
Умные люди придумали коды, по которым можно определить, что произошло с HTTP-запросом. Успешен ли он, произошло ли перенаправление. Или же все закончилось ошибкой. Как раз об ошибках и будем говорить в этой статье. Вкратце расскажу, какие они бывают и с чем связаны.
А еще тут будет парочка забавных (и не очень) пикч и анимаций на тему описанных ошибок. Хоть какое-то развлечение.
Ошибки со стороны клиента (4xx)
Для начала перечислим коды ошибок на стороне клиента. Вина за их появление ложится на плечи обоих участников соединения.
400 Bad Request
Такой ответ от браузера можно получить в том случае, если сервер не смог правильно отреагировать на запрос со стороны пользователя. Часто код 400 возникает при попытке клиента получить доступ к серверу без соблюдения правил оформления синтаксиса протокола передачи гипертекста (HTTP). Повторный запрос не стоит отправлять до тех пор, пока не будет исправлена ошибка (или несколько из них).
401 Unauthorized
Код 401 возникает при попытке клиента получить доступ к серверу, используя неправильные данные для авторизации. По сути, используется, когда пользователь вводит неправильный логин и пароль на ресурсе, где требуется эта информация для входа. Читайте: Как исправить ошибку 401
402 Payment Required
Эта ошибка сообщает клиенту о том, что для успешного выполнения запроса ему необходимо оплатить доступ к серверу. Изначально код 402 должен был стать неким стандартом для цифровой валюты и оплаты контента в сети. Но не срослось. До сих пор нет единого решения по поводу того, как должны выглядеть платежи в сети. Также нет и единого решения по поводу того, как стоит использовать 402.
Все еще считается, что код существует с расчетом на будущее. Сейчас почти не используется и поддерживается не всеми браузерами.
403 Forbidden
Почти то же, что и 401. Сервер снова не разрешает к нему подключиться, хотя с запросом все в порядке. Просто нет доступа. Причем повторная авторизация с другими логином и паролем никак не помогут. Все вопросы к владельцам сервера (но не всегда). Инструкция по устранению ошибки.

Творчество на тему знаменитой киносаги
404 Not Found
Легендарная ошибка, ставшая популярным мемом. 404 оповещает клиента о том, что его запрос ведет в никуда. Код возникает, когда пользователь пытается попасть на страницу, которой не существует. Например, когда случайно ошибается при вводе ссылки и вводит ее с опечаткой. Или же пытается получить доступ к странице, которой на сайте уже нет.
В отличие от других кодов, страницу с 404 частенько кастомизируют, создавая для нее уникальный дизайн. Мало того, что это выглядит симпатичнее, так еще и полезнее для посетителей. Можно прямо на странице с ошибкой разъяснить, что произошло и как дальше действовать.


И таких вариаций тысячи. Каждый пытается добавить в оформление что-то свое.
405 Method Not Allowed
405 сообщает клиенту о том, что метод, используемый при запросе, не разрешен. В качестве примера можно привести попытку со стороны клиента ввести данные в форму с помощью GET, когда она работает только с POST. Ну и в таком же духе.
406 Not Acceptable
Ошибка 406 сообщает о том, что страница передает контент, который не может быть распознан клиентом. Возможно, проблема в методе сжатия или в формате страницы. Иногда сюда же приплетают неправильные настройки кодировки.
Этот код редко используют на практике, так как его появления можно избежать, предоставив пользователю информацию на сайте в том виде, который его браузер способен принять. Посетитель сайта по итогу получит не то, что ожидал, но хотя бы не ошибку.
407 Proxy Authentication Required
Этот код тоже похож на 401. Только на этот раз логин и пароль нужны не для основного сервера, а для прокси, который находится между клиентом и сервером. Обычно в теле ошибки содержится информация о том, как можно правильно пройти авторизацию и получить доступ к ресурсу.
408 Request Timeout
408 говорит нам о том, что сервер пожелал разорвать соединение с клиентом, потому что оно никак не используется. Происходит это в том случае, если сервер буквально устал ждать, пока наладится соединение с ним. Поэтому такую ошибку часто можно лицезреть после очень долгой и безуспешной загрузки какого-нибудь сайта.
Многие серверы не отправляют никаких сообщений, а просто прерывают соединение по той же причине. На запрос уходит больше времени, чем на то полагается.

В Мистере Роботе частенько называли серии в честь ошибок HTTP (весь четвертый сезон в нумерации 4хх). В честь 408, например, назвали восьмую серию четвертого сезона
409 Conflict
Сообщение о конфликте возникает, когда запрос со стороны клиента не соответствует тому, чего ожидает сервер. В качестве примера приводят проблемы при проверки версий, когда пользователь пытается с помощью метода PUT загрузить на сервер новый файл, но там уже имеется более новая версия того же файла. Конфликта версий можно легко избежать, загрузив корректную версию.
410 Gone
Своего рода аналог 404. Разница лишь в том, что 410 намекает на перманентность отсутствия страницы. Так что этот код стоит использовать, когда на 100% уверен, что страница ушла в небытие (ну или с текущего адреса) навсегда. В любом другом случае есть универсальный 404.
411 Length Required
411 оповещает пользователя о том, что сервер не желает принимать запрос со стороны клиента, потому что в нем не определен заголовок Content-Length. Да, это первый код в подборке, который смогут понять только люди, сведущие в настройке серверов. По-простому уложить сущность HTML-заголовков в этот материал не получится.
412 Precondition Failed
Еще один код, сообщающий о том, что сервер отклонил запрос пользователя и не разрешает доступ к выбранному ресурсу. Проблемы возникают при неправильной настройке работы методов, отличающихся от GET и HEAD.
413 Payload Too Large/Request Entity Too Large
Код 413 говорит нам, что запрос, который посылает клиент на сервер, слишком большой. Поэтому сервер отказывается его обрабатывать и разрывает соединение. Обычно это происходит при попытке загрузить на ресурс какой-то файл, превышающий ограничение, выставленное в настройках сервера. Соответственно, решается проблема изменением настроек сервера.
414 URI Too Long
Чем-то этот код похож на предыдущий. Здесь тоже идет речь о превышение лимита. Только теперь это касается не запроса со стороны клиента, а длины URI. То есть ссылки. Выходит, что адрес, используемый клиентом, больше, чем тот, что может обработать сервер. Как-то так.
Такая ошибка иногда выскакивает при попытке взломать ресурс. Сайт так реагирует на слишком частые попытки воспользоваться потенциальными дырами в безопасности.
415 Unsupported Media Type
Ошибка 415 возникает, когда клиент пытается загрузить на сервер данные в неподходящем формате. В таком случае сервер просто отказывается принимать посылаемые файлы и разрывает соединение. Как и в случае с 413.
416 Range Not Satisfiable
Подобный ответ можно ожидать, если клиент запрашивает у сервера определенные данные, но эти данные на сервере не соответствуют запросу. То есть, грубо говоря, вы просите у сервера какой-то набор данных с заранее заданным размером, а в итоге оказывается, что размер этих данных меньше, чем объем, указанный в запросе. Серверу ничего не остается, кроме как послать вас, ведь он не обучен поведению в таких ситуациях.
417 Expectation Failed
Такая ошибка высвечивается, когда ожидания сервера не совпадают с данными в запросе клиента. Сведения об ожиданиях прописываются в заголовке Expect заранее. Так что можно ознакомиться с ними, чтобы выяснить, как решить названную проблему.
418 I’m a teapot
Код 418 можно увидеть, если сервер откажется варить кофе, потому что он чайник. Это первоапрельская шутка. Естественно, 418 не используется нигде всерьез и просто существует как дань памяти программистам-юмористам, придумавшим это в 1998 году.

У Google получился такой симпатичный чайник
421 Misdirected Request
Появляется когда запрос клиента переправляется на сервер, который не может дать на него адекватный ответ. Например, если запрос был отправлен на ресурс, который вообще не настроен обрабатывать запросы извне.
Чтобы исправить проблему, можно попробовать переподключиться к ресурсу заново или попробовать другое соединение.
422 Unprocessable Entity
Код 422 говорит, что сервер вроде бы принял запрос, понял его, все хорошо, но из-за семантических ошибок корректно обработать не смог. Значит, где-то в запросе затаилась логическая ошибка, мешающая корректному взаимодействию клиента и сервера. Надо ее найти и исправить.
423 Locked
Обычно на этот код напарываются, когда запрашиваемый ресурс оказывается под защитой. Используемые клиентом методы блокируются на уровне сервера. Это делается, чтобы обезопасить данные, хранящиеся на защищенной странице. Без логина и пароля выудить информацию с такого сервера не получится.
424 Failed Dependency
424 сообщает о том, что для выполнения запроса со стороны клиента успешно должна завершиться еще одна или несколько параллельных операций. Если какая-то из них «провалится», то «помрет» все соединение сразу, и обработать запрос до конца не получится. Аналогичное происходит, если некорректно был обработан один из предыдущих запросов.
425 Too Early
Появляется в ответ на запрос, который может быть моментально запущен заново. Сервер не рискует и не берется за его обработку, чтобы не подставиться под так называемую «атаку повторного воспроизведения».
426 Upgrade Required
Тут нам прямо сообщают, что сервер не желает с нами общаться, пока мы не перейдем на более современный протокол. Наткнуться на такую ошибку очень тяжело, но в случае появления, скорее всего, будет достаточно установить браузер посвежее.
428 Precondition Required
428 выскакивает, если пользователь отправляет запрос на сервер, но получает некорректные или неактуальные данные. Так ресурс оповещает о необходимости внести в запрос информацию о предварительных условиях обработки данных. Только так он сможет гарантировать получение клиентом нужной информации.
429 Too Many Requests
Здесь все просто. Ошибка появляется, когда клиент отправляет на сервер слишком много запросов в короткий промежуток времени. Очень похоже на поведение взломщиков. По этой причине запрос моментально блокируется.

431 Request Header Fields Too Large
Из названия понятно, что ошибка с кодом 431 появляется из-за того, что в запросе клиента используются слишком длинные заголовки (неважно, один или несколько из них). Исправляется это с помощью сокращения заголовков и повторной отправки запроса. В теле ошибки обычно отображается краткая информация о том, как пользователь может решить эту проблему самостоятельно.
444 No Response
Этот код вам вряд ли удастся увидеть. Он отображается в лог-файлах, чтобы подтвердить, что сервер никак не отреагировал на запрос пользователя и прервал соединение.
449 Retry With
Код используется в расширениях компании Microsoft. Он сигнализирует о том, что запрос от клиента не может быть принят сервером. Причиной становятся неверно указанные параметры. Сама 449 ошибка говорит о необходимости скорректировать запрос и повторить его снова, подготовив к работе с сервером.
450 Blocked by Windows Parental Controls
450 код увидят дети, попавшие под действие системы «Родительский контроль» компании Microsoft. По сути, ошибка говорит о том, что с компьютера попытались зайти на заблокированный ресурс. Избежать этой ошибки можно изменением параметров родительского контроля.
451 Unavailable For Legal Reasons
Этот код сообщает клиенту, что он не может попасть на запрашиваемый ресурс из юридических соображений. Скорее всего, доступ был заблокирован из-за каких-нибудь государственных санкций, нового законодательства или цензуры со стороны властей. В общем, все вопросы к государству и провайдеру связи.

Читайте также


Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Список ошибок на стороне сервера (5xx)
Теперь поговорим об ошибках, которые возникают где-то на сервере. Все они связаны с запросами, которые не удается обработать на том конце. Пользователь зачастую в их появлении не виноват.
500 Internal Server Error
Этот код возникает, когда сервер сталкивается с непредвиденными обстоятельствами. Такими, которые и сам не может пояснить. Как, собственно, и завершить запрос со стороны пользователя. По факту, эта ошибка говорит нам что-то вроде «Я не могу подобрать более подходящий код ошибки, поэтому лови 500 и делай с этим, что хочешь». Мы писали о нем чуть подробнее тут.

Дело не в тебе, дело во мне (С)

501 Not Implemented
501 говорит нам, что функциональность, необходимая для обработки запроса со стороны клиента, попросту не реализована на сервере. Он не сможет корректно обработать используемый метод.
Иногда в теле ошибки еще пишут что-то в духе «Приходите попозже, возможно, в будущем нужная функция появится».
502 Bad Getaway
Можно встретить в том случае, если запрашиваемый сервер выступает в роли шлюза или прокси. Возникает из-за несогласования протоколов между вышестоящим серверов и его шлюзом. Рассказываем о том, как ее исправить, в этой статье.
503 Service Unavailable
Появляется, когда сервер не может обработать запрос клиента по одной из двух технических причин:
- Слишком много пользователей в текущий момент пытаются отправить запросы, и у сервера не остается ресурсов, чтобы ответить кому-либо еще.
- На сервере ведутся технические работы, временно блокирующие его работу.
Обычно ошибка 503 носит временный характер, и для ее решения достаточно немного подождать.
504 Gateway Timeout
Ошибка похожа на 408. Здесь же прокси-сервер пытается выйти на контакт с вышестоящим сервером, но не успевает это сделать до истечения тайм-аута. Отсюда и ошибка.

505 HTTP Version Not Supported
Этот код похож на 426. Он тоже связан с неподходящей версией протокола HTTP. В этом случае нужно обеспечить и клиента, и сервер единой версией. Она, как правило, указывается в запросе со стороны пользователя.
506 Variant Also Negotiates
Обычно с такой ошибкой сталкиваются только в том случае, если сервер изначально настроен неправильно. То есть это не сиюминутная проблема, а что-то серьезное на уровне базовой конфигурации. Тут придется потрудиться разработчикам. Выявить проблему и разрешить ее.
507 Insufficient Storage
Код 507 встречается в тех ситуациях, когда серверу не хватает пространства в хранилище для обработки запроса со стороны клиента. Проблема решается освобождением места или расширением доступного пространства. Тогда сервер сможет без проблем обработать запрос пользователя.
508 Loop Detected
Таким кодом сервер отзовется в случае, если заметит бесконечный цикл в запросе клиента. Можно расценивать его как провал запроса и выполняемой операции в целом.
509 Bandwidth Limit Exceeded
Возникает, если сервер начинает потреблять больше трафика, чем ему позволено.
510 Not Extended
Появляется, если клиент посылает запрос на использование какого-либо расширения, отсутствующего на сервере. Чтобы исправить проблему, надо убрать декларирование неподдерживаемого расширения из запроса или добавить поддержку на сервер.
511 Network Authentication Required
511 код говорит о том, что перед тем как выйти в сеть, надо авторизоваться (ввести логин и пароль). Можно воспринимать это неким PPPoE подключением, когда от клиента требуются данные для авторизации.
Заключение
Закончили. Это все ошибки, которыми отзывается HTTP, если на стороне сервера или клиента что-то пошло не так. Наткнуться на большую их часть довольно тяжело. Особенно, если вы раньше только серфили в интернете, а не занимались разработкой сайтов. А тем, кто входит в эту стезю, полезно знать основные ошибки, так как, скорее всего, придется не раз их исправлять.
Все курсы > Анализ и обработка данных > Занятие 5
На прошлом занятии, посвященном практике EDA, мы работали с «чистыми данными», то есть такими данными, в которых нет ни ошибок, ни пропущенных значений. К сожалению, так бывает далеко не всегда.
Сегодня мы научимся очищать данные от дубликатов, неверных и плохо отформатированных значений, а также исправлять ошибки в дате и времени. На следующем занятии мы поговорим про работу с пропусками.
Откроем ноутбук к этому занятию⧉
Ошибки в данных могут встречаться по многим причинам. Они могут быть связаны с человеческим фактором, например, простой невнимательностью, или вызваны сбоями в работе записывающего какие-либо показатели оборудования.
В качестве примера мы будем использовать несложный датасет, в котором содержатся данные за 2019 год об отдельных финансовых показателях сети магазинов одежды, представленной в нескольких городах мира. В частности, нам доступна следующая информация:
- month — за какой месяц сделана запись
- profit — прибыль (profit) по сети
- MoM — изменение выручки (revenue) сети по отношению к предыдущему месяцу
- high — магазин с наибольшей маржинальностью (margin) продаж
Создадим датафрейм из словаря.
|
financials = pd.DataFrame({‘month’ : [’01/01/2019′, ’01/02/2019′, ’01/03/2019′, ’01/03/2019′, ’01/04/2019′, ’01/05/2019′, ’01/06/2019′, ’01/07/2019′, ’01/08/2019′, ’01/09/2019′, ’01/10/2019′, ’01/11/2019′, ’01/12/2019′, ’01/12/2019′], ‘profit’ : [‘1.20$’, ‘1.30$’, ‘1.25$’, ‘1.25$’, ‘1.27$’, ‘1.11$’, ‘1.23$’, ‘1.20$’, ‘1.31$’, ‘1.24$’, ‘1.18$’, ‘1.17$’, ‘1.23$’, ‘1.23$’], ‘MoM’ : [0.03, —0.02, 0.01, 0.02, —0.01, —0.015, 0.017, 0.04, 0.02, 0.01, 0.00, —0.01, 2.00, 2.00], ‘high’ : [‘Dubai’, ‘Paris’, ‘singapour’, ‘singapour’, ‘moscow’, ‘Paris’, ‘Madrid’, ‘moscow’, ‘london’, ‘london’, ‘Moscow’, ‘Rome’, ‘madrid’, ‘madrid’] }) financials |
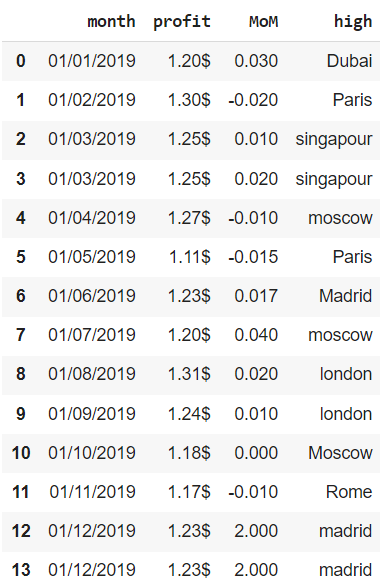
Воспользуемся методом .info() для получения общей информации о датасете.
|
<class ‘pandas.core.frame.DataFrame’> RangeIndex: 14 entries, 0 to 13 Data columns (total 4 columns): # Column Non-Null Count Dtype — —— ————— —— 0 month 14 non-null object 1 profit 14 non-null object 2 MoM 14 non-null float64 3 high 14 non-null object dtypes: float64(1), object(3) memory usage: 576.0+ bytes |
Перейдем к поиску ошибок в данных.
Дубликаты
Поиск дубликатов
Заметим, что хотя данные представлены за 12 месяцев, в датафрейме тем не менее содержится 14 значений. Это заставляет задуматься о дубликатах (duplicates) или повторяющихся значениях. Воспользуемся методом .duplicated(). На выходе мы получим логический массив, в котором повторяющееся значение обозначено как True.
|
# keep = ‘first’ (параметр по умолчанию) # помечает как дубликат (True) ВТОРОЕ повторяющееся значение financials.duplicated(keep = ‘first’) |
|
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
# keep = ‘last’ соответственно считает дубликатом ПЕРВОЕ повторяющееся значение financials.duplicated(keep = ‘last’) |
|
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 True 13 False dtype: bool |
Результат метода .duplicated() можно использовать как фильтр.
|
# с параметром keep = ‘last’ будет выведено наблюдение с индексом 12 financials[financials.duplicated(keep = ‘last’)] |

Также заметим, что если смотреть по месяцам, у нас две дублирующихся записи, а не одна. В частности, повторяется запись не только за декабрь, но и за март. Проверим это с помощью параметра subset.
|
# с помощью параметра subset мы ищем дубликаты по конкретным столбцам financials.duplicated(subset = [‘month’]) |
|
0 False 1 False 2 False 3 True 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
# посчитаем количество дубликатов по столбцу month financials.duplicated(subset = [‘month’]).sum() |
Создадим новый фильтр и выведем дубликаты по месяцам.
|
# укажем параметр keep = ‘last’, больше доверяя, таким образом, # последнему записанному за конкретный месяц значению financials[financials.duplicated(subset = [‘month’], keep = ‘last’)] |

Аналогичным образом мы можем посмотреть на неповторяющиеся значения.
|
( ~ financials.duplicated(subset = [‘month’])).sum() |
Этот логический массив можно также использовать как фильтр.
|
financials[ ~ financials.duplicated(subset = [‘month’], keep = ‘last’)] |
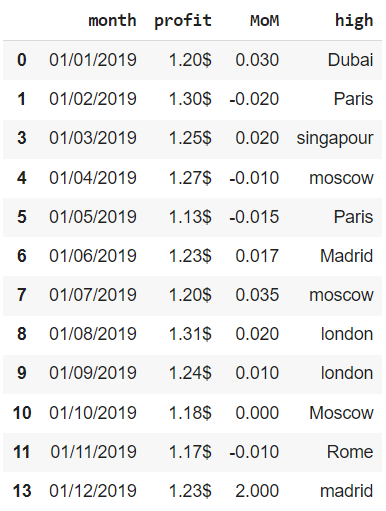
Обратите внимание, индекс остался прежним (из него просто выпали наблюдения 2 и 12). Мы исправим эту неточность при удалении дубликатов.
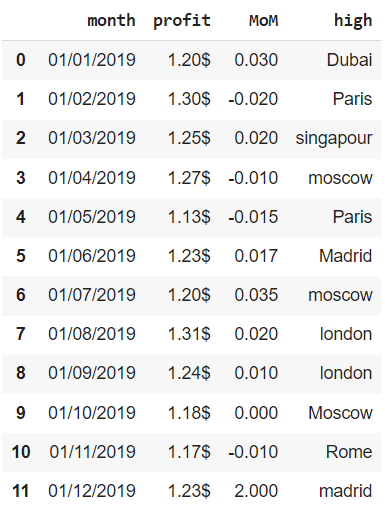
Удаление дубликатов
Метод .drop_duplicates() удаляет дубликаты из датафрейма и, по сути, принимает те же параметры, что и метод .duplicated().
|
# параметр ignore_index создает новый индекс financials.drop_duplicates(keep = ‘last’, subset = [‘month’], ignore_index = True, inplace = True) financials |
Неверные значения
Распространенным типом ошибок в данных являются неверные значения.
Базовый подход к поиску неверных значений — проверить, что данные не противоречат своей природе. Например, цена товара не может быть отрицательной.
В нашем случае мы видим, что в столбце MoM все строки отражают доли процента, а последняя строка — проценты. Из-за этого сильно искажается, например, средний показатель изменения выручки за год.
|
# рассчитаем среднемесячный рост financials.MoM.mean() |
С учетом имеющихся данных вряд ли среднее изменение выручки (в месячном, а не годовом выражении) составило 17,3%. Заменим проценты на доли процента.
|
# заменим 2% на 0.02 financials.iloc[11, 2] = 0.02 |
Вновь рассчитаем средний показатель.
Новое среднее значение 0,8% выглядит гораздо реалистичнее.
Форматирование значений
Тип str вместо float
Попробуем сложить данные о прибыли.
|
‘1.20$1.30$1.25$1.27$1.13$1.23$1.20$1.31$1.24$1.18$1.17$1.23$’ |
Так как столбец profit содержит тип str, произошло объединение (concatenation) строк. Преобразуем данные о прибыли в тип float.
|
# вначале удалим знак доллара с помощью метода .strip() financials[‘profit’] = financials[‘profit’].str.strip(‘$’) # затем воспользуемся знакомым нам методом .astype() financials[‘profit’] = financials[‘profit’].astype(‘float’) |
Проверим полученный результат с помощью нового для нас ключевого слова assert (по-англ. «утверждать»).
Если условие идущее после assert возвращает True, программа продолжает исполняться. В противном случае Питон выдает AssertionError.
Приведем пример.
|
# напишем простейшую функцию деления одного числа на другое def division(a, b): # если делитель равен нулю, Питон выдаст ошибку (текст ошибки указывать не обязательно) assert b != 0 , ‘На ноль делить нельзя’ return round(a / b, 2) |
|
# попробуем разделить 5 на 0 division(5, 0) |

Выражение
b != 0 превратилось в False и Питон выдал ошибку. Теперь вернемся к нашему коду.
|
# проверим превратился ли тип данных во float assert financials.profit.dtype == float |
Сообщения об ошибке не появилось, значит выражение верное (True). Теперь снова рассчитаем прибыль за год.
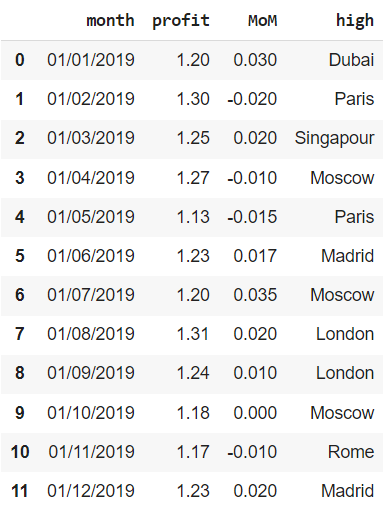
Названия городов с заглавной буквы
Остается сделать так, чтобы названия всех городов в столбце high начинались с заглавной буквы. Для этого подойдет метод .title().
|
financials[‘high’] = financials[‘high’].str.title() financials |
Дата и время
Как мы уже знаем, с датой и временем гораздо удобнее работать, когда они представляют собой объект datetime. В этом случае мы можем использовать все возможности Питона по анализу и прогнозированию временных рядов.
Начнем с того, что воспользуемся функцией pd.to_datetime(), которой передадим столбец month и формат, которого следует придерживаться при создании объекта datetime.
|
# запишем дату в формате datetime в столбец date1 financials[‘date1’] = pd.to_datetime(financials[‘month’], format = ‘%d/%m/%Y’) financials |

Мы получили верный результат. Как и должно быть в Pandas на первом месте в столбце date1 стоит год, затем месяц и наконец день. Теперь давайте попросим Питон самостоятельно определить формат даты.
|
# для этого подойдет параметр infer_datetime_format = True financials[‘date2’] = pd.to_datetime(financials[‘month’], infer_datetime_format = True) financials |

У нас снова получилось создать объект datetime, однако возникла одна сложность. Функция pd.to_datetime() предположила, что в столбце month данные содержатся в американском формате (месяц/день/год), тогда как у нас они записаны в европейском (день/месяц/год). Из-за этого в столбце date2 мы получили первые 12 дней января, а не 12 месяцев 2019 года.
|
# исправить неточность с месяцем можно с помощью параметра dayfirst = True financials[‘date3’] = pd.to_datetime(financials[‘month’], infer_datetime_format = True, dayfirst = True) financials |

Теперь мы снова получили верный формат.
|
# убедимся, что столбцы с датами имеют тип данных datetime financials.dtypes |
|
month object profit float64 MoM float64 high object date1 datetime64[ns] date2 datetime64[ns] date3 datetime64[ns] dtype: object |
Удалим избыточные столбцы и сделаем дату индексом.
|
financials.set_index(‘date3’, drop = True, inplace = True) # drop = True удаляет столбец date3 financials.drop(labels = [‘month’, ‘date1’, ‘date2’], axis = 1, inplace = True) financials.index.rename(‘month’, inplace = True) financials |
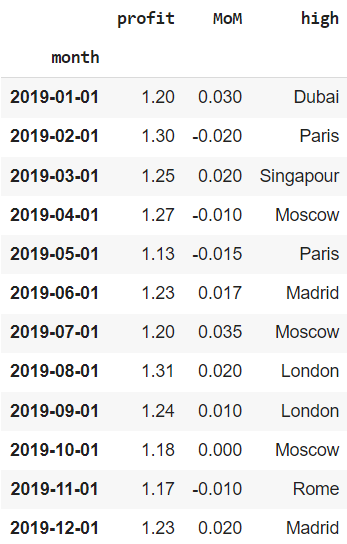
Посмотрим на еще один интересный инструмент. Предположим, что мы ошиблись с годом (вместо 2019 у нас на самом деле данные за 2020 год) или просто хотим создать индекс с датой с нуля. Для таких случаев подойдет функция pd.data_range().
|
# создадим последовательность из 12 месяцев, # передав начальный период (start), общее количество периодов (periods) # и день начала каждого периода (MS, т.е. month start) range = pd.date_range(start = ‘1/1/2020’, periods = 12, freq = ‘MS’) # сделаем эту последовательность индексом датафрейма financials.index = range financials |
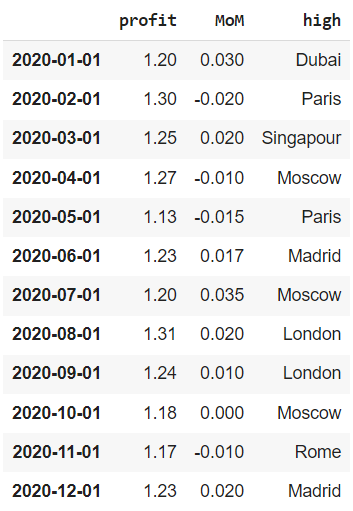
Как мы уже знаем, когда индекс имеет тип данных datetime, мы можем делать срезы по датам.
|
# напоминаю, что для datetime конечная дата входит в срез financials[‘2020-01’: ‘2020-06’] |

Завершим раздел про дату и время построением двух подграфиков. Для этого вначале преобразуем индекс из объекта datetime обратно в строковый формат с помощью метода .strftime().
|
# будем выводить только месяцы (%B), так как все показатели у нас за 2020 год financials.index = financials.index.strftime(‘%B’) financials |

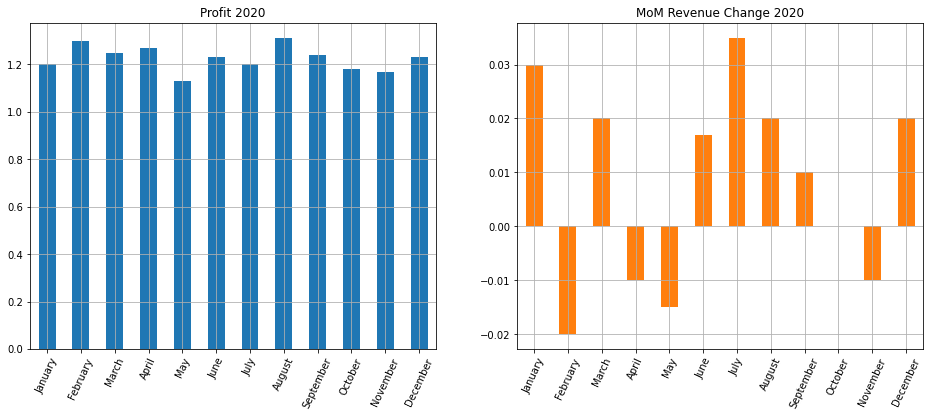
Теперь используем метод .plot() библиотеки Pandas с параметром subplots = True.
|
# построим графики для размера прибыли и изменения выручки за месяц financials[[‘profit’, ‘MoM’]].plot(subplots = True, # обозначим, что хотим несколько подграфиков layout = (1,2), # зададим сетку kind = ‘bar’, # укажем тип диаграммы rot = 65, # повернем деления шкалы оси x grid = True, # добавим сетку figsize = (16, 6), # укажем размер figure legend = False, # уберем легенду title = [‘Profit 2020’, ‘MoM Revenue Change 2020’]); # добавим заголовки |
Подведем итог
Сегодня мы рассмотрели типичные ошибки в данных и способы их исправления. В частности, мы изучили как выявить и удалить дубликаты, обнаружить неверные значения и скорректировать неподходящий формат. Кроме того, мы еще раз обратились к объекту datetime и посмотрели на возможности изменения даты и времени.
Перейдем к работе с пропущенными значениями.
Содержание
Составили подробный классификатор кодов состояния HTTP. Добавляйте в закладки, чтобы был под рукой, когда понадобится.
Что такое код ответа HTTP
Когда посетитель переходит по ссылке на сайт или вбивает её в поисковую строку вручную, отправляется запрос на сервер. Сервер обрабатывает этот запрос и выдаёт ответ — трехзначный цифровой код HTTP от 100 до 510. По коду ответа можно понять реакцию сервера на запрос.
Первая цифра в ответе обозначает класс состояния, другие две — причину, по которой мог появиться такой ответ.
Как проверить код состояния страницы
Проверить коды ответа сервера можно вручную с помощью браузера и в панелях веб‑мастеров: Яндекс.Вебмастер и Google Search Console.
В браузере
Для примера возьмём Google Chrome.
-
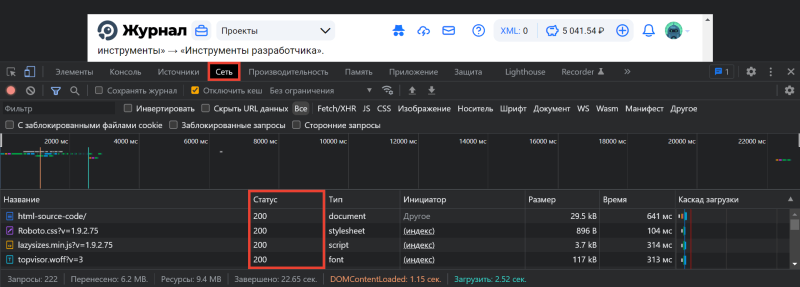
Откройте панель разработчика в браузере клавишей F12, комбинацией клавиш Ctrl + Shift + I или в меню браузера → «Дополнительные инструменты» → «Инструменты разработчика». Подробнее об этом рассказывали в статье «Как открыть исходный код страницы».
-
Переключитесь на вкладку «Сеть» в Инструментах разработчика и обновите страницу:
В Яндекс.Вебмастере
Откройте инструмент «Проверка ответа сервера» в Вебмастере. Введите URL в специальное поле и нажмите кнопку «Проверить»:
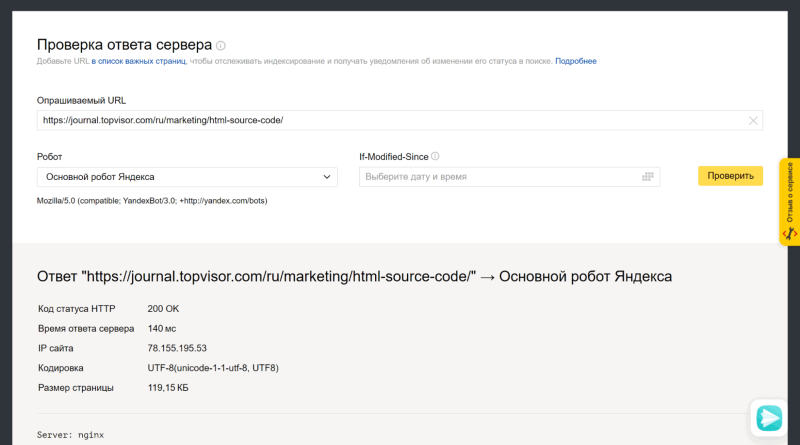
Как добавить сайт в Яндекс.Вебмастер и другие сервисы Яндекса
В Google Search Console
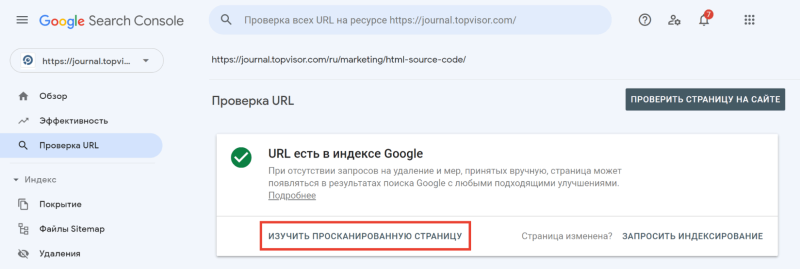
Чтобы посмотреть код ответа сервера в GSC, перейдите в инструмент проверки URL — он находится в самом верху панели:

Введите ссылку на страницу, которую хотите проверить, и нажмите Enter. В результатах проверки нажмите на «Изучить просканированную страницу» в блоке «URL есть в индексе Google».
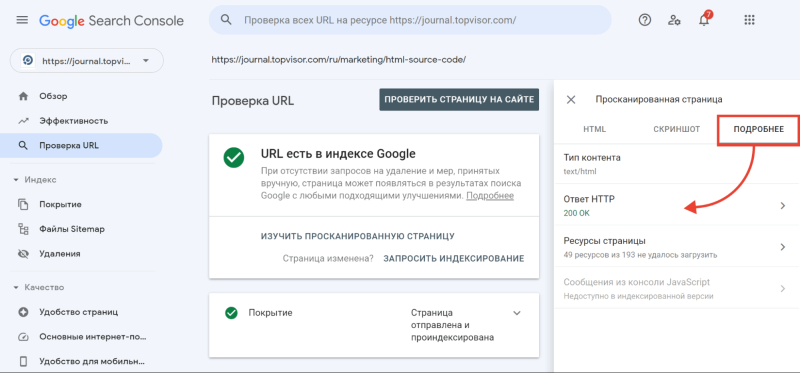
А затем в открывшемся окне перейдите на вкладку «Подробнее»:
Теперь расскажем подробнее про все классы кодов состояния HTTP.
1* класс кодов (информационные сообщения)
Это системный класс кодов, который только информирует о процессе передачи запроса. Такие ответы не являются ошибкой, хотя и могут отображаться в браузере как Error Code.
100 Continue
Этот ответ сообщает, что полученные сведения о запросе устраивают сервер и клиент может продолжать отправлять данные. Такой ответ может требоваться клиенту, если на сервер отправляется большой объём данных.
101 Switching Protocols
Сервер одобрил переключение типа протокола, которое запросил пользователь, и в настоящий момент выполняет действие.
102 Processing
Запрос принят — он находится в обработке, и на это понадобится чуть больше времени.
103 Checkpoint
Контрольная точка — используется в запросах для возобновления после прерывания запросов POST или PUT.
POST отправляет данные на сервер, PUT создает новый ресурс или заменяет существующий данными, представленными в теле запроса.
Разница между ними в том, что PUT работает без изменений: повторное его применение даёт такой же результат, что и в первый раз, а вот повторный вызов одного и того же метода POST часто меняет данные.
Пример — оформленный несколько раз интернет‑заказ. Такое часто происходит как раз по причине неоднократного использования запроса PUT.
105 Name Not Resolved
Не удается преобразовать DNS‑адрес сервера — это означает ошибку в службе DNS. Эта служба преобразует IP‑адреса в знакомые нам доменные имена.
2* класс кодов (успешно обработанные запросы)
Эти коды информируют об успешности принятия и обработки запроса. Также сервер может передать заголовки или тело сообщений.
200 ОК
Все хорошо — HTTP‑запрос успешно обработан (не ошибка).
201 Created
Создано — транзакция успешна, сформирован новый ресурс или документ.
202 Accepted
Принято — запрос принят, но ещё не обработан.
203 Non‑Authoritative Information
Информация не авторитетна — запрос успешно обработан, но передаваемая информация была взята не из первичного источника (данные могут быть устаревшими).
204 No Content
Нет содержимого — запрос успешно обработан, однако в ответе только заголовки без контента сообщения. Не нужно обновлять содержимое документа, но можно применить к нему полученные метаданные.
205 Reset Content
Сбросить содержимое. Запрос успешно обработан — но нужно сбросить введенные данные. Страницу можно не обновлять.
206 Partial Content
Частичное содержимое. Сервер успешно обработал часть GET‑запроса, а другую часть вернул.
GET — метод для чтения данных с сайта. Он говорит серверу, что клиент хочет прочитать какой‑то документ.
Представим интернет‑магазин и страницы каталога. Фильтры, которые выбирает пользователь, передаются благодаря методу GET. GET‑запрос работает с получением данных, а POST‑запрос нужен для отправки данных.
При работе с подобными ответами следует уделить внимание кэшированию.
207 Multi‑Status
Успешно выполнено несколько операций — сервер передал результаты выполнения нескольких независимых операций. Они появятся в виде XML‑документа с объектом multistatus.
226 IM Used
Успешно обработан IM‑заголовок (специальный заголовок, который отправляется клиентом и используется для передачи состояния HTTP).
3* класс кодов (перенаправление на другой адрес)
Эти коды информируют, что для достижения успешной операции нужно будет сделать другой запрос, возможно, по другому URL.
300 Multiple Choices
Множественный выбор — сервер выдает список нескольких возможных вариантов перенаправления (максимум — 5). Можно выбрать один из них.
301 Moved Permanently
Окончательно перемещено — страница перемещена на другой URL, который указан в поле Location.
302 Found/Moved
Временно перемещено — страница временно перенесена на другой URL, который указан в поле Location.
303 See Other
Ищите другую страницу — страница не найдена по данному URL, поэтому смотрите страницу по другому URL, используя метод GET.
304 Not Modified
Модификаций не было — с момента последнего визита клиента изменений не было.
305 Use Proxy
Используйте прокси — запрос к нужному ресурсу можно сделать только через прокси‑сервер, URL которого указан в поле Location заголовка.
306 Unused
Зарезервировано. Код в настоящий момент не используется.
307 Temporary Redirect
Временное перенаправление — запрашиваемый ресурс временно доступен по другому URL.
Этот код имеет ту же семантику, что код ответа 302 Found, за исключением того, что агент пользователя не должен изменять используемый метод HTTP: если в первом запросе использовался POST, то во втором запросе также должен использоваться POST.
308 Resume Incomplete
Перемещено полностью (навсегда) — запрашиваемая страница была перенесена на новый URL, указанный в поле Location заголовка. Метод запроса (GET/POST) менять не разрешается.
4* класс кодов (ошибки на стороне клиента)
Эти коды указывают на ошибки со стороны клиентов.
400 Bad Request
Неверный запрос — запрос клиента не может быть обработан, так как есть синтаксическая ошибка (возможно, опечатка).
401 Unauthorized
Не пройдена авторизация — запрос ещё в обработке, но доступа нет, так как пользователь не авторизован.
Для доступа к запрашиваемому ресурсу клиент должен представиться, послав запрос, включив при этом в заголовок сообщения поле Authorization.
402 Payment Required
Требуется оплата — зарезервировано для использования в будущем. Код предусмотрен для платных пользовательских сервисов, а не для хостинговых компаний.
403 Forbidden
Запрещено — запрос принят, но не будет обработан, так как у клиента недостаточно прав. Может возникнуть, когда пользователь хочет открыть системные файлы (robots, htaccess) или не прошёл авторизацию.
404 Not Found
Не найдено — запрашиваемая страница не обнаружена. Сервер принял запрос, но не нашёл ресурса по указанному URL (возможно, была ошибка в URL или страница была перемещена).
405 Method Not Allowed
Метод не разрешён — запрос был сделан методом, который не поддерживается данным ресурсом. Сервер должен предложить доступные методы решения в заголовке Allow.
406 Not Acceptable
Некорректный запрос — неподдерживаемый поисковиком формат запроса (поисковый робот не поддерживает кодировку или язык).
407 Proxy Authentication Required
Нужно пройти аутентификацию прокси — ответ аналогичен коду 401, только нужно аутентифицировать прокси‑сервер.
408 Request Timeout
Тайм‑аут запроса — запрос клиента занял слишком много времени. На каждом сайте существует свое время тайм‑аута — проверьте интернет‑соединение и просто обновите страницу.
409 Conflict
Конфликт (что‑то пошло не так) — запрос не может быть выполнен из‑за конфликтного обращения к ресурсу (несовместимость двух запросов).
410 Gone
Недоступно — ресурс раньше был размещён по указанному URL, но сейчас удалён и недоступен (серверу неизвестно месторасположение).
411 Length Required
Добавьте длины — сервер отклоняет отправляемый запрос, так как длина заголовка не определена, и он не находит значение Content‑Length.
Нужно исправить заголовки на сервере, и в следующий раз робот сможет проиндексировать страницу.
412 Precondition Failed
Предварительное условие не выполнено — стоит проверить правильность HTTP‑заголовков данного запроса.
413 Request Entity Too Large
Превышен размер запроса — перелимит максимального размера запроса, принимаемого сервером. Браузеры поддерживают запросы от 2 до 8 килобайт.
414 Request‑URI Too Long
Превышена длина запроса — сервер не может обработать запрос из‑за длинного URL. Такая ошибка может возникнуть, например, когда клиент пытается передать чересчур длинные параметры через метод GET, а не POST.
415 Unsupported Media Type
Формат не поддерживается — сервер не может принять запрос, так как данные подгружаются в некорректном формате, и сервер разрывает соединение.
416 Requested Range Not Satisfiable
Диапазон не поддерживается — ошибка возникает в случаях, когда в самом HTTP‑заголовке прописывается некорректный байтовый диапазон.
Корректного диапазона в необходимом документе может просто не быть, или есть опечатка в синтаксисе.
417 Expectation Failed
Ожидания не оправдались — прокси некорректно идентифицировал содержимое поля «Expect: 100‑Continue».
418 I’m a teapot
Первоапрельская шутка разработчиков в 1998 году. В расшифровке звучит как «я не приготовлю вам кофе, потому что я чайник». Не используется в работе.
422 Unprocessable Entity
Объект не обработан — сервер принял запрос, но в нём есть логическая ошибка. Стоит посмотреть в сторону семантики сайта.
423 Locked
Закрыто — ресурс заблокирован для выбранного HTTP‑метода. Можно перезагрузить роутер и компьютер. А также использовать только статистический IP.
424 Failed Dependency
Неуспешная зависимость — сервер не может обработать запрос, так как один из зависимых ресурсов заблокирован.
Выполнение запроса напрямую зависит от успешности выполнения другой операции, и если она не будет успешно завершена, то вся обработка запроса будет прервана.
425 Unordered Collection
Неверный порядок в коллекции — ошибка возникает, если клиент указал номер элемента в неупорядоченном списке или запросил несколько элементов в порядке, отличном от серверного.
426 Upgrade Required
Нужно обновление — в заголовке ответа нужно корректно сформировать поля Upgrade и Connection.
Этот ответ возникает, когда серверу требуется обновление до SSL‑протокола, но клиент не имеет его поддержки.
428 Precondition Required
Нужно предварительное условие — сервер просит внести в запрос информацию о предварительных условиях обработки данных, чтобы выдавать корректную информацию по итогу.
429 Too Many Requests
Слишком много запросов — отправлено слишком много запросов за короткое время. Это может указывать, например, на попытку DDoS‑атаки, для защиты от которой запросы блокируются.
431 Request Header Fields Too Large
Превышена длина заголовков — сервер может и не отвечать этим кодом, вместо этого он может просто сбросить соединение.
Исправляется это с помощью сокращения заголовков и повторной отправки запроса.
434 Requested Host Unavailable
Адрес запрашиваемой страницы недоступен.
444 No Response
Нет ответа — код отображается в лог‑файлах, чтобы подтвердить, что сервер никак не отреагировал на запрос пользователя и прервал соединение. Возвращается только сервером nginx.
Nginx — программное обеспечение с открытым исходным кодом. Его используют для создания веб‑серверов, а также в качестве почтового или обратного прокси‑сервера. Nginx решает проблему падения производительности из‑за роста трафика.
449 Retry With
Повторите попытку — ошибка говорит о необходимости скорректировать запрос и повторить его снова. Причиной становятся неверно указанные параметры (возможно, недостаточно данных).
450 Blocked by Windows Parental Controls
Заблокировано родительским контролем — говорит о том, что с компьютера попытались зайти на заблокированный ресурс. Избежать этой ошибки можно изменением параметров системы родительского контроля.
451 Unavailable For Legal Reasons
Недоступно по юридическим причинам — доступ к ресурсу закрыт, например, по требованию органов государственной власти или по требованию правообладателя в случае нарушения авторских прав.
456 Unrecoverable Error
Неустранимая ошибка — при обработке запроса возникла ошибка, которая вызывает некорректируемые сбои в таблицах баз данных.
499 Client Closed Request
Запрос закрыт клиентом — нестандартный код, используемый nginx в ситуациях, когда клиент закрыл соединение, пока nginx обрабатывал запрос.
5* класс кодов (ошибки на стороне сервера)
Эти коды указывают на ошибки со стороны серверов.
При использовании всех методов, кроме HEAD, сервер должен вернуть в теле сообщения гипертекстовое пояснение для пользователя. И его можно использовать в работе.
500 Internal Server Error
Внутренняя ошибка сервера — сервер столкнулся с неким условием, из‑за которого не может выполнить запрос.
Проверяйте, корректно ли указаны директивы в системных файлах (особенно htaccess) и нет ли ошибки прав доступа к файлам. Обратите внимание на ошибки внутри скриптов и их медленную работу.
501 Not Implemented
Не выполнено — код отдается, когда сам сервер не может идентифицировать метод запроса.
Сами вы эту ошибку не исправите. Устранить её может только сервер.
502 Bad Gateway
Ошибка шлюза — появляется, когда сервер, выступая в роли шлюза или прокси‑сервера, получил ответное сообщение от вышестоящего сервера о несоответствии протоколов.
Актуально исключительно для прокси и шлюзовых конфигураций.
503 Service Unavailable
Временно не доступен — сервер временно не имеет возможности обрабатывать запросы по техническим причинам (обслуживание, перегрузка и прочее).
В поле Retry‑After заголовка сервер укажет время, через которое можно повторить запрос.
504 Gateway Timeout
Тайм‑аут шлюза — сервер, выступая в роли шлюза или прокси‑сервера, не получил ответа от вышестоящего сервера в нужное время.
Исправить эту ошибку самостоятельно не получится. Здесь дело в прокси, часто — в веб‑сервере.
Первым делом просто обновите веб‑страницу. Если это не помогло, нужно почистить DNS‑кэш. Для этого нажмите горячие клавиши Windows+R и введите команду cmd (Control+пробел). В открывшемся окне укажите команду ipconfig / flushdns и подтвердите её нажатием Enter.
505 HTTP Version Not Supported
Сервер не поддерживает версию протокола — отсутствует поддержка текущей версии HTTP‑протокола. Нужно обеспечить клиента и сервер одинаковой версией.
506 Variant Also Negotiates
Неуспешные переговоры — с такой ошибкой сталкиваются, если сервер изначально настроен неправильно. По причине ошибочной конфигурации выбранный вариант указывает сам на себя, из‑за чего процесс и прерывается.
507 Insufficient Storage
Не хватает места для хранения — серверу недостаточно места в хранилище. Нужно либо расчистить место, либо увеличить доступное пространство.
508 Loop Detected
Обнаружен цикл — ошибка означает провал запроса и выполняемой операции в целом.
509 Bandwidth Limit Exceeded
Превышена пропускная способность — используется при чрезмерном потреблении трафика. Владельцу площадки следует обратиться к своему хостинг‑провайдеру.
510 Not Extended
Не продлён — ошибка говорит, что на сервере отсутствует нужное для клиента расширение. Чтобы исправить проблему, надо убрать часть неподдерживаемого расширения из запроса или добавить поддержку на сервер.
511 Network Authentication Required
Требуется аутентификация — ошибка генерируется сервером‑посредником, к примеру, сервером интернет‑провайдера, если нужно ввести пароль для получения доступа к сети через платную точку доступа.
Расшифровка 55 состояний прикладного протокола HTTP (протокол передачи гипертекста): от информационных сообщений до ошибок.
Во время запроса информации с удаленного веб-сервера может возникнуть ошибка. Тогда веб-сервер посылает в ответ код ошибки HTTP. Например 404 — Not Found (ресурс не найден).
Коды состояния HTTP состоят из трех цифр от 100 и до 510. Они делятся на следующие группы:
- Информационные (100-105).
- Успешные (200-226).
- Перенаправление (300-307).
- Ошибка клиента (400-499).
- Ошибка сервера (500-510).
Чтобы получить сведения об ошибке, введите её код в поле поиска по странице. Для этого нажмите сочетание клавиш CTRL + F и укажите номер.
100
Continue
Cервер удовлетворён начальными сведениями о запросе, клиент может продолжать пересылать заголовки. Появился в HTTP/1.1.
101
Switching Protocols
Сервер предлагает перейти на более подходящий для указанного ресурса протокол; список предлагаемых протоколов сервер обязательно указывает в поле заголовкаUpdate. Если клиента это заинтересует, то он посылает новый запрос с указанием другого протокола. Появился в HTTP/1.1.
102
Processing
Запрос принят, но на его обработку понадобится длительное время. Используется сервером, чтобы клиент не разорвал соединение из-за превышения времени ожидания. Клиент при получении такого ответа должен сбросить таймер и дожидаться следующей команды в обычном режиме. Появился в WebDAV.
200
ОК
Успешный запрос. Если клиентом были запрошены какие-либо данные, то они находятся в заголовке и/или теле сообщения. Появился в HTTP/1.0.
201
Created
В результате успешного выполнения запроса был создан новый ресурс. Сервер должен указать его местоположение в заголовке Location. Серверу рекомендуется[источник не указан 336 дней] ещё указывать в заголовке характеристики созданного ресурса (например, в поле Content-Type). Если сервер не уверен, что ресурс действительно будет существовать к моменту получения данного сообщения клиентом, то лучше использовать ответ с кодом 202. Появился в HTTP/1.0.
202
Accepted
Запрос был принят на обработку, но она не завершена. Клиенту не обязательно дожидаться окончательной передачи сообщения, так как может быть начат очень долгий процесс. Появился в HTTP/1.0.
203
Non-Authoritative Information
Аналогично ответу 200, но в этом случае передаваемая информация была взята не из первичного источника (резервной копии, другого сервера и т. д.) и поэтому может быть неактуальной. Появился в HTTP/1.1.
204
No Content
Сервер успешно обработал запрос, но в ответе были переданы только заголовки без тела сообщения. Клиент не должен обновлять содержимое документа, но может применить к нему полученные метаданные. Появился в HTTP/1.0.
205
Reset Content
Сервер обязывает клиента сбросить введённые пользователем данные. Тела сообщения сервер при этом не передаёт и документ обновлять не обязательно. Появился в HTTP/1.1.
206
Partial Content
Сервер удачно выполнил частичный GET-запрос, возвратив только часть сообщения. В заголовке Content-Range сервер указывает байтовые диапазоны содержимого. Особое внимание при работе с подобными ответами следует уделить кэшированию. Появился в HTTP/1.1. (подробнее…)
207
Multi-Status
Сервер передаёт результаты выполнения сразу нескольких независимых операций. Они помещаются в само тело сообщения в виде XML-документа с объектом multistatus. Не рекомендуется размещать в этом объекте статусы из серии 1xx из-за бессмысленности и избыточности. Появился в WebDAV.
226
IM Used
Заголовок A-IM от клиента был успешно принят и сервер возвращает содержимое с учётом указанных параметров. Введено в RFC 3229 для дополнения протокола HTTP поддержкой дельта-кодирования.
300
Multiple Choices
По указанному URI существует несколько вариантов предоставления ресурса по типу MIME, по языку или по другим характеристикам. Сервер передаёт с сообщением список альтернатив, давая возможность сделать выбор клиенту автоматически или пользователю. Появился в HTTP/1.0.
301
Moved Permanently
Запрошенный документ был окончательно перенесен на новый URI, указанный в поле Location заголовка. Некоторые клиенты некорректно ведут себя при обработке данного кода. Появился в HTTP/1.0.
302
Found, Moved Temporarily
Запрошенный документ временно доступен по другому URI, указанному в заголовке в поле Location. Этот код может быть использован, например, приуправляемом сервером согласовании содержимого. Некоторые клиенты некорректно ведут себя при обработке данного кода. Введено в HTTP/1.0.
303
See Other
Документ по запрошенному URI нужно запросить по адресу в поле Location заголовка с использованием метода GET несмотря даже на то, что первый запрашивался иным методом. Этот код был введён вместе с 307-ым для избежания неоднозначности, чтобы сервер был уверен, что следующий ресурс будет запрошен методом GET. Например, на веб-странице есть поле ввода текста для быстрого перехода и поиска. После ввода данных браузер делает запрос методом POST, включая в тело сообщения введённый текст. Если обнаружен документ с введённым названием, то сервер отвечает кодом 303, указав в заголовке Location его постоянный адрес. Тогда браузер гарантировано его запросит методом GET для получения содержимого. В противном случае сервер просто вернёт клиенту страницу с результатами поиска. Введено в HTTP/1.1.
304
Not Modified
Сервер возвращает такой код, если клиент запросил документ методом GET, использовал заголовок If-Modified-Since или If-None-Match и документ не изменился с указанного момента. При этом сообщение сервера не должно содержать тела. Появился в HTTP/1.0.
305
Use Proxy
Запрос к запрашиваемому ресурсу должен осуществляться через прокси-сервер, URI которого указан в поле Location заголовка. Данный код ответа могут использовать только исходные HTTP-сервера (не прокси). Введено в HTTP/1.1.
306
(зарезервировано)
использовавшийся раньше код ответа, в настоящий момент зарезервирован. Упомянут в RFC 2616 (обновление HTTP/1.1).
307
Temporary Redirect
Запрашиваемый ресурс на короткое время доступен по другому URI, указанный в поле Location заголовка. Этот код был введён вместе с 303 вместо 302-го для избежания неоднозначности. Введено в RFC 2616 (обновление HTTP/1.1).
400
Bad Request
Сервер обнаружил в запросе клиента синтаксическую ошибку. Появился в HTTP/1.0.
401
Unauthorized
Для доступа к запрашиваемому ресурсу требуется аутентификация. В заголовке ответ должен содержать поле WWW-Authenticate с перечнем условий аутентификации. Клиент может повторить запрос, включив в заголовок сообщения поле Authorization с требуемыми для аутентификации данными.
402
Payment Required
Предполагается использовать в будущем. В настоящий момент не используется. Этот код предусмотрен для платных пользовательских сервисов, а не для хостинговыхкомпаний. Имеется в виду, что эта ошибка не будет выдана хостинговым провайдером в случае просроченной оплаты его услуг. Зарезервирован, начиная с HTTP/1.1.
403
Forbidden
Сервер понял запрос, но он отказывается его выполнять из-за ограничений в доступе для клиента к указанному ресурсу. Если для доступа к ресурсу требуется аутентификация средствами HTTP, то сервер вернёт ответ 401 или 407 при использовании прокси. В противном случае ограничения были заданы администратором сервера или разработчиком веб-приложения и могут быть любыми в зависимости от возможностей используемого программного обеспечения. В любом случае клиенту следует сообщить причины отказа в обработке запроса. Наиболее вероятными причинами ограничения может послужить попытка доступа к системным ресурсам веб-сервера (например, файлам .htaccess или .htpasswd) или к файлам, доступ к которым был закрыт с помощью конфигурационных файлов, требование аутентификации не средствами HTTP, например, для доступа к системе управления содержимым или разделу для зарегистрированных пользователей либо сервер не удовлетворён IP-адресом клиента, например, при блокировках. Появился в HTTP/1.0.
404
Not Found
Самая распространенная ошибка при пользовании Интернетом, основная причина — ошибка в написании адреса Web-страницы. Сервер понял запрос, но не нашёл соответствующего ресурса по указанному URI. Если серверу известно, что по этому адресу был документ, то ему желательно использовать код 410. Ответ 404 может использоваться вместо 403, если требуется тщательно скрыть от посторонних глаз определённые ресурсы. Появился в HTTP/1.0.
405
Method Not Allowed
Указанный клиентом метод нельзя применить к текущему ресурсу. В ответе сервер должен указать доступные методы в заголовке Allow, разделив их запятой. Эту ошибку сервер должен возвращать, если метод ему известен, но он не применим именно к указанному в запросе ресурсу, если же указанный метод не применим на всём сервере, то клиенту нужно вернуть код 501 (Not Implemented). Появился в HTTP/1.1.
406
Not Acceptable
Запрошенный URI не может удовлетворить переданным в заголовке характеристикам. Если метод был не HEAD, то сервер должен вернуть список допустимых характеристик для данного ресурса. Появился в HTTP/1.1.
407
Proxy Authentication Required
Ответ аналогичен коду 401 за исключением того, что аутентификация производится для прокси-сервера. Механизм аналогичен идентификации на исходном сервере. Появился в HTTP/1.1.
408
Request Timeout
Время ожидания сервером передачи от клиента истекло. Клиент может повторить аналогичный предыдущему запрос в любое время. Например, такая ситуация может возникнуть при загрузке на сервер объёмного файла методом POST или PUT. В какой-то момент передачи источник данных перестал отвечать, например, из-за повреждения компакт-диска или потеря связи с другим компьютером в локальной сети. Пока клиент ничего не передаёт, ожидая от него ответа, соединение с сервером держится. Через некоторое время сервер может закрыть соединение со своей стороны, чтобы дать возможность другим клиентам сделать запрос. Этот ответ не возвращается, когда клиент принудительно остановил передачу по команде пользователя или соединение прервалось по каким-то иным причинам, так как ответ уже послать невозможно. Появился в HTTP/1.1.
409
Conflict
Запрос не может быть выполнен из-за конфликтного обращения к ресурсу. Такое возможно, например, когда два клиента пытаются изменить ресурс с помощью метода PUT.Появился в HTTP/1.1.
410
Gone
Такой ответ сервер посылает, если ресурс раньше был по указанному URL, но был удалён и теперь недоступен. Серверу в этом случае неизвестно и местоположение альтернативного документа, например, копии). Если у сервера есть подозрение, что документ в ближайшее время может быть восстановлен, то лучше клиенту передать код 404. Появился в HTTP/1.1.
411
Length Required
Для указанного ресурса клиент должен указать Content-Length в заголовке запроса. Без указания этого поля не стоит делать повторную попытку запроса к серверу по данному URI. Такой ответ естественен для запросов типа POST и PUT. Например, если по указанному URI производится загрузка файлов, а на сервере стоит ограничение на их объём. Тогда разумней будет проверить в самом начале заголовок Content-Length и сразу отказать в загрузке, чем провоцировать бессмысленную нагрузку, разрывая соединение, когда клиент действительно пришлёт слишком объёмное сообщение. Появился в HTTP/1.1.
412
Precondition Failed
Возвращается, если ни одно из условных полей заголовка[неизвестный термин] запроса не было выполнено. Появился в HTTP/1.1.
413
Request Entity Too Large
Возвращается в случае, если сервер отказывается обработать запрос по причине слишком большого размера тела запроса. Сервер может закрыть соединение, чтобы прекратить дальнейшую передачу запроса. Если проблема временная, то рекомендуется в ответ сервера включить заголовок Retry-After с указанием времени, по истечении которого можно повторить аналогичный запрос. Появился в HTTP/1.1.
414
Request-URL Too Long
Сервер не может обработать запрос из-за слишком длинного указанного URL. Такую ошибку можно спровоцировать, например, когда клиент пытается передать длинные параметры через метод GET, а не POST. Появился в HTTP/1.1.
415
Unsupported Media Type
По каким-то причинам сервер отказывается работать с указанным типом данных при данном методе. Появился в HTTP/1.1.
416
Requested Range Not Satisfiabl
В поле Range заголовка запроса был указан диапазон за пределами ресурса и отсутствует поле If-Range. Если клиент передал байтовый диапазон, то сервер может вернуть реальный размер в поле Content-Range заголовка. Данный ответ не следует использовать при передаче типа multipart/byteranges[источник не указан 336 дней]. Введено в RFC 2616 (обновление HTTP/1.1).
417
Expectation Failed
По каким-то причинам сервер не может удовлетворить значению поля Expect заголовка запроса. Введено в RFC 2616 (обновление HTTP/1.1).
422
Unprocessable Entity
Сервер успешно принял запрос, может работать с указанным видом данных, в теле запроса XML-документ имеет верный синтаксис, но имеется какая-то логическая ошибка, из-за которой невозможно произвести операцию над ресурсом. Введено в WebDAV.
423
Locked
Целевой ресурс из запроса заблокирован от применения к нему указанного метода. Введено в WebDAV.
424
Failed Dependency
Реализация текущего запроса может зависеть от успешности выполнения другой операции. Если она не выполнена и из-за этого нельзя выполнить текущий запрос, то сервер вернёт этот код. Введено в WebDAV.
425
Unordered Collection —
Посылается, если клиент послал запрос, обозначив положение в неотсортированной коллекции или используя порядок следования элементов, отличный от серверного[уточнить]. Введено в черновике по WebDAV Advanced Collections Protocol[14].
426
Upgrade Required
Сервер указывает клиенту на необходимость обновить протокол. Заголовок ответа должен содержать правильно сформированные поля Upgrade и Connection. Введено вRFC 2817 для возможности перехода к TLS посредством HTTP.
449
Retry With
Возвращается сервером, если для обработки запроса от клиента поступило недостаточно информации. При этом в заголовок ответа помещается поле Ms-Echo-Request. Введено корпорацией Microsoft для WebDAV. В настоящий момент как минимум используется программой Microsoft Money.
456
Unrecoverable Error
Возвращается сервером, если обработка запроса вызывает некорректируемые сбои в таблицах баз данных[источник не указан 336 дней]. Введено корпорацией Microsoftдля WebDAV.
500
Internal Server Error
Любая внутренняя ошибка сервера, которая не входит в рамки остальных ошибок класса. Появился в HTTP/1.0.
501
Not Implemented
Сервер не поддерживает возможностей, необходимых для обработки запроса. Типичный ответ для случаев, когда сервер не понимает указанный в запросе метод. Если же метод серверу известен, но он не применим к данному ресурсу, то нужно вернуть ответ 405. Появился в HTTP/1.0.
502
Bad Gateway
Сервер, выступая в роли шлюза или прокси-сервера, получил недействительное ответное сообщение от вышестоящего сервера. Появился в HTTP/1.0.
503
Service Unavailable
Сервер временно не имеет возможности обрабатывать запросы по техническим причинам (обслуживание, перегрузка и прочее). В поле Retry-After заголовка сервер может указать время, через которое клиенту рекомендуется повторить запрос. Хотя во время перегрузки очевидным кажется сразу разрывать соединение, эффективней может оказаться установка большого значения поля Retry-After для уменьшения частоты избыточных запросов. Появился в HTTP/1.0.
504
Gateway Timeout
Сервер в роли шлюза или прокси-сервера не дождался ответа от вышестоящего сервера для завершения текущего запроса. Появился в HTTP/1.1.
505
HTTP Version Not Supported
Сервер не поддерживает или отказывается поддерживать указанную в запросе версию протокола HTTP. Появился в HTTP/1.1.
506
Variant Also Negotiates
В результате ошибочной конфигурации выбранный вариант указывает сам на себя, из-за чего процесс связывания прерывается. Экспериментальное. Введено в RFC 2295 для дополнения протокола HTTP технологией Transparent Content Negotiation.
507
Insufficient Storage
Не хватает места для выполнения текущего запроса. Проблема может быть временной. Введено в WebDAV.
509
Bandwidth Limit Exceeded
Используется при превышении веб-площадкой отведённого ей ограничения на потребление трафика. В данном случае владельцу площадки следует обратиться к своему хостинг-провайдеру. В настоящий момент данный код не описан ни в одном RFC и используется только модулем «bw/limited», входящим в панель управления хостингом cPanel, где и был введён.
510
Not Extended
На сервере отсутствует расширение, которое желает использовать клиент. Сервер может дополнительно передать информацию о доступных ему расширениях. Введено в RFC 2774 для дополнения протокола HTTP поддержкой расширений.
В прошлом посте я поведала историю о том, как иногда бывает: все работает по ТЗ, но в прод выводить нельзя!
Если вкратце — в интернет-магазине сделали возможность видеть в профиле участника все его отзывы к товарам. Надеялись, что принесет добро, а участники пошли выискивать компромат на «неугодных». Функционал убрали, стали дорабатывать (видимо).
Добавили возможность указать видимость отзыва во время его написания:
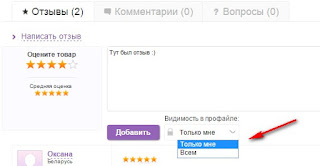
Теперь можно выбирать, будет ли отзыв виден
А сегодня зашла на форум и увидела такую фразу: «Сейчас видимость своего профайла Пользователь может выбрать в Личном Кабинете самостоятельно».
Мне же любопытно, я пошла искать ![]()
Зашла в свои отзывы и увидела большую кнопку изменения видимости.

Теперь можно выбирать, будет ли отзыв виден
А сегодня зашла на форум и увидела такую фразу: «Сейчас видимость своего профайла Пользователь может выбрать в Личном Кабинете самостоятельно».
Мне же любопытно, я пошла искать ![]()
Зашла в свои отзывы и увидела большую кнопку изменения видимости.
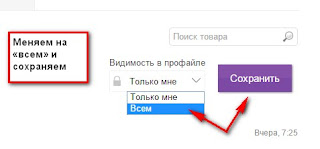
Попробуем, попробуем…
Поменяла на «всем» и попробовала сохранить
Вылезло чудное сообщение «а вы уверены…?»
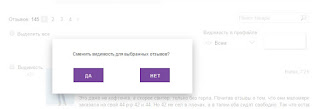
Вылезло чудное сообщение «а вы уверены…?»
Раскина на них нет! Винда же научила — видишь такое ужасное сообщение, раздражайся и кликай «ДА!», даже если успел передумать. Подтверждаем свои действия и…

Увы и ах. Некая ошибка входных данных. И думай, что хочешь. Как пользователю понять из такого текста, в чем он ошибся?
См также:
Сообщения об ошибках — тоже документация, тестируйте их!
Давайте заведем это как баг! Прежде чем скакать заводить, надо локализовать и выяснить точные шаги воспроизведения. Оказывается, это не такая кнопка, которая меняет сразу и все. Слева от отзывов стоят чек-боксы выбора. Нужно отметить нужные и изменять видимость им:

Увы и ах. Некая ошибка входных данных. И думай, что хочешь. Как пользователю понять из такого текста, в чем он ошибся?
См также:
Сообщения об ошибках — тоже документация, тестируйте их!
Давайте заведем это как баг! Прежде чем скакать заводить, надо локализовать и выяснить точные шаги воспроизведения. Оказывается, это не такая кнопка, которая меняет сразу и все. Слева от отзывов стоят чек-боксы выбора. Нужно отметить нужные и изменять видимость им:
Так еще выбирать надо было!
Попробуем. Выделяем чек-бокс, меняем видимость — ошибки нет. Ничего не выбираем — ошибка есть. То есть фейл на простейшем граничном условии. Ноль и пустоту проверять стоит всегда ![]()
Оформляем по шаблону:
****************************************************************
«Ошибка входных данных» при смене видимости у 0 отзывов
Шаги для воспроизведения
- Войти в личный кабинет, «Мои отзывы» — https://lk.wildberries.ru/discussion/feedback (тут были тестовые данные для входа)
- Нажать «Сохранить» у блока «Видимость в профайле», ничего не выбрав, см рис «1. Сохранение».
- Подтвердить действие.
Результат
См рис «2. Ошибка» — появляется сообщение «Ошибка входных данных».
Ожидаемый результат
Текст должен пояснять пользователю, что он должен сделать для исправления ситуации. Например: «Ни один отзыв не выбран. Сменить видимость для всех?» и при выборе «да» система меняет видимость у всех отзывов, не заставляя пользователя выполнять дополнительные действия.
Также желательно не допустить такую ситуацию в принципе. Для этого можно:
— По умолчанию изменять видимость для всего (галка «Выбрать все» по-умолчанию, но ее можно снять)
— Подписать под кнопкой «Выберите отзывы, для которых хотите изменить видимость. По-умолчанию меняется для всех».
Это сильно лучше, чем дополнительный pop-up с текстом об ошибке
****************************************************************
Еще тут стоит поставить улучшение на то, чтобы убрать шаг 3 из описания бага, убрать это сообщение об ошибке. Будет вам в качестве домашнего задания, описать и обосновать ![]()
См также:
Шаблон улучшения — Как продумывать свое улучшение с примером, когда это приводит к отказу от постановки задачи.
Как заводить задачи в баг-трекер → подробнее о том, как ставить задачу и заполнять обязательные поля.
PS — добавила пост в общую копилку багов.
PPS — магазин я люблю и уважаю, эти посты не о том, «какие они плохие». Баги бывают повсюду, я показываю начинающим тестировщикам, что их много. И их можно и нужно искать повсюду, набивать руку.
Я показываю примеры, где такие баги встречаются. И, разумеется, чем больше функционала, тем выше вероятность появления багов. Поэтому у вайлдберрис я постоянно что-то такое нахожу после очередного релиза. Но магазин молодец, развивается, новые фичи делает! И часто выпускает фичи в тестовом режиме, так что это просто кладезь для начинающих тестировщиков =)
Типы компьютерных уязвимостей
Многие IDS предоставляют описания атак, которые они определяют. Это описание часто включает типы уязвимостей, которые используют атаки. Данная информация является очень полезной после того, как атака произошла, потому что системный администратор может исследовать и скорректировать использованную уязвимость. NIST рекомендует использовать ICAT Metabase проект для исследования и фиксации уязвимостей в сетях организации. ICAT содержит тысячи примеров реальных компьютерных уязвимостей со ссылками на детальное описание. ICAT доступна по адресу http://icat.nist.gov.
Здесь мы обсудим основные типы уязвимостей. Может быть предложено много различных схем для их классификации, мы не будем перечислять их все. Ниже приведен список некоторых наиболее общих типов.
Ошибка корректности входных данных
При такой ошибке входные данные, полученные некоторой системой, не проверяются на корректность, в результате чего возникает уязвимость, которая может быть использована с помощью посылки определенной входной последовательности. Существует два основных типа ошибок корректности входа: переполнение буфера и ошибки граничных условий.
Переполнение буфера
При переполнении буфера входные данные, получаемые системой, являются длиннее, чем ожидаемая длина входа, но система не проверяет данный факт. Входной буфер заполняется и переполняет память, выделенную для входных данных. При грамотном конструировании таких входных данных, выходящих за границу выделенного для них буфера, атакующий может заставить систему выполнять команды от имени атакующего.
Ошибка граничного условия
При такой ошибке входные данные, полученные системой, вызывают в системе нарушение некоторого граничного условия. Данное нарушение само по себе и представляет уязвимость. Например, у системы может переполниться память, дисковое пространство или ширина пропускания сети. Другим примером данной уязвимости является переменная, которая может достигнуть своего максимального значения и перейти в минимальное. Еще одним примером с переменной может быть множество таких ситуаций, как возникновение деления на ноль. Ошибка граничного условия является подмножеством класса ошибок корректности входа. Хотя можно показать, что переполнение буфера является типом ошибки граничного условия, мы поместим данную ошибку в отдельную категорию, понимая ее важность и тот факт, что переполнение буфера возникает чаще других ошибок.
Ошибка управления доступом
При такой ошибке система является уязвимой, потому что механизм управления доступом не функционирует. Проблема заключается не в конфигурации механизма управления доступом, а в самом механизме.
Исключительное условие при обработке ошибки
При возникновении исключительного условия при обработке ошибки система также иногда может стать уязвимой.
Ошибка окружения
При такой ошибке окружение, в котором система инсталлирована, каким-либо образом приводит к тому, что система становится уязвимой. Это может произойти, например, при непредвиденном взаимодействии приложения и ОС или при взаимодействии двух приложений на некотором хосте. Такая уязвимая система может быть правильно сконфигурирована и с большой вероятностью безопасна в тестовом окружении разработчиков, но какие-то предположения, касающиеся безопасности, были нарушены в инсталлируемом окружении.
Ошибка конфигурирования
Ошибка конфигурирования возникает, когда установки управления определены таким образом, что система стала уязвимой. Данная уязвимость говорит не о том, как система была разработана, а о том, как администратор сконфигурировал систему. Можно также считать конфигурационной ошибкой ситуацию, при которой система поставляется от разработчика со слабой, с точки зрения безопасности, конфигурацией.
Race-условие
Race-условия цикла возникают, если существует задержка между временем, когда система проверяет, что операция допустима моделью безопасности, и временем, когда система реально выполняет операцию. Реальная проблема возникает, если окружение в течение интервала времени, когда была выполнена проверка безопасности, и времени, когда была выполнена операция, изменилось таким образом, что модель безопасности более не разрешает операцию. Атакующий имеет возможность в течение данного небольшого окна выполнить незаконные действия, подобные записи в файл паролей, пока состояние является привилегированным.
Будущие направления развития IDS
Хотя функция аудита системы, которая являлась первоначальной задачей IDS, стала формальной дисциплиной за последние пятьдесят лет, поле для исследований IDS все еще остается обширным, большинство исследований датировано не позднее 1980-х годов. Более того, широкое коммерческое использование IDS не начиналось до середины 1990-х.
Intrusion Detection и Vulnerability Assessment является быстро развивающейся областью исследований.
Коммерческое использование IDS находится в стадии формирования. Некоторые коммерческие IDS получили негативную публичную оценку за большое число ложных срабатываний, неудобные интерфейсы управления и получения отчетов, огромное количество отчетов об атаках, плохое масштабирование и плохую интеграцию с системами сетевого управления. Тем не менее потребность в хороших IDS возрастает, поэтому с большой вероятностью эти проблемы будут успешно решаться в ближайшее время.
Ожидается, что улучшение качества функционирования IDS будет осуществляться аналогично антивирусному ПО. Раннее антивирусное ПО создавало большое число ложных тревог при нормальных действиях пользователя и не определяло все известные вирусы. Однако сейчас положение существенно улучшилось, антивирусное ПО стало прозрачным для пользователей и достаточно эффективным.
Более того – очень вероятно, что основные возможности IDS скоро станут ключевыми в сетевой инфраструктуре (такой как роутеры, мосты и коммутаторы) и в операционных системах. При этом, скорее всего, разработчики IDS сфокусируют свое внимание на решении проблем, связанных с масштабируемостью и управляемостью IDS.
Имеются также и другие тенденции, которые, скорее всего, будут влиять на функциональности IDS следующего поколения. Существует заметное движение в сторону аппаратно-программных (appliance) решений для IDS. Также вероятно, что в будущем некоторые функции определения соответствия шаблону могут быть реализованы в аппаратуре, что увеличит скорость обработки.
Наконец, механизмы, связанные с управлением рисками в области сетевой безопасности, будут оказывать влияние на требования к IDS.
Добавлено 31 мая 2021 в 22:08
Большинство программ, имеющих какой-либо пользовательский интерфейс, должны обрабатывать вводимые пользователем данные. В программах, которые мы писали, мы использовали std::cin, чтобы попросить пользователя ввести текст. Поскольку ввод текста имеет произвольную форму (пользователь может вводить что угодно), пользователю очень легко ввести данные, которые не ожидаются.
При написании программ вы всегда должны учитывать, как пользователи (непреднамеренно или наоборот) будут использовать ваши программы некорректно. Хорошо написанная программа будет предвидеть, как пользователи будут использовать ее неправильно, и либо аккуратно обработает эти случаи, либо вообще предотвратит их появление (если это возможно). Программа, которая хорошо обрабатывает случаи ошибок, называется надежной.
В этом уроке мы подробно рассмотрим способы, которыми пользователь может вводить недопустимые текстовые данные через std::cin, и покажем вам несколько разных способов обработки таких случаев.
std::cin, буферы и извлечение
Чтобы обсудить, как std::cin и operator>> могут давать сбой, сначала полезно немного узнать, как они работают.
Когда мы используем operator>> для получения пользовательского ввода и помещения его в переменную, это называется «извлечением». Соответственно, в этом контексте оператор >> называется оператором извлечения.
Когда пользователь вводит данные в ответ на операцию извлечения, эти данные помещаются в буфер внутри std::cin. Буфер (также называемый буфером данных) – это просто часть памяти, отведенная для временного хранения данных, пока они перемещаются из одного места в другое. В этом случае буфер используется для хранения пользовательских входных данных, пока они ожидают извлечения в переменные.
При использовании оператора извлечения происходит следующая процедура:
- Если во входном буфере уже есть данные, то для извлечения используются они.
- Если входной буфер не содержит данных, пользователя просят ввести данные для извлечения (так бывает в большинстве случаев). Когда пользователь нажимает Enter, во входной буфер помещается символ ‘n’.
operator>>извлекает столько данных из входного буфера, сколько может, в переменную (игнорируя любые начальные пробельные символы, такие как пробелы, табуляции или ‘n’).- Любые данные, которые не могут быть извлечены, остаются во входном буфере для следующего извлечения.
Извлечение завершается успешно, если из входного буфера извлечен хотя бы один символ. Любые неизвлеченные входные данные остаются во входном буфере для дальнейшего извлечения. Например:
int x{};
std::cin >> x;Если пользователь вводит «5a», 5 будет извлечено, преобразовано в целое число и присвоено переменной x. А «an» останется во входном потоке для следующего извлечения.
Извлечение не выполняется, если входные данные не соответствуют типу переменной, в которую они извлекаются. Например:
int x{};
std::cin >> x;Если бы пользователь ввел ‘b’, извлечение не удалось бы, потому что ‘b’ не может быть извлечено в переменную типа int.
Проверка ввода
Процесс проверки того, соответствуют ли пользовательские входные данные тому, что ожидает программа, называется проверкой ввода.
Есть три основных способа проверки ввода:
- встроенный (по мере печати пользователя):
- прежде всего, не позволить пользователю вводить недопустимые данные;
- пост-запись (после печати пользователя):
- позволить пользователю ввести в строку всё, что он хочет, затем проверить правильность строки и, если она корректна, преобразовать строку в окончательный формат переменной;
- позволить пользователю вводить всё, что он хочет, позволить
std::cinиoperator>>попытаться извлечь данные и обработать случаи ошибок.
Некоторые графические пользовательские интерфейсы и расширенные текстовые интерфейсы позволяют проверять входные данные, когда пользователь их вводит (символ за символом). В общем случае, программист предоставляет функцию проверки, которая принимает входные данные, введенные пользователем, и возвращает true, если входные данные корректны, и false в противном случае. Эта функция вызывается каждый раз, когда пользователь нажимает клавишу. Если функция проверки возвращает истину, клавиша, которую только что нажал пользователь, принимается. Если функция проверки возвращает false, введенный пользователем символ отбрасывается (и не отображается на экране). Используя этот метод, вы можете гарантировать, что любые входные данные, вводимые пользователем, гарантированно будут корректными, потому что любые недопустимые нажатия клавиш обнаруживаются и немедленно отбрасываются. Но, к сожалению, std::cin не поддерживает этот стиль проверки.
Поскольку строки не имеют никаких ограничений на ввод символов, извлечение гарантированно завершится успешно (хотя помните, что std::cin прекращает извлечение на первом неведущем пробельном символе). После того, как строка введена, программа может проанализировать эту строку, чтобы узнать, корректна она или нет. Однако анализ строк и преобразование вводимых строк в другие типы (например, числа) может быть сложной задачей, поэтому это делается только в редких случаях.
Чаще всего мы позволяем std::cin и оператору извлечения выполнять эту тяжелую работу. В этом методе мы позволяем пользователю вводить всё, что он хочет, заставляем std::cin и operator>> попытаться извлечь данные и справиться с последствиями, если это не удастся. Это самый простой способ, о котором мы поговорим ниже.
Пример программы
Рассмотрим следующую программу-калькулятор, в которой нет обработки ошибок:
#include <iostream>
double getDouble()
{
std::cout << "Enter a double value: ";
double x{};
std::cin >> x;
return x;
}
char getOperator()
{
std::cout << "Enter one of the following: +, -, *, or /: ";
char op{};
std::cin >> op;
return op;
}
void printResult(double x, char operation, double y)
{
switch (operation)
{
case '+':
std::cout << x << " + " << y << " is " << x + y << 'n';
break;
case '-':
std::cout << x << " - " << y << " is " << x - y << 'n';
break;
case '*':
std::cout << x << " * " << y << " is " << x * y << 'n';
break;
case '/':
std::cout << x << " / " << y << " is " << x / y << 'n';
break;
}
}
int main()
{
double x{ getDouble() };
char operation{ getOperator() };
double y{ getDouble() };
printResult(x, operation, y);
return 0;
}Эта простая программа просит пользователя ввести два числа и математический оператор.
Enter a double value: 5
Enter one of the following: +, -, *, or /: *
Enter a double value: 7
5 * 7 is 35Теперь подумайте, где неверный ввод пользователя может нарушить работу этой программы.
Сначала мы просим пользователя ввести несколько чисел. Что, если он введет что-то, отличающееся от числа (например, ‘q’)? В этом случае извлечение не удастся.
Во-вторых, мы просим пользователя ввести один из четырех возможных символов. Что, если он введет символ, отличный от ожидаемых? Мы сможем извлечь входные данные, но пока не обрабатываем то, что происходит после.
В-третьих, что, если мы попросим пользователя ввести символ, а он введет строку типа «*q hello». Хотя мы можем извлечь нужный нам символ ‘*’, в буфере останутся дополнительные входные данные, которые могут вызвать проблемы в будущем.
Типы недопустимых входных текстовых данных
Обычно мы можем разделить ошибки ввода текста на четыре типа:
- извлечение входных данных выполняется успешно, но входные данные не имеют смысла для программы (например, ввод ‘k’ в качестве математического оператора);
- извлечение входных данных выполняется успешно, но пользователь вводит дополнительные данные (например, вводя «*q hello» в качестве математического оператора);
- ошибка извлечения входных данных (например, попытка ввести ‘q’ при запросе ввода числа);
- извлечение входных данных выполнено успешно, но пользователь выходит за пределы значения числа.
Таким образом, чтобы сделать наши программы устойчивыми, всякий раз, когда мы запрашиваем у пользователя ввод, мы в идеале должны определить, может ли произойти каждый из вышеперечисленных возможных вариантов, и если да, написать код для обработки этих случаев.
Давайте разберемся в каждом из этих случаев и в том, как их обрабатывать с помощью std::cin.
Случай ошибки 1: извлечение успешно, но входные данные не имеют смысла
Это самый простой случай. Рассмотрим следующий вариант выполнения приведенной выше программы:
Enter a double value: 5
Enter one of the following: +, -, *, or /: k
Enter a double value: 7В этом случае мы попросили пользователя ввести один из четырех символов, но вместо этого он ввел ‘k’. ‘k’ – допустимый символ, поэтому std::cin успешно извлекает его в переменную op, и она возвращается в main. Но наша программа не ожидала этого, поэтому она не обрабатывает этот случай правильно (и, таким образом, ничего не выводит).
Решение здесь простое: выполните проверку ввода. Обычно она состоит из 3 шагов:
- убедитесь, что пользовательский ввод соответствует вашим ожиданиям;
- если да, верните значение вызывающей функции;
- если нет, сообщите пользователю, что что-то пошло не так, и попросите его повторить попытку.
Вот обновленная функция getOperator(), которая выполняет проверку ввода.
char getOperator()
{
while (true) // Цикл, пока пользователь не введет допустимые данные
{
std::cout << "Enter one of the following: +, -, *, or /: ";
char operation{};
std::cin >> operation;
// Проверяем, ввел ли пользователь подходящие данные
switch (operation)
{
case '+':
case '-':
case '*':
case '/':
return operation; // возвращаем символ вызывающей функции
default: // в противном случае сообщаем пользователю, что пошло не так
std::cout << "Oops, that input is invalid. Please try again.n";
}
} // и попробуем еще раз
}Как видите, мы используем цикл while для бесконечного цикла до тех пор, пока пользователь не предоставит допустимые данные. Если он этого не делает, мы просим его повторить попытку, пока он не даст нам правильные данные, не закроет программу или не уничтожит свой компьютер.
Случай ошибки 2: извлечение успешно, но с посторонними входными данными
Рассмотрим следующий вариант выполнения приведенной выше программы:
Enter a double value: 5*7Как думаете, что будет дальше?
Enter a double value: 5*7
Enter one of the following: +, -, *, or /: Enter a double value: 5 * 7 is 35Программа выводит правильный ответ, но форматирование испорчено. Давайте подробнее разберемся, почему.
Когда пользователь вводит «5*7» в качестве вводных данных, эти данные попадают в буфер. Затем оператор >> извлекает 5 в переменную x, оставляя в буфере «*7n». Затем программа напечатает «Enter one of the following: +, -, *, or /:». Однако когда был вызван оператор извлечения, он видит символы «*7n», ожидающие извлечения в буфере, поэтому он использует их вместо того, чтобы запрашивать у пользователя дополнительные данные. Следовательно, он извлекает символ ‘*’, оставляя в буфере «7n».
После запроса пользователя ввести другое значение double, из буфера извлекается 7 без ожидания ввода пользователя. Поскольку у пользователя не было возможности ввести дополнительные данные и нажать Enter (добавляя символ новой строки), все запросы в выводе идут вместе в одной строке, даже если вывод правильный.
Хотя программа работает, выполнение запутано. Было бы лучше, если бы любые введенные посторонние символы просто игнорировались. К счастью, символы игнорировать легко:
// очищаем до 100 символов из буфера или пока не будет удален символ 'n'
std::cin.ignore(100, 'n');Этот вызов удалит до 100 символов, но если пользователь ввел более 100 символов, мы снова получим беспорядочный вывод. Чтобы игнорировать все символы до следующего символа ‘n’, мы можем передать std::numeric_limits<std::streamsize>::max() в std::cin.ignore(). std::numeric_limits<std::streamsize>::max() возвращает наибольшее значение, которое может быть сохранено в переменной типа std::streamsize. Передача этого значения в std::cin.ignore() приводит к отключению проверки счетчика.
Чтобы игнорировать всё, вплоть до следующего символа ‘n’, мы вызываем
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), 'n');Поскольку эта строка довольно длинная для того, что она делает, будет удобнее обернуть ее в функцию, которую можно вызвать вместо std::cin.ignore().
#include <limits> // для std::numeric_limits
void ignoreLine()
{
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), 'n');
}Поскольку последний введенный пользователем символ должен быть ‘n’, мы можем указать std::cin игнорировать символы в буфере, пока не найдет символ новой строки (который также будет удален).
Давайте обновим нашу функцию getDouble(), чтобы игнорировать любой посторонний ввод:
double getDouble()
{
std::cout << "Enter a double value: ";
double x{};
std::cin >> x;
ignoreLine();
return x;
}Теперь наша программа будет работать, как ожидалось, даже если мы введем «5*7» при первом запросе ввода – 5 будет извлечено, а остальные символы из входного буфера будут удалены. Поскольку входной буфер теперь пуст, при следующем выполнении операции извлечения данные у пользователя будут запрашиваться правильно!
Случай ошибки 3: сбой при извлечении
Теперь рассмотрим следующий вариант выполнения нашей программы калькулятора:
Enter a double value: aНеудивительно, что программа работает не так, как ожидалось, но интересно, как она дает сбой:
Enter a double value: a
Enter one of the following: +, -, *, or /: Enter a double value: и программа внезапно завершается.
Это очень похоже на случай ввода посторонних символов, но немного отличается. Давайте посмотрим подробнее.
Когда пользователь вводит ‘a’, этот символ помещается в буфер. Затем оператор >> пытается извлечь ‘a’ в переменную x, которая имеет тип double. Поскольку ‘a’ нельзя преобразовать в double, оператор >> не может выполнить извлечение. В этот момент происходят две вещи: ‘a’ остается в буфере, а std::cin переходит в «режим отказа».
Находясь в «режиме отказа», будущие запросы на извлечение входных данных будут автоматически завершаться ошибкой. Таким образом, в нашей программе калькулятора вывод запросов всё еще печатается, но любые запросы на дальнейшее извлечение игнорируются. Программа просто выполняется до конца, а затем завершается (без вывода результата потому, что мы не прочитали допустимую математическую операцию).
К счастью, мы можем определить, завершилось ли извлечение сбоем, и исправить это:
if (std::cin.fail()) // предыдущее извлечение не удалось?
{
// да, давайте разберемся с ошибкой
std::cin.clear(); // возвращаем нас в "нормальный" режим работы
ignoreLine(); // и удаляем неверные входные данные
}Вот и всё!
Давайте, интегрируем это в нашу функцию getDouble():
double getDouble()
{
while (true) // Цикл, пока пользователь не введет допустимые данные
{
std::cout << "Enter a double value: ";
double x{};
std::cin >> x;
if (std::cin.fail()) // предыдущее извлечение не удалось?
{
// да, давайте разберемся с ошибкой
std::cin.clear(); // возвращаем нас в "нормальный" режим работы
ignoreLine(); // и удаляем неверные входные данные
}
else // иначе наше извлечение прошло успешно
{
ignoreLine();
return x; // поэтому возвращаем извлеченное нами значение
}
}
}Примечание. До C++11 неудачное извлечение не приводило к изменению извлекаемой переменной. Это означает, что если переменная была неинициализирована, она останется неинициализированной в случае неудачного извлечения. Однако, начиная с C++11, неудачное извлечение из-за недопустимого ввода приведет к тому, что переменная будет инициализирована нулем. Инициализация нулем означает, что для переменной установлено значение 0, 0.0, «» или любое другое значение, в которое 0 преобразуется для этого типа.
Случай ошибки 4: извлечение успешно, но пользователь выходит за пределы значения числа
Рассмотрим следующий простой пример:
#include <cstdint>
#include <iostream>
int main()
{
std::int16_t x{}; // x - 16 бит, может быть от -32768 до 32767
std::cout << "Enter a number between -32768 and 32767: ";
std::cin >> x;
std::int16_t y{}; // y - 16 бит, может быть от -32768 до 32767
std::cout << "Enter another number between -32768 and 32767: ";
std::cin >> y;
std::cout << "The sum is: " << x + y << 'n';
return 0;
}Что произойдет, если пользователь введет слишком большое число (например, 40000)?
Enter a number between -32768 and 32767: 40000
Enter another number between -32768 and 32767: The sum is: 32767В приведенном выше случае std::cin немедленно переходит в «режим отказа», но также присваивает переменной ближайшее значение в диапазоне. Следовательно, x остается с присвоенным значением 32767. Дополнительные входные данные пропускаются, оставляя y с инициализированным значением 0. Мы можем обрабатывать этот вид ошибки так же, как и неудачное извлечение.
Примечание. До C++11 неудачное извлечение не приводило к изменению извлекаемой переменной. Это означает, что если переменная была неинициализирована, в случае неудачного извлечения она останется неинициализированной. Однако, начиная с C++11, неудачное извлечение вне диапазона приведет к тому, что переменной будет присвоено ближайшее значение в диапазоне.
Собираем всё вместе
Вот наш пример калькулятора с полной проверкой ошибок:
#include <iostream>
#include <limits>
void ignoreLine()
{
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), 'n');
}
double getDouble()
{
while (true) // Цикл, пока пользователь не введет допустимые данные
{
std::cout << "Enter a double value: ";
double x{};
std::cin >> x;
// Проверяем на неудачное извлечение
if (std::cin.fail()) // предыдущее извлечение не удалось?
{
// да, давайте разберемся с ошибкой
std::cin.clear(); // возвращаем нас в "нормальный" режим работы
ignoreLine(); // и удаляем неверные входные данные
std::cout << "Oops, that input is invalid. Please try again.n";
}
else
{
ignoreLine(); // удаляем любые посторонние входные данные
// пользователь не может ввести бессмысленное значение double,
// поэтому нам не нужно беспокоиться о его проверке
return x;
}
}
}
char getOperator()
{
while (true) // Цикл, пока пользователь не введет допустимые данные
{
std::cout << "Enter one of the following: +, -, *, or /: ";
char operation{};
std::cin >> operation;
ignoreLine();
// Проверяем, ввел ли пользователь осмысленные данные
switch (operation)
{
case '+':
case '-':
case '*':
case '/':
return operation; // возвращаем символ вызывающей функции
default: // в противном случае сообщаем пользователю, что пошло не так
std::cout << "Oops, that input is invalid. Please try again.n";
}
} // и попробуем еще раз
}
void printResult(double x, char operation, double y)
{
switch (operation)
{
case '+':
std::cout << x << " + " << y << " is " << x + y << 'n';
break;
case '-':
std::cout << x << " - " << y << " is " << x - y << 'n';
break;
case '*':
std::cout << x << " * " << y << " is " << x * y << 'n';
break;
case '/':
std::cout << x << " / " << y << " is " << x / y << 'n';
break;
default: // Надежность означает также обработку неожиданных параметров,
// даже если getOperator() гарантирует, что op в этой
// конкретной программе корректен
std::cerr << "Something went wrong: printResult() got an invalid operator.n";
}
}
int main()
{
double x{ getDouble() };
char operation{ getOperator() };
double y{ getDouble() };
printResult(x, operation, y);
return 0;
}Заключение
При написании программы подумайте о том, как пользователи будут неправильно использовать вашу программу, особенно при вводе текста. Для каждой точки ввода текста учтите:
- Могло ли извлечение закончиться неудачей?
- Может ли пользователь ввести больше, чем ожидалось?
- Может ли пользователь ввести бессмысленные входные данные?
- Может ли пользователь переполнить входные данные?
Вы можете использовать операторы if и булеву логику, чтобы проверить, являются ли входные данные ожидаемыми и осмысленными.
Следующий код очистит любые посторонние входные данные:
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), 'n');Следующий код будет проверять и исправлять неудачные извлечения или переполнение:
if (std::cin.fail()) // предыдущее извлечение не удалось или закончилось переполнением?
{
// да, давайте разберемся с ошибкой
std::cin.clear(); // возвращаем нас в "нормальный" режим работы
ignoreLine(); // и удаляем неверные входные данные
}Наконец, используйте циклы, чтобы попросить пользователя повторно ввести данные, если исходные входные данные были недопустимыми.
Примечание автора
Проверка ввода важна и полезна, но она также делает примеры более сложными и трудными для понимания. Соответственно, на будущих уроках мы, как правило, не будем проводить никакой проверки вводимых данных, если они не имеют отношения к чему-то, чему мы пытаемся научить.
Теги
C++ / CppLearnCppstd::cinДля начинающихОбнаружение ошибокОбработка ошибокОбучениеПрограммирование

Привет, сегодня я хочу поговорить о том, с чем мы рано или поздно сталкиваемся, имея много доменной логики — и даже не микросервисную, — а хотя бы просто сервисную архитектуру.
В ожидании комбинаторного взрыва
Я работаю в команде сервиса расписания занятий, который оркестрирует весь процесс подбора преподавателя в Skyeng. Когда новый клиент хочет найти учителя, нам приходит запрос: «ID ученика такой-то хочет заниматься с такого-то числа и в такое-то время». Чтобы подобрать преподавателя, мы идем в сервисы других команд:
- в CRM — чтобы определить, что за услуга сейчас должна быть оказана: занятия английским, математикой или по одному из новых экспериментальных предметов,
- в сервис рейтинга — чтобы отсортировать преподавателей по данной услуге, лучше подходящих для данного ученика,
- и в сам сервис преподавателей, который хранит информацию, кто берёт новых учеников — и много-много других нюансов.
На самом деле, сервисов больше, но даже на этом масштабе можно отследить проблему. Каждый сервис пишет своя команда: и ее разработчики возвращают ошибки, как придумали.

Гипотетическая ситуация, когда все сервисы упали сразу, может обернуться такими ответами.
У каждого сервиса может быть куча вариантов ошибок, и мы должны обрабатывать все их виды на своей стороне. При интеграции любого нового сервиса мы увеличим кучу кода, которая не имеет отношения к бизнес-логике, но которую нужно будет поддерживать. Более того, подключая новый сервис, мы не можем быть уверены, что документация не изменится.
Бывает и такое — бизнес приходит и просит «А добавьте тут…» Допустим, у нас есть форма ввода данных, в ней 10 полей, мы валидируем девять, а десятое — это комментарий, он опционален. В один день нас просят добавить валидацию на комментарий. Фронт говорит: «Если придет такой-то код, я у себя доработаю». Ты пишешь новую обработку: и вот на 10 ошибок у фронта появляется 10 обработчиков, а еще у тебя есть разные вариации if-ов, else-ов и т.д.
При этом сами ошибки возникают редко — и это тоже проблема.

При взаимодействии между сервисами мы используем REST, а он как таковой не регламентирует нам форматы, кроме того, что основан на HTTP.
Все мы знаем какие-то определенные наборы ошибок, а остальные вряд ли можем вспомнить без словаря. В итоге, видя какой-то ответ, мы тратим время на осознание, что он значит на самом деле, — а это сильно влияет на скорость тушения пожара на проде, разбора логов и каких-то еще критичных ситуаций.
Давайте попробуем решить эту проблему
Мы c командой посмотрели обсуждения в комьюнити, посмотрели ролики на ютубе, статьи на хабре (вот интересный хабра-холивар про 200-й ответ). Похоливарили внутри. Пришли к выводу, что серебряной пули не существует… и пошли своим путем. Ввели единый формат, при котором у нас есть:
1. Поле «data» для полезной нагрузки — скажем, вот так может выглядеть успешный ответ:
{
"data": [
{
"field1": 1
},
{
"field2": 2
}
],
"errors": null
}
2. И поле «errors» для ошибок.
...
"data": null,
"errors": [
{
"property": null,
"error": {
"message": "The selected time is alr...",
"code": "selected_time_already_taken"
}
}
]
…
Поля data и errors в ответе не могут быть заполнены одновременно.
У нас большое разнообразие ошибок, поэтому на каждую вариацию мы добавили свои правила.
Ошибки бизнес-логики возвращают код 200 и список ошибок в поле errors. Мы не должны падать, например, если у преподавателя превышено количество учеников, которых он может вести. Поэтому решили отображать на фронт полезную ошибку.
Если это не ошибка бизнес-логики, возвращаем соответствующий по смыслу HTTP-код. Но вы скажете, что в таком случае проблема разнообразия ошибок никуда не уходит. Поэтому их тоже нужно подразделять:
- Непредвиденные ошибки: где-то что-то забыли, линтер не допроверил — всякое бывает.
- Инфраструктурные ошибки — например, ошибки Redis Cluster, ошибка связанности или если приложение не дождалось чего-нибудь другого. Мы понимаем, что у сервиса что-то произошло в эту секунду, и можем отреагировать с помощью retry. Такие ошибки удобно обрабатывать с помощью воркера, который периодически ходит по сервисам и опрашивает их: прошел, собрал метрики, хоп — что-то отвалилось, сделали retry.
- Ошибки валидации входных данных. Они вылазят где-то на тестингах, на dev-режиме, — и должны быть максимально полезными для разработчика. Мы используем Symfony serializer и validator, чтобы маппить все, что пришло на вход: чтобы не просто узнать, что Error validation, а понять, что именно не так, мы выделили отдельный класс ошибок, которые выдаются массивом.
Пример ошибок, которые используем
Первое, что нам нужно четко понимать, — у нас произошла, скажем, ошибка валидации или ошибка инфраструктуры? Нужно как-то разделять это на уровне кода — и не бесконечными if в бизнес-логике, а именно на уровне инструмента языка.
Мы создали иерархию Exception. Например, делаем базовый класс ValidationException и от него наследуем всё, что зависит от валидации. Это может быть TeacherValidationException. А у него свои наследники — NicknameException, AgeException и так далее.
Дальше делаем Exception, который хранит подробную информацию о бизнес-ошибке. Бывают ситуации, когда нам важно понимать, на каком слое что-то пошло не так. Тогда каждого слоя мы получаем свои Exception: есть API-репозиторий с APIRepositoryException, выше идет сервис, у него есть ServiceException, потом идёт Exception контроллера и т.д.
Остается сделать единую точку выхода из приложения, которая позволит отлавливать все исключения и выдавать код формате с data и errors. Это просто — сейчас так или иначе все фреймворки позволяют отлавливать Exception ивентами.
Вот как это выглядит на практике:
class ValidationException extends Exception
interface HttpExceptionInterface extends ThrowableValidationException — бросаем, если Symfony validator собрал что-то, что не позволяет нам продолжить дальше. Здесь же есть HttpExceptionInterface, который кидает Guzzle, дабы мы понимали, какой ответ http, какой response, какие headers и так далее нам пришли.
class SomeServiceException extends ExceptionSomeServiceException — у каждого сервиса есть FeaturesException или какой-нибудь ещё Exception, которые позволяют нам пробрасывать информацию между слоями приложения. Мы можем понять, что у нас произошла бизнес-ошибка, и вывести ее на фронт, либо подавить и отдать ответ о том, что мы ответим позже. Это дает вариативность в нашей логике.
interface ConventionalResponseExceptionInterface extends Throwable
{
public function getConventionalCode(): string;
public function getProperty(): ?string;
}ConventionalResponseExceptionInterface — есть интерфейс бизнес-ошибки, фронту нужно получить информацию и вывести текст. Мы на бэкенде рулим тем, что увидит пользователь. В поле Property у нас может быть запись teacher — то есть, что-то произошло на стороне учителя. А ConventionalCode — это какой это уникальный код ошибки. Допустим, это может быть «Selected time have already taken» — выбранное время уже занято. Фронт по факту пишет один обработчик на такие типы ошибок, а мы просто бросаем Exception, который наследует такой интерфейс. Он возвращает все нужные данные, а фронт добавляет в обработку ошибок этот код. Больше ничего дорабатывать не нужно.
Как внедрить на практике
Самое главное — мы не можем сказать бизнесу, что «решили всё переписать, чтобы у нас все работало». Такие вещи делаются с сохранением обратной совместимости: вы вводите API версии 2, которое теперь работает с нужным форматом, и делаете доработки на уровне middleware, либо OnKernelRequest, чтобы каждый раз не проверять, новая это апишка или старая.
Подключаем единый обработчик исключений. Так как мы используем Symfony, то просто сконфигурировали listener, который подписан на события onKernelException. По факту, он перехватывает и обрабатывает любое исключение, которое возникает в системе — при версиях PHP старше семёрки проблем не возникает.
kernel.listener.conventional:
class: ConventionalApiExceptionListener
tags:
- {
name: kernel.event_listener,
event: kernel.exception,
method: onKernelException
}Сам код listener-а очень большой, покажу интересный кусок: приходит event, он содержит в себе instance Exception-а, мы проверяем, к какому типу ошибки это относится, и в зависимости от этого формируем список наших ошибок.
switch (true) {
case $exception instanceof ConventionalResponseExceptionInterface:
...
break;
case $exception instanceof ValidationException:
...
break;
case $exception instanceof BadRequestHttpException:
...
break;
case $exception instanceof HttpExceptionInterface:
...
break;
case $exception instanceof SomeServiceException:
...
break;
default:
...
}В случае, если приходит ConventionalResponseException, мы знаем, что есть уникальный код и текст ошибки, какая-то подробная информация, — упаковываем это и выводим так, чтобы фронт тоже это понимал. А если пришёл ValidationException, он уже содержит в себе весь список ошибок, — и нам нужно просто преобразовать его в наш формат.
В логах есть три уровня приоритета — info, warning и critical. В зависимости от приоритета, ошибки попадают в разные хранилища: не критичное в файлы, критичное в Slack. Бизнес-ошибки уходят в info, всё остальное у нас либо warning, либо critical.
Отдельно скажу про 500-е. Мы проверяем environment, и на дев-стенде и тестингах позволяем себе вывести весь стэктрейс пятисотки. Если это прод, мы просто меняем ошибку на текст Internal Error и делаем проброс в Sentry, а Sentry стучится в Slack к разработчику: «Бросай все, горим».
Спойлер
После того, как мы вели регламенты, про которые я сегодня расскажу, у нас увеличилась скорость тушения пожаров (̶х̶о̶т̶я̶,̶ ̶к̶о̶н̶е̶ч̶н̶о̶,̶ ̶б̶и̶з̶н̶е̶с̶ ̶д̶у̶м̶а̶е̶т̶,̶ ̶ч̶т̶о̶ ̶у̶ ̶н̶а̶с̶ ̶п̶о̶ж̶а̶р̶о̶в̶ ̶н̶е̶т̶)̶.
А теперь нам нужно как-то отличить ошибки от других сервисов по нашему регламенту на нашей стороне.
К старым апишкам мы проверки, о которых расскажу, не применяем, — только к тем, о которых договорились. Допустим, у нас есть какой-то service class, который ходит на чужой API, с котором договорились.
Проверяем, корректен ли ответ: если пришел не JSON — сразу бросаем Exception.
try {
$decodedResponse = json_decode($contents, true, 512, JSON_THROW_ON_ERROR);
} catch (Throwable $exception) {
return false;
}Также проверяем HTTP-статусы: есть 4 варианта, о которых мы договорились, что это корректная ситуация.
$isHttpStatusOk = in_array(
$code,
[
Response::HTTP_OK,
Response::HTTP_CREATED,
Response::HTTP_ACCEPTED,
Response::HTTP_NO_CONTENT,
],
true
);
if ($isHttpStatusOk === false) {
return false;
}Если отсутствуют ключи data или errors, — тоже считаем, что это не по регламенту. В остальном — главное, чтобы ошибок не было: если в поле errors не пришло ошибок, значит все ок.
if (!array_key_exists('errors', $decodedResponse)
||
!array_key_exists('data', $decodedResponse)
) {
return false;
}
return $decodedResponse['errors'] === null;Положив этот код в trait, мы используем его в фасадах нескольких API-репозиториев: и теперь нам не нужно добавлять новый обработчик на каждый чих, а затем тыкать все апишки — упадут или нет.
В каких случаях подход дает выгоду, в чем минусы, как поддерживать
Ни в коем случае не предлагаю бессмысленно и беспощадно транслировать такую практику на всех и вся. Мы сами используем регламент ограниченно: договорились с несколькими командами, с чьими сервисами взаимодействуем чаще всего. Например, это команда сервисов для учителей: они ходят к нам за расписанием, мы к ним за данными о преподавателях. У нас много разных кейсов взаимодействия: и, договорившись один раз, мы выиграли в скорости разбора логов и тушения пожаров.
Но есть нюансы, которые мы уже увидели на практике:
- Подход требует ответственного отношения от старших разработчиков и тимлидов: мы должны поддерживать при разработке единый формат. В каждом код-ревью нужно вникать и понимать, тот ли тип Exception-а вернулся, если что — создать новый, назвать его корректно, наследовать его от нужного типа ошибки. А когда регламент поменяется (его придется менять), потому что у вас появилась новая договоренность с другими командами, нужно не полениться сходить к соседям и сделать pull request.
- Регламент усложнит онбординг новичков: но зато когда человек вник, увидев ошибку в логах, он будет четко понимать, что произошло и куда бежать.
Но несмотря на эти трудности — мы довольны. Экономим время при обнаружении ошибки и добавление новых однотипных ошибок. А как устроено у вас?