
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
15 |
||||||||||||||||
|
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||||||||
|
C(2) |
1.014411 |
0.020750 |
48.88608 |
0.0000 |
|||||||||||||
|
C(3) |
0.702102 |
0.078268 |
8.970448 |
0.0000 |
|||||||||||||
|
т.е. yt |
= 1.014 yt – 1 + 0.702 (xt – 1.014 xt – 1) + e t , или |
||||||||||||||||
|
yt |
= 1.014 yt – 1 + 0.702 xt |
– 0.712 xt – 1 + e t |
Отметим близость результатов, полученных тремя методами:
|
yt = |
1.005 yt – 1 + 0.695 xt |
– 0.707 xt – 1 + et |
(метод 1), |
|
yt = |
yt – 1 + 0.710 xt |
– 0.710 xt – 1 + et |
(метод 2), |
|
yt = |
1.014 yt – 1 + 0.702 xt |
– 0.712 xt – 1 + e t |
(метод 3). |
Фактически, во всех трех случаях воспроизводится одна и та же линейная модель связи между рядами разностей:
∆yt = 0.7 ∆xt + et .
Эта регрессионная связь между продифференцированными рядами не является ложной (в отличие от регрессионной связи между рядами уровней): статистика Дарбина – Уотсона принимает значение 1.985; P-значение критерия Jarque – Bera равно 0.344.
Замечание
В связи с результатами, полученными при рассмотрении последних примеров, естественно возникает следующий вопрос, который поднимался в свое время различными исследователями. Не будет ли разумным, имея дело с рядами, траектории которых обнаруживают выраженный тренд, сразу приступать к оцениванию связей между рядами разностей (между продифференцированными рядами) ?
Против некритичного использования такого подхода говорят два обстоятельства:
(a)Если ряды в действительности стационарны относительно детерминированного тренда, то тогда дифференцирование приводит к
передифференцированным рядам, имеющим необратимую MA
составляющую.
(b)Если ряды являются интегрированными порядка 1 и при этом коинтегрированы, то при переходе к продифференцированным рядам теряется информация о долговременной связи между уровнями этих рядов.
Дифференцирование рядов оправданно и полезно, если ряды являются интегрированными, но при этом между ними отсутствует коинтеграционная связь.
Пусть yt ~ I(1), xt ~ I(0). Строить регрессию yt на xt в этом случае бессмысленно, т.к. для любых a и b в такой ситуации
yt – a – b xt ~ I(1).
Пусть, наоборот, yt ~ I(0), xt ~ I(1). Для любых a и b ≠ 0 здесь опять yt – a – b xt ~ I(1),
и только при b = 0 получаем yt – a – b xt ~ I(0),
так что и в таком сочетании строить регрессию одного ряда на другой не имеет смысла.
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
16 |
|
|
Пусть теперь yt ~ I(1), |
xt ~ I(1) – два интегрированных ряда. |
|
|
Если для любого b |
||
|
yt – b xt ~ I(1), |
||
|
то регрессия yt на |
xt является фиктивной, и мы уже выяснили, как следует |
действовать в такой ситуации.
Обратимся теперь к случаю, когда при некотором b ≠ 0 yt – b xt ~ I(0) – стационарный ряд.
Если это так, то ряды yt и xt называют коинтегрированными рядами, а вектор (1, – b)T – коинтегрирующим вектором.
Вообще, ряды yt ~ I(1), xt ~ I(1) называют коинтегрированными (в узком смысле – детерминистская коинтеграция), если существует ненулевой (коинтегрирующий)
вектор β = (β1, β2)T ≠ 0 , для которого
β1 xt + β2 yt ~ I(0) – стационарный ряд.
Заметим, что если вектор β = (β1, β2)T является коинтегрирующим вектором для рядов xt и yt , то тогда коинтегрирующим для этих рядов будет и любой вектор вида сβ = (сβ1, сβ2)T , где с ≠ 0 – постоянная величина. Чтобы выделить какой-то определенный вектор, приходится вводить условие нормировки, например, рассматривать только векторы вида (1, – b)T (или только векторы (– a, 1)T ).
Поскольку мы предполагаем сейчас, что xt , yt ~ I(1), то ряды разностей ∆xt , ∆yt стационарны. Будем предполагать в дополнение, что стационарен векторный ряд (∆xt , ∆yt)T , так что для него существует разложение Вольда в виде скользящего среднего
(∆xt , ∆yt)T = µ + B(L) εt ,
где
µ = (µ 1, µ 2 )T , µ 1 = E(∆xt ) , µ 2 = E(∆yt) ;
εt = (ε1t , ε2t )T – векторный белый шум,
т.е.
|
ε 1, ε 2 , … |
– последовательность не коррелированных между собой, одинаково |
||||||||
|
распределенных случайных векторов, для которых |
|||||||||
|
E(εt) = (0, 0)T , |
D(ε1t) = σ12 , D(ε2t) = σ22 , Cov(ε1t , ε2t ) = σ12 – постоянные величины; |
||||||||
|
1 |
0 |
∞ b |
(k ) |
b |
(k ) |
k |
|||
|
11 |
12 |
L |
. |
||||||
|
B(L) = |
0 |
1 |
+∑ |
b |
(k ) |
b |
(k ) |
||
|
k =1 |
|||||||||
|
21 |
22 |
Знаменитый результат Гренджера ([Granger (1983)], см. также [Engle, Granger (1987)])
состоит в том, что в случае коинтегрированности I(1) рядов xt и yt (в узком смысле)
|
(I) |
В разложении Вольда (∆xt , ∆yt)T = µ + B(L) εt матрица B(1) имеет ранг 1. |
|
(II)Система рядов xt и yt допускает векторное ARMA представление |
A(L) (xt, yt )T = c + d(L)εt ,
в котором
εt – тот же векторный белый шум, что и в (I), c = (c1, c2)T , c1 и c2 – постоянные,
A(L) – матричный полином от оператора запаздывания, d(L) – скалярный полином от оператора запаздывания, причем
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
17 |
A(0) = I2 (единичная матрица размера 2×2), rank A(1) = 1 (ранг 2×2-матрицы A(1) равен 1),
значение d(1) конечно.
Всвязи с тем, что в последнем представлении ранг (2×2)-матрицы A(1) меньше двух, об этом представлении часто говорят как о векторной авторегрессии пониженного ранга (reduced rank VAR).
Вразвернутой форме представление (II) имеет вид
|
p |
q |
|||||||||||||||
|
xt =c1 + |
∑(a1j xt − j +b1j yt − j )+ |
∑θkε1,t − k , |
||||||||||||||
|
j =1 |
k = 0 |
|||||||||||||||
|
p |
(a |
)+ |
q θ |
|||||||||||||
|
y |
t |
=c |
2 |
+ |
2 j |
x |
t − j |
+b |
y |
t − j |
ε |
2,t − k |
||||
|
∑ |
2 j |
∑ k |
||||||||||||||
|
j =1 |
k = 0 |
При этом верхние пределы p и q у сумм в правых частях могут быть бесконечными.
Если возможно векторное AR представление, то в нем d(L) ≡ 1 , p < ∞ .
|
(III) |
Система рядов xt и yt допускает представление в форме модели |
||
|
коррекции ошибок (error correction model – ECM) |
|||
|
∆xt =µ1 +α1zt −1 +∑∞ (γ 1j ∆xt − j +δ1j ∆yt − j )+ ∑∞ θkε1,t − k , |
|||
|
j =1 |
k = 0 |
||
|
∆yt = µ2 +α2 zt −1 +∑∞ (γ 2 j ∆xt − j +δ 2 j ∆yt − j )+ ∑∞ θkε2,t − k , |
|||
|
j =1 |
k = 0 |
||
|
где |
|||
|
zt = yt – β xt – E(yt – β xt) |
– стационарный ряд с нулевым |
математическим |
|
|
ожиданием, |
zt ~ I(0),
и
α12 + α22 > 0.
Если в (II) возможно векторное AR(p) представление (p < ∞), то тогда ECM принимает вид
∆xt =µ1 +α1zt −1 +∑p −1(γ 1j ∆xt − j +δ1j ∆yt − j ) +ε1,t , j =1
∆yt = µ2 +α2 zt −1 +∑p −1(γ 2 j ∆xt − j +δ 2 j ∆yt − j )+ε2,t , j =1
Здесь важно отметить следующее:
•Если ряды xt , yt ~ I(1) коинтегрированы, то все составляющие в ECM стационарны.
•Если векторный ряд (xt , yt)T ~ I(1) (так что векторный ряд (∆xt , ∆yt)T стационарен) и порождается ECM моделью, то ряды xt и yt коинтегрированы. (Действительно, в этом случае все составляющие ECM, отличные от zt–1, стационарны; но тогда стационарна и zt – 1.)
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
18 |
• Если ряды xt , yt ~ I(1) коинтегрированы, то тогда VAR в разностях не может иметь конечный порядок. (В отличие от случая, когда ряды xt и yt не коинтегрированы.)
|
Абсолютную величину zt = yt – α – β xt , где α = E(yt – β xt), |
можно рассматривать как |
|
|
расстояние, отделяющее систему в |
момент t от |
равновесия, задаваемого |
|
соотношением yt – α – β xt = 0. |
Величины и направления изменений xt и yt |
принимают во внимание величину и знак предыдущего отклонения от равновесия zt – 1 . Ряд zt , конечно, вовсе не обязательно убывает по абсолютной величине при переходе от одного периода времени к другому, но он является стационарным рядом, и поэтому расположен к движению по направлению к своему среднему.
Замечание 1
Переменная xt не является причиной по Гренджеру для переменной yt , если неучет прошлых значений переменной xt не приводит к ухудшению качества прогноза значения yt по совокупности прошлых значений этих двух переменных. Переменная yt не является причиной по Гренджеру для переменной xt , если неучет прошлых значений переменной yt не приводит к ухудшению качества прогноза значения xt по совокупности прошлых значений этих двух переменных. (Качество прогноза измеряется среднеквадратичной ошибкой прогноза.)
Если xt , yt ~ I(1) и коинтегрированы, то должна иметь место причинность по Гренджеру , по крайней мере, в одном направлении. Этот факт вытекает из представления такой системы рядов в форме ECM, в которой α12 + α22 > 0. Значение xt
– 1 через посредство zt– 1 помогает в прогнозировании значения yt (т.е. переменная xt является причиной по Гренджеру для переменной yt), если α2 ≠ 0. Значение yt – 1 через посредство zt– 1 помогает в прогнозировании значения xt (т.е. переменная yt является причиной по Гренджеру для переменной xt), если α1 ≠ 0.
Замечание 2
Пусть xt , yt ~ I(1) коинтегрированы и wt ~ I(0). Тогда для любого k коинтегрированы ряды xt и γ yt – k + wt , γ ≠ 0. Формально, если xt ~ I(1), то коинтегрированы ряды xt
и xt – k . (Действительно, тогда xt – xt – k = ∆xt + ∆xt – 1 + … + ∆xt – k – сумма I(0)- переменных, которая также является I(0)-переменной.)
Итак, при коинтегрированности рядов xt , yt ~ I(1) мы имеем
|
• |
модель долговременной (равновесной) связи yt = α + β xt ; |
•модель краткосрочной динамики в форме ECM,
иэти модели согласуются друг с другом.
Проблема, однако, состоит в том, что для построения ECM по реальным статистическим данным нам надо знать коинтегрирующий вектор (в данном случае, знать значение β). Хорошо, если этот вектор определяется экономической теорией. К сожалению, чаще его приходится оценивать по имеющимся данным.
Энгл и Гренджер [Engle, Granger (1987)] рассмотрели двухшаговую процедуру, в которой на первом шаге значения α и β оцениваются в рамках модели регрессии yt на xt
yt = α + β xt + ut .
Получив методом наименьших квадратов оценки αˆ и βˆ (НK-оценки), мы тем самым находим оцененные значения отклонений от положения равновесия
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
19 |
zˆt = yt – αˆ – βˆ xt
– это просто остатки от оцененной регрессии.
После этого, на втором шаге, методом наименьших квадратов раздельно (не как система!) оцениваются уравнения
∆xt =µ1 +α1zˆt −1 +∑p −1(γ 1j ∆xt − j +δ1j ∆yt − j ) +ν t , j =1
∆yt = µ2 +α2 zˆt −1 + ∑p −1(γ 2 j ∆xt − j +δ 2 j ∆yt − j ) +wt , j =1
(т.е. предполагается модель VAR(p) для xt , yt).
Определяющим в этой процедуре является то обстоятельство, что получаемая на первом шаге оценка βˆ быстрее обычного приближается (по вероятности) к истинному
значению β – второй компоненте коинтегрирующего вектора (1, β)T . ( βˆ является суперсостоятельной оценкой для β .) Это, в конечном счете, приводит к тому, что оценки в отдельном уравнении ECM, использующие оцененные значения zt−1 , имеют то же самое асимптотическое распределение, что и оценка максимального правдоподобия, использующая истинные значения zt−1 . (Обычно это асимптотически
нормальное распределение.) При этом НК-оценки стандартных ошибок всех коэффициентов являются состоятельными оценками истинных стандартных ошибок.
Заметим, что последние результаты справедливы несмотря на то, что ряд оцененных значений zˆt формально не является стационарным, поскольку βˆ ≠ β.
Отметим также, что если мы хотим использовать другую нормировку коинтегрирующего вектора в виде (β, 1)T , то нам придется оценивать регрессию xt на константу и yt , и это приведет к вектору, не пропорциональному вектору, оцененному в первом случае.
Замечание
|
ˆ |
|
|
Тот факт, что β |
быстрее обычного сходится (по вероятности) к β , вовсе не |
означает,что мы можем пользоваться на первом шаге процедуры Энгла – Гренджера обычными регрессионными критериями. Дело в том, что получаемые на первом шаге оценки и статистики, вообще говоря, имеют нестандартные асимптотические распределения.
Однако первый шаг является в данном контексте вспомогательным, и на этом шаге нет необходимости обращать внимание на сообщаемые в протоколах соответствующих пакетов программ значения статистик.
Напротив, на втором шаге мы можем использовать обычные статистические процедуры (разумеется, если количество наблюдений не мало и если коинтеграция имеется).
Пример Расмотрим реализацию процесса порождения данных
DGP: xt = xt – 1 + εt , yt = 2 xt + νt ,
где x1 = 0, а εt и νt – порождаемые независимо друг от друга последовательности независимых, одинаково распределенных случайных величин, имеющих стандартное
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
20 |
|||||||||||
|
нормальное распределение |
N(0, |
1). Графики полученных реализаций рядов |
xt |
и |
yt |
|||||||
|
имеют следующий вид |
||||||||||||
|
10 |
||||||||||||
|
0 |
||||||||||||
|
-10 |
||||||||||||
|
-20 |
||||||||||||
|
-30 |
||||||||||||
|
-40 |
||||||||||||
|
10 |
20 |
30 |
40 |
50 |
60 |
70 |
80 |
90 |
100 |
|||
|
Y |
X |
Пара (xt , yt) образует векторный процесс авторегрессии
xt = xt – 1 + εt , yt = 2 xt – 1 + ηt ,
где ηt = νt + 2εt ~ i.i.d. N(0, 5).
В форме ECM пара уравнений принимает вид
∆xt = εt ,
∆yt = – (yt – 1 – 2 xt – 1) + ηt = – zt + где zt = yt – 2 xt ,
или
∆xt = α1 zt – 1 + εt ,
∆yt = α2 zt – 1 + ηt ,
где α1 = 0, α2 = – 1, так что α12
На практике, приступая к анализу статистических данных, исследователь не знает точно, какой порядок имеет VAR в DGP. Имея это в виду, выберем для оценивания в качестве статистической модели ECM в виде
∆xt = α1 zt – 1 + γ11∆xt – 1 + δ11∆yt – 1 + vt ,
∆yt = α2 zt – 1 + γ21∆xt – 1 + δ21∆yt – 1 + wt ,
допуская, что данные порождаются моделью векторной авторегрессии второго порядка (p = 2). Для анализа используем 100 наблюдений.
(I шаг) Исходим из модели yt = α + β xt + ut . Оцененная модель:
|
Dependent Variable: Y |
||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
C |
-0.006764 |
0.165007 |
-0.040992 |
0.9674 |
|
X |
1.983373 |
0.020852 |
95.11654 |
0.0000 |
|
R-squared |
0.989284 |
Durbin-Watson stat |
2.217786 |
т.е.
yt = – 0.006764 + 1.983373 xt + uˆt ,
так что
zˆt = uˆt = yt + 0.006764 – 1.983373 xt .
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
21 |
Допустив, что VAR имеет порядок 2, при использовании критерия Дики – Фуллера для проверки рядов yt и xt на коинтегрированность в правую часть уравнения включаем одну запаздывающую разность:
∆zˆt = φ zˆt−1 + θ1∆zˆt−1 + ζt . ,
Оценивая последнее уравнение получаем:
Augmented Dickey-Fuller Test Equation Dependent Variable: D(Z) Sample(adjusted): 3 100
Included observations: 98 after adjusting endpoints
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
Z(-1) |
-1.153515 |
0.151497 |
-7.614088 |
0.0000 |
||||||||
|
D(Z(-1)) |
0.038156 |
0.100190 |
0.380837 |
0.7042 |
||||||||
Полученное значение тестовой статистики tφ = – 7.614 намного ниже 5% критического уровня –3.396 (см. [Patterson (2000), таблица 8.7]). Гипотеза некоинтегрированности рассматриваемых рядов уверенно отвергается. (Ввиду статистической незначимости коэффициента при запаздывающей разности, можно было бы переоценить модель, не включая запаздывающую разность в правую часть уравнения. Это дало бы значение tφ = – 11.423, при котором гипотеза некоинтегрированности отвергается еще более уверенно.)
Таким образом, мы принимаем решение о коинтегрированности рядов yt и xt , и переходим к построению модели коррекции ошибок.
(Шаг II) Сначала отдельно оцениваем уравнение для ∆xt :
|
Dependent Variable: D(X) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
C |
-0.028016 |
0.100847 |
-0.277810 |
0.7818 |
||||||||
|
Z(-1) |
0.250942 |
0.176613 |
1.420858 |
0.1587 |
||||||||
|
D(X(-1)) |
0.639967 |
0.257823 |
2.482201 |
0.0148 |
||||||||
|
D(Y(-1)) |
-0.258740 |
0.116654 |
-2.218019 |
0.0290 |
||||||||
Поочередное исключение из правой части уравнения переменных со статистически незначимыми коэффициентами и наибольшим P-значением приводит к оцененной модели
|
Dependent Variable: D(X) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
D(X(-1)) |
0.115141 |
0.100249 |
1.148554 |
0.2536 |
||||||||
и, в конечном счете, к модели
∆xt = νt ,
которая и была использована при порождении ряда xt . Оценивая теперь уравнение для ∆yt , получаем
|
Dependent Variable: D(Y) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
C |
-0.060101 |
0.211899 |
-0.283630 |
0.7773 |
||||||||
|
Z(-1) |
-0.641060 |
0.371097 |
-1.727472 |
0.0874 |
||||||||
|
D(X(-1)) |
1.313872 |
0.541733 |
2.425311 |
0.0172 |
||||||||
|
D(Y(-1)) |
-0.482981 |
0.245111 |
-1.970459 |
0.0517 |
||||||||
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
22 |
Исключая из правой части оцениваемого уравнения константу, получаем:
|
Dependent Variable: D(Y) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
Z(-1) |
-0.638888 |
0.369218 |
-1.730381 |
0.0868 |
||||||||
|
D(X(-1)) |
1.317763 |
0.538932 |
2.445138 |
0.0163 |
||||||||
|
D(Y(-1)) |
-0.483722 |
0.243908 |
-1.983217 |
0.0502 |
||||||||
Хотя формально здесь следовало бы начать исключение статистически незначимых переменных с zˆt −1 , мы должны принять во внимание уже принятое решение о
коинтегрированности рядов yt и xt . Но если эти ряды действительно коинтегрированы, то в ECM должно выполняться соотношение α12 + α22 > 0. Поскольку же переменная zt – 1 не вошла в правую часть уравнения для ∆xt , она должна оставаться в правой части уравнения для ∆yt . Если начать исключение с переменной ∆yt – 1 , то в оцененном редуцированном уравнении
|
Dependent Variable: D(Y) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
Z(-1) |
-1.186411 |
0.248876 |
-4.767072 |
0.0000 |
||||||||
|
D(X(-1)) |
0.331411 |
0.210732 |
1.572671 |
0.1191 |
||||||||
статистически незначим коэффициент при ∆xt – 1 , что приводит нас к уравнению ∆yt = α2 zˆt−1 + wt , оценивая которое, получаем
|
Dependent Variable: D(Y) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
Z(-1) |
-1.273584 |
0.247887 |
-5.137760 |
0.0000 |
||||||||
Проверка гипотезы H0: α2 = – 1 дает:
|
Null Hypothesis: |
C(1)= -1 |
|||||||||
|
F-statistic |
1.218077 |
Probability |
0.272441 |
|||||||
|
Chi-square |
1.218077 |
Probability |
0.269738 |
|||||||
Поскольку эта гипотеза не отвергается, мы можем остановиться на модели ECM
∆xt = εt , ∆yt = – zˆt−1 + wt ,
где
zˆt−1 = yt – 1 + 0.006764 – 1.983373 xt – 1 .
Подстановка последнего выражения для zˆt−1 в уравнение для ∆yt приводит к соотношению
yt = – 0.0068 + 1.983 xt – 1 + wt ,
которое близко к соотношению yt = 2 xt – 1 + ηt ,
соответствующему использованному DGP.
Заметим, наконец, что последовательность wt = ∆yt + zˆt−1 идентифицируется по
наблюдаемой ее реализации как гауссовский белый шум с оцененной дисперсией 4.62 (использованному DGP соответствует значение 5.00), а последовательность εt = ∆xt идентифицируется как гауссовский белый шум с оцененной дисперсией 1.04 (использованному DGP соответствует значение 1.00).
Оценив ECM и остановившись на модели
∆xt = εt , ∆yt = – zˆt−1 + wt ,
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
23 |
мы тем самым обнаруживаем, что коррекция производится только в отношении ряда yt : при положительных zˆt−1 , т.е. при
yt– 1 – (– 0.0068 + 1.983 xt – 1) > 0,
в правой части уравнения для ∆yt корректирующая составляющая – zˆt−1 отрицательна и действует в сторону уменьшения приращения переменной yt . Напротив, при отрицательных zˆt−1 корректирующая составляющая действует в сторону увеличения приращения переменной yt .
Прошлые значения переменной xt через посредство zˆt−1 помогают в прогнозировании
значения yt , т.е. переменная xt является причиной по Гренджеру для переменной yt . В то же время, прошлые значения переменной yt никак не помогают прогнозированию значения xt , так что yt не является причиной по Гренджеру для xt .
Заметим далее, что даже если в ECM Cov(vt, wt) ≠ 0, оценивание пары уравнений ЕСМ как системы не повышает эффективности оценок, поскольку в правые части обоих уравнений входят одни и те же переменные.
Расмотренный в нашем примере процесс порождения данных
DGP: xt = xt – 1 + εt , yt = 2 xt + νt ,
является частным случаем модели, известной как треугольная система Филлипса. В общем случае (для двух рядов) эта система имеет вид
yt = β xt + νt , xt = xt – 1 + εt ,
где (εt , νt)T ~ i.i.d. N2(0, Σ) – последовательность независимых, одинаково распределенных случайных векторов, имеющих двумерное нормальное распределение с нулевым математическим ожиданием и ковариационной матрицей Σ . (Такая последовательность называется двумерным гауссовским белым шумом.)
Если матрица Σ диагональная, так что Cov(εt , νt) = 0, то тогда xt является экзогенной переменной в первом уравнении, и никаких проблем с оцениванием коэффициента β в этом случае не возникает.
Если же Cov(εt , νt) ≠ 0, то тогда xt уже не является экзогенной переменной в первом уравнении, т.к. при этом Cov(xt , νt) = Cov(xt – 1 + εt , νt) ≠ 0. Поэтому получаемая в первом уравнении оценка наименьших квадратов для β не имеет даже асимптотически нормального распределения.
В дальнейшем мы еще вернемся к проблеме оценивания коинтегрирующего вектора, а сейчас обратимся к вопросу о коинтеграции нескольких временных рядов.
Пусть мы имеем N временных рядов y1t , … , yN t , каждый из которых является интегрированным порядка 1. Если существует такой вектор β = (β1, … , βN)T , отличный от нулевого, для которого
β1 y1t + … + βN yN t ~ I(0) – стационарный ряд,
то говорят, что эти ряды коинтегрированы (в узком смысле); такой вектор β называется коинтегрирующим вектором. Если при этом
c = E(β1 y1t + … + βN yN t),
то тогда можно говорить о долговременном положении равновесия системы в виде
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
24 |
β1 y1t + … + βN yN t = c .
В каждый конкретный момент времени t существует некоторое отклонение системы от этого положения равновесия, характеризующееся величиной
zt = β1 y1t + … + βN yN t – c .
Ряд zt , в силу сделанных предположений, является стационарным рядом, имеющим нулевое математическое ожидание, так что он достаточно часто пересекает нулевой уровень, т.е. система колеблется вокруг указанного выше положения равновесия.
Естественной процедурой для проверки коинтегрированности рядов y1t , … , yN t является построение регрессии одного из этих рядов на остальные N – 1 рядов и проверка гипотезы наличия единичного корня у ряда zt на основании исследования ряда остатков от оцененной регрессии. Иначе говоря, мы оцениваем, например, модель
y1t = θ1 + θ2 y2 t + … + θN yN t + ut ,
и проверяем гипотезу единичного корня на основании исследования ряда остатков uˆt = y1t – (θˆ1+ θˆ2 y2 t + … + θˆN yN t),
опираясь на статистику Дики – Фуллера. Критические значения можно найти, следуя
[MacKinnon (1991)] (см. также [Patterson (2000), таблица A8.1]).
Если гипотеза единичного корня отвергается, то вектор
βˆ = (1, – θˆ2 , … , – θˆN )
берется в качестве оцененного коинтегрирующего вектора. При этом отклонение системы от положения равновесия оценивается величиной
zˆt = uˆt .
Поясним теперь, что мы имели в виду, оговаривая, что приведенные выше определения коинтеграции соответствуют коинтеграции в узком смысле.
В приведенных определениях ненулевой вектор β = (β1, … , βN)T определялся как коинтегрирующий вектор, если β1 y1t + … + βN yN t – стационарный ряд. Это означает, что если ряды y1t , … , yN t (по крайней мере, некоторые из них) содержат, наряду со стохастическим, еще и детерминированные тренды, то тогда коинтегрирующий вектор должен аннулировать оба вида трендов одновременно. И в связи с этим, коинтеграцию в узком смысле называют еще детерминистской коинтеграцией.
7.3. Проверка нескольких рядов на коинтегрированность. Критерии Дики – Фуллера
Здесь надо различать несколько случаев.
(1) Коинтегрирующий вектор определяется экономической теорией.
Тогда надо просто проверить на наличие единичного корня соответствующую линейную комбинацию
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
25 |
β1 y1t + … + βN yN t .
При этом используются те же критические значения, которые рассчитаны на применение к отдельно взятому ряду; эти значения не зависят от количества задействованных рядов N .
Пусть возможный коинтегрирующий вектор не определен заранее.
Тогда отдельно рассматриваются следующие ситуации.
(2) Ряды y1t , … , yN t не имеют детерминированного тренда (точнее, E(∆yk t) = 0).
(2a) В коинтеграционное соотношение (SM) константа не включается.
В этом случае мы оцениваем
SM: y1t = γ2 y2t + … + γN yN t + ut ,
получаем ряд остатков
uˆt = y1t − (γˆ2 y2 t +K+ γˆN yN t ),
оцениваем модель регрессии
∆uˆt = ϕ uˆt −1 +ζ1∆uˆt −1 +K+ζ K ∆uˆt − K + εt
с достаточным количеством запаздывающих разностей и проверяем гипотезу H0: φ
= 0 против альтернативы H0: φ < 0 .
На этот раз критические значения для t-статистики tφ зависят от количества задействованных рядов N . При большом количестве наблюдений можно использовать
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
26 |
критические значения, приведенные в [Hamilton (1994), Table B.9, Case 1]. Однако на практике в правую часть оцениваемого уравнения константа обычно включается.
(2b) В коинтеграционное соотношение (SM) константа включается.
В этом случае мы оцениваем
SM: y1t = α + γ2 y2t + … + γN yN t + ut ,
опять получаем ряд остатков – теперь это будет ряд
uˆt = y1t − (αˆ + γˆ2 y2 t +K+ γˆN yN t ),
оцениваем модель регрессии
∆uˆt = ϕ uˆt −1 +ζ1∆uˆt −1 +K+ζ K ∆uˆt − K + εt
с достаточным количеством запаздывающих разностей и проверяем гипотезу H0: φ
= 0 против альтернативы H0: φ < 0 .
Критические значения в этом случае отличаются от случая (2a). При большом
количестве наблюдений можно использовать критические значения, приведенные в
[Hamilton (1994), Table B.9, Case 2]. При небольших T критические значения
вычисляются по формуле, приведенной в [MacKinnon (1991), таблица 1 (вариант “no
trend”)] и воспроизведенной в [Patterson (2000)].
|
(3) |
Хотя бы один из рядов y2t , … , yN t имеет линейный тренд , так что E(∆yk t) |
|
≠ 0 |
хотя бы для одного из регрессоров. |
(3a) В коинтеграционное соотношение включается константа.
В этом случае оценивается
SM: y1t = α + γ2 y2t + … + γN yN t + ut .
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
27 |
Далее действуем опять как в (2b), только критические значения другие. При
большом количестве наблюдений можно использовать критические значения,
приведенные в [Hamilton (1994), Table B.9, Case 3]. При небольших T критические
значения вычисляются по формуле, приведенной в работе [MacKinnon (1991), Table
1 (вариант “with trend”)] и воспроизведенной в [Patterson (2000)].
(3b) В коинтеграционное соотношение включается линейный тренд.
В этом случае оценивается
SM: y1t = α + δt + γ2 y2t + … + γN yN t + ut .
Действуя так же, как и ранее, используем те же таблицы, что и в (3a), но только не для N , а для N + 1 переменных.
Включение тренда в коинтеграционное соотношение приводит к уменьшению
мощности критерия из-за необходимости оценивания “мешающего” параметра δ .
Однако такой подход вполне уместен в тех случаях, когда нет полной уверенности в
том, имеется ли ненулевой тренд хотя бы у одного из рядов y1t, y2t , … , yN t .
Пример
Смоделируем реализации четырех рядов y1t , y2t , y3t , y4t , следуя процессу порождения данных
DGP: y1t = y2, t + y3, t + y4, t + ε1t ,
y2t = y2, t – 1 + ε2t , y3t = y3, t – 1 + ε3t , y4t = y4, t – 1 + ε4t ,
где ε1t , ε2t , ε3t , ε4t – независимые друг от друга процессы гауссовского белого шума с дисперсиями, равными 1 для ε2t , ε3t , ε4t и 2 для ε1t .
Графики полученных реализаций для T = 200 приведены ниже.
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
28 |
|||||||||
|
60 |
||||||||||
|
40 |
||||||||||
|
20 |
||||||||||
|
0 |
||||||||||
|
-20 |
||||||||||
|
-40 |
||||||||||
|
-60 |
||||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
|
Y1 |
Y3 |
|||||||||
|
Y2 |
Y4 |
Не зная точно процесс порождения данных, мы должны были бы начать с исследования отдельных рядов. У всех четырех рядов не обнаруживается детерминированного тренда. Проверка по критерию Дики – Фуллера дает значения t-статистик, равные – 2.18, – 1.78, – 0.57, –1.70, соответственно. Все 4 ряда признаются интегрированными. Продифференцированные ряды идентифицируются как гауссовские белые шумы, так что ряды y1t , y2t , y3t , y4t идентифицируются как AR(1) ряды с единичным корнем, т.е. как интегрированные ряды порядка 1.
Теперь можно приступить к проверке этих четырех рядов на коинтегрированность. (1) Если “экономическая теория” предполагает теоретическое
долговременное соотношение между рассматриваемыми рядами в форме
|
y1t = y2, t + y3, t + y4, t , |
|||||||||
|
то мы просто проверяем на интегрированность ряд |
|||||||||
|
y1t – y2, t – y3, t – y4, t . |
|||||||||
|
График этого ряда |
|||||||||
|
8 |
|||||||||
|
6 |
|||||||||
|
4 |
|||||||||
|
2 |
|||||||||
|
0 |
|||||||||
|
-2 |
|||||||||
|
-4 |
|||||||||
|
-6 |
|||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
COINT |
вполне похож на график стационарного ряда, что подтверждается проверкой по критерию Дики – Фуллера: вычисленное значение t-статистики критерия равно – 15.07. Гипотеза некоинтегрированности рядов отвергается.
Представим теперь, что теория не предлагает нам готового коинтегрирующего вектора.
(2a) Оценивание статистической модели без включения в нее константы дает:
Dependent Variable: Y1
Method: Least Squares
|
Variable |
Coefficient Std. Error |
t-Statistic |
Prob. |
|||||||||
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
29 |
||||||||||||||
|
Y2 |
0.996084 |
0.009973 |
99.88161 |
0.0000 |
|||||||||||
|
Y3 |
0.992550 |
0.009578 |
103.6296 |
0.0000 |
|||||||||||
|
Y4 |
1.002305 |
0.012393 |
80.87922 |
0.0000 |
|||||||||||
При оценивании тестового уравнения Дики – Фуллера для ряда остатков получаем
|
Augmented Dickey-Fuller Test Equation |
|||||||||||||
|
Dependent Variable: D(RESID_2A) |
|||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|||||||||
|
RESID_2A(-1) |
-1.075552 |
0.070892 |
-15.17178 |
0.0000 |
|||||||||
Вычисленное значение t-статистики критерия равно – 15.17, что намного ниже 5%
критического значения – 3.74 ([Hamilton (1994), Table B.9, Case 1]). Гипотеза некоинтегрированности отвергается.
(2b) Оценивание статистической модели с включением константы:
|
Dependent Variable: Y1 |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
C |
0.332183 |
0.373542 |
0.889279 |
0.3749 |
||||||||
|
Y2 |
1.002583 |
0.012369 |
81.05843 |
0.0000 |
||||||||
|
Y3 |
0.987369 |
0.011215 |
88.04048 |
0.0000 |
||||||||
|
Y4 |
0.999022 |
0.012937 |
77.22129 |
0.0000 |
||||||||
При оценивании тестового уравнения Дики – Фуллера для ряда остатков получаем
|
Augmented Dickey-Fuller Test Equation |
|||||||||||||
|
Dependent Variable: D(RESID_2B) |
|||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|||||||||
|
RESID_2B(-1) |
-1.079049 |
0.070861 |
-15.22764 |
0.0000 |
|||||||||
Вычисленное значение t-статистики – 15.23 опять намного ниже 5% критического значения, которое здесь равно – 4.11 ([Hamilton (1994), Table B.9, Case 2]). Гипотеза некоинтегрированности отвергается.
|
(3) Модифицируем теперь ряд y1t , переходя к ряду y*1t = y1t + 0.75t , график которого |
|||||||||
|
в сравнении с графиком ряда y1t |
имеет следующий вид: |
||||||||
|
200 |
|||||||||
|
150 |
|||||||||
|
100 |
|||||||||
|
50 |
|||||||||
|
0 |
|||||||||
|
-50 |
|||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
Y1 |
Y1_STAR |
||||||||
|
Картина изменения всех 4 рядов принимает вид |
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
30 |
|||||||||
|
200 |
||||||||||
|
150 |
||||||||||
|
100 |
||||||||||
|
50 |
||||||||||
|
0 |
||||||||||
|
-50 |
||||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
|
Y1_STAR |
Y3 |
|||||||||
|
Y2 |
Y4 |
(3a) Оцениваем статистическую модель с константой в правой части:
|
Dependent Variable: Y1_STAR |
|||
|
Variable |
Coefficient Std. Error |
t-Statistic |
Prob. |
|
C |
11.49053 |
2.704802 |
4.248195 |
0.0000 |
||||||
|
Y2 |
-1.333762 |
0.089561 |
-14.89224 |
0.0000 |
||||||
|
Y3 |
2.856952 |
0.081207 |
35.18115 |
0.0000 |
||||||
|
Y4 |
0.072630 |
0.093677 |
0.775323 |
0.4391 |
||||||
|
В этом случае график остатков имеет несколько отличный вид: |
||||||||||
|
15 |
||||||||||
|
10 |
||||||||||
|
5 |
||||||||||
|
0 |
||||||||||
|
-5 |
||||||||||
|
-10 |
||||||||||
|
-15 |
||||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
|
RESID_3A |
||||||||||
|
Проверка по Дики – Фуллеру дает следующие результаты: |
При оценивании тестового уравнения Дики – Фуллера для ряда остатков получаем
|
Augmented Dickey-Fuller Test Equation |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
RESID_3A(-1) |
-0.119805 |
0.033630 |
-3.562431 |
0.0005 |
||||||||
Вычисленное значение t-статистики – 3.56 выше 5% критического значения, которое здесь равно – 4.16 ([Hamilton (1994), Table B.9, Case 3]). Гипотеза некоинтегрированности не отвергается.
(3b) Включаем в правую часть тренд:
|
Dependent Variable: Y1_STAR |
||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
C |
0.304068 |
0.390739 |
0.778187 |
0.4374 |
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
31 |
||||||||||
|
@TREND |
0.751890 |
0.007507 |
100.1621 |
0.0000 |
|||||||
|
Y2 |
1.008470 |
0.026468 |
38.10166 |
0.0000 |
|||||||
|
Y3 |
0.982658 |
0.021830 |
45.01453 |
0.0000 |
|||||||
|
Y4 |
1.001356 |
0.015942 |
62.81247 |
0.0000 |
|||||||
|
График остатков: |
|||||||||||
|
8 |
|||||||||||
|
6 |
|||||||||||
|
4 |
|||||||||||
|
2 |
|||||||||||
|
0 |
|||||||||||
|
-2 |
|||||||||||
|
-4 |
|||||||||||
|
-6 |
|||||||||||
|
-8 |
|||||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
||
|
RESID_3B |
|||||||||||
|
Последний график похож на график стационарного ряда, что подтверждается |
|||||||||||
|
проверкой по Дики – Фуллеру: |
|
Augmented Dickey-Fuller Test Equation |
|||||||||||||
|
Dependent Variable: D(RESID_3B) |
|||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|||||||||
|
RESID_3B(-1) |
-1.079492 |
0.070859 |
-15.23448 |
0.0000 |
|||||||||
Вычисленное значение t-статистики – 15.234 намного ниже 5% критического значения, которое здесь равно –4.49 ([Hamilton (1994), Table B.9, Case 3]). Гипотеза некоинтегрированности отвергается.
Последние два результата весьма важны для уточнения того, что понимается под коинтеграцией в настоящее время.
Фактически, мы обнаружили следующее. Ряды y1t , y2t , y3t , y4t коинтегрированы в том смысле, который был определен выше (коинтегрированы в узком смысле). Именно в таком виде ввели в обиход понятие коинтеграции Энгл и Гренджер. Ряды y*1t , y2t , y3t , y4t не являются коинтегрированными в узком смысле. В то же время, включение в правую часть статистической модели трендовой составляющей приводит к стационарным остаткам.
Вспомним в связи с этим, что при включении тренда в правую часть линейного регрессионного уравнения коэффициенты при объясняющих переменных интерпретируются как коэффициенты линейной связи между переменными, очищенными от детерминированного тренда. Последние же действительно были коинтегрированы по построению.
Наблюдаемая ситуация известна теперь под названием “стохастическая коинтеграция”. Оно указывает на наличие коинтеграционной связи между стохастическими трендами, входящими в состав рассматриваемых рядов, и не требует согласованности детерминированных трендовых составляющих ( если таковые имеются). В этом случае коинтегрирующий вектор аннулирует стохастический тренд, но не обязан одновременно аннулировать и детерминированный тренд. Другими словами, существует линейная комбинация рассматриваемых рядов, которая образует ряд, стационарный относительно детерминированного тренда, но не обязательно стационарный.
В противоположность стохастической коинтеграции, при наличии коинтеграции в узком смысле коинтегрирующий вектор аннулирует и стохастический и
www.iet.ru/mipt/2/text/curs_econometrics.htm
12.1. Проблема обнаружения ложной корреляции в данных
Тренды в данных могут привести к ложным корреляциям, следствием которых являются ложные связи между переменными в регрессионном уравнении. Однако в действительности между собой коррелируют только временные тренды.
Временной тренд может быть исключен из результирующей переменной путем построения регрессии этой переменной по времени и перехода к остаткам, которые образуют новую стационарную переменную, уже свободную от тренда. Или этот тренд может быть сразу включен в модель путем введения времени в качестве одной из переменных-регрессоров. При этом используются регрессионные модели, основанные на стандартных  — и
— и 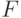 -тестах и оперирующие со стационарными временными рядами, имеющими постоянные средние и дисперсии.
-тестах и оперирующие со стационарными временными рядами, имеющими постоянные средние и дисперсии.
При построении регрессии нестационарной переменной на детерминированную переменную времени остатки обычно не дают в результате стационарную переменную.
Рассмотрим, например, два процесса случайного блуждания
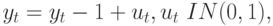 |
(12.1) |
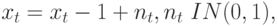 |
(12.2) |
где
 |
— | класс временных рядов с независимыми приращениями с нулевым средним и единичной дисперсией, подчиняющимися нормальному закону. |
Оба процесса представляют некоррелированные нестационарные переменные. Поэтому, если оценивается регрессионная модель
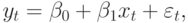 |
(12.3) |
то естественно за нулевую гипотезу 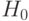 принять, что
принять, что 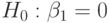 , и ожидать, что коэффициент детерминации
, и ожидать, что коэффициент детерминации 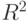 будет близок к нулю. Однако нестационарная природа данных влечет нестационарность
будет близок к нулю. Однако нестационарная природа данных влечет нестационарность 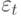 . Таким образом, любая тенденция к росту в обоих рядах ведет к появлению корреляции, которая и будет отражена в регрессионный модели. Хотя каждый ряд растет по совершенно разным причинам с некоррелированными уровнями роста, а значит, что в уравнении
. Таким образом, любая тенденция к росту в обоих рядах ведет к появлению корреляции, которая и будет отражена в регрессионный модели. Хотя каждый ряд растет по совершенно разным причинам с некоррелированными уровнями роста, а значит, что в уравнении 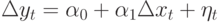 коэффициент
коэффициент 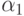 сходится по вероятности к нулю. Итак, корреляция между нестационарными рядами еще не означает наличие существенных (причинных) связей между ними, как это выводится в случае стационарных рядов.
сходится по вероятности к нулю. Итак, корреляция между нестационарными рядами еще не означает наличие существенных (причинных) связей между ними, как это выводится в случае стационарных рядов.
Кроме того, проблема ложной (кажущейся) корреляции, выражающаяся в ненулевой оценке коэффициента  , осложняется тем, что обычные выборочные — и -статистики не имеют стандартных распределений, как в случае стационарных рядов. Существует явная тенденция к отрицанию гипотезы , которая возрастает по мере увеличения объема выборки. Были проведены по методу Монте-Карло следующие эксперименты. Уравнение (12.3) было оценено 10 000 раз, при этом
, осложняется тем, что обычные выборочные — и -статистики не имеют стандартных распределений, как в случае стационарных рядов. Существует явная тенденция к отрицанию гипотезы , которая возрастает по мере увеличения объема выборки. Были проведены по методу Монте-Карло следующие эксперименты. Уравнение (12.3) было оценено 10 000 раз, при этом  и
и 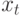 определялись по уравнениям (12.1) и (12.2). В результате оценок среднее значение
определялись по уравнениям (12.1) и (12.2). В результате оценок среднее значение 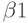 оказалось равным
оказалось равным 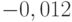 и соответствующая стандартная ошибка равна
и соответствующая стандартная ошибка равна 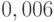 (при размере выборки
(при размере выборки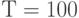 ). Это дает отрицание нулевой гипотезы. Основываясь на 10 000 повторений, вероятность отрицания при уровне значимости 0,05 равна 0,753, т.е. для 75,3% регрессий были получены значения -статистики с
). Это дает отрицание нулевой гипотезы. Основываясь на 10 000 повторений, вероятность отрицания при уровне значимости 0,05 равна 0,753, т.е. для 75,3% регрессий были получены значения -статистики с  . Это объясняется тем, что средняя -статистика, полученная в эксперименте, равна -0,12 с соответствующим стандартным отклонением 7,3. Нестандартное распределение -статистики привело к очень высокой вероятности отрицания гипотезы .
. Это объясняется тем, что средняя -статистика, полученная в эксперименте, равна -0,12 с соответствующим стандартным отклонением 7,3. Нестандартное распределение -статистики привело к очень высокой вероятности отрицания гипотезы .
Это позволяет сделать вывод, что проблема ошибочного обнаружения связей часто возникает в не связанных между собой нестационарных временных рядах. Данная проблема возрастает с ростом выборки и не может быть разрешена путем выделения трендов в изучаемых рядах, как для стационарных рядов с временным трендом.
Возникает вопрос: когда можно делать вывод о причинной долговременной связи между нестационарными рядами, основываясь на регрессионном уравнении (12.3)? Решение этой проблемы лежит в области коинтеграции нестационарных временных рядов.
Говорят, что ряд содержит единичные корни и интегрируем с порядком  , т.е. принадлежит классу
, т.е. принадлежит классу 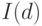 , если он становится стационарным после взятия раз операций вычисления разности от временного ряда. В общем случае любая линейная комбинация рядов класса должна также принадлежать . Однако если существует такой вектор
, если он становится стационарным после взятия раз операций вычисления разности от временного ряда. В общем случае любая линейная комбинация рядов класса должна также принадлежать . Однако если существует такой вектор 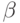 , при котором вектор возмущений
, при котором вектор возмущений 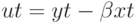 имеет меньший порядок интеграции
имеет меньший порядок интеграции 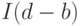 , где
, где  , то, по определению Р. Энгла и К. Грангера, и коинтегрированы с порядком
, то, по определению Р. Энгла и К. Грангера, и коинтегрированы с порядком  . Если
. Если 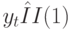 и
и 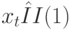 , а
, а  , то оба ряда коинтегрированы с порядком CI(1, 1).
, то оба ряда коинтегрированы с порядком CI(1, 1).
С экономической точки зрения, если два или более ряда коинтегрированы, то между ними существует равновесная устойчивая долговременная связь, хотя сами ряды содержат стохастические тренды, т.е. не стационарны. Концепция коинтеграции может быть интерпретирована как существование долговременного устойчивого равновесного соотношения между параметрами экономической системы, а (см. (12.3)) — как расстояние (ошибка) от равновесного направления в пространстве состояний  .
.
Раздел 11 регрессионный анализ для нестационарных переменных. коинтегрированные временные ряды. модели коррекции ошибок тема 11.1 проблема ложной регрессии. коинтегрированные временные ряды. модели коррекции ошибок
Проблема ложной регрессии
Начнем обсуждение с проблемы ложной (фиктивной, паразитной — spurious) регрессии. О ней говорилось в первой части учебника (см. пример 1.3.4 в разд. 1) и при этом был сделан вывод о том, что близость к 1 абсолютной величины наблюдаемого значения коэффициента детерминации необязательно означает наличие причинной связи между двумя переменными, а может являться лишь следствием наличия тренда значений обеих переменных.
ПРИМЕР 11.1.1
Смоделируем реализации двух статистически независимых между собой последовательностей єи и s2t независимых, одинаково распределенных случайных величин, имеющих стандартное нормальное распределение 7V(0, 1). Смоделированные реализации показаны на рис. 11.1 и 11.2. На их основе построим реализацию линейной модели DGP
DGP: xt = 1 +0.2t+sln
yt = 2 + 0At + e2n
в которой переменные х и у не связаны между собой причинными отношениями.
Рассмотрим, однако, результаты оценивания статистической модели
SM: yt = а + J3xt + st
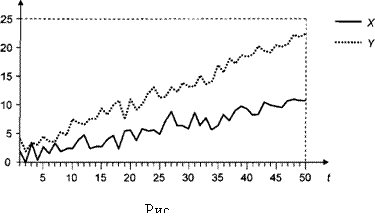 |
по смоделированной реализации. Графики рядов xt иу, приведены на рис. 11.3. Оба ряда имеют выраженные линейные тренды.
Оцененная статистическая модель приведена в табл. 11.1.
Оцененные коэффициенты статистически значимы, коэффициент детерминации высокий, проверка на адекватность не выявляет нарушений стандартных предположений классической линейной модели регрессии.
Включим в правую часть статистической модели линейный тренд. Оценивание расширенной модели дает следующий результат (табл. 11.2).
Остатки проходят тесты на адекватность, так что можно обратить внимание на протокол оценивания расширенной статистической модели. В соот ветствии с этим протоколом коэффициент при переменной xt статистически незначим, так что хп по существу, не проявляет себя в качестве переменной, объясняющей изменчивость значений переменной^.
ветствии с этим протоколом коэффициент при переменной xt статистически незначим, так что хп по существу, не проявляет себя в качестве переменной, объясняющей изменчивость значений переменной^.
Исключение xt из правой части уравнения приводит к оцененной модели (табл. 11.3), которая предпочтительнее расширенной модели и по критерию Акаике, и по критерию Шварца.
Более того, по этим критериям последняя модель намного предпочтительнее исходной модели j;, = а + j3xt + єг Это связано с тем, что при оценивании исходной SM остаточная сумма квадратов равна 233.59, а при оценивании
 последней модели — равна всего лишь 41.91. Это еще более убедительно подтверждает, что изменчивость переменной yt в действительности не объясняется изменчивостью переменной хгШ
последней модели — равна всего лишь 41.91. Это еще более убедительно подтверждает, что изменчивость переменной yt в действительности не объясняется изменчивостью переменной хгШ
В рассмотренном примере паразитная связь между переменными была обусловлена тем, что в модели DGP обе переменные имеют в своем составе детерминированный линейный тренд.
Однако ложная (паразитная) связь между переменными может возникать не только в результате наличия у этих переменных детерминированного тренда. Паразитная связь может возникать и между переменными, имеющими не детерминированный, а стохастический тренд. Приведем соответствующий пример.
ПРИМЕР 11.1.2
Возьмем процесс порождения данных в виде:
DGP: xt =х,_! + €и,
где єи и єь — те же, что и в примере 11.1.1. Графики рядов xt nyt показаны на рис. 11.4.
Предположим, что нам доступны статистические данные, соответствующие последним 50 наблюдениям (с 51-го по 100-е). Оценивание по этим наблюдениям статистической модели
SM: yt = а + j3xt + st
приводит к следующим результатам (табл. 11.4).
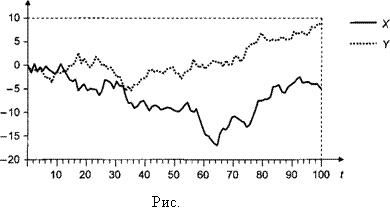 |
Таблица 11.4
Объясняемая переменная У
Sample: 51 100; Included observations: 50
|
Переменная |
Коэффициент |
Стандартная ошибка |
/-статистика |
Р-значение |
|
С |
8.616496 |
0.748277 |
11.515120 |
0.0000 |
|
X |
0.597513 |
0.077520 |
7.707873 |
0.0000 |
|
R-squared |
0.553120 |
Mean dependent var |
3.404232 |
|
|
Adjusted R-squared |
0.543810 |
S.D. dependent var |
3.354003 |
|
|
S.E. of regression |
2.265356 |
Akaike info criterion |
4.512519 |
|
|
Sum squared resid |
246.3283 |
Schwarz criterion |
4.589000 |
|
|
Log likelihood |
-110.8130 |
F-statistic |
59.41131 |
|
|
Durbin-Watson stat |
0.213611 |
Prob. (F-statistic) |
0.000000 |
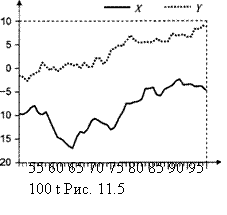 |
Несмотря на то что в DGP ряды yt и xt порождаются независимо друг от друга и их модели не содержат детерминированного тренда, здесь также наблюдаем довольно высокое значение коэффициента детерминации: 0.553. Конечно, это связано с тем, что на рассматриваемом периоде реализации обоих рядов имеют видимый тренд (рис. 11.5).
Если, однако, обратиться ко всему периоду из 100 наблюдений, то результаты оценивания будут совсем другими (табл. 11.5).
 В этом случае значение коэффициента детерминации близко к нулю, а оцененный коэффициент при xt равен 0.0551 против 0.5975, полученного при оценивании по наблюдениям с 51-го по 100-е. Это отражает действительное отсутствие детерминированного тренда в DGP и в связи с этим крайнюю нестабильность оценок коэффициента при хп полученных на различных интервалах. Последнее сопровождается также крайне низкими значениями статистики Дарбина — Уотсона (0.214 на полном периоде наблюдений и 0.062 на второй половине этого интервала). ■
В этом случае значение коэффициента детерминации близко к нулю, а оцененный коэффициент при xt равен 0.0551 против 0.5975, полученного при оценивании по наблюдениям с 51-го по 100-е. Это отражает действительное отсутствие детерминированного тренда в DGP и в связи с этим крайнюю нестабильность оценок коэффициента при хп полученных на различных интервалах. Последнее сопровождается также крайне низкими значениями статистики Дарбина — Уотсона (0.214 на полном периоде наблюдений и 0.062 на второй половине этого интервала). ■
Все указанные признаки являются характерными чертами, которые присущи результатам оценивания линейной модели связи между переменными, которые имеют стохастический (но не детерминированный!) тренд и порождаются статистически независимыми моделями. Теоретическое исследование подобной ситуации показывает следующее.
Пусть DGP: xt =xt_{ + єи, yt = yt_x + є2п где xQ = 0, yQ = 0, a eu и slt — статистически независимые между собой последовательности одинаково распределенных случайных величин, єи ~ N(0, <j{2 єь ~ N(0, сг^Х так что Cov(xn yt) = 0. Предположим, что по Т наблюдениям (хп yt)9 t 1,2, Г, производится оценивание статистической модели
SM: yt = j3xt + ип ut i.i.d. 7V(0, <тм2), Cov(xn ut) = 0.
Стандартная оценка наименьших квадратов для коэффициента J3 в этой гипотетической модели имеет вид:
т
t=
При сделанных предположениях относительно DGP оценка /3Т не сходится по вероятности при Т -> оо ни к какой константе и имеет предельное распределение, отличное от нормального.
Вместе с тем при выбранной спецификации SM (статистической модели), в предположениях этой модели (а не DGP!) имеем
Cov(xt, yt) = Cov(xn J3xt+ut) = j3Cov(xn xt) = /?£)(*,),
т.е. оцениваемым параметром является
Cov(xnyt) D(xt)
Поскольку в действительности (в DGP) Cov(xn yt) = О, то и это значение J5 равно нулю, так что если бы гипотетическая модель (соответствующая SM) была верна, то имело бы место J3T —> О по вероятности.
Далее, при Т -> со значения /-статистики tp для проверки гипотезы Я0: J3= О неограниченно возрастают по абсолютной величине, так что использование таблиц /-распределения будет практически всегда приводить к отклонению этой гипотезы, т.е. к выводу о том, что между переменными xt и yt существует линейная регрессионная связь. В действительности нетривиальное предель1
ное распределение имеет не статистика tfi9 а статистика —f=tp, причем прел/71
дельное распределение последней является нестандартным.
Что касается статистики Дарбина — Уотсона (DW), то в рассматриваемой ситуации DW —> 0 по вероятности при Т —» оо, и это позволяет распознавать неправильную спецификацию статистической модели в форме паразитной регрессии. Последнее обстоятельство проявляется в поведении остатков от оцененной статистической модели, которое не соответствует поведению стационарного процесса.
ПРИМЕР 11.1.3
В предыдущем примере было задано
DGP: xt =xt_x + єи, y,=yt-x +еЬ9
где єи и s2t — последовательности независимых, одинаково распределенных случайных величин, имеющих стандартное нормальное распределение yV(0, 1).
Мы оценивали статистическую модель
SM: yt = а + Pxt + st
и по наблюдениям с 51-го по 100-е получили
рТ = 0.598, /, = 7.708, DW= 0.214.
При этом график остатков (рис. 11.6) не похож на график стационарного ряда.И
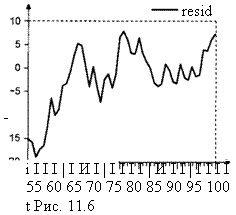 Естественно было бы для выявления такого «неподобающего» поведения остатков не просто увидеть график остатков, но и попытаться использовать формальные статистические критерии, тем более что критерии проверки интегрированное™ временных рядов были рассмотрены ранее (критерии Дики — Фуллера, Филлипса — Перрона и др.).
Естественно было бы для выявления такого «неподобающего» поведения остатков не просто увидеть график остатков, но и попытаться использовать формальные статистические критерии, тем более что критерии проверки интегрированное™ временных рядов были рассмотрены ранее (критерии Дики — Фуллера, Филлипса — Перрона и др.).
Проблема, однако, в том, что теперь мы имеем дело не с «сырым» рядом, а с рядом остатков, которые вычисляются после предварительного оценивания модели (коэффициентов а и Р в последнем примере). Это обстоятельство существенно влияет на распределения соответствующих статистик и не дает возможности пользоваться таблицами, которые были использованы ранее при анализе на интегрированность «сырых» рядов. С учетом этого были построены таблицы, позволяющие производить анализ остатков в случае интегрированных объясняемой и объясняющих переменных, о чем подробнее будет сказано в теме 11.2. Сейчас же только покажем, что дает применение соответствующих таблиц к рассмотренному выше примеру.
ПРИМЕР 11.1.4
При оценивании статистической модели SM: yt = а + Pxt + st по наблюдениям с 51-го по 100-е получили оцененную модель
yt = 8.616 + 0.598х, + е,.
С полученным рядом остатков поступим так же, как и в случае применения критерия Дики — Фуллера к «сырому» ряду, т.е. оценим модель
Aet = (pet_ j + V,
и вычислим /-статистику / для проверки гипотезы Я0: 0, интерпретируя эту гипотезу как гипотезу единичного корня для ряда остатков.
Гипотеза Н0 отвергается в пользу НА: (р < 0 (интерпретируемой как гипотеза стационарности ряда остатков), если /^ < /крит. Приближенные значения /крит (в применении к ряду остатков) можно найти по формуле: ^крит ~ к™ + КТ + ,
где к^, кх, лг2 зависят от выбранного уровня значимости и указаны в табл. П-9 в Приложении к заданиям для семинарских занятий… (MacKinnon, 1991). Для 5%-го уровня значимости
/крит * -3.3377 5.967Г»1 8.98Г»2,
что при Т = 50 дает /крит = -3.46. Последнее значение существенно меньше 5%-го критического значения статистики Дики — Фуллера (-2.92), рассчитанного для случая «сырого» ряда.
В нашем примере оценивание тестового уравнения Дики — Фуллера дает значение f = -2.01. Последнее существенно выше 5%-го критического уровня, и гипотеза единичного корня не отвергается. ■
Вообще говоря, вопрос о ложной (паразитной) или неложной (действительной) линейной регрессионной связи между двумя переменными xt и уп представляющими интегрированные ряды первого порядка (xt, yt ~ 7(1)), более точно формулируется следующим образом: существует ли такое значение Д при котором ряд yt Де, стационарен?
Если ответ на этот вопрос положительный, то говорят, что ряды xt и yt (переменные xt и yt) коинтегрированы (cointegrated time series). Если же ответ оказывается отрицательным, то ряды xt и yt (переменные xt и yt) не являются коинтегрированными.
В последнем случае непосредственное оценивание модели yt = а + f3xt + ut
бессмысленно, так как получаемая оценка J3T, собственно говоря, не является оценкой какого-либо теоретического параметра связи между переменными xt nyt (см., впрочем, ниже замечание 11.1.6).
Напротив, если переменные xt и yt коинтегрированы, то (3Т является оценкой того единственного значения Д при котором ряд jy, J3xt стационарен. Заметим теперь, что если в
DGP: xt =xt_{ + єи,
Уг=Уг+£lt
допустить коррелированность значений єи и slt в совпадающие моменты времени, т.е. Cov(slt, s2t) * 0, то коррелированность єи и s2t вовсе не означает, что ряды xt и yt коинтегрированы. Предположим все же, что существует некоторое значение Д при которому, = j5xt + ut, где ut — стационарный ряд. Тогдаyt_x = /3xt_x + ut_x, так что Ayt = (5Axt + Aut, а отсюда єь = /Зєи + Aut. Последнее можно записать в виде ut -ut_x + rjt, где
Пі = £it ~P£ ~ iidN(09 rf). Но это означает, что ut — нестационарный процесс. В то же время если х0 = у0 = 0, то
Cov(xt,yt) = Cov(sn + … + єи, є2Х + … + єь) = tCov(slu є2)9
так что xt и yt — коррелированные, но не коинтегрированные случайные блуждания.
Существенно, что распределение статистики Дики — Фуллера в подобной ситуации не зависит от конкретного вида матрицы ковариаций
І, = (Соу(єкІ9єЯІ))9 k9s =192.
Тем же свойством обладает и распределение статистики Дарбина — Уотсона, примененной к ряду остатков (CRDW — cointegrating regression DW)
et=yt~ dTpTxt.
При T = 50 5%-е критическое значение последней статистики равно 0.78. Гипотеза некоинтегрированности рядов отвергается, если наблюдаемое значение этой статистики превышает критическое значение.
В примере 11.1.3 значение статистики Дарбина — Уотсона равно 0.214, так что гипотеза некоинтегрированности не отвергается и этим критерием.
Что следует предпринять в случае обнаружения паразитной связи между интегрированными порядка 1 переменными xt nyt? Имеются три возможных пути обхода возникающих здесь трудностей.
1. Включить в правую часть уравнения запаздывающие значения обеих переменных, точнее, рассмотреть статистическую модель
SM: yt = а+ уУг+ Pxt + $xt+ ип где ut — стационарный ряд и переменная xt трактуется как экзогенная переменная.
Последнее уравнение можно записать иначе в следующих двух формах:
а) yt = а+ ryt+ + (/? + S)xt_x + щ9
б) yt = а+ ryt-i S)xt SAxt + ut9
В обеих формах слева стоит интегрированная переменная^ ~/(1).
В правой части уравнения а) параметр J3 является коэффициентом при стационарной переменной Ахп имеющей нулевое математическое ожидание; yt_l9 xt_x ~ 1(1), ut — стационарный ряд. Как было показано в (Sims, Stock, Watson, 1990), в такой ситуации оценки наименьших квадратов для всех коэффициентов SM состоятельны, оценка параметра Д асимптотически нормальна. Обычная /-статистика для проверки гипотезы Я0: Р = 0 имеет асимптотически нормальное распределение N(0, 1), если ut — белый шум.
Аналогично в правой части уравнения б) параметр -8 является коэффициентом при стационарной переменной Ахп имеющей нулевое математическое ожидание; yt_l9 xt ~ 1(1), ut — стационарный ряд. Поэтому оценка параметра 8 в рамках модели SM асимптотически нормальна, и /-статистика для проверки гипотезы Н0: 8 = 0 имеет асимптотически нормальное распределение N(0, 1), если ut — белый шум.
Оценки для Р и 8 остаются асимптотически нормальными и в том случае, если ut — стационарный ряд, не являющийся белым шумом. Однако при этом асимптотическое распределение N(0, 1) имеет скорректированные варианты /-статистик, в знаменателях которых стандартные оценки дисперсии ряда ut заменяются состоятельными оценками долговременной дисперсии этого ряда, определенной в теме 10.2.
В то же время статистика qF = 2F для проверки гипотезы Н0: Р = 8 = О
не имеет асимптотического распределения ;f2(2), поскольку рассматриваемую SM не удается линейно репараметризовать таким образом, чтобы в правой части преобразованного уравнения и р и 8 одновременно стали коэффициентами при стационарных переменных, имеющих нулевые математические ожидания (у нас они становятся таковыми при разных репараметризациях).
Перед оцениванием модели связи продифференцировать ряды xt и уп т.е. рассмотреть модель в разностях
SM: Ay, = а + ДДх, + ип
где ut — стационарный ряд.
В этой модели оценки наименьших квадратов и для а, и для Р асимптотически нормальны. Обе /-статистики имеют асимптотически нормальное распределение N(0, 1), если ut — белый шум. Если ut — стационарный ряд, не являющийся белым шумом, то необходимо произвести коррекцию /-статистик, как в предыдущем пункте.
Использовать для оценивания модель регрессии с автокоррелированными остатками:
SM: yt = а + Pxt + ип ut = pxt_x + єп ut ~ i.i.d. N(0, a]),
При этом предпочтительнее оценивать все три параметра а, Д, р одновременно, используя представление
Уг-РУг= а(1 -Р) + Р(Х,-РХ,_Х) + ЄГ
В случае ложной регрессии р —> 1 (по вероятности), так что при больших Т этот метод фактически равносилен предварительному дифференцированию рядов.
ПРИМЕР 11.1.5
Применим указанные три подхода к анализу реализаций, смоделированных ранее в данном разделе в соответствии с
DGP: xt =xt+ єп
где єи и slt — последовательности независимых, одинаково распределенных случайных величин, имеющих стандартное нормальное распределение 7V(0, 1).
Для анализа используем последние 50 наблюдений.
 Применив первый подход, получим оцененную модель, приведенную в табл. 11.6.
Применив первый подход, получим оцененную модель, приведенную в табл. 11.6.
Наблюдаемые Р-значения для коэффициентов при переменных xt и xt_x указывают на то, что переменная xt фактически не объясняет изменчивость переменной уг
Применив второй подход, получим оцененную модель, приведенную в табл. 11.7.
 Оба коэффициента статистически незначимы, и это отражает некоррелированность рЯДОВ Єи И £1г.
Оба коэффициента статистически незначимы, и это отражает некоррелированность рЯДОВ Єи И £1г.
Применив третий подход, оценим модель
yt -pyt.x = a(l -р) + J3(xt -pxt_x) + єп
т.е.
 Уг = a+Pyt+ A*r -Pxt-i) + *r При этом получим следующие результаты (табл. 11.8).
Уг = a+Pyt+ A*r -Pxt-i) + *r При этом получим следующие результаты (табл. 11.8).
Как и ожидалось, коэффициент при оказался очень близким к 1, а два других коэффициента статистически незначимы. Проверка на одновременное зануление этих двух коэффициентов дает Р-значение 0.367.■
ПРИМЕР 11.1.6
Изменим процесс порождения данных, оставляя те же формулы для xt и уп т.е.
Xt — Xt_ і + £f, yt=yt-x +£2r
Но теперь пусть:
s -> £2t — последовательности независимых, одинаково распределенных случайных величин, имеющих нормальное распределение N(0, 1.25); Cov(su, s2s) 0 для t*s, Cov(su, s2t) = 1.
Отсюда, в частности, следует, что Согг(єи, s2t) = 0.8.
Смоделированные реализации єи и s2t изображены на рис. 11.7.
Траектории смоделированной пары рядов єи и є2і ведут себя достаточно согласованным образом, оцененный коэффициент корреляции между этими рядами равен 0.789. Полученные при этом реализации рядов xt nyt ведут себя так, как показано на рис. 11.8. Для сравнения на рис. 11.9 изображено поведение реализаций рядов хг и уг при полной статистической независимости
рЯДОВ £и И Є2г
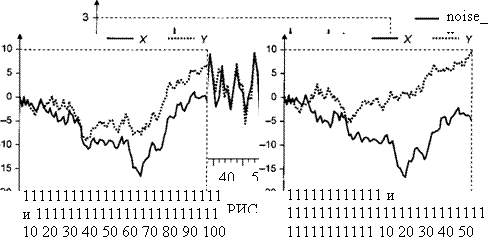 Для сопоставимости с ранее полученными результатами опять обратимся ко второй части отрезка наблюдений; здесь оцененный коэффициент корреляции между рядами еи и e2t равен 0.792.
Для сопоставимости с ранее полученными результатами опять обратимся ко второй части отрезка наблюдений; здесь оцененный коэффициент корреляции между рядами еи и e2t равен 0.792.
Сначала оценим модель yt = а + J3xt + иг В результате получим для ряда остатков значение статистики Дики — Фуллера, равное -2.112, которое выше 5%-го критического уровня -3.46. Соответственно гипотеза о ложности регрессионной связи не отвергается.
Применив первый подход, получим оцененную модель, приведенную в табл. 11.9.
По сравнению с ранее рассмотренным случаем, где ряды єи и еъ были между собой статистически не связанными, теперь оказываются статистически значимыми и коэффициенты при переменных xt и xt_!. Исключив из правой части модели константу, получим табл. 11.10.
 То есть>>г = .005yt_x + 0.695л;, 0.101 xt_x + et. Оценка коэффициента при^_! близка к 1, оцененные коэффициенты при xt и xt_x близки по абсолютной величине и противоположны по знаку, что вполне согласуется с реализованной моделью DGP.
То есть>>г = .005yt_x + 0.695л;, 0.101 xt_x + et. Оценка коэффициента при^_! близка к 1, оцененные коэффициенты при xt и xt_x близки по абсолютной величине и противоположны по знаку, что вполне согласуется с реализованной моделью DGP.
Объясняемая переменная D(Y)
 Применив второй подход, получим оцененную модель, приведенную в табл. 11.11.
Применив второй подход, получим оцененную модель, приведенную в табл. 11.11.
И здесь в отличие от ранее использовавшегося DGP становится значимым коэффициент при переменной Ахп что отражает коррелированность случайных величин єи и s2t, т.е. коррелированность Axt и Ауг Исключив из правой части уравнения статистически незначимую константу, получим результаты, приведенные в табл. 11.12.
 То есть Ayt = 0.7ЮДх, 4еп ишу{ = yt_x + 0.710jc, 0.710хг_! 4et. Наконец, применив третий подход, оценим модель
То есть Ayt = 0.7ЮДх, 4еп ишу{ = yt_x + 0.710jc, 0.710хг_! 4et. Наконец, применив третий подход, оценим модель
yt = a+ pyt.! + j3(xt -pxt_х) + єг
 При этом получим табл. 11.13.
При этом получим табл. 11.13.
Объясняемая переменная У
Convergence achieved after 8 iterations; У=С(1)+С(2)*У(-1)+С(3)*(Х-С(2)*Х(-1))
Объясняемая переменная У
Convergence achieved after Л iterations; У=С(2)*У(-1)+С(3)*(Х-С(2)*Х(-1))

Здесь становится статистически значимым коэффициент Д Исключение из правой части константы дает табл. 11.14.
То есть
yt = 1.014уг_! + 0.702(jc, №4xt_x) + en
или
yt = 1.014>>,_i + 0.702jc, 0.712jcr_! + er
Отметим близость результатов, полученных тремя методами:
yt = 1.005^.! + 0.695jc, 0.707х,_! + et (метод 1);
yt = yt-X + 0.71 Ox, 0.7 Юх^ 4et (метод 2);
yt = 1.014^_! + 0.702x, 0.712jc,_! + e, (метод 3).
Фактически во всех трех случаях воспроизводится одна и та же линейная модель связи между рядами разностей:
Ду, = 0.7Дх, 4ег
Эта регрессионная связь между продифференцированными рядами не является ложной (в отличие от регрессионной связи между рядами уровней): статистика Дарбина — Уотсона принимает значение 1.985, Р-значение критерия Харке — Бера равно 0.344.■
у/ Замечание 11.1.1. В связи с результатами, полученными в последних примерах, естественно возникает следующий вопрос, который поднимался в свое время различными исследователями. Не будет ли разумным, имея дело с рядами, траектории которых обнаруживают выраженный тренд, сразу приступать к оцениванию связей между рядами разностей (между продифференцированными рядами)?
Против некритичного использования такого подхода говорят два обстоятельства:
если ряды в действительности стационарны относительно детерминированного тренда, то дифференцирование приводит к передифференцированным рядам, имеющим необратимую МА-составляющую;
если ряды являются интегрированными порядка 1 и при этом коинтегрированы, то при переходе к продифференцированным рядам теряется информация о долговременной связи между уровнями этих рядов.
Дифференцирование рядов оправданно и полезно, если ряды являются интегрированными, но при этом между ними отсутствует коинтеграционная связь.
Коинтегрированные временные ряды
Пусть yt ~ 7(1), х, ~ ДО). Строить регрессию уг на xt в этом случае бессмысленно, так как для любых аиЬв такой ситуации
yt a bxt ~/(1).
Пусть, наоборот, yt ~ 1(0), xt ~ 7(1). Для любых аиЬ^О здесь опять
yt a bxt ~/(1)
и только при Ь = 0 получаем
yt-a-bxt -1(0%
так что и в таком сочетании строить регрессию одного ряда на другой не имеет смысла.
Пусть теперь^ ~ 7(1), xt ~1(1) — два интегрированных ряда. Если для любого Ъ
yt-bxt ~/(1),
то регрессия yt на xt является фиктивной, и мы уже выяснили, как следует действовать в такой ситуации.
Обратимся теперь к случаю, когда при некотором ЬфО
yt bxt ~ 1(0) — стационарный ряд.
Если это так, то ряды yt и xt называют коинтегрированными, а вектор (1, -Ь)Т— коинтегрирующим вектором (cointegrating vector).
Вообще, ряды^г ~ 1(1), xt ~1(1) называют коинтегрированными (в узком смысле — детерминистская коинтеграция, deterministic cointegration), если существует ненулевой (коинтегрирующий) вектор Р= (Рх, J32)T * 0, для которого
Pxxt + P2yt ~ 1(0) — стационарный ряд.
Заметим, что если вектор /? = (Д, р2)Т является коинтегрирующим для рядов xt nyt, то коинтегрирующим для этих рядов будет и любой вектор вида с/? = (сД, сР2)т, где с ф 0 — постоянная величина. Чтобы выделить какой-то определенный вектор, приходится вводить условие нормировки (normalization) — например, рассматривать только векторы вида (1, -Ь)т (или только векторы (-а, )т).
Поскольку предполагаем в данном случае, что xt,yt ~ 1(1), то ряды разностей Дх,, Ayt стационарны. Будем предполагать в дополнение, что стационарен векторный ряд (Axt, Ayt)T и для него существует представление в виде векторного скользящего среднего (VMA)
(Axt, Ayt)T = ju +B(L)st, где /£ = (jil9 ju2)T, ju{ = E(Axt), ju2 = E(Ayt), 6t = (eXt, s2t)T — векторный белый шум,
т.е. єх, є2, … — последовательность не коррелированных между собой, одинаково распределенных случайных векторов, для которых
E(st) = (О, 0)Т, d(sXt) = <jx, d(s2t) = <j2, Cov(sXt, є2і) = an— постоянные величины;
B(L) =
О 1
+ 1
k =
(h{k) h(k)
Uik) r(k) u2l u22 J
Таким образом, предполагается, что разложение Вольда центрированного векторного ряда (Дх„ Ayt)Tju не содержит линейно детерминированной компоненты.
Знаменитый результат Грейнджера (см. (Granger, 1983), а также (Engle, Granger, 1987)), состоит в том, что в случае коинтегрированности 7(1) рядов xt nyt (в узком смысле):
в представлении (Axt, Ayt)T = ju + B(L)st матрица 5(1) имеет ранг 1;
система рядов xt и yt допускает векторное ARMA представление
A(L)(xt,yt)T = c + d(L)st,
где et — тот же векторный белый шум, что и в (I); с = (сх, с2)Т, сх и с2 — постоянные; А(Ь)— матричный полином от оператора запаздывания; d(L) — скалярный полином от оператора запаздывания,
причем ДО) = 12 (единичная матрица размера (2 х 2)),
rank А() = 1 (ранг (2 х 2)-матрицыЛ(1) равен 1), значение d() конечно.
В связи с тем что в последнем представлении ранг (2 х 2)-матрицы А() меньше двух, об этом представлении часто говорят как о векторной авторегрессии пониженного ранга (reduced rank VAR).
В развернутой форме представление (II) имеет вид:
Р ч
xt = ci + ХКЛ-У Y*ek*u-k>
7=1 k = 0
Р Я
Уі~С2 + Z(*2/*f-y +b2jyt_j)+ YuekS2,t-k7=1 k = 0
При этом верхние пределы р и q у сумм в правых частях могут быть бес-конечными.
Если возможно векторное AR представление, то в нем d(L) =1,р <ю.
Система рядов xt и yt допускает представление в форме модели коррекции ошибок (error correction model — ЕСМ)
00 00
Axt =fix + axzt_x + Х(Гі7-Л*,-7 +sijAyt-j)+ Z^*u-*>
7=1 k=0
00 00
Ayt = //2 + a2zt_x + Y.iYij A*,-; + S2J Ayt_j) + ^0ke2tt_k,
7=1 k=0
где zt=yt J3xt E(yt J3xt) — стационарный ряд с нулевым математическим ожиданием, zt ~ 1(0); ах2 + ai > 0.
Если в (II) возможно векторное AR(p) представление (р < оо), то ЕСМ принимает вид:
РAxt=px+axzt_x + Y, (Г и Л*, -у + sj ДУг -j ) +
7 = 1
Ayt = р2 + a2zt_x + £(^f Дх,_, + ДУг-у) + *2,г
7 = 1
Здесь важно отметить следующее.
Если ряды xt, yt ~ 1(1) коинтегрированы, то все составляющие в ЕСМ стационарны.
Если векторный ряд (xt, yt)T ~ 1(1) (так что векторный ряд (Дх„ Ayt)T стационарен) и порождается ЕСМ-моделью, то ряды xt и yt коинтегрированы. (Действительно, в этом случае все составляющие ЕСМ, отличные от zt_х, стационарны, но тогда стационарна и z,_ х.)
Если ряды xt, уг ~1(1) коинтегрированы, то VAR в разностях не может иметь конечный порядок (в отличие от случая, когда ряды xt и yt не коинтегрированы).
Абсолютную величину zt-yta-J3xt, где а = E(yt J3xt), можно рассматривать как расстояние, отделяющее систему в момент t от равновесия (equilibrium), задаваемого соотношением yt a-fixt = 0. Величины и направления изменений хг и yt принимают во внимание величину и знак предыдущего отклонения от равновесия zt_x. Ряд zt, конечно, вовсе не обязательно убывает по абсолютной величине при переходе от одного периода времени к другому, но он является стационарным и поэтому расположен к движению по направлению к своему среднему (mean-reversion).
Замечание 11.1.2. Переменная xt не является причиной по Грейнд-жеру для переменной уt, если неучет прошлых значений переменной xt не приводит к ухудшению качества прогноза значения yt по совокупности прошлых значений этих двух переменных. Переменная yt не является причиной по Грейнджеру для переменной xt, если неучет прошлых значений переменной yt не приводит к ухудшению качества прогноза значения xt по совокупности прошлых значений этих двух переменных1. (Качество прогноза измеряется среднеквадрати-ческой ошибкой прогноза.)
В четвертой части учебника рассмотрим более подробно вопросы, связанные с определением причинности по Грейнджеру.
Если xt, yt ~1(1) и коинтегрированы, то должна иметь место причинность по Грейнджеру (Granger causality), по крайней мере, в одном направлении. Этот факт вытекает из представления такой системы рядов в форме ЕСМ, в которой ах + а2 > 0. Значение xt_x через посредство zt_ х помогает в прогнозировании значения yt (т.е. переменная хг является причиной по Грейнджеру для переменной yt), если а2 ф 0. Значение yt_ х через посредство zt_, помогает в прогнозировании значения xt (т.е. переменная yt является причиной по Грейнджеру для переменной xt), если ах ф 0.
Замечание 11.1.3. Пусть xt, yt ~ 1(1) коинтегрированы и wt ~ 1(0). Тогда для любого к коинтегрированы ряды xt и yyt_k + wt, у ф 0. Если xt ~ 1(1), то коинтегрированы ряды xt и xt_k. (Действительно, тогда xt хг_к = Axt + Axt_x 4… + Axt_k — сумма /(О)-переменных, которая также является /(О)-переменной.)
Процедура Энгла — Грейнджера построения модели коррекции ошибок
Итак, при коинтегрированности рядов xt,yt ~ 1(1) имеем:
модель долговременной (равновесной) связи уt = а + J3xt;
модель краткосрочной динамики в форме ЕСМ,
и эти модели согласуются друг с другом.
Проблема, однако, состоит в том, что для построения ЕСМ по реальным статистическим данным надо знать коинтегрирующий вектор (в данном случае — знать значение /?). Хорошо, если этот вектор определяется экономической теорией. К сожалению, чаще его приходится оценивать по имеющимся данным.
Энгл и Грейнджер (Engle, Granger, 1987) предложили двухшаговую процедуру построения ЕСМ для коинтегрированных рядов.
На первом шаге значения а и (5 оцениваются в рамках модели регрессии Ух на xt
ytа лJ3xt + ut.
Получив методом наименьших квадратов оценки а и ft для параметров этой модели (МНК-оценки), находим оцененные значения отклонений от положения равновесия
zt=yt-d-f3xt, т.е. остатки от оцененной регрессии.
На втором шаге методом наименьших квадратов раздельно (не как система!) оцениваются уравнения:
рAxt=jux + axzt_x + ХО^’-У +SXJAyt_j) + vn р-і
Ayt=ju2 + a2zt_x + ^(rij^t-j +S2jAyt_j) + wn y = i
т.е. предполагается модель VAR(p) для xt9yr
Определяющим в этой процедуре является то обстоятельство, что (в случае коинтегрированности рядов xt nyt) полученная на первом шаге оценка J3 быстрее обычного приближается (по вероятности) к истинному значению (З — второй компоненте коинтегрирующего вектора (1, Д)г (иначе говоря, /? является суперсостоятельной оценкой для Д). Это, в конечном счете, приводит к тому, что оценки в отдельном уравнении ЕСМ, использующие оцененные значения zt_l9 имеют то же асимптотическое распределение, что и оценка максимального правдоподобия, использующая истинные значения zt_ х (обычно это асимптотически нормальное распределение). При этом МНК-оценки стандартных ошибок всех коэффициентов являются состоятельными оценками истинных стандартных ошибок.
Заметим, что последние результаты справедливы, несмотря на то что ряд оцененных значений £, формально не является стационарным, поскольку
Отметим также, что если использовать другую нормировку коинтегрирующего вектора в виде (Д 1)г, то придется оценивать регрессию xt на константу иуп а это приведет к вектору, не пропорциональному вектору, оцененному в первом случае.
/
v Замечание 11.1.4. Тот факт, что Р быстрее обычного сходится (по вероятности) к Д вовсе не означает, что на первом шаге процедуры Энгла — Грейнджера можно использовать обычные регрессионные критерии. Дело в том, что получаемые на первом шаге оценки и статистики имеют, вообще говоря, нестандартные асимптотические распределения. Кроме того, при небольших Т оценка J3 может иметь весьма значительное смещение.
Однако в данном контексте первый шаг является вспомогательным, и на этом шаге нет необходимости обращать внимание на сообщаемые в протоколах соответствующих пакетов программ значения статистик. Напротив, на втором шаге можно использовать обычные статистические процедуры (разумеется, если количество наблюдений достаточно велико и ряды коинтегрированы).
у/ Замечание 11.1.5. При практическом применении двухшаговой процедуры Энгла — Грейнджера полученный на первом шаге ряд остатков z , -yt а j5xt используют не только при оценивании модели коррекции ошибок на втором шаге процедуры, но и для проверки гипотезы о некоинтегрированности рядов xtnyr
Эту гипотезу можно проверять следующим образом. Для ряда z, строится статистика Дики — Фуллера t9, которая использовалась бы для проверки гипотезы существования единичного корня у этого ряда, если бы этот ряд был «сырым», а не являлся рядом остатков от оцененной регрессии. Гипотеза некоинтегрированности рядов xt и yt отвергается, если вычисленное значение f оказывается ниже критического значения tKpm, соответствующего заданному уровню значимости, т.е. если t < tKpm. Следует отметить только, что это tKpm отличается от критического значения статистики t9, рассчитанного для случая «сырого» ряда, так что здесь необходимы другие таблицы критических значений. В связи с этим уже указывалась работа (MacKinnon, 1991); среди других источников, содержащих необходимые таблицы, упомянем монографии (Patterson, 2000) и (Hamilton, 1994). Более подробно этот вопрос будет рассмотрен в теме 11.2.
ПРИМЕР 11.1.7
Расмотрим реализацию процесса порождения данных
DGP: xt = х,_1 + st, Уг = 2х, + v„
где х{ = 0;
et и v, — порождаемые независимо друг от друга последовательности независимых, одинаково распределенных случайных величин, имеющих стандартное нормальное распределение yV(0, 1).
Графики полученных реализаций рядов xt uyt изображены на рис. 11.10. Пара (xt,yt) образует векторный процесс авторегрессии
xt — xt_ і 4st, yt = 2xt_l + r/t,
где 77, = v, 42st ~ Lid. N(0, 5).
В форме ЕСМ пара уравнений принимает вид:
Ду, = -(у,_і -2xt_x) + rit = -zt_x + //„
rjxezt =yt-2xt,
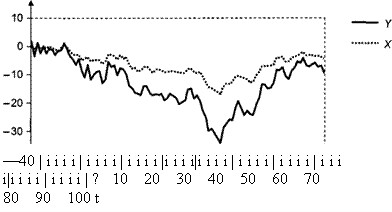 |
ИЛИ
Дх, = alzt_l + єп
Ayt = a2zt_x + rjn
где ax = 0, a2 = -1, так что ах + а2 > 0.
На практике, приступая к анализу статистических данных, исследователь не знает точно, какой порядок имеет VAR в DGP. Имея это в виду, выберем для оценивания в качестве статистической модели ЕСМ в виде:
Axt = axzt_x +ГцА*/-і +£ц4У/-і +v»
Ayt = a2zt_x + y2XAxt_x + S2xAyt.x + w„
допуская, что данные порождаются моделью векторной авторегрессии второго порядка (р = 2). Для анализа используем 100 наблюдений.
 Шаг I. Исходим из модели yt а + (3xt + иг Оцененная модель приведена в табл. 11.15.
Шаг I. Исходим из модели yt а + (3xt + иг Оцененная модель приведена в табл. 11.15.
То есть у, = -0.006764 + 1.983373л:, + й„ так что
zt = u,=y, + 0.006764 1.983373jc,.
Допустив, что VAR имеет порядок 2, при использовании критерия Дики — Фуллера для проверки рядов yt и xt на коинтегрированность в правую часть уравнения включаем одну запаздывающую разность:
 Azt=<pzt_x +6xl±zt_x + £. Оценивив последнее уравнение, получим табл. 11.16.
Azt=<pzt_x +6xl±zt_x + £. Оценивив последнее уравнение, получим табл. 11.16.
Значение тестовой статистики f = -7.614 ниже 5%-го критического уровня -3.396 (см. {Patterson, 2000, табл. 8.7)). Гипотеза некоинтегрированности рассматриваемых рядов уверенно отвергается. (Ввиду статистической незначимости коэффициента при запаздывающей разности можно было бы переоценить модель, не включая запаздывающую разность в правую часть уравнения. Но это дало бы значение f = -11.423, при котором гипотеза некоинтегрированности отвергается еще более уверенно.)
Таким образом, принимаем решение о коинтегрированности рядову, и^и переходим к построению модели коррекции ошибок.
 Шаг П. Сначала отдельно оцениваем уравнение для Axt (табл. 11.17).
Шаг П. Сначала отдельно оцениваем уравнение для Axt (табл. 11.17).
Поочередное исключение из правой части уравнения переменных со статистически незначимыми коэффициентами и наибольшим Р-значением приводит к оцененной модели (табл. 11.18) и, в конечном счете, к модели
Ах, = v„
которая и была использована при порождении ряда хг
 Исключая из правой части оцениваемого уравнения константу, получаем табл. 11.20.
Исключая из правой части оцениваемого уравнения константу, получаем табл. 11.20.
Хотя формально здесь следовало бы начать исключение статистически незначимых переменных с £j, необходимо учитывать уже принятое решение о коинтегрированности рядову, и хг Но если эти ряды действительно коинтег-рированы, то в ЕСМ должно выполняться соотношение ах2 + а2 > 0. Поскольку переменная z,_! не вошла в правую часть уравнения для Дх„ она должна оставаться в правой части уравнения для Ауг Если начать исключение с переменной Ду,_і, то в оцененном редуцированном уравнении (табл. 11.21) оказывается статистически незначимым коэффициент при Дх,_15 что приводит нас к уравнению Ay, = a2zt_{ + wr Оценивая последнее, получаем табл. 11.22.
Проверка гипотезы Н0: а2=-1 дает табл. 11.23.
 Поскольку эта гипотеза не отвергается, можно остановиться на модели ЕСМ
Поскольку эта гипотеза не отвергается, можно остановиться на модели ЕСМ
Axt = st, Ayt=-zt_x +и>„ где £,_! = yt_x + 0.0067641.983373х,_1.
Подстановка последнего выражения для zt_ х в уравнение для Ayt приводит к соотношению
yt = -0.0068 + 1.983*,.! + wn которое близко к соотношению
yt = 2xt_x + rjn
соответствующему использованному DGP.
Заметим, наконец, что последовательность wt = Ayt + zt_ х идентифицируется по наблюдаемой ее реализации как гауссовский белый шум с оцененной дисперсией 4.62 (использованному DGP соответствует значение 5.00), а последовательность et Ах, идентифицируется как гауссовский белый шум с оцененной дисперсией 1.04 (использованному DGP соответствует значение 1.00).
Остановившись на модели
Axt = sn Ayt = -zt_x +и>„ тем самым получили, что коррекция производится только в отношении ряда>>„ а именно — при положительных zt_x, т.е. при
yt_x (-0.0068 + 1.983Х,.!) > 0,
в правой части уравнения для Ду, корректирующая составляющая £,_ х отрицательна и действует в сторону уменьшения приращения переменной^,. Напротив, при отрицательных z,_ х корректирующая составляющая действует в сторону увеличения приращения переменной^,.
Прошлые значения переменной х, через посредство £,_ х помогают в прогнозировании значения уп т.е. переменная х, является причиной по Грейнджеру для переменной уг В то же время прошлые значения переменной yt никак не помогают прогнозированию значения х„ так что у, не является причиной по Грейнджеру для х,.И
Заметим далее, что даже если в ЕСМ Cov(vn wt) Ф 0, оценивание пары уравнений ЕСМ как системы не повышает эффективности оценок, поскольку в правые части обоих уравнений входят одни и те же переменные.
Расмотренный в нашем примере процесс порождения данных
DGP: х, = х,_! + £„ yt = 2х, + v,
является частным случаем модели, известной как треугольная система Филлипса (Phillips’s triangular system). В общем случае (для двух рядов) эта система имеет вид:
Уг = P*t + V/f X, — Х,_ і + €t9
где (snvt)T ~ lid. N2(0, X) — последовательность независимых, одинаково распределенных случайных векторов, имеющих двумерное нормальное распределение с нулевым математическим ожиданием и ковариационной матрицей I. Такая последовательность называется двумерным гауссовским белым шумом (two-dimentional Gaussian white noise).
Если матрица X диагональная, так что Cov(sn v,) = 0, то х, является экзогенной переменной в первом уравнении, и никаких проблем с оцениванием коэффициента /? в этом случае не возникает.
Если же Cov(sn v,) Ф 0, то х, не является экзогенной переменной в первом уравнении, так как при этом Cov(x„ v,) = Cov(xt_x + єп v,) Ф 0. Поэтому получаемая в первом уравнении оценка наименьших квадратов для /3 не имеет даже асимптотически нормального распределения.
В дальнейшем еще вернемся к проблеме оценивания коинтегрирующего вектора, а сейчас обратимся к вопросу о коинтеграции нескольких временных рядов.
Коинтегрированная система нескольких временных рядов. Проверка на коинтегрированность нескольких временных рядов
Пусть имеем N временных рядову,,yNt, каждый из которых является интегрированным порядка 1. Если существует такой ненулевой вектор Р=(РХ,PN)T, для которого
РУи + • • • + P^y^t ~ ДО) — стационарный ряд,
то говорят, что эти ряды коинтегрированы (в узком смысле), такой вектор Р называется коинтегрирующим. Если при этом
c = E(PxyXt + …+pNyNt),
то можно говорить о долговременном положении равновесия системы
{long-run equilibrium relation) в виде:
Pxyx + …+PNyN = c.
В каждый конкретный момент времени t существует некоторое отклонение (deviation) системы от этого положения равновесия, характеризующееся величиной
В силу сделанных предположений ряд zt является стационарным, имеющим нулевое математическое ожидание, так что он достаточно часто пересекает нулевой уровень, т.е. система колеблется вокруг указанного выше положения равновесия.
При проверке на коинтегрированность нескольких рядов надо различать несколько случаев.
Коинтегрирующий вектор определяется экономической теорией.
В этом случае надо просто проверить на наличие единичного корня соответствующую линейную комбинацию
РУи + — +РыУиг При этом используются те же критические значения, которые рассчитаны на применение к отдельно взятому «сырому» ряду. Эти значения не зависят от количества задействованных рядов N.
Пусть возможный коинтегрирующий вектор не определен заранее.
Тогда отдельно рассматриваются следующие ситуации.
Ряды у1п yNt не имеют детерминированного тренда (точнее, E(Aykt) = О для всех к =1,2,N).
2а. В коинтеграционное соотношение (SM) константа не включается. В этом случае оцениваем
SM: yXt = y2y2t + … + yNyNt + щ, получаем ряд остатков
оцениваем модель регрессии
Aut = (piit_x + £xAut_x + … + £KAut_K + st
с достаточным количеством запаздывающих разностей и проверяем гипотезу Н0: <р = 0 против альтернативы Н0: ^ < 0.
На этот раз критические значения для ^-статистики f зависят от количества задействованных рядов N. При большом количестве наблюдений можно использовать критические значения, приведенные в (Hamilton, 1994, табл. В.9, случай 1). Однако на практике в правую часть оцениваемого уравнения константа обычно включается.
2Ь. В коинтеграционное соотношение (SM) константа включается.
В этом случае оцениваем
SM: уи = а+ y2y2t + … + yNyNt + щ, опять получаем ряд остатков — теперь это будет ряд
«/ =Уи ~ (а + y2y2t + … + yNyNt оцениваем модель регрессии
Aw, = cput_x + £xAut_x + … + + €t
с достаточным количеством запаздывающих разностей и проверяем гипотезу Н0: ср 0 против альтернативы Н0: р<0.
Критические значения в этом случае отличаются от случая 2а. При большом количестве наблюдений можно использовать критические значения, приведенные в (Hamilton, 1994, табл. В.9, случай 2). При небольших Т критические значения вычисляются по формуле, приведенной в (MacKinnon, 1991, табл. 1 (вариант «по trend»)) (см. также (Patterson, 2000)).
3. Хотя бы один из рядов у1п yNt имеет линейный тренд, так что
E(Aykt) Ф 0 хотя бы для одного из регрессоров.
За. В коинтеграционное соотношение включается константа. В этом случае оцениваем
SM: ylt = a+ y2y2t + … + yNyNt + ur
Действуем опять как в случае 2Ь, только критические значения другие. При большом количестве наблюдений можно использовать критические значения, приведенные в (Hamilton, 1994, табл. В.9, случай 3). При небольших Т критические значения вычисляются по формуле, приведенной в работе (MacKinnon, 1991, табл. 1 (вариант «with trend»)) и воспроизведенной в (Patterson, 2000).
ЗЬ. В коинтеграционное соотношение включается линейный тренд.
В этом случае оцениваем
SM: уи = а+ St+y2y2t + … + yNyNt + ur
Действуя так же, как и ранее, используем те же таблицы, что и в случае За, но не для N, а для (Л/Ч 1) переменных.
Включение тренда в коинтеграционное соотношение приводит к уменьшению мощности критерия из-за необходимости оценивания «мешающего» параметра 8. Однако такой подход вполне уместен в тех случаях, когда нет полной уверенности в том, имеется ли ненулевой тренд хотя бы у одного из рядовуи,у2п .Ум-пример 11.1.8
Смоделируем реализации 4 рядов уи, y2t, y3t, y4t, следуя процессу порождения данных
DGP: уи=Уъ+Уы+Уъ + еи
Уіі ~Уі,і+ Є2п
Узг=Уз,гУаі =Уа,і+ ^4/’
где єи, s2t, s3t, s4t— независимые друг от друга процессы гауссовского белого шума с дисперсиями, равными 1 для s2t, s3t, s4t и 2 для єи.
Графики полученных реализаций для Т= 200 приведены на рис. 11.11.
Не зная точно процесс порождения данных, нужно было бы начать с исследования отдельных рядов. У всех 4 рядов не обнаруживается детерминированного тренда. Проверка по критерию Дики — Фуллера дает значения /-статистик, равные -2.18, -1.78, -0.57, -1.70 соответственно. Все 4 ряда признаются интегрированными. Продифференцированные ряды идентифицируются как гауссовские белые шумы, так что ряды уи, y2t, y3t, y4t идентифицируются как АЫ(1)-ряды с единичным корнем, т.е. как интегрированные ряды порядка 1.
Раздел 11 регрессионный анализ для нестационарных переменных. коинтегрированные временные ряды. модели коррекции ошибок тема 11.1 проблема ложной регрессии. коинтегрированные временные ряды. модели коррекции ошибок: Эконометрика Книга первая Часть 2, Носко Владимир Петрович, 2011 читать онлайн, скачать pdf, djvu, fb2 скачать на телефон Под временным рядом (time series) в экономике понимается ряд значений некоторой переменной, измеренных в последовательные моменты времени.
This example considers trending variables, spurious regression, and methods of accommodation in multiple linear regression models. It is the fourth in a series of examples on time series regression, following the presentation in previous examples.
Introduction
Predictors that trend over time are sometimes viewed with suspicion in multiple linear regression (MLR) models. Individually, however, they need not affect ordinary least squares (OLS) estimation. In particular, there is no need to linearize and detrend each predictor. If response values are well-described by a linear combination of the predictors, an MLR model is still applicable, and classical linear model (CLM) assumptions are not violated.
If, however, a trending predictor is paired with a trending response, there is the possibility of spurious regression, where t-statistics and overall measures of fit become misleadingly «significant.» That is, the statistical significance of relationships in the model do not accurately reflect the causal significance of relationships in the data-generating process (DGP).
To investigate, we begin by loading relevant data from the previous example Time Series Regression III: Influential Observations, and continue the analysis of the credit default model presented there:
Confounding
One way that mutual trends arise in a predictor and a response is when both variables are correlated with a causally prior confounding variable outside of the model. The omitted variable (OV) becomes a part of the innovations process, and the model becomes implicitly restricted, expressing a false relationship that would not exist if the OV were included in the specification. Correlation between the OV and model predictors violates the CLM assumption of strict exogeneity.
When a model fails to account for a confounding variable, the result is omitted variable bias, where coefficients of specified predictors over-account for the variation in the response, shifting estimated values away from those in the DGP. Estimates are also inconsistent, since the source of the bias does not disappear with increasing sample size. Violations of strict exogeneity help model predictors track correlated changes in the innovations, producing overoptimistically small confidence intervals on the coefficients and a false sense of goodness of fit.
To avoid underspecification, it is tempting to pad out an explanatory model with control variables representing a multitude of economic factors with only tenuous connections to the response. By this method, the likelihood of OV bias would seem to be reduced. However, if irrelevant predictors are included in the model, the variance of coefficient estimates increases, and so does the chance of false inferences about predictor significance. Even if relevant predictors are included, if they do not account for all of the OVs, then the bias and inefficiency of coefficient estimates may increase or decrease, depending, among other things, on correlations between included and excluded variables [1]. This last point is usually lost in textbook treatments of OV bias, which typically compare an underspecified model to a practically unachievable fully-specified model.
Without experimental designs for acquiring data, and the ability to use random sampling to minimize the effects of misspecification, econometricians must be very careful about choosing model predictors. The certainty of underspecification and the uncertain logic of control variables makes the role of relevant theory especially important in model specification. Examples in this series Time Series Regression V: Predictor Selection and Time Series Regression VI: Residual Diagnostics describe the process in terms of cycles of diagnostics and respecification. The goal is to converge to an acceptable set of coefficient estimates, paired with a series of residuals from which all relevant specification information has been distilled.
In the case of the credit default model introduced in the example Time Series Regression I: Linear Models, confounding variables are certainly possible. The candidate predictors are somewhat ad hoc, rather than the result of any fundamental accounting of the causes of credit default. Moreover, the predictors are proxies, dependent on other series outside of the model. Without further analysis of potentially relevant economic factors, evidence of confounding must be found in an analysis of model residuals.
Detrending
Detrending is a common preprocessing step in econometrics, with different possible goals. Often, economic series are detrended in an attempt to isolate a stationary component amenable to ARMA analysis or spectral techniques. Just as often, series are detrended so that they can be compared on a common scale, as with per capita normalizations to remove the effect of population growth. In regression settings, detrending may be used to minimize spurious correlations.
A plot of the credit default data (see the example Time Series Regression I: Linear Models) shows that the predictor BBB and the response IGD are both trending. It might be hoped that trends could be removed by deleting a few atypical observations from the data. For example, the trend in the response seems mostly due to the single influential observation in 2001:
figure hold on plot(dates,y0,'k','LineWidth',2); plot(dates,y0-detrend(y0),'m.-') plot(datesd1,yd1-detrend(yd1),'g*-') hold off legend(respName0,'Trend','Trend with 2001 deleted','Location','NW') xlabel('Year') ylabel('Response Level') title('{bf Response}') axis tight grid on
Deleting the point reduces the trend, but does not eliminate it.
Alternatively, variable transformations are used to remove trends. This may improve the statistical properties of a regression model, but it complicates analysis and interpretation. Any transformation alters the economic meaning of a variable, favoring the predictive power of a model over explanatory simplicity.
The manner of trend-removal depends on the type of trend. One type of trend is produced by a trend-stationary (TS) process, which is the sum of a deterministic trend and a stationary process. TS variables, once identified, are often linearized with a power or log transformation, then detrended by regressing on time. The detrend function, used above, removes the least-squares line from the data. This transformation often has the side effect of regularizing influential observations.
Stochastic Trends
Not all trends are TS, however. Difference stationary (DS) processes, also known as integrated or unit root processes, may exhibit stochastic trends, without a TS decomposition. When a DS predictor is paired with a DS response, problems of spurious regression appear [2]. This is true even if the series are generated independently from one another, without any confounding. The problem is complicated by the fact that not all DS series are trending.
Consider the following regressions between DS random walks with various degrees of drift. The coefficient of determination (R2) is computed in repeated realizations, and the distribution displayed. For comparison, the distribution for regressions between random vectors (without an autoregressive dependence) is also displayed:
T = 100; numSims = 1000; drifts = [0 0.1 0.2 0.3]; numModels = length(drifts); Steps = randn(T,2,numSims); % Regression between two random walks: ResRW = zeros(numSims,T,numModels); RSqRW = zeros(numSims,numModels); for d = 1:numModels for s = 1:numSims Y = zeros(T,2); for t = 2:T Y(t,:) = drifts(d) + Y(t-1,:) + Steps(t,:,s); end % The compact regression formulation: % % MRW = fitlm(Y(:,1),Y(:,2)); % ResRW(s,:,d) = MRW.Residuals.Raw'; % RSqRW(s,d) = MRW.Rsquared.Ordinary; % % is replaced by the following for % efficiency in repeated simulation: X = [ones(size(Y(:,1))),Y(:,1)]; y = Y(:,2); Coeff = Xy; yHat = X*Coeff; res = y-yHat; yBar = mean(y); regRes = yHat-yBar; SSR = regRes'*regRes; SSE = res'*res; SST = SSR+SSE; RSq = 1-SSE/SST; ResRW(s,:,d) = res'; RSqRW(s,d) = RSq; end end % Plot R-squared distributions: figure [v(1,:),edges] = histcounts(RSqRW(:,1)); for i=2:size(RSqRW,2) v(i,:) = histcounts(RSqRW(:,i),edges); end numBins = size(v,2); ax = axes; ticklocs = edges(1:end-1)+diff(edges)/2; names = cell(1,numBins); for i = 1:numBins names{i} = sprintf('%0.5g-%0.5g',edges(i),edges(i+1)); end bar(ax,ticklocs,v.'); set(ax,'XTick',ticklocs,'XTickLabel',names,'XTickLabelRotation',30); fig = gcf; CMap = fig.Colormap; Colors = CMap(linspace(1,64,numModels),:); legend(strcat({'Drift = '},num2str(drifts','%-2.1f')),'Location','North') xlabel('{it R}^2') ylabel('Number of Simulations') title('{bf Regression Between Two Independent Random Walks}')
clear RsqRW % Regression between two random vectors: RSqR = zeros(numSims,1); for s = 1:numSims % The compact regression formulation: % % MR = fitlm(Steps(:,1,s),Steps(:,2,s)); % RSqR(s) = MR.Rsquared.Ordinary; % % is replaced by the following for % efficiency in repeated simulation: X = [ones(size(Steps(:,1,s))),Steps(:,1,s)]; y = Steps(:,2,s); Coeff = Xy; yHat = X*Coeff; res = y-yHat; yBar = mean(y); regRes = yHat-yBar; SSR = regRes'*regRes; SSE = res'*res; SST = SSR+SSE; RSq = 1-SSE/SST; RSqR(s) = RSq; end % Plot R-squared distribution: figure histogram(RSqR) ax = gca; ax.Children.FaceColor = [.8 .8 1]; xlabel('{it R}^2') ylabel('Number of Simulations') title('{bf Regression Between Two Independent Random Vectors}')
The R2 for the random-walk regressions becomes more significant as the drift coefficient increases. Even with zero drift, random-walk regressions are more significant than regressions between random vectors, where R2 values fall almost exclusively below 0.1.
Spurious regressions are often accompanied by signs of autocorrelation in the residuals, which can serve as a diagnostic clue. The following shows the distribution of autocorrelation functions (ACF) for the residual series in each of the random-walk regressions above:
numLags = 20; ACFResRW = zeros(numSims,numLags+1,numModels); for s = 1:numSims for d = 1:numModels ACFResRW(s,:,d) = autocorr(ResRW(s,:,d)); end end clear ResRW % Plot ACF distributions: figure boxplot(ACFResRW(:,:,1),'PlotStyle','compact','BoxStyle','outline','LabelOrientation','horizontal','Color',Colors(1,:)) ax = gca; ax.XTickLabel = {''}; hold on boxplot(ACFResRW(:,:,2),'PlotStyle','compact','BoxStyle','outline','LabelOrientation','horizontal','Widths',0.4,'Color',Colors(2,:)) ax.XTickLabel = {''}; boxplot(ACFResRW(:,:,3),'PlotStyle','compact','BoxStyle','outline','LabelOrientation','horizontal','Widths',0.3,'Color',Colors(3,:)) ax.XTickLabel = {''}; boxplot(ACFResRW(:,:,4),'PlotStyle','compact','BoxStyle','outline','LabelOrientation','horizontal','Widths',0.2,'Color',Colors(4,:),'Labels',0:20) line([0,21],[0,0],'Color','k') line([0,21],[2/sqrt(T),2/sqrt(T)],'Color','b') line([0,21],[-2/sqrt(T),-2/sqrt(T)],'Color','b') hold off xlabel('Lag') ylabel('Sample Autocorrelation') title('{bf Residual ACF Distributions}') grid on
Colors correspond to drift values in the bar plot above. The plot shows extended, significant residual autocorrelation for the majority of simulations. Diagnostics related to residual autocorrelation are discussed further in the example Time Series Regression VI: Residual Diagnostics.
Differencing
The simulations above lead to the conclusion that, trending or not, all regression variables should be tested for integration. It is then usually advised that DS variables be detrended by differencing, rather than regressing on time, to achieve a stationary mean.
The distinction between TS and DS series has been widely studied (for example, in [3]), particularly the effects of underdifferencing (treating DS series as TS) and overdifferencing (treating TS series as DS). If one trend type is treated as the other, with inappropriate preprocessing to achieve stationarity, regression results become unreliable, and the resulting models generally have poor forecasting ability, regardless of the in-sample fit.
Econometrics Toolbox™ has several tests for the presence or absence of integration: adftest, pptest, kpsstest, and lmctest. For example, the augmented Dickey-Fuller test, adftest, looks for statistical evidence against a null of integration. With default settings, tests on both IGD and BBB fail to reject the null in favor of a trend-stationary alternative:
IGD = y0; BBB = X0(:,2); [h1IGD,pValue1IGD] = adftest(IGD,'model','TS')
[h1BBB,pValue1BBB] = adftest(BBB,'model','TS')
Other tests, like the KPSS test, kpsstest, look for statistical evidence against a null of trend-stationarity. The results are mixed:
s = warning('off'); % Turn off large/small statistics warnings [h0IGD,pValue0IGD] = kpsstest(IGD,'trend',true)
[h0BBB,pValue0BBB] = kpsstest(BBB,'trend',true)
The p-values of 0.1 and 0.01 are, respectively, the largest and smallest in the table of critical values used by the right-tailed kpsstest. They are reported when the test statistics are, respectively, very small or very large. Thus the evidence against trend-stationarity is especially weak in the first test, and especially strong in the second test. The IGD results are ambiguous, failing to reject trend-stationarity even after the Dickey-Fuller test failed to reject integration. The results for BBB are more consistent, suggesting the predictor is integrated.
What is needed for preprocessing is a systematic application of these tests to all of the variables in a regression, and their differences. The utility function i10test automates the required series of tests. The following performs paired ADF/KPSS tests on all of the model variables and their first differences:
I.names = {'model'};
I.vals = {'TS'};
S.names = {'trend'};
S.vals = {true};
i10test(DataTable,'numDiffs',1,...
'itest','adf','iparams',I,...
'stest','kpss','sparams',S);
Test Results
I(1) I(0)
======================
AGE 1 0
0.0069 0.1000
D1AGE 1 0
0.0010 0.1000
----------------------
BBB 0 1
0.6976 0.0100
D1BBB 1 0
0.0249 0.1000
----------------------
CPF 0 0
0.2474 0.1000
D1CPF 1 0
0.0064 0.1000
----------------------
SPR 0 1
0.2563 0.0238
D1SPR 1 0
0.0032 0.1000
----------------------
IGD 0 0
0.1401 0.1000
D1IGD 1 0
0.0028 0.1000
----------------------
warning(s) % Restore warning state
Columns show test results and p-values against nulls of integration, I(1), and stationarity, I(0). At the given parameter settings, the tests suggest that AGE is stationary (integrated of order 0), and BBB and SPR are integrated but brought to stationarity by a single difference (integrated of order 1). The results are ambiguous for CPF and IGD, but both appear to be stationary after a single difference.
For comparison with the original regression in the example Time Series Regression I: Linear Models, we replace BBB, SPR, CPF, and IGD with their first differences, D1BBB, D1SPR, D1CPF, and D1IGD. We leave AGE undifferenced:
D1X0 = diff(X0); D1X0(:,1) = X0(2:end,1); % Use undifferenced AGE D1y0 = diff(y0); predNamesD1 = {'AGE','D1BBB','D1CPF','D1SPR'}; respNameD1 = {'D1IGD'};
Original regression with undifferenced data:
M0 =
Linear regression model:
IGD ~ 1 + AGE + BBB + CPF + SPR
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ _______ _________
(Intercept) -0.22741 0.098565 -2.3072 0.034747
AGE 0.016781 0.0091845 1.8271 0.086402
BBB 0.0042728 0.0026757 1.5969 0.12985
CPF -0.014888 0.0038077 -3.91 0.0012473
SPR 0.045488 0.033996 1.338 0.1996
Number of observations: 21, Error degrees of freedom: 16
Root Mean Squared Error: 0.0763
R-squared: 0.621, Adjusted R-Squared: 0.526
F-statistic vs. constant model: 6.56, p-value = 0.00253
Regression with differenced data:
MD1 = fitlm(D1X0,D1y0,'VarNames',[predNamesD1,respNameD1])
MD1 =
Linear regression model:
D1IGD ~ 1 + AGE + D1BBB + D1CPF + D1SPR
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ ________ _________
(Intercept) -0.089492 0.10843 -0.82535 0.4221
AGE 0.015193 0.012574 1.2083 0.24564
D1BBB -0.023538 0.020066 -1.173 0.25909
D1CPF -0.015707 0.0046294 -3.393 0.0040152
D1SPR -0.03663 0.04017 -0.91187 0.37626
Number of observations: 20, Error degrees of freedom: 15
Root Mean Squared Error: 0.106
R-squared: 0.49, Adjusted R-Squared: 0.354
F-statistic vs. constant model: 3.61, p-value = 0.0298
The differenced data increases the standard errors on all coefficient estimates, as well as the overall RMSE. This may be the price of correcting a spurious regression. The sign and the size of the coefficient estimate for the undifferenced predictor, AGE, shows little change. Even after differencing, CPF has pronounced significance among the predictors. Accepting the revised model depends on practical considerations like explanatory simplicity and forecast performance, evaluated in the example Time Series Regression VII: Forecasting.
Summary
Because of the possibility of spurious regression, it is usually advised that variables in time series regressions be detrended, as necessary, to achieve stationarity before estimation. There are trade-offs, however, between working with variables that retain their original economic meaning and transformed variables that improve the statistical characteristics of OLS estimation. The trade-off may be difficult to evaluate, since the degree of «spuriousness» in the original regression cannot be measured directly. The methods discussed in this example will likely improve the forecasting abilities of resulting models, but may do so at the expense of explanatory simplicity.
References
[1] Clarke, K. A. «The Phantom Menace: Omitted Variable Bias in Econometric Research.» Conflict Management and Peace Science. Vol. 22, 2005, pp. 341–352.
[2] Granger, C. W. J., and P. Newbold. «Spurious Regressions in Econometrics.» Journal of Econometrics. Vol. 2, 1974, pp. 111–120.
[3] Nelson, C., and C. Plosser. «Trends and Random Walks in Macroeconomic Time Series: Some Evidence and Implications.» Journal of Monetary Economics. Vol. 10, 1982, pp. 130–162.