
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Prerequisite – TCP/IP Model
TCP protocol has methods for finding out corrupted segments, missing segments, out-of-order segments and duplicated segments.
Error control in TCP is mainly done through the use of three simple techniques :
- Checksum – Every segment contains a checksum field which is used to find corrupted segments. If the segment is corrupted, then that segment is discarded by the destination TCP and is considered lost.
- Acknowledgement – TCP has another mechanism called acknowledgement to affirm that the data segments have been delivered. Control segments that contain no data but have sequence numbers will be acknowledged as well but ACK segments are not acknowledged.
- Retransmission – When a segment is missing, delayed to deliver to a receiver, corrupted when it is checked by the receiver then that segment is retransmitted again. Segments are retransmitted only during two events: when the sender receives three duplicate acknowledgements (ACK) or when a retransmission timer expires.
- Retransmission after RTO: TCP always preserves one retransmission time-out (RTO) timer for all sent but not acknowledged segments. When the timer runs out of time, the earliest segment is retransmitted. Here no timer is set for acknowledgement. In TCP, the RTO value is dynamic in nature and it is updated using the round trip time (RTT) of segments. RTT is the time duration needed for a segment to reach the receiver and an acknowledgement to be received by the sender.
- Retransmission after Three duplicate ACK segments: RTO method works well when the value of RTO is small. If it is large, more time is needed to get confirmation about whether a segment has been delivered or not. Sometimes one segment is lost and the receiver receives so many out-of-order segments that they cannot be saved. In order to solve this situation, three duplicate acknowledgement method is used and missing segment is retransmitted immediately instead of retransmitting already delivered segment. This is a fast retransmission because it makes it possible to quickly retransmit lost segments instead of waiting for timer to end.
This article is contributed by Swasthik. If you like GeeksforGeeks and would like to contribute, you can also write an article using write.geeksforgeeks.org or mail your article to review-team@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks.
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Last Updated :
13 Jun, 2022
Like Article
Save Article
Курс лекций по сетевым технологиям. Часть I 1
Уровни модели OSI
Прикладной уровень
Виды сервиса прикладного уровня
Функции управления сетями на прикладном уровне
Уровень представления данных
Сеансовый уровень
Транспортный уровень
Сетевой уровень
Канальный уровень
Контроль ошибок на канальном уровне
Основные протоколы канального уровня
Физический уровень
Подведем краткие итоги
Прежде чем приступить к рассмотрению технологий, давайте вспомним некоторые
базовые понятия, на которых основываются все сетевые процессы и взаимодействия.
Во-первых, это модель OSI.
Уровни модели OSI
В настоящее время общепринятой является семиуровневая модель архитектуры открытых
систем (Open System Interconnection). В этой модели рассматриваются:
- Уровень 1. Физический уровень (управление физическим каналом).
- Уровень 2. Канальный уровень (управление информационным каналом).
- Уровень 3. Сетевой уровень (управление сетью).
- Уровень 4. Транспортный уровень (управление передачей).
- Уровень 5. Сеансовый уровень (управление сеансом).
- Уровень 6. Представительный уровень (управление представлением).
- Уровень 7. Прикладной уровень (управление сервисом).
Какие же задачи решаются на различных уровнях протоколов открытых систем? Рассмотрим
этот вопрос несколько подробнее.
|
|
Прикладной уровень
В модели OSI прикладная программа, которой нужно выполнить конкретную задачу
(например, обновить базу данных на компьютере В), посылает конкретные данные
в виде дейтаграммы на прикладной уровень. Одна из основных «обязанностей» этого
уровня — определить, как следует обрабатывать запрос прикладной программы, иными
словами — какой вид должен принять данный запрос. Если в запросе прикладной
программы определен, например, дистанционный ввод заданий, то это потребует
работы нескольких программ, которые будут собирать информацию, организовывать
ее, обрабатывать и посылать по соответствующему адресу. Еще одна важная функция
прикладного уровня — электронная почта.
|
|
Виды сервиса прикладного уровня
Прикладной уровень содержит несколько так называемых общих элементов прикладного
сервиса (ACSE — Application Common Service Elements) и специальных элементов
прикладного сервиса (SASE — Specific Application Service Elements). Сервисы
ACSE предоставляются прикладным процессам во всех системах. Они включают, например,
требование определенных параметров качества сервиса.
Допустим, необходимо установить связь через модем по глобальной сети между
рабочей станцией локальной сети в Лос-Анджелесе и мэйнфреймом в Бостоне. Поскольку
качество телефонной линии иногда оказывается неудовлетворительным, прикладной
процесс, работающий в ЛВС, может запросить такое качество сервиса, которое предусматривает
подтверждение приема и распознавания информации.
(Если провести аналогию с почтой, то указанное действие равносильно требованию,
чтобы доставка вашей посылки подтверждалась квитанцией.)
Специальные элементы прикладного сервиса (SASE) обеспечивают сервис для конкретных
прикладных программ, таких как программы пересылки файлов и эмуляции терминалов.
Если, например, прикладной программе необходимо переслать файлы, то обязательно
будет использован протокол передачи, доступа и управления файлами (FTAM — File
Transfer, Access and Management), являющийся одним из ключевых протоколов прикладного
уровня.
Давайте на минутку заглянем в будущее, когда локальные сети и мэйнфреймы станут
работать с OSI-совместимым программным обеспечением. Поскольку FTAM работает
как виртуальный банк файлов и имеет собственную службу каталогов, то программы
смогут получать доступ к базам данных, не имея информации о фактическом местонахождении
файла. Поскольку FTAM поддерживает широкое разнообразие различных типов структур,
включая последовательную, упорядоченную иерархическую и общую иерархическую,
то информация из базы данных, расположенной на удаленном Unisys-компьютере,
будет использоваться для обновления другой базы данных, работающей в локальной
сети в другом городе. Данные из первой базы, в свою очередь, будут обновляться
на основе информации, взятой из третьей базы данных, размещенной на IBM-мэйнфрейме.
Еще одна важная составляющая SASE прикладного уровня — сервис виртуального
терминала (VT — Virtual Terminal). VT — это сложный сервис, который освобождает
компьютер от необходимости посылать соответствующие сигналы для обращения ко
всем терминалам, подключенным ко второму компьютеру. Первый компьютер может
использовать набор параметров виртуального терминала, а решение вопросов конкретизации
конфигурации терминалов можно предоставить второму компьютеру.
На разных этапах разработки находятся еще несколько SASE: обработка транзакций
(trunks actions), электронный обмен данными (EDI — Electronic Data Interchange),
передача и обработка заданий (JTM — Job Transfer and Manipulation). Разработка
стандарта OSI на EDI, в частности, очень важна для пользователей ЛВС. Например,
на рабочей станции ЛВС можно составить заказ на покупку и передать эту информацию
по сети непосредственно изготовителю или продавцу, где данные будут автоматически
внесены в счет-фактуру. Можно проверять и автоматически корректировать инвентаризационные
ведомости, можно заключать договора на поставку товаров — и все это без бумаг
и волокиты.
|
|
Функции управления сетями на прикладном уровне
По мере усложнения информационных сетей вопрос административного управления
ими приобретает все большее значение. Поскольку сейчас любые системы передачи
информации позволяют обрабатывать и передавать также и речевые данные, а локальные
сети все теснее связываются с глобальными сетями и мэйнфреймами, то все очевиднее
необходимость в разработке эффективного метода организации этой информации и
управления ею. Фирма IBM в качестве решения предложила свои системы NetView
и NetView/PC, a Hewlett-Packard вышла на рынок с пакетом прикладных программ
OpenView.
На сегодняшний день проблема заключается в том, что при наличии нескольких
решений нет международного стандарта по управлению сетями. Для прикладного уровня
модели OSI существует несколько спецификаций информационно-управляющих протоколов,
которые претендуют на то, чтобы в будущем стать международными стандартами.
Вопросы, касающиеся разработки международных стандартов по управлению сетями,
будут рассмотрены позже.
|
|
Уровень представления данных
Уровень представления данных отвечает за физическое отображение (представление)
информации. Так, в полях базы данных информация должна быть представлена в виде
букв и цифр, а зачастую — и графических изображений. Обрабатывать же эти данные
нужно, например, как числа с плавающей запятой.
Уровень представления данных обеспечивает возможность передачи данных с гарантией,
что прикладные процессы, осуществляющие обмен информацией, смогут преодолеть
любые синтаксические различия. Для того чтобы обмен имел место, эти два процесса
должны использовать общее представление данных или язык.
Важность уровня представления данных заключается в том, что в основу его работы
положена единая для всех уровней модели OSI система обозначений для описания
абстрактного синтаксиса — ASN.1. Эта система служит для описания структуры файлов.
На прикладном уровне система ASN.1 применяется и для выполнения всех операций
пересылки файлов, и при работе с виртуальным терминалом. Использование этой
системы позволяет также решить одну из важнейших проблем, возникающих при управлении
крупными сетями, — проблему шифрования данных. Шифрование данных с помощью ASN.1
можно выполнять на уровне представления данных; разработка стандарта OSI для
этого уровня окажет значительное влияние на обеспечение межмашинной связи.
|
|
Сеансовый уровень
Представьте себе опытного администратора, отвечающего за подготовку и согласование
всех деталей предстоящей важной встречи двух высокопоставленных руководителей.
Если он действует правильно, встреча проходит четко и организованно. Аналогично
и работа сеансового уровня обеспечивает проведение сеанса и в конечном итоге
обмен информацией между двумя прикладными процессами.
Сеансовый уровень отвечает за такие серьезные вопросы, как режим передачи и
установка точек синхронизации. Иными словами, на этом уровне определяется, какой
будет передача между двумя прикладными процессами: полудуплексной (процессы
будут передавать и принимать данные по очереди) или дуплексной (процессы будут
передавать и принимать данные одновременно). В полудуплексном режиме сеансовый
уровень выдает тому процессу, который первым начинает передачу, маркер данных.
Когда второму процессу приходит время отвечать, маркер данных передается ему.
Сеансовый уровень, таким образом, разрешает передачу только той стороне, которая
обладает маркером данных.
Синхронизирующие точки представляют собой точки внутри «диалога», в которых
сеансовый уровень проверяет наличие фактического обмена.
Еще одна функция сеансового уровня модели OSI заключается в решении вопроса
о восстановлении связи в случае ее нарушения. Например, логично было бы ставить
точки синхронизации между страницами текста и в случае нарушения связи начинать
передачу с последней синхронизирующей точки. Таким образом, для восстановления
сеанса не нужно будет начинать все сначала и повторять передачу текста, который
уже принят правильно.
Сеансовый уровень, кроме того, отвечает за детали, связанные с упорядоченным
(«плавным») завершением соединения в конце сеанса. Могут возникнуть и ситуации,
когда требуется безусловное («резкое») завершение. Это необходимо в тех случаях,
когда одна из сторон прекращает обмен и отказывается с этого момента принимать
данные.
Сеансовый уровень обрабатывает не все запросы на соединения. Он может выдать
примитив отказа от соединения, если определит, что соединение приведет к перегрузке
сети или что затребованный прикладной процесс отсутствует.
|
|
Транспортный уровень
Транспортный уровень имеет большое значение для пользователей компьютерных
сетей, поскольку именно он определяет качество сервиса, которое необходимо обеспечить
посредством сетевого уровня. Для того чтобы лучше понять функции транспортного
уровня, представим его как аналогию набора специальных услуг, которые местное
почтовое отделение предоставляет клиентам за дополнительную плату. Например,
заплатив некоторую сумму, клиент может получить квитанцию о том, что письмо
доставлено по указанному им адресу. Можно заказать срочную доставку, если клиент
желает, чтобы его посылка пришла, к примеру, в Бостон на следующий день. Плату
за эти дополнительные высококачественные услуги почтовое ведомство США взимает
с клиентов деньгами, а для пользователя сети, работающего с OSI-coвместимыми
аппаратными и программными средствами, эта плата выражается в дополнительных
битах, необходимых для предоставления информации о статусе возможных дополнительных
услуг.
На транспортном уровне предусмотрено три типа сетевого сервиса. Сервис типа
А предоставляет сетевые соединения с приемлемым для пользователей количеством
необнаруживаемых ошибок и приемлемой частотой сообщений об обнаруженных ошибках.
Сервис типа В отличается приемлемым количеством необнаруживаемых ошибок, но
неприемлемой частотой сообщений об обнаруженных ошибках. Наконец, сервис типа
С предоставляет сетевые соединения с количеством необнаруженных ошибок, неприемлемым
для сеансового уровня.
Возникает вопрос: а для чего вообще нужны классы сервиса с неприемлемым количеством
ошибок? Ответ состоит в том, что для установки многих сетевых соединений необходимы
дополнительные протоколы, обеспечивающие обнаружение и устранение ошибок на
достаточном для нормальной работы уровне, и на транспортном уровне такой сервис
просто не нужен.
Транспортный уровень, тем не менее, предоставляет программистам возможность
писать программы для прикладного уровня в самых различных сетях, не обращая
внимания на то, надежна ли передача по этим сетям или нет. Некоторые называют
три верхних уровня модели OSI «пользователями транспортного уровня», а четыре
нижних — «поставщиками транспортного уровня».
Существует пять классов сервиса транспортного протокола:
Класс 0, известный как телекс, представляет собой сервис с самым низким качеством.
В этом классе сервиса предусматривается, что управление потоком данных осуществляет
сетевой уровень (под транспортным уровнем). Транспортный уровень разрывает соединение,
когда аналогичную операцию выполняет сетевой уровень. Сервис класса 1 был разработан
CCITT для стандарта Х.25 на сети с коммутацией пакетов. Он обеспечивает передачу
срочных данных, однако управление потоком все равно осуществляется на сетевом
уровне.
Класс 2 — это модифицированный класс 0. Уровень сервиса этого класса базируется
на предположении о том, что сеть обладает высокой надежностью. Предлагаемое
качество сервиса предусматривает возможность мультиплексирования множества транспортных
соединений из одного сетевого соединения. Класс 2 обеспечивает необходимую сборку
мультиплексированных пакетов данных, прибывающих неупорядоченными.
Класс 3 обеспечивает виды сервиса, предлагаемые уровнями 1 и 2, а в случае
обнаружения ошибки предоставляет возможность ресинхронизации для переустановления
соединения.
Класс 4 предполагает, что сетевому уровню присуща надежность, поэтому он предлагает
обнаружение и устранение ошибок.
|
|
Сетевой уровень
На сетевом уровне осуществляется сетевая маршрутизация. Этот уровень — ключ
к пониманию того, как функционируют шлюзы к мэйнфреймам IBM и другим компьютерным
системам. Протоколы верхних уровней модели OSI выдают запросы на передачу пакетов
из одной компьютерной системы в другую, а задача сетевого уровня состоит в практической
реализации механизма этой передачи.
Сетевой уровень является основой стандарта CCITT Х.25 на глобальные сети. Позже
мы изучим структуру пакета Х.25, включая назначение и структуру полей управляющей
информации.
На сетевом уровне реализован ряд ключевых видов сервиса для транспортного уровня,
который в модели OSI расположен непосредственно над сетевым. Сетевой уровень
уведомляет транспортный уровень об обнаружении неисправимых ошибок, помогая
ему поддерживать качество сервиса и избегать перегрузки сети путем прекращения,
если это необходимо, передачи пакетов.
Поскольку в процессе обмена информацией между двумя сетями физические соединения
время от времени могут изменяться, сетевой уровень поддерживает виртуальные
каналы и обеспечивает правильную сборку пакетов, прибывающих в неправильной
последовательности. Работа этого уровня осуществляется с помощью таблиц маршрутизации,
которые служат для определения пути продвижения того или иного пакета. Во многих
случаях сообщение, состоящее из нескольких пакетов, идет по нескольким путям.
Сетевой уровень предоставляет соответствующую «отгрузочную» информацию, необходимую
для этих пакетов (например, общее число пакетов в сообщении и порядковый номер
каждого из них).
С передачей данных в сетях связана одна очень неприятная проблема: такие характеристики,
как длина поля адреса, размер пакета и даже промежуток времени, в течение которого
пакету разрешается перемещаться по сети и по истечении которого пакет считается
потерянным и выдается запрос на пакет-дубликат, в каждой сети различны. По этой
причине управляющая информация, включаемая в пакеты на сетевом уровне, должна
быть достаточной для предотвращения возможных недоразумений и обеспечения успешной
доставки и сборки пакетов.
Как уже упоминалось выше, транспортный и сетевой уровни в значительной степени
дублируют друг друга, особенно в плане функций управления потоком данных и контроля
ошибок. Главная причина подобного дублирования заключается в том, что существует
два варианта связи — с установлением соединения (connection-orientied) и без
установления соединения (connectionless). Эти варианты связи базируются на разных
предположениях относительно надежности сети.
Сеть с установлением соединения работает почти так же, как и обычная телефонная
система. После установления соединения происходит поэтапный обмен информацией,
причем в данном случае «собеседники» не обязаны завершать каждое заявление своим
именем, именем вызываемого партнера и его адресом, поскольку предполагается,
что связь надежна и противоположная сторона получает сообщение без искажений.
В надежной сети с установлением соединения адрес пункта назначения необходим
лишь при установлении соединения, а в самих пакетах он не нужен. В подобной
сети сетевой уровень принимает на себя ответственность за контроль ошибок и
управление потоком данных. Кроме того, в его функции входит сборка пакетов.
Сетевой сервис без установления соединения, наоборот, предполагает, что контроль
ошибок и управление потоком данных осуществляются на транспортном уровне. Адрес
пункта назначения необходимо указывать в каждом пакете, а соблюдение очередности
пакетов не гарантируется. Основная идея такого сервиса состоит в том, что важнейшим
показателем является скорость передачи и пользователи должны полагаться на собственные
программы контроля ошибок и управления потоком данных, а не на встроенные стандартные
средства модели OSI.
Как это всегда бывает, когда члены комитета обсуждают сложный вопрос, был найден
компромисс, который не удовлетворил ни одну из сторон. Он состоит в том, что
возможности и сервиса с соединением, и сервиса без соединения встроены в оба
уровня: сетевой и транспортный. Конечный пользователь может выбрать соответствующие
стандартные значения для управляющих полей этих уровней и использовать тот метод,
который ему больше по душе. Недостаток этого компромисса состоит в излишней
избыточности, предусмотренной в обоих уровнях, что означает значительное количество
дополнительных информационных битов. При передаче информации в таком формате
по линиям дальней связи это приводит к дополнительным накладным расходам, поскольку
процесс передачи занимает больше времени.
|
|
Канальный уровень
Канальный уровень можно сравнить со складом и погрузочно-разгрузочным цехом
крупного производственного предприятия. Обязанность канального уровня — брать
пакеты, поступающие с сетевого уровня, и готовить их к передаче (отгрузке),
укладывая в кадры (коробки) соответствующего размера. В процессе перемещения
информации вверх по уровням модели OSI канальный уровень должен принимать информацию
в виде потока битов, поступающих с физического уровня, и производить ее обработку.
Этот уровень обязан определять, где начинается и где заканчивается передаваемый
блок, а также обнаруживать ошибки передачи. Если обнаружена ошибка, канальный
уровень должен инициировать соответствующие действия по восстановлению потерянных,
искаженных и даже дублированных данных.
Между компьютерными системами может одновременно существовать несколько независимо
работающих каналов передачи данных. Канальный уровень обязан обеспечить отсутствие
перекрытия этих каналов и предотвратить возможное искажение данных. Канальный
уровень инициализирует канал с соответствующим уровнем на компьютере, с которым
будет обмениваться данными. Он должен обеспечить синхронизацию обеих машин и
использование в них одинаковых схем кодирования и декодирования.
Поскольку управление потоком и контроль ошибок также входят в функции канального
уровня, то он отслеживает получаемые кадры и ведет статистические записи. По
завершении передачи информации пользователем канальный уровень проверяет, все
ли данные приняты правильно, а затем закрывает канал.
|
|
Контроль ошибок на канальном уровне
Для выполнения этой функции на канальном уровне применяется метод автоматического
запроса повторной передачи (ARQ — Automatic Repeat Request). В зависимости от
типа протокола, который работает на канальном уровне, для контроля ошибок используется
одна из трех разновидностей этого метода. ARQ с остановкой и ожиданием — это
метод, при котором компьютер передает кадр информации, а затем ожидает получение
кода подтверждения приема (АСК — acknowledgment), который показывает, что кадр
принят правильно. Если выявлена ошибка, то принимающая станция передаст код
неподтверждения приема (NAK — negative acknowledgment) и передающая станция
повторяет передачу.
При использовании метода непрерывного ARQ с возвратом на N станция принимает
несколько кадров (в зависимости от используемого протокола), а затем отвечает
выдачей АСК или NAK с указанием кадра, который содержит ошибку. Если станция
передала один за другим семь кадров и в четвертом кадре выявлена ошибка, то
передающая станция ответит на NAK повторной передачей кадров с 4-го по 7-й.
Метод непрерывного ARQ с избирательным повторением представляет собой модификацию
предыдущего варианта ARQ. Принимающая станция записывает все получаемые кадры
по порядку в специальный буфер, а затем отвечает, что такой-то кадр (скажем,
номер 4) содержит ошибку. Сохраняя все остальные кадры в буфере, принимающая
станция передает NAK. Передающая станция повторно передает только кадр, содержавший
ошибку (то есть номер 4). Принимающая станция вновь собирает пакеты в нужном
порядке (с 1-го по 7-й) и обрабатывает информацию.
|
|
Основные протоколы канального уровня
Канальный уровень содержит ряд протоколов,
которые разработаны комитетом IEEE 802. Для того чтобы понять, как работает
этот уровень — ключевой в модели OSI, — нужно иметь некоторое представление
о деятельности упомянутого комитета. Протоколы IEEE канального уровня будут
рассмотрены позже.
|
|
Физический уровень
Физический уровень модели OSI наименее противоречивый, поскольку включает международные
стандарты на аппаратуру, уже вошедшие в обиход. По сути дела, единственная реальная
проблема на этом уровне заключается в том, как ISO собирается учитывать вновь
разрабатываемые стандарты на аппаратуру. Методы передачи данных становятся все
более скоростными, появляются новые интерфейсы с дополнительными функциями контроля
ошибок. В связи с этим возникает вопрос: будут ли добавлены к модели OSI новые
стандарты или же физический уровень останется без изменений? Суд еще не вынес
свой вердикт, поэтому предсказать реакцию ISO сейчас не представляется возможным.
Для физического уровня определен очень подробный список рекомендованных к употреблению
соединителей. Здесь упомянуты, к примеру, 25-контактные разъемы для интерфейсов
RS-232C, 34-контактные разъемы для широкополосных модемов спецификации V.35
CCITT и 15-контактные разъемы для интерфейсов общедоступных сетей передачи данных,
определенных в рекомендациях CCITT Х.20, Х.21, Х.22 и т.д. Кроме того, регламентируются
допустимые электрические характеристики, в частности RS-232C, RS-449, RS-410
и V.35 CCITT.
Физический уровень может обеспечивать как асинхронную (последовательную) передачу,
которая используется для многих персональных компьютеров и в некоторых недорогих
ЛВС, так и синхронный режим, который применяется для некоторых мэйнфреймов и
мини-компьютеров.
Поскольку подкомитеты ISO и IEEE последние несколько лет работают в тесном
контакте, не удивительно, что во многих стандартах на ЛВС используются определения,
предложенные на физическом уровне модели OSI. На базе физического уровня различные
подкомитеты IEEE разрабатывают подробные описания реального физического оборудования,
которое передает сетевую информацию в виде электрических сигналов: требования
к применяемым кабельным системам, разъемам и соединителям.
На физическом уровне модели OSI определяются такие важнейшие компоненты сети,
как тип коаксиального кабеля для одноканальной передачи при скорости 10 Мбит/с.
Сюда включено принятое в стандарте IEEE 802.3 определение более тонкого коаксиального
кабеля cheapenet. К физическому уровню будет добавлено и включенное в стандарт
IEEE 802.3 определение одноканальной передачи данных по кабелю на витых парах
со скоростью 10 Мбит/с.
К средствам, определенным на физическом уровне, также относятся волоконно-оптические
кабели и витые пары, применяемые в самых различных ЛВС. В некоторых сетях, например
стандарта Token Ring Network фирмы IBM, используются неэкранированные витые
пары, а в сетях других типов — экранированные. Упомянутым подкомитетом, кроме
того, были разработаны спецификации различных типов коаксиальных кабелей для
широкополосных ЛВС различных типов.
На физическом уровне модели OSI должна быть определена и схема кодирования,
которой компьютер пользуется для представления двоичных значений с целью их
передачи по каналу связи. В стандарте Ethernet, как и во многих других локальных
сетях, используется манчестерское кодирование. В манчестерском кодировании отрицательное
напряжение в течение первой половины такта передачи с переходом на положительное
напряжение во втором полутакте означает единицу, а положительное напряжение
с переходом на отрицательное — нуль. Таким образом, в каждом такте передачи
имеется переход с отрицательного на положительное напряжение, или наоборот.
Итак, физический уровень отвечает за тип физической среды, тип передачи, метод
кодирования и скорость передачи данных для различных типов локальных сетей.
К его функциям, кроме того, относится установление физического соединения между
двумя коммуникационными устройствами, формирование сигнала и обеспечение синхронизации
этих устройств. Тактовые генераторы обоих устройств должны работать синхронно,
иначе передаваемая информация не будет расшифрована и прочитана.
В таблице представлено описание четырех нижних уровней
модели OSI. Особо следует отметить избыточность, предусмотренную в модели OSI
для связи с установлением соединения и связи без установления соединения.
|
|
Подведем краткие итоги
Модель OSI разбивает задачи коммуникаций на более мелкие составляющие, называемые
подзадачами. Реализации протоколов представляют собой компьютерные процессы,
относящиеся к этим подзадачам. Конкретные протоколы выполняют подзадачи определенных
уровней модели OSI. Когда протоколы группируются вместе для выполнения полной
задачи, образуется стек протоколов.
Стек протоколов — это группа протоколов, упорядоченных в виде уровней для реализации
коммуникационного процесса. Каждый уровень модели OSI имеет собственный связанный
с ним протокол. Если для осуществления процесса коммуникаций необходимо более
одного протокола, то протоколы группируются в стек. Примером стека протоколов
является TCP/IP — стек, широко применяемый в ОС UNIX и в Internet.
Каждый уровень в стеке протоколов обслуживается нижерасположенным уровнем и
реализует сервис для вышерасположенного уровня. Иными словами, уровень N использует
сервис нижерасположенного уровня (уровня N-1) и обслуживает вышерасположенный
уровень (уровень N+1).
Для обеспечения взаимодействия двух компьютеров на каждом из них должен выполняться
один и тот же стек протоколов. Каждый уровень стека протоколов на компьютере
взаимодействует со своим эквивалентом на другой машине. Выполняя одинаковый
стек протоколов, компьютеры могут иметь различные операционные системы. Например,
машина DOS, выполняющая стек TCP/IP, может взаимодействовать с ПК Macintosh,
где также функционирует TCP/IP.2
КомпьютерПресс 2’2000
Методы контроля ошибок в сети.
Для контроля ошибок в сети есть несколько методов.Существует не одна хорошая стратегия,поскольку везде работают различные механизмы,используя данные,которые по разному реагируют на ошибки.Действительно,есть различные виды ошибок,которые могут иметь различное воздействие на одной и той же системе.Основная технология обнаружения ошибок,самый распространенный случай — изменились данные в передаче или их хранении,повреждена структура данных.В некоторых случаях, таких как передача голоса по интернет-протоколу,является вполне адекватной для передачи случайной единицы,содержащей ошибочные биты.Когда оцифрованный голос преобразуется обратно в звук, человеческое ухо вполне терпимо к случайным прерываниям звука.
Прослушивание гораздо менее терпимых задержек между квантами звука,задержками изменения звука,обычно не рассматриваются в рамках контроля ошибок.
Если приложение не может работать из-за битных ошибок,возникает следующий вопрос: как исправить ошибку. Наиболее распространенный метод,по крайней мере в области сетевых технологий, является ретрансляция данных,полученных по ошибке,пока они не получат правильный бит данных или другой механизм,определяющий,что канал связи является непригодным для использования.
Ошибка обнаружения
Пожалуй, основной методов обнаружения ошибок — проверка чётности.Предположим, что единица информации входит в группу из 7 бит данных. На передаче, отправитель подсчитывает число «один» бит данных. Если это всё странно, восьмой «бит» включен, считая «нечетный» по умолчанию. Если даже бит устанавливается в ноль.
На другом конце канала, приемник рассчитывает «один» бит, вычисляет соотношение полученных битов, и сравнивает его с битом чётности. Если установка бита чётности не соответствует четности бита данных, вся группа из 8 бит считается ошибками, которая охватывает случайный бит данных, фактически правильный, но бит был поврежден.
Просто паритет имеет ограничения. Он может обнаружить одну ошибку , но если изменились два бита,соотношение останется прежним, и ошибка не будет обнаружена.
Есть множество более мощных алгоритмов обнаружения ошибок, которые производят проверку ошибок поля больше, чем один бит. 16 или 32 бита поля являются общими. В зависимости от конкретного механизма, все поля могут быть отброшены. Кроме того, некоторыми методами можно восстановить правильную информацию, чтобы сделать это, избыточные биты управления ошибки должны быть отправлены с данными. Существует постоянный компромисс между введением отправки, с каждой единицы данных, достаточной информации, чтобы восстановить правильные данные, и просто с ошибками данных повторно.
Различные стратегии применяются к устройствам хранения данных в сети. Если произошла ошибка в письменном виде диска с данными, или если диск был поврежден, по-прежнему читает повторяющиеся ошибки и данные неудачны. В сетях есть вероятность, что ошибка произошла при передаче, и ретрансляция может привести к передаче достоверной информации.
Ошибка коррекции
Как уже упоминалось,есть ряд методов исправления ошибок, каждая из которых имеет свои собственные компромиссы производительности.
Ретрансляция
Один из основных методов ретрансляции называется «остановиться и ждать», или «АСК-НАК», Постоянное ACK для подтверждения. В этом сообщении, данные передаются с ошибками обнаружения поля. Передатчик не будет посылать другой блок данных, пока не получит положительное подтверждение того, что данные были получены правильно. Данные исправляющих ошибки протокола могут иметь или не иметь «отрицательное подтверждение», которые редко используются.
Даже при явных подтверждениях системы, передатчик может начать таймер, когда он посылает данные. Если таймер истекает, и данные не были признаны, он должен полстаь данные повторно. Предположительно, если НАК может быть доставлен гораздо быстрее, чем передавать истечение времени таймера, там может быть выигрыш в производительности, но еще передатчик должен иметь таймер для покрытия против случайности ACK или NAK, исчезающие в обратном пути. Transmission Control Protocol является типичным примером, где есть только положительные подтверждения отправки.
Стоп-и-ожидание изначально неэффективны, если есть транспортный поток в обоих направлениях,отправитель должен ждать данных, которые будут переданы, проверены, а затем передается ответ. Есть несколько методов, которые могут быть использованы в сочетании, в целях повышения эффективности. Все требуют, чтобы единица информации была пронумерована в другом пространстве порядкового номера в обоих направлениях передачи.
Предполагая связи TCP от А до Б,Б получает трафик от А и посылает свои данные, он посылает сообщения могут содержанием признания количества единиц данных, которые были успешно получены. Это наложения методов позволяет одновременно отправить поток данных и подтверждений.
Резервные передачи
С плохими данными, записанными для хранения которые не могут быть возмещены, можно сделать их разумными, написать избыточный массив недорогих дисков (RAID) систем. Есть большое количество вариантов на RAID массивы, некоторые имеют защиту от ошибок, нотак же они и с повышенной производительностью. Последний метод, называется чередованием, рассматривает два или более физических диска, как если бы они были одним логическим томом, чередование позволяет совершить быстрее процессы в компьютере, сделать одновременное чтение и запись на медленные диски.
Чередование пишет различную информацию в различных средствах массовой информации. Зеркально пишет более одной копии тех же данных в нескольких средствах массовой информации, защита физического уровня информации от отдельных неудач. Так же, как при отправке проверки ошибок или исправления полей с данными по сети, эти методы создания метаданных,показывают, какие части виртуального файла существуют, в которых физическое расположение на нескольких дисках, или там, где находится резервная копия . Конечно, метаданные критические, и они нуждаются в тщательной защите.
В сети, некоторые критические приложения используют несколько физических путей передачи направления тех же данных. В ориентированных на подключение протокола (SSCOP), используемого для внутренних телефонных сетей проведения сигнальной системы управления информацией, нет единой точки сбоя оборудования. Всё, по крайней мере дублируется.
SSCOP, как LAP-B и TCP, могут исправить ошибки путем ретрансляции. Если одно из звеньев в паре перестает работать, то ретрансляция является единственной альтернативой. С двух рабочих станций,приемник может смотреть на ошибки проверки полей двух полученных кадров, и если одна проходит ошибку детектора, а другой нет, необходима ретрансляция; приемник сохраняет хорошую копию и выбрасывает плохие .
Переслать ошибки коррекции
Другой метод, используемый в обеих сетях и хранения Forward Error Correction (FEC). В ТЭК, проверка ошибок полей больше, чем необходимо для простого обнаружения ошибок. FEC система кодирования как правило, может обнаружить ошибки, влияющие (N 1) бит и исправлять ошибки бит N. Алгоритмы, являются довольно сложными, но упрощенный пример может это проиллюстрировать. Допустим, квадратный массив M × M бит. Форма — один набор контрольных сумм на каждом вертикальном столбце, и независимые контрольные суммы на каждой горизонтальной строке. Если проверка не удалась в вертикальных строках, но не горизонтальных, значение частности бит будет иметь значение, которое будет, с другим битом и производить правильный код обнаружения ошибок.FEC обычно используется в высокоскоростных модемах, где скорость передачи ошибки достаточно высока, чтобы оправдать накладные расходы.
P.P.S. Если у Вас есть вопросы, желание прокомментировать или поделиться опытом, напишите, пожалуйста, в комментариях ниже.
- Распечатать
Оцените статью:
- 5
- 4
- 3
- 2
- 1
(0 голосов, среднее: 0 из 5)
Поделитесь с друзьями!
В сетях Ethernet наиболее распространенными являются следующие типы ошибок.
Короткий кадр — кадр длиной менее 64 байт (после 8-байтной преамбулы) с правильной контрольной последовательностью.
Наиболее вероятная причина появления коротких кадров — неисправная сетевая плата или неправильно сконфигурированный или испорченный сетевой драйвер.
Длинный кадр (long frame) — кадр длиннее 1518 байт.
Длинный кадр может иметь правильную или неправильную контрольную последовательность. В последнем случае такие кадры обычно называют jabber. Фиксация длинных кадров с правильной контрольной последовательностью указывает чаще всего на некорректность работы сетевого драйвера; фиксация ошибок типа jabber — на неисправность активного оборудования или наличие внешних помех.
Ошибки контрольной последовательности (CRC error) — правильно оформленный кадр допустимой длины (от 64 до 1518 байт), но с неверной контрольной последовательностью (ошибка в поле CRC).
Ошибка выравнивания (alignment error) — кадр, содержащий число бит, не кратное числу байт.
Впервые данный термин был введен компанией Fluke с целью дифференциации различий между удаленными коллизиями и шумами в канале связи.
В соответствии с общепринятым стандартом дефакто число ошибок канального уровня не должно превышать 1% от общего числа переданных по сети кадров. Как показывает опыт, эта величина перекрывается только при наличии явных дефектов кабельной системы сети. При этом многие серьезные дефекты активного оборудования, вызывающие многочисленные сбои в работе сети, не проявляются на канальном уровне сети.
Правило 9.1 Прежде чем анализировать ошибки в сети, необходимо выяснить, какие типы ошибок могут быть определены сетевой платой и драйвером платы на компьютере, где работает программный анализатор протоколов.
Работа любого анализатора протоколов основана на том, что сетевая плата и драйвер переводятся в режим приема всех кадров сети (promiscuous mode). В этом режиме сетевая плата принимает все проходящие по сети кадры, а не только широковещательные и адресованные непосредственно к ней, как в обычном режиме. Анализатор протоколов всю информацию о событиях в сети получает именно от драйвера сетевой платы, работающей в режиме приема всех кадров.
Не все сетевые платы и сетевые драйверы предоставляют анализатору протоколов идентичную и полную информацию об ошибках в сети. Сетевые платы 3Com вообще никакой информации об ошибках не выдают. Если установить анализатор протоколов на такую плату, то значения на всех счетчиках ошибок будут нулевыми.
EtherExpress Pro компании Intel сообщают только об ошибках CRC и выравнивания.
Сетевые платы компании SMC предоставляют информацию только о коротких кадрах.
Сетевые карты D-Link (например, DFE-500TX) и Kingstone (например, KNE 100TX) сообщают полную, а при наличии специального драйвера — даже расширенную, информацию об ошибках и коллизиях в сети.
Ряд разработчиков анализаторов протоколов предлагают свои драйверы для наиболее популярных сетевых плат.
Правило 9.2 В пределах одного домена сети (collision domain) тип и число ошибок, фиксируемых анализатором протоколов, зависят от места подключения измерительного прибора.
Другими словами, в пределах сегмента коаксиального кабеля, концентратора или стека концентраторов картина статистики по каналу может зависеть от места подключения измерительного прибора.
Одна и та же помеха может вызвать фиксацию ошибки CRC, блика, удаленной коллизии или вообще не обнаруживаться в зависимости от взаимного расположения источника помех и измерительного прибора
Одна и та же коллизия может фиксироваться как удаленная или поздняя в зависимости от взаимного расположения конфликтующих станций и измерительного прибора. Кадр, содержащий ошибку CRC на одном концентраторе стека, может быть не зафиксирован на другом концентраторе того же самого стека.
Правило 9.3 Для выявления ошибок на канальном уровне сети измерения необходимо проводить на фоне генерации анализатором протоколов собственного трафика.
Генерация трафика позволяет обострить имеющиеся проблемы и создает условия для их проявления. Трафик должен иметь невысокую интенсивность (не более 100 кадров/с) и способствовать образованию коллизий в сети, т. е. содержать короткие (<100 байт) кадры.
При выборе анализатора протоколов или другого диагностического средства внимание следует обратить прежде всего на то, чтобы выбранный инструмент имел встроенную функцию генерации трафика задаваемой интенсивности. Эта функция имеется, в частности, в анализаторах Observer компании Network Instruments и NetXray компании Cinco (ныне Network Associates).
Правило 9.4 Если наблюдаемая статистика зависит от места подключения измерительного прибора, то источник ошибок, скорее всего, находится на физическом уровне данного домена сети (причина — дефекты кабельной системы или шум внешнего источника).
В противном случае источник ошибок расположен на канальном уровне (или выше) или в другом, смежном, домене сети.
Правило 9.5 Если доля ошибок CRC в общем числе ошибок велика, то следует определить длину кадров, содержащих данный тип ошибок.
При большой доле ошибок CRC в общем числе ошибок целесообразно выяснить причину их появления. Для этого ошибочные кадры из серии надо сравнить с аналогичными хорошими кадрами из той же серии. Если ошибочные кадры будут существенно короче хороших, то это, скорее всего, результаты коллизий. Если ошибочные кадры будут практически такой же длины, то причиной искажения, вероятнее всего, является внешняя помеха. Если же испорченные кадры длиннее хороших, то причина кроется, вероятнее всего, в дефектном порту концентратора или коммутатора, которые добавляют в конец кадра «пустые» байты.
Сравнить длину ошибочных и правильных кадров проще всего посредством сбора в буфер анализатора серии кадров с ошибкой CRC.
Правило 9.6 Если сеть диагностируется впервые и в ней наблюдаются проблемы, то не следует ожидать, что в сети дефектен только один компонент.
Наиболее надежным способом локализации дефектов является поочередное отключение подозрительных станций, концентраторов и кабельных трасс, тщательная проверка топологии линий заземления компьютеров (особенно для сетей 10Base2).
Если сбои в сети происходят в непредсказуемые моменты времени, не связанные с активностью пользователей, проверьте уровень шума в кабеле с помощью кабельного сканера. При отсутствии сканера визуально убедитесь, что кабель не проходит вблизи сильных источников электромагнитного излучения: высоковольтных или сильноточных кабелей, люминесцентных ламп, электродвигателей, копировальной техники и т. п.
Правило 9.7 Отсутствие ошибок на канальном уровне еще не гарантирует того, что информация в сети не искажается.
Следствием ошибок нижнего уровня является повторная передача кадров. Благодаря высокой скорости сети Ethernet (особенно Fast Ethernet) и высокой производительности современных компьютеров, ошибки нижнего уровня не оказывает существенного влияния на время реакции ППО. На самом деле, очень редко встречаются случаи, когда ликвидация только ошибок нижних (канального и физического) уровней сети позволяла существенно улучшить время реакции ППО. В основном проблемы были связаны с серьезными дефектами кабельной системы сети.
Значительно большее влияние на работу ППО в сети оказывают такие ошибки, как бесследное исчезновение или искажение информации в сетевых платах, маршрутизаторах или коммутаторах при полном отсутствии информации об ошибках нижних уровней. Здесь употребляется слово «информация», так как в момент искажения данные еще не оформлены в виде кадра. Причина таких дефектов в следующем. Информация искажается (или исчезает) «в недрах» активного оборудования — сетевой платы, маршрутизатора или коммутатора. При этом приемо-передающий блок этого оборудования вычисляет правильную контрольную последовательность (CRC) уже искаженной ранее информации, и корректно оформленный кадр передается по сети. Ошибок в этом случае, естественно, не фиксируется.
Иногда кроме искажения наблюдается исчезновение информации. Чаще всего оно происходит на дешевых сетевых платах или на коммутаторах Ethernet-FDDI. Механизм исчезновения информации в последнем случае понятен В ряде коммутаторов Ethernet-FDDI обратная связь быстрого порта с медленным (или наоборот) отсутствует, в результате другой порт не получает информации о перегруженности входных/выходных буферов быстрого (медленного) порта. В этом случае при интенсивном трафике информация на одном из портов может пропасть.
Если же защита не установлена, то поведение ППО может быть непредсказуемым.
Помимо замены (отключения) подозрительного оборудования выявить такие дефекты можно двумя способами:
1) первый способ заключается в захвате, декодировании и анализе кадров от подозрительной станции, маршрутизатора или коммутатора. Признаком описанного дефекта служит повторная передача пакета IP или IPX, которой не предшествует ошибка нижнего уровня сети. Некоторые анализаторы протоколов и экспертные системы упрощают задачу, выполняя анализ трассы или самостоятельно вычисляя контрольную сумму пакетов.
2) Вторым способом является метод стрессового тестирования сети.
Выводы. Основная задача диагностики канального уровня сети — выявить наличие повышенного числа коллизий и ошибок в сети и найти взаимосвязь между числом ошибок, степенью загруженности канала связи, топологией сети и местом подключения измерительного прибора. Все измерения следует проводить на фоне генерации анализатором протоколов собственного трафика.
Если установлено, что повышенное число ошибок и коллизий не является следствием перегруженности канала связи, то сетевое оборудование, при работе которого наблюдается повышенное число ошибок, следует заменить.
Если не удается выявить взаимосвязи между работой конкретного оборудования и появлением ошибок, то необходимо провести комплексное тестирование кабельной системы, проверьте уровень шума в кабеле, топологию линий заземления компьютеров, качество питающего напряжения.

«Это должна быть проблема с сетью» — это общий вывод, который можно сделать при устранении нечетных проблем с ПК, приложениями и системами. Человек, выступающий с этим заявлением, теперь обычно получает деньги от того, кому остается выяснить, какая загадочная «проблема сети» действительно существует. Если вы читаете это, то кто-то, вероятно, вы.
В этой части мы познакомим вас с некоторыми инструментами, которые помогут упростить вашу работу по устранению неполадок с сетью, и предоставим примеры, которые помогут вам начать работу. Вне зависимости от того, являетесь ли вы опытным пользователем, который хочет выяснить это для себя, системным администратором, которому поручено доказать, что это действительно является ошибкой разработчика, или руководителем группы, стремящимся оснастить свой ИТ-персонал инструментами для более эффективного решения проблем, эта статья будет содержать что-то для тебя.
Мы подробно рассмотрим каждый из инструментов, которые мы выбрали ниже, но если у вас мало времени, вот наш Список лучших инструментов диагностики и устранения неисправностей сети:
- Сканер портов SolarWinds (СКАЧАТЬ БЕСПЛАТНО) — Бесплатный инструмент для проверки портов на ваших сетевых устройствах, чтобы убедиться, что у вас нет открытых портов, открытых.
- Устранение неполадок в сети Paessler с помощью PRTG (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ) — Система управления инфраструктурой, включающая мониторинг портов.
- пинг — Простая утилита командной строки, которая проверяет скорость соединений.
- Tracert — Бесплатная утилита командной строки, которая перечисляет вероятные переходы к сетевому или интернет-адресу назначения.
- Ipconfig — Этот инструмент командной строки сообщает адреса IPv4 и IPv6, подсети и шлюзы по умолчанию для всех сетевых адаптеров на ПК..
- Netstat — Этот инструмент отображает активные соединения на вашем компьютере.
- Nslookup — Этот инструмент, доступный для Windows, Unix, Linux и Mac OS, обеспечивает диагностику DNS-сервера..
- Скорость и вверх / вниз тестовые площадки — Список сайтов, которые будут проверять ваши интернет-соединения.
- Sysinternals — Набор инструментов Microsoft для Windows, которые помогают устранять неполадки и настраивать Active Directory.
- Wireshark — Бесплатный анализатор пакетов, который поможет вам анализировать потоки трафика.
- Nmap — Инструмент сетевой безопасности и мониторинга, которому в качестве пользовательского интерфейса нужна служебная программа Zenmap..
Contents
- 1 Краткое руководство по устранению неполадок в сети
- 2 Лучшие инструменты для устранения неполадок в сети
- 2.1 1. Сканер портов SolarWinds (БЕСПЛАТНАЯ ЗАГРУЗКА)
- 2.2 2. Устранение неполадок сети Paessler с помощью PRTG (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
- 2.3 3. Пинг
- 2.4 4. Tracert
- 2.5 5. Ipconfig
- 2.6 6. Netstat
- 2.7 7. Nslookup
- 2.7.1 Поиск доменного имени по IP-адресу
- 2.7.2 Поиск почтовых серверов для домена
- 2.8 8. Скорость и вверх / вниз тестовых площадок
- 2.9 9. Sysinternals
- 2.10 10. Wireshark
- 2.11 11. Nmap
- 3 Резюме
Краткое руководство по устранению неполадок в сети
Для сетевого администратора, желающего использовать инструменты, уже имеющиеся на их ПК, современные операционные системы Windows поставляются с широким набором инструментов для устранения неполадок в сети, доступных без установки каких-либо дополнительных приложений. Пять инструментов в нашем списке (ping, tracert, ipconfig, netstat, & nslookup) может быть запущен непосредственно из командной строки Windows (cmd.exe) без установки каких-либо дополнительных программ для устранения неполадок..
Основная проблема, с которой вы столкнетесь в своей сети, заключается в том, что она работает слишком медленно. Время, необходимое для передачи данных из источника в место назначения, может быть настолько продолжительным, что приложения, к которым получают доступ конечные пользователи, сдаются и сообщают о сбое сети. В других случаях медленные сети делают невозможным использование интерактивных инструментов, таких как VoIP или потоковое видео. Используя все инструменты из этого списка, вы можете собрать рабочий процесс, который предоставит вам информацию обо всех потенциальных проблемах сети. Если сетевые инженеры спланировали вашу сеть должным образом, она никогда не должна сталкиваться с проблемами, которые приводят к замедлению работы системы, а управление сетью должно быть приятной задачей. Основные причины проблем с сетью, таких как медленная скорость, обрыв соединений и центр потери пакетов на перегруженных сетевых устройствах, таких как коммутаторы и маршрутизаторы, или отсутствие информации в таблице маршрутизации и других системных базах данных, таких как DNS-сервер или DHCP система.
Выполнение стандартных тестов производительности, которые предоставляет каждый из инструментов в нашем списке, покажет узкое место в вашей сети или покажет сбой DNS или устранение конфликтов, которые вызывают проблемы с подключением.
Лучшие инструменты для устранения неполадок в сети
Как и в большинстве задач, когда дело доходит до устранения неполадок в сети, используемые вами инструменты могут изменить мир к лучшему. При составлении этого списка мы учитывали надежность инструмента, используемого в различных ситуациях, простоту настройки и использования, документацию и поддержку, а также то, как обновляется программное обеспечение..
1. Сканер портов SolarWinds (БЕСПЛАТНАЯ ЗАГРУЗКА)
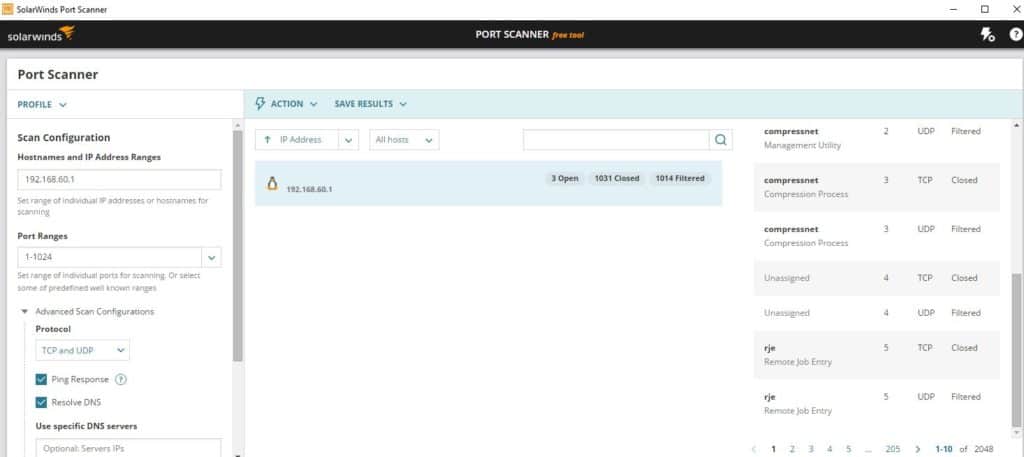
Сканер свободных портов SolarWinds предлагает преимущества, аналогичные преимуществам популярного сканера портов nmap (о котором мы также поговорим в этом списке), с интуитивно понятным графическим интерфейсом, с которым легко начать работу. Если вы хотите погрузиться в мир устранения неполадок в сети и сканирования портов, этот инструмент — отличное место для начала. Простота использования помогает устранить некоторые технические барьеры для входа, которые могут иметь другие подобные инструменты.
Бесплатная загрузка: сканер портов SolarWinds
Этот сканер является переносимым исполняемым файлом, который может быть запущен в операционных системах Windows. Помимо сканирования портов TCP и UDP, чтобы определить, открыты ли они / закрыты / отфильтрованы, сканер портов SolarWinds может обнаруживать MAC-адреса и операционные системы. Результаты сканирования могут быть сохранены в формате .csv, .xlsx или .xml. Вы можете бесплатно скачать сканер портов SolarWinds здесь.
Сканер портов SolarWindsСкачать БЕСПЛАТНЫЙ ИНСТРУМЕНТ на SolarWinds.com
2. Устранение неполадок сети Paessler с помощью PRTG (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
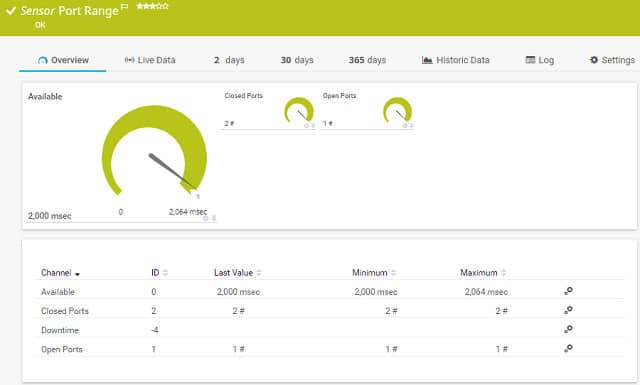
PRTG от Paessler — это полноценная система мониторинга. Это может помочь вам в устранении неполадок, поскольку позволяет отслеживать проблемы с производительностью прямо в стеке протоколов и выявлять причину проблемы. Мониторинг портов является одним из методов устранения неполадок, которые вы можете использовать с этим инструментом.
Система PRTG включает в себя два датчика контроля порта. Один подключается к указанному порту на определенном устройстве, другой проверяет диапазон номеров портов. Этот инструмент только контролирует порты TCP. Датчик диапазона портов имеет одну дополнительную функцию, которой нет у датчика с одним портом. Вы можете установить его для проверки порта с защитой TLS. Оба датчика сообщают о времени отклика порта и о том, открыт он или закрыт.
PRTG включает в себя инструменты анализа сетевого трафика, которые помогут вам устранить проблемы со скоростью доставки. Этот инструмент включает в себя ряд методов мониторинга трафика, в том числе трассировку маршрута к месту назначения с помощью Traceroute и проверку Ping, которая даст вам время отклика для каждого узла в вашей сети. Утилита перехвата пакетов может сказать вам, какие приложения и конечные точки производят избыточный трафик, и вы можете запросить сетевые устройства, чтобы узнать, какие из них перегружены до точки очередей.
Paessler создал инструмент, который охватывает серверы и приложения, а также состояние сети, время отклика порта и службы для мониторинга всех условий, которые могут вызвать проблемы с производительностью программного обеспечения. Если у вас есть виртуальные машины в вашей сети, PRTG может сортировать их базовые соединения, службы, серверы и операционное программное обеспечение. Этот мониторинг постоянен, поэтому вы сможете отслеживать события, чтобы определить источник проблем с производительностью.
Paessler поставляет PRTG как облачный сервис, или вы можете установить программное обеспечение у себя дома. Инструмент устанавливается в средах Windows Server. Вы можете использовать систему бесплатно до 100 датчиков. Paessler предлагает 30-дневную бесплатную пробную версию с неограниченным количеством датчиков, чтобы вы могли оценить инструмент мониторинга и устранения неполадок.
Сетевой монитор Paessler PRTGСкачать 30-дневную бесплатную пробную версию
3. Пинг
Ping — это идеальная команда, которую нужно использовать, когда вам нужно подтвердить сетевое соединение, на уровне IP, между двумя хостами или чтобы убедиться, что стек TCP / IP работает на вашем локальном компьютере. Успешный пинг подтверждает сетевое соединение между двумя хостами, а также выдает отчеты о потере пакетов. Ниже приведен пример успешного запуска команды ping для удаленного хоста «google.com»..
C: Users>пинг google.com
Pinging google.com [172.217.9.46] с 32 байтами данных:
Ответ от 172.217.9.46: bytes = 32 time = 38ms TTL = 56
Ответ от 172.217.9.46: bytes = 32 time = 12ms TTL = 56
Ответ от 172.217.9.46: bytes = 32 time = 14ms TTL = 56
Ответ от 172.217.9.46: bytes = 32 time = 12ms TTL = 56
Статистика пинга для 172.217.9.46:
Пакеты: отправлено = 4, получено = 4, потеряно = 0 (потеря 0%),
Приблизительное время прохождения туда и обратно в миллисекундах:
Минимум = 12мс, Максимум = 38мс, Среднее = 19мс
Помимо подтверждения IP-подключения к «google.com», эти результаты подтверждают, что мы можем правильно разрешать доменные имена (т.е. DNS работает на локальном компьютере).
Тот потеря цифра, которую вы видите в последней строке вывода ping — это количество потерянных пакетов, за которым следует коэффициент потери пакетов в скобках.
Несколько советов по работе с командой ping для устранения неполадок:
- Используйте ping –t для непрерывного пинга хоста. Например:
ping –t google.com
будет продолжать пинговать google.com, пока пинг не будет прерван. Нажмите control-c (клавиши «CTRL» и «C»), чтобы завершить непрерывный пинг.
- Если вы не можете пропинговать доменные имена, такие как google.com, но можете пинговать IP-адреса в Интернете, например, 8.8.8.8 (DNS-серверы Google), у вас может быть проблема, связанная с DNS.
- Если вы не можете пропинговать IP-адреса в Интернете, как 8.8.8.8, но вы можете пропинговать хосты в вашей локальной сети (LAN), у вас может быть проблема с вашим шлюзом по умолчанию.
- Вы можете использовать «ping localhost», «ping :: 1» или «ping 127.0.0.1» для проверки стека TCP / IP на вашем локальном компьютере. «Localhost» — это имя, которое разрешается в один из петлевых адресов локальной машины, «:: 1» — это петлевой адрес IPv6, а «127.0.0.1» — это петлевой адрес IPv4..
4. Tracert
Tracert похож на ping, за исключением того, что он использует значения времени жизни (TTL), чтобы показать, сколько «прыжков» существует между двумя хостами. Это делает его полезным инструментом для определения места нарушения сетевого подключения. По сути, tracert помогает вам понять, является ли маршрутизатор или сеть, которая находится между вашим компьютером и удаленным хостом, тем, кем вы управляете или нет. Снова используя google.com в качестве примера, мы видим, что между нашим ПК и google.com было 10 переходов.
C: Users>tracert google.com
Отслеживание маршрута до google.com [172.217.4.78]
более 30 прыжков:
1 1 мс 1 мс 3 мс 192.168.1.1
2 246 мс 49 мс 56 мс 10.198.1.177
3 58 мс 48 мс 54 мс 10.167.184.102
4 63 мс 55 мс 85 мс 10.167.184.107
5 50 мс 55 мс 56 мс 10.164.72.244
6 72 мс 365 мс 69 мс 10.164.165.43
7 92 мс 61 мс 45 мс 209,85,174,154
8 67 мс 42 мс 58 мс 108.170.244.1
9 372 мс 66 мс 46 мс 216.239.51.145
10 64 мс 73 мс 44 мс lga15s47-in-f78.1e100.net 172.217.4.78]
Трассировка завершена.
5. Ipconfig
Определение настроек IP на вашем компьютере является важной частью устранения неполадок в сети. Команда ipconfig поможет вам сделать это. Ввод ipconfig из командной строки возвращает адреса IPv4 и IPv6, подсети и шлюзы по умолчанию для всех сетевых адаптеров на ПК. Это может быть полезно при определении правильности IP-конфигурации вашего компьютера. Кроме того, ipconfig можно использовать для изменения или обновления выбранных настроек IP..
Советы по работе с ipconfig:
- Если ipconfig возвращает IP-адрес, который начинается с 169.254 (например, 169.254.0.5), ваш компьютер, вероятно, настроен для DHCP, но не смог получить IP-адрес от сервера DHCP.
- Используйте ipconfig / all, чтобы получить полную информацию о конфигурации TCP / IP для всех сетевых адаптеров и интерфейсов..
- Используйте ipconfig / release для освобождения текущих сетевых параметров, назначенных DHCP.
- Используйте ipconfig / renew для обновления текущих сетевых параметров, назначенных DHCP.
- Используйте ipconfig / flushdns для очистки кеша DNS при устранении проблем с разрешением имен.
6. Netstat
Netstat позволяет отображать активные соединения на вашем локальном компьютере. Это может быть полезно при определении того, почему пользователи не могут подключиться к определенному приложению на сервере, или при определении того, какие подключения выполняются к удаленным хостам с компьютера. Ввод netstat в командной строке отобразит все активные соединения TCP. Добавление параметров в команду netstat расширит или изменит функциональность. Вот несколько полезных команд netstat и их действия:
- netstat –a отображает все активные соединения TCP и порты TCP и UDP, которые прослушивает компьютер.
- netstat –n отображает все активные TCP-подключения точно так же, как команда netstat, но она не пытается преобразовать адреса или номера портов в имена и просто отображает числовые значения.
- netstat –o отображает все активные TCP-соединения и включает идентификатор процесса (PID) для процесса, использующего каждое соединение.
Вы можете комбинировать различные параметры для расширения функциональности netstat. Например, netstat –ano отображает все активные соединения TCP и порты TCP и UDP, которые прослушивает компьютер, использует числовые значения и сообщает PID, связанный с соединениями..
7. Nslookup
nslookup — это полезная утилита командной строки, которая позволяет устранять неполадки и диагностику DNS. Nslookup доступен в операционных системах Windows и * nix. Существует множество вариантов использования этой гибкой утилиты, и ее можно запустить в интерактивном режиме или путем ввода команд непосредственно в командной строке..
Чтобы помочь вам начать, мы рассмотрим некоторые команды nslookup, которые полезны в трех наиболее распространенных случаях: поиск IP-адреса на основе доменного имени, поиск доменного имени на основе IP-адреса и поиск почтовых серверов. для домена. Ниже приведены примеры того, как сделать каждый из командной строки Windows.
Поиск IP-адреса на основе доменного имени:
C: Users>nslookup google.com
Сервер: ns2.dns.mydns.net
Адрес: 192.168.247.45
Неофициальный ответ:
Название: google.com
Адреса: 2607: f8b0: 4009: 805 :: 200e
172.217.10.46
Приведенные выше результаты показывают нам, что DNS-сервер, используемый на нашей локальной машине, был ns2.dns.mydns.net, и поскольку ns2.dns.mydns.net не является официальным сервером имен в домене Google, мы получаем «неавторизованный ответ» , Если мы хотим указать другой DNS-сервер в нашем запросе, мы просто добавляем доменное имя или IP-адрес DNS-сервера после команды, например, (используя DNS-сервер 1.1.1.1 из CloudFlare).
C: Users>nslookup google.com 1.1.1.1
Сервер: 1dot1dot1dot1.cloudflare-dns.com
Адрес: 1.1.1.1
Неофициальный ответ:
Название: google.com
Адреса: 2607: f8b0: 4009: 812 :: 200e
216.58.192.174
Поиск доменного имени по IP-адресу
Поиск доменного имени на основе IP-адреса аналогичен предыдущему процессу, вы просто используете IP-адрес вместо имени домена после команды «nslookup». Например, чтобы узнать, что такое полное доменное имя (FQDN) для IP-адреса 8.8.8.8, мы использовали бы следующую команду:
C: Users>nslookup 8.8.8.8
Сервер: ns2.dns.mydns.net
Адрес: 192.168.247.45
Название: google-public-dns-a.google.com
Адрес: 8.8.8.8
Исходя из результатов, мы видим, что полное доменное имя, связанное с 8.8.8.8, называется «google-public-dns-a.google.com», что имеет смысл, учитывая, что 8.8.8.8 является одним из двух популярных общедоступных DNS-серверов, доступных в Google..
Поиск почтовых серверов для домена
Иногда вам может понадобиться определить, какие почтовые серверы доступны в домене. Для этого нам просто нужно указать, что мы ищем записи MX, используя ключ -ty. В приведенном ниже примере мы проверим, какие почтовые серверы возвращаются для gmail.com:
C: Users>nslookup -ty = mx gmail.com
Сервер: ns2.dns.mydns.net
Адрес: 192.168.247.45
Неофициальный ответ:
Настройки gmail.com MX = 40, почтовый обменник = alt4.gmail-smtp-in.l.google.com
Настройки gmail.com MX = 5, почтовый обменник = gmail-smtp-in.l.google.com
Настройки gmail.com MX = 30, почтовый обменник = alt3.gmail-smtp-in.l.google.com
Настройки gmail.com MX = 10, почтовый обменник = alt1.gmail-smtp-in.l.google.com
Настройки gmail.com MX: почтовый обменник alt2.gmail-smtp-in.l.google.com
Здесь пять почтовых серверов были возвращены вместе со значением предпочтения MX. Чем ниже значение предпочтения MX, тем выше приоритет этого сервера (то есть эти серверы должны использоваться первыми).
8. Скорость и вверх / вниз тестовых площадок
Иногда вам необходимо начать устранение неполадок, определив, связана ли проблема с клиентскими компьютерами, обращающимися к веб-сайту, или с самим веб-сайтом. Есть ряд сайтов, которые могут помочь вам сделать это. Например, инструмент проверки доступности Uptrends позволяет проверять состояние и время отклика веб-сайта с контрольных точек по всему миру..
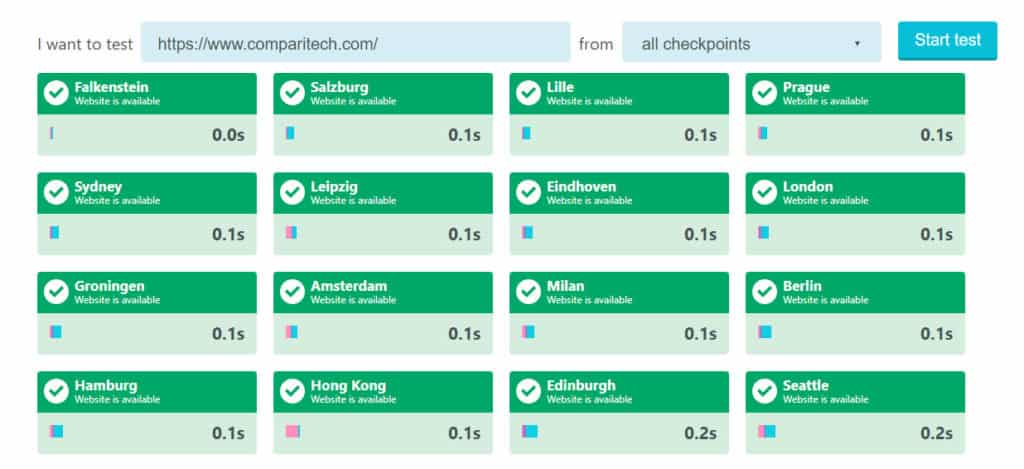
Это может быть особенно полезно, если вам необходимо определить, почему некоторые пользователи могут заходить на ваш сайт, а другие — нет. Для более простой, но более интенсивной рекламы, вы можете попробовать Down For Everyone или Just Me.
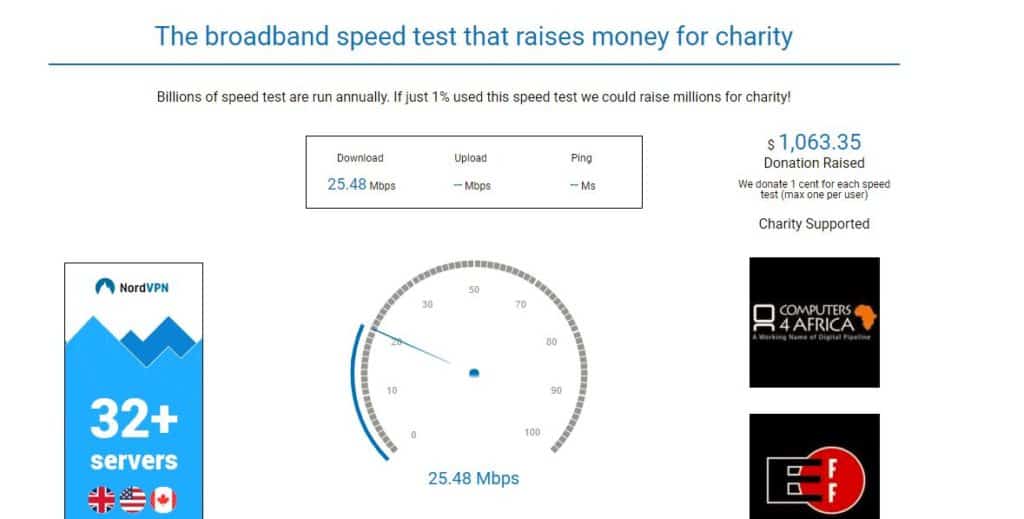
В качестве альтернативы вам может потребоваться быстрый и простой способ проверить скорость загрузки и выгрузки, чтобы определить, есть ли у вас проблемы с пропускной способностью или задержкой. Наш тест скорости широкополосного доступа — отличный способ сделать это и помочь собрать деньги на благотворительность.
9. Sysinternals
Администраторы Windows, которым требуются расширенные средства диагностики и устранения неполадок в сети, будут хорошо обслуживаться сетевыми утилитами Microsoft Sysinternals. Утилиты Sysinternals включают инструменты, которые могут помочь в устранении неполадок и настройке Active Directory (AD), такие как AD Explorer и AD Insight. Другие инструменты могут помочь измерять производительность сети (PsPing), сканировать общие файлы (ShareEnum), просматривать или запускать процессы удаленно (PsTools) и многое другое. Если вам требуется только одна или несколько утилит Sysinternals, вы можете установить их отдельно, в отличие от загрузки всего пакета Sysinternals..
10. Wireshark
Wireshark — это анализатор протоколов и один из самых распространенных сетевых инструментов для организаций всех размеров, когда проблемы с сетью необходимо устранять с высокой степенью детализации. Преимущество использования Wireshark для анализа сетевого трафика заключается в том, что вы сможете просматривать необработанные сетевые пакеты, и это часто позволяет вам определить основную причину проблемы. Это может быть особенно полезно в ситуациях, когда неясно, какое приложение не выполняет то, что должно, или когда вы пытаетесь выполнить обратный инжиниринг функциональности плохо документированной программы. Компромисс здесь заключается в том, что у вас будет много данных для анализа, поэтому могут потребоваться некоторые технические знания для детализации и идентификации важной информации. Вы можете скачать Wireshark бесплатно здесь.
В операционных системах Windows захват пакетов на канальном уровне с помощью WireShark часто делается возможным с помощью Winpcap (требуется либо Winpcap, либо Npcap). В дополнение к включению WireShark в Windows, Winpcap может включить мощную утилиту командной строки Windump, которая является ответом Windows на популярную программу tcpdump, встречающуюся во многих операционных системах * nix. Для более глубокого погружения в Winpcap, Windump и tcpdump, ознакомьтесь с нашей недавней статьей о анализаторах пакетов и сетевых анализаторах.
Несмотря на то, что WireShark — отличный инструмент, сгенерированные данные не всегда легко понять непосвященным. Если вы ищете способ лучше визуализировать и анализировать данные, созданные с помощью WireShark, SolarWinds Response Time Viewer может помочь. Этот инструмент позволяет пользователям загружать и анализировать файлы .pcap и предоставляет удобные для чтения сводки времени отклика и объемов данных..
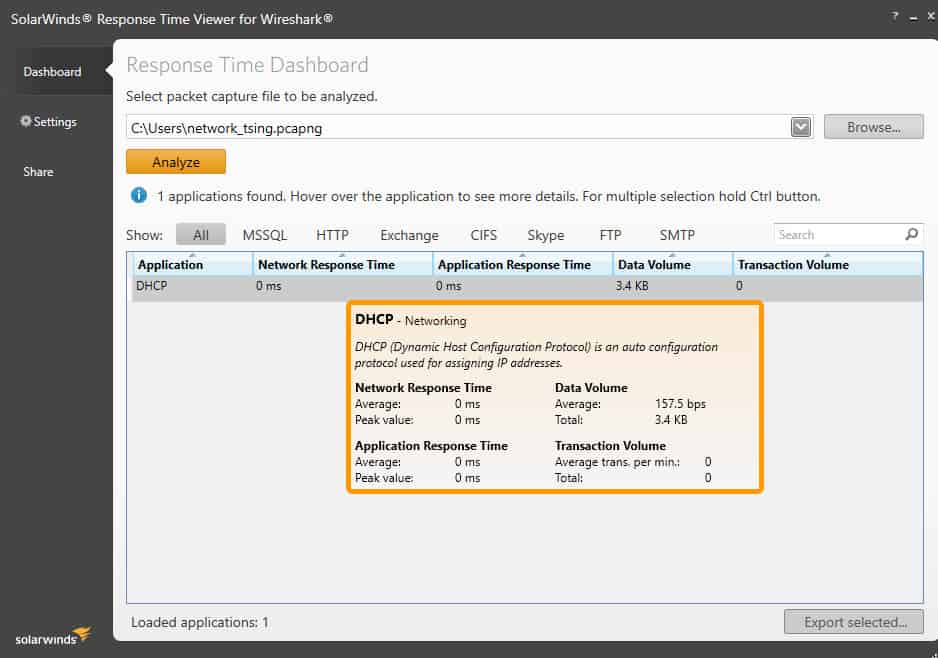
Средство просмотра времени отклика SolarWinds для бесплатного инструмента WireSharkDownload
11. Nmap
Nmap — это популярный инструмент аудита безопасности и исследования сети, выпущенный по специальной лицензии с открытым исходным кодом на основе GPLv2. Хотя наиболее популярными вариантами использования Nmap являются сканирование безопасности и тестирование на проникновение, оно может оказаться весьма полезным в качестве инструмента для устранения неполадок в сети. Например, если вы имеете дело с незнакомым приложением и хотите узнать, какие службы запущены и какие порты открыты, nmap может помочь. Сам Nmap использует интерфейс командной строки (CLI), но это не означает, что вам не повезло, если вы предпочитаете графический интерфейс пользователя (GUI). Zenmap является официальным графическим интерфейсом nmap и является хорошим способом для начинающих начать работать с nmap. Чтобы узнать больше о Zenmap и о том, как глубже погрузиться в nmap, ознакомьтесь со статьей «10 лучших бесплатных контроллеров портов для 2023 года»..
Резюме
Инструменты, которые мы обсуждали здесь, прекрасно использовать в вашем сетевом наборе инструментов, и мы рекомендуем попробовать некоторые из них в следующий раз, когда вы столкнетесь со сценарием устранения неполадок в сети. Мы оставили какие-либо из ваших любимых инструментов для устранения неполадок в сети или у вас есть вопросы об инструментах, которые мы упомянули здесь? Дайте нам знать в комментариях ниже.
43e 74e a5d cf1 c57 649 5ee ec6 c51 363 1e4 ccc 378 cb0 bb4