
Коэффициенты ошибок
Появление ошибки
в двоичной последовательности зависит
от многих факторов и оценивается как
случайное явление. Вероятность появления
ошибки находится как предел отношения
количества ошибок в переданной двоичной
последовательности к общему числу
элементов этой последовательности при
условии, что общее число элементов
последовательности стремится к
бесконечности, т.е.
![]()
.
В реальных условиях
выполнить требование
![]()
невозможно. Поэтому при анализе используют
понятие частость ошибок или коэффициент
ошибок
![]()
,
который определяется как отношение
числа ошибочных элементов (комбинаций,
сообщений) в принятой последовательности
к общему числу принятых элементов
(комбинаций, сообщений) этой
последовательности:
![]()
При достаточно
большом
![]()
величины
![]()
и
![]()
мало отличаются друг от друга.
В связи с выше
сказанным различают
следующие коэффициенты ошибок:
1.
Коэффициент ошибок по элементам
![]()
где
![]()
число
ошибочных элементов в переданном
сообщении,
![]()
общее число
элементов в переданном сообщении.
В рассмотренном
выше примере
![]()
2. Коэффициент
ошибок по комбинациям:
![]()
где
![]()
число комбинаций принятых с ошибками
в переданном сообщении,
![]()
общее
число комбинаций в переданном сообщении.
В рассмотренном
выше примере
![]()
3. Коэффициент
ошибок по сообщениям:
![]()
где
![]()
число
сообщений принятых с ошибками,
![]()
общее
число принятых сообщений.
В рассмотренном
выше примере![]()
Расчет вероятности ошибок
Вероятность
появления ошибок можно вычислить,
предположив, что ошибки появляются
независимо друг от друга, т.е. представить
появление ошибок как независимые
случайные события (такие ошибки называют
простейшими).
Будем считать, что
вероятность появления ошибки P
численно
равна вероятности появления искажения,
превышающего допустимое значение
![]()
.
Вероятность
превышения случайной величиной некоторого
значения без учета знака может быть
определена по формуле:

В
выражении учтено, что, согласно
исследованиям, проведенным с помощью
анализатора искажений, закон распределения
смещений границ принимаемых импульсов
близок к нормальному.
Интеграл в этой
формуле не выражается через элементарные
функции, но его можно вычислить через
функцию Лапласа, воспользовавшись
соответствующими таблицами:
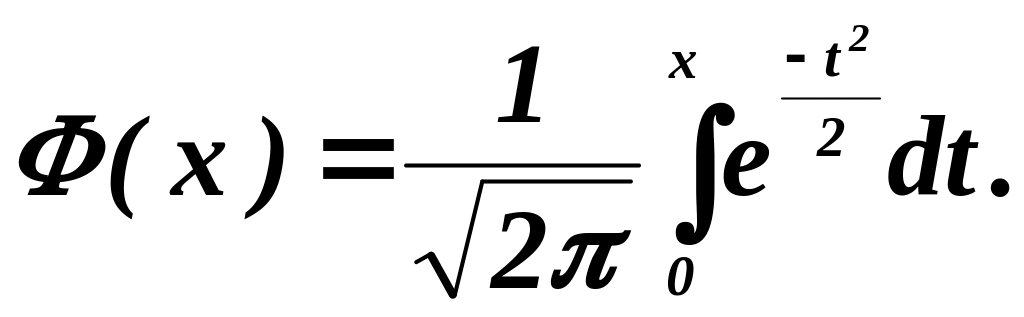
В этом
случае вероятность ошибки при симметричной
кривой распределения искажений (а
= 0)
равна:
![]()
,
где
![]()
Такой упрощенный
метод расчета отличается простотой
получения исходных данных и может быть
рекомендован для ориентировочного
анализа.
Математические модели ошибок
Для анализа
механизма возникновения ошибок при
аналитических исследованиях применяют
математические модели ошибок, т.е.
математическое описание процесса их
появления.
Простейшей модель
основана на предположении статистической
независимости ошибок. При этом свойства
канала как источника ошибок описываются
лишь единственным параметром –
вероятностью p
ошибочного приема одного элемента.
Задача формулируется
следующим образом: происходит испытание,
состоящее в том, что по каналу связи
передается кодовый элемент. Вероятность
того, что этот кодовый элемент будет
принят неверно (т.е. произойдет ошибка
при передаче — событие A),
равна p,
тогда вероятность того, что ошибка не
произойдет (т.е. событие А
не наступит) равна q=1-p.
Происходит n
независимых испытаний, т.е. передается
n
кодовых элементов. Вероятность наступления
события А
в каждом испытании постоянна и равна
p.
Требуется определить вероятность
наступления события А
ровно k
раз, если опыт повторялся n
раз. Такая постановка задачи полностью
соответствует схеме Бернулли, тогда
имеем:
![]()
где
![]()
число
ошибочно принятых элементов в кодовой
комбинации,
![]()
число сочетаний
из n
по
![]()
.
Тогда вероятность
приема неискаженной комбинации
![]()
равно
![]()
Чтобы упростить
дальнейшие выкладки, разложим данное
выражение в ряд Маклорена, воспользовавшись
известной формулой:
![]()
Беря два члена
данного разложения и используя введенные
обозначения, получим:
![]()
(Заметим, что данным
разложением можно воспользоваться,
т.к. вероятность p
всегда меньше единицы).
Тогда вероятность
приема ошибочной комбинации, т.е.
комбинации, содержащей хотя бы одну
ошибку, равна:
![]()
Результат получен
с достаточной для практики точностью,
т.к. вероятность неправильного приема
одного элемента p![]()
.
Простейшая модель
ошибок носит приближенный характер,
дает грубое описание реальных каналов
и может быть использована только для
ориентировочных расчетов.
Все остальные
известные модели ошибок основаны на
допущении, что ошибки не являются
независимыми, а группируются в пакеты.
Модель Э.Н.Гильберга
основана на предложении, что при пакетном
группировании поток ошибок может быть
описан простым Марковским процессом.
Согласно Э.Н.Гильберту, канал может
находиться в одном из двух состояний:
«хорошем» (ошибки не возможны) и «плохом»,
при этом ошибки полностью определяются
матрицей переходных вероятностей:
![]()
где
p00
–
вероятность передачи по каналу «0» без
ошибки,
p11
–
вероятность передачи по каналу «1» без
ошибки,
p01
–
вероятность ошибки 0→1 при передачи по
каналу,
p10
– вероятность
ошибки 1→0 при передачи по каналу.
и вероятностью
p0.
Вероятности изменения состояний канала
p01
и p10
должны быть значительно меньше
вероятностей сохранения состояния
канала p00
и p11.
Эта модель хорошо описывает характер
распределения ошибок в каналах с длинными
и плотными пакетами ошибок.
Имеется ряд моделей,
дающих частичное описание канала.
Например, по одной из них можно определить
зависимость вероятности появления
ошибочной комбинации (Рок)
от ее длины n
и вероятности появления
![]()
—
кратной ошибки в комбинации:
![]()
,
где
— коэффициент группирования ошибок.
Если
![]()
,
то пакетирование ошибок отсутствует,
они считаются независимыми, и выражение
преобразуется в формулу, полученную по
схеме Бернулли.
Известна модель
Б.Бенета и Ф.Фройлиха основанная на
предположении, что ошибки группируются
в пакеты и что ошибки в пакете, как и
сами пакеты, возникают независимо друг
от друга. Для описания канала с ошибками
следует знать три параметра: вероятность
появления пакета ошибок любой длины
![]()
,
вероятность ошибки в пакете
![]()
и распределение вероятностей длин
пакетов ошибок
![]()
![]()
.
Основным недостатком рассматриваемой
модели является предположением о
независимости появления пакетов ошибок.
Ни одна модель не
дает абсолютно точного описания реального
процесса возникновения ошибок вследствие
его сложности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
6.1. Определения коэффициента ошибок
6.2. Математическое выражение коэффициента битовых ошибок
6.3. Нормы на параметры ошибок систем передачи
6.4. Принципы построения измерителей ошибок
6.5. Техника измерения коэффициента ошибок
6.1. Определения коэффициента ошибок
Коэффициент ошибок – важнейшая характеристика линейного тракта. Он измеряется как для отдельных участков регенерации, так и для тракта в целом. Определяется коэффициент ошибок kОШ, по формуле:
kОШ = NОШ /N, (6.1)
где N – общее число символов, переданных за интервал измерения; NОШ – число ошибочно принятых символов за интервал измерения.
Измерение коэффициента ошибок носит статистический характер, так как получаемый за конечное время результат является случайной величиной. Относительную погрешность измерения в случае нормального закона распределения числа ошибок, что допустимо при N≥10, можно определить по формуле:
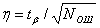 . (6.2)
. (6.2)
Здесь ![]() — коэффициент, зависящий от доверительной вероятности результата измерений:
— коэффициент, зависящий от доверительной вероятности результата измерений:
![]() , (6.3)
, (6.3)
где ![]() — обратная функция интеграла вероятности
— обратная функция интеграла вероятности ![]() :
:
![]() . (6.4)
. (6.4)
Значение kОШ позволяет оценивать вероятность ошибки pОШ – количественную оценку помехоустойчивости. Область возможных значений оценки, в которой с заданной доверительной вероятностью будет находиться значение pОШ, определяется верхней (pВ) и нижней (pН) доверительными границами. При нормальном законе распределения числа ошибок значения pВ и pН определяются по формулам:
![]() , (6.5)
, (6.5)
![]() , (6.6)
, (6.6)
Очевидно, что точность оценок вероятности ошибки и коэффициента ошибки растет с увеличением N. Общее число символов цифрового сигнала, переданных за интервал измерения T, зависит от скорости передачи B: N = TB. Отсюда следует, что чем больше скорость передачи, тем быстрее и точнее можно оценить коэффициент ошибок.
6.2. Математическое выражение коэффициента битовых ошибок
Определим коэффициент битовых ошибок для реальных приёмников, которым свойственно наличие различных источников шумов. При этом будем считать, что приёмник принимает решение, какой бит (0 или 1) был передан в каждом битовом интервале путем стробирования фототока. Очевидно, что из-за наличия шумов данное решение может быть неверным, что приводит к появлению ошибочных битов. Поэтому, чтобы определить коэффициент битовых ошибок, необходимо понять, каким образом приемник принимает решение относительно переданного бита.
Обозначим через I1 и I0 фототоки, стробированные приемником в течение 1 и 0 битов, соответственно, а через s12 и s02 соответствующие шумы. Принимая, что последние имеют гауссовское распределение, проблема установления истинного значения принятого бита имеет следующую математическую формулировку. Фототок для битов 1 и 0 является выборкой гауссовской переменной со средним значением I1 и вариацией s1, а приёмник должен отслеживать этот сигнал и решать, является ли переданный бит 0 или 1. При этом существует много возможных правил принятия решения, которые могут быть реализованы в приёмнике с целью минимизации коэффициента битовых ошибок. Для значения фототока I этим оптимальным решением является наиболее вероятное значение переданного бита, которое определяется путём сравнения текущего значения фототока с пороговым значением Iп, используемым для принятия решения.
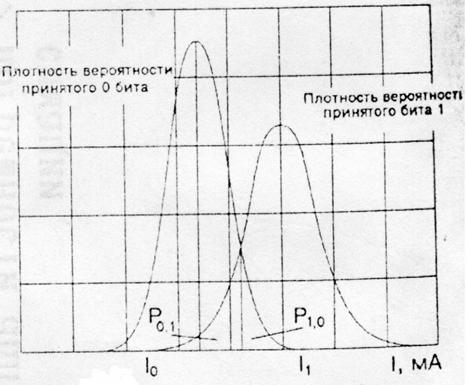
Рисунок 6.1. Функция плотности вероятности фототока принятых сигналов
Пусть при I ³ Iп принимается решение о том, что был передан бит 1, в противном случае – бит 0. Когда биты 1 и 0 равновероятны, что и рассматривается в дальнейшем, пороговый ток приблизительно равен:
![]() (6.7)
(6.7)
Геометрически Iп представляет собой значение тока I, для которого две кривые плотности вероятностей (рис. 6.1) пересекаются.
Вероятность того, что I < Iп, т. е. вероятность ошибки при передаче бита 1, обозначим через Р0,1, а вероятность решения для переданного бита 1, когда I ³ Iп при переданном 0, обозначим Р1,0.
Пусть Q(х) обозначает вероятность того, что нулевая средняя вариация гауссовской переменной превышает значение х, тогда:
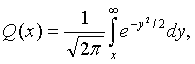 (6.8)
(6.8)
а
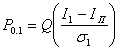 (6.9)
(6.9)
а
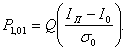 (6.10)
(6.10)
Можно показать [14], что BER определяется,
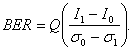 (6.11)
(6.11)
Очень важно отметить, что в ряде случаев эффективным является использование изменяемого в зависимости от уровня сигнала порога принятия решения, как, например, шума оптического усилителя. Многие высокоскоростные приёмники обладают такой особенностью. Однако более простые приемники имеют порог, соответствующий среднему уровню принимаемого тока, а именно (I1 + I0)/2. Такая настройка порогового значения дает большой коэффициент битовых ошибок, определяемый выражением [14].
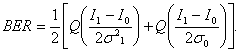 (6.12)
(6.12)
Выражение (6.11) можно использовать для оценки BER, когда известны как мощность полученного сигнала, соответствующего битам 0 и 1, так и статистика шумов.
6.3. Нормы на параметры ошибок систем передачи
Битовые ошибки являются основным источником ухудшения качества связи, проявляющегося в искажении речи в телефонных каналах, недостоверности передачи информации или снижении пропускной способности передачи данных, и характеризуются статистическими параметрами и нормами на них, которые определены соответствующей вероятностью выполнения этих норм. Последние делятся на долговременные и оперативные нормы, первые из которых определяются рекомендациями ITU-T G.821 и G.826, а вторые – М.2100, М.2110 и М.2120, при этом, согласно М.2100, качество цифрового тракта по критерию ошибок делят на три категории:
- нормальное – BER < 10-6;
- пониженное – 10-6 ≤ BER < 10-3 (предаварийное состояние);
- неприемлемое – BER ≥ 10-3 (аварийное состояние).
Так как появление ошибок является следствием совокупности всех текущих условий передачи цифровых сигналов, имеющих случайный характер, то при отсутствии данных о законе распределения ошибок его отдельные элементы могут быть определены с определенной степенью достоверности только по результатам продолжительных измерений. В то же время на практике необходимо, чтобы значения параметров ошибок для ввода в эксплуатацию и технического обслуживания систем передачи основывались на достаточно коротких интервалах времени измерения. Исходя из этого, были определены следующие параметры ошибок [14]:
- секунда с ошибками (error second, ES) – односекундный интервал, содержащий хотя бы один ошибочный бит;
- секунда, пораженная ошибками (severely error second, SES) – односекундный интервал с BER ≥ 10-3.
Данные параметры ошибок должны оцениваться в течение времени готовности (available time), отсчет которого начинается с первой секунды из десяти следующих друг за другом секунд, в каждой из которых BER<10-3. ITU-T M.2100 регламентирует нормы качества (performance objectives, PO) на выраженные максимальным процентом времени параметры ошибок, которые зависят только от скорости передачи и приводятся для условного эталонного соединения (hypothetical reference connection, HRC/HRX/) длиной 27500 км. При этом нормы качества распределяются по участкам соединения соответствующей категории качества. В качестве эталонной модели такого распределения принимается участок высокой категории качества протяженностью 25000 км, которому присваивается 40% от общей нормы качества на параметры ошибок передачи точка-точка, что в пересчете на 1 км, дает 0.0016 %/км.. Остальные 4 участка (2 среднего качества и 2 с приемлемым качеством) длиной 2 х 1250 км расположены по обе стороны от центрального. Поэтому распределение, пропорциональное протяженности L км тракта высокой категории качества, будет определяться, как
AL = 0.0016 · L %/км. (6.13)
Нормы качества на цифровые тракты и каналы подразделяются на настроечные и эксплуатационные, причем вводимые в эксплуатацию впервые или после проведения корректирующих действий они должны сдаваться по настроечным нормам качества, а в процессе эксплуатации должны соответствовать эксплуатационным нормам. Обычно [105] эксплуатационная норма представляется в виде эталонной нормы качества (reference performance objective, RPO)
RPO = A · T · PO, (6.14)
а настроечная, включающая запас на старение, используемая при вводе в эксплуатацию (bringing into service objective, BISO), определяется, как половина RPO, т.е.
BISO = RPO/2. (6.15)
Здесь PO – норма качества оцениваемого параметра, а T = 86400 с (одни сутки) – продолжительность измерений (количество односекундных интервалов).
Для анализа результатов, полученных в процессе измерений, используются также предельные значения S1и S2 норм (рисунок 6.2), которые соответствуют числу событий (ES,SES) и определяются, как:
S1 = RPO/2 – D и S2 = RPO/2 + D, (6.16)
где D = 2![]() — дисперсия оцениваемого параметра.
— дисперсия оцениваемого параметра.
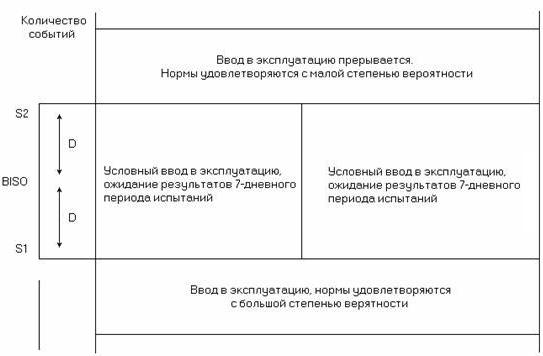
Рисунок 6.2. Предельные значения и условия ввода в эксплуатацию системы передачи
При соответствии результатов измерений норме S1 цифровой тракт может быть введен в эксплуатацию без всякого сомнения, а при превышении нормы S2 в обязательном порядке требуется повышение качества испытываемого цифрового тракта, т.е. должны быть проведены корректирующие действия с повторными измерениями. Если значение ES или SES лежит в интервале от S1 до S2, цифровой тракт может быть введен в эксплуатацию условно или временно с продолжением измерений в течение 7 суток. Данный подход к оценке качества цифровых систем передачи по параметрам ошибок позволяет сократить время измерений и получить норму цифрового тракта суммированием норм цифровых участков. При этом значения RPO, D, S1 и S2 выражаются в виде числа событий за установленный интервал времени, а не в виде процентов времени.
Для измерения коэффициента ошибок разработан ряд специальных BER анализаторов – измерителей коэффициента ошибок, включающих генераторы псевдослучайных и детерминированных последовательностей передаваемых кодированных символов, а также приемное оборудование, осуществляющее собственно измерение коэффициента ошибок. В случае посимвольного сравнения кодов измерение может быть выполнено с использованием шлейфа, т.е. путем измерения ошибок с одной оконечной станции при установке на противоположном конце шлейфа. Другой метод основан на выделении ошибок благодаря избыточности используемых кодов и используется для измерений от передающей до приемной сторон тракта или участка линии, т.е. когда выделение и фиксация ошибок производятся на ее приемном конце. Очевидно, что в первом случае требуется использование одного комплекта, а во втором – двух комплектов приборов. При этом измеренное значение коэффициента ошибок отражает качество передачи при прохождении сигнала в обоих направлениях и в каждом направлении соответственно.
6.4. Принципы построения измерителей ошибок
В зависимости от скорости передачи контролируемой системы передачи в анализаторе используются различные схемотехнические решения.
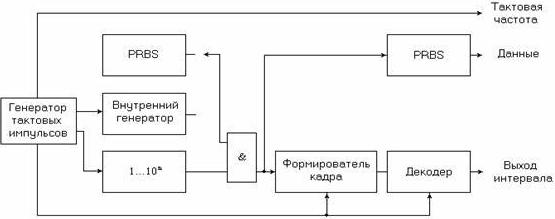
Рисунок 6.3. Генератор низкоскоростного BER анализатора
Низкоскоростной генератор тестовых кодов и детектор ошибок. Используемый в телекоммуникациях анализатор BER, состоящий [106] из генератора тестовых кодов и собственно анализатора ошибок, представлен на рисунках 6.3 и 6.4. Он предназначен для невысоких (до 200 Мбит/с) битовых скоростей, учитывая, что максимальные типовые скорости составляют 44.736 Мбит/с (DS3) в Северной Америке и 139.364 Мбит/с – за пределами Северной Америки.
PRBS с генератором кодовых групп, представленный на рис. 6.16, синхронизируется либо от источника тактового сигнала с фиксированной частотой (согласно G.703), либо от синтезатора, осуществляя тем самым изменение частоты синхронизации. В связи с этим использование данных средств требует задания некоторых определенных частот синхронизации и наличия возможности обеспечения их небольших смещений от ±15 до ±50 ppm. Для повторения тестовых кодов схема PRBS и генератор кодовых групп обычно имеют триггерную схему, управляющую либо выходным усилителем бинарных данных, который обеспечивает данные и данные с сопровождающим синхросигналом, либо выходную схему кодированных данных. Это позволяет создавать цикловую синхронизацию сигнала в соответствии с требованием, например, системы SONET/SDH. Кроме этого, данная схема способствует созданию соответствующего интерфейсного кода для эффективного восстановления тактовой синхронизации. Выходной усилитель обеспечивает необходимый уровень сигнала в соответствии со спецификацией электрического интерфейса, в том числе сигнала с чередованием полярности импульсов.
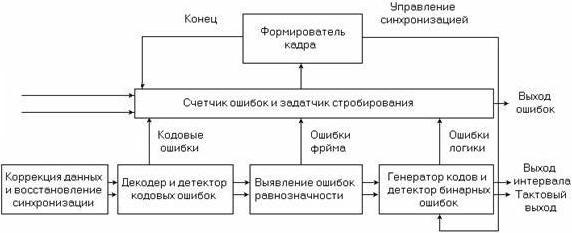
Рисунок 6.4. Низкоскоростной детектор ошибок
Детектор ошибок, показанный на рисунке 6.4, получает стандартный кодированный сигнал, восстанавливает генератор синхросигнала и устраняет кодирование для обеспечения бинарной даты и синхросигналов. Он обнаруживает любые нарушения алгоритма интерфейсного кода и посылает сигналы на счетчик ошибок, что составляет первый уровень процесса обнаружения ошибок. При работе с цикловыми сигналами приемник захватывает любой присутствующий элемент цикловой синхронизации, проверяет наличие цикловых ошибок и декодирует любые встроенные сигналы тревоги, или CRC биты, тем самым обеспечивая возможность измерения.
Наконец, бинарные данные и синхросигнал направляются на детектор ошибок и генератор эталонных тестовых кодов, которые проверяют полученный тестовый код бит за битом на предмет обнаружения логических ошибок. Временная база контролирует пропускание измерения для непрерывного, периодического и ручного режима. Накопленное количество ошибок обрабатывается для получения значения BER и анализа функционирования при наличии ошибок.
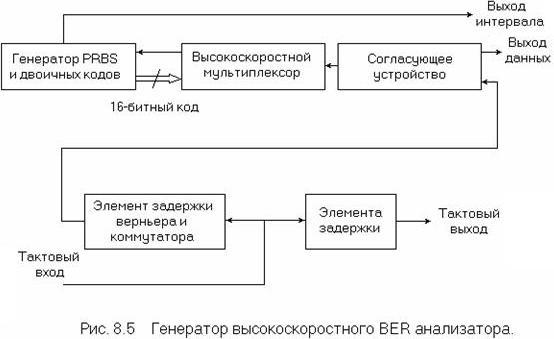
Высокоскоростной генератор тестовых кодов и детектор ошибок. На рисунках 6.5 и 6.6 показаны схемы [14] для 3 Гбит/с генератора тестовых кодов и детектора ошибок. Вследствие высокой битовой скорости генерация последовательных PRBS и кодовых групп на этой скорости не представляется целесообразной. Поэтому тестовые коды генерируются (рисунок 6.5) как параллельные 16-битные кодовые группы при максимальной скорости 200 Мбит/с, используя затем выполненные по биполярной технологии регистраторы смещения и высокоемкостную память. Высокоскоростные схемы обычно выполняются на основе арсенид-галлиевых логических схем, преобразующих параллельные данные в последовательный поток на скорости до 3 Гбит/с.
Согласно данной схеме, вход синхросигнала генерируется синтезатором частоты, согласующее устройство управляется через линию фиксированной задержки, а генератор тестовых кодов и выходной усилитель синхронизируются через схему дискретной и плавно изменяемой задержки, так что фаза синхросигнала/данных может изменяться как в положительном направлении, так и в отрицательном. Дискретные значения задержки составляют 250, 500 и 1000 пс, тогда как диапазон плавной задержки лежит в пределах от 0 до 250 пс с 1 пс инкрементом.
Корректор временной диаграммы, связанный с выходным усилителем, пересинхронизирует данные через триггер D типа для поддержания минимального фазового дрожания. Так как подобный тип тестового устройства обычно используется при проведении лабораторных измерений, выходные уровни синхросигнала и данных и постоянные смещения могут варьироваться для того или иного конкретного случая использования.
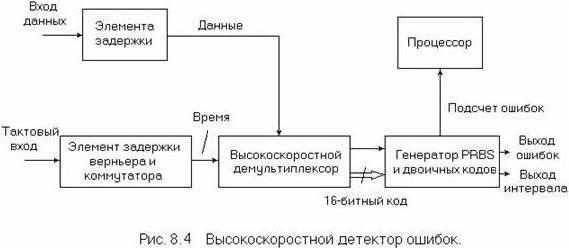
Детектор ошибок, показанный на рис. 6.6, имеет простое параллельное соединение, в связи с чем входы синхросигнала и данных проходят через схемы дискретной и плавной задержки, обеспечивая оптимальную настройку при обнаружении ошибок для любой фазы синхросигнала/данных. Действительно, путем настройки под контролем внутреннего процессора решающего порога и фазы синхросигнала условия функционирования детектора ошибок могут быть оптимизированы автоматически. Высокоскоростной демультиплексор преобразует последовательный поток данных в 16-битные параллельные кодовые группы наряду с поделенным на 16 синхросигналом. Параллельно соединенный генератор эталонных тестовых кодов синхронизируется с входными данными и осуществляет сравнение битов, поэтому любая ошибка фиксируется одним из двух счетчиков, первый из которых подсчитывает число ошибок, а второй – общее число битов. Процессор измерения обеспечивает анализ функционирования при наличии ошибок с разрешением до 1 мс.
6.5. Техника измерения коэффициента ошибок
Рассмотрим измерение коэффициента ошибок путем посимвольного сравнения и подсчета ошибочно принятых элементарных импульсов. Для этого вначале (перед измерением) на передающей станции с помощью оптического аттенюатора устанавливают заданный в технических условиях на аппаратуру линейного тракта уровень оптического излучения. Затем на передающем конце подключают генератор испытательных сигналов, а на приемном – измеритель коэффициента ошибок и, изменяя значения уровней средней мощности, измеряют коэффициент ошибок. Время измерения определяют в зависимости от скорости передачи, объема информации и значений коэффициента ошибок Кошi (BERi).
Коэффициент ошибок при заданном уровне оптического излучения вычисляют по формуле [14]
![]() (6.17)
(6.17)
где
![]() ,
, 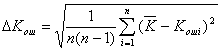 , (6.18)
, (6.18)
где ![]() и
и ![]() — погрешность и среднее значение коэффициента ошибок при пяти и более измерениях с интервалом 3 мин, соответственно, a — коэффициент, учитывающий наличие погрешности измерения при проведении n измерений.
— погрешность и среднее значение коэффициента ошибок при пяти и более измерениях с интервалом 3 мин, соответственно, a — коэффициент, учитывающий наличие погрешности измерения при проведении n измерений.
Вероятность ошибки является основным показателем качества распознавания образов, и поэтому её оценивание представляет собой очень важную задачу. Вероятность ошибки есть сложная функция, представляющая собой n-кратный интеграл от плотности вероятности при наличии сложной границы. Поэтому при её вычислении часто приходится обращаться к экспериментальным методам.
При оценке вероятности ошибки рассматривают две задачи. Первая из них состоит в оценивании вероятности ошибки по имеющейся выборке в предположении, что задан классификатор [3].
Вторая задача заключается в оценке вероятности ошибки при заданных распределениях. Для этой ошибки вероятность ошибки зависит как от используемого классификатора, так и от вида распределения. Поскольку в распоряжении имеется конечное число объектов, нельзя построить оптимальный классификатор. Поэтому параметры такого классификатора представляют собой случайные величины [3].
Оценка вероятности ошибки для заданного классификатора.
1) Неизвестны априорные вероятности — случайная выборка.
Предположим, что заданы распределения обоих классов и классификатор. Задача заключается в оценивании вероятности ошибки по N объектам, полученным в соответствии с этими распределениями.
Когда неизвестны априорные вероятности P(Ci), i=1, 2, то можно случайно извлечь N объектов и проверить, даёт ли данный классификатор правильные решения для этих объектов. Такие объекты называют случайной выборкой.
Пусть ф — число объектов, неправильно классифицированных в результате этого эксперимента. Величина ф есть дискретная случайная величина. Обозначим истинную вероятность ошибки через е. Распределение значений величины ф является биномиальным:

. (1.64)
Оценка максимального правдоподобия из уравнения (1.56) равна

, (1.65)
т.е. оценка максимального правдоподобия равна отношению числа неправильно классифицированных объектов к общему числу объектов.
Математическое ожидание и дисперсия биномиального распределения соответственно равны

, (1.66)

. (1.67)
Таким образом, оценка является несмещённой.
2) Известны априорные вероятности — селективная выборка.
Если известны априорные вероятности классов P(Ci), i=1, 2, то можно извлечь N1=P(C1)N и N2=P(C2)N объектов соответственно и проверить их с помощью заданного классификатора. Такой процесс известен как селективная выборка. Пусть ф1 и ф2 — число неправильно классифицированных объектов соответственно из классов C1 и C2. Поскольку ф1 и ф2 взаимно независимы, то совместная плотность вероятности ф1 и ф2 будет равна
 , (1.68)
, (1.68)
где еi — истинная вероятность ошибки для класса Ci. В этом случае оценка максимального правдоподобия равна

. (1.69)
Математическое ожидание и дисперсия оценки соответственно

, (1.70)

. (1.71)
Таким образом, оценка (1.69) также несмещённая.
Нетрудно показать, что дисперсия (1.71) меньше, чем дисперсия (1.67). Это естественный результат, поскольку в случае селективной выборки используется априорная информация.
Изложенное выше легко обобщить на случай M классов. Для этого надо лишь изменить верхние пределы у сумм и произведений в формулах (1.68) — (1.71) с 2 на M.
Оценка вероятности ошибки, когда классификатор заранее не задан.
Когда даны N объектов в случае отсутствия классификатора, то можно использовать эти объекты как для проектирования классификатора, так и для проверки его качества. Очевидно, оцениваемая вероятность ошибки зависит от данных распределений и используемого классификатора.
Предположим, что всегда используется байесовский классификатор, минимизирующий вероятность ошибки. Тогда минимальную вероятность ошибки байесовского классификатора, которую необходимо оценить, можно рассматривать как фиксированный параметр при заданных распределениях. Кроме того, эта вероятность является минимальной для данных распределений.
Как правило, вероятность ошибки есть функция двух аргументов:
е (И1, И2), (1.72)
где И1 — множество параметров распределений, используемых для синтеза байесовского классификатора, а И2 — множество параметров распределений, используемых для проверки его качества.
Оптимальная классификация объектов, характеризуемых распределением с параметром И2, осуществляется байесовским классификатором, который построен для распределения с параметром И2. Поэтому
е (И2, И2) ? е (И1, И2). (1.73)
Пусть для данной задачи И — вектор истинных параметров, а — его оценка. Таким образом, оценка является случайным вектором и е0=е (И, И). Для любого конкретного значения оценки на основании (1.73) справедливы неравенства

, (1.74)

. (1.75)
Выполнив над обеими частями неравенств (1.74) и (1.75) операцию математического ожидания, получим

, (1.76)

. (1.77)
Если

, (1.78)
то для вероятности ошибки байесовского классификатора имеет место двустороннее ограничение

. (1.79)
Левое неравенство (1.79) основано на предположении (1.78) и не доказано для произвольных истинных плотностей вероятности. Однако это неравенство можно проверить многими экспериментальными способами. Из выражения (1.5) видно, что равенство (1.78) выполняется тогда, когда оценка проверяемой плотности вероятности, основанная на N наблюдениях, является несмещённой и классификатор заранее фиксирован. Следует отметить, что нижняя граница менее важна, чем верхняя.

Обе границы вероятности ошибки можно интерпретировать следующим образом:

1) : одни и те же N объектов используются и для синтеза байесовского классификатора, и для последующей классификации. Этот случай назовём C-методом. Из (1.79) следует, что C-метод даёт, вообще говоря, заниженную оценку вероятности ошибки.

2) : для синтеза байесовского классификатора используются N объектов, а классифицируются объекты из истинных распределений. Эту процедуру называют U-методом. U-метод также даёт смещённую оценку вероятности ошибки е0. Это смещение таково, что его математическое ожидание является верхней границей вероятности ошибки. Объекты из истинного распределения могут быть заменены объектами, которые не были использованы для синтеза классификатора и независимы от объектов, по которым классификатор был синтезирован. Когда число классифицируемых объектов увеличивается, их распределение стремится к истинному распределению.
Для реализации U-метода имеется много возможностей. Рассмотрим две типовые процедуры.
1. Метод разбиения выборки. Вначале имеющиеся объекты разбивают на две группы и используют одну из них для синтеза классификатора, а другую — для проверки его качества. Основной вопрос, характерный для этого метода, заключается в том, как разделить объекты.


2. Метод скользящего распознавания. Во втором методе попытаемся использовать имеющиеся объекты более эффективно, чем в методе разбиения выборки. Для оценки необходимо, вообще говоря, извлечь много выборок объектов и синтезировать большое количество классификаторов, проверить качество каждого классификатора с помощью неиспользованных объектов и определить среднее значение показателя качества. Подобная процедура может быть выполнена путём использования только имеющихся N объектов следующим образом. Исключая один объект, синтезируется классификатор по имеющимся N-1 объектам, и классифицируется неиспользованный объект. Затем эту процедуру повторяют N раз и подсчитывают число неправильно классифицированных объектов. Этот метод позволяет более эффективно использовать имеющиеся объекты и оценивать . Один из недостатков этого метода заключается в том, что приходится синтезировать N классификаторов.
Метод разбиения выборки.
Для того, чтобы разбить имеющиеся объекты на обучающую и экзаменационную выборки, изучим, как это разбиение влияет на дисперсию оценки вероятности ошибки.
Вначале предположим, что имеется бесконечное число объектов для синтеза классификатора и N объектов для проверки его качества. При бесконечном числе объектов синтезируемый классификатор является классификатором для истинных распределений, и его вклад в дисперсию равен нулю. Для фиксированного классификатора организуем селективную выборку. В этом случае распределение оценки подчиняется биномиальному закону с дисперсией

, (1.80)
где еi — истинная вероятность ошибки для i-го класса.
С другой стороны, если имеется N объектов для синтеза классификатора и бесконечное число экзаменационных объектов, то оценка вероятности ошибки выражается следующим образом:

, (1.81)
где Гi — область пространства признаков, соответствующая i-му классу. В этом случае подынтегральные выражения постоянны, но граница этих областей изменяется в зависимости от выборки из N объектов.
Дисперсию оценки вычислить сложно. Однако в случае нормальных распределений с равными корреляционными матрицами интегралы в (1.81) можно привести к одномерным интегралам

,(1.81)
где зi и у2i определяются условными математическими ожиданиями:

,(1.82)

,(1.83)

. (1.84)
Это преобразование основано на том, что для нормальных распределений с равными корреляционными матрицами байесовский классификатор — линейный, а распределение отношения правдоподобия также является нормальным распределением.
Следует заметить, что даже если две истинные корреляционные матрицы равны, то оценки их различны. Однако для простоты предположим, что обе эти оценки равны и имеют вид

, (1.85)
где Ni — число объектов x(i)j класса i, используемых для синтеза классификатора.
Выражение для математического ожидания оценки достаточно громоздкое, здесь приводится простейший случай, когда P(C1)=P(C2) и N1=N2:

, (1.86)

, (1.87)
где d — расстояние между двумя векторами математических ожиданий, определяемое по формуле

. (1.88)
Величина е0 является минимальной вероятностью ошибки байесовского классификатора. Так как е0 — минимальное значение оценки , то распределение для является причинным Причинным распределением называется распределение p(x)=д(x-о), где д(x-о) — дельта-функция.. Поэтому можно определить оценку дисперсии величины, основанную на её математическом ожидании. Предположим, что плотность вероятности является плотностью вероятности гамма-распределения, которое включает в себя широкий класс причинных распределений. Тогда

(1.89)
при Де>0 (b?0 и c>0).
Математическое ожидание и дисперсия плотности вероятности (1.89) соответственно равны

, (1.90)

. (1.91)
Исключив c, получим верхнюю границу дисперсии , т.е.

(1.91)
при b ? 0.
Таким образом, степень влияния числа обучающих объектов на оценку вероятности ошибки е0 в случае нормальных распределений с равными корреляционными матрицами и равными априорными вероятностями равна

. (1.92)
Величину sэксп следует сравнивать с величиной sтеор, которая характеризует влияние числа объектов в экзаменационной выборке на оценку вероятности ошибки. Значение sтеор получается подстановкой в формулу (1.80) значений P(C1) = P(C2) =0.5 и е1 = е2 = е0:

. (1.93)
Исключение задания класса для объектов экзаменационной выборки.
Для того, чтобы оценить вероятность ошибки как при обучении, так и на экзамене, требуются выборки объектов, в которых известно, какой объект к какому конкретному классу принадлежит. Однако в некоторых случаях получение такой информации связано с большими затратами.
Рассмотрим метод оценки вероятности ошибки, не требующий информации о принадлежности объектов экзаменационной выборки к конкретному классу. Применение этого метода наиболее эффективно в случае, когда при оптимальном разбиении выборки на обучающую и экзаменационную число объектов в экзаменационной выборке больше, чем в обучающей.
Введём критическую область для задач классификации M классов:
,(1.94)

где P(x) — плотность вероятности смеси, t — критический уровень, 0 ? t ? 1. Условие (1.94) устанавливает, что если для данного объекта x значения P(C1)p(x/C1), вычисленные для каждого класса Mi, не превышают величины (1-t)p(x), то объект х не классифицируют вообще; в противном случае объект x классифицируют и относят его к i-му классу. Таким образом, вся область значений x делится на критическую область Гr(t) и допустимую область Гa(t), причём размеры обеих областей являются функциями критического уровня t.
При таком решающем правиле вероятность ошибки е(t), коэффициент отклонения r(t) и коэффициент правильного распознавания c(t) будут равны

, (1.95)

, (1.96)
е(t) = 1 — c(t) — r(t). (1.97)
Предположим, что область отклонения увеличивается на Гr(t) за счёт замены значения t на t-Дt. Тогда те x, которые раньше классифицировались правильно, теперь отклоняются:

(1.98)
при xДГr(t). Интегрируя (1.98) в пределах области ДГr(t), получим
(1 — t)Дr(t) ? -Дc(t) < (1 — t+Дt)Дr(t), (1.99)
где Дr(t) и Дc(t) — приращения r(t) и c(t), вызванные изменениями t. Из формулы (1.97) следует, что неравенство (1.99) можно переписать следующим образом:
— tДr(t) ? Де(t) < -У(t — Дt)Дr(t). (1.100)
Полагая Дt>0, получаем интеграл Стилтьеса

. (1.101)
Уравнение (1.101) показывает, что вероятность ошибки е(t) может быть вычислена после того, как установлена зависимость между значениями t и r(t). Из решающего правила (1.94) следует, что при t = 1-1/M область отклонения отсутствует, так что байесовская ошибка е0= е(1-1/M). Кроме того, из формулы (1.101) можно установить взаимосвязь между вероятностью ошибки и коэффициентом отклонения, так как изменение вероятности ошибки можно вычислить как функцию от изменения коэффициента отклонения.
Воспользуемся выражением (1.94) для исключения задания класса объектов экзаменационной выборки. Для этого поступим следующим образом.
1. Для определения ДГr(kt0) при t = kt0, k = 0, 1, …, m = (1-1/M)t0, где t0 — дискретный шаг переменной t, будем использовать относительно дорогостоящие классифицируемые объекты.
2. Подсчитаем число неклассифицированных объектов экзаменационной выборки, которые попали в область ДГr(kt0), разделим это число на общее число объектов и обозначим полученное соотношение через Дr(kt0).
3. Тогда из выражения (1.94) следует, что оценка вероятности ошибки

. (1.102)
В описанной процедуре использовалось то, что коэффициент отклонения является функцией от плотности вероятности смеси, а не от плотностей вероятности отдельных классов. Поэтому после того, как по классифицированным объектам найдены расширенные области отклонения, в дальнейшем для оценивания Дr(t) и вероятности ошибки е(t) нет необходимости использовать классифицированные объекты.
В цифровой передаче , количество битовых ошибок является количеством принятых бит одного потока данных над каналом связи , которые были изменены из — за шум , помехи , искажений или битой синхронизацию ошибок.
Коэффициент битовых ошибок ( BER ) — это количество битовых ошибок в единицу времени. Коэффициент битовых ошибок (также BER ) — это количество битовых ошибок, деленное на общее количество переданных битов за исследуемый интервал времени. Коэффициент битовых ошибок — это безразмерная мера производительности, часто выражаемая в процентах .
Бита вероятность ошибка р е является ожидаемым значением коэффициента ошибок по битам. Коэффициент битовых ошибок можно рассматривать как приблизительную оценку вероятности битовых ошибок. Эта оценка точна для длительного интервала времени и большого количества битовых ошибок.
Пример
В качестве примера предположим, что эта переданная битовая последовательность:
0 1 1 0 0 0 1 0 1 1
и следующая полученная битовая последовательность:
0 0 1 0 1 0 1 0 0 1,
Количество битовых ошибок (подчеркнутые биты) в этом случае равно 3. BER — это 3 неверных бита, разделенных на 10 переданных битов, в результате чего BER составляет 0,3 или 30%.
Коэффициент ошибок пакета
Коэффициент ошибок пакетов (PER) — это количество неправильно принятых пакетов данных, деленное на общее количество принятых пакетов. Пакет объявляется некорректным, если хотя бы один бит ошибочен. Ожидаемое значение PER обозначается вероятностью ошибки пакета p p , которая для длины пакета данных N бит может быть выражена как
-
 ,
,

предполагая, что битовые ошибки не зависят друг от друга. Для малых вероятностей битовых ошибок и больших пакетов данных это примерно

Подобные измерения могут быть выполнены для передачи кадров , блоков или символов .
Факторы, влияющие на BER
В системе связи на BER на стороне приемника могут влиять шум канала передачи , помехи , искажения , проблемы битовой синхронизации , затухание , замирания из-за многолучевого распространения беспроводной связи и т. Д.
BER может быть улучшен путем выбора сильного уровня сигнала (если это не вызывает перекрестных помех и большего количества битовых ошибок), путем выбора медленной и надежной схемы модуляции или схемы линейного кодирования , а также путем применения схем канального кодирования , таких как избыточные коды прямого исправления ошибок. .
КОБ передачи является количество обнаруженных битов , которые являются неправильными до коррекции ошибок, разделенных на общее количество переданных битов ( в том числе избыточных кодов ошибок). Информация КОБ , примерно равна вероятности ошибки декодирования , это число декодированных битов , которые остаются неправильно после коррекции ошибок, деленное на общее число декодированных битов (полезная информация). Обычно BER передачи больше, чем BER информации. На информационный BER влияет сила кода прямого исправления ошибок.
Анализ BER
BER можно оценить с помощью стохастического ( Монте-Карло ) компьютерного моделирования. Если предполагается простая модель канала передачи и модель источника данных , BER также может быть вычислен аналитически. Примером такой модели источника данных является источник Бернулли .
Примеры простых моделей каналов, используемых в теории информации :
- Двоичный симметричный канал (используется при анализе вероятности ошибки декодирования в случае непакетных битовых ошибок в канале передачи)
- Канал аддитивного белого гауссова шума (AWGN) без замирания.
Наихудший сценарий — это полностью случайный канал, в котором шум полностью преобладает над полезным сигналом. Это приводит к BER передачи 50% (при условии, что предполагается источник двоичных данных Бернулли и двоичный симметричный канал, см. Ниже).
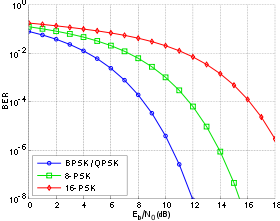

В канале с шумом BER часто выражается как функция нормированного показателя отношения несущей к шуму, обозначаемого Eb / N0 (отношение энергии на бит к спектральной плотности мощности шума) или Es / N0 (энергия на символ модуляции для спектральная плотность шума).
Например, в случае QPSK модуляции и канал АБГШ, КОБ в зависимости от Eb / N0 определяется по формуле:
.

Люди обычно строят кривые BER для описания производительности цифровой системы связи. В оптической связи обычно используется зависимость BER (дБ) от принимаемой мощности (дБм); в то время как в беспроводной связи используется BER (дБ) по сравнению с SNR (дБ).
Измерение коэффициента ошибок по битам помогает людям выбрать подходящие коды прямого исправления ошибок. Поскольку большинство таких кодов исправляют только перевороты битов, но не вставки или удаления битов, метрика расстояния Хэмминга является подходящим способом измерения количества битовых ошибок. Многие кодеры FEC также непрерывно измеряют текущий BER.
Более общий способ измерения количества битовых ошибок — это расстояние Левенштейна . Измерение расстояния Левенштейна больше подходит для измерения характеристик сырого канала перед кадровой синхронизацией , а также при использовании кодов коррекции ошибок, предназначенных для исправления вставки и удаления битов, таких как коды маркеров и коды водяных знаков.
Математический проект
BER — это вероятность неправильной интерпретации из-за электрического шума . Рассматривая биполярную передачу NRZ, мы имеем

 для «1» и для «0». Каждый из и имеет период .
для «1» и для «0». Каждый из и имеет период .




Зная, что шум имеет двустороннюю спектральную плотность ,

является 
и есть .

Возвращаясь к BER, у нас есть вероятность неправильного толкования .

 и
и 
где — порог принятия решения, установленный в 0, когда .


Мы можем использовать среднюю энергию сигнала, чтобы найти окончательное выражение:


± §
Проверка коэффициента битовых ошибок
BERT или тест на частоту ошибок по битам — это метод тестирования схем цифровой связи, в котором используются заранее определенные шаблоны нагрузки, состоящие из последовательности логических единиц и нулей, сгенерированных генератором тестовых шаблонов.
BERT обычно состоит из генератора тестовых шаблонов и приемника, который может быть настроен на один и тот же шаблон. Их можно использовать парами, по одному на любом конце линии передачи, или по отдельности на одном конце с кольцевой проверкой на удаленном конце. BERT обычно представляют собой автономные специализированные инструменты, но могут быть основаны на персональном компьютере . При использовании количество ошибок, если таковые имеются, подсчитывается и представляется в виде отношения, например 1 на 1 000 000 или 1 на 1e06.
Распространенные типы стресс-паттернов BERT
- PRBS ( псевдослучайная двоичная последовательность ) — псевдослучайный двоичный секвенсор из N бит. Эти последовательности шаблонов используются для измерения джиттера и глаз-маски TX-данных в электрических и оптических каналах передачи данных.
- QRSS (квазислучайный источник сигнала) — псевдослучайный двоичный секвенсор, который генерирует каждую комбинацию 20-битного слова, повторяет каждые 1048 575 слов и подавляет последовательные нули не более чем до 14. Он содержит последовательности с высокой плотностью, последовательности с низкой плотностью, и последовательности, которые меняются от низкого к высокому и наоборот. Этот шаблон также является стандартным шаблоном, используемым для измерения джиттера.
- 3 из 24 — шаблон содержит самую длинную строку последовательных нулей (15) с самой низкой плотностью (12,5%). Этот шаблон одновременно подчеркивает минимальную плотность единиц и максимальное количество последовательных нулей. Формат кадра D4 3 из 24 может вызвать желтый аварийный сигнал D4 для цепей кадра в зависимости от выравнивания одного бита с кадром.
- 1: 7 — Также упоминается как 1 из 8 . Он имеет только один в восьмибитной повторяющейся последовательности. Этот шаблон подчеркивает минимальную плотность 12,5% и должен использоваться при тестировании средств, установленных для кодирования B8ZS, поскольку шаблон 3 из 24 увеличивается до 29,5% при преобразовании в B8ZS.
- Мин. / Макс. — последовательность быстрого перехода узора с низкой плотности на высокую. Наиболее полезно при усилении функции ALBO ретранслятора .
- Все единицы (или отметка) — шаблон, состоящий только из единиц. Этот шаблон заставляет повторитель потреблять максимальное количество энергии. Если постоянный ток к ретранслятору отрегулирован должным образом, ретранслятор не будет иметь проблем с передачей длинной последовательности. Этот образец следует использовать при измерении регулирования мощности диапазона. Шаблон «все единицы без рамки» используется для обозначения AIS (также известного как синий сигнал тревоги ).
- Все нули — шаблон, состоящий только из нулей. Это эффективно при поиске оборудования, неправильно настроенного для AMI , такого как низкоскоростные входы мультиплексного волокна / радио.
- Чередование нулей и единиц — шаблон, состоящий из чередующихся единиц и нулей.
- 2 из 8 — шаблон содержит не более четырех последовательных нулей. Он не вызовет последовательность B8ZS, потому что для подстановки B8ZS требуется восемь последовательных нулей. Схема эффективна при поиске оборудования, не использованного для B8ZS.
- Bridgetap — разветвления моста в пределах пролета можно обнаружить с помощью ряда тестовых шаблонов с различной плотностью единиц и нулей. Этот тест генерирует 21 тестовую таблицу и длится 15 минут. Если возникает ошибка сигнала, на участке может быть один или несколько ответвлений моста. Этот шаблон эффективен только для участков T1, которые передают необработанный сигнал. Модуляция, используемая в пролетах HDSL, сводит на нет способность шаблонов моста обнаруживать ответвления моста.
- Multipat — этот тест генерирует пять часто используемых тестовых шаблонов, позволяющих проводить тестирование диапазона DS1 без необходимости выбирать каждый тестовый шаблон отдельно. Шаблоны: все единицы, 1: 7, 2 из 8, 3 из 24 и QRSS.
- T1-DALY и 55 OCTET — Каждый из этих шаблонов содержит пятьдесят пять (55) восьмибитовых октетов данных в последовательности, которая быстро изменяется между низкой и высокой плотностью. Эти паттерны используются в основном для нагрузки на схему ALBO и эквалайзера, но они также усиливают восстановление синхронизации. 55 OCTET имеет пятнадцать (15) последовательных нулей и может использоваться только без рамки без нарушения требований к плотности. Для сигналов с фреймами следует использовать шаблон T1-DALY. Оба шаблона вызовут код B8ZS в схемах с опцией для B8ZS.
Тестер коэффициента битовых ошибок
Тестер коэффициента ошибок по битам (BERT), также известный как «тестер коэффициента ошибок по битам» или решение для тестирования коэффициента ошибок по битам (BERT), представляет собой электронное испытательное оборудование, используемое для проверки качества передачи сигнала отдельных компонентов или целых систем.
Основные строительные блоки BERT:
- Генератор шаблонов , который передает определенный тестовый шаблон в ИУ или тестовую систему.
- Детектор ошибок, подключенный к DUT или тестовой системе, для подсчета ошибок, генерируемых DUT или тестовой системой.
- Генератор тактовых сигналов для синхронизации генератора шаблонов и детектора ошибок
- Анализатор цифровой связи не является обязательным для отображения переданного или принятого сигнала.
- Электрооптический преобразователь и оптико-электрический преобразователь для проверки сигналов оптической связи.
Смотрите также
- Пакетная ошибка
- Код исправления ошибок
- Секунда с ошибкой
- Частота ошибок Витерби
использованная литература
![]() Эта статья включает материалы, являющиеся общественным достоянием, из документа Управления общих служб : «Федеральный стандарт 1037C» .(в поддержку MIL-STD-188 )
Эта статья включает материалы, являющиеся общественным достоянием, из документа Управления общих служб : «Федеральный стандарт 1037C» .(в поддержку MIL-STD-188 )
внешние ссылки
- QPSK BER для канала AWGN — онлайн-эксперимент