадратов отклонений наблюдений
зависимой переменной от искомой линейной
функции.
![]() .
.
Функция
Q
является квадратичной функцией двух
параметров a
и b.
Т.к. она непрерывна, выпукла и ограничена
снизу (![]() ),
),
поэтому она достигает минимума.
Необходимым условием существования
минимума является равенство нулю её
частных производных поa
и b:

 .
.
Разделив
оба уравнения системы на n,
получим:

 или
или

Иначе
можно записать:

![]() и
и
![]()
средние квадратические отклонения
значений тех же признаков.
Т.о.
линия регрессии проходит через точку
со средними значениями х
и у
![]() ,
,
акоэффициент
регрессии
b
пропорционален
показателю ковариации и коэффициенту
линейной корреляции.
Если
кроме регрессии Y
на X
для тех же эмпирических значений найдено
уравнение регрессии X
на Y
(![]() ,
,
где ),
),
то произведение коэффициентов![]() :
:
![]() .
.
К оэффициент
оэффициент
регрессии
![]()
это величина, показывающая, на сколько
единиц размерности изменится величина
![]() при изменении величины
при изменении величины![]() на одну единицу ее размерности. Аналогично
на одну единицу ее размерности. Аналогично
определяется коэффициент![]() .
.
Как
и коэффициент корреляции, коэффициент
регрессии может принимать и положительные
и отрицательные значения. Например,
если коэффициент
![]() имеет знак «»,
имеет знак «»,
то это означает, что при увеличении
значения признака
![]() на единицу его размерности значение
на единицу его размерности значение
признака![]() уменьшается на величину, равную
уменьшается на величину, равную![]() .
.
Уравнения
линейной регрессии являются уравнениями
прямых линий в плоскости
![]() ,
,
проходящих внутри соответствующего
корреляционного поля. Такие линии
называютсялиниями
регрессии.
Для
того, чтобы полученные МНК оценки
обладали желательными свойствами,
сделаем следующие предпосылки
об отклонениях
![]() :
:
1)
величина
![]() является случайной переменной;
является случайной переменной;
2)
математическое ожидание
![]() равно нулю:
равно нулю:![]() ;
;
3)
значения
![]() независимы между собой. Откуда вытекает,
независимы между собой. Откуда вытекает,
в частности, что
4)
дисперсия
![]() постоянна:
постоянна:![]() ;
;
5)
ошибки
![]() подчиняются нормальному распределению
подчиняются нормальному распределению![]() ~
~![]() (это
(это
условие не является обязательным, но
оно необходимо для проверки статистической
значимости найденных оценок и определения
для них доверительных интервалов).
Если
условия 1)-4) выполняются, то оценки,
сделанные с помощью МНК, обладают
следующими свойствами:
1.
Оценки являются несмещёнными (т.е.
математическое ожидание каждого
параметра равно его истинному значению
![]() ).
).
2.
Оценки состоятельны (дисперсия оценок
параметров при возрастании числа
наблюдений стремится к нулю:
![]() ).
).
Иначе говоря, надёжность оценки при
возрастании выборки растёт. Еслиn
велико, то почти наверняка a
близко к
![]() ,
,
аb
близко к
![]() .
.
3.
Оценки эффективны, они имеют наименьшую
дисперсию по сравнению с любыми другими
оценками данного параметра, линейными
относительно величин
![]() .
.
Пример
1.
По данным примера
1 оценить параметры уравнения линейной
регрессии.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
53.1. Корреляционный анализ
Корреляционный анализ является одним из методов статистического анализа взаимозависимости нескольких признаков.
Основная задача корреляционного анализа состоит в оценке корреляционной матрицы генеральной совокупности по выборке и определении на основе этой матрицы частных и множественных коэффициентов корреляции и детерминации.
Парный и частный коэффициенты корреляции характеризуют тесноту линейной зависимости между двумя переменными соответственно на фоне действия и при исключении влияния всех остальных показателей, входящих в модель. Они изменяются в пределах от -1 до +1, причем чем ближе коэффициент корреляции к 1, тем сильнее зависимость между переменными. Если коэффициент корреляции больше нуля, то связь положительная, а если меньше нуля — отрицательная.
Множественный коэффициент корреляции характеризует тесноту, линейной связи между одной переменной (результативной) и остальными, входящими в модель; он изменяется в пределах от 0 до 1.
Квадрат множественного коэффициента корреляции называется множественным коэффициентом детерминации. Он характеризует долю дисперсии одной переменной (результативной), обусловленной влиянием всех остальных переменных (аргументов), входящих в модель.
Исходной для анализа является матрица

размерности п х k, i-я строка которой характеризует i-е наблюдение (объект) по всем k показателям (j = 1, 2, …, k).
В корреляционном анализе матрицу Х рассматривают как выборку объема п из k-мерной генеральной совокупности, подчиняющейся k-мерному нормальному закону распределения.
По выборке определяют оценки параметров генеральной совокупности, а именно: вектор средних 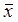 , вектор средних квадратических отклонений s и корреляционную матрицу R порядка k:
, вектор средних квадратических отклонений s и корреляционную матрицу R порядка k:

где
 (53.1)
(53.1)
 (53.2)
(53.2)
xij — значение i-го наблюдения j-го фактора,
ril — выборочный парный коэффициент корреляции, характеризующий тесноту линейной связи между показателями xj и xl. При этом rjl является оценкой генерального парного коэффициента корреляции.
Матрица R является симметричной (rjl = rlj) и положительно определенной.
Кроме того, находятся точечные оценки частных и множественных коэффициентов корреляции любого порядка. Например, частный коэффициент корреляции (k — 2)-го порядка между переменными х1 и х2 равен
 (53.3)
(53.3)
где Rjl — алгебраическое дополнение элемента rjl корреляционной матрицы R. При этом Rjl = (-l)j+l Mjl, где Mjl — минор, т.е. определитель матрицы, получаемой из матрицы R путем вычерчивания j-й строки и l-го столбца.
Множественный коэффициент корреляции (k — 1)-го порядка результативного признака x1 определяется по формуле
 (53.4)
(53.4)
где | R | — определитель матрицы R.
Значимость частных и парных коэффициентов корреляции, т.е. гипотеза H0: ρ = 0, проверяется по t-критерию Стьюдента. Наблюдаемое значение критерия находится по формуле
 (53.5)
(53.5)
где r — соответственно оценка частного или парного коэффициента корреляции ρ; l — порядок частного коэффициента корреляции, т.е. число фиксируемых факторов (для парного коэффициента корреляции l=0).
Напомним, что проверяемый коэффициент корреляции считается значимым, т.е. гипотеза H0: ρ = 0 отвергается с вероятностью ошибки α, если tнабл по модулю будет больше, чем значение tкр, определяемое по таблицам t-распределения для заданного α и υ = n – l — 2.
Значимость коэффициентов корреляции можно также проверить с помощью таблиц Фишера — Иейтса.
При определении с надежностью у доверительного интервала для значимого парного или частного коэффициента корреляции р используют Z-преобразование Фишера и предварительно устанавливают интервальную оценку для Z:
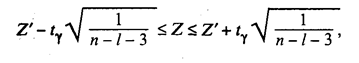 (53.6)
(53.6)
где tγ вычисляют по таблице значений интегральной функции Лапласа из условия

значение Z’ определяют по таблице Z-преобразования по найденному значению r. Функция Z’ — нечетная, т.е.

Обратный переход от Z к ρ осуществляют также по таблице Z-преобразования, после использования которой получают интервальную оценку для ρ с надежностью γ:

Таким образом, с вероятностью γ гарантируется, что генеральный коэффициент корреляции ρ будет находиться в интервале (rmin, rmax).
Значимость множественного коэффициента корреляции (или его квадрата — коэффициента детерминации) проверяется по F-критерию. Например, для множественного коэффициента корреляции проверка значимости сводится к проверке гипотезы, что генеральный множественный коэффициент корреляции равен нулю, т.е. H0 : ρ1/2,…,k = 0, а наблюдаемое значение статистики находится по формуле
 (53.7)
(53.7)
Множественный коэффициент корреляции считается значимым, т.е. имеет место линейная статистическая зависимость между х1 и остальными факторами х2, …, хk, если Fнабл > Fкр, где Fкр определяется по таблице F-распределения для заданных α, υ1 = k — 1, υ2 = n — k.
53.2. Регрессионный анализ
Регрессионный анализ — это статистический метод исследования зависимости случайной величины у от переменных (аргументов) хj (j = 1, 2,…, k), рассматриваемых в регрессионном анализе как неслучайные величины независимо от истинного закона распределения xj.
Обычно предполагается, что случайная величина у имеет нормальный закон распределения с условным математическим ожиданием ![]() = φ(x1, …, хk), являющимся функцией от аргументов хj и с постоянной, не зависящей от аргументов дисперсией σ2.
= φ(x1, …, хk), являющимся функцией от аргументов хj и с постоянной, не зависящей от аргументов дисперсией σ2.
Для проведения регрессионного анализа из (k + 1)-мерной генеральной совокупности (у, x1, х2, …, хj, …, хk) берется выборка объемом n, и каждое i-е наблюдение (объект) характеризуется значениями переменных (уi, xi1, хi2, …, хij, …, xik), где хij — значение j-й переменной для i-го наблюдения (i = 1, 2,…, n), уi — значение результативного признака для i-го наблюдения.
Наиболее часто используемая множественная линейная модель регрессионного анализа имеет вид
 (53.8)
(53.8)
где βj — параметры регрессионной модели;
εj — случайные ошибки наблюдения, не зависимые друг от друга, имеют нулевую среднюю и дисперсию σ2.
Отметим, что модель (53.8) справедлива для всех i = 1,2, …, n, линейна относительно неизвестных параметров β0, β1,…, βj, …, βk и аргументов.
Как следует из (53.8), коэффициент регрессии Bj показывает, на какую величину в среднем изменится результативный признак у, если переменную хj увеличить на единицу измерения, т.е. является нормативным коэффициентом.
В матричной форме регрессионная модель имеет вид
 (53.9)
(53.9)
где Y — случайный вектор-столбец размерности п х 1 наблюдаемых значений результативного признака (у1, у2,…. уn); Х— матрица размерности п х (k + 1) наблюдаемых значений аргументов, элемент матрицы х,, рассматривается как неслучайная величина (i = 1, 2, …, n; j=0,1, …, k; x0i, = 1); β — вектор-столбец размерности (k + 1) х 1 неизвестных, подлежащих оценке параметров модели (коэффициентов регрессии); ε — случайный вектор-столбец размерности п х 1 ошибок наблюдений (остатков). Компоненты вектора εi не зависимы друг от друга, имеют нормальный закон распределения с нулевым математическим ожиданием (Mεi = 0) и неизвестной постоянной σ2 (Dεi = σ2).
На практике рекомендуется, чтобы значение п превышало k не менее чем в три раза.
В модели (53.9)

В первом столбце матрицы Х указываются единицы при наличии свободного члена в модели (53.8). Здесь предполагается, что существует переменная x0, которая во всех наблюдениях принимает значения, равные единице.
Основная задача регрессионного анализа заключается в нахождении по выборке объемом п оценки неизвестных коэффициентов регрессии β0, β1, …, βk модели (53.8) или вектора β в (53.9).
Так как в регрессионном анализе хj рассматриваются как неслучайные величины, a Mεi = 0, то согласно (53.8) уравнение регрессии имеет вид
 (53.10)
(53.10)
для всех i = 1, 2, …, п, или в матричной форме:
 (53.11)
(53.11)
где  — вектор-столбец с элементами
— вектор-столбец с элементами  1…, i,…, n.
1…, i,…, n.
Для оценки вектора-столбца β наиболее часто используют метод наименьших квадратов, согласно которому в качестве оценки принимают вектор-столбец b, который минимизирует сумму квадратов отклонений наблюдаемых значений уi от модельных значений i, т.е. квадратичную форму:

где символом «Т» обозначена транспонированная матрица.
Наблюдаемые и модельные значения результативного признака у показаны на рис. 53.1.

Рис. 53.1. Наблюдаемые и модельные значения результативного признака у
Дифференцируя, с учетом (53.11) и (53.10), квадратичную форму Q по β0, β1, …, βk и приравнивая частные производные к нулю, получим систему нормальных уравнений

решая которую получим вектор-столбец оценок b, где b = (b0, b1, …, bk)T. Согласно методу наименьших квадратов, вектор-столбец оценок коэффициентов регрессии получается по формуле
 (53.12)
(53.12)

ХT — транспонированная матрица X;
(ХTХ)-1 — матрица, обратная матрице ХTХ.
Зная вектор-столбец b оценок коэффициентов регрессии, найдем оценку  уравнения регрессии
уравнения регрессии
 (53.13)
(53.13)
или в матричном виде:


Оценка ковариационной матрицы вектора коэффициентов регрессии b определяется выражением
 (53.14)
(53.14)
где
 (53.15)
(53.15)
Учитывая, что на главной диагонали ковариационной матрицы находятся дисперсии коэффициентов регрессии, имеем
 (53.16)
(53.16)
Значимость уравнения регрессии, т.е. гипотеза Н0: β = 0 (β0,= β1 = βk = 0), проверяется по F-критерию, наблюдаемое значение которого определяется по формуле
 (53.17)
(53.17)
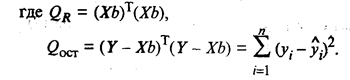
По таблице F-распределения для заданных α, v 1 = k + l,v2 = n – k — l находят Fкр.
Гипотеза H0 отклоняется с вероятностью α, если Fнабл > Fкр. Из этого следует, что уравнение является значимым, т.е. хотя бы один из коэффициентов регрессии отличен от нуля.
Для проверки значимости отдельных коэффициентов регрессии, т.е. гипотезы Н0: βj = 0, где j = 1, 2, …, k, используют t-критерий и вычисляют tнабл(bj) = bj /  bj. По таблице t-распределения для заданного α и v = п — k — 1 находят tкр.
bj. По таблице t-распределения для заданного α и v = п — k — 1 находят tкр.
Гипотеза H0 отвергается с вероятностью α, если tнабл > tкр. Из этого следует, что соответствующий коэффициент регрессии βj значим, т.е. βj ≠ 0. В противном случае коэффициент регрессии незначим и соответствующая переменная в модель не включается. Тогда реализуется алгоритм пошагового регрессионного анализа, состоящий в том, что исключается одна из незначительных переменных, которой соответствует минимальное по абсолютной величине значение tнабл. После этого вновь проводят регрессионный анализ с числом факторов, уменьшенным на единицу. Алгоритм заканчивается получением уравнения регрессии со значимыми коэффициентами.
Существуют и другие алгоритмы пошагового регрессионного анализа, например с последовательным включением факторов.
Наряду с точечными оценками bj генеральных коэффициентов регрессии βj регрессионный анализ позволяет получать и интервальные оценки последних с доверительной вероятностью γ.
Интервальная оценка с доверительной вероятностью γ для параметра βj имеет вид
 (53.19)
(53.19)
где tα находят по таблице t-распределения при вероятности α = 1 — γ и числе степеней свободы v = п — k — 1.
Интервальная оценка для уравнения регрессии в точке, определяемой вектором-столбцом начальных условий X0 = (1, x , x
, x ,,…, x
,,…, x )T записывается в виде
)T записывается в виде
 (53.20)
(53.20)
Интервал предсказания n+1 с доверительной вероятностью у определяется как
 (53.21)
(53.21)
где tα определяется по таблице t-распределения при α = 1 — γ и числе степеней свободы v = п — k — 1.
По мере удаления вектора начальных условий х0 от вектора средних  ширина доверительного интервала при заданном значении γ будет увеличиваться (рис. 53.2), где = (1,
ширина доверительного интервала при заданном значении γ будет увеличиваться (рис. 53.2), где = (1,  ).
).

Рис. 53.2. Точечная  и интервальная
и интервальная  оценки уравнения регрессии
оценки уравнения регрессии  .
.
Мультиколлинеарность
Одним из основных препятствий эффективного применения множественного регрессионного анализа является мультиколлинеарность. Она связана с линейной зависимостью между аргументами х1, х2, …, хk. В результате мультиколлинеарности матрица парных коэффициентов корреляции и матрица (XTX) становятся слабообусловленными, т.е. их определители близки к нулю.
Это приводит к неустойчивости оценок коэффициентов регрессии (53.12), завышению дисперсии s , оценок этих коэффициентов (53.14), так как в их выражения входит обратная матрица (XTX)-1, получение которой связано с делением на определитель матрицы (ХTХ). Отсюда следуют заниженные значения t(bj). Кроме того, мультиколлинеарность приводит к завышению значения множественного коэффициента корреляции.
, оценок этих коэффициентов (53.14), так как в их выражения входит обратная матрица (XTX)-1, получение которой связано с делением на определитель матрицы (ХTХ). Отсюда следуют заниженные значения t(bj). Кроме того, мультиколлинеарность приводит к завышению значения множественного коэффициента корреляции.
На практике о наличии мультиколлинеарности обычно судят по матрице парных коэффициентов корреляции. Если один из элементов матрицы R больше 0,8, т.е. | rjl | > 0,8, то считают, что имеет место мультиколлинеарность, и в уравнение регрессии следует включать один из показателей — хj или xl.
Чтобы избавиться от этого негативного явления, обычно используют алгоритм пошагового регрессионного анализа или строят уравнение регрессии на главных компонентах.
Пример. Построение регрессионного уравнения
Согласно данным двадцати (п = 20) сельскохозяйственных районов, требуется построить регрессионную модель урожайности на основе следующих показателей:
у — урожайность зерновых культур (ц/га);
x1 — число колесных тракторов (приведенной мощности) на 100 га;
х2 — число зерноуборочных комбайнов на 100 га;
х3 — число орудий поверхностной обработки почвы на 100 га;
x4 — количество удобрений, расходуемых на гектар;
х5 — количество химических средств оздоровления растений, расходуемых на гектар.
Исходные данные для анализа приведены в табл. 53.1.
Таблица 53.1
Исходные данные для анализа

Решение. С целью предварительного анализа взаимосвязи показателей построена матрица R — таблица парных коэффициентов корреляции.

Анализ матрицы парных коэффициентов корреляции показывает, что результативный признак наиболее тесно связан с показателем х4 — количеством удобрений, расходуемых на гектар (ryx4 = 0,58).
В то же время связь между аргументами достаточно тесная. Так, существует практически функциональная связь между числом колесных тракторов (x1) и числом орудий поверхностной обработки почвы x3(rx1x3) = 0,98.
О наличии мультиколлинеарности свидетельствуют также коэффициенты корреляции rx1x2 = 0,85 и rx3x2 = 0,88.
Чтобы продемонстрировать отрицательное влияние мультиколлинеарности, рассмотрим рассчитанное на ЭВМ регрессионное уравнение урожайности, включив в него все исходные показатели:
= 3,515 – 0,006x1 + 15,542x2 + 110x3 + 4,475х4 — 2,932x5. (53.22)
(-0,01) (0,72) (0,13) (2,90) (-0,95)
В скобках указаны tнабл (βj) = tj — расчетные значения t-критерия для проверки гипотезы о значимости коэффициента регрессии Н0: βj = 0, j = 1, 2, 3, 4, 5. Критическое значение tкр = 1,76 найдено по таблице t-распределения при уровне значимости α = 0,1 и числе степеней свободы v = 14. Из уравнения следует, что статистически значимым является коэффициент регрессии только при х4, так как |t4| = 2,90 > tкр = 1,76. Не поддаются экономической интерпретации отрицательные значения коэффициентов регрессии при х1 и x5, из чего следует, что повышение насыщенности сельского хозяйства колесными тракторами (х1) и средствами оздоровления растений (x5) отрицательно сказывается на урожайности. Таким образом, полученное уравнение регрессии неприемлемо.
После реализации алгоритма пошагового регрессионного анализа с исключением переменных и учетом того, что в уравнение должна войти только одна из трех тесно связанных переменных (x1, х2 или x3), получаем окончательное уравнение регрессии
= 7,342 + 0,345x1 + 3,294x4. (53.23)
(11,12) (2,09) (3,02)
Уравнение значимо при α = 0,05, так как Fнабл = 266 > Fкр = 3,20, найденного по таблице F-распределения при α = 0,05, v1 = 3 и v2 = 17. Значимы и коэффициенты регрессии β1 и β4, так как |tj| > tкр = 2,11 (при α = 0,05, v = 17). Коэффициент регрессии β1 следует признать значимым (β1 ≠ 0) из экономических соображений; при этом t1 = 2,09 лишь незначительно меньше tкр = 2,11. В случае если α = 0,1, tкр = 1,74 и коэффициент регрессии β1 статистически значим.
Из уравнения регрессии следует, что увеличение на единицу числа тракторов на 100 га пашни приводит к росту урожайности зерновых в среднем на 0,345 ц/га (b1 = 0,345).
Коэффициенты эластичности Э1 = 0,068 и Э4 = 0,161 (Эj =  ) показывают, что при увеличении показателей x1 и х4 на 1% урожайность зерновых повышается соответственно на 0,068% и 0,161%.
) показывают, что при увеличении показателей x1 и х4 на 1% урожайность зерновых повышается соответственно на 0,068% и 0,161%.
Множественный коэффициент детерминации r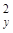 = 0,469 свидетельствует о том, что только 46,9% вариации урожайности объясняется вошедними в модель показателями (x1 и x4), т.е. насыщенностью растениеводства тракторами и удобрениями. Остальная часть вариации обусловлена действием неучтенных факторов (х2, x3, х5, погодными условиями и др.). Средняя относительная ошибка аппроксимации
= 0,469 свидетельствует о том, что только 46,9% вариации урожайности объясняется вошедними в модель показателями (x1 и x4), т.е. насыщенностью растениеводства тракторами и удобрениями. Остальная часть вариации обусловлена действием неучтенных факторов (х2, x3, х5, погодными условиями и др.). Средняя относительная ошибка аппроксимации 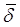 = 10,5% свидетельствует об адекватности модели, так же как и величина остаточной дисперсии s2 = 1,97.
= 10,5% свидетельствует об адекватности модели, так же как и величина остаточной дисперсии s2 = 1,97.
53.3. Компонентный анализ
Компонентный анализ предназначен для преобразования системы k исходных признаков в систему k новых показателей (главных компонент). Главные компоненты не коррелированы между собой и упорядочены по величине их дисперсий, причем первая главная компонента имеет наибольшую дисперсию, а последняя, k-я — наименьшую. При этом выявляются неявные, непосредственно не измеряемые, но объективно существующие закономерности, обусловленные действием как внутренних, так и внешних причин.
Компонентный анализ является одним из основных методов факторного анализа. В задачах снижения размерности и классификации обычно используются т первых компонент (т << k).
При наличии результативного признака у может быть построено уравнение регрессии на главных компонентах.
На основании матрицы исходных данных

размерности п х k, где хij.— значение j-го показателя у i-го наблюдения (i = 1, 2, …, n; j = 1, 2, …. k), вычисляют средние значения показателей  а также s1, …, sk и матрицу нормированных значений
а также s1, …, sk и матрицу нормированных значений

с элементами

Рассчитывается матрица парных коэффициентов корреляции:
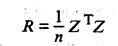 (53.24)
(53.24)
с элементами
 (53.25)
(53.25)
где j, l= 1, 2, …. k.
На главной диагонали матрицы R, т.е. при j = l, расположены элементы

Модель компонентного анализа имеет вид
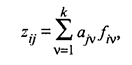 (53.26)
(53.26)
где aiv — «вес», т.е. факторная нагрузка v-й главной компоненты на j-ю переменную;
fiv — значение v-й главной компоненты для i-го наблюдения (объекта), где v = 1, 2, …,k.
В матричной форме модель (53.26) имеет вид
 (53.27)
(53.27)

fiv — значение v-й главной компоненты для i-го наблюдения (объекта);
aiv — значение факторной нагрузки v-й главной компоненты на j-ю переменную.
Матрица F описывает п наблюдений в пространстве k главных компонент. При этом элементы матрицы F нормированы, т.е. fv =  , a главные компоненты не коррелированы между собой. Из этого следует, что
, a главные компоненты не коррелированы между собой. Из этого следует, что
 (53.28)
(53.28)

Выражение (53.28) может быть представлено в виде
 (53.29)
(53.29)
С целью интерпретации элементов матрицы А рассмотрим выражение для парного коэффициента корреляции между переменной zj и, например, f1-й главной компонентой. Так как zо и f1 нормированы, будем иметь с учетом (53.26):

Принимая во внимание (53.29), окончательно получим

Рассуждая аналогично, можно записать в общем виде
 (53.30)
(53.30)
для всех j = 1, 2, .,., k и v = 1, 2, …. k.
Таким образом, элемент ajv матрицы факторных нагрузок А характеризует тесноту линейной связи между исходной переменной zj и главной компонентой fv, т.е. –1 ≤ ajv ≤ +1.
Рассмотрим теперь выражение для дисперсии нормированной переменной zj. С учетом (53.26) будем иметь

где v, v’= 1, 2, …, k.
Учитывая (53.29), окончательно получим
 (53.31)
(53.31)
По условию, переменные zj нормированы и s = 1. Таким образом, дисперсия переменной zj, согласно (53.31), представлена своими составляющими, определяющими долю вклада в нее всех k главных компонент.
= 1. Таким образом, дисперсия переменной zj, согласно (53.31), представлена своими составляющими, определяющими долю вклада в нее всех k главных компонент.
Полный вклад v-й главной компоненты в дисперсию всех k исходных признаков вычисляется по формуле
 (53.32)
(53.32)
Одно из основополагающих условий метода главных компонент связано с представлением корреляционной матрицы R через матрицу факторных нагрузок А. Подставив для этого (53.27) в (53.24), будем иметь

Учитывая (53.28), окончательно получим
 (53.33)
(53.33)
Перейдем теперь непосредственно к отысканию собственных значений и собственных векторов корреляционной матрицы R.
Из линейной алгебры известно, что для любой симметричной матрицы R всегда существует такая ортогональная матрица U, что выполняется условие
 (53.34)
(53.34)

Так как матрица R положительно определена, т.е. ее главные миноры положительны, то все собственные значения λv > 0 для любых v =1, 2, …, k.
В компонентном анализе элементы матрицы Λ ранжированы: λ1 ≥ λ2 ≥ … ≥ λv … ≥ λk ≥ 0. Как будет показано ниже, собственное значение λv характеризует вклад v-й главной компоненты в суммарную дисперсию исходного признакового пространства.
Таким образом, первая главная компонента вносит наибольший вклад в суммарную дисперсию, а последняя, k-я, — наименьший.
В ортогональной матрице U собственных векторов v-й столбец является собственным вектором, соответствующим λv -му значению.
Собственные значения λ1 ≥ … ≥ λv…. ≥ λk находятся как корни характеристического уравнения
 (53.35)
(53.35)
Собственный вектор Vv, соответствующий собственному значению λv корреляционной матрицы R, определяется как отличное от нуля решение уравнения, которое следует из (53.34):
 (53.36)
(53.36)
Нормированный собственный вектор Uv равен

Из условия ортогональности матрицы U следует, что U-1 = UT, но тогда, по определению, матрицы R и Λ подобны, так как они, согласно (53.34), удовлетворяют условию

Так как у подобных матриц суммы диагональных элементов равны, то

Учитывая, что сумма диагональных элементов матрицы R равна k, будем иметь

Таким образом,
 (53.37)
(53.37)
Представим матрицу факторных нагрузок А в виде
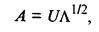 (53.38)
(53.38)
а v-й столбец матрицы А — как

где Uv — собственный вектор матрицы R, соответствующий собственному значению λv.
Найдем норму вектора Аv:
 (53.39)
(53.39)
Здесь учитывалось, что вектор Uv — нормированный и U Uv = 1. Таким образом,
Uv = 1. Таким образом,

Сравнив полученный результат с (53.32), можно сделать вывод, что собственное значение λv характеризует вклад v-й главной компоненты в суммарную дисперсию всех исходных признаков. Из (53.38) следует, что
 (53.40)
(53.40)
Согласно (53.37), общий вклад всех главных компонент в суммарную дисперсию равен k. Тогда удельный вклад v-й главной компоненты определяется по формуле  .
.
Суммарный вклад т первых главных компонент определяется из выражения  .
.
Обычно для анализа используют т первых главных компонент, вклад которых в суммарную дисперсию превышает 60—70%.
Матрица факторных нагрузок А используется для экономической интерпретации главных компонент, которые представляют собой линейные функции исходных признаков. Для экономической интерпретации fv используются лишь те хj, для которых |ajv| > 0,5.
Значения главных компонент для каждого i-го объекта (i = 1, 2, …. n) задаются матрицей F.
Матрицу значений главных компонент можно получить из формулы

откуда

Уравнение регрессии на главных компонентах строится по алгоритму пошагового регрессионного анализа, где в качестве аргументов используются главные компоненты, а не исходные показатели. К достоинству последней модели следует отнести тот факт, что главные компоненты не коррелированы. При построении уравнений регрессии следует учитывать все главные компоненты.
Пример. Построение регрессионного уравнения
По данным примера из § 53.2 провести компонентный анализ и построить уравнение регрессии урожайности Y на главных компонентах.
Решение. В примере из § 53.2 пошаговая процедура регрессионного анализа позволила исключить отрицательное значение мультиколлинеарности на качество регрессионной модели за счет значительной потери информации. Из пяти исходных показателей в окончательную модель вошли только два (x1 и x4). Более рациональным в условиях мультиколлинеарности можно считать построение уравнения регрессии на главных компонентах, которые являются линейными функциями всех исходных показателей и не коррелированы между собой.
Воспользовавшись методом главных компонент, найдем собственные значения и на их основе — вклад главных компонент в суммарную дисперсию исходных показателей x1, х2, х3, х4, х5 (табл. 53.2).
Таблица 53.2
Собственные значения главных компонент

Ограничимся экономической интерпретацией двух первых главных компонент, общий вклад которых в суммарную дисперсию составляет 89,0%. В матрице факторных нагрузок

звездочкой указаны элементы аjv = rxjfv, учитывающиеся при интерпретации главных компонент fv, где j, v = 1, 2, …, 5.
Из матрицы факторных нагрузок А следует, что первая главная компонента наиболее тесно связана со следующими показателями: x1 — число колесных тракторов на 100 га (a11 = rx1f1 = 0,95); х2 — число зерноуборочных комбайнов на 100 га (rx2f1 = 0,97); х3 — число орудий поверхностной обработки почвы на 100 га (rx3f1 = 0,94). В этой связи первая главная компонента — f1 — интерпретирована как уровень механизации работ.
Вторая главная компонента — f2 — тесно связана с количеством удобрений (х4) и химических средств оздоровления растений (x5), расходуемых на гектар, и интерпретирована как уровень химизации растениеводства.
Уравнение регрессии на главных компонентах строится по данным вектора значений результативного признака Y и матрицы F значений главных компонент.
Некоррелированность главных компонент между собой и тесноту их связи с результативным признаком у показывает матрица парных коэффициентов корреляции (табл. 53.3).
Анализ матрицы парных коэффициентов корреляции свидетельствует о том, что результативный признак у наиболее тесно связан с первой (ryf1 = 0,48), третьей (ryf3 = 0,37) и. второй (ryf2 = 0,34) главными компонентами. Можно предположить, что только эти главные компоненты войдут в регрессионную модель у.
Таблица 53.3
Матрица парных коэффициентов корреляции

Первоначально в модель у включают все главные компоненты (в скобках указаны расчетные значения t-критерия):
 (53.41)
(53.41)
Качество модели характеризуют: множественный коэффициент детерминации r = 0,517, средняя относительная ошибка аппроксимации = 10,4%, остаточная дисперсия s2 = 1,79 и Fнабл = 121. Ввиду того что Fнабл > Fкр =2,85 при α = 0,05, v1 = 6, v2 = 14, уравнение регрессии значимо и хотя бы один из коэффициентов регрессии — β1, β2, β3, β4 — не равен нулю.
Если значимость уравнения регрессии (гипотеза Н0: β1 = β2 = β3 = β4 = 0 проверялась при α = 0,05, то значимость коэффициентов регрессии, т.е. гипотезы H0: βj = 0 (j = 1, 2, 3, 4), следует проверять при уровне значимости, большем, чем 0,05, например при α = 0,1. Тогда при α = 0,1, v = 14 величина tкр = 1,76, и значимыми, как следует из уравнения (53.41), являются коэффициенты регрессии β1, β2, β3.
Учитывая, что главные компоненты не коррелированы между собой, можно сразу исключить из уравнения все незначимые коэффициенты, и уравнение примет вид
 (53.42)
(53.42)
Сравнив уравнения (53.41) и (53.42), видим, что исключение незначимых главных компонент f4 и f5, не отразилось на значениях коэффициентов уравнения b0 = 9,52, b1 = 0,93, b2 = 0,66 и соответствующих tj (j = 0, 1, 2, 3).
Это обусловлено некоррелированностью главных компонент. Здесь интересна параллель уравнений регрессии по исходным показателям (53.22), (53.23) и главным компонентам (53.41), (53.42).
Уравнение (53.42) значимо, поскольку Fнабл = 194 > Fкр = 3,01, найденного при α = 0,05, v1 = 4, v2 = 16. Значимы и коэффициенты уравнения, так как tj > tкр. = 1,746, соответствующего α = 0,01, v = 16 для j = 0, 1, 2, 3. Коэффициент детерминации r = 0,486 свидетельствует о том, что 48,6% вариации у обусловлено влиянием трех первых главных компонент.
Уравнение (53.42) характеризуется средней относительной ошибкой аппроксимации = 9,99% и остаточной дисперсией s2 = 1,91.
Уравнение регрессии на главных компонентах (53.42) обладает несколько лучшими аппроксимирующими свойствами по сравнению с регрессионной моделью (53.23) по исходным показателям: r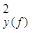 = 0,486 > r
= 0,486 > r = 0,469;
= 0,469;  = 9,99% < (х) = 10,5% и s2(f) = 1,91 < s2(x) = 1,97. Кроме того, в уравнении (53.42) главные компоненты являются линейными функциями всех исходных показателей, в то время как в уравнение (53.23) входят только две переменные (x1 и х4). В ряде случаев приходится учитывать, что модель (53.42) трудноинтерпретируема, так как в нее входит третья главная компонента f3, которая нами не интерпретирована и вклад которой в суммарную дисперсию исходных показателей (x1, …, х5) составляет всего 8,6%. Однако исключение f3 из уравнения (53.42) значительно ухудшает аппроксимирующие свойства модели: r = 0,349; = 12,4% и s2(f) = 2,41. Тогда в качестве регрессионной модели урожайности целесообразно выбрать уравнение (53.23).
= 9,99% < (х) = 10,5% и s2(f) = 1,91 < s2(x) = 1,97. Кроме того, в уравнении (53.42) главные компоненты являются линейными функциями всех исходных показателей, в то время как в уравнение (53.23) входят только две переменные (x1 и х4). В ряде случаев приходится учитывать, что модель (53.42) трудноинтерпретируема, так как в нее входит третья главная компонента f3, которая нами не интерпретирована и вклад которой в суммарную дисперсию исходных показателей (x1, …, х5) составляет всего 8,6%. Однако исключение f3 из уравнения (53.42) значительно ухудшает аппроксимирующие свойства модели: r = 0,349; = 12,4% и s2(f) = 2,41. Тогда в качестве регрессионной модели урожайности целесообразно выбрать уравнение (53.23).
Содержание
- Оценка значимости коэффициента корреляции
- Пример. Значимость коэффициента корреляции
- Пример нахождения коэффициента корреляции
- Значимость коэффициента корреляции
- Коэффициент корреляции и проверка его значимости
Оценка значимости коэффициента корреляции
Так как оценка тесноты связи с помощью коэффициента корреляции проводится, как правило, на основе выборочной информации об изучаемом явлении, то возникает вопрос: насколько правомерно наше заключение по выборочным данным о наличии корреляционной связи в генеральной совокупности, из которой была извлечена выборка?
В связи с этим возникает необходимость оценки значимости (существенности) линейного коэффициента корреляции, дающая возможность распространить выводы по результатам выборки на генеральную совокупность. В зависимости от объема выборочной совокупности предлагаются различные методы оценки существенности линейного коэффициента корреляции.
Оценка значимости коэффициента корреляции при малых объемах выборки выполняется с использованием t-критерия Стьюдента. При этом наблюдаемое (фактическое) значение этого критерия определяется по формуле:
Вычисленное по этой формуле значение сравнивается с критическим значением t-критерия, которое берется из таблицы значений t-критерия Стьюдента с учетом заданного уровня значимости α и числа степеней свободы (n-2).
Если , то полученное значение коэффициента корреляции признается значимым (т.е. нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается). И делается вывод, что между исследуемыми переменными есть тесная статистическая взаимосвязь.
Если корреляция между случайными величинами:
– положительная, то при возрастании одной случайной величины другая имеет тенденцию в среднем возрастать;
– отрицательная, то при возрастании одной случайной величины другая имеет тенденцию в среднем убывать.
Источник
Пример. Значимость коэффициента корреляции
Линейное уравнение регрессии имеет вид y=ax+b
1. Параметры уравнения регрессии.
Средние значения
Дисперсия
Среднеквадратическое отклонение
Коэффициент корреляции
Связь между признаком Y фактором X сильная и прямая.
Уравнение регрессии
| x | y | x 2 | y 2 | x·y | y(x) | (y- y ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 1 | 0.4 | 1 | 0.16 | 0.4 | 0.4357 | 0.2359 | 0.0013 | 9 |
| 2 | 0.6 | 4 | 0.36 | 1.2 | 0.5857 | 0.0816 | 0.0002 | 4 |
| 3 | 0.7 | 9 | 0.49 | 2.1 | 0.7357 | 0.0345 | 0.0013 | 1 |
| 4 | 0.9 | 16 | 0.81 | 3.6 | 0.8857 | 0.0002 | 0.0002 | 0 |
| 5 | 1.1 | 25 | 1.21 | 5.5 | 1.0357 | 0.0459 | 0.0041 | 1 |
| 6 | 1.3 | 36 | 1.69 | 7.8 | 1.1857 | 0.1716 | 0.0131 | 4 |
| 7 | 1.2 | 49 | 1.44 | 8.4 | 1.3357 | 0.0988 | 0.0184 | 9 |
| 28 | 6.2 | 140 | 6.16 | 29 | 6.2 | 0.6686 | 0.0386 | 28 |
2. Оценка параметров уравнения регрессии.
Значимость коэффициента корреляции определяется по формуле (см. п. VI):
Для оценки значимости коэффициента корреляции используют критерий Стьюдента. По таблице Стьюдента находим Tтабл(n-m-1;α/2) = Tтабл(5;0.025) = 2.571 (двусторонняя критическая область)
1-α (95% — доверительный интервал)
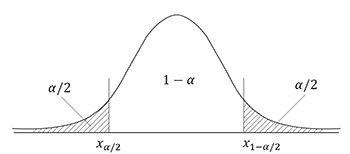
Поскольку Tнабл > Tтабл (наблюдаемое значение критерия Tнабл принадлежит критической области), то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Интервальная оценка для коэффициента корреляции (доверительный интервал).
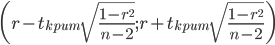
Доверительный интервал для коэффициента корреляции. 
r(0.695;1)
Источник
Пример нахождения коэффициента корреляции

Другие варианты формул:
или 

Кxy — корреляционный момент (коэффициент ковариации)

 Для нахождения линейного коэффициента корреляции Пирсона необходимо найти выборочные средние x и y , и их среднеквадратические отклонения σx = S(x), σy = S(y):
Для нахождения линейного коэффициента корреляции Пирсона необходимо найти выборочные средние x и y , и их среднеквадратические отклонения σx = S(x), σy = S(y):
Свойства коэффициента корреляции
- |rxy| ≤ 1;, -1≤x≤1
- если X и Y независимы, то rxy=0 , обратное не всегда верно;
- если |rxy|=1 , то Y=aX+b , |rxy(X,aX+b)|=1 , где a и b постоянные, а ≠ 0;
- |rxy(X,Y)|=|rxy(a1X+b1, a2X+b2)|, где a1, a2, b1, b2 – постоянные.
Поэтому для проверки направления связи выбирается проверка гипотезы при помощи коэффициента корреляции Пирсона с дальнейшей проверкой на достоверность при помощи t-критерия (пример см. ниже).
- Решение онлайн
- Видеоинструкция
- Оформление Word
- Типовые задачи
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
Пример . На основе данных, приведенных в Приложении 1 и соответствующих Вашему варианту (таблица 2), требуется:
- Рассчитать коэффициент линейной парной корреляции и построить уравнение линейной парной регрессии одного признака от другого. Один из признаков, соответствующих Вашему варианту, будет играть роль факторного (х), другой – результативного (y). Причинно-следственные связи между признаками установить самим на основе экономического анализа. Пояснить смысл параметров уравнения.
- Определить теоретический коэффициент детерминации и остаточную (необъясненную уравнением регрессии) дисперсию. Сделать вывод.
- Оценить статистическую значимость уравнения регрессии в целом на пятипроцентном уровне с помощью F-критерия Фишера. Сделать вывод.
- Выполнить прогноз ожидаемого значения признака-результата y при прогнозном значении признака-фактора х, составляющим 105% от среднего уровня х. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал с вероятностью 0,95.
Решение. Уравнение имеет вид y = ax + b
Средние значения
Коэффициент регрессии: k = a = 4.01
Коэффициент детерминации
R 2 = 0.99 2 = 0.97, т.е. в 97% случаев изменения х приводят к изменению y . Другими словами — точность подбора уравнения регрессии — высокая. Остаточная дисперсия: 3%.
| x | y | x 2 | y 2 | x·y | y(x) | (yi— y ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 1 | 107 | 1 | 11449 | 107 | 103.19 | 333.06 | 14.5 | 30.25 |
| 2 | 109 | 4 | 11881 | 218 | 107.2 | 264.06 | 3.23 | 20.25 |
| 3 | 110 | 9 | 12100 | 330 | 111.21 | 232.56 | 1.47 | 12.25 |
| 4 | 113 | 16 | 12769 | 452 | 115.22 | 150.06 | 4.95 | 6.25 |
| 5 | 120 | 25 | 14400 | 600 | 119.23 | 27.56 | 0.59 | 2.25 |
| 6 | 122 | 36 | 14884 | 732 | 123.24 | 10.56 | 1.55 | 0.25 |
| 7 | 123 | 49 | 15129 | 861 | 127.26 | 5.06 | 18.11 | 0.25 |
| 8 | 128 | 64 | 16384 | 1024 | 131.27 | 7.56 | 10.67 | 2.25 |
| 9 | 136 | 81 | 18496 | 1224 | 135.28 | 115.56 | 0.52 | 6.25 |
| 10 | 140 | 100 | 19600 | 1400 | 139.29 | 217.56 | 0.51 | 12.25 |
| 11 | 145 | 121 | 21025 | 1595 | 143.3 | 390.06 | 2.9 | 20.25 |
| 12 | 150 | 144 | 22500 | 1800 | 147.31 | 612.56 | 7.25 | 30.25 |
| 78 | 1503 | 650 | 190617 | 10343 | 1503 | 2366.25 | 66.23 | 143 |
Примечание: значения y(x) находятся из полученного уравнения регрессии:
y(1) = 4.01*1 + 99.18 = 103.19
y(2) = 4.01*2 + 99.18 = 107.2
. . .
Значимость коэффициента корреляции
Анализ точности определения оценок коэффициентов регрессии
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 7
(122.4;132.11)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
Статистическая значимость коэффициента регрессии подтверждается (18.63>2.228).
Статистическая значимость коэффициента регрессии подтверждается (62.62>2.228).
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=2.228):
(a — tтабл·Sa; a + tтабл·S a)
(3.6205;4.4005)
(b — tтабл·Sb; b + tтабл·Sb)
(96.3117;102.0519)
Пример №2
1. Расчет средних значений x , y : x = ∑xi n = 660.6 11 = 60.05 y = ∑yi n = 333.94 11 = 30.36 x·y = ∑xi·yi n = 19952.07 11 = 1813.82
2. Расчет дисперсий: S 2 (x) = xi 2 n — x 2 = 40337.2 11 — 60.05 2 = 60.47 S 2 (y) = yi 2 n — y 2 = 10329.52 11 — 30.36 2 = 17.43 3. Расчет среднеквадратических отклонений: S(x) = √ S 2 (x) = √ 60.47 = 7.78 S(y) = √ S 2 (y) = √ 17.43 = 4.17
4. Расчет линейного коэффициента корреляции Пирсона: rxy = x·y — x · y S(x)·S(y) = 1813.82-60.05·30.36 7.78·4.17 = -0.2872 Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 2 y 2 x·y y(x) (yi— y ) 2 (y-y(x)) 2 68.5 22.39 4692.25 501.31 1533.72 29.06 63.49 44.44 75.7 29.24 5730.49 854.98 2213.47 27.95 1.25 1.67 52.7 32.92 2777.29 1083.73 1734.88 31.49 6.56 2.04 60.2 33.52 3624.04 1123.59 2017.9 30.34 10 10.14 62.3 30.98 3881.29 959.76 1930.05 30.01 0.39 0.94 48.3 37.17 2332.89 1381.61 1795.31 32.17 46.4 25 56.5 32.12 3192.25 1031.69 1814.78 30.91 3.1 1.47 65.9 31.76 4342.81 1008.7 2092.98 29.46 1.97 5.3 56.2 28.48 3158.44 811.11 1600.58 30.95 3.53 6.11 51.1 23.17 2611.21 536.85 1183.99 31.74 51.67 73.42 63.2 32.19 3994.24 1036.2 2034.41 29.87 3.36 5.37 660.6 333.94 40337.2 10329.52 19952.07 333.94 191.71 175.9
Значимость линейного коэффициента корреляции Пирсона. tнабл = rxy· √ n-2 √ 1-rxy 2 = 0.2872· √ 9 √ 1-0.2872 2 = 0.9
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=n-m-1=11-1-1=9 находим tкрит: tкрит(n-m-1;α/2) = tкрит(9;0.025) = 2.262, где m=1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции Пирсона признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл , то принимаем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — не значим
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
Интервальная оценка для линейного коэффициента корреляции Пирсона ( rxy — tкрит· 1-rxy 2 √ n ; rxy + tкрит· 1-rxy 2 √ n )
Доверительный интервал для коэффициента корреляции ( 0.29 — 2.262· 1-0.29 2 √ 11 ; 0.29 + 2.262· 1-0.29 2 √ 11 ) Доверительный интервал для линейного коэффициента корреляции Пирсона: r(-0.9129;0.3386)
Источник
Коэффициент корреляции и проверка его значимости




![]()
![]()
Одним из важнейших элементов эконометрического анализа является установление наличия и тесноты связи между различными показателями (например, между ценой и спросом, доходом и потреблением, инфляцией и безработицей). Обычно анализ начинают с простейшей – линейной зависимости.
Числовой характеристикой, измеряющей степень тесноты линейной статистической связи между случайными переменными Х и Y, является коэффициент корреляции между Х и Y, который обозначается r = 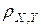 и определяется по формуле
и определяется по формуле
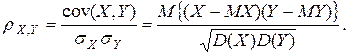
Приведем основные его свойства.
1. Для любых переменных Х и Y абсолютная величина коэффициента корреляции не превосходит единицы: 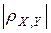 £ 1, или – 1 £ £ + 1.
£ 1, или – 1 £ £ + 1.
2. Абсолютная величина коэффициента корреляции равна единице тогда и только тогда, когда между переменными Х и Y существует линейная функциональная зависимость, т. е. Y = aX + b, где a ¹ 0 и b – некоторые постоянные величины. При этом = 1, если a > 0, и = – 1, если a
Из этих свойств вытекает смысл , который состоит в том, что коэффициент корреляции характеризует тесноту линейной статистической связи между переменными Х и Y: чем ближе к единице, тем связь сильнее; чем ближе к нулю, тем связь слабее. Переменные X и Y называются положительно коррелированными, если 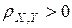 и отрицательно коррелированными, если
и отрицательно коррелированными, если 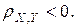
Определение и свойства теоретического коэффициента корреляции показывают, что изучение линейной статистической зависимости между переменными Х и Y имеет смысл лишь тогда, когда величина r =  значима (или существенна), т. е. не очень близка к нулю. Однако эта величина на практике, как правило, неизвестна и может быть лишь оценена с помощью выборочных данных.
значима (или существенна), т. е. не очень близка к нулю. Однако эта величина на практике, как правило, неизвестна и может быть лишь оценена с помощью выборочных данных.
Точечной оценкой теоретического коэффициента корреляции является выборочный коэффициент корреляции r = rxy , который находится по формуле
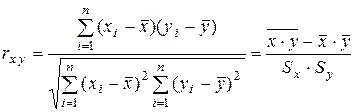 . (2.33)
. (2.33)
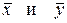 – выборочные средние переменных X и Y соответственно;
– выборочные средние переменных X и Y соответственно;
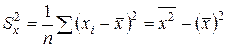 – выборочная дисперсия переменной X;
– выборочная дисперсия переменной X;
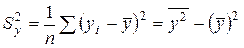 – выборочная дисперсия переменной Y;
– выборочная дисперсия переменной Y;
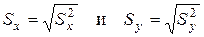 – выборочные среднеквадратические (стандартные) отклонения переменных X и Y соответственно;
– выборочные среднеквадратические (стандартные) отклонения переменных X и Y соответственно;
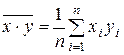 – выборочное среднее переменной X× Y .
– выборочное среднее переменной X× Y .
Исходя из определения (2.33), можно показать, что выборочный коэффициент корреляции также обладает сформулированными выше свойствами 1 – 3.
Если выборка имеет достаточно большой объем и хорошо представляет генеральную совокупность (репрезентативна), то заключение о тесноте линейной зависимости между переменными, полученное по выборочным данным, в известной мере может быть распространено и на генеральную совокупность. Для достижения этой цели используется критерий, основанный на распределении Стьюдента.
Пусть основная гипотеза Н0состоит в том, что корреляция между Х и Y не значима, т. е. Н0: = 0. Альтернативная гипотеза Н1= 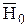 состоит в том, что корреляция между Х и Y значима. Если справедлива нулевая гипотеза Н0 и объем выборки n достаточно велик, то статистика
состоит в том, что корреляция между Х и Y значима. Если справедлива нулевая гипотеза Н0 и объем выборки n достаточно велик, то статистика
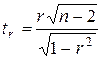 (2.34)
(2.34)
имеет приближенно распределение Стьюдента с (n – 2) степенями свободы.
Для заданного уровня значимости a находим по таблице 1 Приложения
t1–a/2(n – 2) – квантиль порядка (1–a/2) распределения Стьюдента с (n – 2) степенями свободы. Тогда нулевая гипотеза Н0принимается при выполнении неравенства
Решение. В примере 2.2 были определены
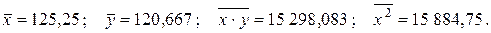
Вычислим далее среднее
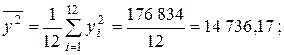
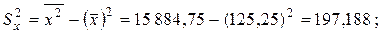
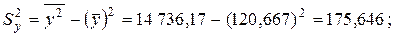
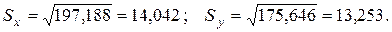
По формуле (2.33) находим
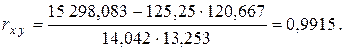
Данное значение коэффициента корреляции позволяет сделать вывод о сильной (прямой) линейной статистической зависимости между рассматриваемыми переменными Х и Y.
Проверим гипотезу Н0: = 0 против альтернативной Н1: ¹ 0 на уровне значимости a = 0,01. По формуле (2.34) вычислим статистику
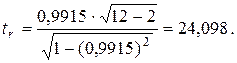
С помощью таблицы квантилей распределения Стьюдента определим
t1–a/2(n – 2) = t0, 995(10) = 3,1693. Поскольку | tr | > t1–a/2(n – 2) (24,098 > 3,1693), то коэффициент корреляции rx y статистически значим. Следовательно, существенно отличается от нуля и между переменными Х и Y существует сильная линейная статистическая зависимость. g
Замечание 2.5. Сравнивая формулы (2.7) и (2.33) для коэффициентов регрессии и корреляции соответственно, нетрудно заметить, что в линейной модели между ними существует зависимость:
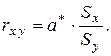
Так, используя результаты вычислений в примерах 2.2 и 2.6, получаем
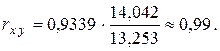
Некоторое (незначительное) расхождение с величиной, полученной в примере 2.6, вызвано ошибками округлений. 3
Замечание 2.6. В случае парной линейной регрессионной модели квадрат коэффициента корреляции между зависимой и независимой переменной равен коэффициенту детерминации:
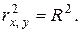
Так для данных примера 2.2 R 2 = 0,983 » (0,9915) 2 = 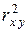 (см. примеры 2.5 и 2.6); неточности в данном случае связаны с округлением вычислений. 3
(см. примеры 2.5 и 2.6); неточности в данном случае связаны с округлением вычислений. 3
Контрольные вопросы
1. Что такое функция регрессии?
2. Чем регрессионная модель отличается от функции регрессии?
3. Какая регрессионная модель называется линейной?
4. Какой смысл имеют коэффициенты парного линейного уравнения регрессии?
5. В чем состоит различие между теоретическим и выборочным уравнением регрессии?
6. В чем сущность метода наименьших квадратов (МНК)?
7. Приведите формулы расчета коэффициентов парного линейного уравнения регрессии по МНК.
8. Перечислите предпосылки регрессионного анализа.
9. Сформулируйте основные свойства МНК-оценок.
10. Имеют ли коэффициенты парной линейной регрессии размерность?
11. Как оценивается дисперсия возмущений?
12. Какие факторы влияют на величину стандартных ошибок коэффициентов регрессии?
13. Как строятся интервальные оценки коэффициентов регрессии?
14. Как строятся доверительные полосы для: а) уравнения регрессии; б) индивидуальных значений результирующей переменной?
13. Какие виды прогнозов Вы знаете?
14. В чем суть предсказания: а) среднего значения; б) индивидуальных значений результирующей переменной?
15. Объясните суть коэффициента корреляции.
16. Сформулируйте основные свойства коэффициента корреляции.
17. Почему коэффициент корреляции называют мерой линейной зависимости между переменными?
18. В чем суть значимости коэффициента корреляции и как она проверяется?
19. Опишите «грубое» правило анализа статистической значимости коэффициента корреляции.
20. Как связаны коэффициенты регрессии и корреляции в парной регрессионной линейной модели?
21. В чем суть статистической значимости коэффициентов регрессии? Как она проверяется?
22. Опишите «грубое» правило анализа статистической значимости коэффициентов регрессии.
23. Объясните суть коэффициента детерминации.
24. В чем суть статистической значимости уравнения регрессии? Как она проверяется?
25. Как связаны коэффициенты детерминации и корреляции в парной регрессионной линейной модели?
Источник
Оценка значимости коэффициента корреляции
Так как оценка тесноты связи с помощью коэффициента корреляции проводится, как правило, на основе выборочной информации об изучаемом явлении, то возникает вопрос: насколько правомерно наше заключение по выборочным данным о наличии корреляционной связи в генеральной совокупности, из которой была извлечена выборка?
В связи с этим возникает необходимость оценки значимости (существенности) линейного коэффициента корреляции, дающая возможность распространить выводы по результатам выборки на генеральную совокупность. В зависимости от объема выборочной совокупности предлагаются различные методы оценки существенности линейного коэффициента корреляции.
Оценка значимости коэффициента корреляции при малых объемах выборки выполняется с использованием t-критерия Стьюдента. При этом наблюдаемое (фактическое) значение этого критерия определяется по формуле:
(5)
Вычисленное по этой формуле значение сравнивается с критическим значением t-критерия, которое берется из таблицы значений t-критерия Стьюдента с учетом заданного уровня значимости α и числа степеней свободы (n-2).
Если , то полученное значение коэффициента корреляции признается значимым (т.е. нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается). И делается вывод, что между исследуемыми переменными есть тесная статистическая взаимосвязь.
Если корреляция между случайными величинами:
– положительная, то при возрастании одной случайной величины другая имеет тенденцию в среднем возрастать;
– отрицательная, то при возрастании одной случайной величины другая имеет тенденцию в среднем убывать.